原文鏈接:http://www.cnblogs.com/juandx/p/4962089.html
python中對文件、文件夾(文件操作函數)的操作需要涉及到os模塊和shutil模塊。
得到當前工作目錄,即當前Python腳本工作的目錄路徑: os.getcwd()
返回指定目錄下的所有文件和目錄名:os.listdir()
函數用來刪除一個文件:os.remove()
刪除多個目錄:os.removedirs(r“c:\python”)
檢驗給出的路徑是否是一個文件:os.path.isfile()
檢驗給出的路徑是否是一個目錄:os.path.isdir()
判斷是否是絕對路徑:os.path.isabs()
檢驗給出的路徑是否真地存:os.path.exists()
返回一個路徑的目錄名和文件名:os.path.split()
eg os.path.split(‘/home/swaroop/byte/code/poem.txt’)
結果:(‘/home/swaroop/byte/code’, ‘poem.txt’)
分離擴展名:os.path.splitext()
獲取路徑名:os.path.dirname()
獲取文件名:os.path.basename()
運行shell命令: os.system()
讀取和設置環境變量:os.getenv() 與os.putenv()
給出當前平臺使用的行終止符:os.linesep Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’
指示你正在使用的平臺:os.name 對于Windows,它是’nt’,而對于Linux/Unix用戶,它是’posix’
重命名:os.rename(old, new)
創建多級目錄:os.makedirs(r“c:\python\test”)
創建單個目錄:os.mkdir(“test”)
獲取文件屬性:os.stat(file)
修改文件權限與時間戳:os.chmod(file)
終止當前進程:os.exit()
獲取文件大小:os.path.getsize(filename)
文件操作:
os.mknod(“test.txt”) 創建空文件
fp = open(“test.txt”,w) 直接打開一個文件,如果文件不存在則創建文件
關于open 模式:
w 以寫方式打開,
a 以追加模式打開 (從 EOF 開始, 必要時創建新文件)
r+ 以讀寫模式打開
w+ 以讀寫模式打開 (參見 w )
a+ 以讀寫模式打開 (參見 a )
rb 以二進制讀模式打開
wb 以二進制寫模式打開 (參見 w )
ab 以二進制追加模式打開 (參見 a )
rb+ 以二進制讀寫模式打開 (參見 r+ )
wb+ 以二進制讀寫模式打開 (參見 w+ )
ab+ 以二進制讀寫模式打開 (參見 a+ )
fp.read([size]) #size為讀取的長度,以byte為單位
fp.readline([size]) #讀一行,如果定義了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作為一個list的一個成員,并返回這個list。其實它的內部是通過循環調用readline()來實現的。如果提供size參數,size是表示讀取內容的總長,也就是說可能只讀到文件的一部分。
fp.write(str) #把str寫到文件中,write()并不會在str后加上一個換行符
fp.writelines(seq) #把seq的內容全部寫到文件中(多行一次性寫入)。這個函數也只是忠實地寫入,不會在每行后面加上任何東西。
fp.close() #關閉文件。python會在一個文件不用后自動關閉文件,不過這一功能沒有保證,最好還是養成自己關閉的習慣。 如果一個文件在關閉后還對其進行操作會產生ValueError
fp.flush() #把緩沖區的內容寫入硬盤
fp.fileno() #返回一個長整型的”文件標簽“
fp.isatty() #文件是否是一個終端設備文件(unix系統中的)
fp.tell() #返回文件操作標記的當前位置,以文件的開頭為原點
fp.next() #返回下一行,并將文件操作標記位移到下一行。把一個file用于for … in file這樣的語句時,就是調用next()函數來實現遍歷的。
fp.seek(offset[,whence]) #將文件打操作標記移到offset的位置。這個offset一般是相對于文件的開頭來計算的,一般為正數。但如果提供了whence參數就不一定了,whence可以為0表示從頭開始計算,1表示以當前位置為原點計算。2表示以文件末尾為原點進行計算。需要注意,如果文件以a或a+的模式打開,每次進行寫操作時,文件操作標記會自動返回到文件末尾。
fp.truncate([size]) #把文件裁成規定的大小,默認的是裁到當前文件操作標記的位置。如果size比文件的大小還要大,依據系統的不同可能是不改變文件,也可能是用0把文件補到相應的大小,也可能是以一些隨機的內容加上去。
