Suppose n1, n2, …, nk are positive integers which are pairwise coprime. Then, for any given integers a1,a2, …, ak, there exists an integer x solving the system of simultaneous congruences

Furthermore, all solutions x to this system are congruent modulo the product N = n1n2…nk.
Hence  for all
for all  , if and only if
, if and only if  .
.
Sometimes, the simultaneous congruences can be solved even if the ni's are not pairwise coprime. A solution x exists if and only if:

All solutions x are then congruent modulo the least common multiple of the ni.
Versions of the Chinese remainder theorem were also known to Brahmagupta (7th century), and appear in Liber Abaci (1202).
[edit] A constructive algorithm to find the solution
This algorithm only treats the situations where the ni's are coprime. The method of successive substitution can often yield solutions to simultaneous congruences, even when the moduli are not pairwise coprime.
Suppose, as above, that a solution is needed to the system of congruences:

Again, to begin, the product  is defined. Then a solution x can be found as follows.
is defined. Then a solution x can be found as follows.
For each i the integers ni and N / ni are coprime. Using the extended Euclidean algorithm we can therefore find integers ri and si such that rini + siN / ni = 1. Then, choosing the label ei = siN / ni, the above expression becomes:

Consider ei. The above equation guarantees that its remainder, when divided by ni, must be 1. On the other hand, since it is formed as siN / ni, the presence of N guarantees that it's evenly divisible by any nj so long as 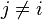 .
.

Because of this, combined with the multiplication rules allowed in congruences, one solution to the system of simultaneous congruences is:

For example, consider the problem of finding an integer x such that



Using the extended Euclidean algorithm for 3 and 4×5 = 20, we find (−13) × 3 + 2 × 20 = 1, i.e. e1 = 40. Using the Euclidean algorithm for 4 and 3×5 = 15, we get (−11) × 4 + 3 × 15 = 1. Hence, e2 = 45. Finally, using the Euclidean algorithm for 5 and 3×4 = 12, we get 5 × 5 + (−2) × 12 = 1, meaning e3 = −24. A solution x is therefore 2 × 40 + 3 × 45 + 1 × (−24) = 191. All other solutions are congruent to 191 modulo 60, (3 × 4 × 5 = 60) which means that they are all congruent to 11 modulo 60.
NOTE: There are multiple implementations of the extended Euclidean algorithm which will yield different sets of e1, e2, and e3. These sets however will produce the same solution i.e. 11 modulo 60.
extended Enclidean algorithm
[edit] Informal formulation of the algorithm
| Dividend | Divisor | Quotient | Remainder |
|---|---|---|---|
| 120 | 23 | 5 | 5 |
| 23 | 5 | 4 | 3 |
| 5 | 3 | 1 | 2 |
| 3 | 2 | 1 | 1 |
| 2 | 1 | 2 | 0 |
It is assumed that the reader is already familiar with .
To illustrate the extension of the Euclid's algorithm, consider the computation of gcd(120, 23), which is shown on the table on the left. Notice that the quotient in each division is recorded as well alongside the remainder.
In this case, the remainder in the fourth line (which is equal to 1) indicates that the gcd is 1; that is, 120 and 23 are coprime (also called relatively prime). For the sake of simplicity, the example chosen is a coprime pair; but the more general case of gcd other than 1 also works similarly.
There are two methods to proceed, both using the division algorithm, which will be discussed separately.
[edit] The iterative method
This method computes expressions of the form ri = axi + byi for the remainder in each step i of the Euclidean algorithm. Each modulus can be written in terms of the previous two remainders and their whole quotient as follows:
By substitution, this gives:
The first two values are the initial arguments to the algorithm:
- r1 = a = a(1) + b(0)
- r2 = b = a(0) + b(1)
The expression for the last non-zero remainder gives the desired results since this method computes every remainder in terms of a and b, as desired.
Example: Compute the GCD of 120 and 23.
