最近有一個(gè)需要支持unicode的項(xiàng)目在上傳和下載文件時(shí)遇到文件名亂碼問題. 項(xiàng)目背景, 這個(gè)項(xiàng)目關(guān)鍵之處在于需要支持unicode以及支持Micorosoft Internet Explorer和Netscape Navigator兩種瀏覽器. 為了解決這個(gè)問題, 我使用以下環(huán)境進(jìn)行了嘗試.
J2SE : 1.5.0_04
Tomcat : 5.5.17
Microsoft Internet Explorer 6.0 with SP2
Netscape Navigator 7.1
Firefox 1.5
以及Struts 1.1 (這個(gè)基本上對(duì)此次測(cè)試不是非常重要)
上傳文件對(duì)于unicode的頁(yè)面進(jìn)行上傳文件的時(shí)候, 我使用一個(gè)text box和一個(gè)file upload box來進(jìn)行比較. 頁(yè)面如下.
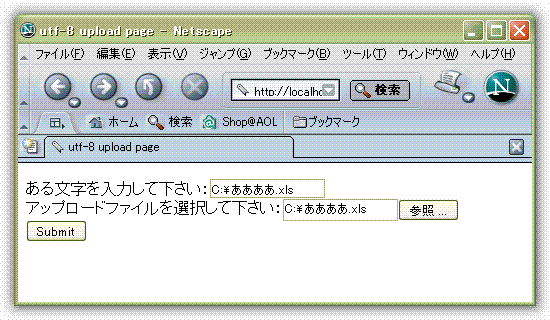
?通過此頁(yè)面進(jìn)行文件上傳后, IE, NC以及FF所傳輸?shù)臄?shù)據(jù)均相同. 如下
Content-Type:?multipart/form-data;?boundary=---------------------------282302224217945
Content-Length:?27980
-----------------------------282302224217945
Content-Disposition:?form-data;?name="theText"
C:\縺ゅ≠縺ゅ≠.xls
-----------------------------282302224217945
Content-Disposition:?form-data;?name="theFile";?filename="縺ゅ≠縺ゅ≠.xls"
Content-Type:?application/vnd.ms-excel
可以看出, 對(duì)text box和file upload box中的文件名所有瀏覽器均采取了相同的編碼. 經(jīng)證實(shí), 是上傳頁(yè)面的編碼方式——所有瀏覽器均對(duì)unicode數(shù)據(jù)(utf-8)采取了本地的編碼方式(這里是ms932).
在服務(wù)器端對(duì)上傳的數(shù)據(jù)進(jìn)行解碼.
解碼的方式有很多, 這里我使用最普遍以及正規(guī)的request.setCharacterEncoding的方法. 發(fā)現(xiàn)form表單中的text box可以被正常解碼, 但是file upload box中的文件名無法通過這種方式解碼. 所以只能使用手工解碼.
String?fixedFileName?=?new?String(fileName.getBytes("SJIS"),?"UTF-8");
其中SJIS是客戶端系統(tǒng)的編碼, UTF-8是客戶端頁(yè)面的編碼.
上傳文件測(cè)試中, 所有瀏覽器表現(xiàn)一致, 需要注意的是文件名和表單數(shù)據(jù)的不同處理方式.
下載文件
使用一個(gè)unicode的JSP頁(yè)面, 在頁(yè)面上有一個(gè)固定的超鏈接, 傳遞給服務(wù)器一個(gè)文件名. 服務(wù)器依照這個(gè)文件名把服務(wù)器端的文件傳遞給客戶端.
下載頁(yè)面
<%@?page?language="java"?contentType="text/html;?charset=utf-8"%>

<meta?http-equiv="content-type"?content="text/html;?charset=utf-8">
<a?href="download.do?name=ああああ.xls">ダウンロード</a> 對(duì)于這樣一個(gè)頁(yè)面, 當(dāng)點(diǎn)擊超鏈接后, 各瀏覽器處理方式不同
IE會(huì)把超鏈接依照頁(yè)面當(dāng)前編碼方式編碼(這里是utf-8)后, 發(fā)送給服務(wù)器端
GET?/nsupload/download.do?name=縺ゅ≠縺ゅ≠.xls?HTTP/1.1
NC和FF會(huì)把超鏈接依照頁(yè)面編碼方式編碼(這里是utf-8)后, 再通過url encoding后, 發(fā)送給服務(wù)器端
GET?/nsupload/download.do?name=%E3%81%82%E3%81%82%E3%81%82%E3%81%82.xls?HTTP/1.1
(經(jīng)證實(shí), E38182是「あ」的unicode代碼)
在服務(wù)器收到提交的數(shù)據(jù)后, 需要對(duì)其進(jìn)行解碼. 需要注意的是這種方式下使用request.setCharacterEncoding無效. 所以必須手工解碼.
name?=?new?String(name.getBytes("ISO-8859-1"),?"UTF-8");
其中ISO-8859-1是Tomcat服務(wù)器的特性, Tomcat會(huì)把所有的數(shù)據(jù)先轉(zhuǎn)換為ISO-8859-1的形式. UTF-8是實(shí)際的編碼方式.
在得到文件名后, 就可以正確地讀取文件, 然后把文件傳遞給客戶端了. 其中, 文件名是保存在Http報(bào)頭(header)的Content-Disposition中.
response.setHeader("Content-Disposition",?"inline;?filename="?+?_filename);
//或者
response.setHeader("Content-Disposition",?"attachment;?filename="?+?_filename);
經(jīng)實(shí)驗(yàn)證明, 使用inline或者attachment對(duì)文件名的編碼方式
沒有影響.
