Select語句的基本結構如下:
Select [All | Distinct] select_list
[Into [new_table-name]]
Form {table_name | view_name}
[,{table_name2 | view_name2}
….,{table_name10|view_name10}]
[Where search_conditions]
[Group By group_by_list]
[Having search_conditions]
[Order By order_list [ASC| DESC]] |
第一行語句中select_list表示需要檢查的字段的列表,字段名稱間用逗號分隔
All 指明查詢結果中可以顯示值相同的列,且為系統默認 *
Distinct 指明查詢結果中如有值相同的列,則只顯示其中的一列 唯一值
第二行語句中Into子句用于把查詢結果存放到一個新建的表中 as 。。。。
new_table-name 指明新建表的名稱
第三行語句中Form 子句指定需要查詢的表注:只要Select中又要查詢的列就必須使用From子句
table_name / view_name 指明Select 語句要用到的表,視圖等數據源,該列表中的數據表名和視圖名之間使用逗號分隔
第四行語句中 Where子句是制定數據檢索的條件,以限制返回的數據行
第五行語句中Group By 子句指定查詢結果的分組條件
第六行語句中 Having 子句指定分組搜索條件,通常與Group By子句一起使用,它與Where語句類似只是其作用對象不同,Where子句作用于表和視圖,Having子句作用于組。
最后一行語句Order By 子句指定查詢結果的排序方式,ASC是升序(系統默認),DESC 降序
下面具體介紹一下Group By 子句
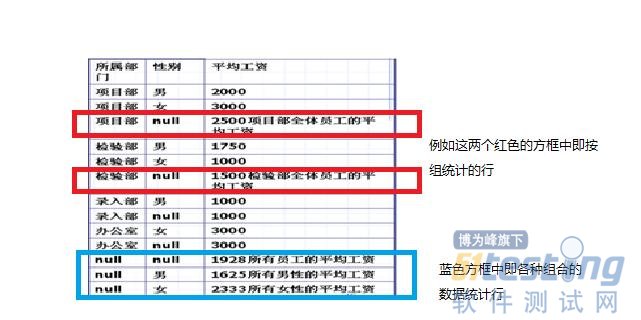
ALL:表示返回所有可能的查詢結果組合,即使此組合中沒有任何滿足Where子句的數據,分組的統計列如果不滿足查詢條件,則將由null值構成其數據
Cube:除了返回由Group By子句指定的列外,還返回按組統計的行,返回的結果按分組的第一個條件列排序顯示,以此類推。統計行包括了Group By子句指定的列的各種組合的數
據統計
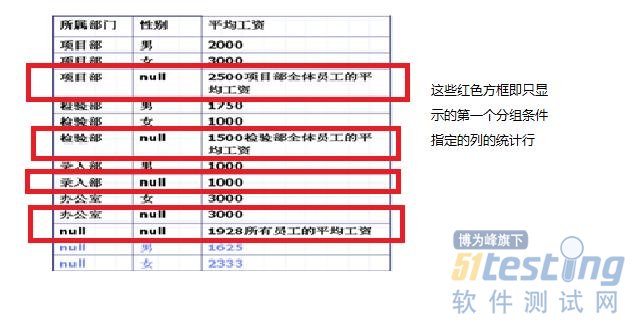
Rollup:只返回第一個分組條件指定的列的統計行,改變列的順序會使返回的結果發生變化
舉例:按所屬部門分類,找出工資大于來2000的所有員工
下面兩個圖即分別是為Cube的返回結果和Rollup的返回結果
如何提高Select語句的效率
1、使用exists關鍵字檢查結果集:不要用count(*)來檢查結果集中是否包含行
2、使用標準連接代替嵌套查詢:在執行嵌套查詢時,SQL Server將執行內部的子查詢,然后將查詢結果返回給外部查詢作為檢索的數據源,最后執行外部的主查詢。而在執行包含標準聯接的查詢時,SQL Server將要查詢的僅僅是一個查詢
3、有效避免整表掃描:使用索引,除了缺失索引外,可能導致整表掃描的另一種情況是在like子句的匹配條件的開始使用了%,如果這樣將會調用整表掃描。