引用:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
摘要
本文以MySQL數(shù)據(jù)庫(kù)為研究對(duì)象,討論與數(shù)據(jù)庫(kù)索引相關(guān)的一些話題。特別需要說明的是,MySQL支持諸多存儲(chǔ)引擎,而各種存儲(chǔ)引擎對(duì)索引的支持也各不相同,因此MySQL數(shù)據(jù)庫(kù)支持多種索引類型,如BTree索引,哈希索引,全文索引等等。為了避免混亂,本文將只關(guān)注于BTree索引,因?yàn)檫@是平常使用MySQL時(shí)主要打交道的索引,至于哈希索引和全文索引本文暫不討論。
文章主要內(nèi)容分為三個(gè)部分。
第一部分主要從數(shù)據(jù)結(jié)構(gòu)及算法理論層面討論MySQL數(shù)據(jù)庫(kù)索引的數(shù)理基礎(chǔ)。
第二部分結(jié)合MySQL數(shù)據(jù)庫(kù)中MyISAM和InnoDB數(shù)據(jù)存儲(chǔ)引擎中索引的架構(gòu)實(shí)現(xiàn)討論聚集索引、非聚集索引及覆蓋索引等話題。
第三部分根據(jù)上面的理論基礎(chǔ),討論MySQL中高性能使用索引的策略。
數(shù)據(jù)結(jié)構(gòu)及算法基礎(chǔ)
索引的本質(zhì)
MySQL官方對(duì)索引的定義為:索引(Index)是幫助MySQL高效獲取數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)。提取句子主干,就可以得到索引的本質(zhì):索引是數(shù)據(jù)結(jié)構(gòu)。
我們知道,數(shù)據(jù)庫(kù)查詢是數(shù)據(jù)庫(kù)的最主要功能之一。我們都希望查詢數(shù)據(jù)的速度能盡可能的快,因此數(shù)據(jù)庫(kù)系統(tǒng)的設(shè)計(jì)者會(huì)從查詢算法的角度進(jìn)行優(yōu)化。最基本的查詢算法當(dāng)然是順序查找(linear search),這種復(fù)雜度為O(n)的算法在數(shù)據(jù)量很大時(shí)顯然是糟糕的,好在計(jì)算機(jī)科學(xué)的發(fā)展提供了很多更優(yōu)秀的查找算法,例如二分查找(binary search)、二叉樹查找(binary tree search)等。如果稍微分析一下會(huì)發(fā)現(xiàn),每種查找算法都只能應(yīng)用于特定的數(shù)據(jù)結(jié)構(gòu)之上,例如二分查找要求被檢索數(shù)據(jù)有序,而二叉樹查找只能應(yīng)用于二叉查找樹上,但是數(shù)據(jù)本身的組織結(jié)構(gòu)不可能完全滿足各種數(shù)據(jù)結(jié)構(gòu)(例如,理論上不可能同時(shí)將兩列都按順序進(jìn)行組織),所以,在數(shù)據(jù)之外,數(shù)據(jù)庫(kù)系統(tǒng)還維護(hù)著滿足特定查找算法的數(shù)據(jù)結(jié)構(gòu),這些數(shù)據(jù)結(jié)構(gòu)以某種方式引用(指向)數(shù)據(jù),這樣就可以在這些數(shù)據(jù)結(jié)構(gòu)上實(shí)現(xiàn)高級(jí)查找算法。這種數(shù)據(jù)結(jié)構(gòu),就是索引。
看一個(gè)例子:
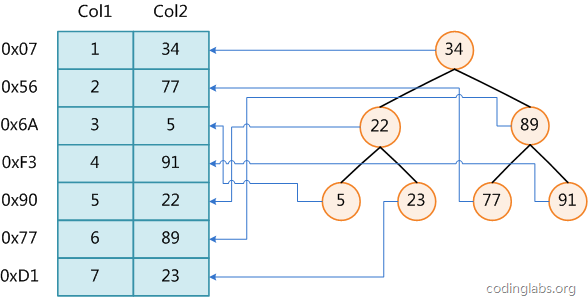
圖1
圖1展示了一種可能的索引方式。左邊是數(shù)據(jù)表,一共有兩列七條記錄,最左邊的是數(shù)據(jù)記錄的物理地址(注意邏輯上相鄰的記錄在磁盤上也并不是一定物理相鄰的)。為了加快Col2的查找,可以維護(hù)一個(gè)右邊所示的二叉查找樹,每個(gè)節(jié)點(diǎn)分別包含索引鍵值和一個(gè)指向?qū)?yīng)數(shù)據(jù)記錄物理地址的指針,這樣就可以運(yùn)用二叉查找在O(log2n)的復(fù)雜度內(nèi)獲取到相應(yīng)數(shù)據(jù)。
雖然這是一個(gè)貨真價(jià)實(shí)的索引,但是實(shí)際的數(shù)據(jù)庫(kù)系統(tǒng)幾乎沒有使用二叉查找樹或其進(jìn)化品種紅黑樹(red-black tree)實(shí)現(xiàn)的,原因會(huì)在下文介紹。
B-Tree和B+Tree
目前大部分?jǐn)?shù)據(jù)庫(kù)系統(tǒng)及文件系統(tǒng)都采用B-Tree或其變種B+Tree作為索引結(jié)構(gòu),在本文的下一節(jié)會(huì)結(jié)合存儲(chǔ)器原理及計(jì)算機(jī)存取原理討論為什么B-Tree和B+Tree在被如此廣泛用于索引,這一節(jié)先單純從數(shù)據(jù)結(jié)構(gòu)角度描述它們。
B-Tree
為了描述B-Tree,首先定義一條數(shù)據(jù)記錄為一個(gè)二元組[key, data],key為記錄的鍵值,對(duì)于不同數(shù)據(jù)記錄,key是互不相同的;data為數(shù)據(jù)記錄除key外的數(shù)據(jù)。那么B-Tree是滿足下列條件的數(shù)據(jù)結(jié)構(gòu):
d為大于1的一個(gè)正整數(shù),稱為B-Tree的度。
h為一個(gè)正整數(shù),稱為B-Tree的高度。
每個(gè)非葉子節(jié)點(diǎn)由n-1個(gè)key和n個(gè)指針組成,其中d<=n<=2d。
每個(gè)葉子節(jié)點(diǎn)最少包含一個(gè)key和兩個(gè)指針,最多包含2d-1個(gè)key和2d個(gè)指針,葉節(jié)點(diǎn)的指針均為null 。
所有葉節(jié)點(diǎn)具有相同的深度,等于樹高h(yuǎn)。
key和指針互相間隔,節(jié)點(diǎn)兩端是指針。
一個(gè)節(jié)點(diǎn)中的key從左到右非遞減排列。
所有節(jié)點(diǎn)組成樹結(jié)構(gòu)。
每個(gè)指針要么為null,要么指向另外一個(gè)節(jié)點(diǎn)。
如果某個(gè)指針在節(jié)點(diǎn)node最左邊且不為null,則其指向節(jié)點(diǎn)的所有key小于v(key1),其中v(key1)為node的第一個(gè)key的值。
如果某個(gè)指針在節(jié)點(diǎn)node最右邊且不為null,則其指向節(jié)點(diǎn)的所有key大于v(keym),其中v(keym)為node的最后一個(gè)key的值。
如果某個(gè)指針在節(jié)點(diǎn)node的左右相鄰key分別是keyi和keyi+1且不為null,則其指向節(jié)點(diǎn)的所有key小于v(keyi+1)且大于v(keyi)。
圖2是一個(gè)d=2的B-Tree示意圖。
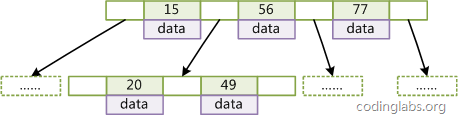
圖2
由于B-Tree的特性,在B-Tree中按key檢索數(shù)據(jù)的算法非常直觀:首先從根節(jié)點(diǎn)進(jìn)行二分查找,如果找到則返回對(duì)應(yīng)節(jié)點(diǎn)的data,否則對(duì)相應(yīng)區(qū)間的指針指向的節(jié)點(diǎn)遞歸進(jìn)行查找,直到找到節(jié)點(diǎn)或找到null指針,前者查找成功,后者查找失敗。B-Tree上查找算法的偽代碼如下:
