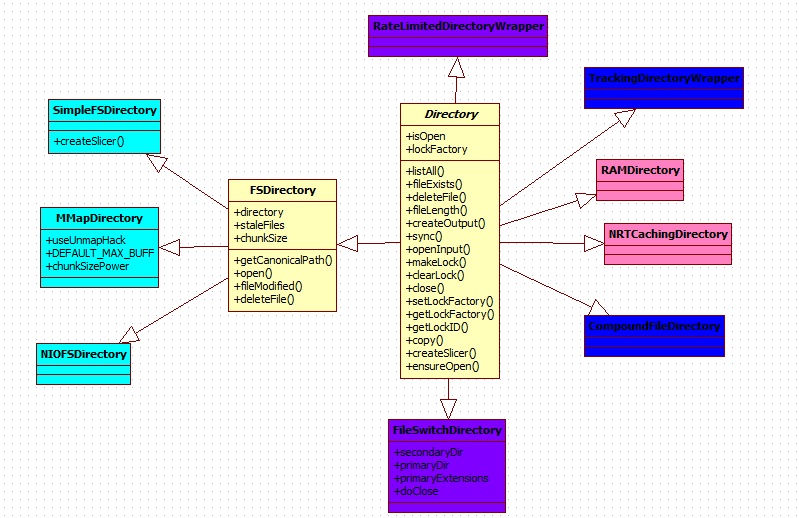
дёҖеQҡж–Ү件зӣ®еҪ?/span>
SimpleFSDirectory:FSDirectoryзҡ„з®ҖеҚ•е®һзҺ?/span>,тq¶еҸ‘иғҪеҠӣжңүйҷҗеQҢйҒҮеҲ°еӨҡҫUҝзЁӢиҜХdҗҢдёҖдёӘж–Ү件时дј?xЁ¬)йҒҮеҲ°з“¶йўҲпјҢйҖҡеёёз”?/span>NIOFSDirectoryжҲ?/span>MMapDirectoryд»ЈжӣҝгҖ?/span>
NIOFSDirectoryеQҡйҖҡиҝҮjava.nio's FileChannelе®һиЎҢе®ҡдҪҚиҜХdҸ–еQҢж”ҜжҢҒеӨҡҫUҝзЁӢиҜ»пјҲй»ҳи®Өжғ…еҶөдёӢжҳҜҫUҝзЁӢе®үе…Ёзҡ„пјү(jЁӘ)гҖӮиҜҘҫcЦM»…дҪҝз”ЁFileChannelҳqӣиЎҢиҜАL“ҚдҪңпјҢеҶҷж“ҚдҪңеҲҷжҳҜйҖҡиҝҮFSIndexOutputе®һзҺ°гҖ?/span>
жіЁж„ҸеQ?/span>NIOFSDirectory дёҚйҖӮз”Ёдә?/span>WindowsҫpИқ»ҹеQҢеҸҰеӨ–еҰӮжһңдёҖдёӘи®ҝй—®иҜҘҫcИқҡ„ҫUҝзЁӢеQҢеңЁIOйҳХdЎһж—¶иў«interruptжҲ?/span>cancelеQҢе°Ҷдј?xЁ¬)еҜјиҮҙеә•еұӮзҡ„ж–ҮдҡgжҸҸиҝ°ҪWҰиў«е…ій—ӯеQҢеҗҺҫlӯзҡ„ҫUҝзЁӢеҶҚж¬Ўи®үK—®NIOFSDirectoryж—¶е°Ҷдј?xЁ¬)еҮәз?/span>ClosedChannelExceptionејӮеёёеQҢжӯӨҝUҚжғ…еҶөеә”з”?/span>SimpleFSDirectoryд»ЈжӣҝгҖ?/span>
MMapDirectoryеQҡйҖҡиҝҮеҶ…еӯҳжҳ е°„ҳqӣиЎҢиҜ»пјҢйҖҡиҝҮFSIndexOutputҳqӣиЎҢеҶҷзҡ„FSDirectoryе®һзҺ°ҫc…RҖӮдӢЙз”ЁиҜҘҫcАL—¶иҰҒдҝқиҜҒз”Ёӯ‘ӣ_Өҹзҡ„иҷҡжӢҹең°еқҖҪIәй—ҙгҖӮеҸҰеӨ–еҪ“йҖҡиҝҮIndexInputзҡ?/span>closeж–ТҺ(guЁ©)і•ҳqӣиЎҢе…ій—ӯж—¶еЖҲдёҚдјҡ(xЁ¬)з«ӢеҚіе…ій—ӯеә•еұӮзҡ„ж–Ү件еҸҘжҹ„пјҢеҸӘжңүGCҳqӣиЎҢиө„жәҗеӣһ收时жүҚдј?xЁ¬)е…ій—ӯгҖ?/span>
