擴展性與硬件
隨著系統的膨脹,硬件的可擴展性體現在增加資源,提高性能的能力上,如添加更多的處理器、內存等。
擴展性與軟件
擴展性要求軟件能夠有效地利用硬件的能力,軟件的設計應該支持并行計算。對于數據庫引擎,這意味著服務器組件必須支持多線程計算,允許操作系統在所有處理器核心上執行并行任務調度。不僅如此,數據庫引擎必須提供有效的方法,以在多核上分解工作負荷。舉個例子,如果數據庫只使用四個線程,那么它在四核處理器和八核處理器上允許,并不能體現出性能差異。
分布式設計
數據庫引擎分割工作流,以充分利用硬件的能力并非易事,不是所有的數據庫管理系統都能很好地支持并行計算。不僅僅是數據庫引擎,數據庫和其它系統資源都必須進行分割,以解決相互依賴性關系。因此,整個系統需要一個分布式設計。
例如,大多數數據庫以B樹架構存儲索引。B樹使得索引可以快速地定位數據,高效地插入、刪除數據,但這需要保持“平衡”,即B樹的樹架構必須具有相同層級的葉節點。一個簡單的插入或刪除操作都可能打破這種平衡。這導致在多核、多線程之間B樹的管理與共享非常困難。多個線程會頻繁搶奪B樹的根節點,這會導致性能瓶頸。
最小化共享資源
最小化共享資源的數量是擴展性的重要話題。最小化共享資源可以使不同的線程運行在不同的核心之上,而無需等待其它線程釋放共享資源。如果線程缺乏獨立性,即便增加處理器,性能也會大打折扣。
這個概念可以通過數據庫管理系統RDM予以體現。RDM對分布式數據庫有非常智能的支持,允許應用在不同的硬件之上進行數據的分布式計算,并能在不同的線程、進程之間盡可能地減少競爭。
多版本并發控制與同時訪問
對同一數據的并發讀寫訪問非常重要,多版本并發控制(MVCC)允許對同一數據進行并發讀寫訪問,而不必阻塞線程或進程。MVCC可以讓讀進程在寫進程訪問數據之前訪問數據的鏡像,通過這種方式,保證了讀寫進程的并行操作。
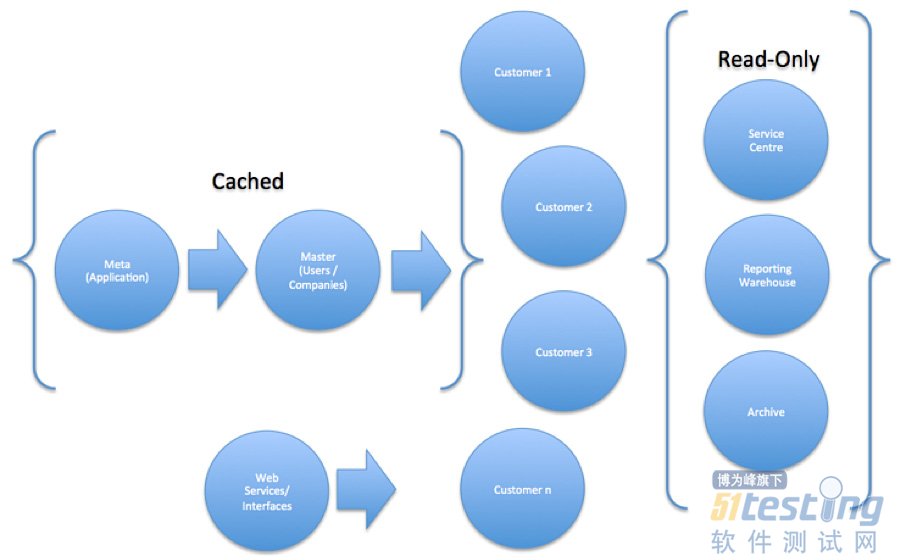
數據復制:高效的分布式技術
數據復制通過將主數據庫復制為多個只讀副本,成為了一種提高擴展性的有效途徑。這樣,遠程服務器的處理器也可以讀取和本地數據一致的副本,非常有助于降低訪問主數據庫的并發進程數目。
總結
簡而言之,一個高度擴展性的分布式數據庫架構應具備如下特性:
1、輕量級服務器的進程不應占用過多的CPU時間,而應通過我們的多個處理器并行運行多個實例。
2、客戶端應用可連接多臺服務器并從中提取數據。
3、通過數據復制技術,客戶端應用可以從主數據庫或從數據庫中檢索數據。