1. java.util.concurrent所提供的并發(fā)容器
java.util.concurrent提供了多種并發(fā)容器,總體上來說有4類,隊列類型的BlockingQueue和 ConcurrentLinkedQueue,Map類型的ConcurrentMap,Set類型的ConcurrentSkipListSet和CopyOnWriteArraySet,List類型的CopyOnWriteArrayList.
這些并發(fā)容器都采用了多種手段控制并發(fā)的存取操作,并且盡可能減小控制并發(fā)所帶來的性能損耗。接下來我們會對每一種類型的實現(xiàn)類進行代碼分析,進而得到java.util.con current包所提供的并發(fā)容器在傳統(tǒng)容器上所做的工作。
2. BlockingQueue
BlockingQueue接口定義的所有方法實現(xiàn)都是線程安全的,它的實現(xiàn)類里面都會用鎖和其他控制并發(fā)的手段保證這種線程安全,但是這些類同時也實現(xiàn)了Collection接口(主要是AbstractQueue實現(xiàn)),所以會出現(xiàn)BlockingQueue的實現(xiàn)類也能同時使用Conllection接口方法,而這時會出現(xiàn)的問題就是像addAll,containsAll,retainAll和removeAll這類批量方法的實現(xiàn)不保證線程安全,舉個例子就是addAll 10個items到一個ArrayBlockingQueue,可能中途失敗但是卻有幾個item已經被放進這個隊列里面了。
下面我們根據(jù)這幅類圖來逐個解析不同實現(xiàn)類的特性和特性實現(xiàn)代碼
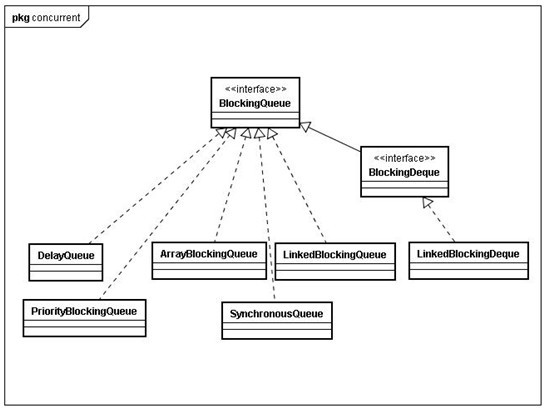
DelayQueue提供了一個只返回超時元素的阻塞隊列,也就是說,即使隊列中已經有數(shù)據(jù)了,但是poll或者take的時候還要判定這個element有沒達到規(guī)定的超時時間,poll方法在element還沒達到規(guī)定的超時時間返回null,take則會通過condition.waitNanos()進入等待狀態(tài)。一般存儲的element類型為Delayed,這個接口JDK中實現(xiàn)的類有ScheduledFutureTask,而DelayQueue為DelayedWorkQueue的Task容器,后者是ScheduledThreadPoolExecutor的工作隊列,所以DelayQueue所具有的超時提供元素和線程安全特性對于并發(fā)的定時任務有很大的意義。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
//控制并發(fā)
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null) {
//condition協(xié)調隊列里面元素
available.await();
} else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay > 0) {
//因為first在隊列里面的delay最短的(優(yōu)先隊列保證),所以wait這個時間那么隊列中最短delay的元素就超時了.即
//隊列有元素供應了.
