前言
學習一個知識之前,我覺得比較好的方式是先理解它的來龍去脈:即這個知識產生的過程,它解決了什么問題,它是怎么樣解決的,還有它引入了哪些新的問題(沒有銀彈),這樣我們才能比較好的抓到它的脈絡和關鍵點,不會一開始就迷失在細節中。
所以,在學習分布式系統之前,我們需要解決的第一個問題是:分布式系統解決了什么問題?
分布式系統解決了什么問題?
第一個是單機性能瓶頸導致的成本問題,由于摩爾定律失效,廉價 PC 機性能的瓶頸無法繼續突破,小型機和大型機能提高更高的單機性能,但是成本太大高,一般的公司很難承受;
第二個是用戶量和數據量爆炸性的增大導致的成本問題,進入互聯網時代,用戶量爆炸性的增大,用戶產生的數據量也在爆炸性的增大,但是單個用戶或者單條數據的價值其實比軟件時代(比如銀行用戶)的價值是只低不高,所以必須尋找更經濟的方案;
第三個是業務高可用的要求,對于互聯網的產品來說,都要求 7 * 24 小時提供服務,無法容忍停止服務等故障,而要提供高可用的服務,唯一的方式就是增加冗余來完成,這樣就算單機系統可以支撐的服務,因為高可用的要求,也會變成一個分布式系統。
基于上面的三個原因可以看出,在互聯網時代,單機系統是無法解決成本和高可用問題的,但是這兩個問題對幾乎對所有的公司來說都是非常關鍵的問題,所以,從單機系統到分布式系統是無法避免的技術大潮流。
分布式系統是怎么來解決問題的?
那么,分布式系統是怎么來解決單機系統面臨的成本和高可用問題呢?
其實思路很簡單,就是將一些廉價的 PC 機通過網絡連接起來,共同完成工作,并且在系統中提供冗余來解決高可用的問題。
分布式系統引入了哪些新的問題?
我們來看分布式系統的定義:分布式系統是由一組通過網絡進行通信、為了完成共同的任務而協調工作的計算機節點組成的系統。在定義中,我們可用看出,分布式系統它通過多工作節點來解決單機系統面臨的成本和可用性問題,但是它引入了對分布式系統內部工作節點的協調問題。
我們經常說掌握一個知識需要理解它的前因后果,對于分布式系統來說,前因是「分布式系統解決了什么問題」,后果是「它是怎么做內部工作節點的協調」,所以我們要解決的第二個問題是:分布式系統是怎么做內部工作節點協調的?
分布式計算引入了哪些新的問題?
先從簡單的情況入手,對于分布式計算(無狀態)的情況,系統內部的協調需要做哪些工作:
1.怎么樣找到服務?
在分布式系統內部,會有不同的服務(角色),服務 A 怎么找到服務 B 是需要解決的問題,一般來說服務注冊與發現機制是常用的思路,所以可以了解一下服務注冊發現機制實現原理,并且可以思考服務注冊發現是選擇做成 AP 還是 CP 系統更合理(嚴格按 CAP 理論說,我們目前使用的大部分系統很難滿足 C 或者 A 的,所以這里只是通常意義上的 AP 或者 CP);
2.怎么樣找到實例?
找到服務后,當前的請求應該選擇發往服務的哪一個實例呢?一般來說,如果同一個服務的實例都是完全對等的(無狀態),那么按負載均衡策略來處理就足夠(輪詢、權重、hash、一致性 hash,fair 等各種策略的適用場景);如果同一個服務的實例不是對等的(有狀態),那么需要通過路由服務(元數據服務等)先確定當前要訪問的請求數據做哪一個實例上,然后再進行訪問。
3.怎么樣避免雪崩?
