此文是前文的后續���,內容是在前輪性能測試的調優后,進行的調優結果驗證�。演示了如何對比兩輪測試的結果���,如何分析突然出現波動的原因��,如何根據大量的數據驗證調優的效果、驗證能否達到預期性能目標����,以及更重要的思考過程��。這是一個比較不錯性能測試調優后驗證的實例��?���?梢郧宄吹綄I人事���,對性能調優后的數據����,進行客觀的比較,分析,再進一步判斷調優的效果。故分享之。
由于本人能力不夠,很多術語,不太明確其中文翻譯,如大家看到有錯誤�,請不吝賜教�����。例如,在文章圖片中% Difference in XXXX 和5.Per.Mov.Avg不知道是如何計算,又該如何翻譯的好�����。
Spike - 數據增加明顯��,形成一個尖����,暫譯:波動
Peak - 數據到達最大值,暫譯:高峰或者峰值
Degradation / Degrade - 性能變差�����,暫譯:退化
Job - 定期執行的后臺程序或服務�����,暫譯:作業
原文連接: http://apmblog.compuware.com/2013/07/11/an-integrated-approach-to-load-test-analysis-part-2-the-follow-up-test/
以下為正文
本文由Andreas Grabner共同撰寫,他是Compuware的APM卓越中心的團隊負責人(Team Lead for the Compuware APM Center of Excellence)。
在之前的一篇文章中,我演示了如何做更深入的分析 - 合并了由Compuware APM網絡負載測試工具(Compuware APM Web Load Test,以下簡稱WLT)得到的外部網絡負載測試結果和由Compuware PureStack技術收集硬件設備的狀態數據���。但是,現在我們已經測試過系統一次,在“解決”我們發現的問題之后�,如果我們再次進行測試���,那又會出現什么呢��?使用前一輪測試時相同的參數,再運行一輪測試,就知道性能得到顯著改善��?我們系統能夠達到期望的負載目標嗎 - 支持200個虛擬用戶��,很少或者沒有性能退化���?
此文將帶領你一步一步���,比較兩次負載測試的結果再判斷調優之后性能的改善(或退化)��。
第1步:根據第一次測試的結果,確定問題和進行調優
在4月14日的負載測試期間,我和Andreas Grabner發現我們網站在高負載下�,有顯著的性能問題����,這時的負載已遠超目前水平����,即使是在APM社區網站人氣最高時的負載水平。這些問題是造成負載水平達不到開發團隊想要達到的目標 - 200個虛擬用戶。

