大名鼎鼎的分布式緩存系統memcached,在開源社區中可謂是無人不知無人不曉,memcached支持分布式的橫向擴展,但memcached的服務端卻是單實例,并無"分布式"的功能,所謂的分布式只是客戶端在存儲的主鍵做分布的存儲;還有memcached組件緩存對象,如果組件無進行序列化必定無法正確取得數據;如何使用memcached的java組件來監控memcached的運行狀態;以上等等的問題是我在日常的工作中碰到并解決的,拿出來跟大家做個分享^_^
對象的序列化
首先memcached是獨立的服務器組件,獨立于應用系統,從客戶端保存和讀取對象到memcached是必須通過網絡傳輸,因為網絡傳輸都是二進制的數據,所以所有的對象都必須經過序列化,否則無法存儲到memcahced的服務器端.
正如我們以往在集群中應用的序列化一樣,memcached的序列化的性能也是往往讓大家頭疼,如果我們對我們的domain類進行對象的序列化,第一次序列化時間會比較長,但后續會優化,也就是說序列化最大的消耗不是對象的序列化,而是類的序列化,如果存儲的只是一個String對象,這種情況是最理想的,省去了序列化的操作.實際上String對象本身已經實現了序列化接口,無法我們再次去進行序列化操作.
memcached的原子加法
記錄一下上次犯得一個錯誤
<%
static int count = 0;
count++;
MemCachedClient mcc = new MemCachedClient();
mcc.add("test.html", count);
%>
這段代碼的作用是將test.html的用戶訪問次數保存到memcached中,粗劣一看好像并無錯誤,但在高并發時的出來的訪問數據一定是小于實際的訪問數量,當然這里并不是memcached對象鎖的問題,主要還是程序中線程的同步問題,但是如果使用java的synchronized或lock那么在性能上肯定是無法忍受的,memcached客戶端組件帶有原子性的加法和減法
<%
MemCachedClient mcc = new MemCachedClient();
System.out.println(mcc.addOrIncr("test.html",1));
%>
long addORIncr(String key,long inc)為計數器值增加inc,如果計數器不存在,則保存inc為計數器的值,必須注意的是服務器端不會對超過2的32次方的行為進行檢查
分布式的mencached
memcached雖然是屬于分布式的緩存服務器,但實際上memcached服務端之間并無分布式的功能,不會互相通信共享數據,如何進行分布式,這完全是取決于客戶端的實現
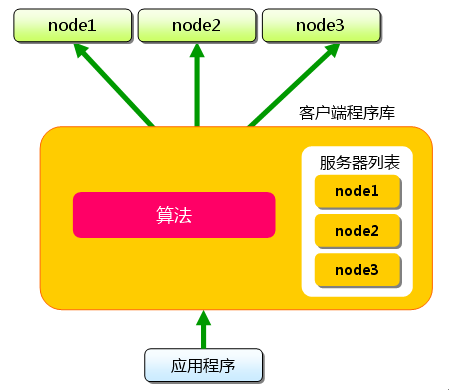
假設我們現在有三臺memcached服務器分別為node1,node2,node3,應用程序要保存鍵名分別為"test1","test2","test3",客戶端實現的算法就是根據鍵名來決定保存數據的memcached服務器,我們將"test1"保存到node1,"test2"保存到node2,"test3"保存到node3,并且在讀取緩存數據也是通過一樣的算法從各臺服務器上讀取相應的key,這樣通過一個最簡單的算法將不同的鍵保存到不同的服務器上,實現了memcached的分布式.
但是這種算法很難確保每臺服務器得到較為平均的數據量,我們需要改變一下客戶端的算法,簡單來說,就是根據服務器的臺數的余數進行分散
<%
"test1".hashCode()%3
%>
根據key的java.lang.String.hashCode()取得散列值,再將值模服務器的臺數得到余數值,我們再根據這個余數值來判定這個key要存入哪一臺服務器,當key的數量越來越大,對key的散列取模也會趨向平均,基本可以保證幾臺memcached服務器所存儲的緩存量趨向平均
似乎很完美,余數計算的方法很簡單,數據的分散性也很優秀,但也有其缺點,就是當需要添加或移除服務器時,緩存的重組代價是相當巨大的,添加或移除服務器時,余數就會發生變化,這樣就無法取到與原來緩存時相同的服務器.