The computation proceeds as follows:
| Step | Quotient | Remainder | Substitute | Combine terms | |
|---|---|---|---|---|---|
| 1 | 120 | 120 = 120 * 1 + 23 * 0 | |||
| 2 | 23 | 23 = 120 * 0 + 23 * 1 | |||
| 3 | 5 | 5 = 120 - 23 * 5 | 5 = (120 * 1 + 23 * 0) - (120 * 0 + 23 * 1) * 5 | 5 = 120 * 1 + 23 * -5 | |
| 4 | 4 | 3 = 23 - 5 * 4 | 3 = (120 * 0 + 23 * 1) - (120 * 1 + 23 * -5) * 4 | 3 = 120 * -4 + 23 * 21 | |
| 5 | 1 | 2 = 5 - 3 * 1 | 2 = (120 * 1 + 23 * -5) - (120 * -4 + 23 * 21) * 1 | 2 = 120 * 5 + 23 * -26 | |
| 6 | 1 | 1 = 3 - 2 * 1 | 1 = (120 * -4 + 23 * 21) - (120 * 5 + 23 * -26) * 1 | 1 = 120 * -9 + 23 * 47 | |
| 7 | 2 | 0 | End of algorithm | ||
The last line reads 1 = −9×120 + 47×23, which is the required solution: x = −9 and y = 47.
This also means that −9 is the multiplicative inverse of 120 modulo 23, and that 47 is the multiplicative inverse of 23 modulo 120.
- −9 × 120 ≡ 1 mod 23 and also 47 × 23 ≡ 1 mod 120.
[edit] The recursive method
This method attempts to solve the original equation directly, by reducing the dividend and divisor gradually, from the first line to the last line, which can then be substituted with trivial value and work backward to obtain the solution.
Consider the original equation:
| 120 | x | + | 23 | y | = | 1 |
| (5×23+5) | x | + | 23 | y | = | 1 |
| 23 | (5x+y) | + | 5 | x | = | 1 |
| ... | ||||||
| 1 | a | + | 0 | b | = | 1 |
Notice that the equation remains unchanged after decomposing the original dividend in terms of the divisor plus a remainder, and then regrouping terms. If we have a solution to the equation in the second line, then we can work backward to find x and y as required. Although we don't have the solution yet to the second line, notice how the magnitude of the terms decreased (120 and 23 to 23 and 5). Hence, if we keep applying this, eventually we'll reach the last line, which obviously has (1,0) as a trivial solution. Then we can work backward and gradually find out x and y.
| Dividend | = | Quotient | x | Divisor | + | Remainder |
|---|---|---|---|---|---|---|
| 120 | = | 5 | x | 23 | + | 5 |
| 23 | = | 4 | x | 5 | + | 3 |
| ... | ||||||
For the purpose of explaining this method, the full working will not be shown. Instead some of the repeating steps will be described to demonstrate the principle behind this method.
Start by rewriting each line from the first table with division algorithm, focusing on the dividend this time (because we'll be substituting the dividend).
| 120 | x0 | + | 23 | y0 | = | 1 |
| (5×23+5) | x0 | + | 23 | y0 | = | 1 |
| 23 | (5x0+y0) | + | 5 | x0 | = | 1 |
| 23 | x1 | + | 5 | y1 | = | 1 |
| (4×5+3) | x1 | + | 5 | y1 | = | 1 |
| 5 | (4x1+y1) | + | 3 | x1 | = | 1 |
| 5 | x2 | + | 3 | y2 | = | 1 |
|
[edit] The table method
The table method is probably the simplest method to carry out with a pencil and paper. It is similar to the recursive method, although it does not directly require algebra to use and only requires working in one direction. The main idea is to think of the equation chain as a sequence of divisors . In the running example we have the sequence 120, 23, 5, 3, 2, 1. Any element in this chain can be written as a linear combination of the original x and y, most notably, the last element, gcd(x,y), can be written in this way. The table method involves keeping a table of each divisor, written as a linear combination. The algorithm starts with the table as follows:
| a | b | d |
| 1 | 0 | 120 |
| 0 | 1 | 23 |
The elements in the d column of the table will be the divisors in the sequence. Each di can be represented as the linear combination . The a and b values are obvious for the first two rows of the table, which represent x and y themselves. To compute di for any i > 2, notice that . Suppose . Then it must be that and . This is easy to verify algebraically with a simple substitution.
