2
3 int main()
4 {
5 union
6 {
7 short s;
8 char c[sizeof(short)];
9 }un;
10 un.s=0x0102;
11
12 if(un.c[0]==0x01)
13 printf("big edian!\n");
14 else if(un.c[1]==0x02)
15 printf("small edian!\n");
16 return 0;
17 }
]]>
 #include<stdio.h> int main()
#include<stdio.h> int main()  {
{ 

 char x,y,z; int i; int a[16]; for(i=0;i<=16;i++)
char x,y,z; int i; int a[16]; for(i=0;i<=16;i++)  {
{  a[i]=0; printf("1\n");
a[i]=0; printf("1\n");  } return 0;
} return 0;  }
�׃��函数内部的局部变量是从栈的高地址向低地址分配.
}
�׃��函数内部的局部变量是从栈的高地址向低地址分配.i=16�Ӟ��数组下标溢出�Q�a[i]引用的其实是i变量�Q�这��P��上述循环成�ؓ一个死循环�?
]]>
]]>
思考:对于�q�个问题,我们可以暴力地来解决,从a[i]一直篏加到a[j],最坏的情况下复杂度为O(n),对于m�ơchange&querry,合�v来的复杂度�ؓO(m*n),在n或m很大的情况下,�q�样的复杂度是让人无法忍受的.另外,如果没有元素的变�?我们完全可以存储sum[1,k](k=1,2,……),然后对�Q意给定的查找区间[i,j],都可以方便的用ans=sum[1,j]-sum[1,i-1],当然�q�只是没有元素改变的情况下的比较优化的解�?那么对于有元素变更的问题是否有更高效的方法呢?(废话!没有我还写啥?!)可以想一�?每次更改的元素是比较���的,有时候甚��x���ơ只改变一个元�?但是在用暴力�Ҏ��求区间和的时�?却对区间内所有的元素都篏加了一�?�q�样其实造成了许多无谓的�q�算.�q�时候也�怼�惛_��如果能把一些结果存��h��会不会减���很多运��?�{�案是肯定的,但问题是怎么�?存什�?如果存�Q意区间的�?n比较大的时候不但内存吃不消,而且存储的量太大,不易更改,反而得不偿�?那么也许可以考虑存储特定的一些区�?比如说线�D�|��,其实现在讨论的问题用�U�段树完全可以解,以后再详�l�写�U�段�?.那么现在重新回过头来,看下�q�个问题,我们已经���定了要存储一些特定区间sum的想�?接下来我们要解决的无非是两个问题:1、减���更改元素后对这些区间里的sum值的更改旉���.2、减���查扄���旉���.
好了废话了这么半�?无非是想让自�׃��及看到的人明白�ؓ什么要用树状数�l?
接下来正式入�?
首先我们可以借鉴元素不变更问题的优化�Ҏ��,先得到前i-1��之和and前j��之�?以s[i]表示前i��之�?那么sum[i,j]=s[j]-s[i-1].那么现在的问题已�l��{化�ؓ求前i��之和了.另外,我们已经���定要存储一些特定区间的�?现在���p��来揭�C����些特定的区间�I�竟指什�?
