當描述代碼之類的東西時,我不喜歡 “氣味(smell)”這個詞。因為用擬人的手法來談論比特和字節往往令人覺得很怪異。并不是說“氣味”這個詞不能準確地反映出某種表明代碼可能有錯誤的癥狀,只是我覺得這樣聽起來很滑稽。然而,我依然選擇再次用這種令人厭煩的方式來描述軟件構建,坦白說,這是因為這些年我見過的很多構建腳本都散發著難聞的氣味。 在創建構建腳本時,即使是偉大的程序員也常常會遇到困難。就好像最近才學會如何編寫程序性 代碼似的 —— 他們還會編寫龐大的單塊構建文件、通過復制-粘貼編寫代碼、對屬性進行硬編碼等等。我總是很想知道為什么會這樣。也許是因為構建腳本沒有被編譯成客戶最終會使用的東西?然而我們都知道,要創建客戶最終使用的代碼,構建腳本是中心,如果那些腳本敗絮其中,那么要想有效地創建 軟件,就需要克服重重挑戰。
幸運的是,您可以輕松地在構建(不管是 Ant、Maven 還是定制的)之上部署一些實踐,它們雖然可以幫助您創建一致的、可重復的、可維護的構建,但其過程會很長。學習如何創建更好的構建腳本的一種有效的方法是搞清楚哪些事情不要 去做,理解其中的道理,然后看看做事的正確 方法。在本文中,我將詳細論述您應該避免的 9 種最常見的構建中的氣味,為什么應該避免它們,以及如何修復它們:
惟 IDE 的構建
復制-粘貼式的編寫腳本方法
冗長的目標
龐大的構建文件
沒有清理干凈
硬編碼的值
測試失敗還能構建成功
魔力機
格式的缺失
這里無意給出完整的列表,不過這份列表的確代表了近年來我讀過的和寫過的構建腳本中,我遇到的較為常見的一些氣味。有些工具,例如 Maven,是為處理與構建有關的很多管道而設計的,它們可以幫助減輕部分氣味。但是無論使用什么工具,還是有很多問題會發生。
避免惟 IDE 的構建
惟 IDE(IDE-only)的構建是指只能通過開發人員的 IDE 執行的構建,不幸的是,這似乎在構建中很常見。惟 IDE 的構建的問題是,它助長了 “在我的計算機上能運行”問題,即軟件在開發人員的環境中可以運行,但是在任何其他人的環境中就不能運行。而且,由于惟 IDE 構建自動化程度不是很高,因而為集成到持續集成(Continuous Integration)環境帶來極大的挑戰。實際上,沒有人為的干預,惟 IDE 常常無法自動化。
我們要清楚:使用 IDE 來執行構建并沒有錯,但是 IDE 不應該成為能構建軟件的惟一環境。特別是,一個完全用腳本編寫的構建,可以使開發團隊能夠使用多種 IDE,因為只存在從 IDE 到構建的依賴性,而不存在相反方向的依賴性,如圖 1 所示:
圖 1. IDE 與構建的依賴關系
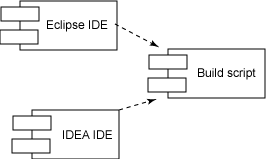
惟 IDE 的構建有礙自動化,清除的惟一方法就是創建可編寫腳本的構建。有足夠的文檔和太多的書籍可以為您提供指導(見 參考資料),而像 Maven 之類的項目也為從頭開始定義構建提供了極大的方便。不管采用何種方法,都是選擇一種構建平臺,然后盡快地讓項目成為可編寫腳本的。
復制-粘貼就像廉價的香水
復制代碼是軟件項目當中一個常見的問題。實際上,甚至很多流行的開放源碼項目都存在 20% 到 30% 的復制代碼。代碼復制令軟件程序更難于維護,同理,構建腳本中的復制代碼也存在這樣的問題。例如,想象一下,假設您需要通過 Ant 的 fileset 類型引用特定的文件,如清單 1 所示:
清單 1. 復制-粘貼 Ant 腳本
<fileset dir="./brewery/src" >
<include name="**/*.java"/>
<exclude name="**/*.groovy"/>
</fileset> |
如果需要在其他地方引用這組文件,例如為了編譯、檢查或生成文檔,那么最終您可能會在多個地方使用相同的 fileset。如果在將來某個時候,您需要對那個 fileset 做出修改(比如說排除 .groovy 文件),那么最終可能需要在多個地方做更改。顯然,這不是可維護的解決方案。然而,要除掉這股氣味其實很簡單。
如清單 2 所示,通過 Ant 的 patternset 類型可以引用一個邏輯名稱,以表示所需要的文件。那么,當需要向 fileset 添加(或排除)文件時,只需更改一次。
清單 2. 復制-粘貼 Ant 腳本
<patternset id="sources.pattern">
<include name="**/*.java"/>
<exclude name="**/*.groovy"/>
</patternset>
...
