 2008年5月19日
2008年5月19日
版權(quán)聲明:本文可以自由轉(zhuǎn)載,轉(zhuǎn)載時請務必以超鏈接形式標明文章原始出處和作者信息及本聲明
作者:cleverpig(作者的Blog:
http://blog.matrix.org.cn/page/cleverpig)
原文:
http://www.matrix.org.cn/resource/article/44/44048_Java+Annotation.html
關(guān)鍵字:Java,annotation,標注
摘要:
本文針對java初學者或者annotation初次使用者全面地說明了annotation的使用方法、定義方式、分類。初學者可以通過以上的說明制作
簡單的annotation程序,但是對于一些高級的annotation應用(例如使用自定義annotation生成javabean映射xml文
件)還需要進一步的研究和探討。涉及到深入annotation的內(nèi)容,作者將在后文《Java Annotation高級應用》中談到。
同時,annotation運行存在兩種方式:運行時、編譯時。上文中討論的都是在運行時的annotation應用,但在編譯時的annotation應用還沒有涉及,
一、為什么使用Annotation:
在JAVA應用中,我們常遇到一些需要使用模版代碼。例如,為了編寫一個JAX-RPC web service,我們必須提供一對接口和實現(xiàn)作為模版代碼。如果使用annotation對遠程訪問的方法代碼進行修飾的話,這個模版就能夠使用工具自動生成。
另外,一些API需要使用與程序代碼同時維護的附屬文件。例如,JavaBeans需要一個BeanInfo
Class與一個Bean同時使用/維護,而EJB則同樣需要一個部署描述符。此時在程序中使用annotation來維護這些附屬文件的信息將十分便利
而且減少了錯誤。
二、Annotation工作方式:
在5.0版之前的Java平臺已經(jīng)具有了一些ad hoc
annotation機制。比如,使用transient修飾符來標識一個成員變量在序列化子系統(tǒng)中應被忽略。而@deprecated這個
javadoc tag也是一個ad hoc
annotation用來說明一個方法已過時。從Java5.0版發(fā)布以來,5.0平臺提供了一個正式的annotation功能:允許開發(fā)者定義、使用
自己的annoatation類型。此功能由一個定義annotation類型的語法和一個描述annotation聲明的語法,讀取annotaion
的API,一個使用annotation修飾的class文件,一個annotation處理工具(apt)組成。
annotation并不直接影響代碼語義,但是它能夠工作的方式被看作類似程序的工具或者類庫,它會反過來對正在運行的程序語義有所影響。annotation可以從源文件、class文件或者以在運行時反射的多種方式被讀取。
當然annotation在某種程度上使javadoc tag更加完整。一般情況下,如果這個標記對java文檔產(chǎn)生影響或者用于生成java文檔的話,它應該作為一個javadoc tag;否則將作為一個annotation。
三、Annotation使用方法:
1。類型聲明方式:
通常,應用程序并不是必須定義annotation類型,但是定義annotation類型并非難事。Annotation類型聲明于一般的接口聲明極為類似,區(qū)別只在于它在interface關(guān)鍵字前面使用“@”符號。
annotation類型的每個方法聲明定義了一個annotation類型成員,但方法聲明不必有參數(shù)或者異常聲明;方法返回值的類型被限制在以下的范
圍:primitives、String、Class、enums、annotation和前面類型的數(shù)組;方法可以有默認值。
下面是一個簡單的annotation類型聲明:
清單1:
/**
* Describes the Request-For-Enhancement(RFE) that led
* to the presence of the annotated API element.
*/
public @interface RequestForEnhancement {
int id();
String synopsis();
String engineer() default "[unassigned]";
String date(); default "[unimplemented]";
}
代碼中只定義了一個annotation類型RequestForEnhancement。
2。修飾方法的annotation聲明方式:
annotation是一種修飾符,能夠如其它修飾符(如public、static、final)一般使用。習慣用法是annotaions用在其它的
修飾符前面。annotations由“@+annotation類型+帶有括號的成員-值列表”組成。這些成員的值必須是編譯時常量(即在運行時不
變)。
A:下面是一個使用了RequestForEnhancement annotation的方法聲明:
清單2:
@RequestForEnhancement(
id = 2868724,
synopsis = "Enable time-travel",
engineer = "Mr. Peabody",
date = "4/1/3007"
)
public static void travelThroughTime(Date destination) { ... }
B:當聲明一個沒有成員的annotation類型聲明時,可使用以下方式:
清單3:
/**
* Indicates that the specification of the annotated API element
* is preliminary and subject to change.
*/
public @interface Preliminary { }
作為上面沒有成員的annotation類型聲明的簡寫方式:
清單4:
@Preliminary public class TimeTravel { ... }
C:如果在annotations中只有唯一一個成員,則該成員應命名為value:
清單5:
/**
* Associates a copyright notice with the annotated API element.
*/
public @interface Copyright {
String value();
}
更為方便的是對于具有唯一成員且成員名為value的annotation(如上文),在其使用時可以忽略掉成員名和賦值號(=):
清單6:
@Copyright("2002 Yoyodyne Propulsion Systems")
public class OscillationOverthruster { ... }
3。一個使用實例:
結(jié)合上面所講的,我們在這里建立一個簡單的基于annotation測試框架。首先我們需要一個annotation類型來表示某個方法是一個應該被測試工具運行的測試方法。
清單7:
import java.lang.annotation.*;
/**
* Indicates that the annotated method is a test method.
* This annotation should be used only on parameterless static methods.
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Test { }
值得注意的是annotaion類型聲明是可以標注自己的,這樣的annotation被稱為“meta-annotations”。
在上面的代碼中,@Retention(RetentionPolicy.RUNTIME)這個meta-annotation表示了此類型的
annotation將被虛擬機保留使其能夠在運行時通過反射被讀取。而@Target(ElementType.METHOD)表示此類型的
annotation只能用于修飾方法聲明。
下面是一個簡單的程序,其中部分方法被上面的annotation所標注:
清單8:
public class Foo {
@Test public static void m1() { }
public static void m2() { }
@Test public static void m3() {
throw new RuntimeException("Boom");
}
public static void m4() { }
@Test public static void m5() { }
public static void m6() { }
@Test public static void m7() {
throw new RuntimeException("Crash");
}
public static void m8() { }
}
Here is the testing tool:
import java.lang.reflect.*;
public class RunTests {
public static void main(String[] args) throws Exception {
int passed = 0, failed = 0;
for (Method m : Class.forName(args[0]).getMethods()) {
if (m.isAnnotationPresent(Test.class)) {
try {
m.invoke(null);
passed++;
} catch (Throwable ex) {
System.out.printf("Test %s failed: %s %n", m, ex.getCause());
failed++;
}
}
}
System.out.printf("Passed: %d, Failed %d%n", passed, failed);
}
}
這個程序從命令行參數(shù)中取出類名,并且遍歷此類的所有方法,嘗試調(diào)用其中被上面的測試annotation類型標注過的方法。在此過程中為了找出哪些方法
被annotation類型標注過,需要使用反射的方式執(zhí)行此查詢。如果在調(diào)用方法時拋出異常,此方法被認為已經(jīng)失敗,并打印一個失敗報告。最后,打印運
行通過/失敗的方法數(shù)量。
下面文字表示了如何運行這個基于annotation的測試工具:
清單9:
$ java RunTests Foo
Test public static void Foo.m3() failed: java.lang.RuntimeException: Boom
Test public static void Foo.m7() failed: java.lang.RuntimeException: Crash
Passed: 2, Failed 2
四、Annotation分類:
根據(jù)annotation的使用方法和用途主要分為以下幾類:
1。內(nèi)建Annotation——Java5.0版在java語法中經(jīng)常用到的內(nèi)建Annotation:
@Deprecated用于修飾已經(jīng)過時的方法;
@Override用于修飾此方法覆蓋了父類的方法(而非重載);
@SuppressWarnings用于通知java編譯器禁止特定的編譯警告。
下面代碼展示了內(nèi)建Annotation類型的用法:
清單10:
package com.bjinfotech.practice.annotation;
/**
* 演示如何使用java5內(nèi)建的annotation
* 參考資料:
* http://java.sun.com/docs/books/tutorial/java/javaOO/annotations.html
* http://java.sun.com/j2se/1.5.0/docs/guide/language/annotations.html
* http://mindprod.com/jgloss/annotations.html
* @author cleverpig
*
*/
import java.util.List;
public class UsingBuiltInAnnotation {
//食物類
class Food{}
//干草類
class Hay extends Food{}
//動物類
class Animal{
Food getFood(){
return null;
}
//使用Annotation聲明Deprecated方法
@Deprecated
void deprecatedMethod(){
}
}
//馬類-繼承動物類
class Horse extends Animal{
//使用Annotation聲明覆蓋方法
@Override
Hay getFood(){
return new Hay();
}
//使用Annotation聲明禁止警告
@SuppressWarnings({"deprecation","unchecked"})
void callDeprecatedMethod(List horseGroup){
Animal an=new Animal();
an.deprecatedMethod();
horseGroup.add(an);
}
}
}
2。開發(fā)者自定義Annotation:由開發(fā)者自定義Annotation類型。
下面是一個使用annotation進行方法測試的sample:
AnnotationDefineForTestFunction類型定義如下:
清單11:
package com.bjinfotech.practice.annotation;
import java.lang.annotation.*;
/**
* 定義annotation
* @author cleverpig
*
*/
//加載在VM中,在運行時進行映射
@Retention(RetentionPolicy.RUNTIME)
//限定此annotation只能標示方法
@Target(ElementType.METHOD)
public @interface AnnotationDefineForTestFunction{}
測試annotation的代碼如下:
清單12:
package com.bjinfotech.practice.annotation;
import java.lang.reflect.*;
/**
* 一個實例程序應用前面定義的Annotation:AnnotationDefineForTestFunction
* @author cleverpig
*
*/
public class UsingAnnotation {
@AnnotationDefineForTestFunction public static void method01(){}
public static void method02(){}
@AnnotationDefineForTestFunction public static void method03(){
