Posted on 2008-11-07 18:18
京山游俠 閱讀(4169)
評論(11) 編輯 收藏 所屬分類:
J2EE學習及探索

各位朋友,等人等車等吃飯的時候可以干些什么呢?掏出手機看電子書是不錯的選擇。昨天,我寫了一個小程序,基本上可以把新浪讀書頻道排行榜一網打盡。
程序只用到了Java中的這樣一些知識:
1、URL類,用來連接新浪網
2、BufferedReader類,用來讀取數據
3、Pattern類和Matcher類,使用正則表達式來提取小說的正文
完整的代碼如下:
/*
?*?To?change?this?template,?choose?Tools?|?Templates
?*?and?open?the?template?in?the?editor.
?*/
package?ebookdownloaderforsinanzt;
import?java.io.BufferedReader;
import?java.io.InputStreamReader;
import?java.net.URL;
import?java.util.regex.Matcher;
import?java.util.regex.Pattern;
/**
?*
?*?@author?海邊沫沫
?*/
public?class?Main?{
????/**
?????*?@param?args?the?command?line?arguments
?????*/
????public?static?void?main(String[]?args)?{
????????int?upbound?=?Integer.parseInt(args[1]);
????????for(int?i?=?1;?i<=upbound?;?i++){
????????????System.out.println(getParagraph("http://book.sina.com.cn/nzt/lit/"+args[0]+"/",i));
????????????System.out.println();
????????}
????}
????private?static?String?getParagraph(String?url,int?index)?{
????????int?status?=?0;
????????String?paragraph?=?"";
????????try?{
????????????URL?ebook?=?new?URL(url?+?index?+?".shtml");
????????????BufferedReader?reader?=?new?BufferedReader(new?InputStreamReader(ebook.openStream()));
????????????String?line;
????????????while?((line?=?reader.readLine())?!=?null)?{
????????????????if?(status?==?0)?{
????????????????????//還沒有碰到標題
????????????????????Pattern?pattern?=?Pattern.compile("(.*)<tr><td?class=title14?align=center><font?color=red><B>(.*)</B></font></td></tr>(.*)");
????????????????????Matcher?matcher?=?pattern.matcher(line);
????????????????????if?(matcher.matches())?{