目錄操作:
os.mkdir(“file”) 創建目錄
復制文件:
shutil.copyfile(“oldfile”,”newfile”) oldfile和newfile都只能是文件
shutil.copy(“oldfile”,”newfile”) oldfile只能是文件夾,newfile可以是文件,也可以是目標目錄
復制文件夾:
shutil.copytree(“olddir”,”newdir”) olddir和newdir都只能是目錄,且newdir必須不存在
重命名文件(目錄)
os.rename(“oldname”,”newname”) 文件或目錄都是使用這條命令
移動文件(目錄)
shutil.move(“oldpos”,”newpos”)
刪除文件
os.remove(“file”)
刪除目錄
os.rmdir(“dir”)只能刪除空目錄
shutil.rmtree(“dir”) 空目錄、有內容的目錄都可以刪
轉換目錄
os.chdir(“path”) 換路徑
Python讀寫文件
1.open
使用open打開文件后一定要記得調用文件對象的close()方法。比如可以用try/finally語句來確保最后能關閉文件。
file_object = open(‘thefile.txt’)
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
注:不能把open語句放在try塊里,因為當打開文件出現異常時,文件對象file_object無法執行close()方法。
2.讀文件
讀文本文件
input = open('data', 'r')
#第二個參數默認為r
input = open('data')
1
2
3
讀二進制文件
input = open('data', 'rb')
1
讀取所有內容
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
1
2
3
4
5
讀固定字節
file_object = open('abinfile', 'rb')
try:
while True:
chunk = file_object.read(100)
if not chunk:
break
do_something_with(chunk)
finally:
file_object.close( )
1
2
3
4
5
6
7
8
9
讀每行
list_of_all_the_lines = file_object.readlines( )
1
如果文件是文本文件,還可以直接遍歷文件對象獲取每行:
for line in file_object:
process line
1
2
3.寫文件
寫文本文件
output = open('data', 'w')
1
寫二進制文件
output = open('data', 'wb')
1
追加寫文件
output = open('data', 'w+')
1
寫數據
file_object = open('thefile.txt', 'w')
file_object.write(all_the_text)
file_object.close( )
1
2
3
寫入多行
file_object.writelines(list_of_text_strings)
1
注意,調用writelines寫入多行在性能上會比使用write一次性寫入要高。
在處理日志文件的時候,常常會遇到這樣的情況:日志文件巨大,不可能一次性把整個文件讀入到內存中進行處理,例如需要在一臺物理內存為 2GB 的機器上處理一個 2GB 的日志文件,我們可能希望每次只處理其中 200MB 的內容。
在 Python 中,內置的 File 對象直接提供了一個 readlines(sizehint) 函數來完成這樣的事情。以下面的代碼為例:
file = open('test.log', 'r')sizehint = 209715200 # 200Mposition = 0lines = file.readlines(sizehint)while not file.tell() - position < 0: position = file.tell() lines = file.readlines(sizehint)
1
每次調用 readlines(sizehint) 函數,會返回大約 200MB 的數據,而且所返回的必然都是完整的行數據,大多數情況下,返回的數據的字節數會稍微比 sizehint 指定的值大一點(除最后一次調用 readlines(sizehint) 函數的時候)。通常情況下,Python 會自動將用戶指定的 sizehint 的值調整成內部緩存大小的整數倍。
file在python是一個特殊的類型,它用于在python程序中對外部的文件進行操作。在python中一切都是對象,file也不例外,file有file的方法和屬性。下面先來看如何創建一個file對象:
file(name[, mode[, buffering]])
1
