摘要: 需求描述:公司通過APP產品分享出去的需求和簡歷是做了一個H5頁面作為分享的鏈接,通過APP分享出去自然是沒問題,也是第一次分享,之后通過微信打開H5頁面后想再次分享出去時候就變成了一個鏈接了,而不是自己定制的卡片模式,初次分享后如下:但是打開以后的H5頁面再分享出去就變成這個樣子了:也就是說需要在H5頁面做微信分享的相關工作,JS-SDK上場了,首先看看JS-SDK的官方說明文檔:https:/...
Apache Zeppelin啟動默認是匿名(anonymous)模式登錄的,也就是任何人都可以訪問,這個可以在/zeppelin/conf下的zeppelin-site.xml中看到:
<property>
<name>zeppelin.anonymous.allowed</name>
<value>true</value>
<description>Anonymous user allowed by default</description>
</property>
description中寫道Anonymous user allowed by default(匿名用戶默認被允許),這樣我們訪問我們安裝的zepplin界面里是這樣的:

右上角顯示anonymous表示匿名模式。
接下來我們要做的就是如何通過修改配置來讓我們的zeppelin擁有驗證登錄的功能:
- 修改/zeppelin/conf/zeppelin-site.xml文件選項zeppelin.anonymous.allowed的value為false,表示不允許匿名訪問:
- <property>
<name>zeppelin.anonymous.allowed</name>
<value>false</value>
<description>Anonymous user allowed by default</description>
</property>
- 修改/zeppelin/conf/shiro.ini文件,顯然zeppelin采用了shiro作為他的驗證登錄權限控制框架,那么我們需要對shiro有一些了解,我們去看該文件的最后幾行:
[urls]
# anon means the access is anonymous.
# authcBasic means Basic Auth Security
# authc means Form based Auth Security
# To enfore security, comment the line below and uncomment the next one
/api/version = anon
/** = anon
#/** = authc
顯然是對localhost:7878/#/**的進行驗證,對/**的不驗證,那我們就修改為對任何url訪問都需要驗證:把/**=anon修改為/**=authc,這樣重啟zeppelin后訪問我們的zeppelin主頁就變成這個樣子了:
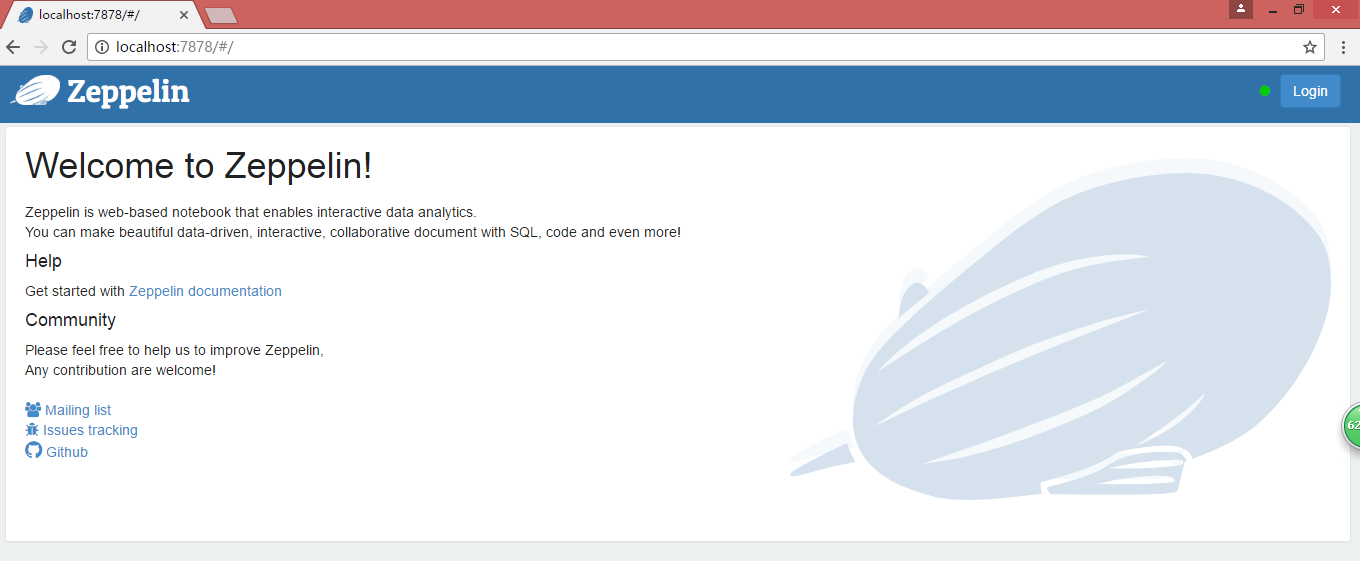
看見右上角的Login按鈕了吧?對的,你現在zeppelin已經需要登錄才能繼續訪問了,可是滿屏幕的去找也沒找到注冊的地方,那么我們通過什么賬號來進行登錄呢?繼續修改zeppelin/conf/shiro.ini文件:
[users]