系統雪崩是指故障的由于正反饋循序導致不斷擴大規則的故障。一次雪崩通常是由于整個系統中一個很小的部分出現故障于引發,進而導致系統其它部分也出現故障。比如系統中某一個服務的一個實例出現故障,導致負載均衡將該實例摘除而引起其它實例負載升高,最終導致該服務的所有實例像多米諾骨牌一樣一個一個全部出現故障。
避免雪崩總體的策略比較簡單,只要是兩個思路,一個是快速失敗和降級機制(熔斷、降級、限流等),通過快速減少系統負載來避免雪崩的發生;另一個為彈性擴容機制,通過快速增加系統的服務能力來避免雪崩的發生。這個根據不同的場景可以做不同的選擇,或者兩個策略都使用。
一般來說,快速失敗會導致部分的請求失敗,如果分布式系統內部對一致性要求很高的話,快速失敗會帶來系統數據不一致的問題,彈性擴容會是一個比較好的選擇,但是彈性擴容的實現成本和響應時間比快速失敗要大得多。
4.怎么樣監控告警?
對于一個分布式系統,如果我們不能很清楚地了解內部的狀態,那么高可用是沒有辦法完全保障的,所以對分布式系統的監控(比如接口的時延和可用性等信息),分布式追蹤 Trace,模擬故障的混沌工程,以及相關的告警等機制是一定要完善的;
分布式存儲引入了哪些新的問題?
接下來我們再來看分布式存儲(有狀態)的內部的協調是怎么做的,同時,前面介紹的分布式計算的協調方式在分布式存儲中同樣適用,就不再重復了:
1.分布式系統的理論與衡權
ACID、BASE 和 CAP 理論,了解這三個主題,推薦這一篇文章以及文章后面相關的參考文獻:
英文版本:https://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed/
中文版本:https://www.infoq.cn/article/cap-twelve-years-later-how-the-rules-have-changed/
2.怎么樣做數據分片?
單機的存儲能力是不可能存儲所有的數據的,所以需要解決怎么將數據按一定的規則分別存儲到不同的機器上,目前使用比較多的方案為:Hash、Consistent Hash 和 Range Based 分片策略,可以了解一下它們的優缺點和各自的應用場景;
3.怎么樣做數據復制?
為什么滿足系統的高可用要求,需要對數據做冗余處理,目前的方案主要為:中心化方案(主從復制、一致性協議比如 Raft 和 Paxos 等)和 去中心化的方案(Quorum 和 Vector Clock)了解一下它們的優缺點和各自的應用場景,以及對系統外部表現出來的數據一致性級別(線性一致性、順序一致性、最終一致性等);
4.怎么樣做分布式事務?
對于分布式系統來說,要實現事務,首先需要有對并發事務進行排序的能力,這樣在事務沖突的時候,確認哪個事務提供成功,哪個事務提交失敗。對于單機系統來說這個完全不是問題,簡單通過時間戳加序號的方式就可以實現,但是對于分布式系統來說,系統中機器的時間不能完全同步,并且單臺機器序號也沒用全局意義,按上面的方式說行不通的。不過整個系統選一臺機器按單機的模式生產事務 ID 是可以的,同城多中心和短距離的異地多中心都沒有問題,不過想做成全球分布式系統的話,那么每一次事務都要去一個節點去獲取事務 ID 的成本太高(比如中國杭州到美國東部的 RTT 為 200 + ms ),Google 的 Spanner 是通過 GPS 和原子鐘實現 TrueTime API 來解決這個問題從而實現全球分布式數據庫的。