file()函數用于創建一個file對象,它有一個別名叫open(),可能更形象一些,它們是內置函數。來看看它的參數。它參數都是以字符串的形式傳遞的。name是文件的名字。
mode是打開的模式,可選的值為r w a U,分別代表讀(默認) 寫 添加支持各種換行符的模式。用w或a模式打開文件的話,如果文件不存在,那么就自動創建。此外,用w模式打開一個已經存在的文件時,原有文件的內容會被清空,因為一開始文件的操作的標記是在文件的開頭的,這時候進行寫操作,無疑會把原有的內容給抹掉。由于歷史的原因,換行符在不同的系統中有不同模式,比如在 unix中是一個\n,而在windows中是‘\r\n’,用U模式打開文件,就是支持所有的換行模式,也就說‘\r’ ‘\n’ ‘\r\n’都可表示換行,會有一個tuple用來存貯這個文件中用到過的換行符。不過,雖說換行有多種模式,讀到python中統一用\n代替。在模式字符的后面,還可以加上+ b t這兩種標識,分別表示可以對文件同時進行讀寫操作和用二進制模式、文本模式(默認)打開文件。
buffering如果為0表示不進行緩沖;如果為1表示進行“行緩沖“;如果是一個大于1的數表示緩沖區的大小,應該是以字節為單位的。
file對象有自己的屬性和方法。先來看看file的屬性。
closed #標記文件是否已經關閉,由close()改寫
encoding #文件編碼
mode #打開模式
name #文件名
newlines #文件中用到的換行模式,是一個tuple
softspace #boolean型,一般為0,據說用于print
1
2
3
4
5
6
file的讀寫方法:
F.read([size]) #size為讀取的長度,以byte為單位
F.readline([size])
#讀一行,如果定義了size,有可能返回的只是一行的一部分
F.readlines([size])
#把文件每一行作為一個list的一個成員,并返回這個list。其實它的內部是通過循環調用readline()來實現的。如果提供size參數,size是表示讀取內容的總長,也就是說可能只讀到文件的一部分。
F.write(str)
#把str寫到文件中,write()并不會在str后加上一個換行符
F.writelines(seq)
#把seq的內容全部寫到文件中。這個函數也只是忠實地寫入,不會在每行后面加上任何東西。
file的其他方法:
F.close()
#關閉文件。python會在一個文件不用后自動關閉文件,不過這一功能沒有保證,最好還是養成自己關閉的習慣。如果一個文件在關閉后還對其進行操作會產生ValueError
F.flush()
#把緩沖區的內容寫入硬盤
F.fileno()
#返回一個長整型的”文件標簽“
F.isatty()
#文件是否是一個終端設備文件(unix系統中的)
F.tell()
#返回文件操作標記的當前位置,以文件的開頭為原點
F.next()
#返回下一行,并將文件操作標記位移到下一行。把一個file用于for ... in file這樣的語句時,就是調用next()函數來實現遍歷的。
F.seek(offset[,whence])
#將文件打操作標記移到offset的位置。這個offset一般是相對于文件的開頭來計算的,一般為正數。但如果提供了whence參數就不一定了,whence可以為0表示從頭開始計算,1表示以當前位置為原點計算。2表示以文件末尾為原點進行計算。需要注意,如果文件以a或a+的模式打開,每次進行寫操作時,文件操作標記會自動返回到文件末尾。
F.truncate([size])
#把文件裁成規定的大小,默認的是裁到當前文件操作標記的位置。如果size比文件的大小還要大,依據系統的不同可能是不改變文件,也可能是用0把文件補到相應的大小,也可能是以一些隨機的內容加上去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
http://www.cnblogs.com/allenblogs/archive/2010/09/13/1824842.html
http://www.cnblogs.com/rollenholt/archive/2012/04/23/2466179.html
首先 dfs.replication這個參數是個client參數,即node level參數。需要在每臺datanode上設置。
其實默認為3個副本已經夠用了,設置太多也沒什么用。
一個文件,上傳到hdfs上時指定的是幾個副本就是幾個。以后你修改了副本數,對已經上傳了的文件也不會起作用。可以再上傳文件的同時指定創建的副本數
Hadoop dfs -D dfs.replication=1 -put 70M logs/2
可以通過命令來更改已經上傳的文件的副本數:
hadoop fs -setrep -R 3 /
查看當前hdfs的副本數
hadoop fsck -locations
FSCK started by hadoop from /172.18.6.112 for path / at Thu Oct 27 13:24:25 CST 2011