throw new RuntimeException("method03");
}
public static void method04(){
throw new RuntimeException("method04");
}
public static void main(String[] argv) throws Exception{
int passed = 0, failed = 0;
//被檢測的類名
String className="com.bjinfotech.practice.annotation.UsingAnnotation";
//逐個檢查此類的方法,當其方法使用annotation聲明時調(diào)用此方法
for (Method m : Class.forName(className).getMethods()) {
if (m.isAnnotationPresent(AnnotationDefineForTestFunction.class)) {
try {
m.invoke(null);
passed++;
} catch (Throwable ex) {
System.out.printf("測試 %s 失敗: %s %n", m, ex.getCause());
failed++;
}
}
}
System.out.printf("測試結(jié)果: 通過: %d, 失敗: %d%n", passed, failed);
}
}
3。使用第三方開發(fā)的Annotation類型
這也是開發(fā)人員所常常用到的一種方式。比如我們在使用Hibernate3.0時就可以利用Annotation生成數(shù)據(jù)表映射配置文件,而不必使用Xdoclet。
五、總結(jié):
1。前面的文字說明了annotation的使用方法、定義方式、分類。初學者可以通過以上的說明制作簡單的annotation程序,但是對于一些高級
的annotation應用(例如使用自定義annotation生成javabean映射xml文件)還需要進一步的研究和探討。
2。同時,annotation運行存在兩種方式:運行時、編譯時。上文中討論的都是在運行時的annotation應用,但在編譯時的
annotation應用還沒有涉及,因為編譯時的annotation要使用annotation processing tool。
涉及以上2方面的深入內(nèi)容,作者將在后文《Java Annotation高級應用》中談到。
=========================================================
GOOGLE不支持通配符,如“*”、“?”等,只能做精確查詢,關(guān)鍵字后面的“*”或者“?”會被忽略掉。
GOOGLE對英文字符大小寫不敏感,“GOD”和“god”搜索的結(jié)果是一樣的。
GOOGLE的關(guān)鍵字可以是詞組(中間沒有空格),也可以是句子(中間有空格),但是,用句子做關(guān)鍵字,必須加英文引號。
示例:搜索包含“long, long ago”字串的頁面。
搜索:“"long, long ago"”
結(jié)果:已向英特網(wǎng)搜索"long, long ago". 共約有28,300項查詢結(jié)果,這是第1-10項。搜索用時0.28秒。
注意:和搜索英文關(guān)鍵字串不同的是,GOOGLE對中文字串的處理并不十分完善。比如,搜索“"啊,我的太陽"”,我們希望結(jié)果中含有這個句子,事實并非
如此。查詢的很多結(jié)果,“啊”、“我的”、“太陽”等詞語是完全分開的,但又不是“啊 我的
太陽”這樣的與查詢。顯然,GOOGLE對中文的支持尚有欠缺之處。
GOOGLE對一些網(wǎng)路上出現(xiàn)頻率極高的詞(主要是英文單詞),如“i”、“com”,以及一些符號如“*”、“.”等,作忽略處理,如果用戶必須要求關(guān)鍵字中包含這些常用詞,就要用強制語法“+”。
示例:搜索包含“Who am I ?”的網(wǎng)頁。如果用“"who am i ?"”,“Who”、“I”、“?”會被省略掉,搜索將只用“am”作關(guān)鍵字,所以應該用強制搜索。
搜索:“"+who +am +i"”
結(jié)果:已向英特網(wǎng)搜索"+who +am +i". 共約有362,000項查詢結(jié)果,這是第1-10項。搜索用時0.30秒。
注意:英文符號(如問號,句號,逗號等)無法成為搜索關(guān)鍵字,加強制也不行。
==============================================================
inurl語法返回的網(wǎng)頁鏈接中包含第一個關(guān)鍵字,后面的關(guān)鍵字則出現(xiàn)在鏈接中或者網(wǎng)頁文檔中。有很多網(wǎng)站把某一類具有相同屬性的資源名稱顯示在目錄名稱
或者網(wǎng)頁名稱中,比如“MP3”、“GALLARY”等,于是,就可以用INURL語法找到這些相關(guān)資源鏈接,然后,用第二個關(guān)鍵詞確定是否有某項具體資
料。INURL語法和基本搜索語法的最大區(qū)別在于,前者通常能提供非常精確的專題資料。
示例:查找MIDI曲“滄海一聲笑”。
搜索:“inurl:midi 滄海一聲笑”
結(jié)果:已搜索有關(guān)inurl:midi 滄海一聲笑的中文(簡體)網(wǎng)頁。共約有14項查詢結(jié)果,這是第1-10項。搜索用時0.01秒。
示例:查找微軟網(wǎng)站上關(guān)于windows2000的安全課題資料。
搜索:“inurl:security windows2000 site:microsoft.com”
結(jié)果:已在microsoft.com內(nèi)搜索有關(guān) inurl:security windows2000的網(wǎng)頁。共約有198項查詢結(jié)果,這是第1-10項。搜索用時0.37秒。
注意:“inurl:”后面不能有空格,GOOGLE也不對URL符號如“/”進行搜索。GOOGLE對“cgi-bin/phf”中的“/”當成空格處理。
1。啟動:mysqld --console
2。調(diào)試:mysql -u root
void *從本質(zhì)上講是一種指針的類型,就像 (char *)、(int *)類型一樣.但是其又具有
特殊性,它可以存放其他任何類型的指針類型:例如:
char *array="I am the pointer of string";
void * temp;
//temp可以存放其他任何類型的指針(地址)
temp=array; // temp 的指針類型
cout<<array<<endl;
cout<<temp<<endl;
cout<<(char *)temp<<endl;
運行結(jié)果:
I am the pointer of string
0x0042510C (這個值就是array指針變量所存儲的值)
I am the pointer of string
2.但是不能將void*類型的值賦給其他既定的類型,除非經(jīng)過顯示轉(zhuǎn)換: 例如:
int a=20;
int * pr=&a;
void *p;
pr=p //error,不能將空的類型賦給int *
pr=(int
*)p; //ok,經(jīng)過轉(zhuǎn)換
begin with first request : web.xml - init
end when container is hsut down: web.xml - destroy
By default setting: each Servlet has a Threadpool to support multithreads.
Class loader priority is bootstrap >extension >application (or system)
1. bootstrap: 主要是負責裝載jre/lib下的jar文件,當然,你也可以通過-Xbootclasspath參數(shù)定義。該ClassLoader不能被Java代碼實例化,因為它是JVM本身的一部分
2. extension: 該ClassLoader是Bootstrap classLoader的子class
loader。它主要負責加載jre/lib/ext/下的所有jar文件。只要jar包放置這個位置,就會被虛擬機加載。一個常見的、類似的問題是,你
將mysql的低版本驅(qū)動不小心放置在這兒,但你的Web應用程序的lib下有一個新的jdbc驅(qū)動,但怎么都報錯,譬如不支持JDBC2.0的
DataSource,這時你就要當心你的新jdbc可能并沒有被加載。這就是ClassLoader的delegate現(xiàn)象。常見的有l(wèi)og4j、
common-log、dbcp會出現(xiàn)問題,因為它們很容易被人塞到這個ext目錄,或是Tomcat下的common/lib目錄。
3. application loader: 也稱為System
ClassLoaer。它負責加載CLASSPATH環(huán)境變量下的classes。缺省情況下,它是用戶創(chuàng)建的任何ClassLoader的父
ClassLoader,我們創(chuàng)建的standalone應用的main
class缺省情況下也是由它加載(通過Thread.currentThread().getContextClassLoader()查看)。
我們實際開發(fā)中,用ClassLoader更多時候是用其加載classpath下的資源,特別是配置文件,如ClassLoader.getResource(),比FileInputStream直接。
ClassLoader是一種分級(hierarchy)的代理(delegation)模型。
Delegation:其實是Parent
Delegation,當需要加載一個class時,當前線程的ClassLoader首先會將請求代理到其父classLoader,遞歸向上,如果該
class已經(jīng)被父classLoader加載,那么直接拿來用,譬如典型的ArrayList,它最終由Bootstrap
ClassLoader加載。并且,每個ClassLoader只有一個父ClassLoader。
Class查找的位置和順序依次是:Cache、parent、self。
Hierarchy:
上面的delegation已經(jīng)暗示了一種分級結(jié)構(gòu),同時它也說明:一個ClassLoader只能看到被它自己加載的
classes,或是看到其父(parent) ClassLoader或祖先(ancestor) ClassLoader加載的Classes。
在一個單虛擬機環(huán)境下,標識一個類有兩個因素:class的全路徑名、該類的ClassLoader。
===================Tomcat Class Loading==========================================
class A
{
void f
() { System.
out.
println("A: doing f()");
}
void g
() { System.
out.
println("A: doing g()");
}
}
class C
{
// delegation
A a =
new A
();
void f
() { a.
f();
}
void g
() { a.
g();
}
// normal attributes
X x =
new X
();
void y
() { /* do stuff */ }
}
public class Main
{
public static void main
(String[] args
) {
C c =
new C
();
c.
f();
c.
g();
}
}
代理模式
Proxy Pattern's 3 roles:
1. (abstract common)Subject:common interface
2. ProxySubject:含有the reference to the RealSubject //delegation
3. RealSubject:實現(xiàn)邏輯的類
類圖如下:

圖1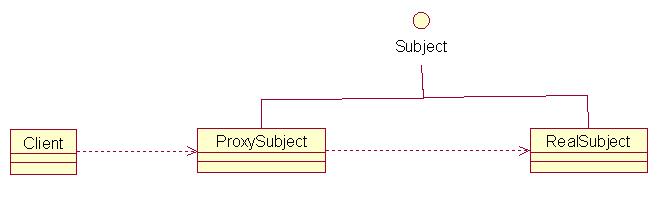
Java 動態(tài)代理
從JDK1.3開始,Java就引入了動態(tài)代理的概念。動態(tài)代理(Dynamic Proxy)可以幫助你減少代碼行數(shù),真正提高代碼的可復用度。
類圖如下:

圖2 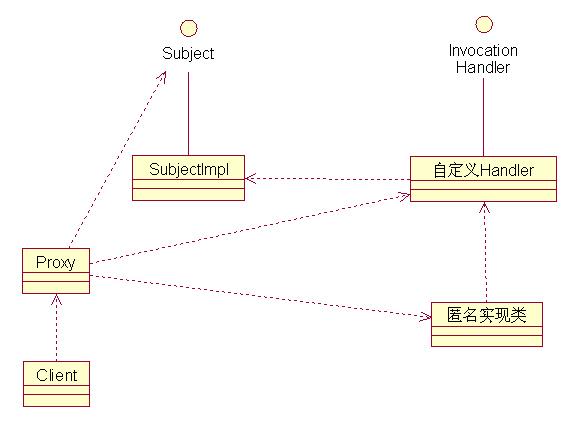
動態(tài)代理和普通的代理模式的區(qū)別,就是動態(tài)代理中的代理類是由java.lang.reflect.Proxy類在運行期時根據(jù)接口定義,采用Java反射功能動態(tài)生成的(圖2的匿名實現(xiàn)類)。和java.lang.reflect.InvocationHandler結(jié)合,可以加強現(xiàn)有類的方法實現(xiàn)。如圖2,圖中的自定義Handler實現(xiàn)InvocationHandler接口,自定義Handler實例化時,將實現(xiàn)類傳入自定義Handler對象。自定義Handler需要實現(xiàn)invoke方法,該方法可以使用Java反射調(diào)用實現(xiàn)類的實現(xiàn)的方法,同時當然可以實現(xiàn)其他功能,例如在調(diào)用實現(xiàn)類方法前后加入Log。而Proxy類根據(jù)Handler和需要代理的接口動態(tài)生成一個接口實現(xiàn)類的對象。當用戶調(diào)用這個動態(tài)生成的實現(xiàn)類時,實際上是調(diào)用了自定義Handler的invoke方法。
下面是使用動態(tài)代理的步驟:
1. Client向Proxy請求一個具有某個功能的實例;
2. Proxy根據(jù)Subject,以自定義Handler創(chuàng)建一個匿名內(nèi)部類,并返回給Client;
3. Client獲取該匿名內(nèi)部類的引用,調(diào)用在Subject接口種定義的方法;
4. 匿名內(nèi)部類將對方法的調(diào)用轉(zhuǎn)換為對自定義Handler中invoke方法的調(diào)用
5. invoke方法根據(jù)一些規(guī)則做處理,如記錄log,然后調(diào)用SubjectImpl中的方法
Examples
Here is a simple example that prints out a message before and after a method invocation on an object that implements an arbitrary list of interfaces:
public interface Foo {
Object bar(Object obj) throws BazException;
}
public class FooImpl implements Foo {
Object bar(Object obj) throws BazException {
// ...