Actually carrying out the table method though is simpler than the above equations would indicate. To find the third row of the table in the example, just notice that 120 divided by 23 goes 5 times plus a remainder. This gives us k, the multiplying factor for this row. Now, each value in the table is the value two rows above it, minus k times the value immediately above it. This correctly leads to , , and . After repeating this method to find each line of the table (note that the remainder written in the table and the multiplying factor are two different numbers!), the final values for a and b will solve :
| a | b | d |
| 1 | 0 | 120 |
| 0 | 1 | 23 |
| 1 | -5 | 5 |
| -4 | 21 | 3 |
| 5 | -26 | 2 |
| -9 | 47 | 1 |
This method is simple, requiring only the repeated application of one rule, and leaves the answer in the final row of the table with no backtracking. Note also that if you end up with a negative number as the answer for the factor of, in this case b, you will then need to add the modulus in order to make it work as a modular inverse (instead of just taking the absolute value of b). I.e. if it returns a negative number, don't just flip the sign, but add in the other number to make it work. Otherwise it will give you the modular inverse yielding negative one.
еҸӮиҖғи§ЈҪ{?/h3>
еҠЁжҖҒ规еҲ’з®—жі•еҸҜжңүж•Ҳең°и§ЈжӯӨй—®йўҳгҖӮдёӢйқўжҲ‘们жҢүз…§еҠЁжҖҒ规еҲ’з®—жі•и®ҫи®Ўзҡ„еҗ„дёӘжӯҘйӘӨжқҘи®ҫи®ЎдёҖдёӘи§ЈжӯӨй—®йўҳзҡ„жңүж•ҲҪҺ—жі•гҖ?/p>
1.жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зҡ„з»“жһ?/h4>
и§ЈжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—й—®йўҳж—¶жңҖе®ТҺ(guЁ©)ҳ“жғӣ_Ҳ°зҡ„з®—жі•жҳҜҪI·дӢDжҗңзғҰжі•пјҢеҚӣ_Ҝ№Xзҡ„жҜҸдёҖдёӘеӯҗеәҸеҲ—еQҢжЈҖжҹҘе®ғжҳҜеҗҰд№ҹжҳҜYзҡ„еӯҗеәҸеҲ—еQҢд»ҺиҖҢзЎ®е®ҡе®ғжҳҜеҗҰдёәXе’ҢYзҡ„е…¬е…ұеӯҗеәҸеҲ—еQҢеЖҲ дё”еңЁӢӮҖ(gЁЁ)жҹҘиҝҮҪEӢдёӯйҖүеҮәжңҖй•ҝзҡ„е…¬е…ұеӯҗеәҸеҲ—гҖӮXзҡ„жүҖжңүеӯҗеәҸеҲ—йғҪжЈҖжҹҘиҝҮеҗҺеҚіеҸҜжұӮеҮәXе’ҢYзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖӮXзҡ„дёҖдёӘеӯҗеәҸеҲ—зӣёеә”дәҺдёӢж ҮеәҸеҲ—{1, 2, …, m}зҡ„дёҖдёӘеӯҗеәҸеҲ—еQҢеӣ жӯӨпјҢXе…ұжңү2mдёӘдёҚеҗҢеӯҗеәҸеҲ—еQҢд»ҺиҖҢз©·дёҫжҗңзҙўжі•йңҖиҰҒжҢҮж•°ж—¶й—ҙгҖ?/p>
дәӢе®һдёҠпјҢжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—й—®йўҳд№ҹжңүжңҖдјҳеӯҗҫl“жһ„жҖ§иҙЁеQҢеӣ дёәжҲ‘们жңүеҰӮдёӢе®ҡзҗҶеQ?/p>
е®ҡзҗҶ: LCSзҡ„жңҖдјҳеӯҗҫl“жһ„жҖ§иҙЁ
и®‘ЦәҸеҲ—X=<x1, x2, …, xm>е’ҢY=<y1, y2, …, yn>зҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—Z=<z1, z2, …, zk>еQҢеҲҷеQ?/p>
- иӢҘxm=ynеQҢеҲҷzk=xm=ynдё”Zk-1жҳҜXm-1е’ҢYn-1зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—еQ?
