在學lucene 之初看了許多書,都是走馬觀花,沒有項目的驅動下,來一個用例demo感覺也不是很難,“我會了”這是我的第一感覺。
在2013年底公司接到一個項目用到lucene,這是我第一次正真接觸Lucene,代碼比較老3.6版本,不適合新項目的需求(空間查詢)。于是下載了最新版本 4.51,有帶“空間查詢”模塊。各大搜索引擎都沒有找到像樣例子,于是想到了lucene svn的 trunk目錄測試用例中找到了測試例子,開始了一段lucene之旅。
寫數據,創建IndexWriter,通過它的構造函數需要一個索引目錄(Diectory)和索引寫入配置項(InderWriterConfig),直接上代碼:
//設置寫入目錄(好幾種呵呵)
Directory d=FSDirectory.open(new File("D:/luceneTest"));
//設置分詞 StandardAnalyzer(會把句子中的字單個分詞)
Analyzer analyzer= new StandardAnalyzer(Version.LUCENE_45);
//設置索引寫入配置
IndexWriterConfig config=new IndexWriterConfig(Version.LUCENE_45,analyzer);
//設置創建模式
//config.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
IndexWriter indexwriter= new IndexWriter(d,config);
上面四行代碼就創建好了indexwriter,下面把數據填入就好了,寫入有多種方式如下圖:

用 addDocment 舉例代碼如下:
Document doc=new Document();
doc.add(new StringField("id", "1", Store.YES));
doc.add(new StringField("name", "brockhong", Store.YES));
doc.add(new TextField("content", "lucene 文檔第一次寫看著給分吧", Store.YES));
//寫入數據
indexwriter.addDocument(doc);
//提交
indexwriter.commit();
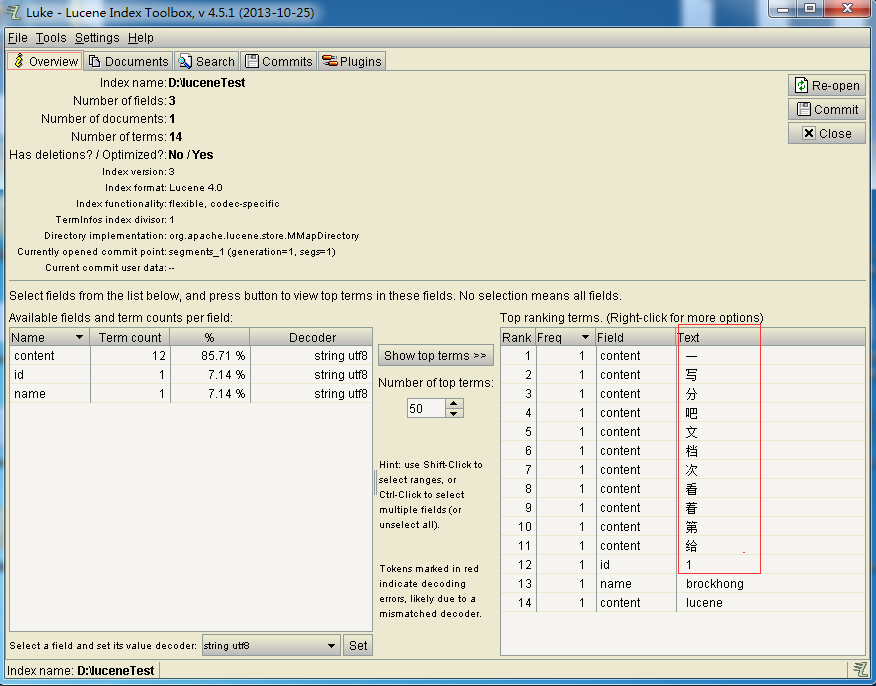
用 Luke 工具查看Text列,這是標準分詞惹的禍哦!寫入成功。
讀數據查詢,創建 IndexSearcher 構造函數設置indexReader ,輸入查詢條件,上面content字段數據設置了分詞,所以必須通過查詢解析類QueryParser設定分詞字段、版本、分詞模式,并通過parse方法得到查詢條件。代碼如下:
//讀數據
//創建 indexReader 這個已過時 IndexReader.open(d),里面的代碼一樣可能為了兼容老版本
IndexReader indexReader = DirectoryReader.open(d);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//查詢 設置分詞字段
QueryParser queryParser = new QueryParser(Version.LUCENE_45, "content",
new StandardAnalyzer(Version.LUCENE_45));
//or 關系 “給”、“分”
queryParser.setDefaultOperator(QueryParser.OR_OPERATOR);
Query query = queryParser.parse("給分");
TopDocs results = indexSearcher.search(query, 100);
int numTotalHits = results.totalHits;
System.out.println("共 " + numTotalHits + " 完全匹配的文檔");
ScoreDoc[] hits = results.scoreDocs;
for (int i = 0; i < hits.length; i++) {
Document document = indexSearcher.doc(hits[i].doc);
System.out.println("content:" + document.get("content"));
}
pasting