有了事務 ID 后,通過 2PC 或者 3PC 協議來實現分布式事務的原子性,其他部分和單機事務差別不大,就不再細說來。
進階學習階段
到這里,對分布式系統脈絡上有了基本的概念,接下來開始進入細節學習階段,這也是非常幸苦的階段,對于分布式系統的理解深入與否,對細節的深入度是很重要的評價指標,畢竟魔鬼在細節。這里可以往兩個方面進行系統的學習:
1.從實踐出發
研究目前比較常用的分布式系統的設計,HDFS 或者 GFS(分布式文件系統)、Kafka 和 Pulsar(分布式消息隊列),Redis Cluster 和 Codis(分布式緩存),MySQL 的分庫分表(傳統關系型數據庫的分布式方案),MongoDB 的 Replica Set 和 Sharing 機制集以及去中心化的 Cassandra(NoSQL 數據庫),中心化的 TiDB 和去中心化的 CockroachDB(NewSQL),以及一些微服務框架等;
2.從理論出發
從理論出發,研究分布式相關的論文,這里推薦一本書「Designing Data-Intensive Applications」(中文版本:數據密集型應用系統設計),先整體看書,對比較感興趣的章節,再讀一讀該章節中涉及到的相關參考文獻。
總結
本文從分布式系統解決的問題開始,再討論它是怎么樣來解決問題的,最后討論了它引入了哪些新的問題,并且討論這些新問題的解決辦法,這個就是分布式系統大概的知識脈絡。掌握這個知識脈絡后,那么就可以從實踐和理論兩個角度結合起來深入細節研究分布式系統了。
參考
Martin Kleppmann.Designing Data-Intensive Applications
CAP Twelve Years Later: How the “Rules” Have Changed
]]>
]]>
隨著紫光展銳、ASR 等芯片廠商發布性價比更高的 Cat.1 芯片之后,Cat.1 模組廠商扎堆發布了自家的模組,
使得市場上的 Cat.1 模組價格已經迅速降至 45-60 元,玩家眾多,競爭慘烈,基本重走 NB-IOT 的老路 —— 量未起,價已跌。
Cat.1 芯片原廠:
高通 MDM9207-1(2016 年發布)
紫光展銳春藤 8910DM(28nm工藝,集成藍牙和WiFi 室內定位)
翱捷 ASR3601
Cat.1 模組廠商(不完全統計):
中移物聯網
移遠通信
合宙電子
移柯通信
域格信息
廣和通
芯訊通
高新興物聯
美格智能
有方科技
有人信息
信位通訊
銳騏(廈門)電子
深圳信可通訊
Cat.1 優勢
相對 NB-IOT,其通信速率優勢明顯
相對 eMTC,其網絡成本低
相對 Cat.4,其具有一定的成本優勢
Cat.1 劣勢:
現階段芯片廠家少
國外以高通為主,輔以 Sequans、Altair。
國內主要是展銳和翱捷。
現階段價格偏高
NB-IoT、Cat.1、Cat.4 模組價格:
cat1 的主要市場和應用場景:
