#
這到底是怎樣一個問題呢?還是用例子說明吧:
public class Parameter{
static void aMethod(){
int a=1; //定義一個int a
change(a);
System.out.println(a);
}
static void change(int a){ //將傳入的a加1
a++;
}
public static void main(String[] args){
aMethod(); //執行并輸出
}
}
猜猜程序的輸出會是什么呢?1還是2?結果是1。為什么呢?
因為a是int 數據,所以作為參數傳遞的時候,a并沒真正傳入change(a).傳入的是a的一個副本。所以change不管怎么對a進行處理都不會改變aMethod中a的值。
那么有沒有辦法通過外部的一個方法改變另一個方法里的值呢?當然有,只要使用對象的引用也叫句柄。說起來文縐縐的倒不如舉個例子:
import java.util.*; //LinkedList要用到這個包
public class Parameter{
static void aMethod(){
LinkedList a = new LinkedList(); //生成一個LinkedList a對象
a.add("a");
change(a);
for(int i=0;i<a.size();i++){ //將鏈表中所有數據輸出
System.out.println(a.get(i).toString());
}
}
static void change(LinkedList a){ //將傳入的a加1
a.add("b"); //為a中再添加一個b
}
public static void main(String[] args){
aMethod(); //執行并輸出
}
}
輸出的結果是:
a
b
這說明了什么?說明change(LinkedList a)方法已經改變了a中的值。那么為什么a是對象就可以改變呢?我們將a傳入change方法的時候傳入的不是某個對象,而是這個對象的引用(或者叫做句柄)插入一句,什么是句柄?比如你,作為一個人,是一個對象,引用(句柄)就是你的身份證號碼。當我們把引用作為參數傳入方法的時候,引用同樣也進行了復制,但復制后的引用指向同一個對象,所以change()里對a 的改變其實也就是對aMethod()里a的改變,因為他們是同一個對象!
是不是說只要是對象就可以了呢?不一定!
比如String類型的數據,即使你這樣生成一個String a對象
String a = new String("go to hell");
a的確是一個對象,但是在a的引用復制的時候,原來的對象也會丟失。其實String 類型的數據在每次改變應用的時候都會清楚原來的對象。
比如在你這么使用的時候:
String a="you";//第一行
a=a+"are fool";//第二行
第一行的a和第二行的a所代表的是完全不同的對象。所以說如果程序里要對String進行大量改變的時候建議不要使用String,如果不小心使用了,你的程序將莫名其妙地占用大量的內存。不用String用什么?用StringBuffer!
不想說得太過于文縐縐,其實序列化,說白了就是將對象以文件的形式保存起來,反序列化,顧名思義,就是將對象文件轉化為程序中的對象。一個對象如果要被序列化則必須實現Serializable接口(implements Serializable)。
序列化:
在這一過程中需要用到java.io包中的地兩個類:FileOutputSteam 和ObjectOutputSteam
下面是一個將LinkedList對象序列化的簡單例子,LinkedList已經實現了Serializable接口(implements Serializable),方法(Method)如下:
import java.io.*;
...//外部代碼
public static void OutputObject() throws
FileNotFoundException,IOException{
LinkedList ll=new LinkedList();
FileOutputStream fos=new FileOutputStream("object");
ObjectOutputStream oos=new ObjectOutputStream(fos);
oos.writeObject(ll);
}
...//外部代碼
關鍵代碼就是三行,相當容易。
反序列化:
這一過程要用到FileInputStream和ObjectInputSteam,都在java.io包里
...//外部代碼
public static Object InputObject() throws FileNotFoundException,
IOException, ClassNotFoundException{
FileInputStream fis=new FileInputStream("object");
ObjectInputStream ois=new ObjectInputStream(fis);
return ois.readObject();//返回對象
}
...//外部代碼
關鍵代碼就是兩行。
當然這只是一個簡單的入門,如果你被老外的書整暈了的話,上面這兩段代碼是很好的參考。
在java中,我們可以通過兩種方式來獲取隨機數(generating a random number)一種是大家熟悉的java.lang.Math.Random()靜態方法,另一種是創建java.util.Random對象。下面是兩種方法的使用過程:
一.java.lang.Math.random()