匯總的數據視圖展現4月14日的負載測試中的外部和內部性能指標
在4月14日負載測試執行時�,我們發現了一些環境問題���。系統團隊記錄下關鍵問題包括:
部署關鍵的APM社區程序到其他的機器���,以防止某一層的性能負面地影響到其他層(Deployment of critical APM Community applications to different machines to prevent the application performance of one layer negatively affecting another laye)
優化應用程序層 - APM社區網站的頁面生成方式���,以降低CPU使用率
優化Confluence的緩存設置,當加載常用的對象時����,可以減少來回查詢數據庫次數
增加虛擬機的CPU分配����,以便他們能夠處理更多的負載�����。
第2步:再次運行測試(使用相同的參數?。?/strong>
一旦這些調整完成后���,根據第二輪測試的結果�,在調優后的環境上,驗證是否能夠達到預期的目標 - 200 虛擬用戶并發�,且沒有響應時間退化的現象�����。第二輪負載測試被安排在整整1周后,即4月21日����,并使用第一輪測試時相同的參數(負載增壓(load ramping)的細節設置參考前一篇文章)�����。使用相同的測試參數(負載增壓����,測試腳本���,測試位置���,測試數據等)是至關重要的�,只有如此��,測試結果的對比才有意義(Using the same test parameters (load ramp, test scripts, testing locations, databanks, etc.) is critical in order to allow a like-for-like comparison to occur.)����。任何測試參數的偏差�����,會影響到最終結果����,影響對應用程序環境的判斷��,可能導致對調優的不真實的信任(或懷疑)���。
當4月21日這輪負載測試完成后�,我們開始分析測試結果����,初步的數據(更高的吞吐量,更快的響應時間���,更低的CPU占用率和更低的數據庫負載),表明這輪負載測試比前一輪的測試更為成功���。這個初步結論是基于性能圖表(包含了我們分析4月14日測試時曾使用的相同的數據),這個圖表直接對比其關鍵數據���,突出在兩輪測試執行之間����,性能表現是否存在了巨大的變化。
第3步:對比測試結果
好了,開始對比分析,我們從4月14日和4月21日兩輪測試的結果中采取了三個關鍵指標,并把兩輪數據放在一起比較對比:外部負載測試(External WLT)的平均響應時間;負載測試(WLT)的每分鐘事務數�;網絡服務器的CPU利用率����。只需對比這三組數據�,很顯然,這兩輪負載測試有非常不同的性能表現。
從WLT測試的平均響應時間(負載測試中腳本里事務匯總后�,完全下載的所有內容所需的時間 - the time required to completely download all of the content in the scripted synthetic transactions used in the load test)�����,很明顯,在08:50 - 測試開始后的40分鐘,響應時間的線開始出現分支�����,隨后也分得越來越遠�����,表現兩輪測試的不同結果�����。從這個數據上看,21日的平均響應時間比14日的短50%左右(注:移動平均線,5分鐘平均響應時間的變化差值的百分比,是一條更清晰的走向 - the Moving Average of percentage change averages 5 minutes of response time change to produce an clearer trend line)。21日的測試中��,又花了近20分鐘���,平均事務響應時間才達到20秒���,即使當時負載水平跟14日時是一樣的���。

響應時間的對比表明在4月21日的APM社區網站負載測試的提升 - 更短的平均響應時間
WLT每分鐘事務數(負載測試中�����,WLT的一分鐘內事務執行的數量)顯示出一個共同點��,其中21日測試和14日測試的數據也是在08:50出現差異。由于從08:50開始,直到測試結束���,一直保持更短的WLT平均響應時間,4月21日測試中系統每分鐘處理的事務數量比4月14日測試中的要多出40%~50%。

每分鐘事務數對比表明在4月21日的APM社區網站負載測試的提升 - 更多的每分鐘事務數
第三個指標也顯示出明顯提升:網絡服務器的CPU利用率(機器上系統和應用程序的執行所有必要的任務所使用的CPU百分比)�?��?v觀4月21日的測試中���,網絡服務器�,經由更多的硬件和優化網頁渲染方式的幫助��,CPU在整個測試過程的壓力有所減小�����,達到100%的使用率時遠遠晚于4月14日測試時的表現。

CPU使用率對比表明在4月21日的APM社區網站負載測試的提升 - 09:40之前的更低的CPU使用率
這三個指標直接關系到每分鐘網絡請求數量(記錄于4月21日測試的Confluence 應用程序層)���。這個數據在4月21日的測試中高峰時達到每分鐘125~140個,而相比4月14日的測試�����,其中高峰時每分鐘約100 個請求��。
盡管看似成功的4月21日的第二輪負載測試,仍然存在有一些問題�����。4月21日負載測試的綜合數據圖表���,顯示當CPU使用率達到100%的邊界后(下圖中的紅色豎線)����,出現了多個性能數據波動。這表明�,盡管上面所討論的環境有所改善���,但在較高負載時還存在著CPU瓶頸����。
在數據庫結果中記錄了兩輪測試之間一個極端反差�。4月14日的測試中數據庫的統計數據清晰顯然(請參考在第1步中的性能指標圖),包含在程序達到CPU的瓶頸前�����,查詢的數量和執行時間都出現大波動��。但想要在4月21日測試中���,找到同一指標����,你得用上你的顯微鏡和非常貼近地看向圖表的底部(you have to break out your microscope and look very closely at the bottom of the chart)�����。