<fileset dir="./brewery/src">
<patternset refid="sources.pattern"/>
</fileset> |
對于精通面向對象編程的人來說,這種修復方法看上去很熟悉:既定的慣例不是在不同的類中一次又一次地定義相同的邏輯,而是將那個邏輯放在一個方法中,在不同地方都可以調用這個方法。于是,這個方法成為惟一的維護點,從而可以限制錯誤級聯并可以鼓勵重用。
不要摻入冗長目標的氣味
Martin Fowler 在他撰寫的 Refactoring 這本書中,對代碼中存在冗長方法的氣味這個問題做了精妙的描述 —— 過程越長,越難理解。實際上,冗長方法最終會擔負太多的責任。當談到構建時, 冗長目標這種構建氣味是指更難于理解和維護的腳本。清單 3 就展示了一個相當冗長的目標:
清單 3. 冗長目標
<target name="run-tests">
<mkdir dir="${classes.dir}"/>
<javac destdir="${classes.dir}" debug="true">
<src path="${src.dir}" />
<classpath refid="project.class.path"/>
</javac>
<javac destdir="${classes.dir}" debug="true">
<src path="${test.unit.dir}"/>
<classpath refid="test.class.path"/>
</javac>
<mkdir dir="${logs.junit.dir}" />
<junit fork="yes" haltonfailure="true" dir="${basedir}" printsummary="yes">
<classpath refid="test.class.path" />
<classpath refid="project.class.path"/>
<formatter type="plain" usefile="true" />
<formatter type="xml" usefile="true" />
<batchtest fork="yes" todir="${logs.junit.dir}">
<fileset dir="${test.unit.dir}">
<patternset refid="test.sources.pattern"/>
</fileset>
</batchtest>
</junit>
<mkdir dir="${reports.junit.dir}" />
<junitreport todir="${reports.junit.dir}">
<fileset dir="${logs.junit.dir}">
<include name="TEST-*.xml" />
<include name="TEST-*.txt" />
</fileset>
<report format="frames" todir="${reports.junit.dir}" />
</junitreport>
</target> |
這個冗長的目標(相信我,我還見過冗長得多的目標)要執行四個不同的過程:編譯源代碼、編譯測試、運行 JUnit 測試和創建一個 JUnitReport。要擔負的責任已經夠多了,更不用說將所有 XML 放在一個地方所增加的相關的復雜性。實際上,這個目標可以拆分成四個不同的、邏輯上的目標,如清單 4 所示:
清單 4. 提取目標
<target name="compile-src">
<mkdir dir="${classes.dir}"/>
<javac destdir="${classes.dir}" debug="true">
<src path="${src.dir}" />
<classpath refid="project.class.path"/>
</javac>
</target>
<target name="compile-tests">
<mkdir dir="${classes.dir}"/>
<javac destdir="${classes.dir}" debug="true">
<src path="${test.unit.dir}"/>
<classpath refid="test.class.path"/>
</javac>
</target>
<target name="run-tests" depends="compile-src,compile-tests">
<mkdir dir="${logs.junit.dir}" />
<junit fork="yes" haltonfailure="true" dir="${basedir}" printsummary="yes">
<classpath refid="test.class.path" />