}
}
public class DebugProxy implements java.lang.reflect.InvocationHandler {
private Object obj;
public static Object newInstance(Object obj) {
return java.lang.reflect.Proxy.newProxyInstance(
obj.getClass().getClassLoader(),
obj.getClass().getInterfaces(),
new DebugProxy(obj));
}
private DebugProxy(Object obj) {
this.obj = obj;
}
public Object invoke(Object proxy, Method m, Object[] args)
throws Throwable
{
Object result;
try {
System.out.println("before method " + m.getName());
result = m.invoke(obj, args);
} catch (InvocationTargetException e) {
throw e.getTargetException();
} catch (Exception e) {
throw new RuntimeException("unexpected invocation exception: " +
e.getMessage());
} finally {
System.out.println("after method " + m.getName());
}
return result;
}
}
To construct a DebugProxy for an implementation of the Foo interface and call one of its methods:
Foo foo = (Foo) DebugProxy.newInstance(new FooImpl());
foo.bar(null);
前言
linux有自己一套完整的啟動體系,抓住了linux啟動的脈絡(luò),linux的啟動過程將不再神秘。
閱讀之前建議先看一下附圖。
本文中假設(shè)inittab中設(shè)置的init tree為:
/etc/rc.d/rc0.d
/etc/rc.d/rc1.d
/etc/rc.d/rc2.d
/etc/rc.d/rc3.d
/etc/rc.d/rc4.d
/etc/rc.d/rc5.d
/etc/rc.d/rc6.d
/etc/rc.d/init.d
目錄
1. 關(guān)于linux的啟動
2. 關(guān)于rc.d
3. 啟動腳本示例
4. 關(guān)于rc.local
5. 關(guān)于bash啟動腳本
6. 關(guān)于開機程序的自動啟動
1. 關(guān)于linux的啟動
init是所有進程之父
init讀取/etc/inittab,執(zhí)行rc.sysinit腳本
(注意文件名是不一定的,有些unix甚至會將語句直接寫在inittab中)
rc.sysinit腳本作了很多工作:
init $PATH
config network
start swap function
set hostname
check root file system, repair if needed
check root space
....
rc.sysinit根據(jù)inittab執(zhí)行rc?.d腳本
linux是多用戶系統(tǒng),getty是多用戶與單用戶的分水嶺
在getty之前運行的是系統(tǒng)腳本
2. 關(guān)于rc.d
所有啟動腳本放置在 /etc/rc.d/init.d下
rc?.d中放置的是init.d中腳本的鏈接,命名格式是:
S{number}{name}
K{number}{name}
S開始的文件向腳本傳遞start參數(shù)
K開始的文件向腳本傳遞stop參數(shù)
number決定執(zhí)行的順序
3. 啟動腳本示例
這是一個用來啟動httpd的 /etc/rc.d/init.d/apache 腳本:
代碼:
#!/bin/bash
source /etc/sysconfig/rc
source $rc_functions
case "$1" in
start)
echo "Starting Apache daemon..."
/usr/local/apache2/bin/apachectl -k start
evaluate_retval
;;
stop)
echo "Stopping Apache daemon..."
/usr/local/apache2/bin/apachectl -k stop
evaluate_retval
;;
restart)
echo "Restarting Apache daemon..."
/usr/local/apache2/bin/apachectl -k restart
evaluate_retval
;;
status)
statusproc /usr/local/apache2/bin/httpd
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
exit 1
;;
esac
可以看出他接受start,stop,restart,status參數(shù)
然后可以這樣建立rc?.d的鏈接:
代碼:
cd /etc/rc.d/init.d &&
ln -sf ../init.d/apache ../rc0.d/K28apache &&
ln -sf ../init.d/apache ../rc1.d/K28apache &&
ln -sf ../init.d/apache ../rc2.d/K28apache &&
ln -sf ../init.d/apache ../rc3.d/S32apache &&
ln -sf ../init.d/apache ../rc4.d/S32apache &&
ln -sf ../init.d/apache ../rc5.d/S32apache &&
ln -sf ../init.d/apache ../rc6.d/K28apache
4. 關(guān)于rc.local
經(jīng)常使用的 rc.local 則完全是習慣問題,不是標準。
各個發(fā)行版有不同的實現(xiàn)方法,可以這樣實現(xiàn):
代碼:
touch /etc/rc.d/rc.local
chmod +x /etc/rc.d/rc.local
ln -sf /etc/rc.d/rc.local /etc/rc.d/rc1.d/S999rc.local &&
ln -sf /etc/rc.d/rc.local /etc/rc.d/rc2.d/S999rc.local &&
ln -sf /etc/rc.d/rc.local /etc/rc.d/rc3.d/S999rc.local &&
ln -sf /etc/rc.d/rc.local /etc/rc.d/rc4.d/S999rc.local &&
ln -sf /etc/rc.d/rc.local /etc/rc.d/rc5.d/S999rc.local &&
ln -sf /etc/rc.d/rc.local /etc/rc.d/rc6.d/S999rc.local
5. 關(guān)于bash啟動腳本
/etc/profile
/etc/bashrc
~/.bash_profile
~/.bashrc
是bash的啟動腳本
一般用來設(shè)置單用戶的啟動環(huán)境,也可以實現(xiàn)開機單用戶的程序,但要明確他們都是屬于bash范疇而不是系統(tǒng)范疇。
他們的具體作用介紹如下:
/bin/bash這個命令解釋程序(后面簡稱shell)使用了一系列啟動文件來建立一個運行環(huán)境:
/etc/profile
/etc/bashrc
~/.bash_profile
~/.bashrc
~/.bash_logout
每一個文件都有特殊的功用并對登陸和交互環(huán)境有不同的影響。
/etc/profile 和 ~/.bash_profile 是在啟動一個交互登陸shell的時候被調(diào)用。
/etc/bashrc 和 ~/.bashrc 是在一個交互的非登陸shell啟動的時候被調(diào)用。
~/.bash_logout 在用戶注銷登陸的時候被讀取
一個交互的登陸shell會在 /bin/login 成功登陸之后運行。一個交互的非登陸shell是通過命令行來運行的,如
[prompt]$/bin/bash。一般一個非交互的shell出現(xiàn)在運行shell腳本的時候。之所以叫非交互的shell,是因為它不在命令行上
等待輸入而只是執(zhí)行腳本程序。
=====================================================================================================
本文以RedHat9.0和i386平臺為例,剖析了從用戶打開電源直到屏幕出現(xiàn)命令行提示符的整個Linux啟動過程。并且介紹了啟動中涉及到的各種文件。
閱讀Linux源代碼,無疑是深入學習Linux的最好方法。在本文對Linux啟動過程的介紹中,我們也嘗試從源代碼的視角來更深入的剖析Linux的啟動過程,所以其中也簡單涉及到部分相關(guān)的Linux源代碼,Linux啟動這部分的源碼主要使用的是C語言,也涉及到了少量的匯編。而啟動過程中也執(zhí)行了大量的shell(主要是bash shell)所寫腳本。為了方便讀者閱讀,筆者將整個Linux啟動過程分成以下幾個部分逐一介紹,大家可以參考下圖:
當用戶打開PC的電源,BIOS開機自檢,按BIOS中設(shè)置的啟動設(shè)備(通常是硬盤)啟動,接著啟動設(shè)備上安裝的引導程序lilo
或grub開始引導Linux,Linux首先進行內(nèi)核的引導,接下來執(zhí)行init程序,init程序調(diào)用了rc.sysinit和rc等程
序,rc.sysinit和rc當完成系統(tǒng)初始化和運行服務的任務后,返回init;init啟動了mingetty后,打開了終端供用戶登錄系統(tǒng),用戶
登錄成功后進入了Shell,這樣就完成了從開機到登錄的整個啟動過程。

下面就將逐一介紹其中幾個關(guān)鍵的部分:
第一部分:內(nèi)核的引導(核內(nèi)引導)
Red Hat9.0可以使用lilo或grub等引導程序開
始引導Linux系統(tǒng),當引導程序成功完成引導任務后,Linux從它們手中接管了CPU的控制權(quán),然后CPU就開始執(zhí)行Linux的核心映象代碼,開始
了Linux啟動過程。這里使用了幾個匯編程序來引導Linux,這一步泛及到Linux源代碼樹中的“arch/i386/boot”下的這幾個文
件:bootsect.S、setup.S、video.S等。
其中bootsect.S是生成引導扇區(qū)的匯編源碼,它完成加載動作后直接跳轉(zhuǎn)到setup.S的程序入口。setup.S的主要功能就是將系
統(tǒng)參數(shù)(包括內(nèi)存、磁盤等,由BIOS返回)拷貝到特別內(nèi)存中,以便以后這些參數(shù)被保護模式下的代碼來讀取。此外,setup.S還將video.S中的
代碼包含進來,檢測和設(shè)置顯示器和顯示模式。最后,setup.S將系統(tǒng)轉(zhuǎn)換到保護模式,并跳轉(zhuǎn)到 0x100000。
那么0x100000這個內(nèi)存地址中存放的是什么代碼?而這些代碼又是從何而來的呢?
0x100000這個內(nèi)存地址存放的是解壓后的內(nèi)核,因為Red Hat提供的內(nèi)核包含了眾多驅(qū)動和
功能而顯得比較大,所以在內(nèi)核編譯中使用了“makebzImage”方式,從而生成壓縮過的內(nèi)核,在RedHat中內(nèi)核常常被命名為vmlinuz,在
Linux的最初引導過程中,是通過"arch/i386/boot/compressed/"中的head.S利用misc.c中定義的
decompress_kernel()函數(shù),將內(nèi)核vmlinuz解壓到0x100000的。
當CPU跳到0x100000時,將執(zhí)行"arch/i386/kernel/head.S"中的startup_32,它也是vmlinux
的入口,然后就跳轉(zhuǎn)到start_kernel()中去了。start_kernel()是"init/main.c"中的定義的函
數(shù),start_kernel()中調(diào)用了一系列初始化函數(shù),以完成kernel本身的設(shè)置。start_kernel()函數(shù)中,做了大量的工作來建立
基本的Linux核心環(huán)境。如果順利執(zhí)行完start_kernel(),則基本的Linux核心環(huán)境已經(jīng)建立起來了。
在start_kernel()的最后,通過調(diào)用init()函數(shù),系統(tǒng)創(chuàng)建第一個核心線程,啟動了init過程。而核心線程init()主要
是來進行一些外設(shè)初始化的工作的,包括調(diào)用do_basic_setup()完成外設(shè)及其驅(qū)動程序的加載和初始化。并完成文件系統(tǒng)初始化和root文件系
統(tǒng)的安裝。
當do_basic_setup()函數(shù)返回init(),init()又打開了/dev/console設(shè)備,重定向三個標準的輸入輸出文件
stdin、stdout和stderr到控制臺,最后,搜索文件系統(tǒng)中的init程序(或者由init=命令行參數(shù)指定的程序),并使用
execve()系統(tǒng)調(diào)用加載執(zhí)行init程序。到此init()函數(shù)結(jié)束,內(nèi)核的引導部分也到此結(jié)束了,
第二部分:運行init
init的進程號是1,從這一點就能看出,init進程是系統(tǒng)所有進程的起點,Linux在完成核內(nèi)引導以后,就開始運行init程序,。init程序需要讀取配置文件/etc/inittab。inittab是一個不可執(zhí)行的文本文件,它有若干行指令所組成。在Redhat系統(tǒng)中,inittab的內(nèi)容如下所示(以“###"開始的中注釋為筆者增加的):