在使用這一靜態方法的時候,我們不需要import任何包,因為java.lang.*包是默認載入的,下面舉例說面使用方法:
public class RandomTest{
public static void main(String[] args){
int i=Math.random();//random()會自動產生一個0.0-1.0的雙精度隨機數
System.out.println(i);//輸出
i=Math.random()*1000;//產生0-1000的雙精度隨機數
System.out.println(i);
int b=(int)(Math.random()*1000);//產生0-1000的整數隨機數
System.out.println(b);
}
}
二.創建java.util.Random對象
import java.util.random
public class RandomTest{
public static void main(String[] args){
Random random=new Random();//創建random對象
int intNumber=random.nextInt();//獲取一個整型數
float floatNumber=random.nextFloat();//獲取一個浮點數(0-1)
double doubleNumber=random.nextDouble();//獲取雙精度數(0-1)
boolean booleanNumber=random.nextBoolean();//獲取boolean數
System.out.println("intNumber:"+intNumber);
System.out.println("floatNumber:"+floatNumber);
System.out.println("doubleNumber:"+doubleNumber);
System.out.println("booleanNumber:"+booleanNumber);
}
}
random在產生隨機數的時候使用當前的時間作為基數,我們可以同過System.currentTimeMillis()來獲取這個基數。當然我們也可以指定基數:
Random random=new Random(100);
同一基數所產生的隨機數序列是一樣的,可以用下面這一段程序進行印證:
import java.util.random
public class RandomTest{
public static void main(String[] args){
Random random1=new Random(100);
Random random2=new Random(100);
for(int i=0;i<5;i++){
System.out.print(random1.nextInt()+"\t");
System.out.println(random2.nextInt()+"\t");
System.out.println("---------------------------------");
}
}
}
我們可以發現random1和random2所產生的隨機數是相同的。
根據約定,在使用java編程的時候應盡可能的使用現有的類庫,當然你也可以自己編寫一個排序的方法,或者框架,但是有幾個人能寫得比JDK里的還要好呢?使用現有的類的另一個好處是代碼易于閱讀和維護,這篇文章主要講的是如何使用現有的類庫對數組和各種Collection容器進行排序,(文章中的一部分例子來自《Java Developers Almanac 1.4》)
首先要知道兩個類:java.util.Arrays和java.util.Collections(注意和Collection的區別)Collection是集合框架的頂層接口,而Collections是包含了許多靜態方法。我們使用Arrays對數組進行排序,使用 Collections對結合框架容器進行排序,如ArraysList,LinkedList等。
例子中都要加上import java.util.*和其他外殼代碼,如類和靜態main方法,我會在第一個例子里寫出全部代碼,接下來會無一例外的省略。
對數組進行排序
比如有一個整型數組:
int[] intArray = new int[] {4, 1, 3, -23};
我們如何進行排序呢?你這個時候是否在想快速排序的算法?看看下面的實現方法:
import java.util.*;
public class Sort{
public static void main(String[] args){
int[] intArray = new int[] {4, 1, 3, -23};
Arrays.sort(intArray);
}
}
這樣我們就用Arrays的靜態方法sort()對intArray進行了升序排序,現在數組已經變成了{-23,1,3,4}.
如果是字符數組:
String[] strArray = new String[] {"z", "a", "C"};
我們用:
Arrays.sort(strArray);
進行排序后的結果是{C,a,z},sort()會根據元素的自然順序進行升序排序。如果希望對大小寫不敏感的話可以這樣寫:
Arrays.sort(strArray, String.CASE_INSENSITIVE_ORDER);
當然我們也可以指定數組的某一段進行排序比如我們要對數組下表0-2的部分(假設數組長度大于3)進行排序,其他部分保持不變,我們可以使用:
Arrays.sort(strArray,0,2);
這樣,我們只對前三個元素進行了排序,而不會影響到后面的部分。
