關(guān)于Google的Suggest功能的實(shí)現(xiàn)
@@@使用Ajax及Lucene對(duì)其進(jìn)行完美實(shí)現(xiàn)@@@ (飛刀和雨)
大家都對(duì)Google的suggest的功能大概很有興趣吧,我們覺得既然Google做的出,那么我們也能做出來,先對(duì)其進(jìn)行分析,1.對(duì)于網(wǎng)頁客戶端的按鍵的動(dòng)態(tài)變化,Ajax是最好的選擇, 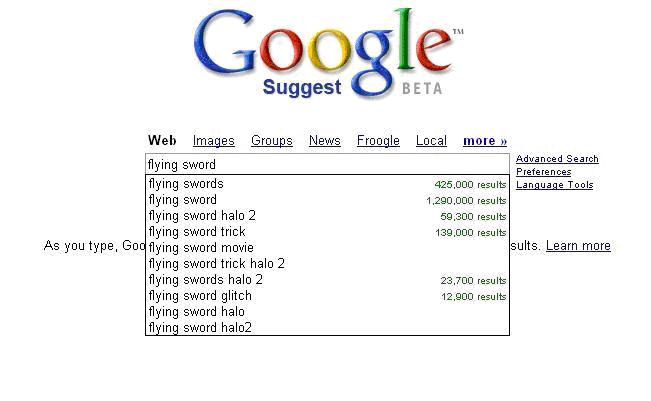
2.如果數(shù)據(jù)庫(kù)的選擇,則可以有多種選擇得,BerkeleyDB, Derby甚至自己做個(gè)txt文本文件,把所需要的單詞和result數(shù)目放在文本文件里都能夠?qū)崿F(xiàn),但今天我們有了一個(gè)很好的索引工具Lucene。加上Lucene對(duì)我的吸引力,因此今天我們用上大炮,卸去鳥槍。開始我們的開發(fā)之路。
首先,我們先建立個(gè)demo的框架,我就做了個(gè)這樣的一個(gè)html文件,用了一個(gè)form,一個(gè)
輸入的文本框,一個(gè)多選項(xiàng)和一個(gè)確認(rèn)按鍵。后面兩個(gè)沒什么好說的,主要是文本框的設(shè)計(jì),我做了以下的定義,<input type="text" size=60 id="userid" name="q" autocomplete="off" onKeyUp="validate(event);"> 這樣autocomplete=off指取消網(wǎng)頁的cache,這樣就不會(huì)彈出以前打過的字的窗口,造成混亂。onKeyUp是實(shí)現(xiàn)ajax的關(guān)鍵,相應(yīng)鍵盤輸入的操作。
其次,開始我們的Ajax了,顧名思義,Ajax指異步的javascript和xml. 我們的所有工作都會(huì)在javascript中完成,至于ajax原理,很多地方都有很詳細(xì)的解釋,這里就指列應(yīng)用了。
validate(e){
var key=e.KeyCode; //獲得輸入的鍵值
//定義按鍵只對(duì)字母數(shù)字,空格,回車,Ins和del有效,可以避免一些無效的相應(yīng),并//轉(zhuǎn)發(fā)url給servlet,那么我們只要等servlet返回xml就可以了
if (key>=48 && key<=90 || key==8 || key==32 || key== 45 || key==46){
var url = "LuceneSearch?id=" + encodeURI(idField.value);
req.open("GET", url, true);
req.onreadystatechange = processRequest;
req.send(null);
}
}
這時(shí),可以通過Ajax的3個(gè)req的請(qǐng)求進(jìn)行向服務(wù)器發(fā)送,我們這里只要等待服務(wù)器返回的xml就可以了。
function processRequest(){
if(req.readyState==4){
if(req.status==200){
parseMessages();
}else{
clearTable();
}
}
}
這里我們通過返回的狀態(tài), 得到一個(gè)XmlHttp的readyState=4表示servlet的操作結(jié)束,status
=200則表示Http得到正常的返回,這時(shí)調(diào)用parseMessage()就可以對(duì)所得到的XmlHttp進(jìn)行操作,
function parseMessages(){
var products = req.responseXML.getElementsByTagName("products")[0];
for (loop=0;loop<products.childNodes.length);loop++){
var product = products.childNodes[loop];
var productname = product.getElementsByTagName("pname")[0];
var productnumber = product.getElementsByTagName("pnumber")[0];
}
}
這里我們就在javascipt里就得到了我們所需要的詞的name和number,然后就只要在javascript里填入一些特效,便能很方便的實(shí)現(xiàn)Google的suggest.
