package com.test.yjw;
public class Sort {
//冒泡
/**
*
*/
public static void bubbleSort(int a[]) {
int len = a.length;
for (int i = 0; i < len - 1; i++) {
for (int j = 0; j < len - 1 - i; j++) {
if (a[j] > a[j + 1]) {
int temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
}
for(int t : a){
System.out.println(t);
}
}
//選擇排序
public static void selectSort(int a[]) {
int temp = 0;
int len = a.length;
for (int i = 0; i < len - 1; i++) {
int min = a[i];
int index = i;
for (int j = i + 1; j < len; j++) {
if (min > a[j]) {
min = a[j];
index = j;
}
}
temp = a[i];
a[i] = a[index];
a[index] = temp;
}
for(int t : a){
System.out.println(t);
}
}
// 插入排序{9,5,1,3,7,8,6,2,0,4}
public static void insertSort(int a[]) {
int len = a.length;
for (int i = 1; i < len; i++) {
int temp = a[i];// 待插入的值
int index = i;// 待插入的位置
while (index > 0 && a[index - 1] > temp) {
a[index] = a[index - 1];// 待插入的位置重新賦更大的值
index--;// 位置往前移
}
a[index] = temp;
}
for(int t : a){
System.out.println(t);
}
}
//快速排序
public static void quickSort(int a[], int low, int height) {
if (low < height) {
int result = partition(a, low, height);
quickSort(a, low, result - 1);
quickSort(a, result + 1, height);
}
}
public static int partition(int a[], int low, int height) {
int key = a[low];
while (low < height) {
while (low < height && a[height] >= key)
height--;
a[low] = a[height];
while (low < height && a[low] <= key)
low++;
a[height] = a[low];
}
a[low] = key;
return low;
}
public static void swap(int a[], int i, int j) { // 通過臨時變量,交換數據
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
} // 第一次交換分析
public static void quicksort(int a[], int low, int high) { // 假設傳入low=0; high=a.length-1;
if (low < high) { // 條件判斷
int pivot, p_pos, i; // 聲明變量
p_pos = low; // p_pos指向low,即位索引為0位置 ;
pivot = a[p_pos]; // 將0位置上的數值賦給pivot;
for (i = low + 1; i <= high; i++) { // 循環次數, i=1;
if (a[i]>pivot) { // 1位置的數與0位置數作比較: a[1]>a[0]
p_pos++; // 2位與1位比較,3位與2位比較......
swap(a, p_pos, i); // 傳參并調用swap
}
}
swap(a, low, p_pos); // 將p_pos設為high再次調用swap
quicksort(a, low, p_pos - 1); // 遞歸調用,排序左半區
quicksort(a, p_pos + 1, high); // 遞歸調用,排序右半區
}
}
public static void main(String[] args) {
int[] a =new int[]{9,5,1,3,7,8,6,2,0,4};
//Sort.bubbleSort(a);
//Sort.selectSort(a);
//Sort.insertSort(a);
Sort.quickSort(a, 0, a.length-1);
for(int t : a){
System.out.println(t);
}
}
}
在java語言 I/O庫的設計中,使用了兩個結構模式,即裝飾模式和適配器模式。
在任何一種計算機語言中,輸入/輸出都是一個很重要的部分。與一般的計算機語言相比,java將輸入/輸出的功能和使用范疇做了很大的擴充。因此輸入輸出在java語言中占有極為重要的位置。