# List of users with their password allowed to access Zeppelin.
# To use a different strategy (LDAP / Database / ...) check the shiro doc at http://shiro.apache.org/configuration.html#Configuration-INISections
admin = admin
user1 = password2, role1, role2
user2 = password3, role3
user3 = password4, role2
已經給我們加了這些賬號了,看第一條注釋提供了用戶以及對應的密碼用來允許訪問zeppelin,然后你自己可以在下面加一些用戶xxx = yyy,其中的角色也可以自行選擇,需要詳細了解的可以熟悉熟悉shiro的角色權限控制。重啟zeppelin用你知道的賬號去登錄吧~!
輸入對應賬號進入主頁后選擇一個你已經添加過的notebook進去然后去右上角看見有一把小鎖:
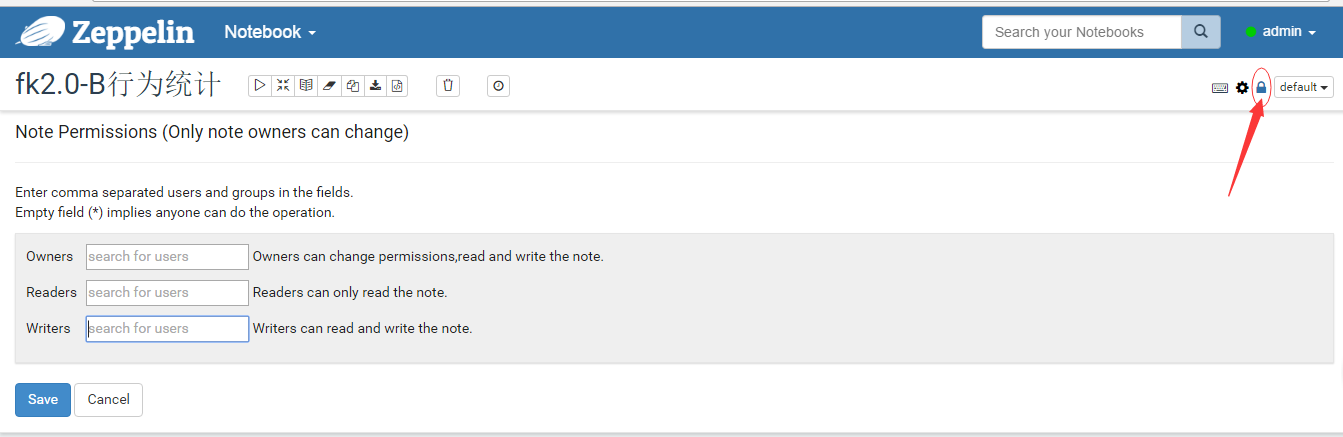
會顯示Note Permissions點擊后出現上圖所示可以填寫該notebook的Owners(所有者)、Readers(只讀用戶)、Writers(讀寫用戶),這樣每一個notebook就可以歸屬于某一個具體的用戶了,避免了多用戶同時使用zeppelin可能造成的沖突。
還有很多其他功能值得你去發現、研究!
