一、相關(guān)概念
基本回收算法
-
引用計數(shù)(Reference Counting)
比較古老的回收算法。原理是此對象有一個引用,即增加一個計數(shù),刪除一個引用則減少一個計數(shù)。垃圾回收時,只用收集計數(shù)為0的對象。此算法最致命的是無法處理循環(huán)引用的問題。
-
標(biāo)記-清除(Mark-Sweep)
此算法執(zhí)行分兩階段。第一階段從引用根節(jié)點(diǎn)開始標(biāo)記所有被引用的對象,第二階段遍歷整個堆,把未標(biāo)記的對象清除。此算法需要暫停整個應(yīng)用,同時,會產(chǎn)生內(nèi)存碎片。
-
復(fù)制(Copying)
此
算法把內(nèi)存空間劃為兩個相等的區(qū)域,每次只使用其中一個區(qū)域。垃圾回收時,遍歷當(dāng)前使用區(qū)域,把正在使用中的對象復(fù)制到另外一個區(qū)域中。次算法每次只處理
正在使用中的對象,因此復(fù)制成本比較小,同時復(fù)制過去以后還能進(jìn)行相應(yīng)的內(nèi)存整理,不過出現(xiàn)“碎片”問題。當(dāng)然,此算法的缺點(diǎn)也是很明顯的,就是需要兩倍
內(nèi)存空間。
-
標(biāo)記-整理(Mark-Compact)
此算法結(jié)合了“標(biāo)記-清除”和“復(fù)
制”兩個算法的優(yōu)點(diǎn)。也是分兩階段,第一階段從根節(jié)點(diǎn)開始標(biāo)記所有被引用對象,第二階段遍歷整個堆,把清除未標(biāo)記對象并且把存活對象“壓縮”到堆的其中一
塊,按順序排放。此算法避免了“標(biāo)記-清除”的碎片問題,同時也避免了“復(fù)制”算法的空間問題。
-
增量收集(Incremental Collecting)
實(shí)施垃圾回收算法,即:在應(yīng)用進(jìn)行的同時進(jìn)行垃圾回收。不知道什么原因JDK5.0中的收集器沒有使用這種算法的。
-
分代(Generational Collecting)
基于對對象生命周期分析后得出的垃圾回收算法。把對象分為年青代、年老代、持久代,對不同生命周期的對象使用不同的算法(上述方式中的一個)進(jìn)行回收。現(xiàn)在的垃圾回收器(從J2SE1.2開始)都是使用此算法的。
分代垃圾回收詳述
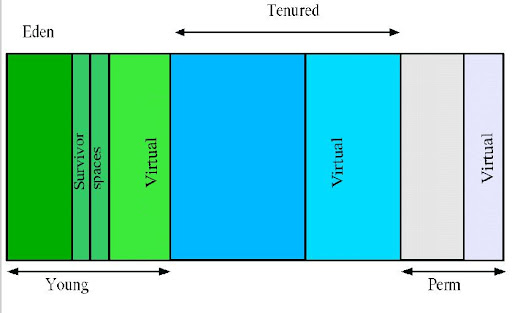
如上圖所示,為Java堆中的各代分布。
-
Young(年輕代)
年
輕代分三個區(qū)。一個Eden區(qū),兩個Survivor區(qū)。大部分對象在Eden區(qū)中生成。當(dāng)Eden區(qū)滿時,還存活的對象將被復(fù)制到Survivor區(qū)
(兩個中的一個),當(dāng)這個Survivor區(qū)滿時,此區(qū)的存活對象將被復(fù)制到另外一個Survivor區(qū),當(dāng)這個Survivor去也滿了的時候,從第一
個Survivor區(qū)復(fù)制過來的并且此時還存活的對象,將被復(fù)制“年老區(qū)(Tenured)”。需要注意,Survivor的兩個區(qū)是對稱的,沒先后關(guān)
系,所以同一個區(qū)中可能同時存在從Eden復(fù)制過來
對象,和從前一個Survivor復(fù)制過來的對象,而復(fù)制到年老區(qū)的只有從第一個Survivor去過來的對象。而且,Survivor區(qū)總有一個是空
的。
-
Tenured(年老代)
年老代存放從年輕代存活的對象。一般來說年老代存放的都是生命期較長的對象。
-
Perm(持久代)
用
于存放靜態(tài)文件,如今Java類、方法等。持久代對垃圾回收沒有顯著影響,但是有些應(yīng)用可能動態(tài)生成或者調(diào)用一些class,例如Hibernate等,
在這種時候需要設(shè)置一個比較大的持久代空間來存放這些運(yùn)行過程中新增的類。持久代大小通過-XX:MaxPermSize=<N>進(jìn)行設(shè)置。
GC類型
GC有兩種類型:Scavenge GC和Full GC
。
- Scavenge GC
一般情況下,當(dāng)新對象生成,并且在Eden申請空間失敗時,就好觸發(fā)Scavenge GC,堆Eden區(qū)域進(jìn)行GC,清除非存活對象,并且把尚且存活的對象移動到Survivor區(qū)。然后整理Survivor的兩個區(qū)。
- Full GC