java語言采用流的機制來實現輸入/輸出。所謂流,就是數據的有序排列,流可以是從某個源(稱為流源,或者 Source of Stream)出來,到某個目的(Sink of Stream)地去。根據流的方向可以將流分成輸出流和輸入流。程序通過輸入流讀取數據,想輸出流寫出數據。
例如:一個java程序可以使用FileInputStream類從一個磁盤文件讀取數據,如下圖:
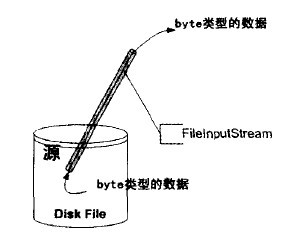
像FileInputStream這樣的處理器叫流處理器。一個流處理器就像一個流的管道一樣,從一個流源吸入某種類型的數據,并輸出某種類型的數據。上面的示意圖叫流的管道圖。
類似地,也可以用FileOutputStream類向一個磁盤文件寫數據,如下圖:

在實際的應用當中,這樣簡單的機制并沒有太大的用處。程序需要寫出的往往是非常結構話的信息,因此這些Byte類型的數據實際上是一些數字、文字、源代碼等。java的I/O庫提供了一個稱作鏈接(Chaining)的機制,可以將一個流處理器與另一個流處理器首尾相接,以其中之一的輸出為輸入,形成一個流管道的鏈接。
例如,DateInputStream流處理器可以把FileInputStream流對象的輸出當做輸入,將Byte類型的數據轉換成java的原始數據類型和String數據類型,如下圖:

類似地,向一個文件中寫入Byte類型的數據也不是一個簡單的過程。一個程序需要向一個文件里寫入的數據往往是結構化的,而Byte類型則是原始的類型,因此,在寫入的時候必須首先經過轉換。DateOutputStream流處理器提供了接受原始數據類型和String數據類型的方法,而這個流處理器的輸出數據則是Byte類型。換而言之,DateOutputStream可以將源數據轉換成Byte類型的數據,在輸出出來。
這樣一來,就可以將DateOutputStream與FileOutputStream鏈接起來。這樣做的結果就是,程序可以將原始數據類型和String數據類型的源數據寫到這個鏈接好的雙重管道里面,達到將結構話數據寫到磁盤文件里的目的,如下圖所示:

這是鏈接的威力。
流處理器所處理的流必定都有流源,如果將流類所處理的流源分類的話,那么基本可以分成兩大類:
(1)數組、String、File等,這一種叫原始流源。
(2)同樣類型的流用做鏈接流類的流源,就叫做鏈接流源。
java I/O庫的設計原則
java語言的I/O庫是對各種常見的流源、流匯以及處理過程的抽象化。客戶端的java 程序不必知道最終的的流源、流匯是磁盤上的文件還是一個數組,或者是一個線程;也不比插手到諸如數據是否緩存、可否按照行號讀取等處理的細節中去。
要理解java I/O 這個龐大而復雜的庫,關鍵是掌握兩個對稱性和兩個設計模式。
java I/O庫的兩個對稱性
java I/O庫具有兩個對稱性,它們分別是:
(1)輸入-輸出對稱:比如InputStream 和OutputStream 各自占據Byte流的輸入和輸出的兩個平行的等級結構的根部;而Reader和Writer各自占據Char流的輸入和輸出的兩個平行的等級結構的根部。
(2)byte-char對稱:InputStream和Reader的子類分別負責byte和插入流的輸入;OutputStream和Writer的子類分別負責byte和Char流的輸出,它們分別形成平行的等級結構。
java I/O庫的兩個設計模式
ava I/O庫的總體設計是符合裝飾模式和適配器模式的。如前所述,這個庫中處理流的類叫流類。
裝飾模式:在由InputStream、OutputStream、Reader和Writer代表的等級結構內部,有一些流處理器可以對另一些流處理器起到裝飾作用,形成新的、具有改善了的功能的流處理器。
適配器模式:在由InputStream、OutputStream、Reader和Writer代表的等級結構內部,有一些流處理器是對其他類型的流處理器的適配。這就是適配器的應用。
裝飾模式的應用
裝飾模式在java中的最著名的應用莫過于java I/O標準庫的設計了。
由于java I/O庫需要很多性能的各種組合,如果這些性能都是用繼承來實現,那么每一種組合都需要一個類,這樣就會造成大量行重復的類出現。如果采用裝飾模式,那么類的數目就會大大減少,性能的重復也可以減至最少。因此裝飾模式是java I/O庫基本模式。
裝飾模式的引進,造成靈活性和復雜性的提高。因此在使用 java I/O 庫時,必須理解java I/O庫是由一些基本的原始流處理器和圍繞它們的裝飾流處理器所組成的。
InputStream類型中的裝飾模式 InputStream有七個直接的具體子類,有四個屬于FilterInputStream的具體子類,如下圖所示:
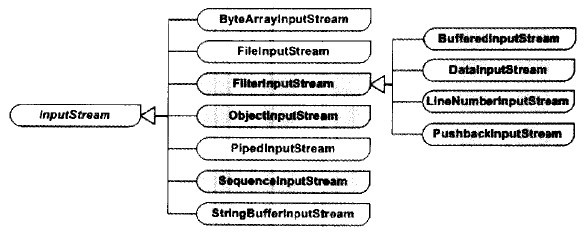
上圖中所有的類都叫做流處理器,這個圖叫做(InputStream類型)流處理器圖。根據輸入流的源的類型,可以將這些流分為兩種,即原始流類和鏈接流處理器。
原始流處理器
原始流處理器接收一個Byte數組對象、String對象、FileDescriptor對象或者不同類型的流源對象(就是前面所說的原始流源),并生成一個InputStream類型的流對象。在InputStream類型的流處理器中,原始流處理器包括以下四種:
(1)ByteArrayInputStream:為多線程的通訊提供緩沖區操作工作,接受一個Byte數組作為流的源。
(2)FileInputStream:建立一個與文件有關的輸入流。接受一個File對象作為流的源。
(3)PipedInputStream:可以和PipedOutputStream配合使用,用于讀入一個數據管道的數據。接受一個PipedOutputStream作為源。