- BTree_Search(node, key) {
- if(node == null) return null;
- foreach(node.key)
- {
- if(node.key[i] == key) return node.data[i];
- if(node.key[i] > key) return BTree_Search(point[i]->node);
- }
- return BTree_Search(point[i+1]->node);
- }
- data = BTree_Search(root, my_key);
關(guān)于B-Tree有一系列有趣的性質(zhì),例如一個(gè)度為d的B-Tree,設(shè)其索引N個(gè)key,則其樹高h(yuǎn)的上限為logd((N+1)/2),檢索一個(gè)key,其查找節(jié)點(diǎn)個(gè)數(shù)的漸進(jìn)復(fù)雜度為O(logdN)。從這點(diǎn)可以看出,B-Tree是一個(gè)非常有效率的索引數(shù)據(jù)結(jié)構(gòu)。另外,由于插入刪除新的數(shù)據(jù)記錄會(huì)破壞B-Tree的性質(zhì),因此在插入刪除時(shí),需要對(duì)樹進(jìn)行一個(gè)分裂、合并、轉(zhuǎn)移等操作以保持B-Tree性質(zhì),本文不打算完整討論B-Tree這些內(nèi)容,因?yàn)橐呀?jīng)有許多資料詳細(xì)說明了B-Tree的數(shù)學(xué)性質(zhì)及插入刪除算法,有興趣的朋友可以在本文末的參考文獻(xiàn)一欄找到相應(yīng)的資料進(jìn)行閱讀。
B+Tree
B-Tree有許多變種,其中最常見的是B+Tree,例如MySQL就普遍使用B+Tree實(shí)現(xiàn)其索引結(jié)構(gòu)。
與B-Tree相比,B+Tree有以下不同點(diǎn):
每個(gè)節(jié)點(diǎn)的指針上限為2d而不是2d+1。
內(nèi)節(jié)點(diǎn)不存儲(chǔ)data,只存儲(chǔ)key;葉子節(jié)點(diǎn)不存儲(chǔ)指針。
圖3是一個(gè)簡(jiǎn)單的B+Tree示意。
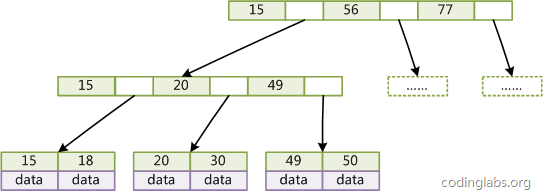
圖3
由于并不是所有節(jié)點(diǎn)都具有相同的域,因此B+Tree中葉節(jié)點(diǎn)和內(nèi)節(jié)點(diǎn)一般大小不同。這點(diǎn)與B-Tree不同,雖然B-Tree中不同節(jié)點(diǎn)存放的key和指針可能數(shù)量不一致,但是每個(gè)節(jié)點(diǎn)的域和上限是一致的,所以在實(shí)現(xiàn)中B-Tree往往對(duì)每個(gè)節(jié)點(diǎn)申請(qǐng)同等大小的空間。
一般來說,B+Tree比B-Tree更適合實(shí)現(xiàn)外存儲(chǔ)索引結(jié)構(gòu),具體原因與外存儲(chǔ)器原理及計(jì)算機(jī)存取原理有關(guān),將在下面討論。
帶有順序訪問指針的B+Tree
一般在數(shù)據(jù)庫(kù)系統(tǒng)或文件系統(tǒng)中使用的B+Tree結(jié)構(gòu)都在經(jīng)典B+Tree的基礎(chǔ)上進(jìn)行了優(yōu)化,增加了順序訪問指針。
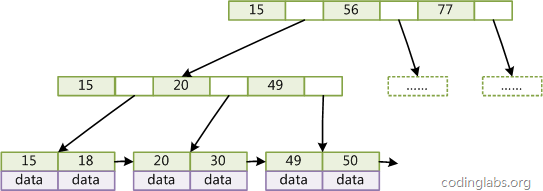
圖4
如圖4所示,在B+Tree的每個(gè)葉子節(jié)點(diǎn)增加一個(gè)指向相鄰葉子節(jié)點(diǎn)的指針,就形成了帶有順序訪問指針的B+Tree。做這個(gè)優(yōu)化的目的是為了提高區(qū)間訪問的性能,例如圖4中如果要查詢key為從18到49的所有數(shù)據(jù)記錄,當(dāng)找到18后,只需順著節(jié)點(diǎn)和指針順序遍歷就可以一次性訪問到所有數(shù)據(jù)節(jié)點(diǎn),極大提到了區(qū)間查詢效率。
這一節(jié)對(duì)B-Tree和B+Tree進(jìn)行了一個(gè)簡(jiǎn)單的介紹,下一節(jié)結(jié)合存儲(chǔ)器存取原理介紹為什么目前B+Tree是數(shù)據(jù)庫(kù)系統(tǒng)實(shí)現(xiàn)索引的首選數(shù)據(jù)結(jié)構(gòu)。
為什么使用B-Tree(B+Tree)
上文說過,紅黑樹等數(shù)據(jù)結(jié)構(gòu)也可以用來實(shí)現(xiàn)索引,但是文件系統(tǒng)及數(shù)據(jù)庫(kù)系統(tǒng)普遍采用B-/+Tree作為索引結(jié)構(gòu),這一節(jié)將結(jié)合計(jì)算機(jī)組成原理相關(guān)知識(shí)討論B-/+Tree作為索引的理論基礎(chǔ)。
一般來說,索引本身也很大,不可能全部存儲(chǔ)在內(nèi)存中,因此索引往往以索引文件的形式存儲(chǔ)的磁盤上。這樣的話,索引查找過程中就要產(chǎn)生磁盤I/O消耗,相對(duì)于內(nèi)存存取,I/O存取的消耗要高幾個(gè)數(shù)量級(jí),所以評(píng)價(jià)一個(gè)數(shù)據(jù)結(jié)構(gòu)作為索引的優(yōu)劣最重要的指標(biāo)就是在查找過程中磁盤I/O操作次數(shù)的漸進(jìn)復(fù)雜度。換句話說,索引的結(jié)構(gòu)組織要盡量減少查找過程中磁盤I/O的存取次數(shù)。下面先介紹內(nèi)存和磁盤存取原理,然后再結(jié)合這些原理分析B-/+Tree作為索引的效率。
主存存取原理
目前計(jì)算機(jī)使用的主存基本都是隨機(jī)讀寫存儲(chǔ)器(RAM),現(xiàn)代RAM的結(jié)構(gòu)和存取原理比較復(fù)雜,這里本文拋卻具體差別,抽象出一個(gè)十分簡(jiǎn)單的存取模型來說明RAM的工作原理。
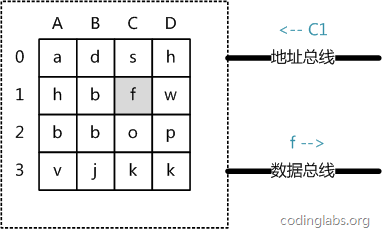
圖5
從抽象角度看,主存是一系列的存儲(chǔ)單元組成的矩陣,每個(gè)存儲(chǔ)單元存儲(chǔ)固定大小的數(shù)據(jù)。每個(gè)存儲(chǔ)單元有唯一的地址,現(xiàn)代主存的編址規(guī)則比較復(fù)雜,這里將其簡(jiǎn)化成一個(gè)二維地址:通過一個(gè)行地址和一個(gè)列地址可以唯一定位到一個(gè)存儲(chǔ)單元。圖5展示了一個(gè)4 x 4的主存模型。
主存的存取過程如下:
當(dāng)系統(tǒng)需要讀取主存時(shí),則將地址信號(hào)放到地址總線上傳給主存,主存讀到地址信號(hào)后,解析信號(hào)并定位到指定存儲(chǔ)單元,然后將此存儲(chǔ)單元數(shù)據(jù)放到數(shù)據(jù)總線上,供其它部件讀取。
寫主存的過程類似,系統(tǒng)將要寫入單元地址和數(shù)據(jù)分別放在地址總線和數(shù)據(jù)總線上,主存讀取兩個(gè)總線的內(nèi)容,做相應(yīng)的寫操作。