<classpath refid="project.class.path"/>
<formatter type="plain" usefile="true" />
<formatter type="xml" usefile="true" />
<batchtest fork="yes" todir="${logs.junit.dir}">
<fileset dir="${test.unit.dir}">
<patternset refid="test.sources.pattern"/>
</fileset>
</batchtest>
</junit>
</target>
<target name="run-test-report" depends="compile-src,compile-tests,run-tests">
<mkdir dir="${reports.junit.dir}" />
<junitreport todir="${reports.junit.dir}">
<fileset dir="${logs.junit.dir}">
<include name="TEST-*.xml" />
<include name="TEST-*.txt" />
</fileset>
<report format="frames" todir="${reports.junit.dir}" />
</junitreport>
</target> |
可以看到,由于每個目標只擔負一種責任,清單 4 中的代碼理解起來要容易得多。根據用途分離目標,不但可以減少復雜性,還為在不同上下文中使用目標創造了條件,必要時還可以重用。
龐大的構建文件也有一種很重的氣味
Fowler 還將 龐大的類也看作一種代碼氣味。就構建腳本而言,有這種類似氣味的就是龐大的構建文件,它相當難以讀懂。很難知道哪個目標是做什么的,目標的依賴關系是什么。這同樣會給維護帶來問題。而且,龐大的構建文件通常有相當多的剪切-粘貼的痕跡。
為了縮小構建文件,可以從腳本中找出邏輯上相關的部分,將它們提取到更小的構建文件中,由主構建文件來執行這些較小的構建文件(例如,在 Ant 中,可以使用 ant 任務調用其他構建文件)。
通常,我喜歡根據核心功能拆分構建腳本,確保它們可以作為獨立腳本來執行(想想構建組件化)。例如,在我的 Ant 構建中,我喜歡定義四種類型的開發者測試:單元、組件、系統和功能。而且,我還喜歡運行四種類型的自動檢查工具:編碼標準、依賴性分析、代碼覆蓋范圍和代碼復雜度。我不是將這些測試和檢查工具的執行放在一個龐大的構建腳本中(還加上編譯、數據庫集成和部署),而是將測試和檢查工具的執行目標提取到兩個不同的構建文件中,如圖 2 所示:
圖 2. 提取構建文件
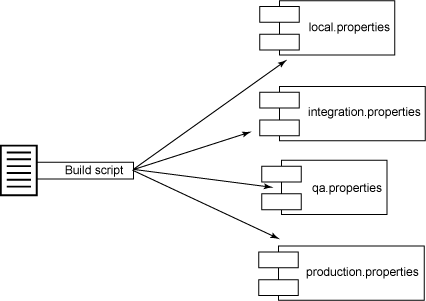
更小、更簡潔的構建文件維護和理解起來要容易得多。實際上,這種模式對于代碼而言同樣適用。我們似乎在這里看到了模式的概念,不是嗎?
沒有清理
沒有嚴格減少所有底層假設的構建無疑是一顆定時炸彈。例如,如果構建沒有避免一些簡單的假設,例如會去掉用陳舊的數據生成的二進制文件,那么前一次構建遺留下來的文件就會引起錯誤。或者,正是由于前一次構建留下的文件,構建竟然得以"成功",這種情況更糟糕。
幸運的是,這個問題的解決辦法很直觀:只需刪除任何之前的構建留下的所有目錄和文件,就可以很容易地消除假設。這個簡單的動作就可以減少假設,保證構建的成功或失敗都是正確的。清單 5 演示了通過使用 delete Ant 任務刪除之前的構建所使用的所有文件或目錄,從而清理構建環境的一個例子:
清單 5. 事先清理
<target name="clean">
<delete dir="${logs.dir}" quiet="true" failonerror="false"/>
<delete dir="${build.dir}" quiet="true" failonerror="false"/>
<delete dir="${reports.dir}" quiet="true" failonerror="false"/>
<delete file="cobertura.ser" quiet="true" failonerror="false"/>
</target> |
眾所周知,舊的構建遺留下來的文件會導致很多不必要的麻煩。為了自己的方便,在運行一個構建之前,務必先刪除構建所創建的任何工件。
硬編碼的臭味
復制-粘貼式的編程有礙重用,將值進行硬編碼又何嘗不是呢。當構建腳本包含硬編碼的值時,如果某個方面需要修改,那么就需要在多個地方修改那個值。更糟糕的是,很可能會忽略了某個地方而沒有改那個值,從而引起與不匹配的值相關的錯誤,這種錯誤是很隱蔽的。而且,如果相信我的建議,選擇使用多個構建腳本,那么硬編碼的值將可能會成為構建維護中最終的挑戰。在這一點上也請相信我!