(4)StringBufferInputStream:將一個字符串緩沖區抓換為一個輸入流。接受一個String對象作為流的源。
與原始流處理器相對應的是鏈接流處理器。
鏈接流處理器
所謂鏈接流處理器就是可以接受另一個(同種類的)流對象(就是鏈接流源)作為流源,并對之進行功能擴展的類。InputStream類型的鏈接流處理器包括以下幾種,它們接受另一個InputStream對象作為流源。
(1)FilterInputStream稱為過濾輸入流,它將另一個輸入流作為流源。這個類的子類包括以下幾種:
BufferInputStream:用來從硬盤將數據讀入到一個內存緩沖區中,并從此緩沖區提供數據。
DateInputStream:提供基于多字節的讀取方法,可以讀取原始數據類型的數據。
LineNumberInputStream:提供帶有行計算功能的過濾輸入流。
PushbackInputStream: 提供特殊的功能,可以將已讀取的直接“推回”輸入流中。
(2)ObjectInputStream 可以將使用ObjectInputStream串行化的原始數據類型和對象重新并行化。
(3)SequenceInputStream可以將兩個已有的輸入流連接起來,形成一個輸入流,從而將多個輸入流排列構成一個輸入流序列。
必須注意的是,雖然PipedInuptStream接受一個流對象PipedOutputStream作為流的源,但是PipedOutputStream流對象的類型不是InputStream,因此PipedInputStream流處理器仍屬于原始流處理器。
抽象結構圖
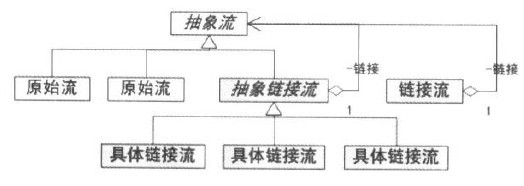
上面流處理器圖與裝飾模式的結構圖有明顯的相同之處。實際上InputStream類型的流處理器結構確實符合裝飾模式,而這可以從它們在結構中所扮演的角色中分辯出來。
裝飾模式的各個角色 在所有InputStream類型的鏈接流處理其中,使用頻率最大的就是FilterInputStream類,以這個類為抽象裝飾角色的裝飾模式結構非常明顯和典型。以這個類為核心說明裝飾模式的各個角色是由哪些流處理器扮演:
抽象構件(Component)角色:由InputStream扮演。這是一個抽象類,為各種子類型處理器提供統一的接口。
具體構建(Concrete Component)角色:由ByteArrayInputStream、FileInputStream、PipedInputStream以及StringBufferInputStream等原始流處理器扮演。它們實現了抽象構建角色所規定的接口,可以被鏈接流處理器所裝飾。
抽象裝飾(Decorator)角色:由FilterInputStream扮演。它實現了InputStream所規定的接口。
具體裝飾(Concrete Decorator)角色:由幾個類扮演,分別是DateInputStream、BufferedInputStream 以及兩個不常用到的類LineNumberInputStream和PushbackInputStream。
鏈接流其實就是裝飾角色,原始流就是具體構建角色,如下圖所示:

一方面,鏈接流對象接受一個(同類型的)原始流對象或者另一個(同類型的)鏈接流對象作為流源;另一方面,它們都對流源對象的內部工作方法做了相應的改變,這種改變是裝飾模式所要達到的目的。比如:
(1)BufferedInputStream “裝飾” 了InputStream的內部工作方式,使得流的讀入操作使用緩沖機制。在使用了緩沖機制后,不會對每一次的流讀入操作都產生一個物理的讀盤動作,從而提高了程序的效率。在涉及到物理流的讀入時,都應當使用這個裝飾流類。
(2)LineNumberInputStream和PushbackInputStream也同樣“裝飾”了InputStream的內部工作方式,前者使得程序能夠按照行號讀入數據;后者能使程序在讀入的過程中退后一個字符。后兩個裝飾類可能在實際的編程工作中很少用到,因為它們是為了支持用java語言做編譯器而準備的。
(3)DateInputStream子類讀入各種不同的原始數據類型以及String類型的數據,這一點可以從它提供的各種read()方法看出來:
readByte()、readUnsignedByte()、readShort()、readUnsignedShort()、readChar()、readInt()、readLong()、readFloat()、readDouble()、readUTF()。使用這個流處理器以及它的搭檔DateOutputStream,可以將原始數據通過流從一個地方移到另一個地方。
OutputStream 類型中的裝飾模式 outputStream是一個用于輸出的抽象類,它的接口、子類的等級結構、子類的功能都和InputStream有很好的對稱性。在OutputStream給出的接口里,將write換成read就得到了InputStream的接口,而其具體子類則在功能上面是平行的。
(1)針對byte數字流源的鏈接流類,以ByteArrayInputStream描述輸入流,以ByteArrayOutputStream描述輸出流。
(2)針對String流源的鏈接流類,以StringBufferInputStream描述輸入流,以StringBufferOutputStream描述輸出流。
(3)針對文件流源的鏈接流類,以FileInputStream描述輸入流,以FileOutputStream描述輸出流。
(4)針對數據管道流源的鏈接流類,以PipedInputStream描述輸入流,以PipedOutputStream描述輸出流。
(5)針對以多個流組成的序列,以SequenceInputStream描述輸入流,以SequenceOutputStream描述輸出流。