在文字说明之前先引入一个非常经典的,在网上找到的树状数组文章里几乎都要出现的一个图�?/p>
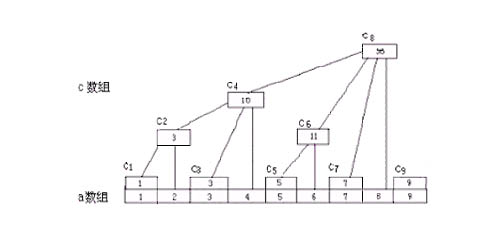
从图中不隑֏��?c[k]存储的实际上是从k开始向前数k的二�q�制表示中右边第一�?所代表的数字个元素的和(�q�么说可能有�Ҏ���?令lowbit为k的二�q�制表示中右边第一�?所代表的数�?然后c[k]里存的就是从a[k]开始向前数lowbit个元素之�?�q�么存有什么好处呢?无论是树状数�l�还是线�D�|��,都用��C��分块的思想,而树状数�l�采用这��L��存储�l�构我想最主要的还是这��h��便计��?我们可以用位�q�算��L��地算出lowbit.分析一下这样做的复杂度:对于更改元素来说,如果�W�i个元素被修改�?因�ؓ我们最�l�还是要求和,所以可以直接在c数组里面�q�行相应的更�?如图中的例子,假设更改的元素是a[2],那么它媄响到得c数组中的元素只有c[2],c[4],c[8],我们只需一层一层往上修改就可以�?�q�个�q�程的最坏的复杂度也不过O(logN);对于查找来说,如查找s[k],只需查找k的二�q�制表示�?的个数次���p��得到最�l�结�?比如查找s[7],7的二�q�制表示中有3�?,也就是要查找3��?到底是不是呢,我们来看上图,s[7]=c[7]+c[6]+c[4],可能你还不知道怎么实现�q�个�q�程.
�q�以7��Z��,二进制�ؓ0111,双����W�一�?出现在第0位上,也就是说要从a[7]开始向前数1个元�?只有a[7]),即c[7];
然后���这�?舍掉,得到6,二进制表�C�Zؓ0110,双����W�一�?出现在第1位上,也就是说要从a[6]开始向前数2个元�?a[6],a[5]),即c[6];
然后舍掉用过�?,得到4,二进制表�C�Zؓ0100,双����W�一�?出现在第2位上,也就是说要从a[4]开始向前数4个元�?a[4],a[3],a[2],a[1]),即c[4].
代码实现:
 int lowbit(int x)//计算lowbit
int lowbit(int x)//计算lowbit {
{

 return x&(-x);
return x&(-x); }void add(int i,int val)//���第i个元素更改�ؓval{ while(i<=n)
}void add(int i,int val)//���第i个元素更改�ؓval{ while(i<=n) {
{ c[i]+=val; i+=lowbit(i);
c[i]+=val; i+=lowbit(i); }}int sum(int i)//求前i��和{ int s=0; while(i>0) { s+=c[i]; i-=lowbit(i); } return s;}
}}int sum(int i)//求前i��和{ int s=0; while(i>0) { s+=c[i]; i-=lowbit(i); } return s;}http://www.cnblogs.com/yykkciwei/archive/2009/05/08/1452889.html
]]>
数据�l�构是对在计���机内存中(有时在磁盘中�Q�的数据的一�U�安排。数据结构包括数�l�、链表、栈、二叉树、哈希表�{�等。算法对�q�些�l�构中的数据�q�行各种处理。例如,查找一条特�D�的数据��Ҏ���Ҏ��据进行排序�?/font>
掌握�q�些知识以后可以解决哪些问题呢?
