Posted on 2019-04-11 14:14
大大毛 閱讀(476)
評論(0) 編輯 收藏 所屬分類:
Nifi

需求:
接收Kafka資料,資料具有Key列(多列),有新增、修改但無刪除,需要同步落地至MariaDB解決方案(僅新增、修改):
這個(gè)場景是最常見的,資料不會有被刪除的狀態(tài),所有的更新就只有Insert Or Update這兩種狀態(tài),先上實(shí)例的圖 (兩邊的LogMessage是為了接收Fail,有感嘆號是避免一起開啟的時(shí)候它也被開啟----這樣failure的訊息就不會再卡在Connection中了)
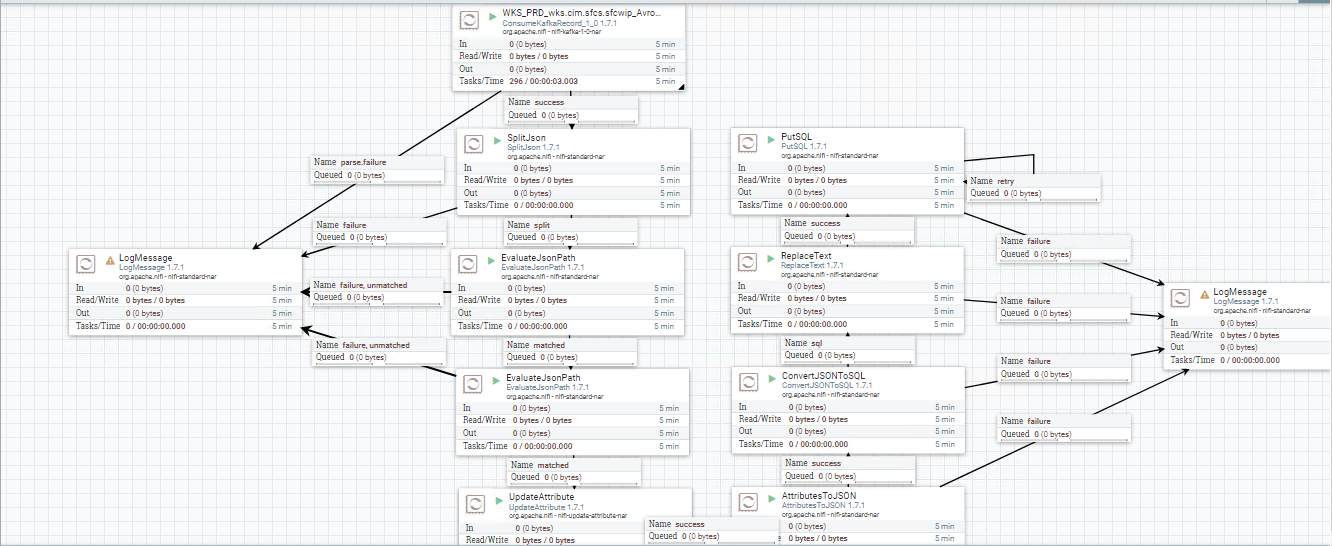
思路:
因?yàn)橛涗浿挥行略龊托薷膬煞N狀態(tài),理論上說這兩種的SQL非常接近,所以可以做以下考量
1. Processor層面是否支援Update Or Insert
> 查網(wǎng)上訊息有個(gè)叫Upsert,不過在Nifi中查找,只有一個(gè)支援Mongo的組件具有這個(gè)功能
2. DB層面是否支援
> Maria DB有個(gè) "REPLACE INTO" 的語法是可以支持Insert Or Update,雖然簡單看了下介紹說是會依主鍵或唯一索引去先做定位,如果定位到已經(jīng)存在則先做刪除再進(jìn)行新增(偽Update),但確實(shí)可以達(dá)成我們的目的,不是嗎?Processor及其設(shè)定:
ConsumeKafkaRecord,作用是從Kafka中Consume出資料(以Record的形態(tài)),這里使用Record是因?yàn)樵磾?shù)據(jù)就是以Record的方式存上去的 (Avro Schema)
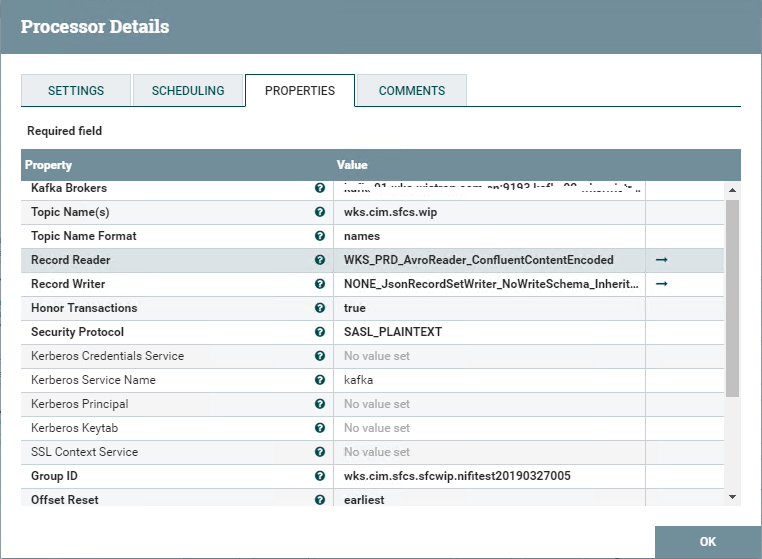
- Kafka Brokers:Kafka的Broker列表,多個(gè)Broker以逗號分隔,類似www.broker1.com:9193,www.broker2.com:9193這樣的形式配置
- Topic Name:需要Consume的Kafka Topic名稱
- Record Reader/Writer:關(guān)于Record所需要設(shè)定的Reader和Writer,要先行在Configure中設(shè)定,當(dāng)然也要設(shè)定好Schema
- Group ID:Consumer所要設(shè)定的ID,這個(gè)的設(shè)定要依Kafka的配置來,現(xiàn)在我們一般就只有單個(gè)的Partition,所以會要求每個(gè)Processor都設(shè)定有不同
- Offset Reset:需要設(shè)定為"earliest",這樣就會依GroupID沒有收過的資料來進(jìn)行收取,否則就只會收新推上去的資料。第一次玩的兄弟經(jīng)常坑在GroupID和Offset Reset這兩項(xiàng)上,若是收不到資料則有 可能就是GroupID沒有換成新的(舊的已經(jīng)收過一次就不會重新再收),或者是Offset Reset = latest又沒有新資料推上去~~~