4月21日負載測試的外部與內部性能表現數據
數據庫負載的減少,是4月14日負載測試后�����,啟用優化的緩存設置的直接結果�����。隨著更多的數據被存儲在應用程序緩存中�����,需要直接在數據庫中查詢的數量下降�����,此數據層在此目前負載量下不能再算為一個潛在的瓶頸。
第4步:結果分析和下一步
在4月21日測試Confluence / Atlassian的處理過程沒有突然的波動(連同數據庫的波動)的��,是由于在運行的負載測試期間���,移除了應用程序層定期執行的作業(job)����。這個作業會影響到系統和用戶體驗,當Andreas審查他的數據���,很快就確認出這個作業問題。一旦這個作業被確認是造成這個問題的元兇���,4月21日測試時它就被移除掉了,完全消除了這個早在4月14日測試時遇到的性能瓶頸�。
教訓:不要在流量高峰期安排會影響系統的作業���;找到流量最低的一個時間段,并在此時間段執行這些作業,以便盡可能最少的游客受到影響����。
正如我們在這篇文章的開始說的����,表面上看���,4月21日的負載測試比4月14日的測試���,更加成功�����。然而目前�����,盡管21日的負載測試性能表現有所提升,結果仍然顯示出還有其他性能問題有待解決���。問題表現在負載測試運行后90分鐘,在09:40和09:50之??間��,響應時間出現非常奇怪的波動�。
當系統開始性能退化,它會體現在這3個關鍵指標:WLT平均響應時間���;WLT每分鐘的交易;CPU利用率。當正在運行的事務開始需要更長的時間來執行���,同時網絡到應用層請求數下降和測試工具中每分鐘執行事務數下降,在下面的圖表可以看到它的根本原因,此圖去掉了一些數據(decreasing both the number of incoming web requests to the application layer and the number of transactions per minute executed by the load generation system, the root cause can be seen in the chart below, which removes some of the data series)。
當167個虛擬用戶時�����,是系統的臨界值���,之后突然10分鐘內性能下降����,然后恢復后����,測試穩定在200個虛擬用戶(點擊圖片見大圖)
在負載測試進行到09:40時,這個性能下降期間被檢測出來�,同時:
WLT工具達到167個虛擬用戶
網絡服務器的CPU使用率達到100%
WLT工具的每分鐘事務數為平均130
Confluence的網絡請求達到每分鐘135次(這是APM社區網站的應用程序)
有趣的是�,10分鐘后��,這個問題徹底消失了�,除了事務響應時間。響應時間沒有回到波動前的水平��,而是現在的平均響應時間比波動前的平均值要高出近20秒����。隨著系統到了200個虛擬用戶頂峰時,并沒有額外的負載增加���,看著其他指標立即回到波動前的水平 - 尤其是每分鐘事務數和每分鐘請求數,非常有趣。因此��,波動后隨著這33個虛擬用戶增加����,系統表現出又直接受到CPU瓶頸的影響,更高的負載并不能增加在應用程序層處理的請求數量。
拋開這些數據(Out of this sea of metrics)��,我們看到的是對比4月14日的測試�����,4月21日的負載測試時程序性能變現的確有所提升,但第二輪測試仍無法達到預期目標 - 200個虛擬用戶�,存在一個瓶頸��,導致性能急劇下降。
分析退化
要找到阻礙4月21日測試達到目標(200個虛擬用戶并且沒有或很少性能退化)的CPU瓶頸的根源����,我們必須更深入一些����,檢查服務器端的指標�,特別是那些和應用程序服務器的健康狀態相關的指標。事務數下降是伴隨系統出現的問題�����,當系統達到167個虛擬用戶(The dip in transactions throughout the system is aligned with the issue captured when the system hit 167 VUs.)?�,F在的問題是:事務處理數下降和事務響應時間增加是這種負載下的結果����?還是性能下降真正根源的一個癥狀�?
服務器端的數據顯示,高垃圾回收(Garbage Collection)可能是一個問題��,因為當系統性能下降�����,這個自動的過程湊巧地也同時發生了���。很顯然��,當網絡服務器的CPU已經被耗盡時,再執行一個非常有影響的任務���,會導致性能大幅下降���。
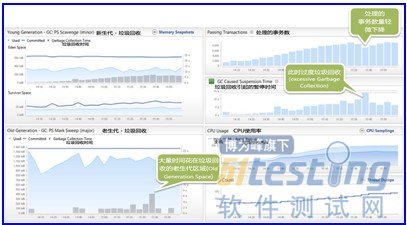
當負載增加�����,GC的增加是正常的 - 但有一個不尋常的波動正是當我們看到的這個事務數量下降
檢查在應用程序服務器具體的事務響應時間����,很容易發現潛在問題�����。下面的圖表顯示��,“又一個”后臺作業依然在每隔一小時周期性地壓榨已經被耗盡系統的CPU。