OutputStream類型有哪些子類
outputStream有5個直接的具體子類,加上三個屬于FilterInputStream的具體子類,一共有8個具體子類,如下圖:
 原始流處理器
原始流處理器
在OutputStream類型的流處理器中,原始流處理器包括以下三種:
ByteArrayOutputStream:為多線程的通信提供緩沖區操作功能。輸出流的匯集是一個byte數組。
FileOutputStream:建立一個與文件有關的輸出流。輸出流的匯集是一個文件對象。
PipedOutputStream: 可以與PipedInputStream配合使用,用于向一個數據管道輸出數據。
鏈接流處理器 OutputStream類型的鏈接流處理器包括以下幾種:
(1)FilterOutputStream:稱為過濾輸出流,它將另一個輸出流作為流匯。這個類的子類有如下幾種:
BufferedOutputStream:用來向一個內存緩沖區中寫數據,并將此緩沖區的數據輸入到硬盤中。
DataOutputStream:提供基于多字節的寫出方法,可以寫出原始數據類型的數據。
PrintStream:用于產生格式化輸出。System.out 靜態對象就是一個
PrintStream。
(2)ObjectOutputStream 可以將原始數據類型和對象串行化。
裝飾模式的各個角色
在所有的鏈接流處理器中,最常見的就是FilterOutputStream類。以這個類為核心的裝飾模式結構非常明顯和典型,如下圖:
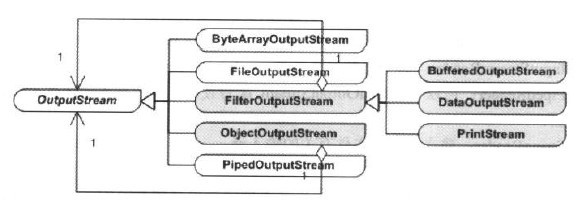
裝飾模式所涉及的各個角色:
抽象構件(Component)角色:由OutputStream扮演,這是一個抽象類,為各種的子類型流處理器提供統一的接口。
具體構件(Concrete Component)角色:由ByteArrayOutputStream、FileOutputStream、PipedOutputStream等扮演,它們均實現了OutputStream所聲明的接口。
抽象裝飾(Decorator)角色:由FilterOutputStream扮演,它與OutputStream有相同的接口,而這正是裝飾類的關鍵。
具體裝飾(Concrete Decorator)角色:由幾個類扮演,分別是BufferedOutputStream、DateOutputStream、以及PrintStream。
所謂鏈接流,就是裝飾模式中的裝飾角色,原始流就是具體構件角色。
與DateInputStream相對應的是DataOutputStream,后者負責將由原始數據類型和String對象組成的數據格式化,并輸出到一個流中,使得任何機器上的任何DataInputStream類型的對象都可以讀入這些數據。所有的方法都是以write開始。
如果需要對數據進行真正的格式化,以便輸出到像控制臺顯示那樣,那就需要使用PrintStream。
PrintStream可以對由原始數據類型和String對象組成的數據進行格式化,以形成可以閱讀的格式;而DataOutputStream則不同,它將數據輸出到一個流中,以便DataInputStream可以在任何機器而后操作系統中都可以重新將數據讀入,并進行結構重建。
PrintStream對象最重要的兩個方法是print() 和println(),這兩個方法都是重載的,以便可以打印出所有使用類型的數據。這兩個方法之間的區別是后者每行結束時多打印出一個換行符號。
BufferedOutputStream對一個輸出流進行裝飾,使得流的寫出操作使用緩沖機制。在使用緩沖機制后,不會對每一次的流的寫入操作都產生一個物理的寫動作,從而提高的程序的效率。在涉及到物理流的地方,比如控制臺I/O、文件I/O等,都應當使用這個裝飾流處理器。
Reader類型中的裝飾模式 在Reader類型的流處理器中,
原始流處理器包括以下四種:
(1)CharArrayReader:為多線程的通信提供緩沖區操作功能。
(2)InputStreamReader:這個類有一個子類--FileReader。
(3)PipedReader:可以與PipedOutputStream配合使用,用于讀入一個數據管道的數據。
(4)StringReader:建立一個與文件有關的輸入流。
鏈接流處理器包括以下:
(1)BufferedReader:用來從硬盤將數據讀入到一個內存緩沖區,并從此緩沖區提供數據,這個類的子類為
LineNumberReader。
(2)FilterReader:成為過濾輸入流,它將另一個輸入流作為流的來源。這個類的子類有PushbackReader,提供基于多字節的讀取方法,可以讀取原始數據類型的數據,Reader類型的類圖如下所示:
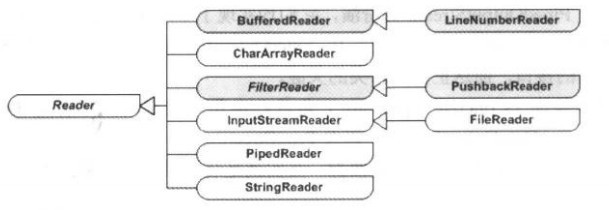
Reader類型中,裝飾模式所涉及的各個角色:
(1)抽象構建(Component)角色:有Reader扮演。這是一個抽象類,為各種的子類型流處理器提供統一的接口。
(2)具體構建(Concrete Component)角色:由CharArrayReader、InputStreamReader、PiPedReader、StringReader等扮演,他們均實現了Reader所聲明的接口。
(3)抽象裝飾(Decorator)角色:由BufferedReader和FilterReader扮演。這兩者有著與Reader相同的接口,它們分別給出兩個裝飾角色的等級結構,第一個給出LineNumberReader作為具體裝飾角色,另一個給出PushbackReader 作為具體裝飾角色。
