小時候老師總說:有壓力才有動力。這次沖動起源于自己發起了一個xx
群,群里面承諾一天一分享,但沒有相關的工具可以統計,同時更多的需求不斷涌現(這不剛才還有群里的朋友說討論希望能夠每周出個定向題),問了一下xx
群開發的朋友,說暫時不開放接口,完蛋,這長期人肉我可沒那個功夫,看了看筆記本上緩慢學習中的python
,得,就這樣把,自己模擬登錄,然后用python
做個簡單爬蟲去抓取數據作為工具數據來源。
學語言我個人還是覺得首先了解他的特點和適用場景,然后就是動手干(官方文檔+g出來的一大堆ref)。寫慣Java的人,一旦介入到動態語言,就會覺得一身輕松。Python可以采用交互的命令行工具,即時寫,即時看,也可以搞個eclipse插件和Java一樣寫。用了urllib庫和cookielib庫,幾句話就可以提交請求和保持cookie了。
接下來就是去看需要登錄網站的登錄模式。看了一下這個網站沒有走https,但是也不是很簡單的明文傳輸,那么就要用個工具看看怎么回事了。Chrome和firefox + firebug都是極佳的工具(以前在IE下搞過破解版的httpwatch,太麻煩了),后面就用chrome來做介紹,它內置的控制臺還是很強大的,包括我這里沒有介紹的性能檢測部分的功能。
