Rational AppScan 工作原理
Rational AppScan(簡稱 AppScan)其實是一個產品家族,包括眾多的應用安全掃描產品,從開發階段的源代碼掃描的 AppScan source edition,到針對 Web 應用進行快速掃描的 AppScan standard edition,以及進行安全管理和匯總整合的 AppScan enterprise Edition 等。我們經常說的 AppScan 就是指的桌面版本的 AppScan,即 AppScan standard edition。其安裝在 Windows 操作系統上,可以對網站等 Web 應用進行自動化的應用安全掃描和測試。
來張 AppScan 的截圖,用圖表說話,更明確。
圖 1. AppScan 標準版界面
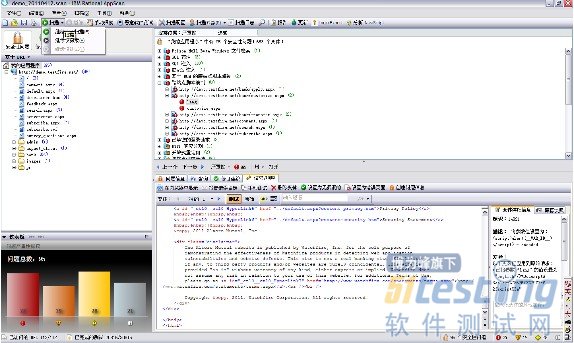
請注意右上角,單擊“掃描”下面的小三角,可以出現如下的三個選型“繼續完全掃描”、“繼續僅探索”、“繼續僅測試”,有木有?什么意思?理解了這個地方,就理解了 AppScan 的工作原理,我們慢慢展開:
還沒有正式開始安全測試之前,所以先不管“繼續”,直接來討論“完全掃描”,“僅探索”,“僅測試”三個名詞:
AppScan 三個核心要素
AppScan 是對網站等 Web 應用進行安全攻擊來檢查網站是否存在安全漏洞;既然是攻擊,需要有明確的攻擊對象吧,比如北約現在的對象就是卡扎菲上校還有他的軍隊。對網站來說,一個網站存在的頁面,可能成千上萬。每個頁面也都可能存在多個字段(參數),比如一個登陸界面,至少要輸入用戶名和密碼吧,這就是一個頁面存在兩個字段,你提交了用戶名密碼等登陸信息,網站總要有地方接受并且檢查是否正確吧,這就可能存在一個新的檢查頁面。這里的每個頁面的每個參數都可能存在安全漏洞,所有都是被攻擊對象,都需要來檢查。
這就存在一個問題,我們來負責來檢查一個網站的安全性,這個網站有多少個頁面,有多少個參數,頁面之間如何跳轉,我們可能并不明確,如何知道這些信息?看起來很復雜,盤根錯節;那就更需要找到那個線索,提綱挈領;想一想,訪問一個網站的時候,我們需要知道的最重要的信息是哪個?網站主頁地址吧?從網站地址開始,很多其他頻道,其他頁面都可以鏈接過去,對不對,那么可不可以有種技術,告訴了它網站的入口地址,然后它“順藤摸瓜”,找出其他的網頁和頁面參數?OK,這就是“爬蟲”技術,具體說,是“網站爬蟲”,其利用了網頁的請求都是用 http 協議發送的,發送和返回的內容都是統一的語言 HTML,那么對 HTML 語言進行分析,找到里面的參數和鏈接,紀錄并繼續發送之,最終,找到了這個網站的眾多的頁面和目錄。這個能力 AppScan 就提供了,這里的術語叫“探索”,explorer,就是去發現,去分析,了解未知的,并記錄之。
在使用 AppScan 的時候,要配置的第一個就是要檢查的網站的地址,配置了以后,AppScan 就會利用“探索”技術去發現這個網站存在多少個目錄,多少個頁面,頁面中有哪些參數等,簡單說,了解了你的網站的結構。
“探索”了解了,測試的目標和范圍就大致確定了,然后呢,利用“軍火庫”,發送導彈,進行安全攻擊,這個過程就是“測試”;針對發現的每個頁面的每個參數,進行安全檢查,檢查的彈藥就來自 AppScan 的掃描規則庫,其類似殺毒軟件的病毒庫,具體可以檢查的安全攻擊類型都在里面做好了,我們去使用即可。
那么什么是“完全測試呢”,完全測試就是把上面的兩個步驟整合起來,“探索”+“測試”;在安全測試過程中,可以先只進行探索,不進行測試,目的是了解被測的網站結構,評估范圍;然后選擇“繼續僅測試”,只對前面探索過的頁面進行測試,不對新發現的頁面進行測試。“完全測試”就是把兩個步驟結合在一起,一邊探索,一邊測試。
AppScan 工作原理小結如下:
通過搜索(爬行)發現整個 Web 應用結構
根據分析,發送修改的 HTTP Request 進行攻擊嘗試(掃描規則庫)
通過對于 Respone 的分析驗證是否存在安全漏洞
圖 2. AppScan 掃描原理:掃描規則庫 + 爬行 + 測試

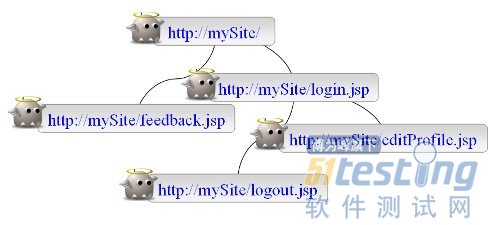
步驟 1:探索(又叫爬行,爬網)
圖 3. 探索(爬網,爬行)
步驟 2:測試(針對找到的頁面,生成測試,進行安全攻擊)
圖 4. 針對探索發現的頁面和參數,進行安全測試