1.JDK和JRE的區別:
JDK是Java Development Kit。是面向開發人員使用的SDK,提供了java的開發環境以及運行環境。
JRE是Java Runtime Enviroment。是指java的運行環境,是面向java程序得使用者,而不是開發者。
2.序列化的目的:
Java中,一切都是對象,在分布式環境中經常需要將Object從這一端網絡或設備傳遞到另一端。這就需要有一種可以在兩端傳輸數據的協議。Java序列化機制就是為了解決這個問題而產生。
以某種存儲形式使自定義對象持久化。
將對象從一個地方傳到另一個地方。
3.equals和==的區別:
基本數據類型應該用“==”來比較他們的值。
當比較對象時候,如果對象里重寫了equals方法,比如String,Integer,Date這些類,比較對象的內存地址應該用“==”,比較對象的值用“equals”,如果沒有重寫equals方法,兩者本質上是相同的,都是比較值。
4.什么時候使用Comparator and Comparable 接口
當需要排序的集合或數組不是單純的數字類型的時候,通常可以使用Comparator或Comparable,以簡單的方式實現對象排序和自定義排序。
Comparable用在對象本身,說明這個對象是可以被比較的,也就是說可以被排序的。(String和Integer之所以可以比較大小,是因為它們都實現了Comparable接口,并實現了compareTo()方法)。
Compator用在對象外,相當于定義了一個排序算法。
5.轉發和重定向的區別:
轉發時URL不會改變,request請求內的對象將可以繼續使用,重定向時瀏覽器URL會改變,之前的request會丟失,因此request里的數據也不會得到。
通常情況下轉發速度更快,而且能保持request內的對象,但是轉發之后,瀏覽器的連接還在先前頁面所以可以重載先前頁面。
轉發:request.getRequestDispatcher("apage.jsp").forward(request, response);
重定向:response.sendRedirect("apage.jsp");
6.編譯期異常和運行時異常
編譯時異常可以捕捉,比如我們讀寫文件時候會拋出IOException,操作數據庫時會有SQLException,運行時異常不可以捕捉,比如數組下標溢出,空指針異常等
7.Struts1原理和Struts2原理以及區別和聯系,在什么項目中用過,有什么體會?
struts1原理:客戶端發送HttpServletRequest請求給ActionServlet,ActionServlet會檢索和用戶請求匹配的ActionMapping實例,如果不存在就返回請求路徑無效的信息,如果存在就會把請求的表單數據保存到ActionForm中去,如果ActionForm不存在就會創建一個ActionForm對象,然后再根據配置信息決定是否需要表單驗證,如果需要驗證就調用ActionForm的validate()方法,驗證通過后ActionServlet根據ActionMapping實例包含的映射信息決定將請求轉發給哪個Action,如果相應的Action實例不存在就先創建這個Action然后調用Action的execute()方法。Action的execute()方法返回一個ActionForward對象,ActionServlet再把客戶請求轉發給ActionForward對象指向的jsp組件。
struts2原理:客戶端發送HttpServletRequest請求,請求被提交到一系列的Filter,首先是ActionContextCleanUp,然后是其他Filter,最后是FilterDispatcher。FilterDispatcher是Struts2的核心,就是MVC的Struts2實現中控制層的核心。FilterDispatcher詢問ActionMapper決定需要調用哪個Action,FilterDispatcher會把請求交給ActionProxy,ActionProxy會根據Struts.xml配置文件找到需要調用的Action類。ActionProxy創建一個ActionInvocation實例,同時ActionInvocation通過代理模式調用Action類,調用之前會加載Action相關的所有攔截器,一旦Action執行完畢,ActionInvocation根據Struts.xml配置文件返回對應的result。
區別:1.Struts1是通過Servlet啟動的,struts1要求Action繼承一個抽象類,而不是接口,Struts2的Action類可以實現一個Action接口也可以實現其他接口。
2.struts1的Action是單例模式線程是不安全的,struts2是線程安全的,Action為每一個請求都生成了一個實例。
3.struts1是以ActionServlet為核心控制器,struts2是以FilterDispatcher為核心控制器。
執行流程:
a)struts1
jsp發起httprequest請求->servlet捕獲->struts.xml->namespace+ActionName-> Action->填充表單setXxx()->action.execute()->”success”->Result->設置request屬性->跳轉目標頁