首先你需要記錄下你進入這個登錄首頁時候所有的http請求,不是說一定只記錄臨門一腳的提交請求就可以了,現在為了防范CSRF等攻擊,都會做一些安全方面的preload page,下面就一張圖一些描述來說明這個過程:
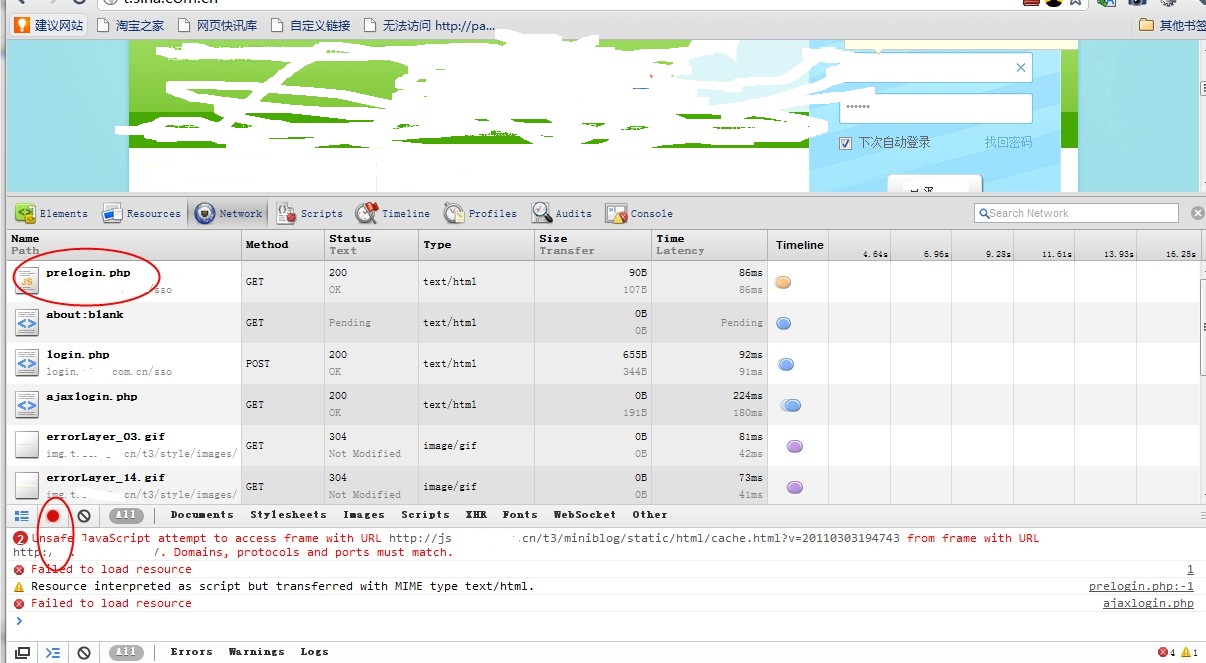
這張圖是用chrome來記錄進入頁面到點擊提交過程中所有的請求,其中紅色圈圈中的那個紅色點就是記錄所有的請求,就算當前頁面被重新載入或者302跳轉到其他地方去,前面的記錄依然存在,這很有必要,不然登錄成功后就找不到前面的記錄了。可以看到紅色的圈中有一個prelogin的頁面,當然現在還不好確定干啥用,接著往下看。
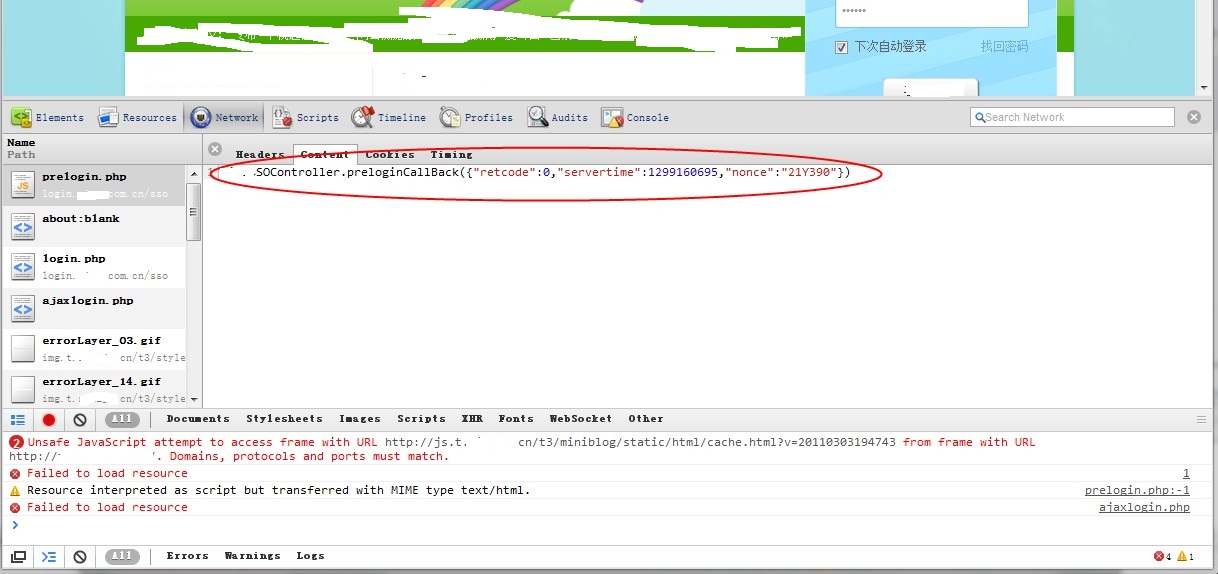
選中這個prelogin頁面,然后看到右面就會出現其相關內容,可以選擇content看看它的范圍,結果是有范圍的,返回了三個值,其中nonce(隨機數)常常被用于防CSRF攻擊或者防重放。至此還看不出什么端倪,接著看
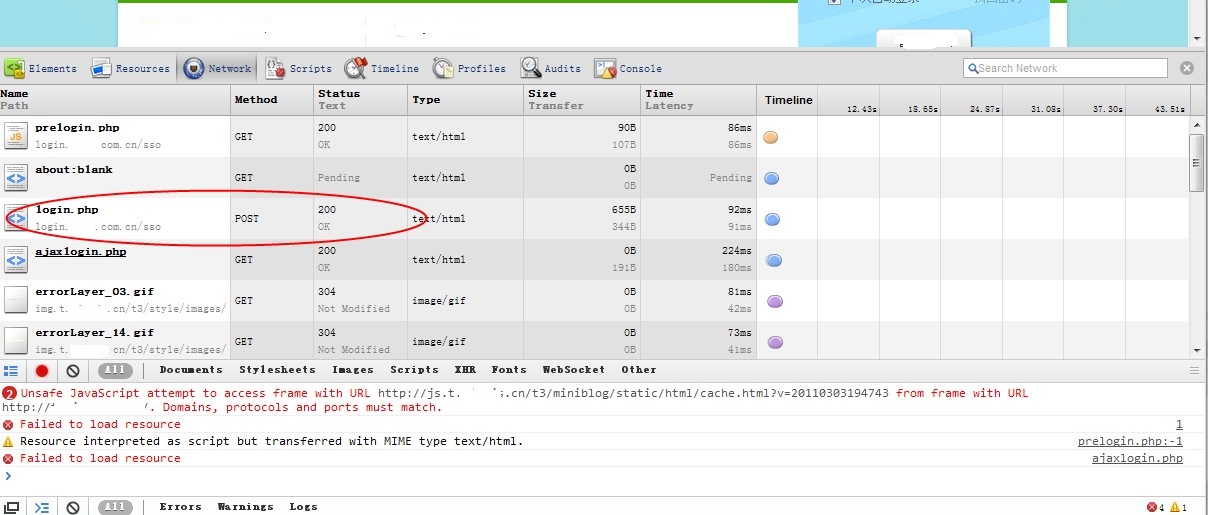