這里可以看出,主存存取的時(shí)間僅與存取次數(shù)呈線性關(guān)系,因?yàn)椴淮嬖跈C(jī)械操作,兩次存取的數(shù)據(jù)的“距離”不會(huì)對(duì)時(shí)間有任何影響,例如,先取A0再取A1和先取A0再取D3的時(shí)間消耗是一樣的。
磁盤存取原理
上文說過,索引一般以文件形式存儲(chǔ)在磁盤上,索引檢索需要磁盤I/O操作。與主存不同,磁盤I/O存在機(jī)械運(yùn)動(dòng)耗費(fèi),因此磁盤I/O的時(shí)間消耗是巨大的。
圖6是磁盤的整體結(jié)構(gòu)示意圖。
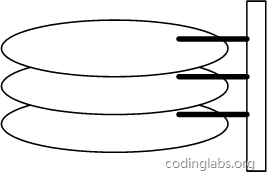
圖6
一個(gè)磁盤由大小相同且同軸的圓形盤片組成,磁盤可以轉(zhuǎn)動(dòng)(各個(gè)磁盤必須同步轉(zhuǎn)動(dòng))。在磁盤的一側(cè)有磁頭支架,磁頭支架固定了一組磁頭,每個(gè)磁頭負(fù)責(zé)存取一個(gè)磁盤的內(nèi)容。磁頭不能轉(zhuǎn)動(dòng),但是可以沿磁盤半徑方向運(yùn)動(dòng)(實(shí)際是斜切向運(yùn)動(dòng)),每個(gè)磁頭同一時(shí)刻也必須是同軸的,即從正上方向下看,所有磁頭任何時(shí)候都是重疊的(不過目前已經(jīng)有多磁頭獨(dú)立技術(shù),可不受此限制)。
圖7是磁盤結(jié)構(gòu)的示意圖。
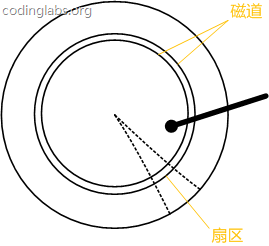
圖7
盤片被劃分成一系列同心環(huán),圓心是盤片中心,每個(gè)同心環(huán)叫做一個(gè)磁道,所有半徑相同的磁道組成一個(gè)柱面。磁道被沿半徑線劃分成一個(gè)個(gè)小的段,每個(gè)段叫做一個(gè)扇區(qū),每個(gè)扇區(qū)是磁盤的最小存儲(chǔ)單元。為了簡(jiǎn)單起見,我們下面假設(shè)磁盤只有一個(gè)盤片和一個(gè)磁頭。
當(dāng)需要從磁盤讀取數(shù)據(jù)時(shí),系統(tǒng)會(huì)將數(shù)據(jù)邏輯地址傳給磁盤,磁盤的控制電路按照尋址邏輯將邏輯地址翻譯成物理地址,即確定要讀的數(shù)據(jù)在哪個(gè)磁道,哪個(gè)扇區(qū)。為了讀取這個(gè)扇區(qū)的數(shù)據(jù),需要將磁頭放到這個(gè)扇區(qū)上方,為了實(shí)現(xiàn)這一點(diǎn),磁頭需要移動(dòng)對(duì)準(zhǔn)相應(yīng)磁道,這個(gè)過程叫做尋道,所耗費(fèi)時(shí)間叫做尋道時(shí)間,然后磁盤旋轉(zhuǎn)將目標(biāo)扇區(qū)旋轉(zhuǎn)到磁頭下,這個(gè)過程耗費(fèi)的時(shí)間叫做旋轉(zhuǎn)時(shí)間。
局部性原理與磁盤預(yù)讀
由于存儲(chǔ)介質(zhì)的特性,磁盤本身存取就比主存慢很多,再加上機(jī)械運(yùn)動(dòng)耗費(fèi),磁盤的存取速度往往是主存的幾百分分之一,因此為了提高效率,要盡量減少磁盤I/O。為了達(dá)到這個(gè)目的,磁盤往往不是嚴(yán)格按需讀取,而是每次都會(huì)預(yù)讀,即使只需要一個(gè)字節(jié),磁盤也會(huì)從這個(gè)位置開始,順序向后讀取一定長(zhǎng)度的數(shù)據(jù)放入內(nèi)存。這樣做的理論依據(jù)是計(jì)算機(jī)科學(xué)中著名的局部性原理:
當(dāng)一個(gè)數(shù)據(jù)被用到時(shí),其附近的數(shù)據(jù)也通常會(huì)馬上被使用。
程序運(yùn)行期間所需要的數(shù)據(jù)通常比較集中。
由于磁盤順序讀取的效率很高(不需要尋道時(shí)間,只需很少的旋轉(zhuǎn)時(shí)間),因此對(duì)于具有局部性的程序來說,預(yù)讀可以提高I/O效率。
預(yù)讀的長(zhǎng)度一般為頁(yè)(page)的整倍數(shù)。頁(yè)是計(jì)算機(jī)管理存儲(chǔ)器的邏輯塊,硬件及操作系統(tǒng)往往將主存和磁盤存儲(chǔ)區(qū)分割為連續(xù)的大小相等的塊,每個(gè)存儲(chǔ)塊稱為一頁(yè)(在許多操作系統(tǒng)中,頁(yè)得大小通常為4k),主存和磁盤以頁(yè)為單位交換數(shù)據(jù)。當(dāng)程序要讀取的數(shù)據(jù)不在主存中時(shí),會(huì)觸發(fā)一個(gè)缺頁(yè)異常,此時(shí)系統(tǒng)會(huì)向磁盤發(fā)出讀盤信號(hào),磁盤會(huì)找到數(shù)據(jù)的起始位置并向后連續(xù)讀取一頁(yè)或幾頁(yè)載入內(nèi)存中,然后異常返回,程序繼續(xù)運(yùn)行。
B-/+Tree索引的性能分析
到這里終于可以分析B-/+Tree索引的性能了。
上文說過一般使用磁盤I/O次數(shù)評(píng)價(jià)索引結(jié)構(gòu)的優(yōu)劣。先從B-Tree分析,根據(jù)B-Tree的定義,可知檢索一次最多需要訪問h個(gè)節(jié)點(diǎn)。數(shù)據(jù)庫(kù)系統(tǒng)的設(shè)計(jì)者巧妙利用了磁盤預(yù)讀原理,將一個(gè)節(jié)點(diǎn)的大小設(shè)為等于一個(gè)頁(yè),這樣每個(gè)節(jié)點(diǎn)只需要一次I/O就可以完全載入。為了達(dá)到這個(gè)目的,在實(shí)際實(shí)現(xiàn)B-Tree還需要使用如下技巧:
每次新建節(jié)點(diǎn)時(shí),直接申請(qǐng)一個(gè)頁(yè)的空間,這樣就保證一個(gè)節(jié)點(diǎn)物理上也存儲(chǔ)在一個(gè)頁(yè)里,加之計(jì)算機(jī)存儲(chǔ)分配都是按頁(yè)對(duì)齊的,就實(shí)現(xiàn)了一個(gè)node只需一次I/O。
B-Tree中一次檢索最多需要h-1次I/O(根節(jié)點(diǎn)常駐內(nèi)存),漸進(jìn)復(fù)雜度為O(h)=O(logdN)。一般實(shí)際應(yīng)用中,出度d是非常大的數(shù)字,通常超過100,因此h非常小(通常不超過3)。
綜上所述,用B-Tree作為索引結(jié)構(gòu)效率是非常高的。
而紅黑樹這種結(jié)構(gòu),h明顯要深的多。由于邏輯上很近的節(jié)點(diǎn)(父子)物理上可能很遠(yuǎn),無法利用局部性,所以紅黑樹的I/O漸進(jìn)復(fù)雜度也為O(h),效率明顯比B-Tree差很多。
上文還說過,B+Tree更適合外存索引,原因和內(nèi)節(jié)點(diǎn)出度d有關(guān)。從上面分析可以看到,d越大索引的性能越好,而出度的上限取決于節(jié)點(diǎn)內(nèi)key和data的大小:
dmax=floor(pagesize/(keysize+datasize+pointsize))
floor表示向下取整。由于B+Tree內(nèi)節(jié)點(diǎn)去掉了data域,因此可以擁有更大的出度,擁有更好的性能。
這一章從理論角度討論了與索引相關(guān)的數(shù)據(jù)結(jié)構(gòu)與算法問題,下一章將討論B+Tree是如何具體實(shí)現(xiàn)為MySQL中索引,同時(shí)將結(jié)合MyISAM和InnDB存儲(chǔ)引擎介紹非聚集索引和聚集索引兩種不同的索引實(shí)現(xiàn)形式。