Cat.1 仍處于商用初期,落地的應用場景和案例還較少,一些明確的場景包括了共享、金融支付、工業控制、車載支付、公網對講、POS 等等。
總結
工信部辦公廳發布了《關于深入推進移動物聯網全面發展的通知》(以下簡稱《通知》)同時為 NB-IOT 和 Cat.1 站臺,未來 NB-IOT 依舊很香,Cat.1 則前途大好。
隨著新基建的啟動,5G 打頭,未來將是 NB-IOT、4G(包括 Cat.1)、5G 共同承載蜂窩物聯網的連接,以應對不同層次的物聯網業務需求。
]]>
背景
QoS 等級 與 通信的流程有關,直接影響了整個通信。而且篇幅比較長,所以我覺得應該單獨拎出來講一下。
概念
QoS 代表了 服務質量等級。 設置上,由2 位 的二進制控制,且值不允許為 3(0x11)。
| QoS值 | Bit 2 | Bit 1 | 描述 |
|---|---|---|---|
| 0 | 0 | 0 | 最多分發一次 |
| 1 | 0 | 1 | 至少分發一次 |
| 2 | 1 | 0 | 只分發一次 |
| - | 1 | 1 | 保留位 |
要注意的是,QoS 是 Sender 和 Receiver 之間達成的協議,不是 Publisher 和 Subscriber 之間達成的協議。
也就是說
Publisher發布一條 QoS1 的消息,只能保證Broker能至少收到一次這個消息;至于對應的Subscriber能否至少收到一次這個消息,還要取決于Subscriber在Subscribe的時候和Broker協商的 QoS 等級。這里又牽扯出一個概念:"QoS 降級":在 MQTT 協議中,從 Broker 到 Subscriber 這段消息傳遞的實際 QoS 等于 "Publisher 發布消息時指定的 QoS 等級和 Subscriber 在訂閱時與 Broker 協商的 QoS 等級,這兩個 QoS 等級中的最小那一個。"
QoS 0 的通信時序圖
此時,整個過程中的 Sender 不關心 Receiver 是否收到消息,它"盡力"發完消息,至于是否有人收到,它不在乎。
QoS1 的通信時序圖
此時,Sender 發送的一條消息,Receiver 至少能收到一次,也就是說 Sender 向 Receiver 發送消息,如果發送失敗,會繼續重試,直到 Receiver 收到消息為止,但是因為重傳的原因,Receiver 有可能會收到重復的消息;
1)Sender 向 Receiver 發送一個帶有消息數據的 PUBLISH 包, 并在本地保存這個 PUBLISH 包。
2)Receiver 收到 PUBLISH 包以后,向 Sender 發送一個 PUBACK 數據包,PUBACK 數據包沒有消息體(Payload),在可變頭中(Variable header)中有一個包標識(Packet Identifier),和它收到的 PUBLISH 包中的 Packet Identifier 一致。
3)Sender 收到 PUBACK 之后,根據 PUBACK 包中的 Packet Identifier 找到本地保存的 PUBLISH 包,然后丟棄掉,一次消息的發送完成。