Login.php是post類型的,多半就是提交驗證的(當然后面談到仔細去看兩個來回交互的js就可以很清楚的知道點擊的那個超鏈接的btn就是觸發這個提交)
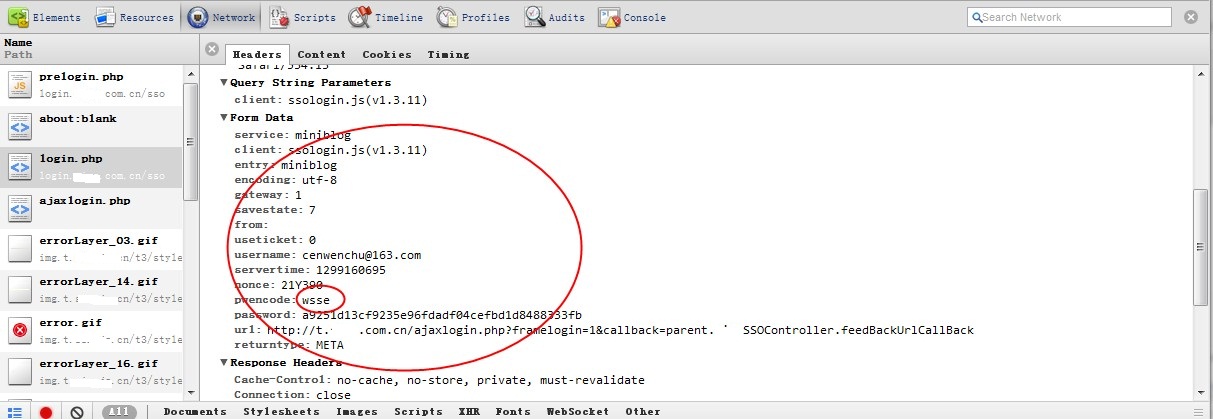
選中login.php的這個post請求,直接看它的Form Data,里面就是所有提交的參數,可以發現nonce,servertime都在此列,同時看password已經被加密,而下面有個關鍵詞“wsse”,其實當年在做webservice接觸的比較多,是一種避免用戶密碼明文傳遞的驗證加密算法,有興趣的同學可以直接搜索一下,有一個pdf很清楚的說明了一切。其實這個頁面我反復不同的密碼請求了幾次,相同的密碼請求了幾次,最后確定哪些內容是動態變化的,哪些是固定的,最后其實就是password,nonce,servertime是變化的,其他都是固化的。這下就簡單了,首先模擬請求prelogin,這直接看看prelogin的get中url便知如何請求,然后將結果拼湊到下一次post到login的請求中,但最后就是password怎么計算出來,先嘗試了直接用標準的模式來生成base64(sha(password+nonce+servertime)),結果不行,那么就要仔細看看js代碼了,其實從剛才到現在都是從現象來猜一些問題,真的不行的時候還是要靠看代碼。
