Author:文初
Email:wenchu.cenwc@alibaba-inc.com
Blog:http://blog.csdn.net/cenwenchu79
什么是Dynamo? Dynamo是Amazon的高效Key-Value存儲(chǔ)基礎(chǔ)組件(類似于現(xiàn)在被廣泛應(yīng)用的Memcached Cache),當(dāng)前被用于Amazon很多系統(tǒng)中作為狀態(tài)管理組件。在2007年年底Amazon的CTO就寫了一篇介紹Dynamo設(shè)計(jì)的文章,今年年底又在日志中提出了對于那篇文章的一個(gè)補(bǔ)充:“Eventual consistency”。這也讓我再次仔細(xì)的去回顧了一下Dynamo的設(shè)計(jì)思想,其中很多設(shè)計(jì)技巧是當(dāng)前分布式系統(tǒng)設(shè)計(jì)也可以借鑒的。
在說幾個(gè)設(shè)計(jì)技巧以前先說幾個(gè)分布式設(shè)計(jì)的需求和概念。
1. Eventual consistency。這個(gè)概念在阿里系中支付寶架構(gòu)設(shè)計(jì)貫徹的最徹底,記得看魯肅的關(guān)于支付寶事務(wù)處理中提出的軟事務(wù)的概念其實(shí)就是Eventual consistency的一種表現(xiàn)。對于系統(tǒng)設(shè)計(jì)來說,系統(tǒng)中的事件往往都會(huì)相互關(guān)聯(lián),孤立的事件在當(dāng)前的互聯(lián)網(wǎng)行業(yè)中變得微乎其微。事件與事件之間存在著一系列的約束和因果關(guān)聯(lián),就需要靠事務(wù)來保證。事務(wù)的特質(zhì)就是ACID,而ACID在當(dāng)前分布式系統(tǒng)設(shè)計(jì)的模式下常常會(huì)和可用性以及高效性產(chǎn)生沖突。ACID中其他三者都很好理解,而C “一致性”往往是初學(xué)者比較難以理解的一個(gè)特質(zhì)。用銀行存款操作的比喻就較為容易理解,銀行帳戶在操作前有100元,存入了50元以后,就有了150元,操作前和操作后保持了銀行帳戶的一致性,存入50元以后帳戶僅僅增加了50元,總額沒有超過150或者少于150,在常規(guī)看來是在正常不過的了,但是試想,如果有兩個(gè)操作在一個(gè)瞬間作操作,一個(gè)需要給賬戶增加50元,一個(gè)要給賬戶增加30元,前一個(gè)操作是基于100元的基礎(chǔ)增加,后一個(gè)也是基于100元增加,然后后一個(gè)操作晚于前一個(gè)操作提交,那么最后帳號里面就只有130,這就是可以認(rèn)為銀行帳號在兩次操作以后出現(xiàn)了狀態(tài)不一致性。一致性就好比自然界平衡,降水、蒸發(fā)維持生態(tài)平常。Eventual consistency其實(shí)是對一致性的一種延展,過程中允許部分不一致,但是在事務(wù)處理結(jié)束或者有限的時(shí)間內(nèi)保持事務(wù)的一致性。一句話簡單概括就是:“過程松,結(jié)果緊,最終結(jié)果必須保持一致性”。
2. 可用性,容錯(cuò)性,高效性。這三個(gè)非功能性需求在當(dāng)前架構(gòu)設(shè)計(jì)中已經(jīng)成為最基本的設(shè)計(jì)要求,但三者常常在設(shè)計(jì)中又存在矛盾。容錯(cuò)性要高就需要作更多額外的工作,而更多的額外工作必將降低高效的特點(diǎn),同時(shí)額外工作也會(huì)間接增加系統(tǒng)復(fù)雜度進(jìn)而影響可用性。在設(shè)計(jì)中協(xié)調(diào)者三者的關(guān)系,沒有什么準(zhǔn)則可以遵循,只有根據(jù)實(shí)際的系統(tǒng)狀況來判斷如何達(dá)到最好的效果,在后面的Dynamo的三個(gè)參數(shù)配置設(shè)計(jì)就可以看到通過配置如何平衡三者關(guān)系并且將組件應(yīng)用到上層系統(tǒng)中。