(4)具體裝飾(Concrete Decorator)角色:LineNumberReader作為BufferedReader的具體裝飾角色,BufferedReader作為FilterReader的具體裝飾角色。
如下圖所示,標有聚合連線的就是抽象裝飾角色:
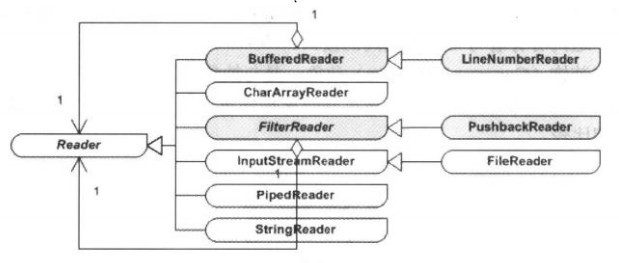 Writer類型中的裝飾模式
Writer類型中的裝飾模式 Writer類型是一個與Reader類型平行的等級結構,而且Writer類型的等級結構幾乎與Reader的等級結構關于輸入/輸出是對稱的。如圖所示:

在Writer類型的流處理器中,原始流處理器包括以下四種:
(1)CharArrayWriter:為多線程的通信提供緩沖區的操作功能。
(2)OutputStreamWriter:建立一個與文件有關的輸出流。含有一個具體子類FileWrite,為Write類型的輸出流提供文件輸出功能。
(3)PipedWriter:可以和PipedOutputStream配合使用,用于讀如果一個數據管道的數據。
(4)StringWriter:想一個StringBuffer寫出數據。
鏈接流處理器包括以下三種:
(1)BufferedWriter:為Writer類型的流處理器提供緩沖區功能。
(2)FilterWriter:稱為過濾輸入流,它將另一個輸入流作為流的來源。這是一個沒有子類的抽象類。
(3)PrintWriter:支持格式化的文字輸出。
Writer類型中,裝飾模式所涉及的各個角色:
(1)抽象構建(Component)角色:由Write扮演。這是一個抽象類,為為各種子類型的流處理器提供統一的接口。
(2)具體構建(Concrete Component):角色由
CharArrayWriter、OutputStreamWriter、
PipedWriter、StringWriter扮演,它們實現了Writer所聲明的接口。 (3)抽象裝飾(Decorator)角色:由
BufferedWriter、FilterWriter、PrintWriter扮演,它們有著與Write
相同的接口。
(4)具體裝飾(Concrete Decorator)角色:與抽象裝飾角色合并。
如下圖所示,標出了從抽象裝飾角色到抽象構件角色的聚合連線,更易于與裝飾模式的結構圖比較。
 適配器模式的應用
適配器模式的應用
適配器模式是java I/O庫中第二個最重要的設計模式。
InputStream原始流處理器中的適配器模式 InputStream類型的原始流處理器是適配器模式的應用。
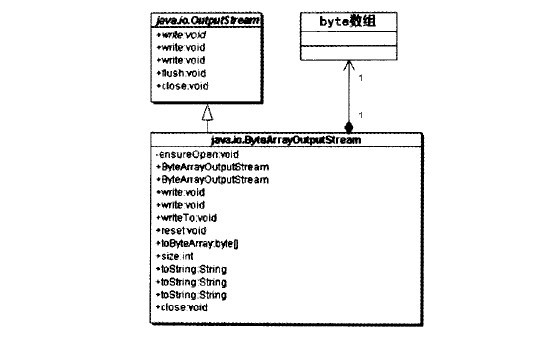
ByteArrayInputStream是一個適配器類
ByteArrayInputStream繼承了InputStream的接口,而封裝了一個byte數組。換而言之,它將一個byte數組的接口適配成了InputStream流處理器的接口。
java語言支持四種類型:java類、java接口、java數組和原始類型。前三章是引用類型,類和數組的實例都是對象,原始類型的值不少對象。java語言的數組是像所有其他對象一樣的對象,而不管數組中所存放的元素的類型是什么。這樣一來,ByteArrayInputStream就符合適配器模式的描述,而且是一個對象形式的適配器類。如下圖所示:
 StringBufferInputStream是一個適配器類
StringBufferInputStream是一個適配器類
StringBufferInputStream繼承了InputStream類型,同時持有一個對String類型的引用。這是將String對象適配成InputStream類型的對象形式的適配器模式,如下圖:
 OutputStream原始流處理器中的適配器模式
OutputStream原始流處理器中的適配器模式
在OutputStream類型中,所有的原始流處理器都是適配器類。
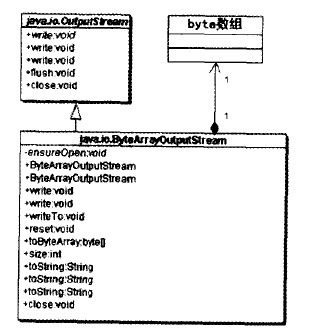
ByteArrayOutputStream是一個適配器類
ByteArrayOutputStream繼承了OutputStream類型,同事持有一個對byte數組的引用。它把一個byte數組的接口適配成OutputStream類型的接口,因此也是一個對象類型的適配器模式的應用。如下圖:
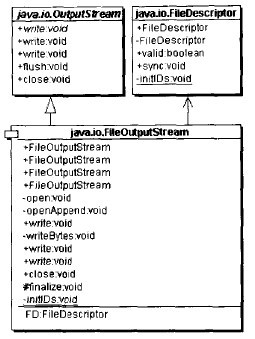
FileOutputStream是一個適配器類
FileOutputStream繼承OutputStream,同時持有一個對FileDescriptor對象的引用。這是一個將FileDescriptor適配成OutputStream接口的對象形式的適配器模式,如下圖所示:
PipedOutputStream是一個適配器類
PipedOutputStream總是和PipedInputStream一起使用,它接收一個類型為PipedInputStream的輸入類型,并將之轉換成OutputStream類型的輸出流,這是一個對象形式的適配器模式應用。如下圖:

Reader原始流處理器中的適配器模式
Reader 類型的原始流處理器都是適配器模式的應用。
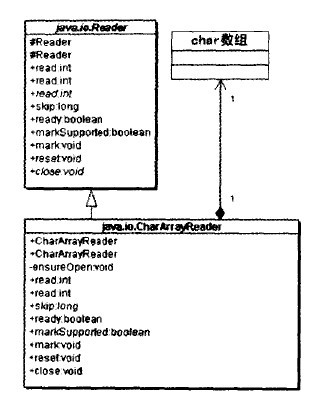
CharArrayReader是一個適配器類。
CharArrayReader將一個Char數組適配成Reader類型的輸入流,因此它是一個對象形式的適配器應用,如下圖所示:
StringReader是一個適配器類
StringReader 繼承了Reader類型,持有一個對String類型的引用。它將String的接口適配成Reader類型的接口,如下圖所示:

Writer類型中的適配器模式