дёЮZәҶ(jiЁЈn)иғҪйҖӮеә”еҗ„дёӘж“ҚдҪңҫpИқ»ҹйҖүжӢ©жңҖдҪ?/span>Directoryж–ТҺ(guЁ©)ЎҲеQ?/span>lucene жҸҗдҫӣFSDirectoryҫcИқҡ„йқ?rЁҙn)жҖҒж–№жі?/span>open()е®һзҺ°иҮӘйҖӮеә”гҖ?/span>
public static FSDirectory open(File path, LockFactory lockFactory) throws IOException {
if ((Constants.WINDOWS || Constants.SUN_OS || Constants.LINUX)
&& Constants.JRE_IS_64BIT && MMapDirectory.UNMAP_SUPPORTED) {
return new MMapDirectory(path, lockFactory);
} else if (Constants.WINDOWS) {
return new SimpleFSDirectory(path, lockFactory);
} else {
return new NIOFSDirectory(path, lockFactory);
}
}
дәҢпјҡ(xЁ¬)еҶ…еӯҳзӣ®еҪ•
RAMDirectoryеQҡеёёй©ХdҶ…еӯҳзҡ„Directoryе®һзҺ°ж–№ејҸгҖӮй»ҳи®ӨйҖҡиҝҮSingleInstanceLockFactoryеQҲеҚ•е®һдҫӢй”Ғе·ҘеҺӮпјү(jЁӘ)ҳqӣиЎҢй”Ғзҡ„е®һзҺ°гҖ?span style="color:red">иҜҘзұ»дёҚйҖӮеҗҲеӨ§йҮҸзҙўеј•зҡ„жғ…еҶ?/span>гҖ?span style="color:red">еҸҰеӨ–д№ҹдёҚйҖӮз”ЁдәҺеӨҡҫUҝзЁӢзҡ„жғ…еҶ?/span>гҖ?/span> еңЁзғҰ(chЁі)еј•ж•°жҚ®йҮҸеӨ§зҡ„жғ…еҶөдёӢеҫҸи®®дӢЙз”?/span>MMapDirectoryд»ЈжӣҝгҖ?/span>RAMDirectoryжҳ?/span>DirectoryжҠҪиұЎҫcХdңЁдҪҝз”ЁеҶ…еӯҳжңҖдёәж–Ү件еӯҳеӮЁзҡ„е®һзҺ°ҫc»пјҢе…¶дё»иҰҒжҳҜһ®ҶжүҖжңүзҡ„зҙўеј•ж–ҮдҡgдҝқеӯҳеҲ°еҶ…еӯҳд(shЁҙ)ёӯгҖӮиҝҷж ·еҸҜд»ҘжҸҗй«ҳж•ҲзҺҮгҖӮдҪҶжҳҜеҰӮжһңзғҰ(chЁі)еј•ж–Ү件иҝҮеӨ§зҡ„иҜқпјҢеҲҷдјҡ(xЁ¬)еҜЖDҮҙеҶ…еӯҳ?shЁҙ)ёҚиғцеQҢеӣ жӯӨпјҢһ®ҸеһӢзҡ„зі»ҫlҹжҺЁиҚҗдӢЙз”ЁпјҢеҰӮжһңеӨ§еһӢзҡ„пјҢзҙўеј•ж–Үдҡgиҫ‘ЦҲ°GҫU§еҲ«дёҠпјҢжҺЁиҚҗдҪҝз”ЁFSDirectoryгҖ?/span>