- иӢҘxm≠ynдё”zk≠xm еQ?/sub>еҲҷZжҳҜXm-1е’ҢYзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—еQ?
- иӢҘxm≠ynдё”zk≠yn еQҢеҲҷZжҳҜXе’ҢYn-1зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖ?
е…¶дёӯXm-1=<x1, x2, …, xm-1>еQҢYn-1=<y1, y2, …, yn-1>еQҢZk-1=<z1, z2, …, zk-1>гҖ?/p>
иҜҒжҳҺ
- з”ЁеҸҚиҜҒжі•гҖӮиӢҘzk≠xmеQҢеҲҷ<z1, z2, …, zk ,xm >жҳҜXе’ҢYзҡ„й•ҝеәҰдШ“(fЁҙ)kеҚ?зҡ„е…¬е…ұеӯҗеәҸеҲ—гҖӮиҝҷдёҺZжҳҜXе’ҢYзҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зҹӣзӣҫгҖӮеӣ жӯӨпјҢеҝ…жңүzk=xm=ynгҖӮз”ұжӯӨеҸҜзҹҘZk-1жҳҜXm-1е’ҢYn-1зҡ„дёҖдёӘй•ҝеәҰдШ“(fЁҙ)k-1зҡ„е…¬е…ұеӯҗеәҸеҲ—гҖӮиӢҘXm-1е’ҢYn-1жңүдёҖдёӘй•ҝеәҰеӨ§дәҺk-1зҡ„е…¬е…ұеӯҗеәҸеҲ—WеQҢеҲҷһ®ҶxmеҠ еңЁе…¶е°ҫйғЁе°Ҷдә§з”ҹXе’ҢYзҡ„дёҖдёӘй•ҝеәҰеӨ§дәҺkзҡ„е…¬е…ұеӯҗеәҸеҲ—гҖӮжӯӨдёәзҹӣзӣҫгҖӮж•…Zk-1жҳҜXm-1е’ҢYn-1зҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖ?
- з”ЧғәҺzk≠xmеQҢZжҳҜXm-1е’ҢYзҡ„дёҖдёӘе…¬е…ұеӯҗеәҸеҲ—гҖӮиӢҘXm-1е’ҢYжңүдёҖдёӘй•ҝеәҰеӨ§дәҺkзҡ„е…¬е…ұеӯҗеәҸеҲ—WеQҢеҲҷWд№ҹжҳҜXе’ҢYзҡ„дёҖдёӘй•ҝеәҰеӨ§дәҺkзҡ„е…¬е…ұеӯҗеәҸеҲ—гҖӮиҝҷдёҺZжҳҜXе’ҢYзҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зҹӣзӣҫгҖӮз”ұжӯӨеҚізҹҘZжҳҜXm-1е’ҢYзҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖ?
- дё?2.ҫcЦMјјгҖ?
