把HTML的內容輸出到LOG中的方法
1、在腳本要記錄HTML的URL前面加入函數:web_create_html_param("MyHtml", "<html>", "");;
2、在腳本要記錄HTML的URL后面加入函數:lr_output_message("###the HTML is %s", lr_eval_string(" {MyHtml}"));;
3、在Controller中設置Run-Time Settings,把log設置為Always Send Message;
4、在Controller中設置Run-Time Settings,把Miscellaneous設置為在發生錯誤時繼續運行(在這里不是必須);
5、在Controller中設置Run-Time Settings,把Preferences設置為Enable image and text check;(在這里不是必須);
6、在Controller的日志文件RES中可以查看到每個虛擬用戶的LOG;
如何在Controller中添加系統資源檢測
今天早上突然想把Windows的性能監視放到LR中,達到方便快捷的目的,下面的是具體的步驟:
1、使用192.168.0.159作為監控的對象,開通Remote Procedure Call和Remote Registry兩個服務,Remote Registry一般都是給禁止的,可以改為手動并啟動;
2、在159中右擊我的電腦,選擇管理->共享文件夾->共享 在這里面要有C$這個共享文件夾;
3、在159中使用命令netstat /ano查看445端口是否被打開;
4、輸入\\192.168.0.159\c$,再輸入用戶名和密碼,如果能進入c盤,那就說明有控制權了;
5、在Controller的Run中找到Windows Resources,對圖點擊右鍵中的Add Measurements,添加計數器;
6、需注意159機上的BlackIce;
7、對Windows Resources Graph的技巧使用,可以凍結窗體,導出HMTL,顯示某個計數器等;
對ANALYSIS中不能導出頁面細分下的子項的問題的處理方法
1、問題描述:對ANALYSIS的導出WORD功能中只能導出樹中的圖表,在頁面細分中點擊不同的節點會有不同的圖表,但是卻無法把所有節點的圖表一起導出;
2、如果想生成Time to First Buffer Breakdown下面Login事務和Loading事務下的圖表都導出來,方法就是新建兩張Time to First Buffer Breakdown圖表,在不同的下面點擊圖表,并修改名稱;
3、在導出列表中選中要導出的圖表:Time to First Buffer Breakdown-All && Time to First Buffer Breakdown-Login && Time to First Buffer Breakdown-Loading;
4、總結:雖然這樣做有點麻煩,但是比之前點擊每個圖再導出一個WORD來有用的多,但是LR可以做到在導出列表中以樹的形式顯示可以導出的圖表,不過LR要解決圖表沒有名稱的問題;
在中文版Analysis中顯示系統資源圖的原因與解決
1、是否可以通過修改ACCESS記錄來修改這個BUG?
2、不知道它添加圖表的列表是不是通過數據庫LOAD的?迄今還沒有找到這些記錄,只找到資源圖表數據;
3、解決辦法1:是用VNC截圖,但是這樣只能看到計數器曲線,沒什么意義;
4、解決辦法2:在Controller中導出系統資源數據,里面有量化數據,比較真實,不過每個場景都要導出一次就很麻煩,并且不好管理,無法對數據進行帥選和合并,如果打開導出的頁面有亂碼,那就在編碼方式選擇"自動選擇";
5、解決辦法3:使用英文版生成的ANALYSIS,再拿到中文版下面,是可以看到系統資源這個圖表的,其實我應該早想到這樣的,因為在中文版下無法顯示不是Analysis的錯,而是Controller的錯,Analysis里面是包括ACCESS和其它包含系統資源的記錄的,所以在中文版是能顯示的;
LoadRunner 參數化詳解