#
# inittab This file describes how the INIT process should set up
# the system in a certain run-level.
#
# Author: Miquel van Smoorenburg, <miquels@drinkel.nl.mugnet.org>
# Modified for RHS Linux by Marc Ewing and Donnie Barnes
#
# Default runlevel. The runlevels used by RHS are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not havenetworking)
# 3 - Full multiuser mode
# 4 - unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
#
###表示當前缺省運行級別為5(initdefault);
id:5:initdefault:
###啟動時自動執(zhí)行/etc/rc.d/rc.sysinit腳本(sysinit)
# System initialization.
si::sysinit:/etc/rc.d/rc.sysinit
l0:0:wait:/etc/rc.d/rc 0
l1:1:wait:/etc/rc.d/rc 1
l2:2:wait:/etc/rc.d/rc 2
l3:3:wait:/etc/rc.d/rc 3
l4:4:wait:/etc/rc.d/rc 4
###當運行級別為5時,以5為參數(shù)運行/etc/rc.d/rc腳本,init將等待其返回(wait)
l5:5:wait:/etc/rc.d/rc 5
l6:6:wait:/etc/rc.d/rc 6
###在啟動過程中允許按CTRL-ALT-DELETE重啟系統(tǒng)
# Trap CTRL-ALT-DELETE
ca::ctrlaltdel:/sbin/shutdown -t3 -r now
# When our UPS tells us power has failed, assume we have a few minutes
# of power left. Schedule a shutdown for 2 minutes from now.
# This does, of course, assume you have powerd installed and your
# UPS connected and working correctly.
pf::powerfail:/sbin/shutdown -f -h +2 "Power Failure; System Shutting Down"
# If power was restored before the shutdown kicked in, cancel it.
pr:12345:powerokwait:/sbin/shutdown -c "Power Restored; Shutdown Cancelled"
###在2、3、4、5級別上以ttyX為參數(shù)執(zhí)行/sbin/mingetty程序,打開ttyX終端用于用戶登錄,
###如果進程退出則再次運行mingetty程序(respawn)
# Run gettys in standard runlevels
1:2345:respawn:/sbin/mingetty tty1
2:2345:respawn:/sbin/mingetty tty2
3:2345:respawn:/sbin/mingetty tty3
4:2345:respawn:/sbin/mingetty tty4
5:2345:respawn:/sbin/mingetty tty5
6:2345:respawn:/sbin/mingetty tty6
###在5級別上運行xdm程序,提供xdm圖形方式登錄界面,并在退出時重新執(zhí)行(respawn)
# Run xdm in runlevel 5
x:5:respawn:/etc/X11/prefdm -nodaemon
以上面的inittab文件為例,來說明一下inittab的格式。其中以#開始的行是注釋行,除了注釋行之外,每一行都有以下格式:
id:runlevel:action:process
對上面各項的詳細解釋如下:
1. id
id是指入口標識符,它是一個字符串,對于getty或mingetty等其他login程序項,要求id與tty的編號相同,否則getty程序?qū)⒉荒苷9ぷ鳌?/p>
2. runlevel
runlevel是init所處于的運行級別的標識,一般使用0-6以及S或s。0、1、6運行級別被系統(tǒng)保留:其中0作為shutdown動
作,1作為重啟至單用戶模式,6為重啟;S和s意義相同,表示單用戶模式,且無需inittab文件,因此也不在inittab中出現(xiàn),實際上,進入單用
戶模式時,init直接在控制臺(/dev/console)上運行/sbin/sulogin。在一般的系統(tǒng)實現(xiàn)中,都使用了2、3、4、5幾個級別,
在Redhat系統(tǒng)中,2表示無NFS支持的多用戶模式,3表示完全多用戶模式(也是最常用的級別),4保留給用戶自定義,5表示XDM圖形登錄方式。
7-9級別也是可以使用的,傳統(tǒng)的Unix系統(tǒng)沒有定義這幾個級別。runlevel可以是并列的多個值,以匹配多個運行級別,對大多數(shù)action來
說,僅當runlevel與當前運行級別匹配成功才會執(zhí)行。
3. action
action是描述其后的process的運行方式的。action可取的值包括:initdefault、sysinit、boot、bootwait等:
initdefault是一個特殊的action值,用于標識缺省的啟動級別;當init由核心激活以后,它將讀取inittab中的
initdefault項,取得其中的runlevel,并作為當前的運行級別。如果沒有inittab文件,或者其中沒有initdefault
項,init將在控制臺上請求輸入runlevel。
sysinit、boot、bootwait等action將在系統(tǒng)啟動時無條件運行,而忽略其中的runlevel。
其余的action(不含initdefault)都與某個runlevel相關(guān)。各個action的定義在inittab的man手冊中有詳細的描述。
4. process
process為具體的執(zhí)行程序。程序后面可以帶參數(shù)。
第三部分:系統(tǒng)初始化
在init的配置文件中有這么一行:
si::sysinit:/etc/rc.d/rc.sysinit
它調(diào)用執(zhí)行了/etc/rc.d/rc.sysinit,而rc.sysinit是一個bash shell的腳本,它主要是完成一些系統(tǒng)初始化的工作,rc.sysinit是每一個運行級別都要首先運行的重要腳本。它主要完成的工作有:激活交換分區(qū),檢查磁盤,加載硬件模塊以及其它一些需要優(yōu)先執(zhí)行任務。
rc.sysinit約有850多行,但是每個單一的功能還是比較簡單,而且?guī)в凶⑨專ㄗh有興趣的用戶可以自行閱讀自己機器上的該文件,以了解系統(tǒng)初始化所詳細情況。由于此文件較長,所以不在本文中列出來,也不做具體的介紹。
當rc.sysinit程序執(zhí)行完畢后,將返回init繼續(xù)下一步。
第四部分:啟動對應運行級別的守護進程
在rc.sysinit執(zhí)行后,將返回init繼續(xù)其它的動作,通常接下來會執(zhí)行到/etc/rc.d/rc程序。以運行級別3為例,init將執(zhí)行配置文件inittab中的以下這行:
l5:5:wait:/etc/rc.d/rc 5
這一行表示以5為參數(shù)運行/etc/rc.d/rc,/etc/rc.d/rc是一個Shell腳本,它接受5作為參數(shù),去執(zhí)行/etc
/rc.d/rc5.d/目錄下的所有的rc啟動腳本,/etc/rc.d/rc5.d/目錄中的這些啟動腳本實際上都是一些鏈接文件,而不是真正的rc
啟動腳本,真正的rc啟動腳本實際上都是放在/etc/rc.d/init.d/目錄下。而這些rc啟動腳本有著類似的用法,它們一般能接受start、
stop、restart、status等參數(shù)。
/etc/rc.d/rc5.d/中的rc啟動腳本通常是K或S開頭的鏈接文件,對于以以S開頭的啟動腳本,將以start參數(shù)來運行。而如果
發(fā)現(xiàn)存在相應的腳本也存在K打頭的鏈接,而且已經(jīng)處于運行態(tài)了(以/var/lock/subsys/下的文件作為標志),則將首先以stop為參數(shù)停止
這些已經(jīng)啟動了的守護進程,然后再重新運行。這樣做是為了保證是當init改變運行級別時,所有相關(guān)的守護進程都將重啟。
至于在每個運行級中將運行哪些守護進程,用戶可以通過chkconfig或setup中的"System Services"來自行設(shè)定。常見的守護進程有:
amd:自動安裝NFS守護進程
apmd:高級電源管理守護進程
arpwatch:記錄日志并構(gòu)建一個在LAN接口上看到的以太網(wǎng)地址和IP地址對數(shù)據(jù)庫
autofs:自動安裝管理進程automount,與NFS相關(guān),依賴于NIS
crond:Linux下的計劃任務的守護進程
named:DNS服務器
netfs:安裝NFS、Samba和NetWare網(wǎng)絡(luò)文件系統(tǒng)
network:激活已配置網(wǎng)絡(luò)接口的腳本程序
nfs:打開NFS服務
portmap:RPC portmap管理器,它管理基于RPC服務的連接
sendmail:郵件服務器sendmail
smb:Samba文件共享/打印服務
syslog:一個讓系統(tǒng)引導時起動syslog和klogd系統(tǒng)日志守候進程的腳本
xfs:X Window字型服務器,為本地和遠程X服務器提供字型集
Xinetd:支持多種網(wǎng)絡(luò)服務的核心守護進程,可以管理wuftp、sshd、telnet等服務
這些守護進程也啟動完成了,rc程序也就執(zhí)行完了,然后又將返回init繼續(xù)下一步。
第五部分:建立終端
rc執(zhí)行完畢后,返回init。這時基本系統(tǒng)環(huán)境已經(jīng)設(shè)置好了,各種守護進程也已經(jīng)啟動了。init接下來會打開6個終端,以便用戶登錄系統(tǒng)。通過按Alt+Fn(n對應1-6)可以在這6個終端中切換。在inittab中的以下6行就是定義了6個終端:
1:2345:respawn:/sbin/mingetty tty1
2:2345:respawn:/sbin/mingetty tty2
3:2345:respawn:/sbin/mingetty tty3
4:2345:respawn:/sbin/mingetty tty4
5:2345:respawn:/sbin/mingetty tty5
6:2345:respawn:/sbin/mingetty tty6
從上面可以看出在2、3、4、5的運行級別中都將以respawn方式運行mingetty程序,mingetty程序能打開終端、設(shè)置模式。同時它會顯示一個文本登錄界面,這個界面就是我們經(jīng)常看到的登錄界面,在這個登錄界面中會提示用戶輸入用戶名,而用戶輸入的用戶將作為參數(shù)傳給login程序來驗證用戶的身份。
第六部分:登錄系統(tǒng),啟動完成
對于運行級別為5的圖形方式用戶來說,他們的登錄是通過一個圖形化的登錄界面。登錄成功后可以直接進入KDE、Gnome等窗口管理器。而本文主要講的還是文本方式登錄的情況:
當我們看到mingetty的登錄界面時,我們就可以輸入用戶名和密碼來登錄系統(tǒng)了。
Linux的賬號驗證程序是
login,login會接收mingetty傳來的用戶名作為用戶名參數(shù)。然后login會對用戶名進行分析:如果用戶名不是root,且存在/etc
/nologin文件,login將輸出nologin文件的內(nèi)容,然后退出。這通常用來系統(tǒng)維護時防止非root用戶登錄。只有/etc
/securetty中登記了的終端才允許root用戶登錄,如果不存在這個文件,則root可以在任何終端上登錄。/etc/usertty文件用于對
用戶作出附加訪問限制,如果不存在這個文件,則沒有其他限制。
在分析完用戶名后,login將搜索/etc/passwd以及/etc/shadow來驗證密碼以及設(shè)置賬戶的其它信息,比如:主目錄是什么、使用何種shell。如果沒有指定主目錄,將默認為根目錄;如果沒有指定shell,將默認為/bin/bash。
login程序成功后,會向?qū)慕K端在輸出最近一次登錄的信息(在/var/log/lastlog中有記錄),并檢查用戶是否有新郵件(在
/usr/spool/mail/的對應用戶名目錄下)。然后開始設(shè)置各種環(huán)境變量:對于bash來說,系統(tǒng)首先尋找/etc/profile腳本文件,
并執(zhí)行它;然后如果用戶的主目錄中存在.bash_profile文件,就執(zhí)行它,在這些文件中又可能調(diào)用了其它配置文件,所有的配置文件執(zhí)行后后,各種
環(huán)境變量也設(shè)好了,這時會出現(xiàn)大家熟悉的命令行提示符,到此整個啟動過程就結(jié)束了。
希望通過上面對Linux啟動過程的剖析能幫助那些想深入學習Linux用戶建立一個相關(guān)Linux啟動過程的清晰概念,進而可以進一步研究Linux接下來是如何工作的。
===============Tomcat setting -- enable JPDA debugging================================
>cd %CATALINA_HOME%\bin
>SET CATALINA_OPTS=-server -Xdebug -Xnoagent -Djava.compiler=NONE -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=5888
>catalina start
================Eclipse Setting===================================================
Debug Configuration->Remote Java Application->new
--Connect--
Name: Debug Tomcat
Project: jpetstore (which project is copied to the tomcat)
Host: localhost
Port: 5888
--Source--
all libs and src (此時可以看到程序會停在本機設(shè)的斷點上,要提醒的是我們程序?qū)嶋H是跑在服務器上的,卻能使用本機的斷點,挺奇妙的!