....................Status: HEALTHY
Total size: 4834251860 B
Total dirs: 21
Total files: 20
Total blocks (validated): 82 (avg. block size 58954290 B)
Minimally replicated blocks: 82 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Thu Oct 27 13:24:25 CST 2011 in 10 milliseconds
The filesystem under path '/' is HEALTHY
某個文件的副本數,可以通過ls中的文件描述符看到
hadoop dfs -ls
-rw-r--r-- 3 hadoop supergroup 153748148 2011-10-27 16:11 /user/hadoop/logs/201108/impression_witspixel2011080100.thin.log.gz
如果你只有3個datanode,但是你卻指定副本數為4,是不會生效的,因為每個datanode上只能存放一個副本。
參考:http://blog.csdn.net/lskyne/article/details/8898666
轉自:https://www.cnblogs.com/shabbylee/p/6792555.html
由于歷史原因,Python有兩個大的版本分支,Python2和Python3,又由于一些庫只支持某個版本分支,所以需要在電腦上同時安裝Python2和Python3,因此如何讓兩個版本的Python兼容,如何讓腳本在對應的Python版本上運行,這個是值得總結的。
對于Ubuntu 16.04 LTS版本來說,Python2(2.7.12)和Python3(3.5.2)默認同時安裝,默認的python版本是2.7.12。
當然你也可以用python2來調用。
如果想調用python3,就用python3.
對于Windows,就有點復雜了。因為不論python2還是python3,python可執行文件都叫python.exe,在cmd下輸入python得到的版本號取決于環境變量里哪個版本的python路徑更靠前,畢竟windows是按照順序查找的。比如環境變量里的順序是這樣的:
那么cmd下的python版本就是2.7.12。
反之,則是python3的版本號。
這就帶來一個問題了,如果你想用python2運行一個腳本,一會你又想用python3運行另一個腳本,你怎么做?來回改環境變量顯然很麻煩。
網上很多辦法比較簡單粗暴,把兩個python.exe改名啊,一個改成python2.exe,一個改成python3.exe。這樣做固然可以,但修改可執行文件的方式,畢竟不是很好的方法。
我仔細查找了一些python技術文檔,發現另外一個我覺得比較好的解決辦法。
借用py的一個參數來調用不同版本的Python。py -2調用python2,py -3調用的是python3.
當python腳本需要python2運行時,只需在腳本前加上,然后運行py xxx.py即可。
#! python2
當python腳本需要python3運行時,只需在腳本前加上,,然后運行py xxx.py即可。
#! python3
就這么簡單。
同時,這也完美解決了在pip在python2和python3共存的環境下報錯,提示Fatal error in launcher: Unable to create process using '"'的問題。
當需要python2的pip時,只需
py -2 -m pip install xxx
當需要python3的pip時,只需
py -3 -m pip install xxx
python2和python3的pip package就這樣可以完美分開了。
Sentry權限控制通過Beeline(Hiveserver2 SQL 命令行接口)輸入Grant 和 Revoke語句來配置。語法跟現在的一些主流的關系數據庫很相似。需要注意的是:當sentry服務啟用后,我們必須使用beeline接口來執行hive查詢,Hive Cli并不支持sentry。
CREATE ROLE Statement
CREATE ROLE語句創建一個可以被賦權的角色。權限可以賦給角色,然后再分配給各個用戶。一個用戶被分配到角色后可以執行該角色的權限。
只有擁有管理員的角色可以create/drop角色。默認情況下,hive、impala和hue用戶擁有管理員角色。
CREATE ROLE [role_name];
DROP ROLE Statement
DROP ROLE語句可以用來從數據庫中移除一個角色。一旦移除,之前分配給所有用戶的該角色將會取消。之前已經執行的語句不會受到影響。但是,因為hive在執行每條查詢語句之前會檢查用戶的權限,處于登錄活躍狀態的用戶會話會受到影響。