Writer類型中的原始流處理器就是適配器模式的具體應用。
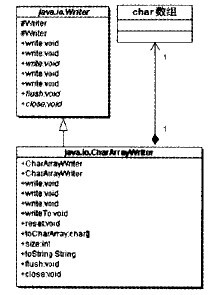
CharArrayWriter是一個適配器類。
CharArrayWriter將一個Char數組適配成Writer 接口,如下圖所示:
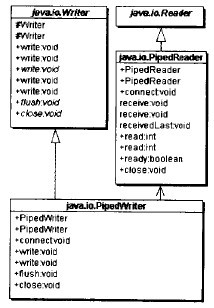
PipedWriter是一個適配器類
PipedWriter總是與PiPedReader一同使用,它將一個PipedReader對象的接口適配成一個Writer類型的接口,如下圖所示:
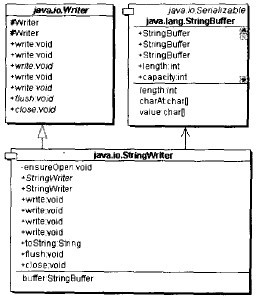
StringWriter是一個適配器類
StringWriter繼承Writer類型,同時持有一個StringBuffer對象,它將StringBuffer對象的接口適配成為了
Writer類型的接口,是一個對象形式的適配器 模式的應用,如下圖所示:
從byte流到char流的適配
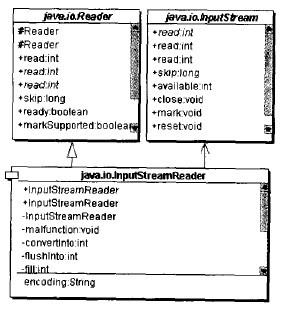
在java語言的標準庫 java I/O 里面,有一個InputStreamReader類叫做橋梁(bridge)類。InputStreamReader是從byte流到char流的一個橋梁,它讀入byte數據并根據指定的編碼將之翻譯成char數據。
InputStreamReader雖然叫“橋梁”,但它不爽橋梁模式,是適配器模式的應用。
InputStreamReader
InputStreamReader是從byte輸入流到char輸入流的一個適配器。下圖所示就是InputStreamReader 的結構圖:
為了說明適配器類InputStreamReader是如何使用,請看下面例子。Echo類可以將控制臺輸入的任何字符串從新打印出來,源代碼如下:
Echo.java
01 |
package com.think.cla; |
03 |
import java.io.BufferedReader; |
04 |
import java.io.IOException; |
05 |
import java.io.InputStreamReader; |
09 |
public static void main(String [] args)throws IOException{ |
11 |
InputStreamReader input = new InputStreamReader(System.in); |
12 |
System.out.println("Enter data and push enter:"); |
13 |
BufferedReader reader = new BufferedReader(input); |
14 |
line = reader.readLine(); |
15 |
System.out.println("Data entered :"+line); |
可以看出,這個類接受一個類型為inputStream的System.in對象,將之適配成Reader類型,然后再使用
BufferedReader類“裝飾”它,將緩沖功能加上去。這樣一來,就可以使用BufferedReader對象的readerLine()
方法讀入整行的輸入數據,數據類型是String。
在得到這個數據之后,程序又將它寫出到System.out 中去,完成了全部的流操作,下圖所示為其管道圖:
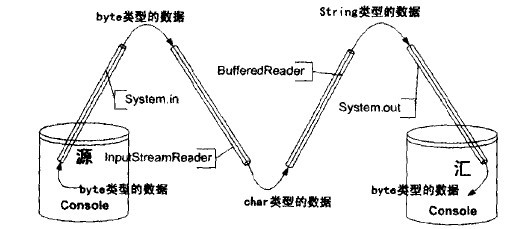
本系統使用了BufferedReader來為流的讀入提供緩沖功能,這樣做的直接效果是可以使用readLine()方法按行讀入數據。但是由于Reader接口并不提供readLine()方法,所以這樣一來,系統就必須聲明一個BufferedReader類型的流處理器,而不是一個Reader類型的流處理器,這意味著裝飾模式的退化。
在上面的管道連接過程中,InputStreamReader 起到了適配器的作用,它將一個byte類型的輸入流適配成為一個char類型的輸入流。在這之后,BufferedReader則起到了裝飾模式的作用,將緩沖機制引入到流的讀入中。因此這個例子涉及到了兩個設計模式。
package com.scpii.ent.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import com.scpii.ent.mode.bean.DataSet;
public class ExcelOperClass {
private static String EXCEL_2003 = ".xls";
private static String EXCEL_2007 = ".xlsx";
public static void readExcelJXL() {
}
/**
* 通過POI方式讀取Excel
*
* @param excelFile
*/
public static DataSet readExcelPOI(String filePath, Integer cons) throws Exception {
File excelFile = new File(filePath);
if (excelFile != null) {
String fileName = excelFile.getName();
fileName = fileName.toLowerCase();
if (fileName.toLowerCase().endsWith(EXCEL_2003)) {
DataSet dataSet = readExcelPOI2003(excelFile, cons);