LoadRunner,是一種預測系統行為和性能的負載測試工具。通過以模擬上千萬用戶實施并發負載及實時性能監測的方式來確認和查找問題,LoadRunner能夠對整個企業架構進行測試。通過使用 LoadRunner,企業能最大限度地縮短測試時間,優化性能和加速應用系統的發布周期。 LoadRunner是一種適用于各種體系架構的自動負載測試工具,它能預測系統行為并優化系統性能。
參數化的定義:使用指定的數據源中的值來替換腳本錄制生成的語句中的參數。
對Vuser腳本進行參數化的好處:
1、減小腳本的大小
2、提供了使用不同的腳本的值執行腳本的能力
參數化涉及兩個任務:
1、用參數替換Vuser腳本的常量值
2、為參數設置屬性和數據源
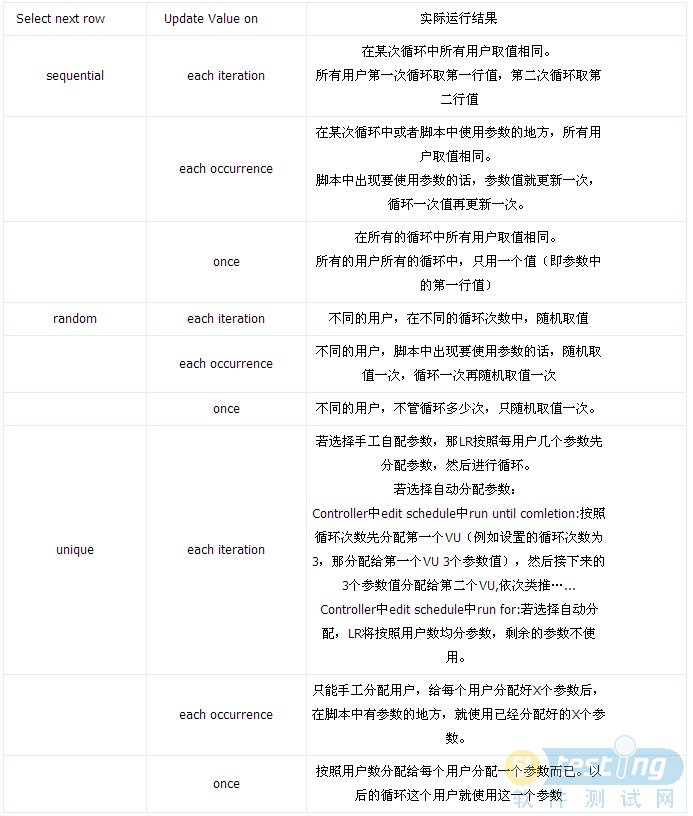
“Select next row”定義的是如何選擇下一行數據。該處有三個選項"Sequential","Random","Unique",
Sequential:順序地向Vuser分配數據。
Random:當測試開始運行時,“隨機”方法為每個Vuser分配一個數據表中的隨機值。
Unique:為每一個Vuser的參數分配一個唯一的順序值。在這種情況下必須確保表中的數據對所有的Vuser
和它們的迭代來說是充足的。如果擁有20個Vuser并且要進行5次迭代,則測試者的表格中必須至
少包含100個數值。
“Update value on”定義的是什么時候更新數據值,備選項有每次迭代,每次出現和一次。
表 LoadRunner參數更新方法和數據分配

如果LoadRunner的函數中某個參數不能直接使用LoadRunner參數,那么可以通過lr_eval_string進行轉換取到參數的值。
參數表中select next row和update value on的設置
LR的參數的取值,和select next row和update value on的設置都有密不可分的關系。下表給出了select next row和update value on不同的設置,對于LR的參數取值的結果將不同,給出了詳細的描述。
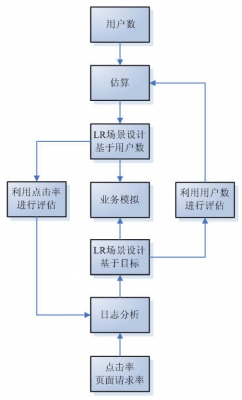
LR場景設計、點擊率和用戶數的相互聯系
1、場景設計、點擊率和用戶數關系圖
2、如何獲得需要的測試數據
測試的數據來源于:1)需求;2)系統日志。
從日志中獲取數據,可以采用日志分析工具,常用的日志分析工具有Awstat和WebTrends,對于它們的區別是前者是輕量級分析工具,分析速度快,報告簡單實用,后者是重量級工具,分析速度慢,報告豐富多樣。
估算虛擬用戶數,雖然有多種方法,但是這里重點推薦以下兩種方法:
方法一,采用Little`s Law方法,它是從服務器端提出的一種計算虛擬用戶數的方法。
方法二,采用段念書中提到的公式。
3、用戶速率不等于并發用戶數
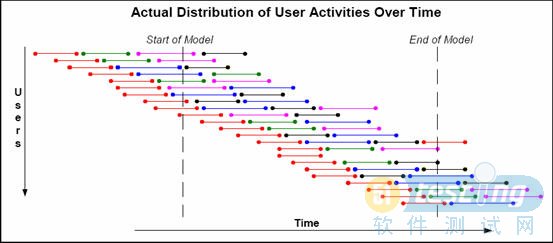
在測試的時候,通常想獲取系統的并發用戶數、峰值用戶數,這些數據都可以從日志中獲取,因此在日志中都會關注當日、月、年的用戶訪問量,我們可以把這些數據平均到每秒訪問用戶數。此時的平均每秒訪問用戶數難道就是我們要找的平均并發用戶數嗎?其實不是的。用戶速率不等于并發用戶數。如下圖,縱坐標代表虛擬用戶,橫坐標代表時間,每條線段代表用戶的一個行為,Start of Model到End of Model代表測試開始和結束過程,持續1個小時。
從服務器角度看,在1個小時內有23個用戶訪問系統,換個角度理解,每小時有23個用戶在訪問系統,在Start of Model到End of Model之間任意一時刻都只有10個用戶在訪問系統。
4、點擊率、用戶數該從哪里入手
縮小話題范圍,這里以用戶體驗感為測試目標,從而提出進行性能測試的重要性是模擬真實的用戶行為,因此提出如何模擬用戶行為?通常進行性能測試的時候,采用估算虛擬用戶數然后進行相關的壓力測試、負載測試。但是這樣測試出來的結果正確嗎?很顯然我們無法斷定,因此提出了對測試結果的評估。
從估算虛擬用戶數開始,以基于用戶數的方式設計場景,進行性能測試,獲得測試結果和點擊率,將測試得到的點擊率和日志中分析的點擊率進行比較,來驗證測試的效果。