DROP ROLE [role_name];
GRANT ROLE Statement
GRANT ROLE語句可以用來給組授予角色。只有sentry的管理員用戶才能執行該操作。
GRANT ROLE role_name [, role_name]
TO GROUP (groupName) [,GROUP (groupName)]
REVOKE ROLE Statement
REVOKE ROLE語句可以用來從組移除角色。只有sentry的管理員用戶才能執行該操作。
REVOKE ROLE role_name [, role_name]
FROM GROUP (groupName) [,GROUP (groupName)]
GRANT (PRIVILEGE) Statement
授予一個對象的權限給一個角色,該用戶必須為sentry的管理員用戶。
GRANT
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
TO ROLE (roleName) [,ROLE (roleName)]
REVOKE (PRIVILEGE) Statement
因為只有認證的管理員用戶可以創建角色,從而只有管理員用戶可以取消一個組的權限。
REVOKE
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
FROM ROLE (roleName) [,ROLE (roleName)]
GRANT (PRIVILEGE) ... WITH GRANT OPTION
在cdh5.2中,你可以委托給其他角色來授予和解除權限。比如,一個角色被授予了WITH GRANT OPTION的權限可以GRANT/REVOKE同樣的權限給其他角色。因此,如果一個角色有一個庫的所有權限并且設置了 WITH GRANT OPTION,該角色分配的用戶可以對該數據庫和其中的表執行GRANT/REVOKE語句。
GRANT
(PRIVILEGE)
ON (OBJECT) (object_name)
TO ROLE (roleName)
WITH GRANT OPTION
只有一個帶GRANT選項的特殊權限的角色或者它的父級權限可以從其他角色解除這種權限。一旦下面的語句執行,所有跟其相關的grant權限將會被解除。
REVOKE
(RIVILEGE)
ON (BJECT) (bject_name)
FROM ROLE (roleName)
Hive目前不支持解除之前賦予一個角色 WITH GRANT OPTION 的權限。要想移除WITH GRANT OPTION、解除權限,可以重新去除 WITH GRANT OPTION這個標記來再次附權。
SET ROLE Statement
SET ROLE語句可以給當前會話選擇一個角色使之生效。一個用戶只能啟用分配給他的角色。任何不存在的角色和當前用戶不能使用的角色是不能生效的。如果沒有使用任何角色,用戶將會使用任何一個屬于他的角色的權限。
選擇一個角色使用:
To enable a specific role:
使用所有的角色:
To enable a specific role:
關閉所有角色
SET ROLE NONE;
SHOW Statement
顯示當前用戶擁有庫、表、列相關權限的數據庫:
SHOW DATABASES;
顯示當前用戶擁有表、列相關權限的表;
SHOW TABLES;
顯示當前用戶擁有SELECT權限的列:
SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name];
顯示當前系統中所有的角色(只有管理員用戶可以執行):
SHOW ROLES;
顯示當前影響當前會話的角色:
SHOW CURRENT ROLES;
顯示指定組的被分配到的所有角色(只有管理員用戶和指定組內的用戶可以執行)
SHOW ROLE GRANT GROUP (groupName);
SHOW語句可以用來顯示一個角色被授予的權限或者顯示角色的一個特定對象的所有權限。
顯示指定角色的所有被賦予的權限。(只有管理員用戶和指定角色分配到的用戶可以執行)。下面的語句也會顯示任何列級的權限。
SHOW GRANT ROLE (roleName);
顯示指定對象的一個角色的所有被賦予的權限(只有管理員用戶和指定角色分配到的用戶可以執行)。下面的語句也會顯示任何列級的權限。
SHOW GRANT ROLE (roleName) on (OBJECT) (objectName);
----------------------------我也是有底線的-----------------------------
摘要: Python 里面的編碼和解碼也就是 unicode 和 str 這兩種形式的相互轉化。編碼是 unicode -> str,相反的,解碼就是 str -> unicode。剩下的問題就是確定何時需要進行編碼或者解碼了.關于文件開頭的"編碼指示",也就是 # -*- codin...