4)如果 Sender 在一段時間內沒有收到 PUBLISH 包對應的 PUBACK,它將該 PUBLISH 包的 DUP 標識設為 1(代表是重新發送的 PUBLISH 包),然后重新發送該 PUBLISH 包。重復這個流程,直到收到 PUBACK,然后執行第 3 步。
QoS 2 的通信時序圖
QoS2 不僅要確保 Receiver 能收到 Sender 發送的消息,還要保證消息不重復。它的重傳和應答機制就要復雜一些,同時開銷也是最大的。
Sender 發送的一條消息,Receiver 確保能收到而且只收到一次,也就是說 Sender 盡力向 Receiver 發送消息,如果發送失敗,會繼續重試,直到 Receiver 收到消息為止,同時保證 Receiver 不會因為消息重傳而收到重復的消息。
QoS 使用 2 套請求/應答流程(一個 4 段的握手)來確保 Receiver 收到來自 Sender 的消息,且不重復:
1)Sender 發送 QoS 為 2 的 PUBLISH 數據包,數據包 Packet Identifier 為 P,并在本地保存該 PUBLISH 包;
2)Receiver 收到 PUBLISH 數據包以后,在本地保存 PUBLISH 包的 Packet Identifier P,并回復 Sender 一個 PUBREC 數據包,PUBREC 數據包可變頭中的 Packet Identifier 為 P,沒有消息體(Payload);
3)當 Sender 收到 PUBREC,它就可以安全地丟棄掉初始的 Packet Identifier 為 P 的 PUBLISH 數據包,同時保存該 PUBREC 數據包,同時回復 Receiver 一個 PUBREL 數據包,PUBREL 數據包可變頭中的 Packet Identifier 為 P,沒有消息體;如果 Sender 在一定時間內沒有收到 PUBREC,它會把 PUBLISH 包的 DUP 標識設為 1,重新發送該 PUBLISH 數據包(Payload);
4)當 Receiver 收到 PUBREL 數據包,它可以丟棄掉保存的 PUBLISH 包的 Packet Identifier P,并回復 Sender 一個 PUBCOMP 數據包,PUBCOMP 數據包可變頭中的 Packet Identifier 為 P,沒有消息體(Payload);
5)當 Sender 收到 PUBCOMP 包,那么它認為數據包傳輸已完成,它會丟棄掉對應的 PUBREC 包。如果 Sender 在一定時間內沒有收到 PUBCOMP 包,它會重新發送 PUBREL 數據包。
我們可以看到在 QoS2 中,完成一次消息的傳遞,Sender 和 Reciever 之間至少要發送四個數據包,QoS2 是最安全也是最慢的一種 QoS 等級了。
QoS 和會話(Session)
客戶端的會話狀態包括:
- 已經發送給服務端,但是還沒有完成確認的QoS 1和QoS 2級別的消息
- 已從服務端接收,但是還沒有完成確認的QoS 2級別的消息。
服務端的會話狀態包括:
- 會話是否存在,即使會話狀態的其它部分都是空。
- 客戶端的訂閱信息。
- 已經發送給客戶端,但是還沒有完成確認的QoS 1和QoS 2級別的消息。