所以,簡言之,AppScan 的核心是提供一個掃描規則庫,然后利用自動化的“探索”技術得到眾多的頁面和頁面參數,進而對這些頁面和頁面參數進行安全性測試。“掃描規則庫”,“探索”,“測試”就構成了 AppScan 的核心三要素。而在安全掃描過程中,如何進行優化,就要結合這三個要素,看哪些部分需要優化,應該如何優化。
AppScan 結果文件
同時,對于 AppScan 標準版來說,掃描的配置和結果信息都保存為后綴名為 Scan 文件,Scan 文件里面主要包括的內容如下:
掃描配置信息:掃描配置信息,如掃描的目標網站地址,錄制的登陸過程腳本等,選擇的掃描設置等都保存在 Scan 文件中。
所有訪問到頁面信息:針對每個發現的頁面,即使沒有進行測試,在探索過程也會訪問該頁面并紀錄 http request/response 信息;所以如果探索的頁面訪問的時候返回的頁面內容比較多,頁面比較大,那么即使只做了探索根本沒有掃描,整個 Scan 文件也會很大。
測試階段,記錄測試成功的測試變體和頁面訪問信息:針對每個頁面都會發送多次測試(測試變體),每次測試都會有 Request/response 信息,這些信息如果測試通過,即發現了一個安全問題,則會把該測試變體對應得 request/response 都會紀錄下來,保存在 .scan 文件中;由于 AppScan 的掃描測試用例庫全面,對于每種安全威脅漏洞,都會發送多個安全測試變體(Variant)進行測試,比如對于 XSS 問題,AppScan 發送了 100 個變體,其中 30 個執行失敗,70 個變體執行成功,則會紀錄 70 次執行成功的具體變體信息,以及每個變體對應的 Request/Response 信息。這就是一個很大的數據量。這些信息保存以后,就可以在不連接在網站的情況下進行結果分析,快速顯示當時測試的頁面快照等。
我們以http://demo.testfire.net/bank/customize.aspx 為例,如下就有 74 個變體都發現了 Customize 頁面的 Lang 參數存在跨站點腳本執行(XSS)類型的安全漏洞:
圖 5. 測試變體顯示

所以針對 AppScan 標準版來說,由于需要保存的信息比較多,結果文件是會比較大的,最根本的方法還是有針對性地進行掃描和測試,使用排除頁面等排除冗余頁面,把一個大的系統分解為多個小的掃描任務等。
好的,了解了 AppScan 的原理,我們就結合原來討論下為什么掃描大型網站時候可能遇到問題了。
大型網站技術特點分析
AppScan 掃描的對象是網站等 Web 應用,而網站規模的大小和使用的技術,都需要針對性的進行掃描設置,我們遇到的很多問題,都是在掃描規模比較大的網站時候遇到的,如一個網站頁面數目超過 2000 個,需要執行的掃描用例是 50,000 個,在掃描這樣的網站時候,默認情況下 AppScan 的掃描 scan 文件可能超過 100M 了,掃描效率就可能比較慢,需要長時間的掃描運行時間。
下面,我們就來分析大型網站中存在的一些可能影響 AppScan 掃描的技術特點。
網站頁面多,頁面參數多,則 AppScan 需要發送的測試用例多
什么叫大型網站,顧名思義,網站規模大,提供內容多;具體說是頁面很多,內容很全。比如 www.sina.com.cn,比如 http://music.10086.cn/,網站中都有多個頻道,包括上萬個頁面。而且除了頁面多,可能還有一個特點 --- 頁面參數多,即要填寫的地方多,和用戶的交互多;比如一個網站如果都是靜態頁面(.html、.jpg 等),沒有讓用戶輸入的地方,那么可以利用,可以作為攻擊點的地方也就不多。如果頁面到處都是有輸入有查詢,要求用戶來參與的,你輸入的越多,可能泄露的信息也越多,可能被別人利用的攻擊點也就越多,所以和頁面參數也是有關系的。
AppScan 產生測試用例的時候,也是根據每個參數來產生的,簡單說,如果一個參數,對應了 200 個安全攻擊測試用例,那么一個登陸界面至少就對應 400 個了,為什么?登陸界面至少有用戶名(username)和密碼(password)兩個字段吧?每個字段 200 個攻擊用例。
這個簡單吧,還可以更復雜:如果遇到下面的兩個地址,那要掃描多少次呢?
http://www.Test.com/focus/satisfy/file.jsp?id=1
http://www.Test.com/focus/satisfy/file.jsp?id=2 |
上面的兩個地址有類似的,“?”號以前的 URL 地址完全一樣,“?”號后面帶的參數不同,這種可以認為是重復頁面,那么對于重復頁面,是否要重復測試呢?
