本篇內容主要來自Introduction to Collections (
http://java.sun.com/docs/books/tutorial/collections/intro/index.html),僅為個人學習和參考之用
集合框架主要包括三部分內容:接口,實現,算法。下面分別來介紹
一. 接口
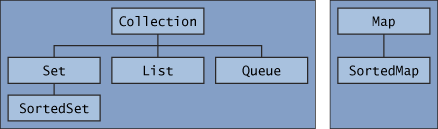
上圖所示即為java中集合框架所包含的各種接口。可以發現Map(包括SortedMap)是不繼承自Collection的,這是因為Map不同于一
般的Collection,只是一堆元素的結合,Map的特點在于他存儲的是一個個“鍵-值”對,因此他不繼承Collection。但是,Map本身還
是提供了很多Collection-views的方法,從而使其能像其他Collection一樣進行各種操作。具體將在后面介紹。
下面來簡要介紹一下各個接口:
·Collection:是整個collection
hierarchy的root,一個Collection代表一組對象的集合,這些對象稱為該Collection的元素(element)。
Collection根據不同的性質可以進行不同的劃分,比如允許有重復元素的,不允許的;元素有順序的,沒有順序的……等等。當時Java
platform并不提供Collection的直接實現類,而是根據上面提到的不同性質,定義了繼承自Collection的多個子接口,比如下面將要
提到的Set,List等
·Set:不允許有重復元素的Collection。這個接口是以數學中的集合概念抽象出來的。
·List:允許有重復元素,并且元素有順序的Collection
·Queue:除了提供基本的Collection操作外,還提供了插入、提取、檢查操作。Queue通常采用FIFO機制,但也有特例,比如
priority queue,就支持通過提供的Comparator或者元素自己的natural
ordering(指實現了Comparable接口)對內部元素進行排序。
·Map:存儲“鍵-值”對。Map不允許重復的key,同時一個key最多指向一個value。
·SortedSet:對內部元素進行升序排列的Set。當然了,既然本身已經排好序,那么SortedSet也就相應的提供了一些額外的操作來利用排好的序列。
·SortedMap:對鍵值進行升序排列的Map。典型的例子:字典,電話簿
下面就來詳細介紹各個接口。
1. Collection
下面是Collection接口的代碼:
public interface Collection<E> extends Iterable<E> {
// Basic operations
int size();
boolean isEmpty();
boolean contains(Object element);
boolean add(E element); //optional
boolean remove(Object element); //optional
Iterator<E> iterator();
// Bulk operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c); //optional
boolean removeAll(Collection<?> c); //optional
boolean retainAll(Collection<?> c); //optional
void clear(); //optional
// Array operations
Object[] toArray();
<T> T[] toArray(T[] a);
}
Collection定義了身為一個集合類所應實現的所有方法。當然,其中一些是optional的,可以根據自己的情況選擇是否實現。但Java platform所提供的general-purpose的Collection實現類,是實現了這里定義的所有方法的。
遍歷一個Collection的方法有兩種:
·使用for循環
for (Object o : collection)
System.out.println(o);
·使用Iterator
public interface Iterator<E> {
boolean hasNext();
E next();
void remove(); //optional
}
在每個Collection的實現類內部都有一個非靜態成員類來實現Iterator接口。
有兩種情況,是必須使用Iterator而不能用for循環的:
·當需要在遍歷的同時刪除元素時。因為Iterator的remove()方法是遍歷過程中修改Collection的唯一安全的方法。
·Iterate over multiple collections in parallel. - 這種情況我沒見過
下面一段代碼展示了如何在遍歷期間刪除元素:
static void filter(Collection<?> c) {
for (Iterator<?> it = c.iterator(); it.hasNext(); )
if (!cond(it.next()))
it.remove();
}
關于Collection接口定義的批量處理操作,沒什么特別的,知道就行了,需要的時候拿來用:
containsAll — returns true if the target
Collection contains all of the elements in the specified
Collection.
addAll — adds all of the elements in the specified
Collection to the target Collection.
removeAll — removes from the target Collection all
of its elements that are also contained in the specified
Collection.
retainAll — removes from the target Collection all
its elements that are not also contained in the specified
Collection. That is, it retains only those elements in the target
Collection that are also contained in the specified
Collection.
clear — removes all elements from the Collection.