long tl = available.awaitNanos(delay);
} else {
E x = q.poll();
assert x != null;
if (q.size() != 0)
available.signalAll(); // wake up other takers
return x;
}
}
}
} finally {
lock.unlock();
}
}
DelayQueue的內部數(shù)據(jù)結構是PriorityQueue,因為Delayed接口同時繼承了Comparable接口,并且Delayed的實現(xiàn)類對于這個compareTo方法的實現(xiàn)是基于超時時間進行大小比較,所以DelayQueue無需關心數(shù)據(jù)的排序問題,只需要做好存取的并發(fā)控制(ReetranLock)和超時判定即可。另外,DelayQueue有一個實現(xiàn)細節(jié)就是通過一個Condition來協(xié)調隊列中是否有數(shù)據(jù)可以提供,這對于take和帶有提取超時時間的poll是有意義的(生產者,消費者的實現(xiàn))。
PriorityBlockingQueue實現(xiàn)對于外部而言是按照元素的某種順序返回元素,同時對存取提供并發(fā)保護(ReetranLock),使用Condition協(xié)調隊列是否有新元素提供。PriorityBlocking Queue內部的數(shù)據(jù)結構為PriorityQueue,優(yōu)先級排序工作交給PriorityQueue,至于怎么排序,需要根據(jù)插入元素的Comparable的接口實現(xiàn),和DelayQueue比起來,它沒有限定死插入數(shù)據(jù)的Comparable實現(xiàn),而DelayQueue的元素實現(xiàn)Comparable必須按照超時時間的長短進行比較,否則DelayQueue返回的元素就很可能是錯誤的。
ArrayBlockingQueue是一個先入先出的隊列,內部數(shù)據(jù)結構為一個數(shù)組,并且一旦創(chuàng)建這個隊列的長度是不可改變的,當然put數(shù)據(jù)時,這個隊列也不會自動增長。ArrayBlockingQueue也是使用ReetranLock來保證存取的原子性,不過使用了notEmpty和notFull兩個Condition來協(xié)調隊列為空和隊列為滿的狀態(tài)轉換,插入數(shù)據(jù)的時候,判定當前內部數(shù)據(jù)結構數(shù)組E[] items的長度是否等于元素計數(shù),如果相等,說明隊列滿,notFull.await(),直到items數(shù)組重新不為滿(removeAt,poll等),插入數(shù)據(jù)后notEmpty.sinal()通知所有取數(shù)據(jù)或者移除數(shù)據(jù)并且因為items為空而等待的線程可以繼續(xù)進行操作了。提取數(shù)據(jù)或者移除數(shù)據(jù)的過程剛好相反。
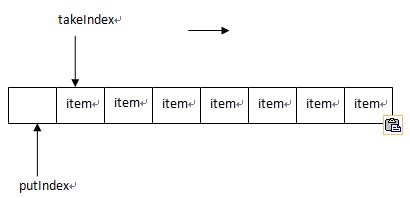
ArrayBlockingQueue使用三個數(shù)字來維護隊列里面的數(shù)據(jù)變更,包括takeIndex,putIndex,count,這里需要講一下takeIndex和putIndex,其中takeIndex指向下一個能夠被提取的元素,而putIndex指向下一個能夠插入數(shù)據(jù)的位置,實現(xiàn)類似下圖的結構,當takeIndex移到內部數(shù)組items最大長度時,重新賦值為0,也就是回到數(shù)組頭部,putIndex也是相同的策略.

 /**
/**
 * 循環(huán)增加putIndex和takeIndex,如果到數(shù)組尾部,那么
* 循環(huán)增加putIndex和takeIndex,如果到數(shù)組尾部,那么
* 置為0
 */
*/
final int inc(int i)  {
{
return (++i == items.length)? 0 : i;
}

//**
* 插入一個item,需要執(zhí)行線程獲得了鎖
*/
private void insert(E x) {
items[putIndex] = x;
//累加putIndex,可能到數(shù)組尾部,那么重新指向0位置
putIndex = inc(putIndex);
++count;
//put后,使用Condition通知正在等待take的線程可以做提取操作
notEmpty.signal();
}
/**
* 獲取一個元素,執(zhí)行這個操作的前提是線程已經獲得鎖,
* 內部調用
*/
private E extract() {
final E[] items = this.items;
E x = items[takeIndex];
items[takeIndex] = null;
//累加takeIndex,有可能到數(shù)組尾部,重新調到數(shù)組頭部
takeIndex = inc(takeIndex);
--count;
//take后,使用Condition通知正在等待插入的線程可以插入
notFull.signal();
return x;
}
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//加一個新的condition等待節(jié)點
Node node = addConditionWaiter();
//釋放自己占用的鎖
int savedState = fullyRelease(node);
int interruptMode = 0;

 while (!isOnSyncQueue(node)) {
while (!isOnSyncQueue(node)) {
//如果當前線程等待狀態(tài)是CONDITION,park住當前線程,等待condition的signal來解除
LockSupport.park(this);
if ((interruptMode =checkInterruptWhileWaiting(node)) != 0)
break;
 }
}
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