對整個堆進(jìn)行整理,包括Young、Tenured和Perm。Full GC比Scavenge GC要慢,因此應(yīng)該盡可能減少Full GC。有如下原因可能導(dǎo)致Full GC:
- 上一次GC之后Heap的各域分配策略動態(tài)變化
分代垃圾回收過程演示




二、垃圾回收器
目前的收集器主要有三種:串行收集器、并行收集器、并發(fā)收集器
。
-
串行收集器
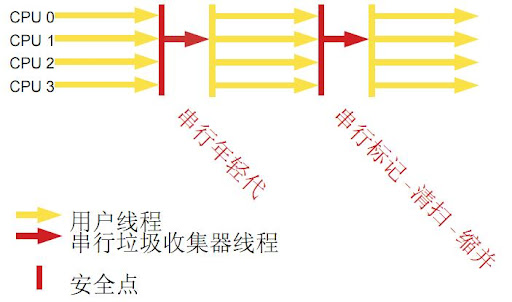
使用單線程處理所有垃圾回收工作,因為無需多線程交互,所以效率比較高。但是,也無法使用多處理器的優(yōu)勢,所以此收集器適合單處理器機(jī)器。當(dāng)然,此收集器也可以用在小數(shù)據(jù)量(100M
左右)情況下的多處理器機(jī)器上。可以使用-XX:+UseSerialGC
打開。
-
并行收集器
擊查看原始大小圖片")
- 對年輕代進(jìn)行并行垃圾回收,因此可以減少垃圾回收時間。一般在多線程多處理器機(jī)器上使用。使用-XX:+UseParallelGC
.打開。并行收集器在J2SE5.0第六6更新上引入,在Java SE6.0中進(jìn)行了增強(qiáng)--可以堆年老代進(jìn)行并行收集。如果年老代不使用并發(fā)收集的話,是使用單線程進(jìn)行垃圾回收
,因此會制約擴(kuò)展能力。使用-XX:+UseParallelOldGC
打開。
- 使用-XX:ParallelGCThreads=<N>
設(shè)置并行垃圾回收的線程數(shù)。此值可以設(shè)置與機(jī)器處理器數(shù)量相等
。
- 此收集器可以進(jìn)行如下配置:
-
最大垃圾回收暫停:
指定垃圾回收時的最長暫停時間,通過-XX:MaxGCPauseMillis=<N>
指定。<N>為毫秒.如果指定了此值的話,堆大小和垃圾回收相關(guān)參數(shù)會進(jìn)行調(diào)整以達(dá)到指定值
。設(shè)定此值可能會減少應(yīng)用的吞吐量。
-
吞吐量:
吞吐量為垃圾回收時間與非垃圾回收時間的比值
,通過-XX:GCTimeRatio=<N>
來設(shè)定,公式為1/(1+N)
。例如,-XX:GCTimeRatio=19時,表示5%的時間用于垃圾回收。默認(rèn)情況為99,即1%的時間用于垃圾回收。
-
并發(fā)收集器
可以保證大部分工作都并發(fā)進(jìn)行(應(yīng)用不停止),垃圾回收只暫停很少的時間,此收集器適合對響應(yīng)時間要求比較高的中、大規(guī)模應(yīng)用。使用-XX:+UseConcMarkSweepGC
打開。
擊查看原始大小圖片")
- 并
發(fā)收集器主要減少年老代的暫停時間,他在應(yīng)用不停止的情況下使用獨(dú)立的垃圾回收線程,跟蹤可達(dá)對象。在每個年老代垃圾回收周期中,在收集初期并發(fā)收集器會
對整個應(yīng)用進(jìn)行簡短的暫停,在收集中還會再暫停一次。第二次暫停會比第一次稍長,在此過程中多個線程同時進(jìn)行垃圾回收工作。
- 并發(fā)收集器使用處理器換來短暫的停頓時間
。在一個N個處理器的系統(tǒng)上,并發(fā)收集部分使用K/N
個可用處理器進(jìn)行回收,一般情況下1<=K<=N/4
。
- 在只有一個處理器的主機(jī)上使用并發(fā)收集器
,設(shè)置為incremental mode
模式也可獲得較短的停頓時間。
-
浮動垃圾
:由于在應(yīng)用運(yùn)行的同時進(jìn)行垃圾回收,所以有些垃圾可能在垃圾回收進(jìn)行完成時產(chǎn)生,這樣就造成了“Floating Garbage”,這些垃圾需要在下次垃圾回收周期時才能回收掉。所以,并發(fā)收集器一般需要20%
的預(yù)留空間用于這些浮動垃圾。
-
Concurrent Mode Failure
:并發(fā)收集器在應(yīng)用運(yùn)行時進(jìn)行收集,所以需要保證堆在垃圾回收的這段時間有足夠的空間供程序使用,否則,垃圾回收還未完成,堆空間先滿了。這種情況下將會發(fā)生“并發(fā)模式失敗”,此時整個應(yīng)用將會暫停,進(jìn)行垃圾回收。
-
啟動并發(fā)收集器
:因為并發(fā)收集在應(yīng)用運(yùn)行時進(jìn)行收集,所以必須保證收集完成之前有足夠的內(nèi)存空間供程序使用,否則會出現(xiàn)“Concurrent Mode Failure”。通過設(shè)置-XX:CMSInitiatingOccupancyFraction=<N>