將Collection轉換為數組有兩種方式:
Object[] a = c.toArray();
String[] a = c.toArray(new String[0]);
第二種方式其實是對
<T> T[] toArray(T[] a);的一種特殊用法。具體參加API doc。
2. Set
首先還是要強調的是Set不允許有重復的元素。
下面是Set接口的代碼:
public interface Set<E> extends Collection<E> {
// Basic operations
int size();
boolean isEmpty();
boolean contains(Object element);
boolean add(E element); //optional
boolean remove(Object element); //optional
Iterator<E> iterator();
// Bulk operations
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c); //optional
boolean removeAll(Collection<?> c); //optional
boolean retainAll(Collection<?> c); //optional
void clear(); //optional
// Array Operations
Object[] toArray();
<T> T[] toArray(T[] a);
}
你會發現Set的接口內容和Collection是一樣的,的確一樣,因為Set只包含從Collection繼承過來的方法,并不包含其他方法;不僅沒加什么東西,反而還多了一個限制:不允許有重復的元素。
除此之外,Set還對equals和hashCode操作有嚴格的規定。要求即使是兩個不同的Set實現類,也能用equals來進行有意義的比較。比如,如果有兩個不同的Set實現類的實例,他們包含的元素相同,那么equals比較的結果就是這兩個實例也是相等的。
Java platform提供了三種general-purpose的Set實現類:
·HashSet:用Hash Table來存放元素。效率最高(在這三個里面)。在遍歷時不能保證元素的順序。
·TreeSet:用紅-黑樹來存放元素,有順序,元素按照值來排列。
·LinkedHashSet:Hash table + linked list存放元素。按照元素的插入順序來排列元素。犧牲了一些空間,但保證了元素順序。
由于Set具有的不允許有重復元素的特性,我們可以用下面兩種方法來去除某Collection實例中的重復元素:
Collection<Type> noDups = new HashSet<Type>(c);
Collection<Type> noDups = new LinkedHashSet<Type>(c);
第二種方法不僅去除重復元素,而且還保證元素的順序不會被打亂。
舉一個例子來說明Set的基本用法:
public class FindDups {
public static void main(String[] args) {
Set<String> s = new HashSet<String>();
for (String a : args)
if (!s.add(a))
System.out.println("Duplicate detected: " + a);
System.out.println(s.size() + " distinct words: " + s);
}
}
這個例子的關鍵在于 if(!s.add(a))這句,由于Set不允許有重復元素,因此當要加入的a在Set里已經存在時,將不會被再次加入,此時add方法將返回false。
如果我們使用如下命令進行測試:
java FindDups i came i saw i left
將得到下列結果:
Duplicate detected: i
Duplicate detected: i
4 distinct words: [i, left, saw, came]
額外提一句,用Set來定義s而不是具體的實現類HashSet,是一個比較好的編程習慣,它是我們能夠不受約束的改變具體的實現類。
比如,如果我們需要按字母順序輸出的話,那么就可以使用TreeSet來代替HashSet,從而得到下面結果:
java FindDups i came i saw i left
Duplicate detected: i
Duplicate detected: i
4 distinct words: [came, i, left, saw]
關于Set的批量操作,更加顯示了Set是作為數學概念上集合的抽象的特性:
s1.containsAll(s2) — returns true if
s2 is a subset of s1. (s2 is a
subset of s1 if set s1 contains all of the elements in
s2.)
s1.addAll(s2) — transforms s1 into the
union of s1 and s2. (The union of two sets is
the set containing all of the elements contained in either set.)
s1.retainAll(s2) — transforms s1 into the
intersection of s1 and s2. (The intersection of two
sets is the set containing only the elements common to both sets.)
s1.removeAll(s2) — transforms s1 into the
(asymmetric) set difference of s1 and s2. (For
example, the set difference of s1 minus s2 is the set
containing all of the elements found in s1 but not in
s2.)
如果我們需要得到這樣一個結果:找出在Set s1或者Set s2中存在,但是不在二者中都存在的元素,下面的代碼可以完成這樣的任務:
Set<Type> symmetricDiff = new HashSet<Type>(s1);
symmetricDiff.addAll(s2);
Set<Type> tmp = new HashSet<Type>(s1);
tmp.retainAll(s2));
symmetricDiff.removeAll(tmp);
注意在上面的代碼段中,我們沒有破壞s1、s2中的元素。這也是編程中的一個小技巧。
關于Set轉換成數組的操作,與Collection接口是完全一樣的,不需再介紹。