3. 分布式設(shè)計(jì)中兩類一致性問題:單點(diǎn)數(shù)據(jù)讀寫一致性問題和分布式數(shù)據(jù)讀寫一致性問題。前者通常通過數(shù)據(jù)存儲(chǔ)的服務(wù)端控制即可(類似于DB的控制),后者通常通過消息傳播的方式來實(shí)現(xiàn)(類似于JGroup在多播通道傳播同步消息)。
4. 沖突解決。這個(gè)我想大部分開發(fā)者每天都會(huì)接觸到,代碼控制(SVN)就是版本控制發(fā)現(xiàn)沖突的具體體現(xiàn)。沖突檢測通常最簡單采用last write的方式,也就好比數(shù)據(jù)庫的解決方式,誰最后修改就以誰的為準(zhǔn)。其他沖突檢測和版本合并就十分復(fù)雜,有些不得不靠人工干預(yù)。這點(diǎn)也是在數(shù)據(jù)一致性通過多版本方式來解決的時(shí)候遇到的問題。
Dynamo設(shè)計(jì)中的學(xué)習(xí)點(diǎn)
1. Consistent hashing算法支持分布式多節(jié)點(diǎn)
簡單hash算法:N為node數(shù)量。處理主鍵為key的節(jié)點(diǎn)為:key.hashValue() mod N。
Consistent hashing算法:環(huán)狀結(jié)構(gòu)。虛擬節(jié)點(diǎn)來替換實(shí)體節(jié)點(diǎn)被分配到環(huán)狀某一位置上(根據(jù)處理能力不同可以將一個(gè)實(shí)體節(jié)點(diǎn)映射到多個(gè)虛擬節(jié)點(diǎn)上)。主鍵為key的節(jié)點(diǎn)position = hash(key),在環(huán)上按照順時(shí)針查找value大于position的第一個(gè)虛擬節(jié)點(diǎn),由它對應(yīng)的實(shí)體節(jié)點(diǎn)處理。下圖中k就優(yōu)先由虛擬節(jié)點(diǎn) B來處理。
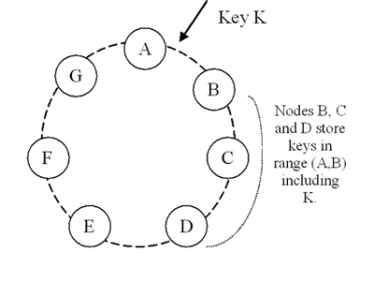
Consistent hashing的優(yōu)點(diǎn):(其實(shí)主要作用是在虛擬節(jié)點(diǎn)以及環(huán)狀負(fù)責(zé)制上)
a. 支持不同能力節(jié)點(diǎn)的權(quán)重設(shè)置。由于采用了虛擬節(jié)點(diǎn),通過虛擬節(jié)點(diǎn)和實(shí)體節(jié)點(diǎn)多對一的配置可以實(shí)現(xiàn)處理能力權(quán)重配置。
b. 新增或者刪除節(jié)點(diǎn)動(dòng)態(tài)配置成為可能,比較上一種簡單算法,由于實(shí)體節(jié)點(diǎn)的數(shù)目直接影響到了hash算法,因此導(dǎo)致新增或者刪除節(jié)點(diǎn)影響全局?jǐn)?shù)據(jù)的重新映射。而Consistent hashing算法不受節(jié)點(diǎn)數(shù)目影響,它的區(qū)間負(fù)責(zé)以及多節(jié)點(diǎn)冗余處理降低動(dòng)態(tài)增減節(jié)點(diǎn)的內(nèi)容失效影響。在一些情況下需要不重新啟動(dòng)而動(dòng)態(tài)的增加或者減少處理節(jié)點(diǎn),因此采用了Consistent hashing的區(qū)間負(fù)責(zé)制,就好比上圖key k的內(nèi)容落在了A和B的區(qū)間內(nèi),根據(jù)規(guī)則由B優(yōu)先來處理,當(dāng)B失效的時(shí)候也可以由C,D來處理,根據(jù)環(huán)狀最近可用節(jié)點(diǎn)來選擇。如果在B節(jié)點(diǎn)和A節(jié)點(diǎn)新增一個(gè)節(jié)點(diǎn)或者刪除B節(jié)點(diǎn),影響的數(shù)據(jù)處理映射也僅僅是是A和B區(qū)間內(nèi)數(shù)據(jù)。