指定還有多少剩余堆時開始執(zhí)行并發(fā)收集
-
小結(jié)
-
串行處理器:
--適用情況:數(shù)據(jù)量比較小(100M左右);單處理器下并且對響應(yīng)時間無要求的應(yīng)用。
--缺點(diǎn):只能用于小型應(yīng)用
-
并行處理器:
--適用情況:“對吞吐量有高要求”,多CPU、對應(yīng)用響應(yīng)時間無要求的中、大型應(yīng)用。舉例:后臺處理、科學(xué)計算。
--缺點(diǎn):應(yīng)用響應(yīng)時間可能較長
-
并發(fā)處理器:
--適用情況:“對響應(yīng)時間有高要求”,多CPU、對應(yīng)用響應(yīng)時間有較高要求的中、大型應(yīng)用。舉例:Web服務(wù)器/應(yīng)用服務(wù)器、電信交換、集成開發(fā)環(huán)境。
三、常見配置舉例
-
堆大小設(shè)置
JVM
中最大堆大小有三方面限制:相關(guān)操作系統(tǒng)的數(shù)據(jù)模型(32-bt還是64-bit)限制;系統(tǒng)的可用虛擬內(nèi)存限制;系統(tǒng)的可用物理內(nèi)存限制。32位系統(tǒng)
下,一般限制在1.5G~2G;64為操作系統(tǒng)對內(nèi)存無限制。我在Windows Server 2003
系統(tǒng),3.5G物理內(nèi)存,JDK5.0下測試,最大可設(shè)置為1478m。
典型設(shè)置:
-
java -Xmx3550m -Xms3550m -Xmn2g
-Xss128k
-
Xmx3550m
:設(shè)置JVM最大可用內(nèi)存為3550M。
-Xms3550m
:設(shè)置JVM促使內(nèi)存為3550m。此值可以設(shè)置與-Xmx相同,以避免每次垃圾回收完成后JVM重新分配內(nèi)存。
-Xmn2g
:設(shè)置年輕代大小為2G。整個堆大小=年輕代大小 + 年老代大小 + 持久代大小
。持久代一般固定大小為64m,所以增大年輕代后,將會減小年老代大小。此值對系統(tǒng)性能影響較大,Sun官方推薦配置為整個堆的3/8。
-Xss128k
:
設(shè)置每個線程的堆棧大小。JDK5.0以后每個線程堆棧大小為1M,以前每個線程堆棧大小為256K。更具應(yīng)用的線程所需內(nèi)存大小進(jìn)行調(diào)整。在相同物理內(nèi)
存下,減小這個值能生成更多的線程。但是操作系統(tǒng)對一個進(jìn)程內(nèi)的線程數(shù)還是有限制的,不能無限生成,經(jīng)驗值在3000~5000左右。
-
java -Xmx3550m -Xms3550m
-Xss128k -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxPermSize=16m -XX:MaxTenuringThreshold=0
-XX:NewRatio=4
:設(shè)置年輕代(包括Eden和兩個Survivor區(qū))與年老代的比值(除去持久代)。設(shè)置為4,則年輕代與年老代所占比值為1:4,年輕代占整個堆棧的1/5
-XX:SurvivorRatio=4
:設(shè)置年輕代中Eden區(qū)與Survivor區(qū)的大小比值。設(shè)置為4,則兩個Survivor區(qū)與一個Eden區(qū)的比值為2:4,一個Survivor區(qū)占整個年輕代的1/6
-XX:MaxPermSize=16m
:設(shè)置持久代大小為16m。
-XX:MaxTenuringThreshold=0
:設(shè)置垃圾最大年齡。如果設(shè)置為0的話,則年輕代對象不經(jīng)過Survivor區(qū),直接進(jìn)入年老代
。對于年老代比較多的應(yīng)用,可以提高效率。如果將此值設(shè)置為一個較大值,則年輕代對象會在Survivor區(qū)進(jìn)行多次復(fù)制,這樣可以增加對象再年輕代的存活時間
,增加在年輕代即被回收的概論。
-
回收器選擇
JVM給了三種選擇:串行收集器、并行收集器、并發(fā)收集器
,但是串行收集器只適用于小數(shù)據(jù)量的情況,所以這里的選擇主要針對并行收集器和并發(fā)收集器。默認(rèn)情況下,JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在啟動時加入相應(yīng)參數(shù)。JDK5.0以后,JVM會根據(jù)當(dāng)前系統(tǒng)配置