MySQL索引實(shí)現(xiàn)
在MySQL中,索引屬于存儲(chǔ)引擎級(jí)別的概念,不同存儲(chǔ)引擎對(duì)索引的實(shí)現(xiàn)方式是不同的,本文主要討論MyISAM和InnoDB兩個(gè)存儲(chǔ)引擎的索引實(shí)現(xiàn)方式。
MyISAM索引實(shí)現(xiàn)
MyISAM引擎使用B+Tree作為索引結(jié)構(gòu),葉節(jié)點(diǎn)的data域存放的是數(shù)據(jù)記錄的地址。下圖是MyISAM索引的原理圖:
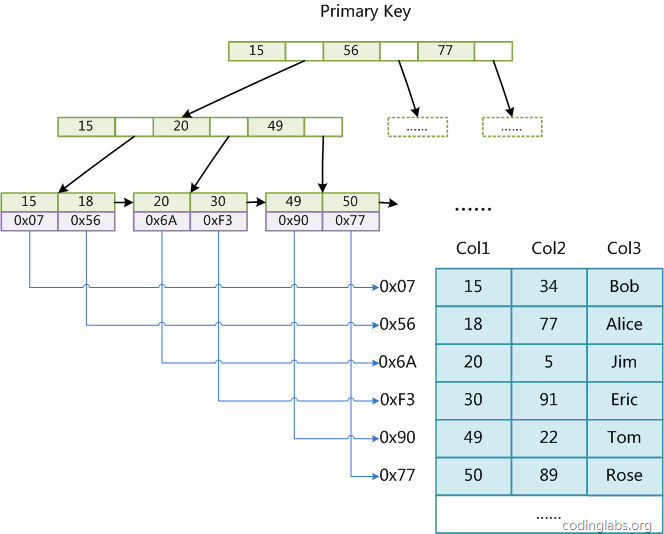
圖8
這里設(shè)表一共有三列,假設(shè)我們以Col1為主鍵,則圖8是一個(gè)MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件僅僅保存數(shù)據(jù)記錄的地址。在MyISAM中,主索引和輔助索引(Secondary key)在結(jié)構(gòu)上沒有任何區(qū)別,只是主索引要求key是唯一的,而輔助索引的key可以重復(fù)。如果我們?cè)贑ol2上建立一個(gè)輔助索引,則此索引的結(jié)構(gòu)如下圖所示:
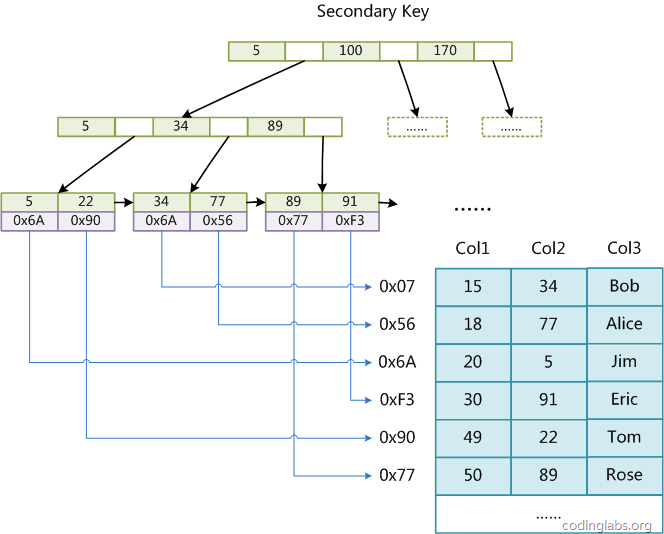
圖9
同樣也是一顆B+Tree,data域保存數(shù)據(jù)記錄的地址。因此,MyISAM中索引檢索的算法為首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,則取出其data域的值,然后以data域的值為地址,讀取相應(yīng)數(shù)據(jù)記錄。
MyISAM的索引方式也叫做“非聚集”的,之所以這么稱呼是為了與InnoDB的聚集索引區(qū)分。
InnoDB索引實(shí)現(xiàn)
雖然InnoDB也使用B+Tree作為索引結(jié)構(gòu),但具體實(shí)現(xiàn)方式卻與MyISAM截然不同。
第一個(gè)重大區(qū)別是InnoDB的數(shù)據(jù)文件本身就是索引文件。從上文知道,MyISAM索引文件和數(shù)據(jù)文件是分離的,索引文件僅保存數(shù)據(jù)記錄的地址。而在InnoDB中,表數(shù)據(jù)文件本身就是按B+Tree組織的一個(gè)索引結(jié)構(gòu),這棵樹的葉節(jié)點(diǎn)data域保存了完整的數(shù)據(jù)記錄。這個(gè)索引的key是數(shù)據(jù)表的主鍵,因此InnoDB表數(shù)據(jù)文件本身就是主索引。
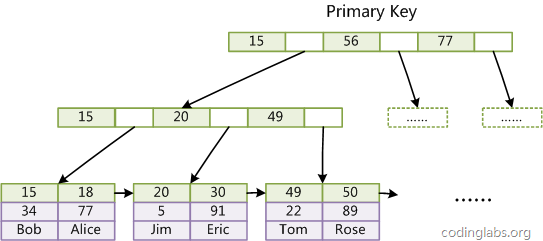
圖10
圖10是InnoDB主索引(同時(shí)也是數(shù)據(jù)文件)的示意圖,可以看到葉節(jié)點(diǎn)包含了完整的數(shù)據(jù)記錄。這種索引叫做聚集索引。因?yàn)镮nnoDB的數(shù)據(jù)文件本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統(tǒng)會(huì)自動(dòng)選擇一個(gè)可以唯一標(biāo)識(shí)數(shù)據(jù)記錄的列作為主鍵,如果不存在這種列,則MySQL自動(dòng)為InnoDB表生成一個(gè)隱含字段作為主鍵,這個(gè)字段長(zhǎng)度為6個(gè)字節(jié),類型為長(zhǎng)整形。
第二個(gè)與MyISAM索引的不同是InnoDB的輔助索引data域存儲(chǔ)相應(yīng)記錄主鍵的值而不是地址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域。例如,圖11為定義在Col3上的一個(gè)輔助索引:
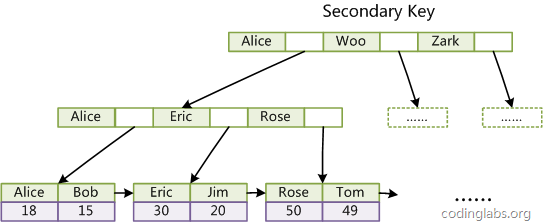
圖11
這里以英文字符的ASCII碼作為比較準(zhǔn)則。聚集索引這種實(shí)現(xiàn)方式使得按主鍵的搜索十分高效,但是輔助索引搜索需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然后用主鍵到主索引中檢索獲得記錄。
了解不同存儲(chǔ)引擎的索引實(shí)現(xiàn)方式對(duì)于正確使用和優(yōu)化索引都非常有幫助,例如知道了InnoDB的索引實(shí)現(xiàn)后,就很容易明白為什么不建議使用過長(zhǎng)的字段作為主鍵,因?yàn)樗休o助索引都引用主索引,過長(zhǎng)的主索引會(huì)令輔助索引變得過大。再例如,用非單調(diào)的字段作為主鍵在InnoDB中不是個(gè)好主意,因?yàn)镮nnoDB數(shù)據(jù)文件本身是一顆B+Tree,非單調(diào)的主鍵會(huì)造成在插入新記錄時(shí)數(shù)據(jù)文件為了維持B+Tree的特性而頻繁的分裂調(diào)整,十分低效,而使用自增字段作為主鍵則是一個(gè)很好的選擇。
下一章將具體討論這些與索引有關(guān)的優(yōu)化策略。
索引使用策略及優(yōu)化
MySQL的優(yōu)化主要分為結(jié)構(gòu)優(yōu)化(Scheme optimization)和查詢優(yōu)化(Query optimization)。本章討論的高性能索引策略主要屬于結(jié)構(gòu)優(yōu)化范疇。本章的內(nèi)容完全基于上文的理論基礎(chǔ),實(shí)際上一旦理解了索引背后的機(jī)制,那么選擇高性能的策略就變成了純粹的推理,并且可以理解這些策略背后的邏輯。
示例數(shù)據(jù)庫(kù)
為了討論索引策略,需要一個(gè)數(shù)據(jù)量不算小的數(shù)據(jù)庫(kù)作為示例。本文選用MySQL官方文檔中提供的示例數(shù)據(jù)庫(kù)之一:employees。這個(gè)數(shù)據(jù)庫(kù)關(guān)系復(fù)雜度適中,且數(shù)據(jù)量較大。下圖是這個(gè)數(shù)據(jù)庫(kù)的E-R關(guān)系圖(引用自MySQL官方手冊(cè)):
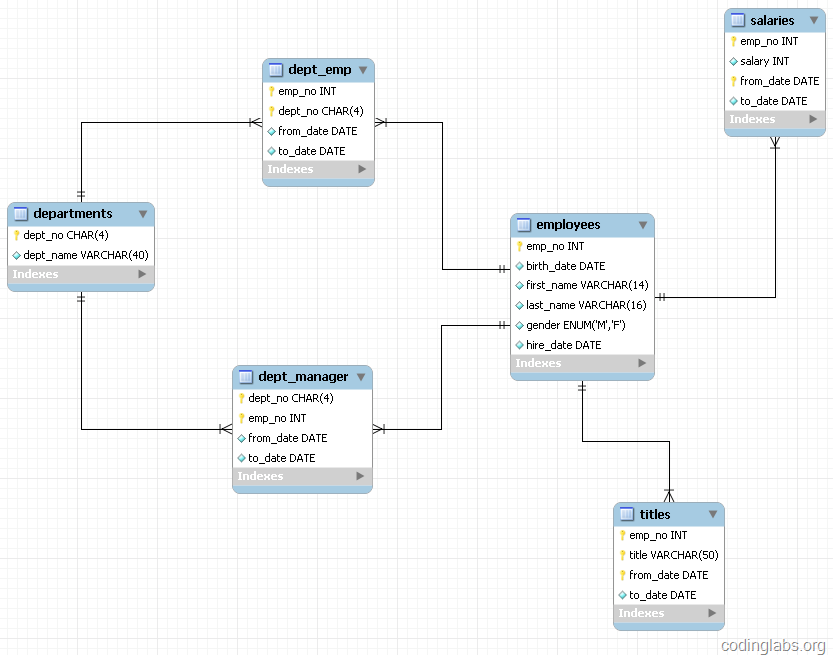
圖12
MySQL官方文檔中關(guān)于此數(shù)據(jù)庫(kù)的頁(yè)面為http://dev.mysql.com/doc/employee/en/employee.html。里面詳細(xì)介紹了此數(shù)據(jù)庫(kù),并提供了下載地址和導(dǎo)入方法,如果有興趣導(dǎo)入此數(shù)據(jù)庫(kù)到自己的MySQL可以參考文中內(nèi)容。
最左前綴原理與相關(guān)優(yōu)化
高效使用索引的首要條件是知道什么樣的查詢會(huì)使用到索引,這個(gè)問題和B+Tree中的“最左前綴原理”有關(guān),下面通過例子說明最左前綴原理。
這里先說一下聯(lián)合索引的概念。在上文中,我們都是假設(shè)索引只引用了單個(gè)的列,實(shí)際上,MySQL中的索引可以以一定順序引用多個(gè)列,這種索引叫做聯(lián)合索引,一般的,一個(gè)聯(lián)合索引是一個(gè)有序元組<a1, a2, …, an>,其中各個(gè)元素均為數(shù)據(jù)表的一列,實(shí)際上要嚴(yán)格定義索引需要用到關(guān)系代數(shù),但是這里我不想討論太多關(guān)系代數(shù)的話題,因?yàn)槟菢訒?huì)顯得很枯燥,所以這里就不再做嚴(yán)格定義。另外,單列索引可以看成聯(lián)合索引元素?cái)?shù)為1的特例。