return dataSet;
}
if (fileName.toLowerCase().endsWith(EXCEL_2007)) {
DataSet dataSet = readExcelPOI2007(excelFile, cons);
return dataSet;
}
}
return null;
}
/**
* 讀取Excel2003的表單
*
* @param excelFile
* @return
* @throws Exception
*/
private static DataSet readExcelPOI2003(File excelFile, Integer rCons)
throws Exception {
List<String[]> datasList = new ArrayList<String[]>();
Set<String> colsSet = new HashSet<String>();
InputStream input = new FileInputStream(excelFile);
HSSFWorkbook workBook = new HSSFWorkbook(input);
// 獲取Excel的sheet數量
Integer sheetNum = workBook.getNumberOfSheets();
// 循環Sheet表單
for (int i = 0; i < sheetNum; i++) {
HSSFSheet sheet = workBook.getSheetAt(i);
if (sheet == null) {
continue;
}
// 獲取Sheet里面的Row數量
Integer rowNum = sheet.getLastRowNum() + 1;
for (int j = 0; j < rowNum; j++) {
if (j>rCons) {
System.out.println("===========");
HSSFRow row = sheet.getRow(j);
if (row == null) {
continue;
}
Integer cellNum = row.getLastCellNum() + 1;
String[] datas = new String[cellNum];
for (int k = 0; k < cellNum; k++) {
HSSFCell cell = row.getCell(k);
if (cell == null) {
continue;
}
if (cell != null) {
cell.setCellType(HSSFCell.CELL_TYPE_STRING);
String cellValue = "";
int cellValueType = cell.getCellType();
if (cellValueType == cell.CELL_TYPE_STRING) {
cellValue = cell.getStringCellValue();
}
if (cellValueType == cell.CELL_TYPE_NUMERIC) {
Double number = cell.getNumericCellValue();
System.out.println("字符串+++=========="+number.intValue());
cellValue = cell.getNumericCellValue() + "";
}
if (rCons==k) {
colsSet.add(cellValue);
}
System.out.println(cellValue);
datas[k] = cellValue;
}
}
datasList.add(datas);
}
}
}
DataSet dataSet = new DataSet(null, null, datasList, colsSet);
return dataSet;
}
/**
* 讀取Excel2007的表單
*
* @param excelFile
* @return
* @throws Exception
*/
private static DataSet readExcelPOI2007(File excelFile, Integer rCons) throws Exception {
List<String[]> datasList = new ArrayList<String[]>();
Set<String> cosSet = new HashSet<String>();
InputStream input = new FileInputStream(excelFile);
XSSFWorkbook workBook = new XSSFWorkbook(input);
// 獲取Sheet數量
Integer sheetNum = workBook.getNumberOfSheets();
for (int i = 0; i < sheetNum; i++) {
XSSFSheet sheet = workBook.getSheetAt(i);
if (sheet == null) {
continue;
}
// 獲取行值
Integer rowNum = sheet.getLastRowNum() + 1;
for (int j = 0; j < rowNum; j++) {
if (j > rCons) {
System.out.println("=============");
XSSFRow row = sheet.getRow(j);
if (row == null) {