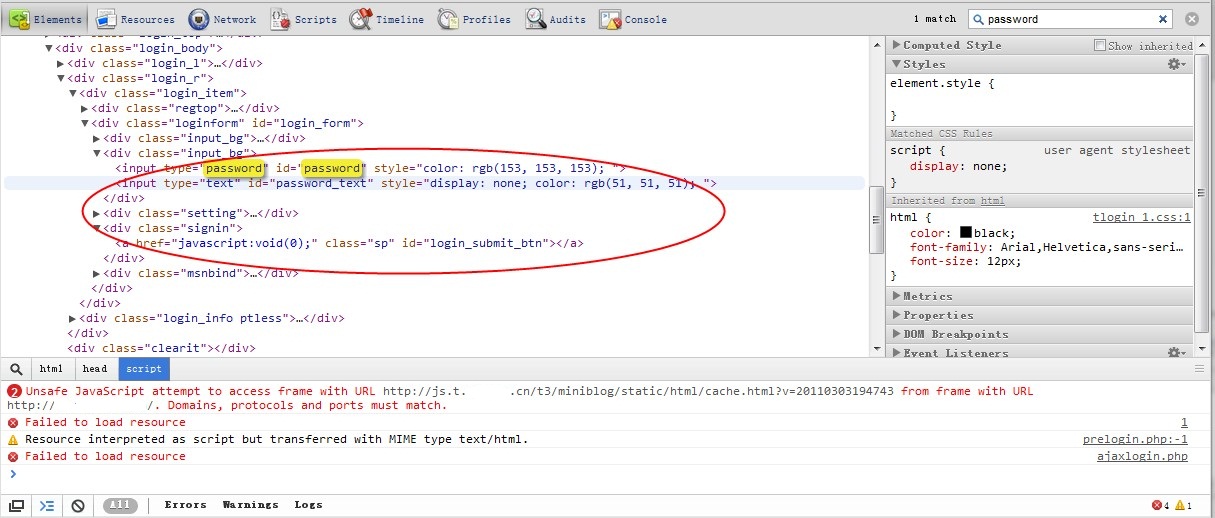
找到了對應的Dom元素,看到login_submit_btn是個超鏈接,然后用了一個啥都不做的js(很多網站都用這種模式,采用動態add event listener的方式),這下就要找js代碼了。因為wsse機制就是在本地做好簽名,然后發送簽名到服務端,服務端做同樣的簽名,由于不可逆,所以保證了安全性和身份有效性,因此只要找到提交的js代碼,然后看清楚里面的簽名算法就可以搞定了。
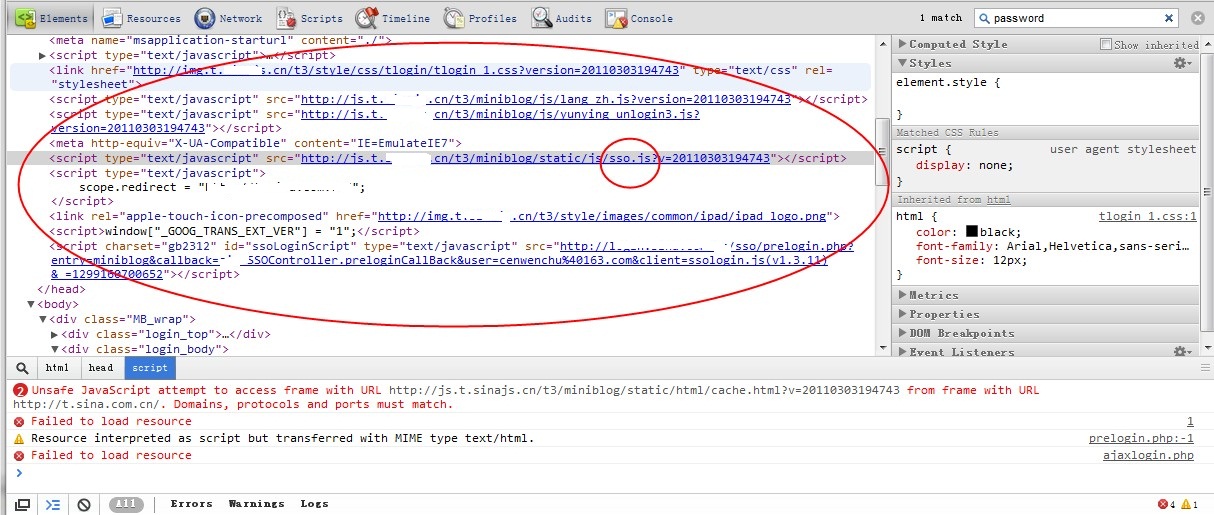
網站的同學寫的很規范,都在head里面放了幾個js,其中sso顧名思義就是用來做登錄的,遂直接下載看看,結果:
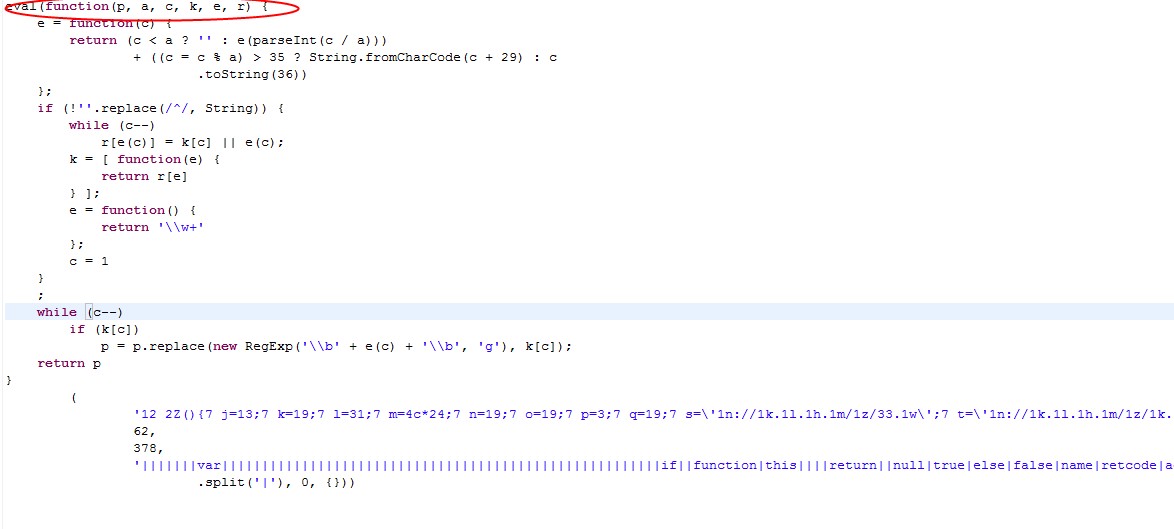
由于上次仔細搞js還是4年多以前的事情了,現在完全落伍,看到這樣的代碼,以為就是直接用document.write執行以下就可以了(原本以為就是用來壓縮的,其實還有混淆的功能,解也不能這么簡單的解開),當然此時我對于詞語的敏感最后還是幫助了我(我紅色標注的地方),其實很多時候對于一些現象和詞語的敏感可以直接幫你在Google中找到答案。