)
spring mvc 這部機器 說白了其實很簡單,DispatcherServlet 把 HandlerMapping Controller ViewResolver 3個組件 組裝在一起就完成了整個處理過程。
想起來就像人吃飯一樣。把飯放入嘴巴,經(jīng)過喉嚨,然后到胃里,處理一下,再接著往下傳,到腸子 最后把處理的結(jié)果 排泄出來。呵呵,惡心一把

當然還吸收了一些,這就類似存了一些數(shù)據(jù)到數(shù)據(jù)庫。說白了還真這么回事。
Linux/Unix 區(qū)別于微軟平臺最大的優(yōu)點就是真正的多用戶,多任務。因此在任務管理上也有別具特色的管理思想。
我們知道,在 Windows 上面,我們要么讓一個程序作為服務在后臺一直運行,要么停止這個服務。而不能讓程序在前臺后臺之間切換。而 Linux 提供了 fg 和 bg 命令,讓你輕松調(diào)度正在運行的任務。
假設(shè)你發(fā)現(xiàn)前臺運行的一個程序需要很長的時間,但是需要干其他的事情,你就可以用 Ctrl-Z ,終止這個程序,然后可以看到系統(tǒng)提示:
[1]+ Stopped /root/bin/rsync.sh
然后我們可以把程序調(diào)度到后臺執(zhí)行:(bg 后面的數(shù)字為作業(yè)號)
#bg 1
[1]+ /root/bin/rsync.sh &
用 jobs 命令查看正在運行的任務:
#jobs
[1]+ Running /root/bin/rsync.sh &
如果想把它調(diào)回到前臺運行,可以用
#fg 1
/root/bin/rsync.sh
這樣,你在控制臺上就只能等待這個任務完成了。
Vi: Search and Replace
Change to normal mode with <ESC>.
Search (Wraped around at end of file):
Search STRING forward : / STRING.
Search STRING backward: ? STRING.
Repeat search: n
Repeat search in opposite direction: N (SHIFT-n
Replace: Same as with sed,
Replace OLD with NEW:
First occurrence on current line: :s/OLD/NEW
Globally (all) on current line: :s/OLD/NEW/g
Between two lines #,#: :#,#s/OLD/NEW/g
Every occurrence in file: :%s/OLD/NEW/g
1 基本解釋
extern可以置于變量或者函數(shù)前,以標示變量或者函數(shù)的定義在別的文件中,提示編譯器遇到此變量和函數(shù)時在其他模塊中尋找其定義。
另外,extern也可用來進行鏈接指定。
2 問題:extern 變量
在一個源文件里定義了一個數(shù)組:
在另外一個文件里用下列語句進行了聲明:
請問,這樣可以嗎?
答案與分析:
1)、不可以,
程序運行時會告訴你非法訪問。原因在于,指向類型T的指針并不等價于類型T的數(shù)組。extern char *a聲明的是一個指針變量而不是字符數(shù)組,因此與實際的定義不同,從而造成運行時非法訪問。應該將聲明改為extern char a[ ]。
2)、例子分析如下,如果a[] = "abcd",則外部變量a=0x61626364 (abcd的ASCII碼值),*a顯然沒有意義,如下圖:
顯然a指向的空間(0x61626364)沒有意義,易出現(xiàn)非法內(nèi)存訪問。
3)、這提示我們,在使用extern時候要嚴格對應聲明時的格式,在實際編程中,這樣的錯誤屢見不鮮。
4)、extern用在變量聲明中常常有這樣一個作用,你在*.c文件中聲明了一個全局的變量,這個全局的變量如果要被引用,就放在*.h中并用extern來聲明。
3 問題:extern 函數(shù)1
常常見extern放在函數(shù)的前面成為函數(shù)聲明的一部分,那么,C語言的關(guān)鍵字extern在函數(shù)的聲明中起什么作用?
答案與分析:
如果函數(shù)的聲明中帶有關(guān)鍵字extern,僅僅是暗示這個函數(shù)可能在別的源文件里定義,沒有其它作用。即下述兩個函數(shù)聲明沒有明顯的區(qū)別:
| extern int f(); 和int f(); |
當然,這樣的用處還是有的,就是在程序中取代include “*.h”來聲明函數(shù),在一些復雜的項目中,我比較習慣在所有的函數(shù)聲明前添加extern修飾。
4 問題:extern 函數(shù)2
當函數(shù)提供方單方面修改函數(shù)原型時,如果使用方不知情繼續(xù)沿用原來的extern申明,這樣編譯時編譯器不會報錯。但是在運行過程中,因為少了或者多了輸入?yún)?shù),往往會照成系統(tǒng)錯誤,這種情況應該如何解決?
答案與分析:
目前業(yè)界針對這種情況的處理沒有一個很完美的方案,通常的做法是提供方在自己的xxx_pub.h中提供對外部接口的聲明,然后調(diào)用方include該頭文件,從而省去extern這一步。以避免這種錯誤。
寶劍有雙鋒,對extern的應用,不同的場合應該選擇不同的做法。
===============================================================================
4.extern "C"的慣用法
(1)在C++中引用C語言中的函數(shù)和變量,在包含C語言頭文件(假設(shè)為cExample.h)時,需進行下列處理:
extern "C"
{
#include "cExample.h"
}
而在C語言的頭文件中,對其外部函數(shù)只能指定為extern類型,C語言中不支持extern "C"聲明,在.c文件中包含了extern "C"時會出現(xiàn)編譯語法錯誤。
筆者編寫的C++引用C函數(shù)例子工程中包含的三個文件的源代碼如下:
- C/C++ code
-
/* c語言頭文件:cExample.h */
#ifndef C_EXAMPLE_H
#define C_EXAMPLE_H
extern int add(int x,int y);
#endif
/* c語言實現(xiàn)文件:cExample.c */
#include "cExample.h"
int add( int x, int y )
{
return x + y;
}
// c++實現(xiàn)文件,調(diào)用add:cppFile.cpp
extern "C"
{
#include "cExample.h"
}
int main(int argc, char* argv[])
{
add(2,3);
return 0;
}
如果C++調(diào)用一個C語言編寫的.DLL時,當包括.DLL的頭文件或聲明接口函數(shù)時,應加extern "C" { }。
(2)在C中引用C++語言中的函數(shù)和變量時,C++的頭文件需添加extern "C",但是在C語言中不能直接引用聲明了extern "C"的該頭文件,應該僅將C文件中將C++中定義的extern "C"函數(shù)聲明為extern類型。
筆者編寫的C引用C++函數(shù)例子工程中包含的三個文件的源代碼如下:
//C++頭文件 cppExample.h
#ifndef CPP_EXAMPLE_H
#define CPP_EXAMPLE_H
extern "C" int add( int x, int y );
#endif
//C++實現(xiàn)文件 cppExample.cpp
#include "cppExample.h"
int add( int x, int y )
{
return x + y;
}
/* C實現(xiàn)文件 cFile.c
/* 這樣會編譯出錯:#include "cExample.h" */
extern int add( int x, int y );
int main( int argc, char* argv[] )
{
add( 2, 3 );
return 0;
}
Linux : "highlighted" means "copy", "middle mouse" means "paste"
To make Xming's clipboard work
change /etc/init.d/custom.conf
in [daemon]
KillInitClients=false
常引用
常引用聲明方式:const 類型標識符 &引用名=目標變量名;
用這種方式聲明的引用,不能通過引用對目標變量的值進行修改,從而使引用的目標成為
const,達到了引用的安全性。
【例3】:
int a ;
const int &ra=a;
ra=1; //錯誤
a=1; //正確
這不光是讓代碼更健壯,也有些其它方面的需要。
【例4】:假設(shè)有如下函數(shù)聲明:
string foo( );
void bar(string & s);
那么下面的表達式將是非法的:
bar(foo( ));
bar("hello world");
原因在于foo( )和"hello world"串都會產(chǎn)生一個臨時對象,而在C++中,這些臨時對象都是
const 類型的。因此上面的表達式就是試圖將一個const 類型的對象轉(zhuǎn)換為非const 類型,
這是非法的。
引用型參數(shù)應該在能被定義為const 的情況下,盡量定義為const 。
1.test測試命令
test命令用于檢查某個條件是否成立,它可以進行數(shù)值、字符和文件三個方面的測試,
其測試符和相應的功能分別如下:
(1)數(shù)值測試:
-eq:等于則為真
-ne:不等于則為真
-gt:大于則為真
-ge:大于等于則為真
-lt:小于則為真
-le:小于等于則為真
(2)字符串測試:
=:等于則為真
!=:不相等則為真
-z 字符串:字符串長度偽則為真
-n 字符串:字符串長度不偽則為真
(3)文件測試:
-e 文件名:如果文件存在則為真
-r 文件名:如果文件存在且可讀則為真
-w 文件名:如果文件存在且可寫則為真
-x 文件名:如果文件存在且可執(zhí)行則為真
-s 文件名:如果文件存在且至少有一個字符則為真
-d 文件名:如果文件存在且為目錄則為真
-f 文件名:如果文件存在且為普通文件則為真
-c 文件名:如果文件存在且為字符型特殊文件則為真
-b 文件名:如果文件存在且為塊特殊文件則為真
另外,Linux還提供了與(“!”)、或(“-o)、非(“-a”)三個邏輯操作符用于將測試條件連接起來,
其優(yōu)先級為:“!”最高,“-a”次之,“-o”最低。
同時,bash也能完成簡單的算術(shù)運算,格式如下:
$[expression]
例如:var1=2
var2=$[var1*10+1]
則:var2的值為21。
2.if條件語句
if [ -x /sbin/quotaon ]; then
echo "Turning on Quota for root filesystem"
/sbin/quotaon /
elif [ -x /sbin/quotaon ]; then
/usr/bin/bash
else
echo "ok"
fi
3.for 循環(huán)
#!/bin/sh
WORD="a b c d e f g h i j l m n o p q r s t u v w x y z"
for i in $WORD ; do
echo $i
done
#!/bin/sh
FILES=`ls /txt/*.txt`
for txt in $FILES ; do
doc=`echo $txt | sed "s/.txt/.doc/"`
mv $txt $doc
done
4.while和until 循環(huán)
#!/bin/sh
while [ -f /var/run/ppp0.pid ] ; do
killall pppd
done
#!/bin/sh
until [ -f /var/run/ppp0.pid ] ; do
sleep 1
done
Shell還提供了true和false兩條命令用于建立無限循環(huán)結(jié)構(gòu)的需要,
它們的返回狀態(tài)分別是總為0或總為非0
5.case 條件選擇
#!/bin/sh
case $1 in
start | begin)
echo "start something"
;;
stop | end)
echo "stop something"
;;
*)