當然有人會想,我怎樣進行降序排序?在眾多的sort方法中有一個
我們使用Comparator獲取一個反序的比較器即可,Comparator會在稍后講解,以前面的intArray[]為例:
Arrays.sort(intArray,Comparator.reverseOrder());
這樣,我們得到的結果就是{4,3,1,-23}。如果不想修改原有代碼我們也可以使用:
Collections.reverse(Arrays.asList(intArray));
得到該數組的反序。結果同樣為4,3,1,-23}。
現在的情況變了,我們的數組里不再是基本數據類型(primtive type)或者String類型的數組,而是對象數組。這個數組的自然順序是未知的,因此我們需要為該類實現Comparable接口,比如我們有一個Name類:
class Name implements Comparable<Name>{
public String firstName,lastName;
public Name(String firstName,String lastName){
this.firstName=firstName;
this.lastName=lastName;
}
public int compareTo(Name o) { //實現接口
int lastCmp=lastName.compareTo(o.lastName);
return (lastCmp!=0?lastCmp:firstName.compareTo(o.firstName));
}
public String toString(){ //便于輸出測試
return firstName+" "+lastName;
}
}
這樣,當我們對這個對象數組進行排序時,就會先比較lastName,然后比較firstName 然后得出兩個對象的先后順序,就像compareTo(Name o)里實現的那樣。不妨用程序試一試:
import java.util.*;
public class NameSort {
public static void main(String[] args) {
Name nameArray[] = {
new Name("John", "Lennon"),
new Name("Karl", "Marx"),
new Name("Groucho", "Marx"),
new Name("Oscar", "Grouch")
};
Arrays.sort(nameArray);
for(int i=0;i<nameArray.length;i++){
System.out.println(nameArray[i].toString());
}
}
}
結果正如我們所愿:
Oscar Grouch
John Lennon
Groucho Marx
Karl Marx
對集合框架進行排序
如果已經理解了Arrays.sort()對數組進行排序的話,集合框架的使用也是大同小異。只是將Arrays替換成了Collections,注意Collections是一個類而Collection是一個接口,雖然只差一個"s"但是它們的含義卻完全不同。
假如有這樣一個鏈表:
LinkedList list=new LinkedList();
list.add(4);
list.add(34);
list.add(22);
list.add(2);
我們只需要使用:
Collections.sort(list);
就可以將ll里的元素按從小到大的順序進行排序,結果就成了:
[2, 4, 22, 34]
如果LinkedList里面的元素是String,同樣會想基本數據類型一樣從小到大排序。
如果要實現反序排序也就是從達到小排序:
Collections.sort(list,Collectons.reverseOrder());
如果LinkedList里面的元素是自定義的對象,可以像上面的Name對象一樣實現Comparable接口,就可以讓Collection.sort()為您排序了。
如果你想按照自己的想法對一個對象進行排序,你可以使用
這個方法進行排序,在給出例子之前,先要說明一下Comparator的使用,
Comparable接口的格式:
public interface Comparator<T> {
int compare(T o1, T o2);
}
其實Comparator里的int compare(T o1,T o2)的寫法和Comparable里的compareTo()方法的寫法差不多。在上面的Name類中我們的比較是從LastName開始的,這是西方人的習慣,到了中國,我們想從fristName開始比較,又不想修改原來的代碼,這個時候,Comparator就可以派上用場了:
final Comparator<Name> FIRST_NAME_ORDER=new Comparator<Name>() {
public int compare(Name n1, Name n2) {
int firstCmp=n1.firstName.compareTo(n2.firstName);
return (firstCmp!=0?firstCmp:n1.lastName.compareTo
(n2.firstName));
}
};
這樣一個我們自定義的Comparator FIRST_NAME_ORDER就寫好了。
將上個例子里那個名字數組轉化為List:
List<Name> list=Arrays.asList(nameArray);
Collections.sort(list,FIRST_NAME_ORDER);
這樣我們就成功的使用自己定義的比較器設定排序。