從日志中獲取的點擊率或者頁面請求率開始,以基于目標的方式設計場景,進行性能測試,獲得測試結果和用戶數,將測試得到用戶數和日志中估算的虛擬用戶數進行比對,來驗證測試效果。
通過上面的方法都可以完成測試且能保證測試結果的準確性,但是點擊率和用戶數從哪個開始比較好呢?個人觀點從點擊率可以更好的去模擬真實用戶對服務器的壓力,而當需求中有明確的并發用戶數要求的時候,從用戶數開始比較好。
在新浪微博上大家常討論和抱怨,中國測試所處的環境多么初級和落后。我也常參與討論,無奈微博140字的限制,表達有限,還導致一些誤解。其實下面的內容,我在2011年2月就整理最原始的思路,今天周末正好拿出來與大家分享,聽聽大家的意見和批判:
我在某軟件工程積累很多的大公司從事過一段時間early testing工作的探索,因此有幾個月時間經常和公司的產品架構師混在一起工作,全程參與了需求和設計工作。從而積累了很多軟件設計,軟件開發工程領域的認知,也對軟件開發工程的發展歷史和規律有了更多了解。(early testing就是沒寫代碼前的測試怎么做?測試人員如何盡可能去發現需求,架構,設計中的缺陷或不足)
原來軟件開發也經歷了:沒有章法單兵作戰,憑感覺開發的1.0時代——>接著有了開發流程的2.0時代——>接著又發現流程的每個環節如何做好,還需要一些更具體的指導(方法論)和幫助(技術工具), 于是有了軟件開發3.0時代,各種IDE開發工具,各種編程規范,各種編程技巧——>進入九十年代后軟件領域有了更多的開發框架(比一般的API庫集成度更高)如J2EE,.net,這些框架不是API代碼或函數的簡單拼湊,而是重用了前輩或領域專家們的設計經驗,系統性的構建起來,是對前人設計技術和思想的繼承重用,從而既提升了開發效率也提升了質量。唯一壞處多增加了一些學習成本(不光學基本語言,還要學習前人定下了的設計規則)。
一直以來測試行業的難題,如何評審用例,如何評審測試設計?在自動化測試運動結束后,這個問題最終還是被測試經理們提出落到我頭上去解決,原來那些評審單個用例文字編寫規范的東西早已不被一線測試經理們認可,必須要有所突破否則整個組織的測試用例質量無法提升,絕大部分的測試執行和測試資源都將在地基不牢的地方浪費,質量提升就等同皇帝新裝。 當時我另開辟渠道,想了解軟件開發如何評審設計的?后來看了一個公司軟件開發專家的內部ppt,他在幾年前也在解決軟件設計如何評審的問題?最終我暫時找到了一個可用答案——設計約束、設計模板、設計回溯 三板斧。 原來現在很流行的J2EE,.net的框架不僅僅是加快開發速度,還提供了設計模板,通過設計約束來保障了基本的設計質量。從而我認為測試設計領域也應該有自己的設計約束和設計模板,測試分析設計人員可以按設計約束和設計模板來填空,測試技術主管或管理主管可以用設計約束和設計模板通過設計回溯的方法評審測試用例。 需要特別強調的是:測試設計模板,不是傳統意義上單個用例的結構或文字描述規范的規定。而是測試用例是通過什么嚴謹系統的大腦處理流程而來的。為此,我從2010年底到2011年初整理開發了《軟件可靠性測試分析設計框架》,《壓力測試分析設計框架》《長時間測試分析設計框架》來輔助不同項目組改進現有這些領域的專項測試用例,改善了用例不再完全憑個人經驗和感覺編寫的問題,給測試經理接下來測試用例評審的武器。
最后再總結整理下軟件開發的發展趨勢:
1.0時代混亂;2.0時代流程化;3、方法和技術;4設計框架。
測試行業的發展和軟件開發發展趨勢也會一致:
1.0時代無流程 (我入行前) 某公司1998年前
2.0有測試流程 (我剛入行) 某公司1998年-2003年
3.0時代大量測試方法和技術 (我2010年前) 某公司2003至今,特別是08年至今有了大量突飛猛進的突破,正在大面積普及的路上
4.0時代有測試設計框架(設計和經驗復用) (我2010年至今,先走一步探索啦)
通過讀史明鑒,找到事物發展的規律后,我有信心并相信,中國測試業界相比開發只是晚1個時代,未來10年內中國多數公司的測試也會進步到3.0和4.0時代。某公司走過的歷史,也必將是國內才起步后來者們未來走的路以及趨勢。
各位tester看到未來的發展方向了嗎?