- 即將傳輸給客戶端的QoS 1和QoS 2級別的消息。
- 已從客戶端接收,但是還沒有完成確認的QoS 2級別的消息。
- 可選,準備發送給客戶端的QoS 0級別的消息。
保留消息不是服務端會話狀態的一部分,會話終止時不能刪除保留消息。
如果 Client 想接收離線消息,必須使用持久化的會話(CONNECT報文中可變頭(byte8[1])Clean Session = 0)連接到 Broker,這樣 Broker 才會存儲 Client 在離線期間沒有確認接收的 QoS 大于 1 的消息。
QoS 等級的選擇
在以下情況下你可以選擇 QoS0:
- Client 和 Broker 之間的網絡連接非常穩定,例如一個通過有線網絡連接到 Broker 的測試用 Client;
- 可以接受丟失部分消息,比如你有一個傳感器以非常短的間隔發布狀態數據,所以丟一些也可以接受;
- 你不需要離線消息。
在以下情況下你應該選擇 QoS1:
- 你需要接收所有的消息,而且你的應用可以接受并處理重復的消息;
- 你無法接受 QoS2 帶來的額外開銷,QoS1 發送消息的速度比 QoS2 快很多。
在以下情況下你應該選擇 QoS2:
- 你的應用必須接收到所有的消息,而且你的應用在重復的消息下無法正常工作,同時你也能接受 QoS2 帶來的額外開銷。
實際上,QoS1 是應用最廣泛的 QoS 等級,QoS1 發送消息的速度很快,而且能夠保證消息的可靠性。雖然使用 QoS1 可能會收到重復的消息,但是在應用程序里面處理重復消息,通常并不是件難事。
]]>
1.網速測試
安裝iperf
yum install epel-release 從epel源中安裝 yum install -y iperf 帶寬檢測
iperf -s 開啟服務端 iperf -c ip 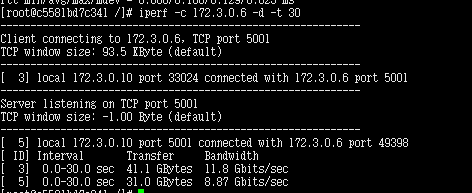
丟包問題
tcpdump進行抓包 tcpdump -i eth0 -s 3000 port 8080 -w /home/tomcat.pcap 對于抓包文件采用wireshark進行分析 丟包(TCP DUP ACK) 重傳(retransmission),超時重傳, 2.cdn性能測試
cdn 緩存,回源問題 304請求,瀏覽器是否使用本地緩存。比較last_modified 和if_modified_since 通過實踐戳來判斷,瀏覽器緩存和cdn緩存 
3.DNS基礎
路由解析
泛域名解析
4.分布式服務鏈路追蹤

http入口產生一個traceId 分發到rpc調用,cache,db,jms調用鏈路中 google的著名論文dapper和zipkin 日志聚合,綁定鏈路日志和業務日志 采樣采集,慢請求,異常服務。 日志量大。日志異步寫入,環狀數組,日志組件自研 共享信息放在ThreadLocal中。比如traceId 5.網卡性能問題定位
tsar -l -i 1 --traffic 查看網卡的進出流量 6.CPU性能問題定位