LinkedBlockingQueue是一個鏈表結構構成的隊列,并且節(jié)點是單向的,也就是只有next,沒有prev,可以設置容量,如果不設置,最大容量為Integer.MAX_VALUE,隊列只持有頭結點和尾節(jié)點以及元素數(shù)量,通過putLock和takeLock兩個ReetranLock分別控制存和取的并發(fā),但是remove,toArray,toString,clear, drainTo以及迭代器等操作會同時取得putLock和takeLock,并且同時lock,此時存或者取操作都會不可進行,這里有個細節(jié)需要注意的就是所有需要同時lock的地方順序都是先putLock.lock再takeLock.lock,這樣就避免了可能出現(xiàn)的死鎖問題。takeLock實例化出一個notEmpty的Condition,putLock實例化一個notFull的Condition,兩個Condition協(xié)調即時通知線程隊列滿與不滿的狀態(tài)信息,這在前面幾種BlockingQueue實現(xiàn)中也非常常見,在需要用到線程間通知的場景時,各位不妨參考下。另外dequeue的時候需要改變頭節(jié)點的引用地址,否則肯定會造成不能GC而內存泄露
private E dequeue() {
Node<E> h = head;
Node<E> first = h.next;
//將原始節(jié)點的next指針指向自己,這樣就能GC到自己否則虛擬機會認為這個節(jié)點仍然在用而不銷毀(不知道是否理解有誤)
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
BlockingDequeue為阻塞的雙端隊列接口,繼承了BlockingQueue,雙端隊列的最大的特性就是能夠將元素添加到隊列末尾,也能夠添加到隊列首部,取元素也是如此。LinkedBlockingDequeue實現(xiàn)了BlockingDequeue接口,就像LinkedBlockingQueue類似,也是由鏈表結構構成,但是和LinkedBlockingQueue不一樣的是,節(jié)點元素變成了可雙向檢索,也就是一個Node持有next節(jié)點引用,同時持有prev節(jié)點引用,這對隊列的頭尾數(shù)據(jù)存取是有決定性意義的。LinkedBlockingDequeue只采用了一個ReetranLock來控制存取并發(fā),并且由這個lock實例化了2個Condition notEmpty和notFull,count變量維護隊列長度,這里只使用一個lock來維護隊列的讀寫并發(fā),個人理解是頭尾的讀寫如果使用頭尾分開的2個鎖,在維護隊列長度和隊列Empty/Full狀態(tài)會帶來問題,如果使用隊列長度做為判定依據(jù)將不得不對這個變量進行鎖定.
//無論是offerLast,offerFirst,pollFirst,pollLast等等方法都會使用同一把鎖.
public E pollFirst() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return unlinkFirst();
} finally {
lock.unlock();
}
}
public E pollLast() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return unlinkLast();
} finally {
lock.unlock();
}
}
3. ConcurrentMap
ConcurrentMap定義了V putIfAbsent(K key,V value),Boolean remove(Object Key,Object value),Boolean replace(K key,V oldValue,V newValue)以及V replace(K key,V value)四個方法,幾個方法的特性并不難理解,4個方法都是線程安全的。
ConcurrentHashMap是ConcurrentMap的一個實現(xiàn)類,這個類的實現(xiàn)相當經典,基本思想就是分拆鎖,默認ConcurrentHashMap會實例化一個持有16個Segment對象的數(shù)組,Segment數(shù)組大小是可以設定的,構造函數(shù)里的concurrencyLevel指定這個值,但是需要注意的是,這個值并不是直接賦值.Segment數(shù)組最大長度為MAX_SEGMENTS = 1 << 16
int sshift = 0;
int ssize = 1;
//ssize是左移位的,也就是2,4,8,16,32增長(*2),所以你設定concurrencyLevel為10的時候,這個時候并發(fā)數(shù)最大為8.
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
每個Segment維持一個自動增長的HashEntry數(shù)組(根據(jù)一個閾值確定是否要增長長度,并不是滿了才做).
int c = count;
//threshold一般(int)(capacity * loadFactor),
if (c++ > threshold)
rehash();
下面3段代碼是ConcurrentHashMap的初始化Segment,計算hash值,以及如何選擇Segment的代碼以及示例注解.
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
//首先確定segment的個數(shù),左移位,并且記錄移了幾次,比如conurrencyLevel為30,那么2->4->8->16,ssize為16,sshift為4
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
//segmentShift為28
segmentShift = 32 - sshift;
//segmentMask為15
segmentMask = ssize - 1;
//this.segments=new Segment[16]
this.segments = Segment.newArray(ssize);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//假設initialCapacity使用32,那么c=2
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
//cap為2
while (cap < c)
cap <<= 1;
//每個Segment的容量為2
for (int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K,V>(cap, loadFactor);
}
/** *//**
*segmentShift為28,segmentMask為15(1111)
*因為hash值為int,所以32位的
*hash >>> segentShift會留下最高的4位,
*再與mask 1111做&操作
*所以這個最終會產生 0-15的序列.