NRTCachingDirectoryеQҡжҳҜеҜ?/span>RAMDirectoryзҡ„е°ҒиЈ…пјҢйҖӮз”ЁдәҺиҝ‘д№Һж—¶ж—УһјҲnear-real-timeеQүж“ҚдҪңзҡ„зҺҜеўғгҖ?/span>
дёүпјҡ(xЁ¬)Direcotryзҡ„д»ЈзҗҶзұ»еҸ?qiЁўng)е·Ҙе…пL(fЁҘng)ұ»
FileSwitchDirectory:ж–ҮдҡgеҲҮжҚўзҡ?/span>Directoryе®һзҺ°.й’ҲеҜ№luceneзҡ„дёҚеҗҢзҡ„зҙўеј•ж–ҮдҡgдҪҝз”ЁдёҚеҗҢзҡ?/span>Directory .еҖҹеҠ©FileSwitchDirectoryж•ҙеҗҲдёҚеҗҢзҡ?/span>Directoryе®һзҺ°ҫcИқҡ„дјҳзӮ№дәҺдёҖнw?/span>
жҜ”еҰӮMMapDirectory,еҖҹеҠ©еҶ…еӯҳжҳ е°„ж–Үдҡgж–№ејҸжҸҗй«ҳжҖ§иғҪеQҢдҪҶеҸҲиҰҒеҮҸе°‘еҶ…еӯҳеҲҮжҚўзҡ„еҸҜиғ?/span> еQҢеҪ“зҙўеј•еӨӘеӨ§зҡ„ж—¶еҖҷпјҢеҶ…еӯҳжҳ е°„д№ҹйңҖиҰҒдёҚж–ӯең°еҲҮжҚўеQҢиҝҷж ·дјҳзӮ№д№ҹеҸҜиғҪеҸҳзјәзӮ№пјҢиҖҢд№ӢеүҚзҡ„NIOFSDirectoryе®һзҺ°java NIOзҡ„ж–№ејҸжҸҗй«ҳй«ҳтq¶еҸ‘жҖ§иғҪеQҢдҪҶеҸҲеӣ й«ҳеЖҲеҸ‘д№ҹдј?xЁ¬)еҜји?/span>IOҳqҮеӨҡзҡ„еӘ„(jiЁЈng)е“ҚпјҢжүҖд»ҘиҝҷӢЖЎеҸҜд»ҘеҖҹеҠ©FileSwitchDirectoryеҸ‘жҢҘ他们дёӨзҡ„дјҳзӮ№гҖ?/span>
RateLimitedDirectoryWrapper:йҖҡиҝҮIOContextжқҘйҷҗеҲ¶иҜ»еҶҷйҖҹзҺҮзҡ?/span>Directoryһ®ҒиЈ…ҫc…RҖ?/span>
CompoundFileDirectoryеQҡз”ЁдәҺи®ҝй—®дёҖдёӘз»„еҗҲзҡ„ж•°жҚ®?huЁӨ)№ҒгҖӮд»…йҖӮз”ЁдәҺиҜ»ж“ҚдҪңгҖӮеҜ№дәҺеҗҢдёҖҢDөеҶ…жү©еұ•еҗҚдёҚеҗҢдҪҶж–ҮдҡgеҗҚзӣёеҗҢзҡ„жүҖжңүж–Ү件еҗҲтq¶еҲ°дёҖдёӘз»ҹдёҖзҡ?/span>.cfsж–Үдҡgе’ҢдёҖдёӘеҜ№еә”зҡ„.cfeж–ҮдҡgеҶ…гҖ?/span>