- Max Poll Records和SCHEDULING中的Run Schedule:需要根據(jù)實(shí)際接收的速度來進(jìn)行調(diào)整。經(jīng)過觀察發(fā)現(xiàn)Consume的速度超快,但整個(gè)Nifi Flow的速度會卡在其它需要做解析或讀寫DB的Processor外 (通常解析JSON會是前面的關(guān)卡),所以任由Consumer的高速讀取就會造成整個(gè)Nifi流程在后段被卡住。造成這個(gè)的主要原因其實(shí)就在于kafka處理的高速上,所以當(dāng)有新?lián)QGroupID或新流程時(shí),Kafka上積累的海量資料就會在一瞬間被接收下來,然后就是各種紅 (其實(shí)紅了也沒事,它會自動向上推,讓前一個(gè)Processor停止處理)。
- 若是常態(tài)下的資料推送量就已經(jīng)超過了你的Nifi處理速度,那么就要考量使用多個(gè)線程處理或者是從源頭的Kafka上就把資料分割開來
- SCHEDULING的Cocurrent Tasks:這個(gè)Default=1,就是當(dāng)前Processor需要開起來的線程數(shù)。但是這個(gè)設(shè)置需要當(dāng)心,你需要仔細(xì)考量過你的資料流是否允許亂序 (多線程時(shí)當(dāng)然不可能還能保證資料處理的順序),所以它是僅適用于不Care資料處理順序的場景,例如每筆Key就只會有一筆資料,而且哪筆資料先收后收無所謂
SplitJson,作用就只是簡單的把一個(gè)JSON數(shù)組切開成單個(gè)的JSON。Consume出來的會是個(gè)數(shù)組,這跟你存放進(jìn)去的單筆訊息是不是數(shù)組沒什么關(guān)系。
Connection,就是Processor中的那根帶箭頭的連線,它的作用是連接不同的Processor并且它還具有緩存池的的一個(gè)用途,除了把數(shù)據(jù)從A導(dǎo)流向B外,還可以將B暫時(shí)處理不動的資料存放在自帶的緩存池中,若是緩存池達(dá)到上限,則Nifi會自動讓A暫停處理直至B緩過勁~~~
- Back Pressure Object Threshold / Back Pressure Data Size Threshold:最大緩存的消息筆數(shù) / 最大緩存消息的體積,兩者任一超過就會讓上游Processor處理暫停
- Available Prioritizers:出入緩存池的順序控制,Default是空,通常來說都應(yīng)該要設(shè)成FIFO先進(jìn)先出的方式
- 不設(shè)定這個(gè)經(jīng)常會造成Nifi資料處理丟失的假象,A1,A2,A3,A4,最后看到的不是A4而是A3,會讓人以為A4被玩掉了,其實(shí)只是A4被先處理,而A3變成了最后一筆狀態(tài)。而且這種錯(cuò)誤很難被發(fā)現(xiàn)!!