以employees.titles表為例,下面先查看其上都有哪些索引:
- SHOW INDEX FROM employees.titles;
- +--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
- | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Null | Index_type |
- +--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
- | titles | 0 | PRIMARY | 1 | emp_no | A | NULL | | BTREE |
- | titles | 0 | PRIMARY | 2 | title | A | NULL | | BTREE |
- | titles | 0 | PRIMARY | 3 | from_date | A | 443308 | | BTREE |
- | titles | 1 | emp_no | 1 | emp_no | A | 443308 | | BTREE |
- +--------+------------+----------+--------------+-------------+-----------+-------------+------+------------+
從結(jié)果中可以到titles表的主索引為<emp_no, title, from_date>,還有一個(gè)輔助索引<emp_no>。為了避免多個(gè)索引使事情變復(fù)雜(MySQL的SQL優(yōu)化器在多索引時(shí)行為比較復(fù)雜),這里我們將輔助索引drop掉:
- ALTER TABLE employees.titles DROP INDEX emp_no;
這樣就可以專心分析索引PRIMARY的行為了。
情況一:全列匹配。
- EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title='Senior Engineer' AND from_date='1986-06-26';
- +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
- | 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | |
- +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
很明顯,當(dāng)按照索引中所有列進(jìn)行精確匹配(這里精確匹配指“=”或“IN”匹配)時(shí),索引可以被用到。這里有一點(diǎn)需要注意,理論上索引對(duì)順序是敏感的,但是由于MySQL的查詢優(yōu)化器會(huì)自動(dòng)調(diào)整where子句的條件順序以使用適合的索引,例如我們將where中的條件順序顛倒:
- EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26' AND emp_no='10001' AND title='Senior Engineer';
- +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
- | 1 | SIMPLE | titles | const | PRIMARY | PRIMARY | 59 | const,const,const | 1 | |
- +----+-------------+--------+-------+---------------+---------+---------+-------------------+------+-------+
效果是一樣的。
情況二:最左前綴匹配。
- EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001';
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
- | 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | |
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------+
當(dāng)查詢條件精確匹配索引的左邊連續(xù)一個(gè)或幾個(gè)列時(shí),如<emp_no>或<emp_no, title>,所以可以被用到,但是只能用到一部分,即條件所組成的最左前綴。上面的查詢從分析結(jié)果看用到了PRIMARY索引,但是key_len為4,說明只用到了索引的第一列前綴。
情況三:查詢條件用到了索引中列的精確匹配,但是中間某個(gè)條件未提供。
- EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26';
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
- | 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where |
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
此時(shí)索引使用情況和情況二相同,因?yàn)閠itle未提供,所以查詢只用到了索引的第一列,而后面的from_date雖然也在索引中,但是由于title不存在而無法和左前綴連接,因此需要對(duì)結(jié)果進(jìn)行掃描過濾from_date(這里由于emp_no唯一,所以不存在掃描)。如果想讓from_date也使用索引而不是where過濾,可以增加一個(gè)輔助索引<emp_no, from_date>,此時(shí)上面的查詢會(huì)使用這個(gè)索引。除此之外,還可以使用一種稱之為“隔離列”的優(yōu)化方法,將emp_no與from_date之間的“坑”填上。
首先我們看下title一共有幾種不同的值:
- SELECT DISTINCT(title) FROM employees.titles;
- +--------------------+
- | title |
- +--------------------+
- | Senior Engineer |
- | Staff |
- | Engineer |
- | Senior Staff |
- | Assistant Engineer |
- | Technique Leader |
- | Manager |
- +--------------------+
只有7種。在這種成為“坑”的列值比較少的情況下,可以考慮用“IN”來填補(bǔ)這個(gè)“坑”從而形成最左前綴:
- EXPLAIN SELECT * FROM employees.titles
- WHERE emp_no='10001'