另外一個(gè)需要設(shè)置的是Content-Type.
response.setContentType("application/vnd.ms-excel");
//或者
response.setContentType("application/vnd.ms-excel;?charset=UTF-8");
//或者
response.setContentType("application/x-download; name=" + _filename);
經(jīng)試驗(yàn)證明, 使用application/*的任何形式都對(duì)文件名的編碼方式
沒有影響.
第二點(diǎn), 經(jīng)試驗(yàn)證明, 這里的charset設(shè)置會(huì)被三種瀏覽器忽略, 所以設(shè)置與否
不影響文件名的編碼方式.
第三點(diǎn), 經(jīng)試驗(yàn)證明, 這里的name設(shè)置對(duì)文件名
沒有任何影響.
可能還有一個(gè)屬性需要注意, 就是Content-Language. 經(jīng)試驗(yàn)證明, Content-Language有無, 或者為何值, 對(duì)文件名沒有任何影響.
那么對(duì)于non-ascii的文件名如何操作才可以保證客戶端可以得到正確的顯示呢?
經(jīng)過調(diào)查, 有三種方法(在網(wǎng)上搜索后認(rèn)為可能這篇文章是對(duì)于這個(gè)問題探討最深入的文章)
第一, 使用URLEncoding方法. 即對(duì)文件名進(jìn)行URLEncoding.
name?=?URLEncoder.encode(name,?"UTF-8");
這種方式適用于IE, 但是不適用于NC和FF. 在這種方式下, 網(wǎng)絡(luò)上傳輸?shù)氖莡rl encoding后的ascii編碼.
Content-Disposition:?inline;?filename=%E3%81%82%E3%81%82%E3%81%82%E3%81%82.xls
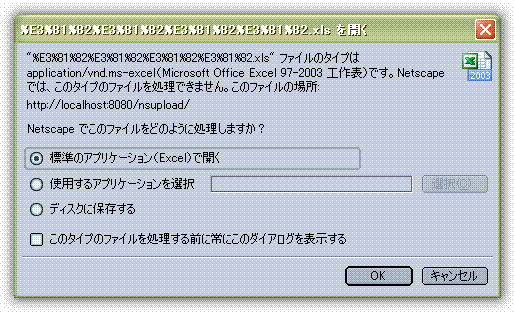
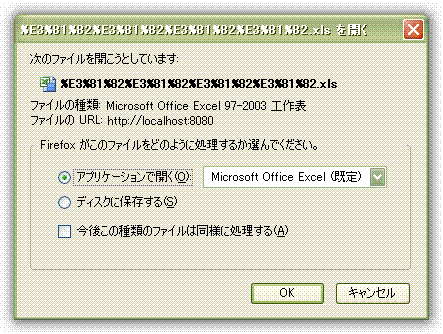
NC和FF不能對(duì)這樣的文件名進(jìn)行有效的解碼.
第二, 使用字符串字符集強(qiáng)行轉(zhuǎn)換為本地字符集方法, 這樣做的原理是JVM底層全部為unicode. 所以一旦一個(gè)字符串表示了正確的字符集而被存儲(chǔ)后, 這個(gè)字符串會(huì)被轉(zhuǎn)換為任意字符集.
原理二是, IE和FF對(duì)非url encoding的non-ascii文件名采用客戶端系統(tǒng)本地的編碼方式進(jìn)行轉(zhuǎn)換.
name?=?new?String(name.getBytes("Shift_JIS"),?"ISO-8859-1");
需要注意的是, 這里的name原本是utf-8的.
在網(wǎng)絡(luò)上傳輸?shù)臑?br />
Content-Disposition:?inline;?filename=ああああ.xls
經(jīng)過試驗(yàn), IE和FF支持這種方式, NC不支持. 表現(xiàn)為NC無法解析文件名.
第三種, 使用Base64編碼文件名. 原理是這種做法符合RFC2047的定義.
name?=?javax.mail.internet.MimeUtility.encodeText(name,?"UTF-8",?"B");
使用到了JavaMail中的Base64編碼的類MimeUtility.
在網(wǎng)絡(luò)上傳輸?shù)臑榻?jīng)過Base64編碼的ascii字符.
Content-Disposition:?inline;?filename==?UTF-8?B?44GC44GC44GC44GCLnhscw==?=
只有FF支持這種方式, IE表現(xiàn)為無法解析文件名, NC表現(xiàn)為忽略Base64編碼.


以上三種方法是目前來講, 使瀏覽器可以正確下載non-ascii文件名的方法. 其中IE支持兩種(url encoding和force transform), FF支持兩種(force transform和base64 encoding), NC一種都不支持.
關(guān)于這次調(diào)查的結(jié)果, 對(duì)于NC多說兩句, 我以為這個(gè)結(jié)果是由于NC 7.1和Tomcat 5.5不兼容造成的. Tomcat 5.5要求必須把所有報(bào)頭先轉(zhuǎn)變?yōu)镮SO-8859-1的格式, 而NC 7.1卻無法直接對(duì)ISO-8859-1進(jìn)行正確的解析或者說是解析功能比較弱. 如果有時(shí)間, 我會(huì)繼續(xù)驗(yàn)證非unicode的情況以及NC 8的情況.
---2006年9月14日21:00 補(bǔ)充---
在NC 8.1上進(jìn)行了測(cè)試, 測(cè)試結(jié)果是NC 8.1支持方法三, 即base64 encoding.