tsar -l -i 1 --cpu 軟件問題定位,perf 采樣所有進程數據 perf record -F 99 -a -g -- sleep 30 java進程的函數map:java -cp attach-main.jar:$JAVA_HOME/lib/tools.jar net.virtualvoid.perf.AttachOnce PID 輸出函數和地址的map 輸出火焰圖 perf script | stackcollapse-perf.pl | flamegraph.pl --color=java --hash > flamegraph.svg 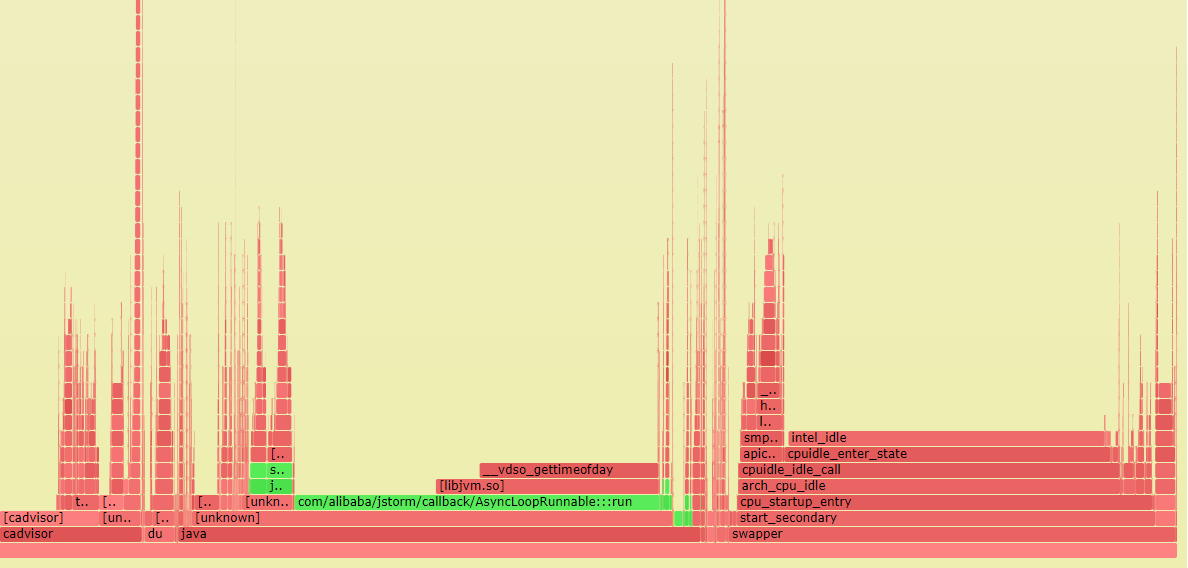
7.內存性能問題定位
-堆內內存問題,
采用jmap dump內存,采用離線工具分析 jprofile、mat -堆外內存問題
a.google-perftools
yum install -y google-perftools graphviz export LD_PRELOAD=/usr/lib64/libtcmalloc.so.4 export HEAPPROFILE=/home/testGperf.prof 執行程序,結束程序,生成prof 分析prof 生成svg, pdf,text pprof --svg $JAVA_HOME/bin/java testGperf.prof.0001.heap > test.svg pprof --pdf $JAVA_HOME/bin/java testGperf.prof.0001.heap > test.pdf pprof --text $JAVA_HOME/bin/java testGperf.prof.0001.heap > test.txt b.jemalloc定位(優勢,適合長時間trace)
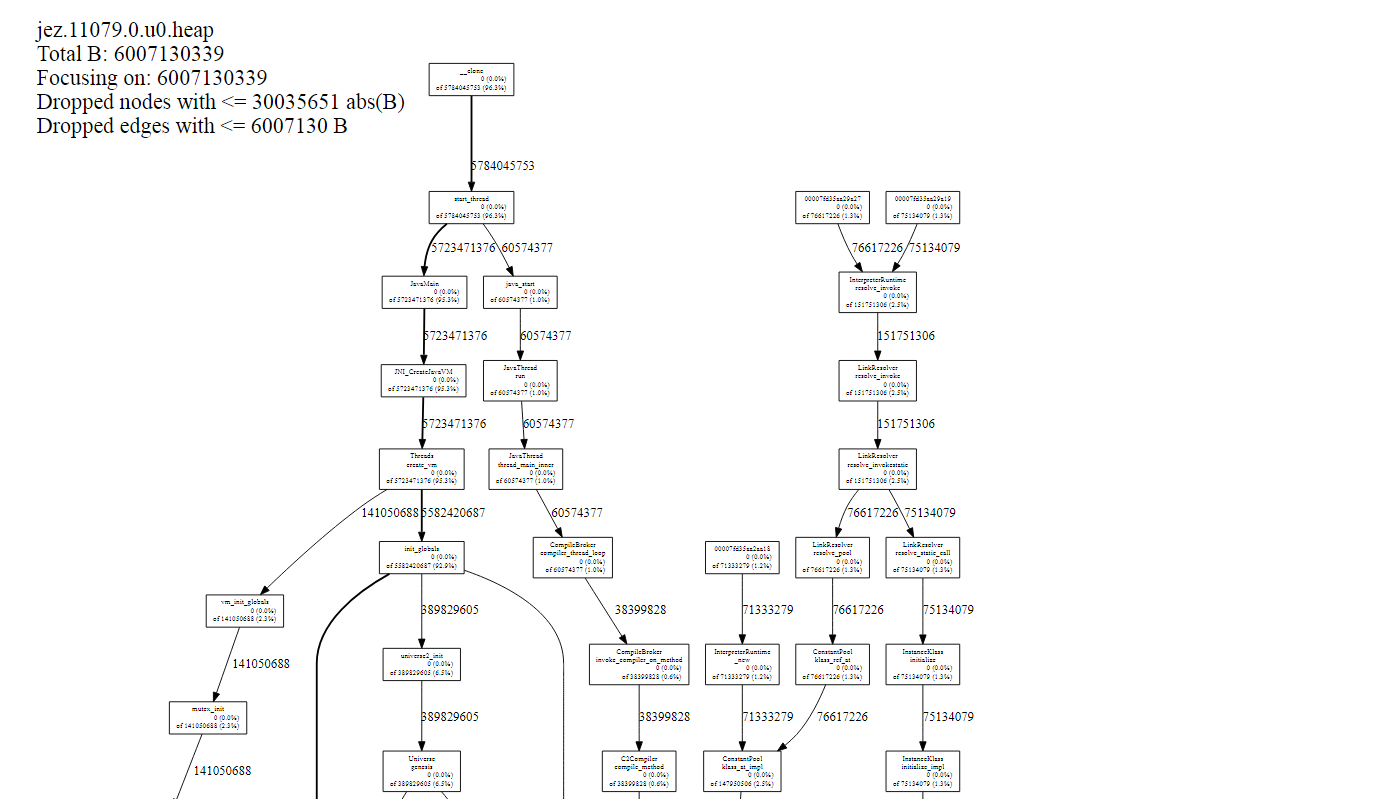
sudo apt-get install graphviz 編譯安裝 ./configure –enable-prof –enable-stats –enable-debug –enable-fill make make install
運行配置 export MALLOC_CONF=”prof:true,prof_gdump:true,prof_prefix:/home/jedump/jez,lg_prof_interval:30,lg_prof_sample:17”
export LD_PRELOAD=/usr/local/lib/libjemalloc.so.2 運行 java -jar target/spring-boot-jemalloc-example-0.0.1-SNAPSHOT.jar
jeprof –show_bytes –svg jez.*.heap > app-profiling.svg
注明:如果在docker容器中,推薦用pprof,jemalloc只顯示函數地址,不顯示函數名
8.機器資源配額問題
/etc/security/limits.conf
- soft nofile 65536
- hard nofile 65536
控制該用戶文件句柄數
9.磁盤性能問題定位
tsar -l -i 1 –io
]]>
]]>
]]>
]]>
]]>
]]>