c. 同時(shí)對于壓力分?jǐn)傄灿袔椭_@個(gè)優(yōu)勢還是沿用B來說,新增、刪除或者失效一個(gè)實(shí)體節(jié)點(diǎn),它可能對應(yīng)的是多個(gè)虛擬節(jié)點(diǎn),此時(shí)數(shù)據(jù)壓力會(huì)分?jǐn)偟江h(huán)狀其他的多個(gè)節(jié)點(diǎn),新增也是同樣,這樣可以降低壓力分?jǐn)偟娘L(fēng)險(xiǎn)。
Consistent hashing算法其實(shí)也可以采用Tree方式來實(shí)現(xiàn),Memcached的客戶端版本中就有支持采用Tree的。
2. Vector clock管理數(shù)據(jù)多版本
為什么會(huì)存在數(shù)據(jù)多版本,其實(shí)這個(gè)在高并發(fā)分布式處理中經(jīng)常會(huì)遇到,同時(shí)也是容錯(cuò)性和高可用性的一種解決方式。兩方面來看,首先在高并發(fā)分布式處理過程中,對于單個(gè)資源的操作要么采用阻塞方式要么采用多版本方式,前者效率相對較低但是處理簡單,后者效率高但是處理復(fù)雜。對于容錯(cuò)性和高可用性要求高的情況下,多版本也是一種解決手段,就好比Amazon的購物車就要求任何時(shí)候都要支持修改,如果某一些處理節(jié)點(diǎn)當(dāng)前不可用,那么就需要支持多個(gè)節(jié)點(diǎn)的處理以及數(shù)據(jù)多點(diǎn)的存儲(chǔ),這樣就出現(xiàn)了不同節(jié)點(diǎn)數(shù)據(jù)的不同版本問題。
Vector clock根據(jù)操作者的不同為一個(gè)對象創(chuàng)建了多個(gè)版本計(jì)數(shù)器,并且通過多個(gè)版本計(jì)數(shù)器來判斷這些版本是否屬于并行分支還是串行分支,由此來確定是否需要解決沖突。
解決沖突分成兩種方式,一種是客戶端選擇如何解決沖突,一種是服務(wù)端解決沖突。前者適用于較為復(fù)雜的沖突解決,后者適用于簡單的版本沖突解決。不過不論哪一種方式,在Dynamo的處理中,客戶端和服務(wù)端之間對于對象的操作交互過程都會(huì)帶有版本歷史信息。
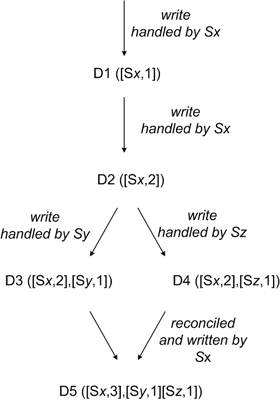
上圖是描述一個(gè)對象D的Vector clock歷史狀況。首先D被Sx節(jié)點(diǎn)處理,那么處理以后產(chǎn)生了第一個(gè)版本D1([Sx,1]),然后又被Sx處理了,產(chǎn)生了第二個(gè)版本D1([Sx,2]),因此需要判斷是否需要版本沖突解決。判斷版本沖突主要是檢查Vector clock中的多個(gè)版本與上一個(gè)歷史Vector clock的關(guān)系,如果歷史的和當(dāng)前的Vector clock中所有的節(jié)點(diǎn)版本都是大于等于的關(guān)系,那么就認(rèn)為兩個(gè)版本不沖突,可以忽略前一個(gè)版本。就拿D2和D1來看,里面只有一個(gè)Sx的版本記錄,對比2大于1,因此就認(rèn)為可以忽略前一個(gè)版本。D3和D4分別是基于D2版本,兩個(gè)不同節(jié)點(diǎn)處理后的結(jié)果,根據(jù)上面的沖突檢測可以認(rèn)為D3和D4版本無法忽略任何一個(gè)版本,因此此時(shí)對于D對象來說存在兩個(gè)版本D3和D4,當(dāng)Sx從服務(wù)端獲取到數(shù)據(jù)以后做處理,此時(shí)就產(chǎn)生了三個(gè)版本。至于這三個(gè)版本由客戶端Sx來解決還是服務(wù)端后期自動(dòng)通過后臺(tái)完成這個(gè)就需要根據(jù)應(yīng)用來決定了。