ҳqҷдёӘе®ҡзҗҶе‘ҠиҜүжҲ‘们еQҢдёӨдёӘеәҸеҲ—зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—еҢ…еҗ«дәҶиҝҷдёӨдёӘеәҸеҲ—зҡ„еүҚҫ~Җзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖӮеӣ жӯӨпјҢжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—й—®йўҳе…дhңүжңҖдјҳеӯҗҫl“жһ„жҖ§иҙЁгҖ?/p>
2.еӯҗй—®йўҳзҡ„йҖ’еҪ’ҫl“жһ„
з”ұжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—й—®йўҳзҡ„жңҖдјҳеӯҗҫl“жһ„жҖ§иҙЁеҸҜзҹҘеQҢиҰҒжү‘ЦҮәX=<x1, x2, …, xm>е’ҢY=<y1, y2, …, yn>зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—еQҢеҸҜжҢүд»ҘдёӢж–№ејҸйҖ’еҪ’ең°иҝӣиЎҢпјҡ(xЁ¬)еҪ“xm=ynж—УһјҢжү‘ЦҮәXm-1е’ҢYn-1зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—еQҢ然еҗҺеңЁе…¶е°ҫйғЁеҠ дёҠxm(=yn)еҚӣ_ҸҜеҫ—Xе’ҢYзҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖӮеҪ“xm≠ynж—УһјҢеҝ…йЎ»и§ЈдёӨдёӘеӯҗй—®йўҳеQҢеҚіжү‘ЦҮәXm-1е’ҢYзҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—еҸ?qiЁўng)Xе’ҢYn-1зҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖӮиҝҷдёӨдёӘе…¬е…ұеӯҗеәҸеҲ—дёӯиҫғй•ҝиҖ…еҚідёәXе’ҢYзҡ„дёҖдёӘжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖ?/p>
з”ұжӯӨйҖ’еҪ’ҫl“жһ„е®ТҺ(guЁ©)ҳ“зңӢеҲ°жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—й—®йўҳе…дhңүеӯҗй—®йўҳйҮҚеҸ жҖ§иҙЁгҖӮдҫӢеҰӮпјҢеңЁи®ЎҪҺ—Xе’ҢYзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—ж—УһјҢеҸҜиғҪиҰҒи®ЎҪҺ—еҮәXе’ҢYn-1еҸ?qiЁўng)Xm-1е’ҢYзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖӮиҖҢиҝҷдёӨдёӘеӯҗй—®йўҳйғҪеҢ…еҗ«дёҖдёӘе…¬е…ұеӯҗй—®йўҳеQҢеҚіи®Ўз®—Xm-1е’ҢYn-1зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖ?/p>
дёҺзҹ©йҳөиҝһд№ҳз§ҜжңҖдјҳи®ЎҪҺ—ж¬ЎеәҸй—®йўҳзұ»дјы|јҢжҲ‘们жқҘеҫҸз«Ӣеӯҗй—®йўҳзҡ„жңҖдјҳеҖјзҡ„йҖ’еҪ’е…ізі»гҖӮз”Ёc[i,j]и®°еҪ•еәҸеҲ—Xiе’ҢYjзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зҡ„й•ҝеәҰгҖӮе…¶дёӯXi=<x1, x2, …, xi>еQҢYj=<y1, y2, …, yj>гҖӮеҪ“i=0жҲ–j=0ж—УһјҢҪIәеәҸеҲ—жҳҜXiе’ҢYjзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—еQҢж•…c[i,j]=0гҖӮе…¶д»–жғ…еҶөдёӢеQҢз”ұе®ҡзҗҶеҸҜеҫҸз«ӢйҖ’еҪ’е…ізі»еҰӮдёӢеQ?/p>