網上介紹的Consistent Hashing算法基本上可以解決這個問題,這里做個簡單的說明,首先是求出memcached服務器節點的哈希值,并將其配置到0-2的32次方的圓上,然后用同樣的方法求出存儲數據的鍵的哈希值,并映射到圓上.然后從數據映射到的位置開始順時針查找,將數據保存到找到的第一個服務器上.如果超過2的32次方仍然找不到服務器,就會保存到第一臺memcached服務器上
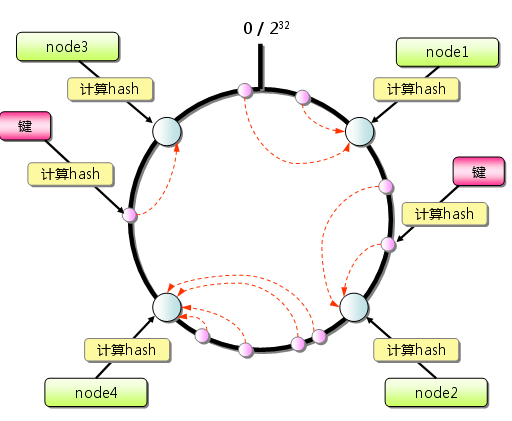
從上圖的狀態中添加一臺memcached服務器。余數分布式算法由于保存鍵的服務器會發生巨大變化而影響緩存的命中率,但Consistent Hashing中,只有在continuum上增加服務器的地點逆時針方向的第一臺服務器上的鍵會受到影響
幾種連接客戶端的對比
目前java的memcached主要有Java-Memcached-Client,Xmemached,Spymemcached三種,這三個客戶端的性能測試可以看
http://xmemcached.googlecode.com/svn/trunk/benchmark/benchmark.html
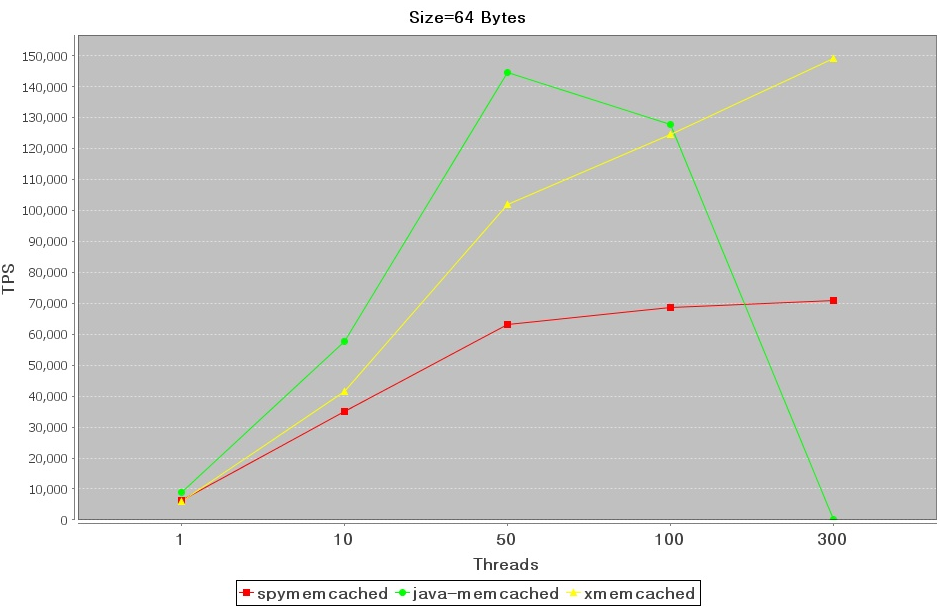
請求的資源為64Bytes,在低并發Java-Memcached-Client是占有一定的優勢,但在并發數超過100以后,Java-Memcached-Client是呈現直線下跌,并發數達到300已經無法承受,Spymemcached和Xmemached表現相對穩定,特別是Xmemached無論在低并發或高并發都保持優秀的性能表現
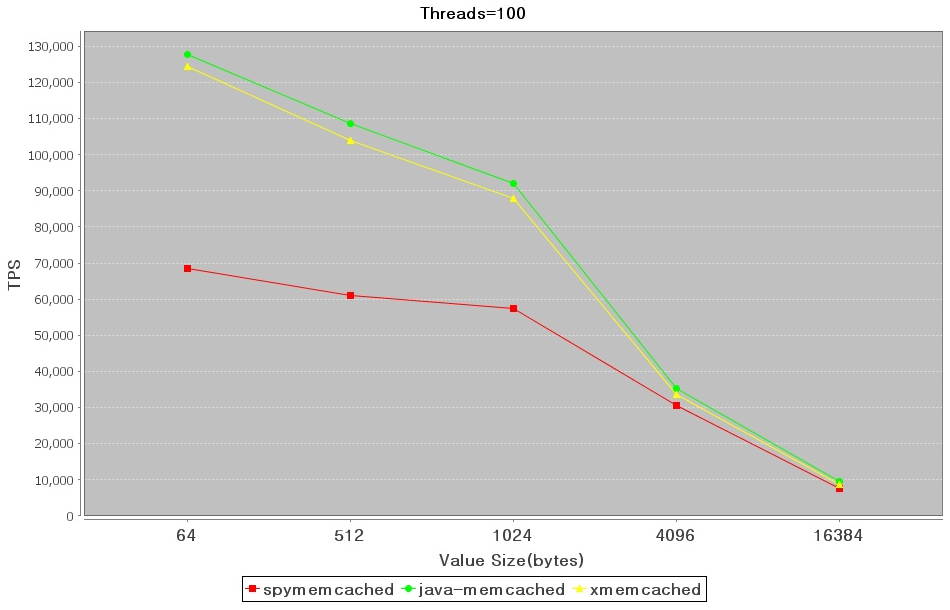
并發數固定為100時,在小文件的請求Java-Memcached-Client還是占有優勢,當隨著請求的size越來越大,三者趨向于同一點
如果你對memcached訪問的負載不高,那么Java-Memcached-Client是一個不錯的選擇,如果你對memcached訪問的負載要求較高,推薦使用Xmemached,如果需要異步的批量處理,可以選擇Spymemcached,如果你什么都不知道,那么建議使用Xmemached,因為無論在何種情況,它都可以表現出較好的性能,雖然不是最好