一、前言
早上醒來打開微信,同事反饋kafka集群從昨天凌晨開始寫入頻繁失敗,趕緊打開電腦查看了kafka集群的機器監控,日志信息,發現其中一個節點的集群負載從昨天凌晨突然掉下來了,和同事反饋的時間點大概一致,于是乎就登錄服務器開始干活。
二、排錯
1、查看機器監控,看是否能大概定位是哪個節點有異常
技術分享
2、根據機器監控大概定位到其中一個異常節點,登錄服務器查看kafka日志,發現有報錯日志,并且日志就停留在這個這個時間點:
[2017-06-01 16:59:59,851] ERROR Processor got uncaught exception. (kafka.network.Processor)
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306)
at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:174)
at sun.nio.ch.IOUtil.read(IOUtil.java:195)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:379)
at org.apache.kafka.common.network.PlaintextTransportLayer.read(PlaintextTransportLayer.java:108)
at org.apache.kafka.common.network.NetworkReceive.readFromReadableChannel(NetworkReceive.java:97)
at org.apache.kafka.common.network.NetworkReceive.readFrom(NetworkReceive.java:71)
at org.apache.kafka.common.network.KafkaChannel.receive(KafkaChannel.java:160)
at org.apache.kafka.common.network.KafkaChannel.read(KafkaChannel.java:141)
at org.apache.kafka.common.network.Selector.poll(Selector.java:286)
at kafka.network.Processor.run(SocketServer.scala:413)3、查看kafka進程和監聽端口情況,發現都正常,尼瑪假死了
ps -ef |grep kafka ## 查看kafka的進程
netstat -ntlp |grep 9092 ##9092kafka的監聽端口4、既然已經假死了,只能重啟了
ps -ef |grep kafka |grep -v grep |awk ‘{print $2}‘ | xargs kill -9
/usr/local/kafka/bin;nohup ./kafka-server-start.sh ../config/server.properties &5、重啟后在觀察該節點的kafka日志,在一頓index重建之后,上面的報錯信息在瘋狂的刷,最后谷歌一番,解決了該問題
三、解決方案:
在
/usr/local/kafka/binkafka-run-class.sh去掉
-XX:+DisableExplicitGC添加
-XX:MaxDirectMemorySize=512m在一次重啟kafka,問題解決。
摘要: 我們每次執行hive的hql時,shell里都會提示一段話:[python] view plaincopy... Number of reduce tasks not specified. Estimated from input data size: 50...
摘要: spark 累加歷史主要用到了窗口函數,而進行全部統計,則需要用到rollup函數
1 應用場景:
1、我們需要統計用戶的總使用時長(累加歷史)
2、前臺展現頁面需要對多個維度進行查詢,如:產品、地區等等
3、需要展現的表格頭如: 產品、2015-04、2015-05、2015-06
2 原始數據:
product_code |event_date |dur...
摘要: Spark1.4發布,支持了窗口分析函數(window functions)。在離線平臺中,90%以上的離線分析任務都是使用Hive實現,其中必然會使用很多窗口分析函數,如果SparkSQL支持窗口分析函數,
那么對于后面Hive向SparkSQL中的遷移的工作量會大大降低,使用方式如下:
1、初始化數據
創建表
[sql] view plain cop...