當虛擬用戶經歷性能下降時,后臺作業每隔一小時執行一次�,占用CPU的300S
檢查這些事務��,該作業是每小時執行的更新作業,同步緩存的用戶對象以及用戶目錄數據庫(user directory database)。這需要相當長的也值得重視的時間,因為我們APM社區系統中有65000多個用戶��。該更新的作業導致了很多對象的創建和銷毀 - 因此增加的內存和GC活動。

同步作業是性能下降的根本原因����,導致高GC活動����,消耗了大量的CPU以及增加內存分配
通過4月14日��,4月21日的兩輪負載測試���,找出系統無達到200虛擬用戶目標的不少的問題�����。但是現在��,我們知道阻礙達成這個目標的罪魁禍首��,因此努力在高負載下,集中精力減少或消除此更新作業對系統的影響。
結論
在這兩輪測試中,無論你是如何衡量“成功的”負載測試,通過匯總測試中內部和外部硬件的指標����,我們現在知道���,4月14日的負載測試之后進行的調優����,使得系統在預定作業會導致了嚴重性能下降的情況下����,能夠每分鐘處理額外40%~50%的事務,支持多達167個虛擬用戶。
只有有了這個數據才能轉為可操作項,因為我們有一個程序能將防火墻內部采集到的數據���,很輕松地整合外部負載測試工具的結果數據。這樣,盡管是在非常受控的情況����,也成為分析系統性能的一個因素����。(This data was only able to be turned into actionable information because we had a process in place that allowed results captured from inside the firewall to be easily aligned with the external results from the load test system. By doing this, the customer, albeit in a very controlled form, becomes a factor in the analysis of system performance.)
通過創建一個完整的性能角度��,PureStack比只提供負載下系統技術指標的�����,提供得更多����。當進行結果分析時,PureStack視用戶體驗的重要性如CPU�,數據庫和應用程序處理請求數一般����。根據用戶體驗的重要性����,然后決定如何劃分問題的優先級和如何解決他們。這些對最終用戶有影響的問題提供了真實世界的反饋 - 您的應用程序在峰值期間所出現性能問題的真實成本(The importance of the user experience then dictates how infrastructure issues are prioritized and resolved, as the effect these issues have on end users provides real-world feedback into the true cost of performance issues that occur to your application during peak periods)�。
根據負載測試中的數據�,可以確定系統需要的額外修改����,特別是頁面呈現方面,需要進一步降低CPU負荷����,使系統能夠達到和保持負載峰值為200的虛擬用戶�。隨著Confluence應用軟件的升級 - 2013年7月初部署的程序 - 達到預期的目標���。但假設這是不夠的��,一旦系統已經穩定運行���,2013年7月將會有對新Confluence系統的額外負載測試��。并且通過使用4月14日和21日的負載測試中同樣事務的路徑�����,將對新系統進行驗證���,以確認升級能帶來所期望的性能表現�����。
版權聲明:本文出自 在劫錄 的51Testing軟件測試博客:http://www.51testing.com/?166582
原創作品�,轉載時請務必以超鏈接形式標明本文原始出處���、作者信息和本聲明��,否則將追究法律責任�。