*/
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
/**
*將計算的hash值補充到原始hashCode中,這是為了防止
*外部用戶傳進來劣質的hash值(比如重復度很高)所帶來
*的危害.
*/
private static int hash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
當put進來一個key、value對,ConcurrentHashMap會計算Key的hash值,然后從Segment數(shù)組根據(jù)key的Hash值選出一個Segment,調用其put方法,Segment級別的put方法通過ReetranLock來控制讀取的并發(fā),其實Segment本身繼承了ReetranLock類。
Segment的put方法在lock()后,首先對數(shù)組長度加了新的元素之后是否會超過閾值threshold進行了判定,如果超過,那么進行rehash(),rehash()的過程相對繁瑣,首先數(shù)組會自動增長一倍,然后需要對HashEntry數(shù)組中的所有元素都需要重新計算hash值,并且置到新數(shù)組的新的位置,同時為了減小操作損耗,將原來不需要移動的數(shù)據(jù)不做移動操作(power-of-two expansion,在默認threshold,在數(shù)組擴大一倍時只需要移動1/6元素,其他都可以不動)。所有動作完成之后,通過一個while循環(huán)尋找Segment中是否有相同Key存在,如果已經存在,那么根據(jù)onlyIfAbsent參數(shù)確定是否替換(如果為true,不替換,如果為false,替換掉value),然后返回替換的value,如果不存在,那么新生成一個HashEntry,并且根據(jù)一開始計算出來的index放到數(shù)組指定位置,并且累積元素計數(shù),返回put的值。最后unlock()釋放掉鎖.
4. CopyOnWriteArrayList和CopyOnWriteArraySet
CopyOnWriteList是線程安全的List實現(xiàn),其底層數(shù)據(jù)存儲結構為數(shù)組(Object[] array),它在讀操作遠遠多于寫操作的場景下表現(xiàn)良好,這其中的原因在于其讀操作(get(),indexOf(),isEmpty(),contains())不加任何鎖,而寫操作(set(),add(),remove())通過Arrays.copyOf()操作拷貝當前底層數(shù)據(jù)結構(array),在其上面做完增刪改等操作,再將新的數(shù)組置為底層數(shù)據(jù)結構,同時為了避免并發(fā)增刪改, CopyOnWriteList在這些寫操作上通過一個ReetranLock進行并發(fā)控制。另外需要注意的是,CopyOnWriteList所實現(xiàn)的迭代器其數(shù)據(jù)也是底層數(shù)組鏡像,所以在CopyOnWriteList進行interator,同時并發(fā)增刪改CopyOnWriteList里的數(shù)據(jù)實不會拋“ConcurrentModificationException”,當然在迭代器上做remove,add,set也是無效的(拋UnsupportedOperationExcetion),因為迭代器上的數(shù)據(jù)只是當前List的數(shù)據(jù)數(shù)組的一個拷貝而已。
CopyOnWriteSet是一個線程安全的Set實現(xiàn),然后持有一個CopyOnWriteList實例,其所有的操作都是這個CopyOnWriteList實例來實現(xiàn)的。CopyOnWriteSet與CopyOnWriteList的區(qū)別實際上就是Set與List的區(qū)別,前者不允許有重復的元素,后者是可以的,所以CopyOnWriteSet的add和addAll兩個操作使用的是其內部CopyOnWriteList實例的addAbsent()和addAllAbsent()兩個防止重復元素的方法,addAbsent()實現(xiàn)是拷貝底層數(shù)據(jù)數(shù)組,然后逐一比較是否相同,如果有一個相同,那么直接返回false,說明插入失敗,如果和其他元素不同,那么將元素加入到新的數(shù)組中,最后置回新的數(shù)組, addAllAbsent()方法實現(xiàn)則是能有多少數(shù)據(jù)插入就插入,也就是說addAllAbsent一個集合的數(shù)據(jù),可能只有一部分插入成功,另外一部分因為元素相同而遭丟棄,完成后返回插入的元素。
posted on 2010-11-25 13:43
BucketLI 閱讀(5177)
評論(3) 編輯 收藏