EvaluateJsonPath1,這個(gè)元件的作用是解析JSON,它也只能簡單的解析,想在Value中對取出來的值做一些處理好象是不允許的....
- Destination:表示解析出來的內(nèi)容是成為Attribute,還是直接替換Flow File內(nèi)容,這里設(shè)定是做為屬性,所以Processor處理后就可以在Flow File上看到多出自定義的那些屬性以及它們的值
- Return Type:返回值的類型,這種簡單從JSON中取值的可以使用Auto-detect即可
- Path Not Found Behavior:是說如果設(shè)定需要解析的JSON路徑不存在時(shí)的處理行為
- Null Value Representation:這個(gè)對于Null值的處理, "empty string"會將null設(shè)為空字符串(MO=),另外一個(gè)"the string 'null'"則是會將null設(shè)為"null"這樣的字符串 (MO="null")
- MO/MODELFAMILY/....:這些是我手工添加的屬性名稱,需要根據(jù)JSON長樣來設(shè),對應(yīng)Value設(shè)定的$.MO則是表示MO的值來源于JSON第一層的"MO"節(jié)點(diǎn)。
- 需要注意的一點(diǎn)是屬性名稱貌似是會區(qū)分大小寫的,所以可以看到我全部使用的大寫
- 截圖是運(yùn)行時(shí)態(tài)的Procssor,停止運(yùn)行時(shí)PROPERTIES上會有一個(gè) + 號,點(diǎn)它即可以新增自己的屬性
- 有一點(diǎn)比較奇怪的地方,就是通過+號維護(hù)進(jìn)去的多個(gè)屬性,它們的排列順序卻不是你手工新增的順序,這點(diǎn)引發(fā)另外一處的一個(gè)疑問,會在下面講
EvaluateJsonPath2,當(dāng)然也是要從JSON中解析,只不過我是要把整個(gè)JSON的內(nèi)容都保留下來,由于它們要求的設(shè)定不同,所以被迫要撕成兩個(gè)元件來做
- Destination:這個(gè)設(shè)定仍然是屬性
- Return Type:json,第一個(gè)解析元件雖然可以隨意設(shè)置,但把這兩種合并成一個(gè)元件并使用Auto時(shí)就會報(bào)錯(cuò),所以看起來第一種簡單屬性實(shí)際上只支持Scalar吧...
- JSONDATA:我定義的一個(gè)屬性名稱,注意Value中設(shè)定的"@"符號,它表示整份FlowFile的內(nèi)容(前面已經(jīng)轉(zhuǎn)成一個(gè)JSON)
- 這個(gè)JSONDATA是因?yàn)槲业男枨螅驗(yàn)镵afka上的資料來源于其它系統(tǒng),而我其實(shí)只需要其中的少量幾個(gè)欄位 (前一個(gè)EvaluateJsonPath解析的那些),為了備查數(shù)據(jù)上的其它欄位以及在后續(xù)使用,所以才要把整份JSON都保留到DB中去 (說得這么高端,實(shí)際的原因卻是他們的JSON屬性是用程序硬拼字串拼出來的,有的東西實(shí)在是在Nifi中搞不出來......)
