 .
.
測試專屬數據(Test specific data):真正影響測試行為的特征數據
了解了測試引用數據和測試專屬數據的區別后,我就可以介紹測試數據構造第一秘技了:
將測試引用數據和測試專屬數據的準備過程分離,分離復用測試引用數據準備,而將測試專屬數據保存在測試腳本中。
具體的做法是,第一個例子中,我們建議在每個測試案例里面,先使用一段公共程序為每個案例準備一樣的測試引用數據,然后再用UPDATE語句來將測試專屬數據導入,測試案例的偽碼如下:
測試案例1
從CSV導入測試引用數據
測試專屬數據導入
UPDATE transactions SET amount = 15.99 WHERE id = 1; UPDATE transactions SET amount = 30.98 WHERE id = 2; UPDATE transactions SET amount = 75.95 WHERE id = 5; UPDATE transactions SET amount = 150.9 WHERE id = 10;UPDATE transactions SET amount = 750.5 WHERE id = 50; |
測試執行
測試驗證 (總和是1024.32)
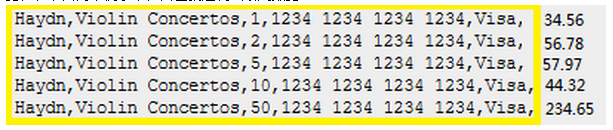
測試案例2
從CSV導入測試引用數據
測試專屬數據導入
UPDATE transactions SET amount = 34.56 WHERE id = 1; UPDATE transactions SET amount = 56.78 WHERE id = 2; UPDATE transactions SET amount = 57.97 WHERE id = 5; UPDATE transactions SET amount = 44.32 WHERE id = 10; UPDATE transactions SET amount = 234.65 WHERE id = 50; |
測試執行
測試驗證 (總和是428.28)
這樣做主要有兩點好處:
測試案例可維護性:上面這些案例中,測試引用數據由于使用了INSERT語句,它其實會受到數據庫表結構變化的影響,而測試專屬數據準備由于使用UPDATE語句,不會受到數據庫表結構變化的影響。我們通過統一測試引用數據準備程序,將這種變化的沖擊大大降低,未來數據表結構變更,我們只需修改統一的測試引用數據準備程序而無需修改每一個案例,這其實暗合了DRY原則(Don’t repeat yourself)。
測試案例可讀性:由于我們將測試引用數據準備從獨立出來了,只要看測試案例本身,就可以明確地看到測試專屬數據,被測行為和結果驗證,讓案例可讀性大大提升。
為了便于大家理解,我們再舉另一個例子,假設有一個測試匯率轉換接口,測試輸入是xml文件:
應用測試引用數據和測試專屬數據分離原則,可以看到哪些是引用數據,哪些是專屬數據
因此,在測試案例中,我們會先準備并加載一個基底XML文件,再設置測試專屬數據,下面是利用Robot Framework編寫的兩個測試案例,可以看出,未來如果XML文件的結構有任何變更,我們都只需要修改基底XML文件即可,而不需要修改任何測試案例了
至此,我們想大家已經明白,對于測試數據準備這個步驟而言,將測試引用數據和測試專屬數據分離,會非常有效地提升測試案例可維護性和可讀性。