.cfsж–Үдҡgз”?/span>HeaderеQ?/span>FileDataе’?/span>FileCountҫl„жҲҗгҖ?/span>.cfeж–Үдҡgз”?/span>HeaderеQ?/span>FileCount,FileName,DataOffset,DataLengthҫl„жҲҗгҖ?/span>.cfsж–ҮдҡgдёӯеӯҳеӮЁзқҖзҙўеј•зҡ„жҰӮиҰҒдҝЎжҒҜеҸҠ(qiЁўng)ҫl„еҗҲж–Үдҡg
зҡ„ж•°зӣ®пјҲFileCountеQүгҖ?/span>.cfeж–ҮдҡgеӯҳеӮЁж–Үдҡgзӣ®еҪ•зҡ„жқЎзӣ®еҶ…е®№пјҢеҶ…е®№дёӯеҢ…жӢ¬ж–Ү件数жҚ®жүҮеҢәзҡ„иө·е§ӢдҪҚзҪ®еQҢж–Ү件зҡ„й•ҝеәҰеҸ?qiЁўng)ж–Ү件зҡ„еҗҚз§°гҖ?/span>
TrackingDirectoryWrapperеQ?/span>Directoryзҡ„д»ЈзҗҶзұ»гҖӮз”ЁдәҺи®°еҪ•е“Әдәӣж–Ү件被еҶҷе…Ҙе’ҢеҲ йҷӨгҖ?/span>
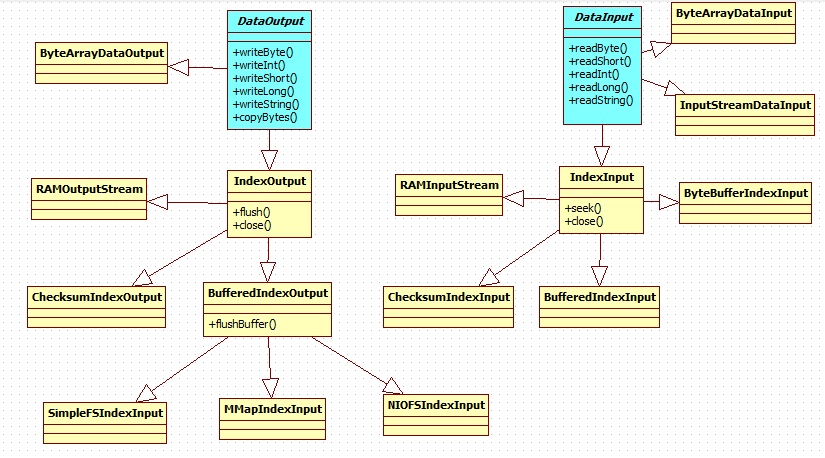
еӣӣпјҡ(xЁ¬)DirecotryиҜХdҶҷеҜ№иұЎзҡ„зұ»еӣ?/span>
ж–Үз« иҪ¬иқІҳqҮжқҘзҡ„пјҒ
ең?/span>2013тqҙеә•е…¬еҸёжҺҘеҲ°дёҖдёӘйЎ№зӣ®з”ЁеҲ?/span>lucene,ҳqҷжҳҜжҲ‘第дёҖӢЖЎжӯЈзңҹжҺҘи§?/span>LuceneеQҢд»Јз ҒжҜ”иҫғиҖ?/span>3.6зүҲжң¬еQҢдёҚйҖӮеҗҲж–°йЎ№зӣ®зҡ„йңҖжұӮпјҲҪIәй—ҙжҹҘиҜўеQүгҖӮдәҺжҳҜдёӢиҪҪдәҶ(jiЁЈn)жңҖж–°зүҲжң?/span> 4.51,жңүеёҰ“ҪIәй—ҙжҹҘиҜў”жЁЎеқ—гҖӮеҗ„еӨ§жҗңзҙўеј•ж“ҺйғҪжІЎжңүжү‘ЦҲ°еғҸж ·дҫӢеӯҗеQҢдәҺжҳҜжғіеҲоCәҶ(jiЁЈn)lucene svnзҡ?/span> trunkзӣ®еҪ•Ӣ№ӢиҜ•з”ЁдҫӢдёӯжүҫеҲоCәҶ(jiЁЈn)Ӣ№ӢиҜ•дҫӢеӯҗеQҢејҖе§ӢдәҶ(jiЁЈn)дёҖҢD?/span>luceneд№Ӣж—…гҖ?/span>