在openssl或其他密碼相關的資料中,我們經常看到對稱加密算法有ECB、CBC之類加密模式的簡稱,到底這些加密模式是什么呢?它們之間有什么不同呢,今天就是為大家解開這個迷。
在現有的對稱加密算法中,主要有4種加密處理模式,這4種加密處理模式一般是針對塊加密算法而言的,如DES算法。這4種加密模式羅列如下:
模式中文描述 英文名稱(Openssl縮寫)
電子密碼本模式 Electronic Code Book(ECB)
加密塊鏈模式 Cipher Block Chaining(CBC)
加密反饋模式 Cipher Feedback Mode(CFB)
輸出反饋模式 Output Feedback Mode(OFB)
下面我們分別介紹這4種加密模式。
**********************************************************************
【電子密碼本模式】
這種模式是最早采用和最簡單的模式,它將加密的數據分成若干組,每組的大小跟加密密鑰長度相同,然后每組都用相同的密鑰進行加密。比如DES算法,一個64位的密鑰,如果采用該模式加密,就是將要加密的數據分成每組64位的數據,如果最后一組不夠64位,那么就補齊為64位,然后每組數據都采用DES算法的64位密鑰進行加密。下圖:
_______________________
My name |is Drago|nKing
-----------------------
上圖“My name is DragonKing”這句話每8個字符(64位)作為一塊,然后使用一個相同的64位的密鑰對每個塊進行加密,最后一塊不足64位,就補齊后再進行加密。
可以看到,因為ECB方式每64位使用的密鑰都是相同的,所以非常容易獲得密文進行密碼破解,此外,因為每64位是相互獨立的,有時候甚至不用破解密碼,只要簡單的將其中一塊替換就可以達到黑客目的。
【加密塊鏈模式】
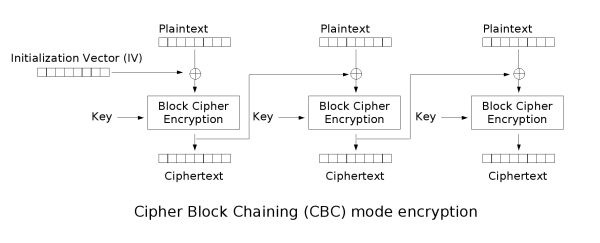
從這兩個圖中大家可以看到,CBC模式的加密首先也是將明文分成固定長度(64位)的塊(P0,P1...),然后將前面一個加密塊輸出的密文與下一個要加密的明文塊進行XOR(異或)操作計算,將計算結果再用密鑰進行加密得到密文。第一明文塊加密的時候,因為前面沒有加密的密文,所以需要一個初始化向量(IV)。跟ECB方式不一樣,通過連接關系,使得密文跟明文不再是一一對應的關系,破解起來更困難,而且克服了只要簡單調換密文塊可能達到目的的攻擊。
但是該加密模式的缺點是不能實時解密,也就是說,必須等到每8個字節都接受到之后才能開始加密,否則就不能得到正確的結果。這在要求實時性比較高的時候就顯得不合適了。所以才有了下面兩種加密模式。
【加密反饋模式】
加密反饋模式為了克服必須等待8個字節全部得到才能進行解密的缺點,采用了一個64位(8個字節)的位移寄存器來獲得密文,如下圖所示:
上面兩個圖中C2、C3以及P10等都是一個字節(8位)的數據,所以能夠實現字符的實時加密和解密,不用再等到8個字節都接受到之后再進行解密。圖示是在進行第10個字節數據的加密和解密過程,在該過程中,先從移位寄存器取8個字節的數據(C2到C9)用密鑰進行加密,然后取加密數據最左邊的一個字節跟輸入的明文P10進行XOR(異或)操作,得到的值作為輸出密文C10,同時將C10送入到移位寄存器中。
需要注意的是,如果其中有一個字節的密文在傳輸的時候發生錯誤(即使是其中的一位),那么它出現在移位寄存器期間解密的8個字節的數據都會得不到正確的解密結果,當然,這8個字節過去之后,依然可以得到正確的解密結果。但是一個比特錯誤就影響到8個字節(64個比特)的正確結果,導致魯棒性太差,所以就又提出了下面的加密模式OFB。
【輸出反饋模式】
輸出反饋模式OFB跟CFB幾乎是一樣的,除了其以為寄存器的輸入數據稍微有一點不同之外,如下圖:
可以看到,這種方法因為沒有采用密文作為加密的數據,所以克服了由于傳輸過程中由于單個比特導致64個相關比特解密失敗的情況,在本模式下,如果一個比特發生錯誤了,那么只會影響其本身對應的一個比特,而不會影響別的。但是相對于其它模式,因為數據之間相關性小,這種加密模式是比較不安全的,所以在應用的時候除非特別需要,一般不提倡應用OFB模式。
原文地址 http://hi.baidu.com/msingle/blog/item/e9d7cd455e02ed25cffca3a6.html
其他的一些補充:
■ 縮寫說明 ■
IN - 輸入向量
OUT - 輸出向量(未用于和明文加密前)
ENC - 加密算法
K - 加密密鑰
P - 明文
C - 密文
XOR - 異或
<< - 左移
BSIZE - 算法的加密塊尺寸
COUNT - 計數器
------------------------------------------------------------------------------
計數器(CTR)模式: IN(N) = ENC(K, COUNT++), C(N) = IN(N) XOR P(N);CTR 模式被廣泛用于 ATM 網絡安全和 IPSec應用中,相對于其它模式而言,CRT模式具有如下特點:
■ 硬件效率:允許同時處理多塊明文 / 密文。
■ 軟件效率:允許并行計算,可以很好地利用 CPU 流水等并行技術。
■ 預處理: 算法和加密盒的輸出不依靠明文和密文的輸入,因此如果有足夠的保證安全的存儲器,加密算法將僅僅是一系列異或運算,這將極大地提高吞吐量。
■ 隨機訪問:第 i 塊密文的解密不依賴于第 i-1 塊密文,提供很高的隨機訪問能力
■ 可證明的安全性:能夠證明 CTR 至少和其他模式一樣安全(CBC, CFB, OFB, ...)