3.и®Ўз®—жңҖдјҳеҖ?/h4>
зӣҙжҺҘеҲ©з”Ё(2.2)ејҸе®№жҳ“еҶҷеҮЮZёҖдёӘи®ЎҪҺ—c[i,j]зҡ„йҖ’еҪ’ҪҺ—жі•еQҢдҪҶе…¶и®ЎҪҺ—ж—¶й—ҙжҳҜйҡҸиҫ“е…Ҙй•ҝеәҰжҢҮж•°еўһй•ҝзҡ„гҖӮз”ұдәҺеңЁжүҖиҖғиҷ‘зҡ„еӯҗй—®йўҳҪIәй—ҙдёӯпјҢжҖХd…ұеҸӘжңүθ(m*n)дёӘдёҚеҗҢзҡ„еӯҗй—®йўҳпјҢеӣ жӯӨеQҢз”ЁеҠЁжҖҒ规еҲ’з®—жі•иҮӘеә•еҗ‘дёҠең°и®Ўз®—жңҖдјҳеҖЖDғҪжҸҗй«ҳҪҺ—жі•зҡ„ж•ҲзҺҮгҖ?/p>
и®Ўз®—жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—й•ҝеәҰзҡ„еҠЁжҖҒ规еҲ’з®—жі•LCS_LENGTH(X,Y)д»ҘеәҸеҲ—X=<x1, x2, …, xm>е’ҢY=<y1, y2, …, yn>дҪңдШ“(fЁҙ)иҫ“е…ҘгҖӮиҫ“еҮЮZёӨдёӘж•°ҫl„c[0..m ,0..n]е’Ңb[1..m ,1..n]гҖӮе…¶дёӯc[i,j]еӯҳеӮЁXiдёҺYjзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зҡ„й•ҝеәҰпјҢb[i,j]и®°еҪ•жҢҮзӨәc[i,j]зҡ„еҖјжҳҜз”ұе“ӘдёҖдёӘеӯҗй—®йўҳзҡ„и§Јиҫ‘ЦҲ°зҡ„пјҢҳqҷеңЁжһ„йҖ жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—ж—¶иҰҒз”ЁеҲ°гҖӮжңҖеҗҺпјҢXе’ҢYзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зҡ„й•ҝеәҰи®°еҪ•дәҺc[m,n]дёӯгҖ?/p>
Procedure LCS_LENGTH(X,Y);
begin
m:=length[X];
n:=length[Y];
for i:=1 to m do c[i,j]:=0;
for j:=1 to n do c[0,j]:=0;
for i:=1 to m do
for j:=1 to n do
if x[i]=y[j] then
begin
c[i,j]:=c[i-1,j-1]+1;
b[i,j]:="вҶ?;
end
else if c[i-1,j]≥c[i,j-1] then
begin
c[i,j]:=c[i-1,j];
b[i,j]:="↑";
end
else
begin
c[i,j]:=c[i,j-1];
b[i,j]:="←"
end;
return(c,b);
end;
з”ЧғәҺжҜҸдёӘж•°з»„еҚ•е…ғзҡ„и®ЎҪҺ—иҖ—иҙ№Ο(1)ж—үҷ—ҙеQҢз®—жі•LCS_LENGTHиҖ—ж—¶Ο(mn)гҖ?/p>
4.жһ„йҖ жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—
з”Юq®—жі•LCS_LENGTHи®Ўз®—еҫ—еҲ°зҡ„ж•°ҫl„bеҸҜз”ЁдәҺеҝ«йҖҹжһ„йҖ еәҸеҲ—X=<x1, x2, …, xm>е’ҢY=<y1, y2, …, yn>зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖӮйҰ–е…Ҳд»Һb[m,n]ејҖе§ӢпјҢжІҝзқҖе…¶дёӯзҡ„з®ӯеӨҙжүҖжҢҮзҡ„ж–№еҗ‘еңЁж•°ҫl„bдёӯжҗңзҙўгҖӮеҪ“b[i,j]дёӯйҒҮеҲ?вҶ?ж—УһјҢиЎЁзӨәXiдёҺYjзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—жҳҜз”ұXi-1дёҺYj-1зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—еңЁе°ҫйғЁеҠ дёҠxiеҫ—еҲ°зҡ„еӯҗеәҸеҲ—еQӣеҪ“b[i,j]дёӯйҒҮеҲ?