еҶҷж•°жҚ®пјҢеҲӣеҫҸIndexWriter,йҖҡиҝҮе®ғзҡ„жһ„йҖ еҮҪж•°йңҖиҰҒдёҖдёӘзғҰ(chЁі)еј•зӣ®еҪ•пјҲDiectoryеQүе’Ңзҙўеј•еҶҷе…Ҙй…ҚзҪ®ҷе№пјҲInderWriterConfigеQ?/span>,зӣҙжҺҘдёҠд»Јз Ғпјҡ(xЁ¬)
//и®„ЎҪ®еҶҷе…Ҙзӣ®еҪ•(еҘҪеҮ ҝUҚе‘өе‘?/span>)
Directory d=FSDirectory.open(new File("D:/luceneTest"));
//и®„ЎҪ®еҲҶиҜҚ StandardAnalyzerеQҲдјҡ(xЁ¬)жҠҠеҸҘеӯҗдёӯзҡ„еӯ—еҚ•дёӘеҲҶиҜҚеQ?/span>
Analyzer analyzer= new StandardAnalyzer(Version.LUCENE_45);
//и®„ЎҪ®зҙўеј•еҶҷе…Ҙй…ҚзҪ®
IndexWriterConfig config=new IndexWriterConfig(Version.LUCENE_45,analyzer);
//и®„ЎҪ®еҲӣеҫҸжЁЎејҸ
//config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
IndexWriter indexwriter= new IndexWriter(d,config);
дёҠйқўеӣӣиЎҢд»Јз Ғһ®ұеҲӣе»әеҘҪдә?/span>indexwriterеQ?/span>дёӢйқўжҠҠж•°жҚ®еЎ«е…Ҙе°ұеҘҪдәҶ(jiЁЈn)еQҢеҶҷе…ҘжңүеӨҡз§Қж–№ејҸеҰӮдёӢеӣҫпјҡ(xЁ¬)

з”?/span> addDocment дёҫдҫӢд»Јз ҒеҰӮдёӢеQ?/span>
Document doc=new Document();
doc.add(new StringField("id", "1", Store.YES));
doc.add(new StringField("name", "brockhong", Store.YES));
doc.add(new TextField("content", "lucene ж–ҮжЎЈҪW¬дёҖӢЖЎеҶҷзңӢзқҖҫlҷеҲҶеҗ?/span>", Store.YES));
//еҶҷе…Ҙж•°жҚ®
indexwriter.addDocument(doc);
//жҸҗдәӨ
indexwriter.commit();
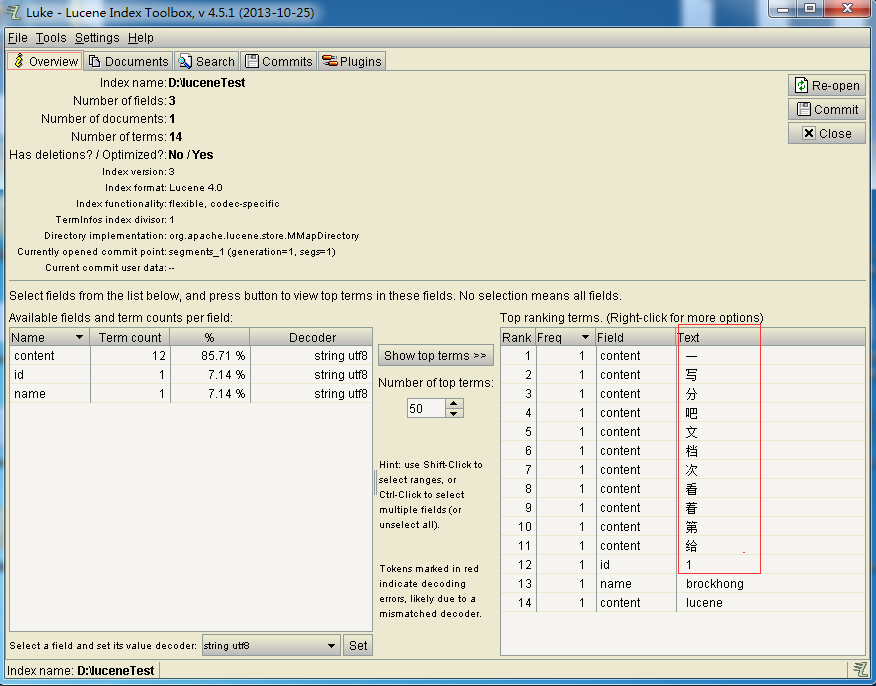
з”?/span> Luke е·Ҙе…·жҹҘзңӢTextеҲ—пјҢҳqҷжҳҜж ҮеҮҶеҲҶиҜҚжғ№зҡ„јңёе“ҰеQҒеҶҷе…ҘжҲҗеҠҹгҖ?/span>