■ 簡單性:與其它模式不同,CTR模式僅要求實現加密算法,但不要求實現解密算法。對于 AES 等加/解密本質上不同的算法來說,這種簡化是巨大的。
■ 無填充,可以高效地作為流式加密使用。
------------------------------------------------------------------------------
密文塊鏈接(CBC)模式:IN(N) = P(N) XOR C(N-1), C(N) = ENC(K, IN(N));在 CTR出現前廣泛使用的塊加密模式,用于安全的分組(迭代式)加密和認證。
------------------------------------------------------------------------------
密文反饋 (CFB) 模式: IN(N) = C(N-1) << (BSIZE-j), C(N) = ENC(K, IN(N)) << (BSIZE-j) XOR P(N). 其中 j 為每次加密的位數。CFB 模式與 CBC 模式原理相似,但一次僅處理 j 位數據,其余 BLOCKSIZE - j 位丟棄。由于以上性質,CFB 模式可以在不損失安全性的前提下,將塊加密變為流式加密。但是該模式也是比較浪費的,因為在每輪加解密中都丟棄了大部分結果(j 通常為一字節(8 位),塊加密算法中每塊的尺寸通常為64、128 或 256 位不等)。
------------------------------------------------------------------------------
輸出反饋 (OFB) 模式:IN(N) = OUT(N-1) << (BSIZE-j), C(N) = ENC(K, IN(N)) << (BSIZE-j) XOR P(N), OUT(N) = ENC(K, IN(N)) << (BSIZE-j). 該模式與 CFB 模式基本相同,只不過本次輸入是上次迭代中尚未與明文異或時的輸出。 與 CFB 模式一樣, OFB 模式也可以作為流加密模式使用,除此之外,由于每次迭代的輸入不是上次迭代的密文,從而保證了較強的容錯能力, 即: 對一塊(一字節)密文的傳輸錯誤不會影響到后繼密文。但是,由于輸入沒有經過密文疊加使得其抗篡改攻擊的能力較差,通常需要與消息驗
證算法或數字簽名算法配套使用。OFB 通常用于噪音水平較高的通信連接以及一般的流式應用中。
------------------------------------------------------------------------------
電碼本(ECB)模式: IN(N) = P(N), C(N) = ENC(K, IN(N)). 最簡單但最不安全的加密方式。每次迭代的輸入都使用相同密鑰進行無變換的直接加密。對于同樣的明文片斷,總會產生相同的,與之對應的密文段。抗重復統計和結構化分析的能力較差。一次性加密的最壞情況 (即:每次輸入的明文都小于等于 BSIZE 時) 就是電碼本模式。 僅在一次一密,或傳出極少數據時考慮使用 ECB 模式。
轉自:IaWeN's Blog-iawen,原創,安全,破解視頻,網頁設計,影視后期,AE特效
鏈接:http://www.iawen.com/read.php?296
形參出現在函數定義中,在整個函數體內都可以使用, 離開該函數則不能使用。
實參出現在主調函數中,進入被調函數后,實參變量也不能使用。
形參和實參的功能是作數據傳送。發生函數調用時, 主調函數把實參的值傳送給被調函數的形參從而實現主調函數向被調函數的數據傳送。
1.形參變量只有在被調用時才分配內存單元,在調用結束時, 即刻釋放所分配的內存單元。因此,形參只有在函數內部有效。 函數調用結束返回主調函數后則不能再使用該形參變量。
2.實參可以是常量、變量、表達式、函數等, 無論實參是何種類型的量,在進行函數調用時,它們都必須具有確定的值, 以便把這些值傳送給形參。 因此應預先用賦值,輸入等辦法使實參獲得確定值。
3.實參和形參在數量上,類型上,順序上應嚴格一致, 否則會發生“類型不匹配”的錯誤。
4.函數調用中發生的數據傳送是單向的。 即只能把實參的值傳送給形參,而不能把形參的值反向地傳送給實參。 因此在函數調用過程中,形參的值發生改變,而實參中的值不會變化。
5.當形參和實參不是指針類型時,在該函數運行時,形參和實參是不同的變量,他們在內存中位于不同的位置,形參將實參的內容復制一份,在該函數運行結束的時候形參被釋放,而實參內容不會改變。 而如果函數的參數是指針類型變量,在調用該函數的過程中,傳給函數的是實參的地址,在函數體內部使用的也是實參的地址,即使用的就是實參本身。所以在函數體內部可以改變實參的值
什么是對稱加密技術?