b) Action(jsp發起httprequest請求,被過濾器捕獲)->FilterDispatcher->struts.xml->namespace+ActionName->new Action->填充表單setXxx()->action.execute()->”success”->Result->設置request屬性->跳轉目標頁
8.spring原理
spring的最大作用ioc/di,將類與類的依賴關系寫在配置文件中,程序在運行時根據配置文件動態加載依賴的類,降低的類與類之間的藕合度。它的原理是在applicationContext.xml加入bean標記,在bean標記中通過class屬性說明具體類名、通過property標簽說明該類的屬性名、通過constructor-args說明構造子的參數。其一切都是反射,當通過applicationContext.getBean(“id名稱”)得到一個類實例時,就是以bean標簽的類名、屬性名、構造子的參數為準,通過反射實例對象,喚起對象的set方法設置屬性值、通過構造子的newInstance實例化得到對象。正因為spring一切都是反射,反射比直接調用的處理速度慢,所以這也是spring的一個問題。
spring第二大作用就是aop,其機理來自于代理模式,代理模式有三個角色分別是通用接口、代理、真實對象。代理、真實對象實現的是同一接口,將真實對象作為代理的一個屬性,向客戶端公開的是代理,當客戶端調用代理的方法時,代理找到真實對象,調用真實對象方法,在調用之前之后提供相關的服務,如事務、安全、日志。其名詞分別是代理、真實對象、裝備、關切點、連接點。
9.簡要概述一下SpringMVC和StrutsMVC
Spring的MVC框架主要由DispatcherServlet、處理器映射、處理器、視圖解析器、視圖組成。
1)DispatcherServlet接收到請求后,根據對應配置文件中配置的處理器映射,找到對應的處理器映射項(HandlerMapping),根據配置的映射規則,找到對應的處理器(Handler)。
2)調用相應處理器中的處理方法,處理該請求,處理器處理結束后會將一個ModelAndView類型的數據傳給DispatcherServlet,這其中包含了處理結果的視圖和視圖中要使用的數據。
3)DispatcherServlet 根據得到的ModelAndView中的視圖對象,找到一個合適的ViewResolver(視圖解析器),根據視圖解析器的配 置,DispatcherServlet將視圖要顯示的數據傳給對應的視圖,最后給瀏覽器構造一個HTTP響應。
DispatcherServlet是整個Spring MVC的核心。它負責接收HTTP請求組織協調Spring MVC的各個組成部分。其主要工作有以下三項:
1)截獲符合特定格式的URL請求。
2)初始化DispatcherServlet上下文對應的WebApplicationContext,并將其與業務層、持久化層的WebApplicationContext建立關聯。
3)初始化Spring MVC的各個組成組件,并裝配到DispatcherServlet中。
StrutsMVC
1.當啟動容器時,容器(tomcat、weblogic)實例化ActionServlet,初始化ActionServlet,在初始化
ActionServlet時加載struts-config.xml文件。
2.當客戶通過url.do將請求發給ActionServlet,ActionServlet將處理轉發給助手RequestProcessor,RequestProcess通過struts-config.xml找到對應的actionForm及 action,如果有ActionForm用已有的,沒有通過類的反射實例化一個新的ActionForm,放置到作用域對象,通過反射
- 將表單域的值填充到actionForm中。如果有Action用已有的,沒有產生一個新的,通過反射調用action實例的execute方法,在執行前將actionForm通過參數注入到execute方法中。
- 3.execute方法執行結束前通過actionMapping找到actionForward轉發到另一個頁面。
10.Servlet的工作原理、生命周期
Servlet的工作原理:
Servlet 生命周期:Servlet 加載--->實例化--->服務--->銷毀。 init():在Servlet的生命周期中,僅執行一次init()方法。它是在服務器裝入Servlet時執行的,負責初始化Servlet 對象。可以配置服務器,以在啟動服務器或客戶機首次訪問Servlet時裝入Servlet。無論有多少客戶機訪問Servlet,都不會重復執行 init()。 service():它是Servlet的核心,負責響應客戶的請求。每當一個客戶請求一個HttpServlet對象,該對象的 Service()方法就要調用,而且傳遞給這個方法一個“請求”(ServletRequest)對象和一個“響應” (ServletResponse)對象作為參數。在HttpServlet中已存在Service()方法。默認的服務功能是調用與HTTP請求的方法 相應的do功能。 destroy(): 僅執行一次,在服務器端停止且卸載Servlet時執行該方法。當Servlet對象退出生命周期時,負責釋放占用的資 源。一個Servlet在運行service()方法時可能會產生其他的線程,因此需要確認在調用destroy()方法時,這些線程已經終止或完成。