現在,已經有大量的
Android自動化測試架構或工具可供我們使用,其中包括:Activity Instrumentation,MonkeyRunner,Robotium,以及Robolectric。另外LessPainful也提供服務來進行真實設備上的自動化測試。
Android自身提供了對instrumentation測試的基本支持,其中之一就是位于android.test包內的ActivityInstrumentationTestCase2類,它擴展了JUnit的TestCase類來提供Android activities的功能測試。在應用測試中,每一個activity首先會被Instrumentation初始化,然后再加載到Android模擬器或設備的Dalvik虛擬機中來執行。
Android SDK自帶一個測試工具MonkeyRunner,它提供的API和執行環境可以運行Python語言編寫的測試代碼。它提供API來連接設備,安裝/卸載應用,運行應用,截屏,比對圖片來判斷特定命令執行后的屏幕是否包含預期信息,以及運行對應用的測試。MonkeyRunner使用ActivityInstrumentationTestCase2,ProviderTestCase,ServiceTestCase,SingleLaunchActivityTestCase及其他類來定義測試用例,并使用InstrumentationTestRunner類來運行測試。
Robotium是另一種通過InstrumentationTestRunner來完成Android交互式測試的架構,它橫跨多個activities,支持功能測試,系統測試和接收測試。Robotium支持Activities、Dialogs、Toasts、Menus、Context Menus甚至Honeycomb,并且它可以同Maven和Ant集成來完成持續集成測試。Robotium被稱之為針對Android應用的又一個“Selenium“。
Robolectric另辟蹊徑,它并不依賴于Android提供的測試功能,它使用了shadow objects并且運行測試于普通的工作站/服務器JVM,不像模擬器或設備需要dexing(Android dex編譯器將類文件編譯成Android設備上的Dalvik VM使用的格式),打包,部署和運行的過程,大大減少了測試執行的時間。Pivotal實驗室聲稱使用Robolectric可以在28秒內運行1047個測試。
LessPainful將Android測試又推進了一步,它提供了一個多設備平臺自動化測試的服務。用戶上傳應用(*.apk)和用Cucumber(一種業務相關的DSL)編寫的測試文件,選擇測試運行需要的設備配置,最后測試將自動執行并生成測試報告。它支持的設備包括Garmin Asus,幾款HTC,LG,Samsung Galaxy,Sony Xperia和Motorola Motodefy。
為了了解更多LessPainful提供的服務細節,我們采訪了LessPainful公司的CEO Jonas Maturana Larsen。下面就是這次簡短的訪問:
InfoQ:在不同版本的Android上運行應用程序,存在什么問題?為了保證程序能正常運行,開發者需要在Android的每一個版本上測試他的應用嗎?
JML:舉個例子,SAXParser在Android 2.2之前有一個bug存在于對ContentHandler.startElement的回調中,它導致應用產生錯誤的行為。
到目前為止,我們已經在很多方面發現了不同操作系統版本間的差異性。其中一些可能在2.1-update1上導致崩潰,但可以正常運行于2.1-update3和2.2.
InfoQ:不同的設備對Android來說,有沒有真正的區別?你能否給我們舉個例子,比如Android2.2應用可以運行在HTC但不能運行于Samsung?(或其他各種Android版本和設備制造商的組合)
JML:在LG手機,HorizontalScrollViews有時會導致子視圖上的背景圖片消失。這個問題存在于我們測試的所有的LG手機,不管Android版本是多少。
如果你不自己處理這類問題,它將導致你的應用在不同設備上不盡相同。例如,Motorola將會用紅色邊框來高亮一個輸入域。在我曾經參與的一個項目中,我們用同樣的紅色邊框來表示輸入有誤。
還有一些問題,與其說和制造商相關,不如說是和硬件相關:比如,一些手機使用了較小的RAM和高分辨率的攝像頭,當你處理手機上的圖像時就會將導致崩潰。
InfoQ:這些測試是如何執行的?
JML:測試就如同運行一個ActivityInstrumentationTestCase2,主要使用Robotium來運行。我們對應用所做的唯一修改就是去掉已有的簽名,再為它重新生成我們的簽名文件。
在測試運行完成后,應用會被卸載,而手機也會被恢復到初始設置。
InfoQ:與MonkeyRunner,Robotium和Robolectric相比,你們所提供的服務有什么優勢呢?
JML:LessPainful是一種服務,而并不僅僅是一種架構。我們希望創建一種服務,不但使測試能夠進行,并且比起其他任何一種架構,它能夠節省我們大量測試時間,還能夠幫助我們發現更多的bug。
另外,我們相信使用Cucumber,可以清晰地定義高層次測試描述,同時可以更好地被開發團隊以外的人員共享。
以Git領域為例,我們更希望成為像是GitHub那樣,而不只是通常的git庫。
InfoQ:你們有計劃未來要支持更多的設備嗎?
JML:是的。我們計劃繼續增加對更多設備的支持。如果有這樣的要求提出,我們就會努力完成它。
目前,我們也在著手于對iOS設備的支持,希望beta版能在今年秋季發布。
InfoQ:什么是LessPainful企業版?
JML:我們將提供一個工具集,它就類似于一個Mac Mini,但我們會非常靈活的滿足顧客的需求。LessPainful企業版目前還沒有正式推出,所以敬請期待。
在六年半的開發和管理歷程中,曾經做過這樣的兩個項目,都是步履維艱、越做越增添無力感的項目,現在回想起這兩個項目,原來有那么多的相似點,而且原來從開始到結束都已經處處透露了危險的信息,只是在初期并未察覺,將危險訊號說出來,讓大家能引以為戒。
這兩個項目的共同危險點是:
(1)二手項目:都是5、6年前開發完成的項目,新系統的目標是用新平臺實現舊平臺相同的功能。
(2)開發文檔不全:第一個項目之前是C/S結構,使用dephi編寫,只有一份代碼眾多的dephi編寫的源代碼,涉及到業務邏輯的部分都封裝在tuxedo中,數據庫不用改造,數據庫操作邏輯部分依然調用之前的tuxedo業務。第二個項目使用甲方的呼叫平臺編寫,該平臺功能不夠強大,在所有涉及到數據庫操作的部分都調用由其開發人員編寫的SQL Server存儲過程,可以拿到甲方的文檔有:數據庫說明文檔、存儲過程源碼、呼叫流程(發現已經有一段時間沒有同步更新)、簡易的需求文檔。
(3)需求不明確:第一個項目沒有明確的說明文檔,為數不多的知道這個項目的人也只能說個五五六六,需要通過他們安裝好的C/S系統來了解,甚至要通過源碼來了解。第二個項目有簡易的需求文檔,但年久未更新,而上線的系統卻一直在更新,只能提供不夠完全的參考。
(4)之前開發人員的流動:第一個項目之前的甲方開發人員都已經走得七七八八,剩下的1、2個知道點情況的人也已經是從前任的前任手里接過來的項目,現在沒有正在運行的舊系統。第二個項目雖然情況好點,但知道項目總體情況的人也寥寥無幾,但是現網在全國80來個點都有舊系統在運行。
(5)都需要變更平臺:第一個項目數據庫結構不需要變更,但平臺需要變更,由dephi->Java,我們項目組無人學習過dephi。第二個項目之前采用甲方的呼叫開發平臺 + SQL Server存儲過程,新系統采用我方的呼叫開發平臺,該項目甲方還需要變更數據庫,從SQL Server變更為Oracle,并且有很長一段時間兩套系統要并行,因此不但涉及到要割接數據,還涉及到兩邊數據庫的雙向同步。
第一個項目從頭到尾都做得苦不堪言:工期緊張(貌似是2個月還是3個月)、項目組成員有幾個是新員工、dephi的代碼被甲方的開發人員寫得晦澀難懂,周旋于一個源文件4000、5000行的dephi代碼當中,而且甲方要求甚多,又不能提供良好的支持,項目組成員被摧殘得“花容”失色,而且經過日復一日的加班加點讓項目組成員流失慘重,經過延期、延期再延期,最后不出所料的以失敗收場。
現在如果來總結這個項目,如此多危險信號的項目就不應該簽約,這個項目的如此種種,注定了他是一個鐵定會失敗的項目。甲方開發人員甚多,有若干Java的開發人員,卻想交給第三方公司使用 Java來實現,從這里也可以看出這個項目并沒有如甲方前期所說的那樣是個不難應付的項目。可惜我等開發人員常常沒有做不做這個項目的權利,合同已經簽在那里了,只能提供做的過程中的參考意見,sigh……
第二個項目相對要好些,雖然暫時還沒有交付,但是交付的可能性還是很大的,但是現在已經延期了2、3月左右,在后期很大一部分開發工作都放在割接和同步方面,與甲方的存儲過程開發人員(也是甲方對該系統最了解的人員)J君交流時,我們私下認為:“這個項目最大的失誤在于當時沒采用同樣的數據庫結構,而導致給割接、同步和項目開發造成不必要的麻煩。” 而這個失誤的造成是由于項目前期雙方沒有人對割接、同步的問題引起重視,而將精力都放在系統的開發方面,當時由上頭決定了采用新的數據庫結構,前期在我方數據庫結構出來之前,甲方都沒有提供當前系統的數據庫說明文檔。
這個項目越到后期做得越步履維艱,為了避免重犯這樣的錯誤,總結如下,希望涉及到割接、同步、新舊系統并行的朋友開發時引以為戒:
(1)如果舊系統數據庫設計合理,不要動修改數據庫結構的念頭,那將是自討苦吃。因為如果是同樣的數據庫結構,即使新舊系統采用的是不同的數據庫,割接、同步等都可采用數據庫方案,即使數據庫層面無法實現,也有很多開源的程序能夠實現。但如果異庫、異構、同步,那將是極其耗費工時,并且麻煩的工作。
(2)如果相對數據庫進行優化,可為系統制造第二期計劃;
(3)抱著不想看舊系統業務邏輯代碼的想法都是過于理想、不現實的。這個項目我是前期的后半段加進來的,之前的核心開發人員對甲方的開發人員說:“我想最壞的情況就是要看你的業務邏輯源碼才能實現新系統,這是一份耗時耗力的工作。前期我盡量將你們實際的需求和注意的點都挖掘出來。”前期確實在需求上下了很多功夫,但是真正投入開發后才知道,了解程度遠遠不夠,很多之前的存儲過程因為年久未作修改,當時了解時甲方的開發人員都說得有異議。最后在項目后期還是落得去核對甲方的存儲過程來確認是否自己的開發過程有細節遺漏。
(4)不要幼稚到將一個已經運行了近6年、一直在增加和修改需求、并且在中國各地都分布運行、甲方若干能力還不錯的開發人員維護的系統想象得過于簡單。若干的地區個性化需求(有的需求甚至一點都不合理)、長久積累的靈活性功能等等,會讓你相信“沒那么簡單”。
縱觀這兩個項目,為何做得如此步履維艱?是否做過類似項目的你也有過這樣苦不堪言的體會?筆者所做過的其余多個全新系統,好像還沒遇到過開發得如此艱難險阻的。希望看到此文的技術同仁們,萬一不得已遇到類似的項目,千萬不要想得過于簡單吧!重視它,是成功的第一步!