這取決于“冗余路徑設置”,默認的是最多測試 5 次;即,這種類型 URL 出現的前 5 次,那么就是要測試 1000 個攻擊用例了。
如果再繼續修改下:遇到下面的 URL 呢
http://www.Test.com/focus/satisfy/file.jsp?id=&Item=open
http://www.Test.com/focus/satisfy/file.jsp?id=2&Item=close |
每個 URL 里面都有 2 個參數,測試的次數就更多了。想象下,如果這個網頁里面的參數如果是 10 個,或者更多的呢?比如很多網站提交注冊信息的時候,要填寫的欄位就很多,要進行的安全測試用例也就隨之不斷增加…
這是網站規模的影響,還有一個問題,就出在“每個參數,發送 200 個安全測試用例”這個假設上。這個假設的前提來源于哪里?來源于我們選擇的掃描規則庫。即你關心那些安全威脅,這個需要在測試策略里面選擇。同樣來參照殺毒軟件,你會用殺毒軟件來查找一些專用的病毒嗎,比如 CIH、木馬;應用安全掃描也是一樣的道理,如果有明確的安全指標或者安全規則范圍,那么就選擇之。這些可能來源于企業的規范,來源于政府的法律法規。就要根據你的理解,在這里選擇。
圖 6. 選擇測試策略

在實際工作中,我們也很難在最開始的階段,就把掃描規范制定下來,按照項目經理們的口頭禪“漸進明細”,“滾動式規劃”,在實踐中,更多時候也是摸著石頭過河,選擇了一個掃描策略,然后根據結果分析,看是否需要調整,不斷優化。比如選擇默認的“缺省值”掃描策略,對網站進行掃描,發現其“敏感信息”里面會去檢查頁面上是否含有 Email 地址,是否含有信用卡號碼等,如果我們覺得這些信息,顯示在頁面上是正常的業務需要(比如這樣的鏈接:<a href=mailto:admin@www.test.com>有問題請聯系admin@www.test.com</a>),我們就可以取消掉這些規則,所以掃描規則也很大程度上影響著我們的掃描效率。
網站采用多種混合的技術,需要不同的掃描設置
一些大型網站,往往是一個統一的入口,在里面提供不同的內容,而這些內容可能來源于不同的技術。如我們熟悉的門戶網站,里面就有“財經”、“體育”、“娛樂”等多個頻道;每個頻道的內容,可能是采用不同的技術,對應不同的服務器。如一個網站的“論壇”頻道,就有很多類似的頁面:
http://www.Test.com/bbs/showthread.php?id=1
Http://www.Test.com/bbs/showthread.php?id=2
Http://www.Test.com/bbs/showthread.php?id=3 |
這里的 showthread.php 頁面存在多次,每次都是參數值不同,訪問后發現這些頁面除了文本內容外,其他的頁面結構等都相同,則這些頁面只需要選擇幾個典型的掃描即可,沒有必要全部掃描。
而同時,在另外的一些頻道,存在另外類型的頁面:
http://www.Test.com/default.aspx?content=inside_community.htm
http://www.Test.com/default.aspx?content=inside_press.htm
http://www.Test.com/default.aspx?content=inside_executives.htm |
這些動態頁面,也是網址相同,參數相同,但是具有不同的參數值,訪問時候發現每種類型的參數值都指向了完全不同的頁面,則需要每種參數值都要測試到。這種情況經常存在跳轉頁面中。
而這兩個頻道中,第一種情況,可以選擇典型的頁面掃描之,而第二種情況則需要進行完全的掃描,每種參數值都需要考慮到。這就需要不同的掃描設置。
同時,可能大家也注意到了,第一種情況下的是 php 頁面,而第二種情況下的則是 aspx 頁面,對應不同的開發技術,這也可能需要不同的掃描設置。
所以,總結下,AppScan 的掃描受到如下因素的影響:
網站規模(頁面個數,頁面參數)
掃描策略的選擇
掃描設置
而對于大型的網站,我們經常需要從幾個方面來優化配置
選擇合適的,最小化的掃描規則
分解掃描任務,把一個大的掃描任務分解為多個小的掃描任務
根據頁面特點,設置可以過濾的類似頁面(冗余頁面)