echo "Ignorant"
;;
esac
case表達式中也可以使用shell的通配符(“*”、“?”、“[ ]”)。
6.無條件控制語句break和continue
break 用于立即終止當前循環(huán)的執(zhí)行,而contiune用于不執(zhí)行循環(huán)中后面的語句
而立即開始下一個循環(huán)的執(zhí)行。這兩個語句只有放在do和done之間才有效。
7.函數(shù)定義
在shell中還可以定義函數(shù)。函數(shù)實際上也是由若干條shell命令組成的,
因此它與shell程序形式上是相似的,不同的是它不是一個單獨的進程,
而是shell程序的一部分。函數(shù)定義的基本格式為:
functionname
{
若干命令行
}
調(diào)用函數(shù)的格式為:
functionname param1 param2 ……
shell函數(shù)可以完成某些例行的工作,而且還可以有自己的退出狀態(tài),
因此函數(shù)也可以作為if、while等控制結(jié)構(gòu)的條件。
在函數(shù)定義時不用帶參數(shù)說明,但在調(diào)用函數(shù)時可以帶有參數(shù),此時
shell將把這些參數(shù)分別賦予相應的位置參數(shù)$1、$2、...及$*。
8.命令分組
在shell中有兩種命令分組的方法:“()”和“{}”,前者當shell執(zhí)行()
中的命令時將再創(chuàng)建一個新的子進程,然后這個子進程去執(zhí)行圓括弧中的命令。
當用戶在執(zhí)行某個命令時不想讓命令運行時對狀態(tài)集合(如位置參數(shù)、環(huán)境變量、
當前工作目錄等)的改變影響到下面語句的執(zhí)行時,就應該把這些命令放在圓括
弧中,這樣就能保證所有的改變只對子進程產(chǎn)生影響,而父進程不受任何干擾;
{}用于將順序執(zhí)行的命令的輸出結(jié)果用于另一個命令的輸入(管道方式)。當我們
要真正使用圓括弧和花括弧時(如計算表達式的優(yōu)先級),則需要在其前面加上轉(zhuǎn)
義符(\)以便讓shell知道它們不是用于命令執(zhí)行的控制所用。
9.信號
trap命令用于在shell程序中捕捉到信號,之后可以有三種反應方式:
(1)執(zhí)行一段程序來處理這一信號
(2)接受信號的默認操作
(3)忽視這一信號
trap對上面三種方式提供了三種基本形式:
第一種形式的trap命令在shell接收到signal list清單中數(shù)值相同的信號時,
將執(zhí)行雙引號中的命令串。
trap 'commands' signal-list
trap "commands" signal-list
為了恢復信號的默認操作,使用第二種形式的trap命令:
trap signal-list
第三種形式的trap命令允許忽視信號:
trap " " signal-list
注意:
(1)對信號11(段違例)不能捕捉,因為shell本身需要捕捉該信號去進行內(nèi)存的轉(zhuǎn)儲。
(2)在trap中可以定義對信號0的處理(實際上沒有這個信號),shell程序在其終止
(如執(zhí)行exit語句)時發(fā)出該信號。
(3)在捕捉到signal-list中指定的信號并執(zhí)行完相應的命令之后,如果這些命令沒有將
shell程序終止的話,shell程序?qū)⒗^續(xù)執(zhí)行收到信號時所執(zhí)行的命令后面的命令,這樣
將很容易導致shell程序無法終止。
另外,在trap語句中,單引號和雙引號是不同的,當shell程序第一次碰到trap語句時,
將把commands中的命令掃描一遍。此時若commands是用單引號括起來的話,那么shell
不會對commands中的變量和命令進行替換,否則commands中的變量和命令將用當時具體
的值來替換。
10. 運行shell程序的方法
執(zhí)行shell程序的方法有三種:
(1)sh shell程序文件名
格式為:
bash shell 程序文件名
這實際上是調(diào)用一個新的bash命令解釋程序,而把shell程序文件名作為參數(shù)傳遞給它。
新啟動的shell將去讀指定的文件,執(zhí)行文件中列出的命令,當所有的命令都執(zhí)行完結(jié)束。
該方法的優(yōu)點是可以利用shell調(diào)試功能。
(2)sh<shell程序文件名
格式為:
bash<shell 程序文件名
這種方式就是利用輸入重定向,使shell命令解釋程序的輸入取自指定的程序文件。
(3)用chmod命令使shell程序成為可執(zhí)行的
11. bash程序的調(diào)試
bash -選擇項 shell程序文件名
幾個常用的選擇項是:
-e:如果一個命令失敗就立即退出
-n:讀入命令但是不執(zhí)行它們
-u:置換時把未設(shè)置的變量看作出錯
-v:當讀入shell輸入行時把它們顯示出來
-x:執(zhí)行命令時把命令和它們的參數(shù)顯示出來
上面的所有選項也可以在shell程序內(nèi)部用“set -選擇項”的形式引用,而“set +選擇項”則
將禁止該選擇項起作用。如果只想對程序的某一部分使用某些選擇項時,則可以將該部分用
上面兩個語句包圍起來。
1.未置變量退出和立即退出
未置變量退出特性允許用戶對所有變量進行檢查,如果引用了一個未賦值的變量就終止shell
程序的執(zhí)行。shell通常允許未置變量的使用,在這種情況下,變量的值為空。如果設(shè)置了未
置變量退出選擇項,則一旦使用了未置變量就顯示錯誤信息,并終止程序的運行。未置變量退
出選擇項為“-u”。
當shell運行時,若遇到不存在或不可執(zhí)行的命令、重定向失敗或命令非正常結(jié)束等情況時,如
果未經(jīng)重新定向,該出錯信息會打印在終端屏幕上,而shell程序仍將繼續(xù)執(zhí)行。要想在錯誤發(fā)
生時迫使shell程序立即結(jié)束,可以使用“-e”選項將shell程序的執(zhí)行立即終止。
2.shell程序的跟蹤
調(diào)試shell程序的主要方法是利用shell命令解釋程序的“-v”或“-x”選項來跟蹤程序的執(zhí)行。“-v”
選擇項使shell在執(zhí)行程序的過程中,把它讀入的每一個命令行都顯示出來,而“-x”選擇項使shell
在執(zhí)行程序的過程中把它執(zhí)行的每一個命令在行首用一個“+”加上命令名顯示出來。并把每一個變量
和該變量所取的值也顯示出來,因此,它們的主要區(qū)別在于:在執(zhí)行命令行之前無“-v”則打印出命
令行的原始內(nèi)容,而有“-v”則打印出經(jīng)過替換后的命令行的內(nèi)容。
除了使用shell的“-v”和“-x”選擇項以外,還可以在shell程序內(nèi)部采取一些輔助調(diào)試的措施。
例如,可以在shell程序的一些關(guān)鍵地方使用echo命令把必要的信息顯示出來,它的作用相當于C語
言中的printf語句,這樣就可以知道程序運行到什么地方及程序目前的狀態(tài)。
12. bash的內(nèi)部命令
bash命令解釋程序包含了一些內(nèi)部命令。內(nèi)部命令在目錄列表時是看不見的,它們由shell本身提供。
常用的內(nèi)部命令有:echo、eval、exec、export、readonly、read、shift、wait和點(.)。
下面簡單介紹其命令格式和功能。
1.echo
命令格式:echo arg
功能:在屏幕上打印出由arg指定的字符串。
2.eval
命令格式:eval args
功能:當shell程序執(zhí)行到eval語句時,shell讀入?yún)?shù)args,并將它們組合成一個新的命令,然后
執(zhí)行。
3.exec
命令格式:exec 命令 命令參數(shù)
功能:當shell執(zhí)行到exec語句時,不會去創(chuàng)建新的子進程,而是轉(zhuǎn)去執(zhí)行指定的命令,
當指定的命令執(zhí)行完時,該進程,也就是最初的shell就終止了,所以shell程序中exec
后面的語句將不再被執(zhí)行。
4.export
命令格式:export 變量名 或:export 變量名=變量值
功能:shell可以用export把它的變量向下帶入子shell從而讓子進程繼承父進程中的環(huán)境變量。
但子shell不能用export把它的變量向上帶入父shell。
注意:不帶任何變量名的export語句將顯示出當前所有的export變量。
5.readonly
命令格式:readonly 變量名
功能:將一個用戶定義的shell變量標識為不可變的。不帶任何參數(shù)的readonly命令將顯示出
所有只讀的shell變量。
6.read
命令格式:
read變量名表
功能:從標準輸入設(shè)備讀入一行,分解成若干字,賦值給shell程序內(nèi)部定義的變量。
7.shift語句
功能:shift語句按如下方式重新命名所有的位置參數(shù)變量:$2成為$1,$3成為$2……在程序中
每使用一次shift語句,都使所有的位置參數(shù)依次向左移動一個位置,并使位置參數(shù)“$#”減一,
直到減到0。
8.wait
功能:是shell等待在后臺啟動的所有子進程結(jié)束。Wait的返回值總是真。
9.exit
功能:退出shell程序。在exit之后可有選擇地指定一個數(shù)字作為返回狀態(tài)。
10.“.”(點)
命令格式:. Shell程序文件名
功能:使shell讀入指定的shell程序文件并依次執(zhí)行文件中的所有語句。
13. 特殊參數(shù):
1. $*: 代表所有參數(shù),其間隔為IFS內(nèi)定參數(shù)的第一個字元
2. $@: 與*星號類同。不同之處在於不參照IFS
3. $#: 代表參數(shù)數(shù)量
4. $?: 執(zhí)行上一個指令的返回值
5. $-: 最近執(zhí)行的foreground pipeline的選項參數(shù)
6. $$: 本身的Process ID
7. $!: 執(zhí)行上一個背景指令的PID
8. $_: 顯示出最後一個執(zhí)行的命令
首先說下/etc/ld.so.conf:
這個文件記錄了編譯時使用的動態(tài)鏈接庫的路徑。
默認情況下,編譯器只會使用/lib和/usr/lib這兩個目錄下的庫文件
如果你安裝了某些庫,比如在安裝gtk+-2.4.13時它會需要glib-2.0 >= 2.4.0,辛苦的安裝好glib后
沒有指定 —prefix=/usr 這樣glib庫就裝到了/usr/local下,而又沒有在/etc/ld.so.conf中添加/usr/local/lib這個搜索路徑,所以編譯gtk+-2.4.13就會出錯了 對于這種情況有兩種方法解決:
一:在編譯glib-2.4.x時,指定安裝到/usr下,這樣庫文件就會放在/usr/lib中,gtk就不會找不到需要的庫文件了 對于安裝庫文件來說,這是個好辦法,這樣也不用設(shè)置PKG_CONFIG_PATH了
二:將/usr/local/lib加入到/etc/ld.so.conf中,這樣安裝gtk時就會去搜索/usr/local/lib,同樣可以找到需要的庫
將/usr/local/lib加入到/etc/ld.so.conf也是必須的,這樣以后安裝東東到local下,就不會出現(xiàn)這樣的問題了。
將自己可能存放庫文件的路徑都加入到/etc/ld.so.conf中是明智的選擇
添加方法也極其簡單,將庫文件的絕對路徑直接寫進去就OK了,一行一個。例如:
/usr/X11R6/lib
/usr/local/lib
/opt/lib
再來看看ldconfig :
它是一個程序,通常它位于/sbin下,是root用戶使用的。具體作用及用法可以man ldconfig查到
簡單的說,它的作用就是將/etc/ld.so.conf列出的路徑下的庫文件 緩存到/etc/ld.so.cache 以供使用
因此當安裝完一些庫文件,(例如剛安裝好glib),或者修改ld.so.conf增加新的庫路徑后,需要運行一下/sbin/ldconfig
使所有的庫文件都被緩存到ld.so.cache中,如果沒做,即使庫文件明明就在/usr/lib下的,也是不會被使用的,結(jié)果編譯過程中報錯,缺少xxx庫
我曾經(jīng)編譯KDE時就犯過這個錯誤,(它需要每編譯好一個東東,都要運行一遍),所以切記改動庫文件后一定要運行一下ldconfig,在任何目錄下運行都可以。
再來說說 PKG_CONFIG_PATH這個變量吧:
經(jīng)常在論壇上看到有人問”為什么我已經(jīng)安裝了glib-2.4.x,但是編譯gtk+-2.4.x 還是提示glib版本太低阿?