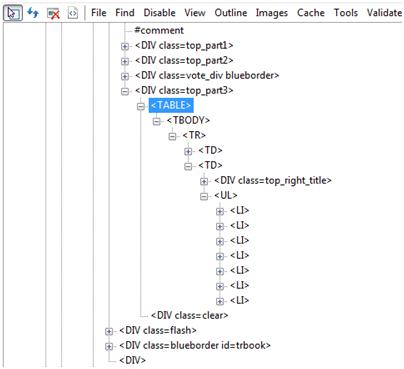
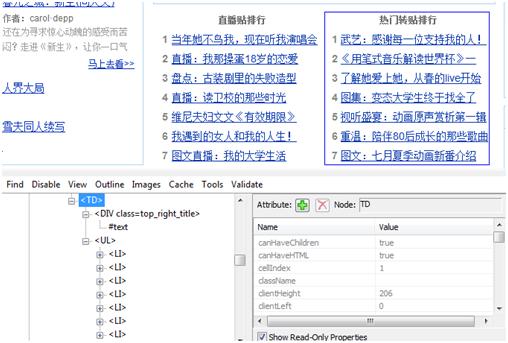
在Web測試中,不可避免的會遇到樹形節點的識別。如下就是通過IEDevToolBar抓下的一個page的樹形結構。
QTP在對樹形結構的節點進行識別時,可以采用DOM(Document Object Model文檔對象模型)模型,在DOM中,每個網頁元素都對應著一個對象。樹結構中每一個元素都被稱為一個節點。QTP可以通過DOM來訪問HTML標簽。在QTP中,訪問DOM主要通過使用page測試對象的object屬性來進一步訪問。
舉個簡單的例子:在百度貼吧首頁,我們需要獲得”熱門轉帖排行”下的標題。
代碼如下:
'獲得貼吧首頁熱門轉帖排行下的所有標題
Set oBj=Browser("貼吧").Page("貼吧page").WebTable("Table").Object
Set oDIV= oBj.getElementsByTagName("DIV")
num=0
For i=0 to oDIV.length-1
If oDIV(i).innertext="熱門轉貼排行" then
For j=0 to oDIV(i).NextSibling.ChildNodes.length-1
num=num+1
Datatable.SetCurrentRow(num)
Datatable.Value("innertext")=oDIV(i).NextSibling.ChildNodes(j).innertext '將獲得的標題儲存到Datatable中
Next
End If
Next
Set oBj=Nothing
Set oDIV=Nothing |
在這段代碼中,就是通過訪問貼吧頁面下的WebTable對象的Object屬性來進一步訪問HTML標簽的。
我們用到了幾個方法和屬性:
getElementsByTagName()方法:返回帶有指定標簽名的對象的集合。
NextSibling屬性:返回處于同級節點下某個元素之后緊跟的元素。
ChildNodes屬性:返回指定節點的子節點的節點列表。
我們借助于IEDevToolBar,可以發現,“熱門轉帖排行”這一列中,“熱門轉帖排行”是DIV的innertext,而底下的標題則分別是UL的innertext,因此要訪問到UL的節點列表,就需要用到NextSibling屬性。
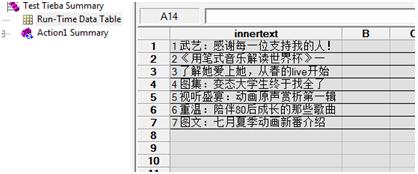
最后程序運行的結果在Report的Run-Time Data Table中:
DOM還有很多方法和屬性,之前提到了NextSibling,那么還有PreviouSibling;以及NodeName,NodeType,NodeValue等等。
關于NodeName,NodeType,NodeValue;很多人可能還有很多混淆,這里做些總結:
Nodetype:返回節點的類型,1為元素,2為屬性,3為文本,8注釋,9文檔
Nodename:返回節點的名稱,元素返回的是標簽名稱,屬性返回的是屬性名稱,文本返回的是#text(innertext),文檔返回的是#document
Nodevalue:返回當前節點的值,文本節點返回文本值,屬性節點返回屬性值,標簽和文檔節點返回null
其他的一些方法和屬性待大家自己學習DOM后了解。如果大家熟悉DOM的方法和屬性,在利用QTP做Web測試時,將會很有益處。
做軟件測試的目的在于找到缺陷和證明缺陷,在這個過程中進行全面覆蓋性或反復測試,以圖無限地趨近100%,結果可能很好,但工作效率非常低。在WEB安全測試上,如何避免大海撈沙,需要有的放矢,把有價值的信息淘出來。
安全測試的出發點和功能測試不太相同,安全測試的手段就是攻擊,攻擊,還是攻擊。尋找有價值的信息,就是測試的第一招。“淘金”就是其中的一種方式,一般來說由以下信息需要關注。
◆ HTML中的代碼注釋
◆ HTML中的敏感代碼