Servlet工作原理:
1、首先簡單解釋一下Servlet接收和響應客戶請求的過程,首先客戶發送一個請求,Servlet是調用service()方法對請求進行響應 的,通過源代碼可見,service()方法中對請求的方式進行了匹配,選擇調用doGet,doPost等這些方法,然后再進入對應的方法中調用邏輯層 的方法,實現對客戶的響應。在Servlet接口和GenericServlet中是沒有doGet()、doPost()等等這些方法 的,HttpServlet中定義了這些方法,但是都是返回error信息,所以,我們每次定義一個Servlet的時候,都必須實現doGet或 doPost等這些方法。
2、每一個自定義的Servlet都必須實現Servlet的接口,Servlet接口中定義了五個方法,其中比較重要的三個方法涉及到 Servlet的生命周期,分別是上文提到的init(),service(),destroy()方法。GenericServlet是一個通用的,不 特定于任何協議的Servlet,它實現了Servlet接口。而HttpServlet繼承于GenericServlet,因此 HttpServlet也實現了Servlet接口。所以我們定義Servlet的時候只需要繼承HttpServlet即可。
3、Servlet接口和GenericServlet是不特定于任何協議的,而HttpServlet是特定于HTTP協議的類,所以 HttpServlet中實現了service()方法,并將請求ServletRequest、ServletResponse 強轉為HttpRequest 和 HttpResponse。
11.OOA、OOD、OOP含義
Object-Oriented Analysis:面向對象分析方法
Object-Oriented Design:面向對象設計
Object Oriented Programming:面向對象編程
OOA是對系統業務調查了解之后根據面向對象的思想進行系統分析,在OOA分析的基礎上對系統根據面向對象的思想進行系統設計,從而能夠直接進行OOP面向對象編程。
12.mysql分頁查詢
對于有大數據量的mysql表來說,使用LIMIT分頁存在很嚴重的性能問題。
查詢從第1000000之后的30條記錄:
SQL代碼1:平均用時6.6秒 SELECT * FROM `cdb_posts` ORDER BY pid LIMIT 1000000 , 30
SQL代碼2:平均用時0.6秒 SELECT * FROM `cdb_posts` WHERE pid >= (SELECT pid FROM `cdb_posts` ORDER BY pid LIMIT 1000000 , 1) LIMIT 30
因為要取出所有字段內容,第一種需要跨越大量數據塊并取出,而第二種基本通過直接根據索引字段定位后,才取出相應內容,效率自然大大提升。
可以看出,越往后分頁,LIMIT語句的偏移量就會越大,兩者速度差距也會越明顯。
實際應用中,可以利用類似策略模式的方式去處理分頁,比如判斷如果是一百頁以內,就使用最基本的分頁方式,大于一百頁,則使用子查詢的分頁方式。
Oracle查詢:SELECT * FROM (SELECT A.*, ROWNUM RN FROM (SELECT * FROM TABLE_NAME) A WHERE ROWNUM <= 40) WHERE RN >= 21
13.單例模式、工廠模式、代理模式
枚舉實現單例模式:
public enum Singleton {
/**
* 定義一個枚舉的元素,它就代表了Singleton的一個實例。
*/
uniqueInstance;
/**
* 單例可以有自己的操作
*/
public void singletonOperation(){
//功能處理
}
}
懶漢同步單例模式:
public class LazySingleton { private static LazySingleton instance = null;
/**
* 私有默認構造子
*/
private LazySingleton(){} /**
* 靜態工廠方法
*/
public static synchronized LazySingleton getInstance(){ if(instance == null){ instance = new LazySingleton();
}
return instance;
}
}
工廠模式:http://www.cnblogs.com/java-my-life/archive/2012/03/28/2418836.html
代理模式:http://yangguangfu.iteye.com/blog/815787
未完待續...