為什么我安裝了glib-2.4.x,還是提示找不到阿?。。。。。。”都是這個變量搞的鬼。
先說說它是哪冒出來的,當安裝了pkgconfig-x.x.x這個包后,就多出了pkg-config,它就是需要PKG_CONFIG_PATH的東東
pkgconfig-x.x.x又是做什么的? 來看一段說明:
The pkgconfig package contains tools for passing the include path
and/or library paths to build tools during the make file execution.
pkg-config is a function that returns meta information for the specified library.
The default setting for PKG_CONFIG_PATH is /usr/lib/pkgconfig because
of the prefix we use to install pkgconfig. You may add to
PKG_CONFIG_PATH by exporting additional paths on your system where
pkgconfig files are installed. Note that PKG_CONFIG_PATH is only needed
when compiling packages, not during run-time.
其實pkg-config就是向configure程序提供系統(tǒng)信息的程序,比如軟件的版本啦,庫的版本啦,庫的路徑啦,等等
這些信息只是在編譯其間使用。你可以 ls /usr/lib/pkgconfig 下,會看到許多的*.pc,用文本編輯器打開
會發(fā)現(xiàn)類似下面的信息:
prefix=/usr
exec_prefix=${prefix}
libdir=${exec_prefix}/lib
includedir=${prefix}/include
glib_genmarshal=glib-genmarshal
gobject_query=gobject-query
glib_mkenums=glib-mkenums
Name: GLib
Description: C Utility Library
Version: 2.4.7
Libs: -L${libdir} -lglib-2.0
Cflags: -I${includedir}/glib-2.0 -I${libdir}/glib-2.0/include
明白了吧,configure就是靠這些信息判斷你的軟件版本是否符合要求。并且得到這些東東所在的位置,要不去哪里找呀。
不用我說你也知道為什么會出現(xiàn)上面那些問題了吧。
解決的辦法很簡單,設(shè)定正確的PKG_CONFIG_PATH,假如將glib-2.x.x裝到了/usr/local/下,那么glib-2.0.pc就會在
/usr/local/lib/pkgconfig下,將這個路徑添加到PKG_CONFIG_PATH下就可以啦。并且確保configure找到的是正確的
glib-2.0.pc,就是將其他的lib/pkgconfig目錄glib-2.0.pc干掉就是啦。(如果有的話 ^-^)
設(shè)定好后可以加入到~/.bashrc中,例如:
PKG_CONFIG_PATH=/opt/kde-3.3.0/lib/pkgconfig:/usr/lib/pkgconfig:/usr/local/pkgconfig:
/usr/X11R6/lib/pkgconfig
[root@NEWLFS ~]#echo $PKG_CONFIG_PATH
/opt/kde-3.3.0/lib/pkgconfig:/usr/lib/pkgconfig:/usr/local/pkgconfig:/usr/X11R6/lib/pkgconfig
從上面可以看出,安裝庫文件時,指定安裝到/usr,是很有好處的,無論是/etc/ld.so.conf還是PKG_CONFIG_PATH
默認都會去搜索/usr/lib的,可以省下許多麻煩,不過從源碼包管理上來說,都裝在/usr下
管理是個問題,不如裝在/usr/local下方便管理
其實只要設(shè)置好ld.so.conf,PKG_CONFIG_PATH路徑后,就OK啦
refresh
tail -f /var/log/messages
tar -xvf foo.tar, tar -xzvf foo.tar.gz
linux kernel version
uname -r
Dir size du -k (kilo byte)
cd ~ : go to your home
directory
cd - : go to the
last directory you were in
cd .. : go up a
directory
#libxml2 and glibmm are not neccessary to compile the main.cpp
#macro
libxml2:=../../libxml2
libxml++:=..
glibmm:=../../glibmm
#adds include directives
CC:=g++
CCINCLUDE:= -I$(libxml++)/include/libxml++-2.6 -I$(libxml++)/lib/libxml++-2.6/include "
-I$(libxml2)/include -I$(glibmm)/include
#linking
LD:=g++
LDSTDLIBS:= -L$(libxml++)/lib -L$(libxml2)/lib -L$(glibmm)/lib
LDLIBS:= -lxml++-2.6
LDLIBFLAGS:= -shared $(LDLIBS) $(LDSTDLIBS)
LDEXEFLAGS:= $(LDSTDLIBS) $(LDLIBS)
#extending library path
#export VAR:=... means make it effective in the subprocess(Makefile)
#export LD_LIBRARY_PATH:=... doesn't work because it's only effective in the subprocesses, not parentprocess(shell)
#therefore the LD_RUN_PATH which allocates dynamic libs to the exe file must be set and export to take effect in the ld cmd
LD_LIBRARY_PATH:=$(libxml++)/lib:$(LD_LIBRARY_PATH)
export LD_RUN_PATH:=$(LD_LIBRARY_PATH)
#list of source files for building the target
SRC:= main.cpp
OBJ:=$(patsubst %.cpp,%.o,$(filter %.cpp,$(SRC)))
#targets
# $^ everyone behinds the : , and $< first one behinds the :
# $(OBJ): %.o: %.cpp is another common implicit rule is for the construction of .o files out of .cpp
.PHONY: all clean
all: $(OBJ)
$(LD) $(LDEXEFLAGS) $^ -o $@
$(OBJ): %.o: %.cpp
$(CC) $(CCINCLUDE) -c $< -o $@
clean:
rm -f $(OBJ) all *~ \.*.swp
1) 文件的最大權(quán)限r(nóng)wx rwx rwx (777)
2 ) u m a s k值為0 2 2 - - - -w- -w-
3) 目錄權(quán)限r(nóng)wx r-x r-x (755) 這就是目錄創(chuàng)建缺省權(quán)限
4) 文件權(quán)限r(nóng)w- r-- r-- (644) 這就是文件創(chuàng)建缺省權(quán)限
三次握手Three-way Handshake
一個虛擬連接的建立是通過三次握手來實現(xiàn)的
1. (B) --> [SYN] --> (A)
假如服務器A和客戶機B通訊. 當A要和B通信時,B首先向A發(fā)一個SYN (Synchronize) 標記的包,告訴A請求建立連接.
注意: 一個 SYN包就是僅SYN標記設(shè)為1的TCP包(參見TCP包頭Resources).
認識到這點很重要,只有當A受到B發(fā)來的SYN包,才可建立連接,除此之外別無他法。因此,如果你的防火墻丟棄所有的發(fā)往外網(wǎng)接口的SYN包,那么你將不
能讓外部任何主機主動建立連接。
2. (B) <-- [SYN/ACK] <--(A)
接著,A收到后會發(fā)一個對SYN包的確認包(SYN/ACK)回去,表示對第一個SYN包的確認,并繼續(xù)握手操作.
注意: SYN/ACK包是僅SYN 和 ACK 標記為1的包.
3. (B) --> [ACK] --> (A)
B收到SYN/ACK 包,B發(fā)一個確認包(ACK),通知A連接已建立。至此,三次握手完成,一個TCP連接完成
Note: ACK包就是僅ACK 標記設(shè)為1的TCP包. 需要注意的是當三此握手完成、連接建立以后,TCP連接的每個包都會設(shè)置ACK位
這就是為何連接跟蹤很重要的原因了.
沒有連接跟蹤,防火墻將無法判斷收到的ACK包是否屬于一個已經(jīng)建立的連接.一般的包過濾(Ipchains)收到ACK包時,會讓它通過(這絕對不是個
好主意). 而當狀態(tài)型防火墻收到此種包時,它會先在連接表中查找是否屬于哪個已建連接,否則丟棄該包
四次握手Four-way Handshake
四次握手用來關(guān)閉已建立的TCP連接
1. (B) --> ACK/FIN --> (A)
2. (B) <-- ACK <-- (A)
3. (B) <-- ACK/FIN <-- (A)
4. (B) --> ACK --> (A)
注意: 由于TCP連接是雙向連接, 因此關(guān)閉連接需要在兩個方向上做。ACK/FIN 包(ACK 和FIN
標記設(shè)為1)通常被認為是FIN(終結(jié))包.然而, 由于連接還沒有關(guān)閉, FIN包總是打上ACK標記.
沒有ACK標記而僅有FIN標記的包不是合法的包,并且通常被認為是惡意的
連接復位Resetting a connection
四次握手不是關(guān)閉TCP連接的唯一方法. 有時,如果主機需要盡快關(guān)閉連接(或連接超時,端口或主機不可達),RST
(Reset)包將被發(fā)送. 注意在,由于RST包不是TCP連接中的必須部分, 可以只發(fā)送RST包(即不帶ACK標記).
但在正常的TCP連接中RST包可以帶ACK確認標記
請注意RST包是可以不要收到方確認的?
無效的TCP標記Invalid TCP Flags
到目前為止,你已經(jīng)看到了 SYN, ACK, FIN, 和RST 標記. 另外,還有PSH (Push) 和URG (Urgent)標記.
最常見的非法組合是SYN/FIN 包. 注意:由于 SYN包是用來初始化連接的, 它不可能和 FIN和RST標記一起出現(xiàn). 這也是一個惡意攻擊.
由于現(xiàn)在大多數(shù)防火墻已知 SYN/FIN 包, 別的一些組合,例如SYN/FIN/PSH, SYN/FIN/RST, SYN/FIN/RST/PSH。很明顯,當網(wǎng)絡(luò)中出現(xiàn)這種包時,很你的網(wǎng)絡(luò)肯定受到攻擊了。
別的已知的非法包有FIN
(無ACK標記)和"NULL"包。如同早先討論的,由于ACK/FIN包的出現(xiàn)是為了關(guān)閉一個TCP連接,那么正常的FIN包總是帶有 ACK
標記。"NULL"包就是沒有任何TCP標記的包(URG,ACK,PSH,RST,SYN,FIN都為0)。
到目前為止,正常的網(wǎng)絡(luò)活動下,TCP協(xié)議棧不可能產(chǎn)生帶有上面提到的任何一種標記組合的TCP包。當你發(fā)現(xiàn)這些不正常的包時,肯定有人對你的網(wǎng)絡(luò)不懷好意。
UDP (用戶數(shù)據(jù)包協(xié)議User Datagram Protocol)
TCP是面向連接的,而UDP是非連接的協(xié)議。UDP沒有對接受進行確認的標記和確認機制。對丟包的處理是在應用層來完成的。(or accidental arrival).
此處需要重點注意的事情是:在正常情況下,當UDP包到達一個關(guān)閉的端口時,會返回一個UDP復位包。由于UDP是非面向連接的, 因此沒有任何確認信息來確認包是否正確到達目的地。因此如果你的防火墻丟棄UDP包,它會開放所有的UDP端口(?)。
由于Internet上正常情況下一些包將被丟棄,甚至某些發(fā)往已關(guān)閉端口(非防火墻的)的UDP包將不會到達目的,它們將返回一個復位UDP包。
因為這個原因,UDP端口掃描總是不精確、不可靠的。
看起來大UDP包的碎片是常見的DOS (Denial of Service)攻擊的常見形式 (這里有個DOS攻擊的例子,http://grc.com/dos/grcdos.htm ).
ICMP (網(wǎng)間控制消息協(xié)議Internet Control Message Protocol)
如同名字一樣, ICMP用來在主機/路由器之間傳遞控制信息的協(xié)議。 ICMP包可以包含診斷信息(ping, traceroute -
注意目前unix系統(tǒng)中的traceroute用UDP包而不是ICMP),錯誤信息(網(wǎng)絡(luò)/主機/端口 不可達 network/host/port
unreachable), 信息(時間戳timestamp, 地址掩碼address mask request, etc.),或控制信息
(source quench, redirect, etc.) 。
你可以在http://www.iana.org/assignments/icmp-parameters中找到ICMP包的類型。
盡管ICMP通常是無害的,還是有些類型的ICMP信息需要丟棄。
Redirect (5), Alternate Host Address (6), Router Advertisement (9) 能用來轉(zhuǎn)發(fā)通訊。
Echo (8), Timestamp (13) and Address Mask Request (17)
能用來分別判斷主機是否起來,本地時間 和地址掩碼。注意它們是和返回的信息類別有關(guān)的。
它們自己本身是不能被利用的,但它們泄露出的信息對攻擊者是有用的。
ICMP消息有時也被用來作為DOS攻擊的一部分(例如:洪水ping flood ping,死 ping ?呵呵,有趣 ping of death)?/p>
包碎片注意A Note About Packet Fragmentation
如果一個包的大小超過了TCP的最大段長度MSS (Maximum Segment Size) 或MTU (Maximum Transmission Unit),能夠把此包發(fā)往目的的唯一方法是把此包分片。由于包分片是正常的,它可以被利用來做惡意的攻擊。
因為分片的包的第一個分片包含一個包頭,若沒有包分片的重組功能,包過濾器不可能檢測附加的包分片。典型的攻擊Typical attacks
involve in overlapping the packet data in which packet header is
典型的攻擊Typical attacks involve in overlapping the packet data in which
packet header isnormal until is it overwritten with different
destination IP (or port) thereby bypassing firewall rules。包分片能作為 DOS
攻擊的一部分,它可以crash older IP stacks 或漲死CPU連接能力。
Netfilter/Iptables中的連接跟蹤代碼能自動做分片重組。它仍有弱點,可能受到飽和連接攻擊,可以把CPU資源耗光。
>gdb ./sysprocess
(gdb)set args -id 0 -taskcfg ub900proc
(gdb)r //run
Starting program: ../sysprocess -id 0 -taskcfg ub900proc
..
Program received signal SIGSEGV, Segmentation fault.
(gdb)backtrace //打印當前的函數(shù)調(diào)用棧的所有信息。
(gdb)frame 7 //查看信息,n是一個從0開始的整數(shù),是棧中的層編號
(gdb)up
(gdb)down
(gdb)quit
#find ... -exec rm {} \;
#find ... | xargs rm -rf
兩者都可以把find命令查找到的結(jié)果刪除,其區(qū)別簡單的說是前者是把find發(fā)現(xiàn)的結(jié)果一次性傳給exec選項,這樣當文件數(shù)量較多的時候,就
可能會出現(xiàn)“參數(shù)太多”之類的錯誤,相比較而言,后者就可以避免這個錯誤,因為xargs命令會分批次的處理結(jié)果。這樣看來,“find ... |
xargs rm -rf”是更通用的方法,推薦使用!
rm不接受標準輸入,所以不能用find / -name "tmpfile" |rm
-exec 必須由一個 ; 結(jié)束,而因為通常 shell 都會對 ; 進行處理,所以用 \; 防止這種情況。
{} 可能需要寫做 '{}',也是為了避免被 shell 過濾
find ./ -type f -exec grep iceskysl {} /dev/null \;
./表示從當前目錄找
-type f,表示只找file,文件類型的,目錄和其他字節(jié)啥的不要
-exec 把find到的文件名作為參數(shù)傳遞給后面的命令行,代替{}的部分
-exec后便跟的命令行,必須用“ \;”結(jié)束
#find ./ -type f -name "*.cpp"|xargs grep "test" -n
#find . -name "*cpp" -exec grep "test" {} \; -print
Each SWT widget has a (possible) containing area as known as the cell.
horizontalAlignment, verticalAlignment is used to set the widget position
grabExcessHorizontalSpace, grabExcessVerticalSpace is used to set the cell.
netstat -nl | grep 3141
=========================
nmap -sT -O localhost
cat /etc/services | grep 3141
netstat -anp | grep 3141
lsof -i | grep 3141
vim /etc/ld.so.conf
====================
LD_LIBRARY_PATH: defines the path of dynamic libraries used at the run time
LD_RUN_PATH: at compile time tells the exe file what is path of dynamic libraries used at the run time
======================
ldd exe // show the used dynamic libs
Dir size
|
du -k (kilo byte)
|
linux kernel version
|
uname -r
|
umlenkung
|
>> , 2>
|
| |
ps -aux | grep "lct*"
|
| |
tar -xvf foo.tar, tar -xzvf foo.tar
|
| refresh |
tail -f /var/log/messages |
There are 4 scopes application, session, request and page in the order of thier significance.
Application represent the ServletContext. The scope is accesible throught out the application.
session represents HTTPSession object. This is valid till the user requests the application.
Request represent the HTTPServletRequest and valdi to a particular request. A request may span a single JSP page or multiple depending upon teh situations.
Page is the least valid scope. It is valid to the particular JSP page only This is some thing like private variable
$ wget -r -np -nd http://example.com/packages/
這條命令可以下載 http://example.com 網(wǎng)站上 packages 目錄中的所有文件。其中,-np 的作用是不遍歷父目錄,-nd 表示不在本機重新創(chuàng)建目錄結(jié)構(gòu)。
$ wget -r -np -nd --accept=iso http://example.com/centos-5/i386/
與上一條命令相似,但多加了一個 --accept=iso 選項,這指示 wget 僅下載 i386 目錄中所有擴展名為 iso 的文件。你也可以指定多個擴展名,只需用逗號分隔即可。
$ wget -i filename.txt
此命令常用于批量下載的情形,把所有需要下載文件的地址放到 filename.txt 中,然后 wget 就會自動為你下載所有文件了。
$ wget -c http://example.com/really-big-file.iso
這里所指定的 -c 選項的作用為斷點續(xù)傳。
$ wget -m -k (-H) http://www.example.com/
該命令可用來鏡像一個網(wǎng)站,wget 將對鏈接進行轉(zhuǎn)換。如果網(wǎng)站中的圖像是放在另外的站點,那么可以使用 -H 選項。
stream應該是水龍頭里的水資源,
InputStream:是一個出水龍頭(把水封裝在里頭)的一個實物對象,該對象的read方法呢,就想成這
個"出水龍頭"這一機制對象的開關(guān)鈕,你read或openStream(其他對象包容InputStream對象的對象方法)
一下呢,就等于打開了出水龍頭的按鈕,水就出來了,里頭封裝的水是什么性質(zhì)的呢,
你就用相應的容器來裝,如string或byte[].....
OutputStream:你就在InputStream基礎(chǔ)上反著想就ok了
=====================================================================================
當然,我們可以在Inputstream和OutputStream數(shù)據(jù)源的基礎(chǔ)上,從實際需要觸發(fā),
來重新封裝出不同性能機制的輸入、輸出流了,java.io包中提供了很豐富的輸入、輸出流對象,如:
基于字節(jié)流的stream:
DataOutputStream----DataInputStream:
FileOutputStream-----FileInputStream:
File->inputstream->...
...->outputstream->File
.............等,可以用InputStream和OutputStream從JDK文檔查閱
基于字符流的stream(典型的以write 和reader來標識的):
FileWriter---FileReader:
StringWriter---StringReader:
.........等,你自己可以用Writer和Reader從JDK文檔里頭查看說明
======================================================================================
InputStreamReader r = new InputStreamReader(System. in ); // InputStream from console
BufferedReader in = new BufferedReader ( r );
String line ;
while (( line = in . readLine ()) != null) {
System. out . println ( "> "+line );
}
FileReader r = new FileReader ( args [0]); // InputStream from file
BufferedReader in = new BufferedReader ( r );
String line ;
while (( line = in . readLine ()) != null) {
System. out . println ( "> "+line );
}
FileWriter w = new FileWriter ( args [0]); //OutputStream to file
BufferedWriter bw = new BufferedWriter (w);
PrintWriter out = new PrintWriter (bw);
out . println ( "dies" );
out . println ( " ... ist ein Log!" );
out . println ( "Ciao!" );
out . close (); // schliessen nicht vergessen !
===================================================================
FileInputStream是InputStream的子類,由名稱上就可以知道, FileInputStream主要就是從指定的File中讀取資料至目的地。
FileOutputStream是OutputStream的子類,顧名思義,F(xiàn)ileOutputStream主要就是從來源地寫入資料至指定的File中。
標準輸入輸出串流物件在程式一開始就會開啟,但只有當您建立一個FileInputStream或FileOutputStream的實例時,實際的串流才會開啟,而不使用串流時,也必須自行關(guān)閉串流,以釋放與串流相依的系統(tǒng)資源。
下面這個程式可以復制檔案,程式先從來源檔案讀取資料至一個位元緩沖區(qū)中,然后再將位元陣列的資料寫入目的檔案:
package onlyfun.caterpillar;
import java.io.*;
public class FileStreamDemo {
public static void main(String[] args) {
try {
byte[] buffer = new byte[1024];
FileInputStream fileInputStream =
new FileInputStream(new File(args[0]));
FileOutputStream fileOutputStream =
new FileOutputStream(new File(args[1]));
System.out.println("復制檔案:" +
fileInputStream.available() + "位元組");
while(true) { // 從來源檔案讀取資料至緩沖區(qū)
if(fileInputStream.available() < 1024) {
int remain;
while((remain = fileInputStream.read())
!= -1) {
fileOutputStream.write(remain);
}
break;
}
else {
fileInputStream.read(buffer);
// 將陣列資料寫入目的檔案
fileOutputStream.write(buffer);
}
}
// 關(guān)閉串流
fileInputStream.close();
fileOutputStream.close();
System.out.println("復制完成");
}
catch(ArrayIndexOutOfBoundsException e) {
System.out.println(
"using: java FileStreamDemo src des");
e.printStackTrace();
}
catch(IOException e) {
e.printStackTrace();
}
}
}
這個程式示范了兩個 read() 方法,一個可以讀入指定長度的資料至陣列,一個一次可以讀入一個位元組,每次讀取之后,讀取的指標都會往前進,您使用available()方法獲得還有多少位元組可以讀取;除了使用File來建立FileInputStream、FileOutputStream的實例之外,您也可以直接使用字串指定路徑來建立。
不使用串流時,記得使用close()方法自行關(guān)閉串流,以釋放與串流相依的系統(tǒng)資源。