◆ 服務器或應用程序的錯誤信息和HTTP響應
代碼注釋是一塊很容易被開發人員忽略掉的信息,因為對于開發人員來說,這些就是他們做后期開發的“工程文檔”,再正常不過的東西,甚至很樂意文件中能有更的關鍵注釋。如代碼中會出現“標記為1時,表示XXX信息”或“若為空,則交由XX處理”。這類信息只需要通過閱讀HTML文件即可發現,并且對于攻擊者來說是非常好的指南。
如果攻擊者能夠根據通過對源代碼的處理,獲取到數據庫信息、用戶名、密碼等數據時,這個應用是非常危險的。要獲取這樣的信息,首先需要清楚應用間的數據傳遞方式。通過GET方式傳遞的,可以直接在URL中獲取到“參數名=參數值”,如果是通過POST傳遞的,就需要借助抓包工具,比如HttpFox、HttpWatch。當把所有關聯頁面都瀏覽完成后,就可以生成一張頁面間的映射關系圖,同時也可以知道它們之間參數的傳遞情況。如果應用程序實現了訪問級別區分,比如高級別用戶享有特權操作,那么就可以從低等級用戶開始,逐級淘金。通過映射圖閱讀源代碼,尋找注釋中引導信息,就可以獲得有價值的信息。除了手工地去尋找,還可以利用正則表達式自動搜尋。
當找到以上信息后,檢查頁面之間傳遞的參數,看看哪些參數能夠使得應用程序出錯,這個時候就能發現一些有用的信息。如連接數據庫時出錯,腳本無法處理,該出錯頁面不但會提示錯誤,還可能把出錯點附近的相關代碼也顯示出來,這些相關代碼可能會把數據庫名、表對象名及字段名等信息暴露出來。或者強行產生語法錯誤、營造無法處理的異常場景來破壞應用程序,則會得到服務器對其響應的許多函數調用。因此無論是應用程序還是Web服務器,應該謹慎維護好應對對策略。還有一種常見的漏洞,大家可以到各網站上去自行尋找,即對于用戶名和密碼輸入不正確時觸發不同的報錯信息。如果使用這樣的邏輯進行用戶名和密碼匹配的判斷,當攻擊者暴力破解時,他能夠很清楚的知道,當前使用的用戶名是否是已注冊用戶(當用戶名正確時,提示是密碼錯誤)。
如何進行防范
1、確定HTML中注釋是否包含敏感信息;或在日常環境中保留這些注釋,而在線上去除這些注釋。
2、盡量對于錯誤信息進行二次處理,盡量讓用戶看到的錯誤提示是模糊且有價值的;盡量把相關細節信息保留在服務器的日志文件中,方便開發調試的同時規避安全風險。同時需要定期檢查這些日志文件,了解是否有錯誤信息是未被處理的。
代碼示例:
public void test1() { //打開網站 selenium.open("http://xxx.xxx.xxx/yyy"); //通過Xpath 找到頁面中的某個DOM對象 selenium.select("xpath=//SELECT[@name='SBBUSYO']", "index=1"); //模擬點擊、輸入等頁面動作 selenium.click("xpath=//input[@type='button']"); //等待頁面加載 selenium.waitForPageToLoad("2000"); //斷言驗證是否正確轉向標題為“welcome”的頁面 assertEquals(selenium.getTitle(), "Welcome"); } |
代碼會啟動IE或者firefox執行,這樣就將單元測試可以覆蓋到了開發的全部環節。我們公司現在使用的LoadRunner是協議級的測試,通過對get\post協議的分析進行測試。
Selenium 是DOM級的測試,通過Xpath 尋找頁面標簽,驗證是否實現了希望的功能。Selenium支持js,和多瀏覽器,所以還可以用于測試瀏覽器兼容性。
百度進行web自動化測試的一些相關經驗:
1. 通過一些自己寫好的框架,加載.xls 文件數據導入測試用例的數據。對于一些需要反復回歸測試的測試用例,測試人員只需要用Excel填寫測試數據就可以。
2. 測試人員更專注于業務、流程比較復雜的用例,簡單的業務可以自動化測試。
3. Web自動化測試并不是為了找到bug,而是作為系統的一個安全網和防護欄,保證代碼的變動不會造成基礎和核心模塊出現問題。