進(jìn)行判斷。
-
吞吐量優(yōu)先
的并行收集器
如上文所述,并行收集器主要以到達(dá)一定的吞吐量為目標(biāo),適用于科學(xué)技術(shù)和后臺處理等。
典型配置
:
-
java -Xmx3800m -Xms3800m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20
-XX:+UseParallelGC
:選擇垃圾收集器為并行收集器。此配置僅對年輕代有效。即上述配置下,年輕代使用并發(fā)收集,而年老代仍舊使用串行收集。
-XX:ParallelGCThreads=20
:配置并行收集器的線程數(shù),即:同時多少個線程一起進(jìn)行垃圾回收。此值最好配置與處理器數(shù)目相等。
-
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:ParallelGCThreads=20 -XX:+UseParallelOldGC
-XX:+UseParallelOldGC
:配置年老代垃圾收集方式為并行收集。JDK6.0支持對年老代并行收集。
-
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:MaxGCPauseMillis=100
:
設(shè)置每次年輕代垃圾回收的最長時間,如果無法滿足此時間,JVM會自動調(diào)整年輕代大小,以滿足此值。
-
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseParallelGC -XX:MaxGCPauseMillis=100
-XX:+UseAdaptiveSizePolicy
-XX:+UseAdaptiveSizePolicy
:設(shè)置此選項后,并行收集器會自動選擇年輕代區(qū)大小和相應(yīng)的Survivor區(qū)比例,以達(dá)到目標(biāo)系統(tǒng)規(guī)定的最低相應(yīng)時間或者收集頻率等,此值建議使用并行收集器時,一直打開。
-
響應(yīng)時間優(yōu)先
的并發(fā)收集器
如上文所述,并發(fā)收集器主要是保證系統(tǒng)的響應(yīng)時間,減少垃圾收集時的停頓時間。適用于應(yīng)用服務(wù)器、電信領(lǐng)域等。
典型配置
:
-
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:ParallelGCThreads=20 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
:設(shè)置年老代為并發(fā)收集。測試中配置這個以后,
-XX:NewRatio=4的配置失效了,原因不明。所以,此時年輕代大小最好用-Xmn設(shè)置。
-XX:+UseParNewGC
:
設(shè)置年輕代為并行收集。可與CMS收集同時使用。JDK5.0以上,JVM會根據(jù)系統(tǒng)配置自行設(shè)置,所以無需再設(shè)置此值。
-
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k -XX:+UseConcMarkSweepGC
-XX:CMSFullGCsBeforeCompaction=5
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction
:由于并發(fā)收集器不對內(nèi)存空間進(jìn)行壓縮、整理,所以運(yùn)行一段時間以后會產(chǎn)生“碎片”,使得運(yùn)行效率降低。此值設(shè)置運(yùn)行多少次GC以后對內(nèi)存空間進(jìn)行壓縮、整理。
-XX:+UseCMSCompactAtFullCollection
:打開對年老代的壓縮。可能會影響性能,但是可以消除碎片
-
輔助信息
JVM提供了大量命令行參數(shù),打印信息,供調(diào)試使用。主要有以下一些:
-
-XX:+PrintGC
輸出形式:[GC 118250K->113543K(130112K), 0.0094143 secs]
[Full GC 121376K->10414K(130112K), 0.0650971 secs]
-
-XX:+PrintGCDetails
輸出形式:[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs]
[GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured:
112761K->10414K(121024K), 0.0433488 secs]
121376K->10414K(130112K), 0.0436268 secs]
-
-XX:+PrintGCTimeStamps
-XX:+PrintGC:PrintGCTimeStamps可與上面兩個混合使用
輸出形式:11.851: [GC 98328K->93620K(130112K), 0.0082960 secs]
-
-XX:+PrintGCApplicationConcurrentTime:
打印每次垃圾回收前,程序未中斷的執(zhí)行時間。可與上面混合使用
輸出形式:Application time: 0.5291524 seconds
-
-XX:+PrintGCApplicationStoppedTime
:打印垃圾回收期間程序暫停的時間。可與上面混合使用
輸出形式:Total time for which application threads were stopped: 0.0468229 seconds
-
-XX:PrintHeapAtGC
:打印GC前后的詳細(xì)堆棧信息
輸出形式:
34.702: [GC {Heap before gc invocations=7:
def new generation total 55296K, used 52568K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 99% used
[0x1ebd0000, 0x21bce430, 0x21bd0000)
from space 6144K, 55% used
[0x221d0000, 0x22527e10, 0x227d0000)
to space 6144K, 0% used [0x21bd0000, 0x21bd0000, 0x221d0000)
tenured generation total 69632K, used 2696K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 3% used
[0x227d0000, 0x22a720f8, 0x22a72200, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
34.735: [DefNew: 52568K->3433K(55296K), 0.0072126 secs] 55264K->6615K(124928K)Heap after gc invocations=8:
def new generation total 55296K, used 3433K [0x1ebd0000, 0x227d0000, 0x227d0000)
eden space 49152K, 0% used
[0x1ebd0000, 0x1ebd0000, 0x21bd0000)
from space 6144K, 55% used [0x21bd0000, 0x21f2a5e8, 0x221d0000)
to space 6144K, 0% used [0x221d0000, 0x221d0000, 0x227d0000)
tenured generation total 69632K, used 3182K [0x227d0000, 0x26bd0000, 0x26bd0000)
the space 69632K, 4% used
[0x227d0000, 0x22aeb958, 0x22aeba00, 0x26bd0000)
compacting perm gen total 8192K, used 2898K [0x26bd0000, 0x273d0000, 0x2abd0000)
the space 8192K, 35% used [0x26bd0000, 0x26ea4ba8, 0x26ea4c00, 0x273d0000)
ro space 8192K, 66% used [0x2abd0000, 0x2b12bcc0, 0x2b12be00, 0x2b3d0000)
rw space 12288K, 46% used [0x2b3d0000, 0x2b972060, 0x2b972200, 0x2bfd0000)
}
, 0.0757599 secs]
-
-Xloggc:filename
:與上面幾個配合使用,把相關(guān)日志信息記錄到文件以便分析。
-
常見配置匯總
- 堆設(shè)置
-
-Xms
:初始堆大小
-
-Xmx
:最大堆大小
-
-XX:NewSize=n
:設(shè)置年輕代大小
-
-XX:NewRatio=n:
設(shè)置年輕代和年老代的比值。如:為3,表示年輕代與年老代比值為1:3,年輕代占整個年輕代年老代和的1/4
-
-XX:SurvivorRatio=n
:年輕代中Eden區(qū)與兩個Survivor區(qū)的比值。注意Survivor區(qū)有兩個。如:3,表示Eden:Survivor=3:2,一個Survivor區(qū)占整個年輕代的1/5
-
-XX:MaxPermSize=n
:設(shè)置持久代大小
- 收集器設(shè)置
-
-XX:+UseSerialGC
:設(shè)置串行收集器
-
-XX:+UseParallelGC
:設(shè)置并行收集器
-
-XX:+UseParalledlOldGC
:設(shè)置并行年老代收集器
-
-XX:+UseConcMarkSweepGC
:設(shè)置并發(fā)收集器
- 垃圾回收統(tǒng)計信息
-
-XX:+PrintGC
-
-XX:+PrintGCDetails
-
-XX:+PrintGCTimeStamps
-
-Xloggc:filename
- 并行收集器設(shè)置
-
-XX:ParallelGCThreads=n
:設(shè)置并行收集器收集時使用的CPU數(shù)。并行收集線程數(shù)。
-
-XX:MaxGCPauseMillis=n
:設(shè)置并行收集最大暫停時間
-
-XX:GCTimeRatio=n
:設(shè)置垃圾回收時間占程序運(yùn)行時間的百分比。公式為1/(1+n)
- 并發(fā)收集器設(shè)置
-
-XX:+CMSIncrementalMode
:設(shè)置為增量模式。適用于單CPU情況。
-
-XX:ParallelGCThreads=n
:設(shè)置并發(fā)收集器年輕代收集方式為并行收集時,使用的CPU數(shù)。并行收集線程數(shù)。
四、調(diào)優(yōu)總結(jié)
-
年輕代大小選擇
-
響應(yīng)時間優(yōu)先的應(yīng)用
:盡可能設(shè)大,直到接近系統(tǒng)的最低響應(yīng)時間限制
(根據(jù)實(shí)際情況選擇)。在此種情況下,年輕代收集發(fā)生的頻率也是最小的。同時,減少到達(dá)年老代的對象。
-
吞吐量優(yōu)先的應(yīng)用
:盡可能的設(shè)置大,可能到達(dá)Gbit的程度。因為對響應(yīng)時間沒有要求,垃圾收集可以并行進(jìn)行,一般適合8CPU以上的應(yīng)用。
-
年老代大小選擇
-
響應(yīng)時間優(yōu)先的應(yīng)用
:年老代使用并發(fā)收集器,所以其大小需要小心設(shè)置,一般要考慮并發(fā)會話率
和會話持續(xù)時間
等一些參數(shù)。如果堆設(shè)置小了,可以會造成內(nèi)存碎片、高回收頻率以及應(yīng)用暫停而使用傳統(tǒng)的標(biāo)記清除方式;如果堆大了,則需要較長的收集時間。最優(yōu)化的方案,一般需要參考以下數(shù)據(jù)獲得:
- 并發(fā)垃圾收集信息
- 持久代并發(fā)收集次數(shù)
- 傳統(tǒng)GC信息
- 花在年輕代和年老代回收上的時間比例
減少年輕代和年老代花費(fèi)的時間,一般會提高應(yīng)用的效率
-
吞吐量優(yōu)先的應(yīng)用
:一般吞吐量優(yōu)先的應(yīng)用都有一個很大的年輕代和一個較小的年老代。原因是,這樣可以盡可能回收掉大部分短期對象,減少中期的對象,而年老代盡存放長期存活對象。
-
較小堆引起的碎片問題
因
為年老代的并發(fā)收集器使用標(biāo)記、清除算法,所以不會對堆進(jìn)行壓縮。當(dāng)收集器回收時,他會把相鄰的空間進(jìn)行合并,這樣可以分配給較大的對象。但是,當(dāng)堆空間
較小時,運(yùn)行一段時間以后,就會出現(xiàn)“碎片”,如果并發(fā)收集器找不到足夠的空間,那么并發(fā)收集器將會停止,然后使用傳統(tǒng)的標(biāo)記、清除方式進(jìn)行回收。如果出
現(xiàn)“碎片”,可能需要進(jìn)行如下配置:
-
-XX:+UseCMSCompactAtFullCollection
:使用并發(fā)收集器時,開啟對年老代的壓縮。
-
-XX:CMSFullGCsBeforeCompaction=0
:上面配置開啟的情況下,這里設(shè)置多少次Full GC后,對年老代進(jìn)行壓縮