↑"ж—УһјҢиЎЁзӨәXiдёҺYjзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—е’ҢXi-1дёҺYjзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зӣёеҗҢеQӣеҪ“b[i,j]дёӯйҒҮеҲ?←"ж—УһјҢиЎЁзӨәXiдёҺYjзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—е’ҢXiдёҺYj-1зҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зӣёеҗҢгҖ?/p>
дёӢйқўзҡ„з®—жі•LCS(b,X,i,j)е®һзҺ°ж ТҺ(guЁ©)Қ®bзҡ„еҶ…е®ТҺ(guЁ©)ү“еҚ°еҮәXiдёҺYjзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖӮйҖҡиҝҮҪҺ—жі•зҡ„и°ғз”ЁLCS(b,X,length[X],length[Y])еQҢдҫҝеҸҜжү“еҚ°еҮәеәҸеҲ—Xе’ҢYзҡ„жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—гҖ?/p>
Procedure LCS(b,X,i,j);
begin
if i=0 or j=0 then return;
if b[i,j]="вҶ? then
begin
LCS(b,X,i-1,j-1);
print(x[i]); {жү“еҚ°x[i]}
end
else if b[i,j]="↑" then LCS(b,X,i-1,j)
else LCS(b,X,i,j-1);
end;
еңЁз®—жі•LCSдёӯпјҢжҜҸдёҖӢЖЎзҡ„йҖ’еҪ’и°ғз”ЁдҪҝiжҲ–jеҮ?еQҢеӣ жӯӨз®—жі•зҡ„и®Ўз®—ж—үҷ—ҙдё?em>O(m+n)гҖ?/p>
дҫӢеҰӮеQҢи®ҫжүҖҫlҷзҡ„дёӨдёӘеәҸеҲ—дёәX=<AеQҢBеQҢCеQҢBеQҢDеQҢAеQҢB>е’ҢY=<BеQҢDеQҢCеQҢAеQҢBеQҢA>гҖӮз”ұҪҺ—жі•LCS_LENGTHе’ҢLCSи®Ўз®—еҮәзҡ„ҫl“жһңеҰӮеӣҫ2жүҖҪCәгҖ?/p>
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | |||||||||
| i | yj | B | D | C | A | B | A | |||||||||
| в”?/td> | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”?/td> | ||
| 0 | xi | в”?/td> | 0 | 0 | 0 | 0 | 0 | 0 | в”?/td> | |||||||
| в”?/td> | ↑ | ↑ | ↑ | вҶ?/td> | вҶ?/td> | в”?/td> | ||||||||||
| 1 | A | в”?/td> | 0 | 0 | 0 | 0 | 1 | ← | 1 | 1 | в”?/td> | |||||
| в”?/td> | вҶ?/td> | ↑ | вҶ?/td> | в”?/td> | ||||||||||||
| 2 | B | в”?/td> | 0 | 1 | ← | 1 | ← | 1 | 1 | 2 | ← | 2 | в”?/td> | |||
| в”?/td> | ↑ | ↑ | вҶ?/td> | ↑ | ↑ | в”?/td> | ||||||||||
| 3 | C | в”?/td> | 0 | 1 | 1 | 2 | ← | 2 | 2 | 2 | в”?/td> | |||||
| в”?/td> | вҶ?/td> | ↑ | ↑ | ↑ | вҶ?/td> | в”?/td> | ||||||||||
| 4 | B | в”?/td> | 0 | 1 | 1 | 2 | 2 | 3 | ← | 3 | в”?/td> | |||||