- AND title IN ('Senior Engineer', 'Staff', 'Engineer', 'Senior Staff', 'Assistant Engineer', 'Technique Leader', 'Manager')
- AND from_date='1986-06-26';
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 7 | Using where |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
這次key_len為59,說明索引被用全了,但是從type和rows看出IN實(shí)際上執(zhí)行了一個(gè)range查詢,這里檢查了7個(gè)key。看下兩種查詢的性能比較:
- SHOW PROFILES;
- +----------+------------+-------------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+-------------------------------------------------------------------------------+
- | 10 | 0.00058000 | SELECT * FROM employees.titles WHERE emp_no='10001' AND from_date='1986-06-26'|
- | 11 | 0.00052500 | SELECT * FROM employees.titles WHERE emp_no='10001' AND title IN ... |
- +----------+------------+-------------------------------------------------------------------------------+
“填坑”后性能提升了一點(diǎn)。如果經(jīng)過emp_no篩選后余下很多數(shù)據(jù),則后者性能優(yōu)勢(shì)會(huì)更加明顯。當(dāng)然,如果title的值很多,用填坑就不合適了,必須建立輔助索引。
情況四:查詢條件沒有指定索引第一列。
- EXPLAIN SELECT * FROM employees.titles WHERE from_date='1986-06-26';
- +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
- | 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
- +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
由于不是最左前綴,索引這樣的查詢顯然用不到索引。
情況五:匹配某列的前綴字符串。
- EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND title LIKE 'Senior%';
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 56 | NULL | 1 | Using where |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
此時(shí)可以用到索引,但是如果通配符不是只出現(xiàn)在末尾,則無法使用索引。(原文表述有誤,如果通配符%不出現(xiàn)在開頭,則可以用到索引,但根據(jù)具體情況不同可能只會(huì)用其中一個(gè)前綴)
情況六:范圍查詢。
- EXPLAIN SELECT * FROM employees.titles WHERE emp_no < '10010' and title='Senior Engineer';
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
范圍列可以用到索引(必須是最左前綴),但是范圍列后面的列無法用到索引。同時(shí),索引最多用于一個(gè)范圍列,因此如果查詢條件中有兩個(gè)范圍列則無法全用到索引。
- EXPLAIN SELECT * FROM employees.titles
- WHERE emp_no < '10010'
- AND title='Senior Engineer'
- AND from_date BETWEEN '1986-01-01' AND '1986-12-31';
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 4 | NULL | 16 | Using where |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
可以看到索引對(duì)第二個(gè)范圍索引無能為力。這里特別要說明MySQL一個(gè)有意思的地方,那就是僅用explain可能無法區(qū)分范圍索引和多值匹配,因?yàn)樵趖ype中這兩者都顯示為range。同時(shí),用了“between”并不意味著就是范圍查詢,例如下面的查詢:
- EXPLAIN SELECT * FROM employees.titles
- WHERE emp_no BETWEEN '10001' AND '10010'
- AND title='Senior Engineer'
- AND from_date BETWEEN '1986-01-01' AND '1986-12-31';
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
- | 1 | SIMPLE | titles | range | PRIMARY | PRIMARY | 59 | NULL | 16 | Using where |
- +----+-------------+--------+-------+---------------+---------+---------+------+------+-------------+
看起來是用了兩個(gè)范圍查詢,但作用于emp_no上的“BETWEEN”實(shí)際上相當(dāng)于“IN”,也就是說emp_no實(shí)際是多值精確匹配。可以看到這個(gè)查詢用到了索引全部三個(gè)列。因此在MySQL中要謹(jǐn)慎地區(qū)分多值匹配和范圍匹配,否則會(huì)對(duì)MySQL的行為產(chǎn)生困惑。
情況七:查詢條件中含有函數(shù)或表達(dá)式。
很不幸,如果查詢條件中含有函數(shù)或表達(dá)式,則MySQL不會(huì)為這列使用索引(雖然某些在數(shù)學(xué)意義上可以使用)。例如:
- EXPLAIN SELECT * FROM employees.titles WHERE emp_no='10001' AND left(title, 6)='Senior';
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
- | 1 | SIMPLE | titles | ref | PRIMARY | PRIMARY | 4 | const | 1 | Using where |
- +----+-------------+--------+------+---------------+---------+---------+-------+------+-------------+