????????????????????????paragraph?+=?matcher.group(2);
????????????????????????paragraph?+=?"\n\n";
????????????????????????status?=?1;
????????????????????}
????????????????}
????????????????if?(status?==?1)?{
????????????????????//還沒有碰到文章的開頭
????????????????????Pattern?pattern?=?Pattern.compile("(.*)<font?id=\"zoom\"?class=f14><p>(.*)<!--NEWSZW_HZH_BEGIN-->(.*)");
????????????????????Matcher?matcher?=?pattern.matcher(line);
????????????????????if?(matcher.matches())?{
????????????????????????paragraph?+=?matcher.group(2);
????????????????????????status?=?2;?//碰到了正文中的畫中畫
????????????????????}
????????????????}
????????????????if?(status?==?2)?{
????????????????????Pattern?pattern?=?Pattern.compile("(.*)<!--NEWSZW_HZH_END-->(.*)</p>");
????????????????????Matcher?matcher?=?pattern.matcher(line);
????????????????????if?(matcher.matches())?{
????????????????????????paragraph?+=?matcher.group(2);
????????????????????????status?=?3;
????????????????????}
????????????????}
????????????}
????????????//替換掉</p><p>
????????????return?paragraph.replaceAll("</p><p>",?"\n\n");
????????}?catch?(Exception?e)?{
????????????System.out.println(e.toString());
????????????return?null;
????????}
????}
}
讓大家看看截圖:
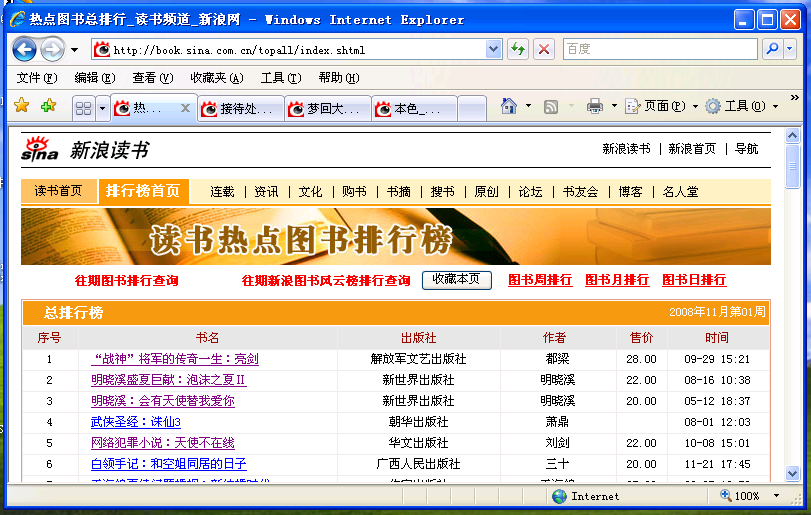
新浪讀書頻道排行榜:
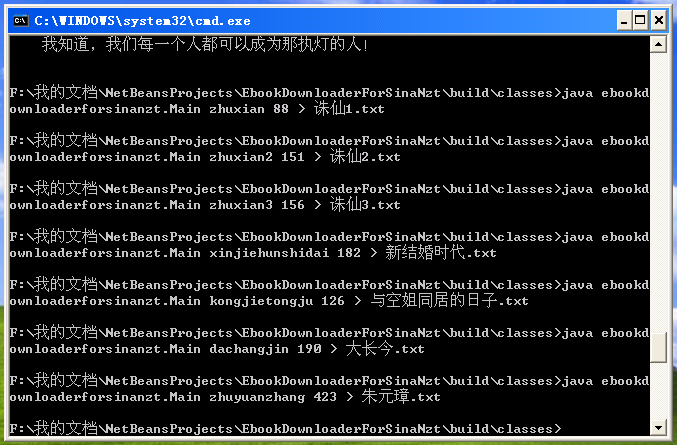
我寫的小程序的運行畫面:
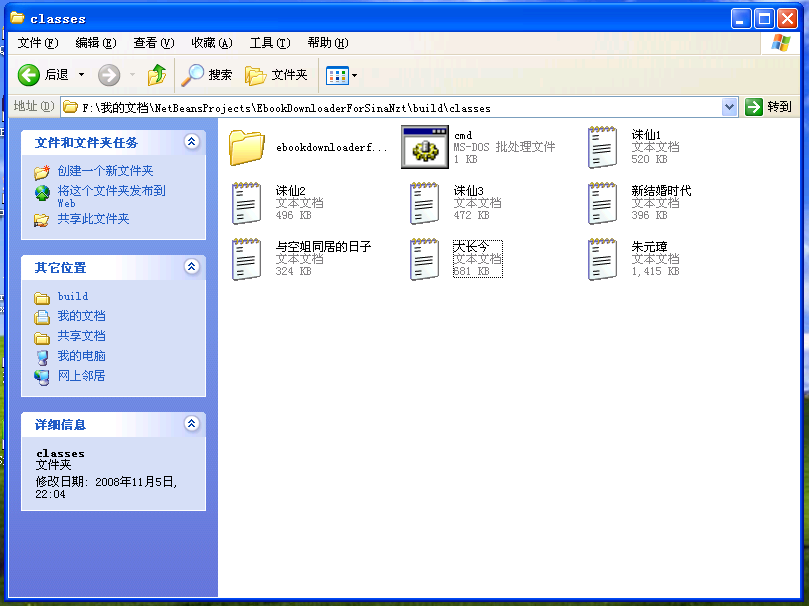
下載下來的成果:
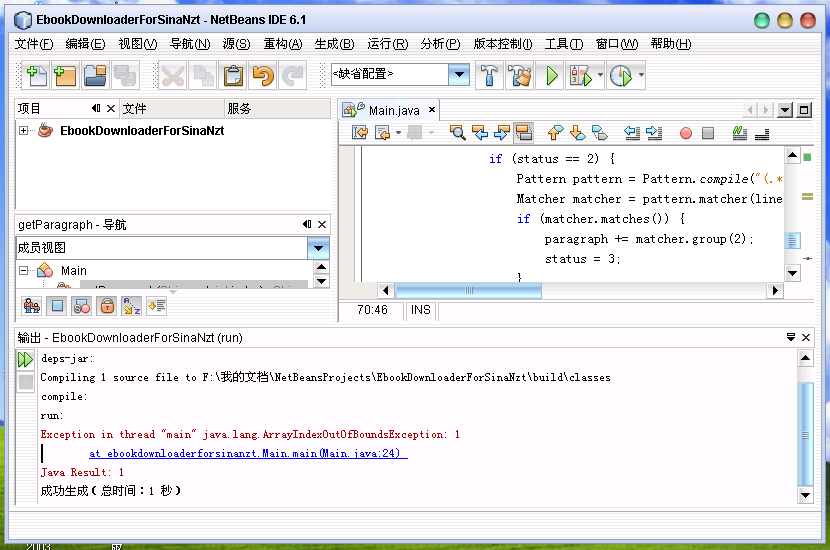
最后讓大家看看我的IDE,我用上了最新版的NetBeans,還把它的主題改成了蘋果樣子:
最后要說的是,新浪讀書頻道上的書,根據URL不同,其源代碼的結構也不同,所以要用不同的正則表達式來提取。上面的程序只能提取http://book.sina.com.cn/nzt/lit/小說名/序號.shtml這樣的電子書。但是對程序做一點修改是很簡單的。