對稱加密采用了對稱密碼編碼技術,它的特點是文件加密和解密使用相同的密鑰,即加密密鑰也可以用作解密密鑰,這種方法在密碼學中叫做對稱加密算法,對稱加密算法使用起來簡單快捷,密鑰較短,且破譯困難,除了數據加密標準(DES),另一個對稱密鑰加密系統是國際數據加密算法(IDEA),它比DES的加密性好,而且對計算機功能要求也沒有那么高。IDEA加密標準由PGP(Pretty Good Privacy)系統使用。
對稱加密算法在電子商務交易過程中存在幾個問題:
1、要求提供一條安全的渠道使通訊雙方在首次通訊時協商一個共同的密鑰。直接的面對面協商可能是不現實而且難于實施的,所以雙方可能需要借助于郵件和電話等其它相對不夠安全的手段來進行協商;
2、密鑰的數目難于管理。因為對于每一個合作者都需要使用不同的密鑰,很難適應開放社會中大量的信息交流;
3、對稱加密算法一般不能提供信息完整性的鑒別。它無法驗證發送者和接受者的身份;
4、對稱密鑰的管理和分發工作是一件具有潛在危險的和煩瑣的過程。對稱加密是基于共同保守秘密來實現的,采用對稱加密技術的貿易雙方必須保證采用的是相同的密鑰,保證彼此密鑰的交換是安全可靠的,同時還要設定防止密鑰泄密和更改密鑰的程序。
假設兩個用戶需要使用對稱加密方法加密然后交換數據,則用戶最少需要2個密鑰并交換使用,如果企業內用戶有n個,則整個企業共需要n×(n-1) 個密鑰,密鑰的生成和分發將成為企業信息部門的惡夢。
常見的對稱加密算法有DES、3DES、Blowfish、IDEA、RC4、RC5、RC6和AES
什么是非對稱加密技術
1976年,美國學者Dime和Henman為解決信息公開傳送和密鑰管理問題,提出一種新的密鑰交換協議,允許在不安全的媒體上的通訊雙方交換信息,安全地達成一致的密鑰,這就是“公開密鑰系統”。相對于“對稱加密算法”這種方法也叫做“非對稱加密算法”。
與對稱加密算法不同,非對稱加密算法需要兩個密鑰:公開密鑰(publickey)和私有密鑰(privatekey)。公開密鑰與私有密鑰是一對,如果用公開密鑰對數據進行加密,只有用對應的私有密鑰才能解密;如果用私有密鑰對數據進行加密,那么只有用對應的公開密鑰才能解密。因為加密和解密使用的是兩個不同的密鑰,所以這種算法叫作非對稱加密算法。
非對稱加密算法實現機密信息交換的基本過程是:甲方生成一對密鑰并將其中的一把作為公用密鑰向其它方公開;得到該公用密鑰的乙方使用該密鑰對機密信息進行加密后再發送給甲方;甲方再用自己保存的另一把專用密鑰對加密后的信息進行解密。甲方只能用其專用密鑰解密由其公用密鑰加密后的任何信息。
非對稱加密算法的保密性比較好,它消除了最終用戶交換密鑰的需要,但加密和解密花費時間長、速度慢,它不適合于對文件加密而只適用于對少量數據進行加密。
如果企業中有n個用戶,企業需要生成n對密鑰,并分發n個公鑰。由于公鑰是可以公開的,用戶只要保管好自己的私鑰即可(企業分發后一般保存的是私鑰,用戶拿的是公鑰),因此加密密鑰的分發將變得十分簡單。同時,由于每個用戶的私鑰是唯一的,其他用戶除了可以可以通過信息發送者的公鑰來驗證信息的來源是否真實,還可以確保發送者無法否認曾發送過該信息。非對稱加密的缺點是加解密速度要遠遠慢于對稱加密,在某些極端情況下,甚至能比非對稱加密慢上1000倍。
非對稱加密的典型應用是數字簽名。
常見的非對稱加密算法有:RSA、ECC(移動設備用)、Diffie-Hellman、El Gamal、DSA(數字簽名用)
企業加密系統應用 常用加密算法介紹
對稱加密、非對稱加密、hash加密(md5加密是典型應用)
Hash算法
Hash算法特別的地方在于它是一種單向算法,用戶可以通過Hash算法對目標信息生成一段特定長度的唯一的Hash值,卻不能通過這個Hash值重新獲得目標信息。因此Hash算法常用在不可還原的密碼存儲、信息完整性校驗等。
常見的Hash算法有MD2、MD4、MD5、HAVAL、SHA
加密算法的效能通常可以按照算法本身的復雜程度、密鑰長度(密鑰越長越安全)、加解密速度等來衡量。上述的算法中,除了DES密鑰長度不夠、MD2速度較慢已逐漸被淘汰外,其他算法仍在目前的加密系統產品中使用。
對于較長的明文進行加密需要進行分塊加密,但是直接加密(ecb)不容易隱藏模式,用OpenCV寫了個程序論證了一下