4. Web自動化測試只能應用適合的場景,很多頁面還是需要人工測試。以百度目前的經驗,大概也只有20-30%的web可以進行自動化測試。所以需要精心挑選和設計測試用例。
5. 測試人員最好也擁有編寫代碼的能力。
TDD 測試驅動開發
1. 測試驅動開發:寫代碼前先寫測試。
2. 如何切入TDD?:從上到下寫代碼。即寫Web測試>Jsp頁面>Action測試>Action實現>service測試>service實現……
3. 通過測試和上層方法進行驅動開發。比如你寫Action測試時發現需要跳轉首頁的方法,就驅動在Action建立toIndex()方法。在Action發現你需要Service ,就建立Service對象,利用IDE的輔助提示功能,快速的進行驅動開發。
4. 隨時重構,包括Test的代碼。如果感覺代碼有bed smell就馬上重構。
5. 對于暫時沒有實現的或者無法實現的,通過Mock的方式實現。
6. Web測試可以先寫空業務場景,暫不實現,因為Web測試需要完整功能開發完畢并進行部署和服務啟動,并且耗時也比較長。
7. 測試用例是一種文檔,測試方法名稱以表達測試目的為第一目標。演示的時候講師經常起了這樣的方法名:Public void testShowMoreDetailWhenFrendListOver5(){} //當好友列表大于5個時顯示"show more"
任何一個測試的開始都要制定一個完整的測試計劃,現在我們就從web安全測試的測試計劃開始
要做一個測試計劃首先要明確測試需求。在寫測試計劃之前必須要明確測試需求,
暗含的要求:例如很少看到這樣明確話的文檔要求:“入侵這相應手冊中不許友拼寫錯誤”但同時有些組織是允許拼寫錯誤存在的。這樣暗含的要求我們就要明確,可以通過和主管部門或是用戶溝通來明確這樣的要求。
不完全的或模糊的要求
比如:“所有的網站都應該安裝SP3補丁”這樣的要求就是模糊不清的,因為沒有指明是操作系統還是網站服務軟件,或是某些具體的系統軟件。這樣的需求就應該有需求提出的人來明確,確定在什么系統上安裝sp3補丁。
未指明的要求
如:“必須使用強密碼”看起來還向沒什么問題,但從測試觀點看,設么是強密碼呢?是常超過7個字符的,還是應該有大小寫的。這樣的要求我們就應該根據密碼要求標準具體化,比如:要求密碼加強必須大于7個字符。
籠統的要求
比如“站點必須是安全的”盡管每個人都會同意這個要求,但展點能夠徹底安全的唯一方法就是,斷開展點的所有連接,內網的外網的,然后鎖在一個加了封條的屋子里。但是這并不是要求的本意。這樣的要求應該具體化,制定要求達到的安全程度。
好了要求明確了,下面就說一下就話的結構。呵呵我也是學來的,照別人的說吧,也有我的體會
測試計劃的結構
測試計劃可以依照工業標準(例如軟件文檔標準——Std.829)組織,也可以基于內部摸版,甚至可以用創獻禮的全新個是編排。但大家一定要注意一點,測試計劃重要的不是個是而是創建測試計劃的過程一定要獲得測試組的認可。但有的測試必須用規格的測試計劃格式,行業內部摸版或行業標準,這樣的測試如:政府機構、保險承銷商等。
測試計劃可以長達幾百頁,也可以簡單的只有一張紙,關鍵測試計劃必須實用,也不必要把大量的人力和物理花費在測試計劃上,要根據具體情況來確定。
根據IEEE Std.829-1998(軟件測試文檔標準1998年修訂版)來介紹測試計劃的內容
1.測試計劃標題
就是說沒個測試計劃和每個測試計劃的版本都應該有一個公司內部的獨一無二標示,這也是文檔控制和版本控制的基本要求,我覺得在正規公司的同仁們都應該明白。
2.介紹
這一部分適度測試的一個總的概括,通過這一部分一該讓讀者明白此項目的準確目標和測試組如何達到這些目標。根據情況也可以做一些基本概念的解釋,比如為什么要做安全測試等等。
3.項目范圍
在這一部分中明確項目的測試目標,如果在介紹中已經描述的測試目標的話在這一部分應該詳盡的介紹測試目標。同時在這一部分可以列出在測試中不設計的測試項。
4.變動控制過程
這一部分主要是解決再測試中如果有需要變動的測試項應做如何處理,可參考CCB(變動控制委員會)的意見進行適當的變動。