Collections.sort(List<T>, Comparator < ? super T > c)方法用于對象集合按用戶自定義規則排序。
Comparable用在對象本身,說明這個對象是可以被比較的,也就是說可以被排序的。(String和Integer之所以可以比較大小,是因為它們都實現了Comparable接口,并實現了compareTo()方法)。
Compator用在對象外,相當于定義了一個排序算法。
還是代碼來的直接:
package com.zx.ww.comparable;
import java.util.Arrays;
import java.util.Comparator;
public class ComparatorTest {
public static void main(String[] args) {
Dog d1 = new Dog(2);
Dog d2 = new Dog(1);
Dog d3 = new Dog(3);
Dog[] dogArray = {d1, d2, d3};
printDogs(dogArray);
Arrays.sort(dogArray, new DogSizeComparator());
printDogs(dogArray);
}
public static void printDogs(Dog[] dogArray) {
for (Dog dog : dogArray) {
System.out.print(dog.size+" ");
}
System.out.println();
}
}
class Dog{
int size;
public Dog(int size) {
this.size = size;
}
}
class DogSizeComparator implements Comparator<Dog> {
@Override
public int compare(Dog dog1, Dog dog2) {
// TODO Auto-generated method stub
return dog1.size - dog2.size;
}
}
輸出結果:
2 1 3
1 2 3
這是對象數組用了Comparator的結果。
下面看對象自身實現了Comparable接口的方式:
/**
*
*/
package com.zx.ww.comparable;
import java.util.Arrays;
/**
* @author wuwei
* 2014年9月29日
*/
public class User implements Comparable<Object>{
private int id;
private String name;
private int age;
public User(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Object o) {
// TODO Auto-generated method stub
return this.age - ((User)o).getAge();
}
public static void main(String[] args) {
User[] users = new User[] {new User(1,"zhangsan",28), new User(2,"lisi",25)};
Arrays.sort(users);
for (int i = 0; i < users.length; i++) {
User user = users[i];
System.out.println(user.getId()+" "+user.getAge());
}
}
}
輸出結果:
2 25
1 28
上述都是Arrays.sort()的應用方式,同理Collections.sort()一樣的實現,代碼如下,比較簡單:
package com.zx.ww.comparable;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class CollectionSortTest {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("ac");
list.add("ab");
list.add("aa");
list.add("db");
list.add("ca");
for (String string : list) {
System.out.print(string + " ");
}
System.out.println();
Collections.sort(list);
for (String string : list) {
System.out.print(string + " ");
}
System.out.println();
//對象A自身實現Comparable接口
List<A> aList = new ArrayList<A>();
aList.add(new A("wuwei", 1));
aList.add(new A("zhangsan", 3));
aList.add(new A("lisi", 2));
for (A a : aList) {
System.out.print(a+" ");
}
System.out.println();
Collections.sort(aList);
for (A a : aList) {
System.out.print(a+" ");
}
System.out.println();
//重寫Conparator接口方法
List<B> bList = new ArrayList<B>();
bList.add(new B("wuwei", 1));
bList.add(new B("zhangsan", 3));
bList.add(new B("lisi", 2));
for (B b : bList) {
System.out.print(b+" ");
}
System.out.println();
Collections.sort(bList, new Comparator<B>() {
@Override
public int compare(B b1, B b2) {
// TODO Auto-generated method stub
return b1.getCount().compareTo(b2.getCount());
}
});
for (B b : bList) {
System.out.print(b+" ");
}
System.out.println();
}
}
//對象A自身實現Comparable接口
class A implements Comparable<A>{
private String name;
private Integer order;
public A(String name, Integer order) {
this.name = name;
this.order = order;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getOrder() {
return order;
}
public void setOrder(Integer order) {
this.order = order;
}
public String toString() {
return "name is " +name+" order is "+order;
}
@Override
public int compareTo(A o) {
// TODO Auto-generated method stub
return this.order.compareTo(o.getOrder());
}
}
class B{
private String name;
private Integer count;
public B(String name, Integer count) {
this.name = name;
this.count = count;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getCount() {
return count;
}
public void setCount(Integer count) {
this.count = count;
}
public String toString() {
return "name is "+name+" count is "+count;
}
}
輸出結果:
ac ab aa db ca
aa ab ac ca db
name is wuwei order is 1 name is zhangsan order is 3 name is lisi order is 2
name is wuwei order is 1 name is lisi order is 2 name is zhangsan order is 3
name is wuwei count is 1 name is zhangsan count is 3 name is lisi count is 2
name is wuwei count is 1 name is lisi count is 2 name is zhangsan count is 3