監控memcached
推薦使用nagios或cactis進行監控,nagios沒有配置過,cactis是需要下載一個腳本插件
這里推薦一個從網上淘來的php,只要把它放到你的機器中,當然你的機器要支持php環境,將此php放入你的網頁訪問網絡就可以訪問
下載
http://www.aygfsteel.com/Files/dongbule/cacti/memcache.rar
修改php以下幾個選項
define('ADMIN_USERNAME','memcache'); // Admin Username
define('ADMIN_PASSWORD','password'); // Admin Password
$MEMCACHE_SERVERS[] = '192.168.1.100:11211'; // add more as an array
#$MEMCACHE_SERVERS[] = 'mymemcache-server2:11211'; // add more as an array
監控的平臺
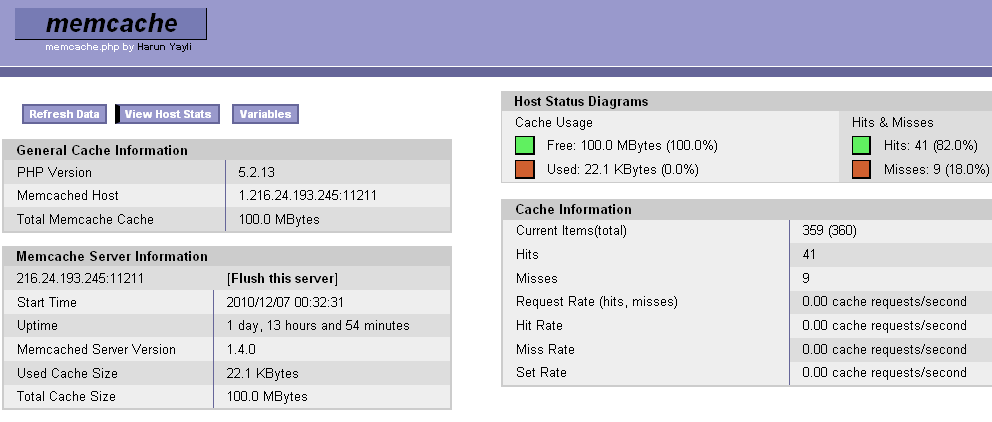
理解memcached的刪除機制
memcached內部不會監視記錄是否過期,而是在get時查看記錄的時間戳,檢查記錄是否過期, 這種技術被稱為lazy(惰性)expiration.因此,memcached不會在過期監視上耗費CPU時間
memcached會優先使用已超時的記錄的空間,并使用LRU算法來分配空間,因此當memcached的內存空間不足,就從最近違背使用的記錄中搜索,并將空間分配給新的記錄
不過在某些情況下LRU機制會造成某些麻煩,如你并不想要淘汰已被緩存過的記錄,可以在memcached啟動時添加 -M 參數來禁止LRU,但這樣在memcached的內存用盡時,memcached會返回錯誤,是否使用LRU,在于你的需求
----------------------------------------
by 陳于喆
QQ:34174409
Mail: dongbule@163.com