例如,在清單 6 中,run-simian 任務有很多硬編碼的路徑和值,即 _reports 目錄:
清單 6. 硬編碼的值
<target name="run-simian">
<taskdef resource="simiantask.properties"
classpath="simian.classpath" classpathref="simian.classpath" />
<delete dir="./_reports" quiet="true" />
<mkdir dir="./_reports" />
<simian threshold="2" language="java"
ignoreCurlyBraces="true" ignoreIdentifierCase="true" ignoreStrings="true"
ignoreStringCase="true" ignoreNumbers="true" ignoreCharacters="true">
<fileset dir="${src.dir}"/>
<formatter type="xml" toFile="./_reports/simian-log.xml" />
</simian>
<xslt taskname="simian"
in="./_reports/simian-log.xml"
out="./_reports/Simian-Report.html"
style="./_config/simian.xsl" />
</target> |
如果硬編碼 _reports 目錄,那么當我決定將 Simian 報告放到另一個目錄時,就會很麻煩。而且,如果其他工具在腳本的其他地方使用這個目錄,那么很可能會有人輸錯目錄名稱,導致報告顯示在不同的目錄中。這時可以定義一個屬性值,由這個屬性值指向這個目錄。然后,在整個腳本中都可以引用這個屬性,這意味著當需要更改的時候,只需光顧一個地方,即屬性的定義。清單 7 展示了重構之后的 run-simian 任務:
清單 7. 使用屬性
<target name="run-simian">
<taskdef resource="simiantask.properties"
classpath="simian.classpath" classpathref="simian.classpath" />
<delete dir="${reports.simian.dir}" quiet="true" />
<mkdir dir="${reports.simian.dir}" />
<simian threshold="${simian.threshold}" language="${language.type}"
ignoreCurlyBraces="true" ignoreIdentifierCase="true" ignoreStrings="true"
ignoreStringCase="true" ignoreNumbers="true" ignoreCharacters="true">
<fileset dir="${src.dir}"/>
<formatter type="xml" toFile="${reports.simian.dir}/${simian.log.file}" />
</simian>
<xslt taskname="simian"
in="${reports.simian.dir}/${simian.log.file}"
out="${reports.simian.dir}/${simian.report.file}"
style="${config.dir}/${simian.xsl.file}" />
</target> |
硬編碼的值不僅沒有提高靈活性,反而擬制了靈活性。就像在源代碼中很容易硬編碼數據庫連接 String 一樣,在構建腳本中也應該避免將路徑之類的東西硬編碼。
測試失敗時,構建卻能成功
構建遠遠不止于單純的源代碼編譯,它還可能包括自動化開發者測試的執行,如果想讓軟件一直正常運行,那么決不能允許構建中有任何失敗的測試。別忘了,如果測試都得不到信任,那么還要測試干什么呢?
清單 8 是這種構建氣味的一個例子。注意 junit Ant 任務的 haltonfailure 屬性被設置為 false(它的缺省值)。這意味著即使任何 JUnit 測試是失敗的,構建也不會失敗。
清單 8. 氣味:測試失敗,構建卻成功
<junit fork="yes" haltonfailure="false" dir="${basedir}" printsummary="yes">
<classpath refid="test.class.path" />
<classpath refid="project.class.path"/>
<formatter type="plain" usefile="true" />
<formatter type="xml" usefile="true" />
<batchtest fork="yes" todir="${logs.junit.dir}">
<fileset dir="${test.unit.dir}">
<patternset refid="test.sources.pattern"/>
</fileset>
</batchtest>
</junit> |
有兩種方法防止構建中的這種氣味。第一種方法是將 haltonfailure 屬性設置為 true。這樣就可以防止測試失敗構建卻成功的情況發生。
對于這種方法,我惟一不喜歡的地方是,我想看看有多大百分比的測試遭到了失敗,以便弄清楚失敗的模式。因此第二種方法就是,每當有測試失敗,就設置一個屬性。然后,我對 Ant 進行配置,使得當執行了所有的測試之后,構建最終失敗。這兩種方法都行之有效。清單 9 演示了使用 tests.failed 屬性的第二種方法:
清單 9. 測試令構建失敗
<junit dir="${basedir}" haltonfailure="false" printsummary="yes"
errorProperty="tests.failed" failureproperty="tests.failed">
<classpath>
<pathelement location="${classes.dir}" />
</classpath>
<batchtest fork="yes" todir="${logs.junit.dir}" unless="testcase">
<fileset dir="${src.dir}">
<include name="**/*Test*.java" />
</fileset>
</batchtest>
<formatter type="plain" usefile="true" />
<formatter type="xml" usefile="true" />
</junit>
<fail if="tests.failed" message="Test(s) failed." /> |