Vector clock只是提供了一種手段來解決多版本的問題,至于客戶端解決沖突還是服務(wù)端解決沖突這個(gè)需要根據(jù)具體情況來選擇。
3. load balance的幾種模式。
a. 客戶端實(shí)施load balance。采用客戶端包來實(shí)現(xiàn)分發(fā)算法,同時(shí)配置分發(fā)節(jié)點(diǎn)情況。Memcached Cache客戶端使用的一種基本方式。
b. 服務(wù)端硬件實(shí)現(xiàn)load balance。
c. 客戶端改進(jìn)模式。配制節(jié)點(diǎn)以及算法都可以采用集中的Master來管理和維護(hù),包括心跳檢測等手段由Master來實(shí)現(xiàn)。當(dāng)然支持Master失效的容錯(cuò)性策略實(shí)施。
d. 服務(wù)端模式改進(jìn)。采用preference list來分離接受和處理任務(wù)的節(jié)點(diǎn)。
首先采用A模式可以防止B模式在單點(diǎn)的情況下出現(xiàn)的不可用風(fēng)險(xiǎn),也可以減輕高并發(fā)下單點(diǎn)的壓力,提高效率(這點(diǎn)淘寶的同學(xué)有和我提到過,他們采用的“軟負(fù)載”方式)。但是A模式會(huì)增加對于客戶端包的依賴性,對于擴(kuò)展和升級都會(huì)有一定的限制。
其次B模式是最省心的方式,擴(kuò)展性也比較好,但是就是在上面提到的單點(diǎn)問題會(huì)有所限制。
C方式是對于A方式的一種改進(jìn),我以前的一篇文章中提到過,這樣可以提高A的可擴(kuò)展性以及可維護(hù)性,減小對于客戶端包的依賴,但是增加了系統(tǒng)復(fù)雜度,同時(shí)Master也是會(huì)有單點(diǎn)的問題,不過問題不大(失效的情況下就是退化到了A模式)。
D方式是解決服務(wù)端簡單的分發(fā)而導(dǎo)致處理的不均衡性,其實(shí)這種模式也可以改進(jìn)客戶端的算法。因?yàn)橥ㄟ^Hash算法未必能夠?qū)毫Ψ謹(jǐn)偩鶆颍秃帽纫恍┨幚硇枰臅r(shí)比較久一些處理耗時(shí)比較少,系統(tǒng)對于key的映射不均衡等等問題,不過在Dynamo中描述的并不很明確,其中的算法還是要根據(jù)實(shí)際情況來做的。
4. 三個(gè)參數(shù)平衡可用性和容錯(cuò)性。
在Dynamo系統(tǒng)中通過三個(gè)參數(shù)(N,R,W)來實(shí)現(xiàn)可用性和容錯(cuò)性的平衡。對于數(shù)據(jù)存儲(chǔ)系統(tǒng)來說,Dynamo的節(jié)點(diǎn)采用冗余存儲(chǔ)是保證容錯(cuò)性的必要手段,N就代表一份數(shù)據(jù)將會(huì)在系統(tǒng)多少個(gè)節(jié)點(diǎn)存儲(chǔ)。R表示在讀取某一存儲(chǔ)的數(shù)據(jù)時(shí),最少參與節(jié)點(diǎn)數(shù),也就是最少需要有多少個(gè)節(jié)點(diǎn)返回存儲(chǔ)的信息才算是成功讀取了該數(shù)據(jù)內(nèi)容。W表示在存儲(chǔ)某一個(gè)數(shù)據(jù)時(shí),最少參與節(jié)點(diǎn)數(shù),也就是最少要有多少個(gè)節(jié)點(diǎn)表示存儲(chǔ)成功才算是成功存儲(chǔ)了該數(shù)據(jù),通常情況下對于N的復(fù)制可以阻塞等待也可以后臺(tái)異步處理,因此W可以和N不一致。這里的R,W的配置僅僅表示參與數(shù)量的配置,但是當(dāng)環(huán)狀節(jié)點(diǎn)其中一個(gè)失效的時(shí)候,會(huì)遞推到下一個(gè)節(jié)點(diǎn)來處理。
很明顯的R,W的數(shù)字越大直接會(huì)影響系統(tǒng)的性能和可用性,但是R,W越大卻能夠保證容錯(cuò)性的增強(qiáng)。因此如何配置N,R,W成為平衡容錯(cuò)性和可用性的一種重要方式。對于一個(gè)系統(tǒng)結(jié)構(gòu)中,節(jié)點(diǎn)本身穩(wěn)定性較高的情況下,將R,W配置的較小,提升系統(tǒng)的可用性。對于節(jié)點(diǎn)穩(wěn)定性不可靠的情況下,適當(dāng)增大R,W配置,提升系統(tǒng)的容錯(cuò)性,同時(shí)也對可用性有一定幫助。
另一方面,從讀寫能力和業(yè)務(wù)操作讀寫比例修改R,W的配置來優(yōu)化系統(tǒng)的性能。對于讀操作十分密集寫相對來說較少的情況來說,配置R=1,W=N,則可以實(shí)現(xiàn)高讀引擎,系統(tǒng)只要還有一個(gè)節(jié)點(diǎn)可以讀取數(shù)據(jù)就可以讀到數(shù)據(jù)。對于寫比較頻繁的情況來說,那么可以配置R=N,W=1實(shí)現(xiàn)高寫引擎,系統(tǒng)只要還有一個(gè)節(jié)點(diǎn)可以寫入,就可以保證業(yè)務(wù)寫入的正常,不過讀取數(shù)據(jù)進(jìn)行沖突解決會(huì)比較復(fù)雜一些。
除了配置這三個(gè)參數(shù)以外,通過讀寫配置本地緩存的方式可以提高系統(tǒng)整體性能以及容錯(cuò)性。
5. 異步處理容錯(cuò)數(shù)據(jù)復(fù)制
當(dāng)一個(gè)數(shù)據(jù)存儲(chǔ)節(jié)點(diǎn)出現(xiàn)問題以后,數(shù)據(jù)存儲(chǔ)交由給下一個(gè)節(jié)點(diǎn)處理,此時(shí)除了在下一個(gè)節(jié)點(diǎn)存儲(chǔ)數(shù)據(jù)內(nèi)容以外,還會(huì)記錄下原本數(shù)據(jù)所應(yīng)該存儲(chǔ)的節(jié)點(diǎn)以及當(dāng)前存儲(chǔ)的節(jié)點(diǎn)和數(shù)據(jù)內(nèi)容,可以放在后臺(tái)的數(shù)據(jù)庫或者存儲(chǔ)中,后臺(tái)定時(shí)處理這些記錄,將數(shù)據(jù)遷移并且刪除復(fù)制任務(wù)。
這部分在我優(yōu)化Memcache客戶端的時(shí)候采用的是客戶端集群配置lazy復(fù)制的方式,當(dāng)發(fā)現(xiàn)配置成集群的節(jié)點(diǎn)中優(yōu)先處理節(jié)點(diǎn)沒有數(shù)據(jù)就考慮從其他節(jié)點(diǎn)獲取,如果存在就異步復(fù)制,不過這種方式對于有timestamp的數(shù)據(jù)就會(huì)有問題。
6. 采用merkle tree來交驗(yàn)節(jié)點(diǎn)存儲(chǔ)數(shù)據(jù)一致性。每一個(gè)節(jié)點(diǎn)所處理的key range將會(huì)被保存在本地節(jié)點(diǎn)中,通過tree的方式在組織存儲(chǔ),通過對比節(jié)點(diǎn)之間的tree可以快速高效的判斷出是否有數(shù)據(jù)不同步需要異步復(fù)制和同步。
Merkle tree的具體算法和使用方式可以參看BT交驗(yàn)改進(jìn)的文章來學(xué)習(xí)一下,這片文章寫得很通俗易懂,推薦一下:http://www.cnblogs.com/neoragex2002/archive/2006/04/26/385077.html
以上的都是自己看Dynamo設(shè)計(jì)中覺得對自己比較有幫助的內(nèi)容,其中一些思想可能會(huì)和原有設(shè)計(jì)有些出入,各位僅作參考。