UpdateAttribute,元件用途是對FlowFile的Attrubute進(jìn)行修改,這里是拿來對解析出來的值進(jìn)行再加工以及添加新屬性
- Delete Attributes Expression:這個(gè)屬性如果有設(shè)置就表示該P(yáng)rocessor為Delete屬性的狀態(tài),會忽略你新加的那些屬性處理,只專心做好一件事"刪除符合條件的屬性"
- PROVIDER:這是一個(gè)新的屬性,它并沒有包含在JSON中,是為表示數(shù)據(jù)來源而新加的
- SO:這個(gè)就是前面
EvaluateJsonPath1解析出來的某個(gè)值,那個(gè)元件無法直接加工,所以放在這里做的二次加工,去掉前導(dǎo)0
AttributesToJson,作用是將一堆Attribute轉(zhuǎn)換為Json,當(dāng)然就只能是那種簡單結(jié)構(gòu)的Json,這里使用它是為了配合后面一個(gè)Processor的使用
- Attributes List:拿來生成JSON的屬性列表,這里我其實(shí)把EvaluateJsonPath1、EvaluateJsonPath2和UpdateAttribute產(chǎn)生的屬性都放上去了 (它們就是我落地MariaDB的Table列)
- 不得不說的一個(gè)灰常遺憾的結(jié)果:那就是生成的JSON屬性順序絕對不是你在List中寫的屬性順序,我比較懷疑是在前面幾個(gè)組件生成Attribute的順序,但更讓人遺憾的是它們的順序也不會是你維護(hù)它們的順序。這個(gè)結(jié)果會導(dǎo)致我們在另外的Case 2中會碰到一個(gè)不可逾越的障礙~~~~
- Attributes Regular Expression:符合條件的正則表達(dá)式
- Destination: 這個(gè)屬性在
EvaluateJsonPath上
就有, 它可以讓結(jié)果成為一個(gè)新的屬性還是直接替換FlowFile的內(nèi)容, Default是直接換掉FlowFile的內(nèi)容。
- JDBC Connection Pool:Configrue中指定的MariaDB連接字符串,那里直接有指定Schema
- Statement Type:這個(gè)有INSERT、UPDATE、DELETE這3個(gè)選項(xiàng),若是Mongo的那個(gè)組件就會看到有UPSERT(Update or Insert),其它各類的都木有~~~,這里我使用的是INSERT選項(xiàng),后面通過玩的一點(diǎn)小花招把它再折騰為REPLACE INTO
- Update Keys: 這個(gè)屬性可以不填,它是For Update時(shí)使用的
。
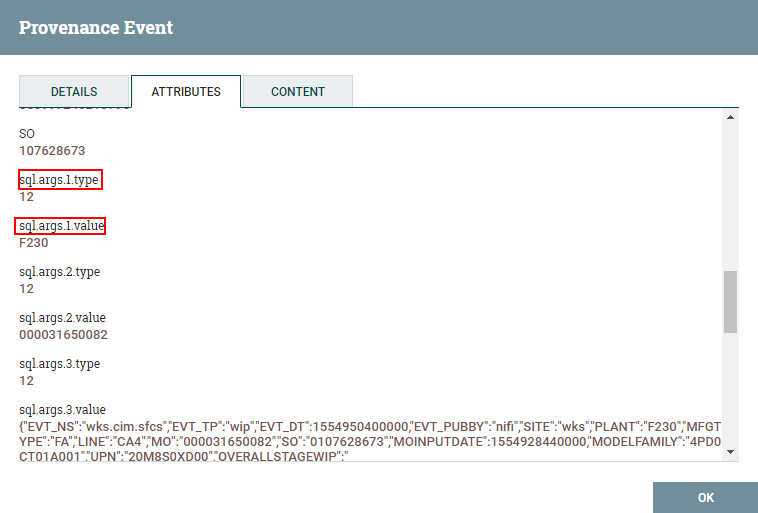
- SQL Parameter Attribute Prefix: default = sql,它其實(shí)影響到組件處理后生成的SQL語句參數(shù)叫什么,設(shè)為sql,最后就會看到生成出來
。如下圖就是處理后的Attribute樣式,它會產(chǎn)生sql.args.X.type和sql.args.X.value,這一組合起來就對應(yīng)于SQL中第一個(gè)?參數(shù)的類型及值,”sql"就是我們這里設(shè)置的前綴名稱 (充分考慮到大家會想要搞事)
ReplaceText,作用是文本替換,這里就是我們處理Update Or Insert的關(guān)鍵,直接把SQL語句換掉它
- Search Value:在FlowFile中查找的字符串,它支持正則
- Replacement Value:替換的值,這里就是簡單的把Insert Into (x1,x2,x3) values (?,?,?)處理為Replace Into (x1,x2,x3) values (?,?,?)而已,Replace Or Insert的行為交給DB去做
PutSQL,作用是在DB上執(zhí)行一段SQL語句
- JDBC Connection Pool:前面ConvertJsonToSQL轉(zhuǎn)換SQL時(shí)就有用過,指定數(shù)據(jù)庫的連接
- SQL Statement:需執(zhí)行的SQL,為空時(shí)表示使用前面?zhèn)鬟f過來的FlowFile的內(nèi)容(已經(jīng)是一個(gè)SQL語句)
總結(jié):