| в”?/td> | ↑ | вҶ?/td> | ↑ | ↑ | ↑ | ↑ | в”?/td> | |||||||||
| 5 | D | в”?/td> | 0 | 1 | 2 | 2 | 2 | 3 | 3 | в”?/td> | ||||||
| в”?/td> | ↑ | ↑ | ↑ | вҶ?/td> | ↑ | вҶ?/td> | в”?/td> | |||||||||
| 6 | A | в”?/td> | 0 | 1 | 2 | 2 | 3 | 3 | 4 | в”?/td> | ||||||
| в”?/td> | вҶ?/td> | ↑ | ↑ | ↑ | вҶ?/td> | ↑ | в”?/td> | |||||||||
| 7 | B | в”?/td> | 0 | 1 | 2 | 2 | 3 | 4 | 5 | в”?/td> | ||||||
| в”?/td> | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”Җ | в”?/td> |
еӣ? ҪҺ—жі•LCSзҡ„и®ЎҪҺ—з»“жһ?/font>
5.ҪҺ—жі•зҡ„ж”№ҳq?/h4>
еҜ№дәҺдёҖдёӘе…·дҪ“й—®йўҳпјҢжҢүз…§дёҖиҲ¬зҡ„ҪҺ—жі•и®ҫи®ЎҪ{–з•Ҙи®ҫи®ЎеҮәзҡ„ҪҺ—жі•еQҢеҫҖеҫҖеңЁз®—жі•зҡ„ж—үҷ—ҙе’Ңз©әй—ҙйңҖжұӮдёҠҳqҳеҸҜд»Ҙж”№ҳqӣгҖӮиҝҷҝUҚж”№ҳqӣпјҢйҖҡеёёжҳҜеҲ©з”Ёе…·дҪ“й—®йўҳзҡ„дёҖдәӣзү№ҢDҠжҖ§гҖ?/p>
дҫӢеҰӮеQҢеңЁҪҺ—жі•LCS_LENGTHе’ҢLCSдёӯпјҢеҸҜиҝӣдёҖжӯҘе°Ҷж•°з»„bзңҒеҺ»гҖӮдәӢе®һдёҠеQҢж•°ҫl„е…ғзҙ c[i,j]зҡ„еҖйg»…з”ұc[i-1,j-1]еQҢc[i-1, j]е’Ңc[i,j-1]дёүдёӘеҖйg№ӢдёҖјӢ®е®ҡеQҢиҖҢж•°ҫl„е…ғзҙ b[i,j]д№ҹеҸӘжҳҜз”ЁжқҘжҢҮҪCәc[i,j]ҪI¶з«ҹз”ұе“ӘдёӘеҖјзЎ®е®ҡгҖӮеӣ жӯӨпјҢеңЁз®—жі•LCSдёӯпјҢжҲ‘们еҸҜд»ҘдёҚеҖҹеҠ©дәҺж•° ҫl„bиҖҢеҖҹеҠ©дәҺж•°ҫl„cжң¬инnдёҙж—¶еҲӨж–ӯc[i,j]зҡ„еҖјжҳҜз”ұc[i-1,j-1]еQҢc[i-1,j]е’Ңc[i,j-1]дёӯе“ӘдёҖдёӘж•°еҖје…ғзҙ жүҖјӢ®е®ҡеQҢд»Јд»дhҳҜΟ(1)ж—үҷ—ҙгҖӮ既然bеҜ№дәҺҪҺ—жі•LCSдёҚжҳҜеҝ…иҰҒзҡ„пјҢйӮЈд№ҲҪҺ—жі•LCS_LENGTHдҫҝдёҚеҝ…дҝқеӯҳе®ғгҖӮиҝҷдёҖжқҘпјҢеҸҜиҠӮзң?em>θ(mn)зҡ„з©әй—Я_(dЁў)јҢиҖҢLCS_LENGTHе’ҢLCSжүҖйңҖиҰҒзҡ„ж—үҷ—ҙеҲҶеҲ«д»Қ然жҳ?em>Ο(mn)е’?em>Ο(m+n)гҖӮдёҚҳqҮпјҢз”ЧғәҺж•°з»„cд»ҚйңҖиҰ?em>Ο(mn)зҡ„з©әй—Я_(dЁў)јҢеӣ жӯӨҳqҷйҮҢжүҖдҪңзҡ„ж”№иҝӣеQҢеҸӘжҳҜеңЁҪIәй—ҙеӨҚжқӮжҖ§зҡ„еёёж•°еӣ еӯҗдёҠзҡ„ж”№иҝӣгҖ?/p>
еҸҰеӨ–еQҢеҰӮжһңеҸӘйңҖиҰҒи®ЎҪҺ—жңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зҡ„й•ҝеәҰпјҢеҲҷз®—жі•зҡ„ҪIәй—ҙйңҖжұӮиҝҳеҸҜеӨ§еӨ§еҮҸһ®‘гҖӮдәӢе®һдёҠеQҢеңЁи®Ўз®—c[i,j]ж—УһјҢеҸӘз”ЁеҲ°ж•°ҫl„cзҡ„第iиЎҢе’ҢҪW¬i-1иЎҢгҖӮеӣ жӯӨпјҢеҸӘиҰҒз”?иЎҢзҡ„ж•°з»„ҪIәй—ҙһ®ұеҸҜд»Ҙи®ЎҪҺ—еҮәжңҖй•ҝе…¬е…ұеӯҗеәҸеҲ—зҡ„й•ҝеәҰгҖӮжӣҙҳqӣдёҖжӯҘзҡ„еҲҶжһҗҳqҳеҸҜһ®Ҷз©әй—ҙйңҖжұӮеҮҸиҮіmin(m, n)гҖ?/p>