ECB
優點就是簡單,可以并行計算,不會迭代誤差
缺點就是隱藏不了模式

CBC
需要初始化向量IV,來加密第一塊C0.
有點就是比ECB好
缺點不利于并行計算、誤差會迭代,還需要初始向量

加密算法為簡單的位翻轉
- #define bitrev(b) (((b)<<7)&0x80) | \
- (((b)<<5)&0x40) | \
- (((b)<<3)&0x20) | \
- (((b)<<1)&0x10) | \
- (((b)>>1)&0x08) | \
- (((b)>>3)&0x04) | \
- (((b)>>5)&0x02) | \
- (((b)>>7)&0x01)
#define bitrev(b) (((b)<<7)&0x80) | \
(((b)<<5)&0x40) | \
(((b)<<3)&0x20) | \
(((b)<<1)&0x10) | \
(((b)>>1)&0x08) | \
(((b)>>3)&0x04) | \
(((b)>>5)&0x02) | \
(((b)>>7)&0x01)
ECB加密,就是直接分塊進行加密
- for(int i=0;i<grey->width;i++)
- for(int j=0;j<grey->height;j++)
- grey->imageData[j*grey->width+i]=bitrev(grey->imageData[j*grey->width+i]);
- cvNamedWindow("ecb");
- cvShowImage("ecb", grey);
for(int i=0;i<grey->width;i++)
for(int j=0;j<grey->height;j++)
grey->imageData[j*grey->width+i]=bitrev(grey->imageData[j*grey->width+i]);
cvNamedWindow("ecb");
cvShowImage("ecb", grey);
CBC加密,與上一塊密文異或后加密
- for(int i=0;i<grey->width;i++)
- for(int j=0;j<grey->height;j++)
- if(i!=0&&j!=0)
- grey->imageData[j*grey->width+i]=bitrev(grey->imageData[j*grey->width+i]^grey->imageData[j*grey->width+i-1]);
- else
- grey->imageData[0]=grey->imageData[0]^IV;
- cvNamedWindow("cbc");
- cvShowImage("cbc", grey);
一. AES對稱加密:

AES加密

分組
二. 分組密碼的填充

分組密碼的填充
e.g.:

三. 流密碼:

四. 分組密碼加密中的四種模式:
3.1 ECB模式

優點:
1.簡單;
2.有利于并行計算;
3.誤差不會被傳送;
缺點:
1.不能隱藏明文的模式;
2.可能對明文進行主動攻擊;

3.2 CBC模式:

優點:
1.不容易主動攻擊,安全性好于ECB,適合傳輸長度長的報文,是SSL、IPSec的標準。
缺點:
1.不利于并行計算;
2.誤差傳遞;
3.需要初始化向量IV
3.3 CFB模式:

優點:
1.隱藏了明文模式;
2.分組密碼轉化為流模式;
3.可以及時加密傳送小于分組的數據;
缺點:
1.不利于并行計算;
2.誤差傳送:一個明文單元損壞影響多個單元;
3.唯一的IV;
3.4 OFB模式:

優點:
1.隱藏了明文模式;
2.分組密碼轉化為流模式;
3.可以及時加密傳送小于分組的數據;
缺點:
1.不利于并行計算;
2.對明文的主動攻擊是可能的;
3.誤差傳送:一個明文單元損壞影響多個單元;
PKCS#5填充方式
參與運算的兩個值,如果兩個相應bit位相同,則結果為0,否則為1。
即:
0^0 = 0,
1^0 = 1,
0^1 = 1,
1^1 = 0
按位異或的3個特點:
(1) 0^0=0,0^1=1 0異或任何數=任何數
(2) 1^0=1,1^1=0 1異或任何數-任何數取反
(3) 任何數異或自己=把自己置0
按位異或的幾個常見用途:
(1) 使某些特定的位翻轉
例如對數10100001的第2位和第3位翻轉,則可以將該數與00000110進行按位異或運算。
10100001^00000110 = 10100111
(2) 實現兩個值的交換,而不必使用臨時變量。
例如交換兩個整數a=10100001,b=00000110的值,可通過下列語句實現:
a = a^b; //a=10100111
b = b^a; //b=10100001
a = a^b; //a=00000110
(3) 在匯編語言中經常用于將變量置零:
xor a,a
(4) 快速判斷兩個值是否相等
舉例1: 判斷兩個整數a,b是否相等,則可通過下列語句實現:
return ((a ^ b) == 0)
舉例2: Linux中最初的ipv6_addr_equal()函數的實現如下:
static inline int ipv6_addr_equal(const struct in6_addr *a1, const struct in6_addr *a2)
{
return (a1->s6_addr32[0] == a2->s6_addr32[0] &&
a1->s6_addr32[1] == a2->s6_addr32[1] &&
a1->s6_addr32[2] == a2->s6_addr32[2] &&
a1->s6_addr32[3] == a2->s6_addr32[3]);
}
可以利用按位異或實現快速比較, 最新的實現已經修改為:
static inline int ipv6_addr_equal(const struct in6_addr *a1, const struct in6_addr *a2)
{
return (((a1->s6_addr32[0] ^ a2->s6_addr32[0]) |
(a1->s6_addr32[1] ^ a2->s6_addr32[1]) |
(a1->s6_addr32[2] ^ a2->s6_addr32[2]) |
(a1->s6_addr32[3] ^ a2->s6_addr32[3])) == 0);
}
5 應用通式:
對兩個表達式執行按位異或。
result = expression1 ^ expression2
參數
result
任何變量。
expression1
任何表達式。
expression2
任何表達式。
說明
^ 運算符查看兩個表達式的二進制表示法的值,并執行按位異或。該操作的結果如下所示:
0101 (expression1)1100 (expression2)----1001 (結果)當且僅當只有一個表達式的某位上為 1 時,結果的該位才為 1。否則結果的該位為 0。
只能用于整數
下面這個程序用到了“按位異或”運算符:
class E
{ public static void main(String args[ ])
{
char a1='十' , a2='點' , a3='進' , a4='攻' ;
char secret='8' ;
a1=(char) (a1^secret);
a2=(char) (a2^secret);
a3=(char) (a3^secret);
a4=(char) (a4^secret);
System.out.println("密文:"+a1+a2+a3+a4);
a1=(char) (a1^secret);
a2=(char) (a2^secret);
a3=(char) (a3^secret);
a4=(char) (a4^secret);
System.out.println("原文:"+a1+a2+a3+a4);
}
}
就是加密啊解密啊
char類型,也就是字符類型實際上就是整形,就是數字.
計算機里面所有的信息都是整數,所有的整數都可以表示成二進制的,實際上計算機只認識二進制的.
位運算就是二進制整數運算啦.
兩個數按位異或意思就是從個位開始,一位一位的比.
如果兩個數相應的位上一樣,結果就是0,不一樣就是1
所以111^101=010
那加密的過程就是逐個字符跟那個secret字符異或運算.
解密的過程就是密文再跟同一個字符異或運算
010^101=111
至于為什么密文再次異或就變原文了,這個稍微想下就知道了..