现实世界数据存储
�E�序员的工具
建模
数据�l�构的特性:
数组�Q�优�Ҏ��插入快,如果知道下标�Q�可以非常快地存取。缺�Ҏ��查找慢,删除慢,大小固定�?/font>
有序数组�Q�优�Ҏ��比无序的数据查找快。缺�Ҏ��删除和插入慢�Q�大���固定�?/font>
栈:优点是提供后�q�先出方式的存取。缺�Ҏ��存取其他��很慢�?/font>
队列�Q�提供先�q�先出方式的存取。缺�Ҏ��存取其他��很慢�?/font>
链表�Q�优�Ҏ��插入快,删除快。缺�Ҏ��查找慢�?/font>
二叉树:优点是查找、插入、删除都快(如果树保持��^衡)。缺�Ҏ��删除���法复杂�?/font>
�U�-黑树�Q�查找、插入、删除都快。树��L���q����的。缺�Ҏ�����法复杂�?/font>
2-3-4树:优点是查找、插入、删除都快。树��L���q����的。类似的树对���盘存储有用。缺�Ҏ�����法复杂�?/font>
哈希表:优点是如果关键字已知则存取极快。插入快。缺�Ҏ��删除慢,如果不知道关键字则存取很慢,对存储空间��用不充分�?/font>
堆:优点是插入、删除快�Q�对最大数据项的存取很快。缺�Ҏ��对其他数据项存取慢�?/font>
图:优点是对现实世界建模。缺�Ҏ��有些���法且复杂�?/font>
对于大多数数据结构来��_��都需要知道如何插入一条新的数据项�Q�如何寻找某一特定的数据项�Q�如何删除某一特定的数据项�Q�还需要知道如何�P代地讉K��某一数据�l�构中的各数据项�Q�以便进行显�C�或其他操作。另一�U�重要的���法范畴是排序�?/font>
一、通用数据�l�构�Q�数�l�,链表�Q�树�Q�哈希表
它们被称之�ؓ通用的数据结构是因�ؓ它们通过关键字的值来存储�q�查找数据,�q�一点在通用数据库程序中常见刎ͼ�栈等�Ҏ���l�构正好相反�Q�它们只允许存取一定的数据��)�?/font>
通用数据�l�构可以完全按照速度的快慢来分类�Q?/font>
数组和链表是最慢的�Q�树相对较快�Q�哈希表是最快的�?/font>
但�ƈ不是使用最快的�l�构永远是最好的�Ҏ��。这些最快的�l�构也有�~�陷�Q�首先,它们的程序在不同�E�度上比数组和链表的复杂;其次�Q�哈希表要求预先知道要存储多���数据,数据对存储空间的利用率也不是非常高。普通的二叉树对��序的数据来��_��会变成缓慢的O(N)�U�操�?而��^衡树虽然避免了上�q�的问题�Q�但是它的程序编制�v来却比较困难�?/font>
数组在下列情况下很有用:
数据量较��?/font>
数据量的大小事先可预��?/font>
如果存储�I�间���_��大的话,可以放松�W�二条,创徏一个��够大的数�l�来应付所有可以预见的数据输入�?/font>
如果插入速度很重要的话,使用无序数组。如果查��N��度很重要的话,使用有序数组�Q��ƈ用二分查找。数�l�元素的删除��L��很慢�Q�这是由于�ؓ了填充空出来的单元,�q�_��半数以上的数�l�元素要被移动。在有序数组中的遍历是很快的�Q�而在无序的数�l�不支持�q�种功能�?/font>
向量�Q�如Java中的向量�c�)是一�U�当数据太满时可以自己扩充空间的数组。向量可以应用于数据量不可预知的情况下。然而,在向量扩充时�Q�要���旧的数据拷入一个新的空间中�Q�这一�q�程会造成�E�序明显的周期性暂停�?/font>
如果需要存储的数据量不能预知或者需要频�J�地插入删除数据元素�Ӟ��考虑使用链表。当有新的元素加入时�Q�链表就开辟新的所需要的�I�间�Q�所以它甚至可以占满全部可用内存;在删除过�E�中没有必要像数�l�那��h���?#8220;�I�洞”�?/font>
二、专用数据结构:栈,队列�Q�优先��队列
三、排序:插入排序�Q�希���排序,快速排序,归�ƈ排序�Q�堆排序
四、图�Q�邻接矩阵,��L���?/font>
五、外部存储:��序存储�Q�烦引文�Ӟ��B-树,哈希�Ҏ��
本文来自CSDN博客�Q��{载请标明出处�Q�http://blog.csdn.net/adcxf/archive/2008/08/06/2775636.aspx
]]>
![]()
先让我们来验证下�q�个巧妙的方法准���性,来算�?的��^�Ҏ�� (Computed by Mathomatic)
1-> x_new = ( x_old + y/x_old )/2 y (x_old + -----) x_old #1: x_new = --------------- 2 1-> calculate x_old 1 Enter y: 2 Enter initial x_old: 1 x_new = 1.5 1-> calculate x_old 2 Enter y: 2 Enter initial x_old: 1 x_new = 1.4166666666667 1-> calculate x_old 3 Enter y: 2 Enter initial x_old: 1 x_new = 1.4142156862745 1-> calculate x_old 10 Enter y: 2 Enter initial x_old: 1 Convergence reached after 6 iterations. x_new = 1.4142135623731 ...