雖然這個(gè)查詢和情況五中功能相同,但是由于使用了函數(shù)left,則無法為title列應(yīng)用索引,而情況五中用LIKE則可以。再如:
- EXPLAIN SELECT * FROM employees.titles WHERE emp_no - 1='10000';
- +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
- | 1 | SIMPLE | titles | ALL | NULL | NULL | NULL | NULL | 443308 | Using where |
- +----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
顯然這個(gè)查詢等價(jià)于查詢emp_no為10001的函數(shù),但是由于查詢條件是一個(gè)表達(dá)式,MySQL無法為其使用索引。看來MySQL還沒有智能到自動(dòng)優(yōu)化常量表達(dá)式的程度,因此在寫查詢語句時(shí)盡量避免表達(dá)式出現(xiàn)在查詢中,而是先手工私下代數(shù)運(yùn)算,轉(zhuǎn)換為無表達(dá)式的查詢語句。
索引選擇性與前綴索引
既然索引可以加快查詢速度,那么是不是只要是查詢語句需要,就建上索引?答案是否定的。因?yàn)樗饕m然加快了查詢速度,但索引也是有代價(jià)的:索引文件本身要消耗存儲(chǔ)空間,同時(shí)索引會(huì)加重插入、刪除和修改記錄時(shí)的負(fù)擔(dān),另外,MySQL在運(yùn)行時(shí)也要消耗資源維護(hù)索引,因此索引并不是越多越好。一般兩種情況下不建議建索引。
第一種情況是表記錄比較少,例如一兩千條甚至只有幾百條記錄的表,沒必要建索引,讓查詢做全表掃描就好了。至于多少條記錄才算多,這個(gè)個(gè)人有個(gè)人的看法,我個(gè)人的經(jīng)驗(yàn)是以2000作為分界線,記錄數(shù)不超過 2000可以考慮不建索引,超過2000條可以酌情考慮索引。
另一種不建議建索引的情況是索引的選擇性較低。所謂索引的選擇性(Selectivity),是指不重復(fù)的索引值(也叫基數(shù),Cardinality)與表記錄數(shù)(#T)的比值:
Index Selectivity = Cardinality / #T
顯然選擇性的取值范圍為(0, 1],選擇性越高的索引價(jià)值越大,這是由B+Tree的性質(zhì)決定的。例如,上文用到的employees.titles表,如果title字段經(jīng)常被單獨(dú)查詢,是否需要建索引,我們看一下它的選擇性:
- SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles;
- +-------------+
- | Selectivity |
- +-------------+
- | 0.0000 |
- +-------------+
title的選擇性不足0.0001(精確值為0.00001579),所以實(shí)在沒有什么必要為其單獨(dú)建索引。
有一種與索引選擇性有關(guān)的索引優(yōu)化策略叫做前綴索引,就是用列的前綴代替整個(gè)列作為索引key,當(dāng)前綴長(zhǎng)度合適時(shí),可以做到既使得前綴索引的選擇性接近全列索引,同時(shí)因?yàn)樗饕齥ey變短而減少了索引文件的大小和維護(hù)開銷。下面以employees.employees表為例介紹前綴索引的選擇和使用。
從圖12可以看到employees表只有一個(gè)索引<emp_no>,那么如果我們想按名字搜索一個(gè)人,就只能全表掃描了:
- EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido';
- +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
- | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
- +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
- | 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where |
- +----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
如果頻繁按名字搜索員工,這樣顯然效率很低,因此我們可以考慮建索引。有兩種選擇,建<first_name>或<first_name, last_name>,看下兩個(gè)索引的選擇性:
- SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees;
- +-------------+
- | Selectivity |
- +-------------+
- | 0.0042 |
- +-------------+
- SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees;
- +-------------+
- | Selectivity |
- +-------------+
- | 0.9313 |
- +-------------+
<first_name>顯然選擇性太低,<first_name, last_name>選擇性很好,但是first_name和last_name加起來長(zhǎng)度為30,有沒有兼顧長(zhǎng)度和選擇性的辦法?可以考慮用first_name和last_name的前幾個(gè)字符建立索引,例如<first_name, left(last_name, 3)>,看看其選擇性:
- SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees;
- +-------------+
- | Selectivity |
- +-------------+
- | 0.7879 |
- +-------------+
選擇性還不錯(cuò),但離0.9313還是有點(diǎn)距離,那么把last_name前綴加到4:
- SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees;
- +-------------+
- | Selectivity |
- +-------------+
- | 0.9007 |
- +-------------+
這時(shí)選擇性已經(jīng)很理想了,而這個(gè)索引的長(zhǎng)度只有18,比<first_name, last_name>短了接近一半,我們把這個(gè)前綴索引 建上:
- ALTER TABLE employees.employees
- ADD INDEX `first_name_last_name4` (first_name, last_name(4));
此時(shí)再執(zhí)行一遍按名字查詢,比較分析一下與建索引前的結(jié)果:
- SHOW PROFILES;
- +----------+------------+---------------------------------------------------------------------------------+