其次,我們所需要的就事編寫我們現(xiàn)在的LuceneSearch的servlet. 這里因?yàn)橥ㄟ^get方式傳遞,這不對(duì)于開發(fā)j2ee的程序員來說,就是小菜一碟,我們只要定義doGet(req, res)就能可以了實(shí)現(xiàn)了。從這里我們得到了Text文本框里的字符串值。
public class LuceneSearch extends HttpServlet{
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException {
String targetId = request.getParameter("id");
}
}
然后我們需要對(duì)這些字符串進(jìn)行清理,去掉些無效的符號(hào),然后把多余空格合并,成為一種真正的需要的字符串,然后我們需要用Lucene來進(jìn)行搜索,先把Document把數(shù)據(jù)從數(shù)據(jù)庫(kù)里讀出來,然后制成Index。然后用Search來進(jìn)行搜索,這里Lucene提供了很好的搜索方式,搜索分兩種方式,一種是單個(gè)單詞,這個(gè)就比較好辦,Lucene 提供了開頭匹配的方法PrefixQuery(), 直接套用就可以了
PrefixQuery query = new PrefixQuery(new Term("keyword", targetId));
IndexSearcher searcher = new IndexSearcher(directory);
Hits hits = searcher.search(query,sort);
for(int i=0; i<hits.length();i++){
sb.append("<product>");
sb.append("<pname>"+hits.doc(i).get("keyword")+"</pname>");
sb.append("<pnumber>"+hits.doc(i).get("number")+"</pnumber>");
sb.append("</product>");
}
這樣我們就把搜索到的詞和數(shù)量都放進(jìn)Xml里了這樣就出來了。
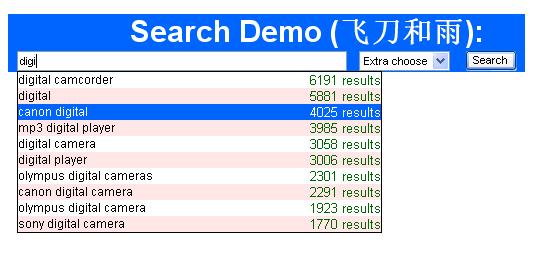
我們還可以注意到如果所需要的詞并不在開頭也能得到實(shí)現(xiàn)。
對(duì)于詞組就比較費(fèi)盡,因?yàn)槭紫纫WC前面詞的位置性,可以任意放置,最后一個(gè)詞則必須以開頭為基準(zhǔn)進(jìn)行模糊查找,這樣才能實(shí)現(xiàn)其功能,還好Lucene還是考慮到了這點(diǎn),有個(gè)PhrasePrefixQuery()的方法,稍稍加以改進(jìn)便可以實(shí)現(xiàn),
//首先要把詞組用split以空格分開
String[] targetIdArray = targetId.split(" ");
PhrasePrefixQuery query = new PhrasePrefixQuery();
for(int i=0; i<targetIdArray.length-1;i++){
query.add(new Term("keyword",targetIdArray[i]));
}
query.setSlop(4); //設(shè)置詞前后位置移動(dòng)范圍。
LinkedList termsWithPrefix = new LinkedList();
IndexReader ir = IndexReader.open(directory);
TermEnum te = ir.terms(new Term("keyword", targetIdArray[targetIdArray.length-1]));
do {
if (te.term().text().startsWith(targetIdArray[targetIdArray.length-1])) {
termsWithPrefix.add(te.term());
}
} while (te.next());
這樣我們先得到最后一個(gè)單詞為開頭的詞,然后加到PrasePrefixQuery里
query.add((Term[])termsWithPrefix.toArray(new Term[0]));
Hits hits;
hits = searcher.search(query, sort);
for(int i=0; i<(hits.length()>20?20:hits.length());i++){
sb.append("<product>");
sb.append("<pname>"+hits.doc(i).get("keyword")+"</pname>");
sb.append("<pnumber>"+hits.doc(i).get("popularity")+"</pnumber>");
sb.append("</product>");
}
這樣我們就可以得到我們所需要的詞組了。如圖所示,很方便吧,這里就基本完成了google
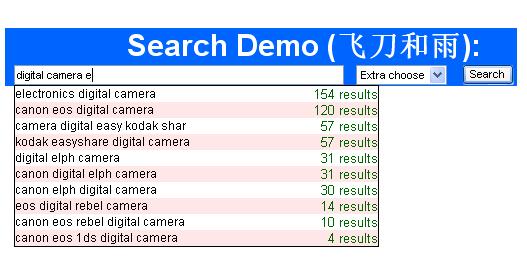
所代表的suggest功能,當(dāng)然,javascript里面還有一些上下鍵,鼠標(biāo)移動(dòng)事件的觸發(fā),加在一起就會(huì)把我們的網(wǎng)頁弄得很完美了。但這些都不是重點(diǎn),我們主要是對(duì)門戶網(wǎng)站功能的實(shí)現(xiàn),如果有問題和建議,可以給我留言,謝謝。