可见�Q�随着�q�代�ơ数的增加,�q�算��g��愈发接近真实倹{��很���奇的算法,可是怎么来的�? 查了�?a title="Wikipedia: Newton's method" >wikipedia�?a title="Wolfram: Newton's Iteration" >wolfram�Q�原来算法的名字叫Newton’s Iteration (牛顿�q�代�?�?/p>
下面是极�?span lang="ja" xml:lang="ja">つまらな�?/span>(boring)的数理介�l�,不喜�Ƣ数学的�a�下之意也���是�l�大部分人可以略�q�了�?/p>
���单推�?/h3>
假设f(x)是关�?code class="math">X的函�?

求出f(x)的一阶导�Q�即斜率:
![]()
���化等式得�?
![]()
然后利用得到的最�l�式�q�行�q�代�q�算直至求到一个比较精���的满意��|����Z��么可以用�q�代法呢?理由是中值定�?Intermediate Value Theorem):
如果
f函数在闭区间[a,b]内连�l�,必存在一�?code class="math">x使得f(x) = c�Q?code class="math">c是函�?code class="math">f在闭区间[a,b]内的一�?
我们先猜���一X初始��|��例如1�Q�当然地球�h都知道除�?本��n之外��M��数的�q�x��栚w��不会�?。然后代入初始��|��通过�q�代�q�算不断推进�Q�逐步靠近�_������|��直到得到我们主观认�ؓ比较满意的��gؓ止。例如要�?68的��^�Ҏ���Q�因�?code class="math">252 = 625�Q��?code class="math">302 = 900�Q�我们可先代入一猜测�?6�Q�然后�P代运���,得到较精����?27.7128�?/p>
回到我们最开始的那个”莫名其妙”的公式,我们要求的是N的��^�Ҏ���Q���ox2 = n�Q�假设一关于X的函�?code class="math">f(x)�?
f(X) = X2 - n
�?code class="math">f(X)的一阶导�?
f'(X) = 2X
代入前面求到的最�l�式�?
Xk+1 = Xk - (Xk2 - n)/2Xk
化简卛_��到我们最初提到的那个求��^�Ҏ��的神奇公式了:
![]()
用泰勒公式推�?/h3>
我之前介�l�过�?em>The Art and Science of C一书中有用�?a title="The Art and Science of C 阅读�W�记 II" >泰勒公式求��^�Ҏ��的算�?/a>�Q�其实牛���P代法也可以看作是泰勒公式(Taylor Series)的简化,先回��下泰勒公式:
![]()
仅保留等式右边前两项:
![]()
�?code class="math">f(X0+ε) = 0�Q�得�?
![]()
再��oX1 = X0 + ε0�Q�得�?code class="math">ε1…依此�c�L��可知:
![]()
转化�?
![]()
引申
从推导来看,其实牛顿�q�代法不仅可以用来求�q�x��根,�q�可以求立方根,甚至更复杂的�q�算�?/p>
同样�Q�我们还可以利用C语言来实��C��那个最���单的求��^�Ҏ��的公�?���管我们可以直接�?code>sqrt()完成)
#include <stdio.h>
#include <math.h>
#define N 768
main() {
float x=1;
int i;
for (i=1;i<=1000;i++) { // recursion times : 1000
x = (x + N/x)/2;
}
printf("The square root of %d is %f\n",N,x);
}
]]>