Play 框架是一個完整的 Web 應用開發框架,覆蓋了 Web 應用開發的各個方面。它借鑒了流行的 Ruby on Rails 和 Grails 等框架,又有自己獨有的優勢。具體表現在以下幾個方面:其一,通過 Play 框架提供的命令行工具,可以快速創建Java Web 應用。其二,它擁有Java 代碼動態編譯機制,在修改代碼之后,不需要重啟服務器就可以直接看到修改之后的結果。其三,它還使用 JPA 規范來完成領域對象的持久化,可以很方便的使用不同的關系數據庫作為后臺存儲。其四,它使用 Groovy 作為視圖層模板使用的表達式語言。模板之間的繼承機制避免了重復的代碼。總的來說,Play 框架非常適合快速創建Web 應用開發。本文將為有一定Java Web框架基礎的讀者,來重點介紹如何使用play框架來編制一個最簡單的信息增刪改查應用。
一、安裝Play框架
安裝play框架前,只需要使用JDK 1.5以上的版本即可,將官網上的play框架下載后解壓到某個指定目錄下,使用的是eclipse開發工具即可。在本文中,將介紹的例子,是一個關于公司、部門、員工之間的CRUD操作,其關系為:一個公司有很多部門,一個部門有很多個員工。
二、開始使用PLAY框架的腳手架功能
PLAY框架為能讓用戶快速開始搭建play系統的原型。下面是使用play中腳手架功能的步驟:
在命令行方式下,轉到play框架的安裝目錄,本文假設為c:\play下。
假設我們的應用的名稱為corporations,則在play中,新建立一個應用只需要用如下命令即可:play new corporations,其中new表示新建應用,new后的名稱則為應用的名稱。
在輸入上面的語句后,會提示輸入確認系統的名字,這里輸入corporations,按回車確認即可。
我們使用cd corporations目錄中,會發現已經有play自帶的框架的內容了。我們可以在命令行方式下,執行play run,這時play就會啟動自帶的jetty服務器,將應用啟動起來。
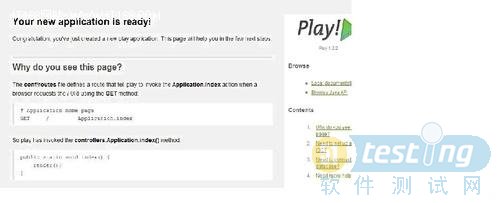
在啟動后,可以通過瀏覽器瀏覽剛才新建的應用了,方法是http://localhost:9000,就可以看到一個默認的play應用,其中顯示的首頁中,簡單指導了一些簡單的配置方法。如下圖:
三、配置應用 將框架工程導入eclipse
我們為了要在eclipse中方便我們的編碼,所以需要把play剛為我們建立好的框架工程導入到我們的eclipse中去,所以我們按如下步驟去做:
1、使用CTRL-C,先把我們正在運行的應用停止下來。
2、依然在corporations目錄下,輸入play eclipse,表示要生成能導入eclipse的框架工程。
3、再啟動eclipse ,然后使用導入工程的方法,把corporations工程導入。
4、在這個例子中,用的只是HSQL,所以打開conf/application.conf文件,將下面的
db=mem 語句前的注釋符號去掉,表示我們將使用hsql。
5、同樣,在conf/application.conf文件中,增加如下這行,表示我們將使用play腳手架框架自帶的CRUD功能:
| module.crud=${play.path}/modules/crud |
6、在conf/routes文件中,增加如下這行:
注意,在play框架中,routes是路由控制器,這行表示,將所有的CRUD操作都是只有通過 */admin訪問的請求,才能實現play自帶的CRUD功能。
7、在進行上述修改后,我們再到命令行方式下,運行play eclipse,然后再到ECLIPSE下按F5刷新一下
8、如果此時再使用play run,運行會發現暫時還沒有更新,因為我們要進行數據層的配置。
Play 框架是一個完整的 Web 應用開發框架,覆蓋了 Web 應用開發的各個方面。它借鑒了流行的 Ruby on Rails 和 Grails 等框架,又有自己獨有的優勢。具體表現在以下幾個方面:其一,通過 Play 框架提供的命令行工具,可以快速創建Java Web 應用。其二,它擁有Java 代碼動態編譯機制,在修改代碼之后,不需要重啟服務器就可以直接看到修改之后的結果。其三,它還使用 JPA 規范來完成領域對象的持久化,可以很方便的使用不同的關系數據庫作為后臺存儲。其四,它使用 Groovy 作為視圖層模板使用的表達式語言。模板之間的繼承機制避免了重復的代碼。總的來說,Play 框架非常適合快速創建Web 應用開發。本文將為有一定Java Web框架基礎的讀者,來重點介紹如何使用play框架來編制一個最簡單的信息增刪改查應用。
一、安裝Play框架
安裝play框架前,只需要使用JDK 1.5以上的版本即可,將官網上的play框架下載后解壓到某個指定目錄下,使用的是eclipse開發工具即可。在本文中,將介紹的例子,是一個關于公司、部門、員工之間的CRUD操作,其關系為:一個公司有很多部門,一個部門有很多個員工。
二、開始使用PLAY框架的腳手架功能
PLAY框架為能讓用戶快速開始搭建play系統的原型。下面是使用play中腳手架功能的步驟:
在命令行方式下,轉到play框架的安裝目錄,本文假設為c:\play下。
假設我們的應用的名稱為corporations,則在play中,新建立一個應用只需要用如下命令即可:play new corporations,其中new表示新建應用,new后的名稱則為應用的名稱。
在輸入上面的語句后,會提示輸入確認系統的名字,這里輸入corporations,按回車確認即可。
我們使用cd corporations目錄中,會發現已經有play自帶的框架的內容了。我們可以在命令行方式下,執行play run,這時play就會啟動自帶的jetty服務器,將應用啟動起來。
在啟動后,可以通過瀏覽器瀏覽剛才新建的應用了,方法是http://localhost:9000,就可以看到一個默認的play應用,其中顯示的首頁中,簡單指導了一些簡單的配置方法。如下圖:
三、配置應用 將框架工程導入eclipse
我們為了要在eclipse中方便我們的編碼,所以需要把play剛為我們建立好的框架工程導入到我們的eclipse中去,所以我們按如下步驟去做:
1、使用CTRL-C,先把我們正在運行的應用停止下來。
2、依然在corporations目錄下,輸入play eclipse,表示要生成能導入eclipse的框架工程。
3、再啟動eclipse ,然后使用導入工程的方法,把corporations工程導入。
4、在這個例子中,用的只是HSQL,所以打開conf/application.conf文件,將下面的
db=mem 語句前的注釋符號去掉,表示我們將使用hsql。
5、同樣,在conf/application.conf文件中,增加如下這行,表示我們將使用play腳手架框架自帶的CRUD功能:
| module.crud=${play.path}/modules/crud |
6、在conf/routes文件中,增加如下這行:
注意,在play框架中,routes是路由控制器,這行表示,將所有的CRUD操作都是只有通過 */admin訪問的請求,才能實現play自帶的CRUD功能。
7、在進行上述修改后,我們再到命令行方式下,運行play eclipse,然后再到ECLIPSE下按F5刷新一下
8、如果此時再使用play run,運行會發現暫時還沒有更新,因為我們要進行數據層的配置。
六、建立部門跟員工之間的連接關系
現在我們在建立了部門類和員工類后,可以開始建立它們之間的關聯關系了。由于一個部門中是有多個員工,所以在員工類employee中,寫入如下代碼,建立兩個類之間的關聯:
| @ManyToOne public Department department; |
這里依然使用了@ManyToOne的JPA注解去實現多對一的關系。在再次運行程序后,會發現,在增加員工時,會出現下拉菜單選擇框,讓其選擇該員工屬于哪一個部門。
七、建立公司實體類和控制類
最后,我們建立公司實體類和控制類。同樣,在app/models目錄下,建立Company類如下:
| package models; import javax.persistence.Entity; import play.db.jpa.Model; @Entity public class Company extends Model { public String name; public String address; public boolean isPublic; } |
company的控制層類代碼如下:
| package controllers; import models.Company; @CRUD.For(Company.class) public class Companies extends CRUD { } |
這里要提醒一點的是,由于company的復數是companies,而play框架原先約定俗成的是在實體類名后直接加字母s,所以這里使用了注解 @CRUD.For(Company.class),以表明該控制類文件Companies是為company實體類服務的。
同樣,一個公司里有許多部門,因此在Deparment部門類中,建立如下的多對一關系:
| @ManyToOne public Company company; |
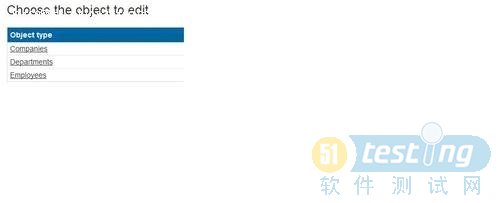
再次運行程序,可以看到,現在三個實體類都建立起來了,可以分別對公司,部門和員工進行CRUD操作,如下圖:
八、優化列表
我們在查看每個實體類的列表時,發現在列表中,會把每條記錄的id都顯示出來,這個在程序中假設不需要看到id字段的話,可以通過修改代碼實現,比如在Company類中,增加toString方法即可:
| public String toString() { return name; } |
而在Department和Employee類中,可以采用同樣的方法,以不顯示它們的id字段。
九、增加校驗規則
在輸入數據時,校驗規則是必不可少的,在play框架中,可以很方便地使用注解來增加校驗規則,比如在員工類中,可以要求輸入的fullName字段內容不能超過100個字符,而且fullName字段不能為空,則在Employee類中,增加如下代碼即可:
| @Required @MaxSize(100) public String fullName; |
下面列出一些常見的校驗規則:
@Email 校驗email合法性
@InFuture 檢驗是否將來的日期
@InPast 檢驗是否是過往的日期
@Match 對正則表達式的判斷
@Max 最大值
@Min 最小值
@Range 檢驗范圍
@URL 檢驗是否URL
十、改變列表的顯示格式
在默認情況下,比如查看employee列表,只能看到employee的名稱字段,假設要在列表中看到每條記錄的每個字段的話,要修改下play的模版,方法如下:
1、停止現在的服務,CTRL-C停止。
2、在命令行下,輸入:
play crud:ov --template Employees/list
這將在app/views/Employees目錄下新建立一個list.html的頁面。
3、重新輸入play run,并切換到eclipse中的項目中,按F5更新頁面。
4、在eclipse中,打開app/views/Employees/list.html,這個是雇員列表的模版文件。
5、在該頁中,找到id=”crudListTable”部分,修改為:
| #{crud.table fields:['fullName', 'dateOfHire', 'salary'] /} |
即顯示完整所有字段。
6、重新運行程序,即可看到效果,如下圖,可以看到,能看到所有字段值。

十一、改變列表中標題的顯示
在默認狀態下,列表中顯示的字段標題是用實體類中的名稱的,假如想把fullName修改位Full Name的話,可以在conf/messages下,增加:
fullName=Full Name
即可,如下圖顯示:

小結
在本文中,我們學習了如何使用Play框架的腳手架功能,快速搭建CRUD的應用原型。Play框架的配置方法簡化了工作代碼量。目前Play框架正在不斷的完善中,讀者可以根據本教程的指引實際操作后,進一步閱讀官方文檔加以深入學習。