continue;
}
Integer cellNum = row.getLastCellNum() + 1;
String[] datas = new String[cellNum];
for (int k = 0; k < cellNum; k++) {
XSSFCell cell = row.getCell(k);
if (cell==null) {
continue;
}
if (cell != null) {
cell.setCellType(XSSFCell.CELL_TYPE_STRING);
String cellValue = "";
int cellValueType = cell.getCellType();
if (cellValueType == cell.CELL_TYPE_STRING) {
cellValue = cell.getStringCellValue();
}
if (cellValueType == cell.CELL_TYPE_NUMERIC) {
Double number = cell.getNumericCellValue();
System.out.println("字符串+++=========="+number.toString());
cellValue = cell.getNumericCellValue() + "";
}
System.out.println(cellValue);
if (rCons == k) {
cosSet.add(cellValue);
}
datas[k] = cellValue;
}
}
datasList.add(datas);
}
}
}
DataSet dataSet = new DataSet(null, null, datasList,cosSet);
return dataSet;
}
public static void main(String[] args) {
// try {
// DataSet dataSet = readExcelPOI("D:\\部門員工資料.xls", 0);
// System.out.println("================================");
// Set<String> datas = dataSet.getConStrctSet();
// String[] datastr = new String[datas.size()];
// datastr = datas.toArray(datastr);
// for (int i = 0; i < datastr.length; i++) {
// System.out.println(datastr[i]);
// }
// } catch (Exception e) {
// e.printStackTrace();
// }
System.out.println(52%4);
}
}
package com.scpii.ent.mode.bean;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
public class DataSet {
private String[] headers;
private String[] rowHeaders;
private List<String[]> datasList = new ArrayList<String[]>();
private Set<String> conStrctSet;
public DataSet(String[] headers, String[] rowHeaders,
List<String[]> datasList, Set<String> conStrctSet) {
this.headers = headers;
this.rowHeaders = rowHeaders;
this.datasList = datasList;
this.conStrctSet = conStrctSet;
}
public DataSet(String[] header, String[] rowsHeader,
List<String[]> datasList2) {
this.headers = header;
this.rowHeaders = rowsHeader;
this.datasList = datasList2;
}
public String[] getHeaders() {
return headers;
}
public void setHeaders(String[] headers) {
this.headers = headers;
}
public String[] getRowHeaders() {
return rowHeaders;
}
public void setRowHeaders(String[] rowHeaders) {
this.rowHeaders = rowHeaders;
}
public List<String[]> getDatasList() {
return datasList;
}
public void setDatasList(List<String[]> datasList) {
this.datasList = datasList;
}
public Set<String> getConStrctSet() {
return conStrctSet;
}
public void setConStrctSet(Set<String> conStrctSet) {
this.conStrctSet = conStrctSet;
}
}