- | Query_ID | Duration | Query |
- +----------+------------+---------------------------------------------------------------------------------+
- | 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
- | 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
- +----------+------------+---------------------------------------------------------------------------------+
性能的提升是顯著的,查詢速度提高了120多倍。
前綴索引兼顧索引大小和查詢速度,但是其缺點(diǎn)是不能用于ORDER BY和GROUP BY操作,也不能用于Covering index(即當(dāng)索引本身包含查詢所需全部數(shù)據(jù)時(shí),不再訪問數(shù)據(jù)文件本身)。
InnoDB的主鍵選擇與插入優(yōu)化
在使用InnoDB存儲(chǔ)引擎時(shí),如果沒有特別的需要,請(qǐng)永遠(yuǎn)使用一個(gè)與業(yè)務(wù)無關(guān)的自增字段作為主鍵。
經(jīng)常看到有帖子或博客討論主鍵選擇問題,有人建議使用業(yè)務(wù)無關(guān)的自增主鍵,有人覺得沒有必要,完全可以使用如學(xué)號(hào)或身份證號(hào)這種唯一字段作為主鍵。不論支持哪種論點(diǎn),大多數(shù)論據(jù)都是業(yè)務(wù)層面的。如果從數(shù)據(jù)庫(kù)索引優(yōu)化角度看,使用InnoDB引擎而不使用自增主鍵絕對(duì)是一個(gè)糟糕的主意。
上文討論過InnoDB的索引實(shí)現(xiàn),InnoDB使用聚集索引,數(shù)據(jù)記錄本身被存于主索引(一顆B+Tree)的葉子節(jié)點(diǎn)上。這就要求同一個(gè)葉子節(jié)點(diǎn)內(nèi)(大小為一個(gè)內(nèi)存頁(yè)或磁盤頁(yè))的各條數(shù)據(jù)記錄按主鍵順序存放,因此每當(dāng)有一條新的記錄插入時(shí),MySQL會(huì)根據(jù)其主鍵將其插入適當(dāng)?shù)墓?jié)點(diǎn)和位置,如果頁(yè)面達(dá)到裝載因子(InnoDB默認(rèn)為15/16),則開辟一個(gè)新的頁(yè)(節(jié)點(diǎn))。
如果表使用自增主鍵,那么每次插入新的記錄,記錄就會(huì)順序添加到當(dāng)前索引節(jié)點(diǎn)的后續(xù)位置,當(dāng)一頁(yè)寫滿,就會(huì)自動(dòng)開辟一個(gè)新的頁(yè)。如下圖所示:
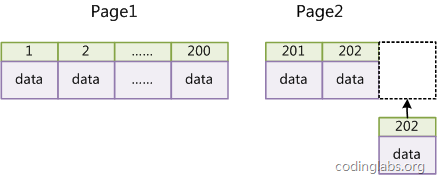
圖13
這樣就會(huì)形成一個(gè)緊湊的索引結(jié)構(gòu),近似順序填滿。由于每次插入時(shí)也不需要移動(dòng)已有數(shù)據(jù),因此效率很高,也不會(huì)增加很多開銷在維護(hù)索引上。
如果使用非自增主鍵(如果身份證號(hào)或?qū)W號(hào)等),由于每次插入主鍵的值近似于隨機(jī),因此每次新紀(jì)錄都要被插到現(xiàn)有索引頁(yè)得中間某個(gè)位置:
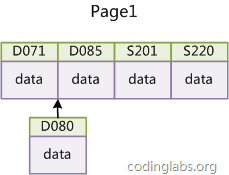
圖14
此時(shí)MySQL不得不為了將新記錄插到合適位置而移動(dòng)數(shù)據(jù),甚至目標(biāo)頁(yè)面可能已經(jīng)被回寫到磁盤上而從緩存中清掉,此時(shí)又要從磁盤上讀回來,這增加了很多開銷,同時(shí)頻繁的移動(dòng)、分頁(yè)操作造成了大量的碎片,得到了不夠緊湊的索引結(jié)構(gòu),后續(xù)不得不通過OPTIMIZE TABLE來重建表并優(yōu)化填充頁(yè)面。
因此,只要可以,請(qǐng)盡量在InnoDB上采用自增字段做主鍵。
后記
這篇文章斷斷續(xù)續(xù)寫了半個(gè)月,主要內(nèi)容就是上面這些了。不可否認(rèn),這篇文章在一定程度上有紙上談兵之嫌,因?yàn)槲冶救藢?duì)MySQL的使用屬于菜鳥級(jí)別,更沒有太多數(shù)據(jù)庫(kù)調(diào)優(yōu)的經(jīng)驗(yàn),在這里大談數(shù)據(jù)庫(kù)索引調(diào)優(yōu)有點(diǎn)大言不慚。就當(dāng)是我個(gè)人的一篇學(xué)習(xí)筆記了。
其實(shí)數(shù)據(jù)庫(kù)索引調(diào)優(yōu)是一項(xiàng)技術(shù)活,不能僅僅靠理論,因?yàn)閷?shí)際情況千變?nèi)f化,而且MySQL本身存在很復(fù)雜的機(jī)制,如查詢優(yōu)化策略和各種引擎的實(shí)現(xiàn)差異等都會(huì)使情況變得更加復(fù)雜。但同時(shí)這些理論是索引調(diào)優(yōu)的基礎(chǔ),只有在明白理論的基礎(chǔ)上,才能對(duì)調(diào)優(yōu)策略進(jìn)行合理推斷并了解其背后的機(jī)制,然后結(jié)合實(shí)踐中不斷的實(shí)驗(yàn)和摸索,從而真正達(dá)到高效使用MySQL索引的目的。
另外,MySQL索引及其優(yōu)化涵蓋范圍非常廣,本文只是涉及到其中一部分。如與排序(ORDER BY)相關(guān)的索引優(yōu)化及覆蓋索引(Covering index)的話題本文并未涉及,同時(shí)除B-Tree索引外MySQL還根據(jù)不同引擎支持的哈希索引、全文索引等等本文也并未涉及。如果有機(jī)會(huì),希望再對(duì)本文未涉及的部分進(jìn)行補(bǔ)充吧。
參考文獻(xiàn)
[1] Baron Scbwartz等 著,王小東等 譯;高性能MySQL(High Performance MySQL);電子工業(yè)出版社,2010
[2] Michael Kofler 著,楊曉云等 譯;MySQL5權(quán)威指南(The Definitive Guide to MySQL5);人民郵電出版社,2006
[3] 姜承堯 著;MySQL技術(shù)內(nèi)幕-InnoDB存儲(chǔ)引擎;機(jī)械工業(yè)出版社,2011
[4] D Comer, Ubiquitous B-tree; ACM Computing Surveys (CSUR), 1979
[5] Codd, E. F. (1970). "A relational model of data for large shared data banks". Communications of the ACM, , Vol. 13, No. 6, pp. 377-387
[6] MySQL5.1參考手冊(cè) - http://dev.mysql.com/doc/refman/5.1/zh/index.html
posted on 2014-07-21 22:10
DLevin 閱讀(614)
評(píng)論(0) 編輯 收藏 所屬分類:
Database