иҜАL•°жҚ®жҹҘиҜўпјҢеҲӣеҫҸ IndexSearcher жһ„йҖ еҮҪж•°и®ҫҫ|?/span>indexReader еQҢиҫ“е…ҘжҹҘиҜўжқЎд»УһјҢдёҠйқўcontentеӯ—ж®өж•°жҚ®и®„ЎҪ®дә?jiЁЈn)еҲҶиҜҚпјҢжүҖд»Ҙеҝ…ҷе»йҖҡиҝҮжҹҘиҜўи§Јжһҗҫc?/span>QueryParserи®‘Ц®ҡеҲҶиҜҚеӯ—ж®өгҖҒзүҲжң¬гҖҒеҲҶиҜҚжЁЎејҸпјҢтqүҷҖҡиҝҮparseж–ТҺ(guЁ©)і•еҫ—еҲ°жҹҘиҜўжқЎдҡgгҖӮд»Јз ҒеҰӮдёӢпјҡ(xЁ¬)
//иҜАL•°жҚ?/span>
//еҲӣеҫҸ indexReader ҳqҷдёӘе·ІиҝҮж—?/span> IndexReader.open(d)еQҢйҮҢйқўзҡ„д»Јз ҒдёҖж ·еҸҜиғҪдШ“(fЁҙ)дә?jiЁЈn)е…је®№иҖҒзүҲжң?/span>
IndexReader indexReader = DirectoryReader.open(d);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//жҹҘиҜў и®„ЎҪ®еҲҶиҜҚеӯ—ж®ө
QueryParser queryParser = new QueryParser(Version.LUCENE_45, "content",
new StandardAnalyzer(Version.LUCENE_45));
//or е…ізі» “ҫl?#8221;гҖ?#8220;еҲ?#8221;
queryParser.setDefaultOperator(QueryParser.OR_OPERATOR);
Query query = queryParser.parse("ҫlҷеҲҶ");
TopDocs results = indexSearcher.search(query, 100);
int numTotalHits = results.totalHits;
System.out.println("е…?/span> " + numTotalHits + " е®Ңе…ЁеҢҡw…Қзҡ„ж–ҮжЎ?/span>");
ScoreDoc[] hits = results.scoreDocs;
for (int i = 0; i < hits.length; i++) {
Document document = indexSearcher.doc(hits[i].doc);
System.out.println("content:" + document.get("content"));
}