用那種自以為可以的方式解開后卻發現還有一些js函數居然沒有出現@_@,一頭汗阿,此時反復去刷頁面看現象的時候,突然發現原來在另外一個浮起登陸的頁面提交登陸時候是明文的,就是去掉了pwencode=wsse和nonce及servertime,測試了一把,成功登錄并且進入群頁面獲得了自己的所有群中信息。本來到此也就算了,因為目的達到了,但是對于js混淆及調試心里還是有些不甘,所以停下原本要做的事,繼續摸索。
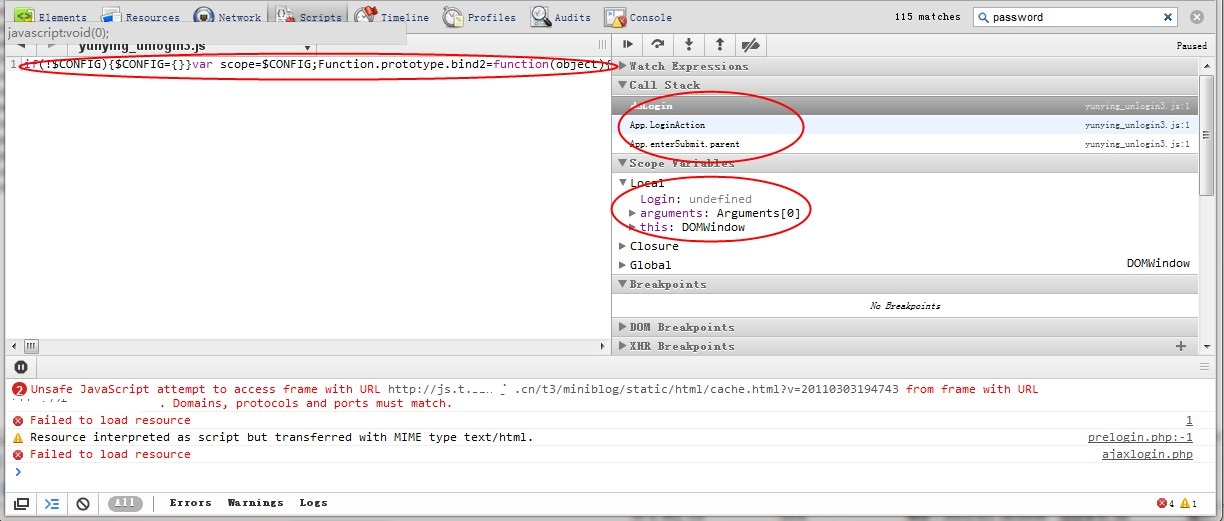
這是用chrome在線調試js的界面,你可以在右邊Event listener breakpoints中設置鼠標點擊事件的debug,當然也可以設置其他的方式,但是由于混淆和壓縮的緣故,左邊的js都是一條語句,調試很困難,不過可以看到右邊的call stack就好比java的調用堆棧輸出(當然沒java那么強大)local可以觀察每次進入不同的請求或者閉包時一些內部變量的變化,總的來說調試正常的js一定是很強大的。
由于調試不成功,只好仔細的去看幾個js,幸好整個頁面就4個js,其中兩個一看就可以過濾掉,另外一個名字取得很怪,里面卻做了它不該做的事情,包括對于事件監聽器的增加,頁面結構的輸出等等,最后調用了sso那個js,又進入死循環了。