1.in 不支持子查詢 eg. select * from src where key in(select key from test);
支持查詢個數 eg. select * from src where key in(1,2,3,4,5);
in 40000個 耗時25.766秒
in 80000個 耗時78.827秒
2.union all/union
不支持頂層的union all eg. select key from src UNION ALL select key from test;
支持select * from (select key from src union all select key from test)aa;
不支持 union
支持select distinct key from (select key from src union all select key from test)aa;
3.intersect 不支持
4.minus 不支持
5.except 不支持
6.inner join/join/left outer join/right outer join/full outer join/left semi join 都支持
left outer join/right outer join/full outer join 中間必須有outer
join是最簡單的關聯操作,兩邊關聯只取交集;
left outer join是以左表驅動,右表不存在的key均賦值為null;
right outer join是以右表驅動,左表不存在的key均賦值為null;
full outer join全表關聯,將兩表完整的進行笛卡爾積操作,左右表均可賦值為null;
left semi join最主要的使用場景就是解決exist in;
Hive不支持where子句中的子查詢,SQL常用的exist in子句在Hive中是不支持的
不支持子查詢 eg. select * from src aa where aa.key in(select bb.key from test bb);
可用以下兩種方式替換:
select * from src aa left outer join test bb on aa.key=bb.key where bb.key <> null;
select * from src aa left semi join test bb on aa.key=bb.key;
大多數情況下 JOIN ON 和 left semi on 是對等的
A,B兩表連接,如果B表存在重復數據
當使用JOIN ON的時候,A,B表會關聯出兩條記錄,應為ON上的條件符合;
而是用LEFT SEMI JOIN 當A表中的記錄,在B表上產生符合條件之后就返回,不會再繼續查找B表記錄了,
所以如果B表有重復,也不會產生重復的多條記錄。
left outer join 支持子查詢 eg. select aa.* from src aa left outer join (select * from test111)bb on aa.key=bb.a;
7. hive四中數據導入方式
1)從本地文件系統中導入數據到Hive表
create table wyp(id int,name string) ROW FORMAT delimited fields terminated by '\t' STORED AS TEXTFILE;
load data local inpath 'wyp.txt' into table wyp;
2)從HDFS上導入數據到Hive表
[wyp@master /home/q/hadoop-2.2.0]$ bin/hadoop fs -cat /home/wyp/add.txt
hive> load data inpath '/home/wyp/add.txt' into table wyp;
3)從別的表中查詢出相應的數據并導入到Hive表中
hive> create table test(
> id int, name string
> ,tel string)
> partitioned by
> (age int)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE;
注:test表里面用age作為了分區字段,分區:在Hive中,表的每一個分區對應表下的相應目錄,所有分區的數據都是存儲在對應的目錄中。
比如wyp表有dt和city兩個分區,則對應dt=20131218city=BJ對應表的目錄為/user/hive/warehouse/dt=20131218/city=BJ,
所有屬于這個分區的數據都存放在這個目錄中。
hive> insert into table test
> partition (age='25')
> select id, name, tel
> from wyp;
也可以在select語句里面通過使用分區值來動態指明分區:
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> insert into table test
> partition (age)
> select id, name,
> tel, age
> from wyp;
Hive也支持insert overwrite方式來插入數據
hive> insert overwrite table test
> PARTITION (age)
> select id, name, tel, age
> from wyp;
Hive還支持多表插入
hive> from wyp
> insert into table test
> partition(age)
> select id, name, tel, age
> insert into table test3
> select id, name
> where age>25;
4)在創建表的時候通過從別的表中查詢出相應的記錄并插入到所創建的表中
hive> create table test4
> as
> select id, name, tel
> from wyp;
8.查看建表語句
hive> show create table test3;
9.表重命名
hive> ALTER TABLE events RENAME TO 3koobecaf;
10.表增加列
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT);
11.添加一列并增加列字段注釋