想起了js壓縮混淆的事情,想了想花了太多時間了,感覺也許真的很難搞(我也咨詢了我們的前端專家,談到如果沒有源碼,光調試想搞清楚混淆的js工作會很困難),不過出于對混淆和壓縮原理的好奇心,就去搜索了一下(本來就是為了學習一下基礎,也許哪天可以用在Java中),可前面提到的對參數使用(p,a,c,k,e,r)的敏感最后讓我看到了js壓縮比較出名的作品,同時他的blog也收錄囊中(以后慢慢看),最后自然找到了破解之法,翻譯出了那段混淆的編碼,得到了寶貴的算法,在微博中喊了一句:爽,hex_sha1("" + hex_sha1(hex_sha1(b)) + j.servertime + j.nonce),結束了這次前端探索之旅,下面是最后一個圖:
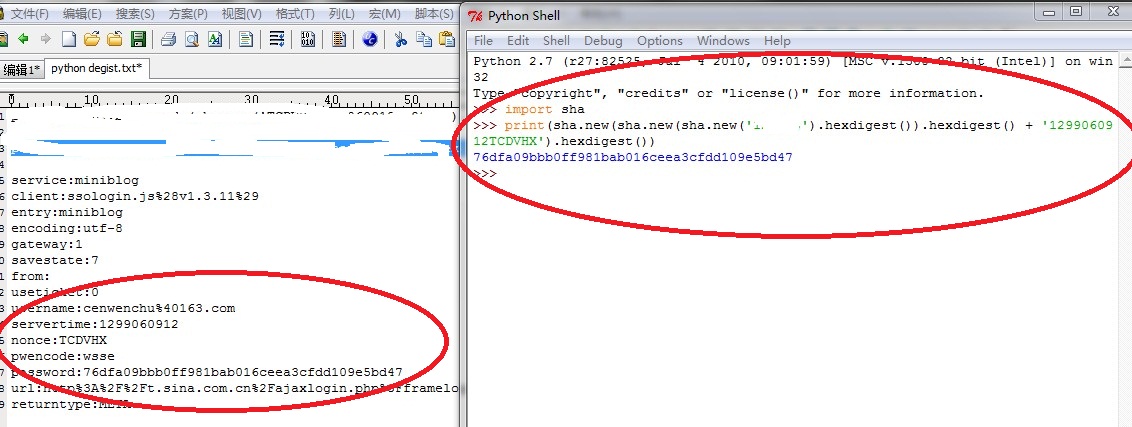
對于前端的內行來說,這點雕蟲小技算不上什么,當然從開頭我就寫了,記錄這個只是想說一些學東西的思維,要做深,這樣是遠遠不夠的,需要更加沉下心來積累很多背后的故事(比如說看完那個高手的blog,了解數據壓縮和混淆的機制,自己寫一個反混淆的代碼)。