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
12.刪除表
hive> DROP TABLE pokes;
13.top n
hive> select * from test order by key limit 10;
14.創建數據庫
Create Database baseball;
14.alter table tablename change oldColumn newColumn column_type 修改列的名稱和類型
alter table yangsy CHANGE product_no phone_no string
15.導入.sql文件中的sql
spark-sql --driver-class-path /home/hadoop/hive/lib/mysql-connector-java-5.1.30-bin.jar -f testsql.sql
insert into table CI_CUSER_20141117154351522 select mainResult.PRODUCT_NO,dw_coclbl_m02_3848.L1_01_02_01,dw_coclbl_d01_3845.L2_01_01_04 from (select PRODUCT_NO from CI_CUSER_20141114203632267) mainResult left join DW_COCLBL_M02_201407 dw_coclbl_m02_3848 on mainResult.PRODUCT_NO = dw_coclbl_m02_3848.PRODUCT_NO left join DW_COCLBL_D01_20140515 dw_coclbl_d01_3845 on dw_coclbl_m02_3848.PRODUCT_NO = dw_coclbl_d01_3845.PRODUCT_NO
insert into CI_CUSER_20141117142123638 ( PRODUCT_NO,ATTR_COL_0000,ATTR_COL_0001) select mainResult.PRODUCT_NO,dw_coclbl_m02_3848.L1_01_02_01,dw_coclbl_m02_3848.L1_01_03_01 from (select PRODUCT_NO from CI_CUSER_20141114203632267) mainResult left join DW_COCLBL_M02_201407 dw_coclbl_m02_3848 on mainResult.PRODUCT_NO = dw_coclbl_m02_3848.PRODUCT_NO
CREATE TABLE ci_cuser_yymmddhhmisstttttt_tmp(product_no string) row format serde 'com.bizo.hive.serde.csv.CSVSerde' ;
LOAD DATA LOCAL INPATH '/home/ocdc/coc/yuli/test123.csv' OVERWRITE INTO TABLE test_yuli2;
創建支持CSV格式的testfile文件
CREATE TABLE test_yuli7 row format serde 'com.bizo.hive.serde.csv.CSVSerde' as select * from CI_CUSER_20150310162729786;
不依賴CSVSerde的jar包創建逗號分隔的表
"create table " +listName+ " ROW FORMAT DELIMITED FIELDS TERMINATED BY ','" +
" as select * from " + listName1;
create table aaaa ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE as select * from
ThriftServer 開啟FAIR模式
SparkSQL Thrift Server 開啟FAIR調度方式:
1. 修改$SPARK_HOME/conf/spark-defaults.conf,新增
2. spark.scheduler.mode FAIR
3. spark.scheduler.allocation.file /Users/tianyi/github/community/apache-spark/conf/fair-scheduler.xml
4. 修改$SPARK_HOME/conf/fair-scheduler.xml(或新增該文件), 編輯如下格式內容
5. <?xml version="1.0"?>
6. <allocations>
7. <pool name="production">
8. <schedulingMode>FAIR</schedulingMode>
9. <!-- weight表示兩個隊列在minShare相同的情況下,可以使用資源的比例 -->
10. <weight>1</weight>
11. <!-- minShare表示優先保證的資源數 -->
12. <minShare>2</minShare>
13. </pool>
14. <pool name="test">
15. <schedulingMode>FIFO</schedulingMode>
16. <weight>2</weight>
17. <minShare>3</minShare>
18. </pool>
19. </allocations>
20. 重啟Thrift Server
21. 執行SQL前,執行
22. set spark.sql.thriftserver.scheduler.pool=指定的隊列名
等操作完了 create table yangsy555 like CI_CUSER_YYMMDDHHMISSTTTTTT 然后insert into yangsy555 select * from yangsy555
創建一個自增序列表,使用row_number() over()為表增加序列號 以供分頁查詢
create table yagnsytest2 as SELECT ROW_NUMBER() OVER() as id,* from yangsytest;

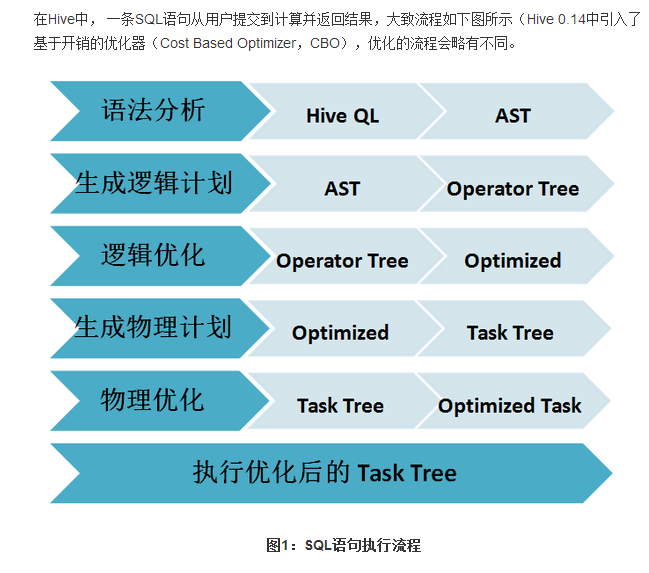
Sparksql的解析與Hiveql的解析的執行流程: