本文主要作為優化查詢性能的一些知識儲備,感覺知識點有些散,不知道起啥名字好,獨立成文又沒有達到把每個點都說透徹那樣的高度,且就當做創建合理索引的一個楔子把。本文對實際應用沒有太大的指導意義,但可以加深我們對SQL Server理解,夯實我們的基本功,就像小說里面的武功一樣,沒有足夠的內功基礎,給你再好的秘籍你也成不了武林高手。
序言
寫這篇文章時表示鴨梨很大,主要是對SQL Server的認識很有限,遠遠不足把這個話題說清楚,不過還是鼓起勇氣寫出來,也算作自己對索引認識的一個總結。索引這潭水太深了,應用場景不同,所建立的索引在有些情況下運行良好,有些情況下可能完全無效。而對于索引理解、認識層次不同,怎樣建才比較合理的也是眾說分云,用萬金油的說法就是沒有最合理的只有最合適的。一般來說最懂數據庫的當屬DBA,不過DBA卻不懂業務,一般除了一些核心業務模塊表建立及索引維護有DBA完成外,大多數情況下索引、SQL維護都是有開發人員完成的,因此我們通常認為的索引建立、優化都是有開發人員完成的(并不是我無視DBA,事實就是這個情況),可能有人疑惑了,DBA不維護索引、不寫SQL那他們都干嘛吃去了,這個俺還真不知道,不過DBA很忙、很累我是知道的,估計、可能、大概會做以下事情:數據庫并發、分發復制、性能監控、數據遷移、備份、日常維護、索引、SQL調優等等,DBA童鞋別噴我,我是真的不知道,DBA童鞋們可以留言告訴我下哈。
下面簡單說一些暫時想到的對使用索引影響較大的幾個注意點
頁是SQL Server存儲數據的基本單位,大小為8KB。
請一定要記住,頁是SQL Server進行數據讀寫的最小I/O單位,而不是行。SQL Server中一個頁大小為8KB,每8個頁形成一個區,每頁8KB,其中頁頭占用96個字節,頁尾的行指示器占用2個字節,還有幾個保留字節,也就是一個頁8192個字節,能用了存儲數據的實際約8000個字節,8000個字節一般可以存儲很多行數據。即便SQL Server只訪問一行數據,它也要把整個頁加載到緩存并從緩存讀取數據,我們通常所說的開銷主要就是I/O開銷,這點不少人都沒有清醒的認知。
認識窄索引
很多書籍和文章都寫過索引要使用窄索引,窄索引是個什么東東呢,大白話就是把索引建在字節長度比較小的列上,比如int占用4個字節,bigint占用8個字節,char(20)占用20個字節nchar(20)最占用40個字節,那么int 相對于bigint來說就是窄了(占用字節數更少),bigint比char(20)也要窄,char(20)和nchar(20)相比要窄(nchar(20)每個字符占用2個字節)。
明白了啥是窄索引我們來說下為什么要使用窄索引,我們知道數據存儲和讀取的最小單位是頁,一個頁8K大小,當使用比較窄的列做索引列時,每個頁能存儲的數據就更多,以int和bigint為例,一個8K的頁大約能存儲8*1024/4(int 4個字節)=2048(實際值要比這個數字小)條數據,使用bigint大約能存儲8*1024/8(bigint為8個字節)=1024(實際值要比這個數字小)條數據,也就是說索引列的長度也小,每個頁能存儲的數據也就越多,反過來說就是存儲索引所需要的頁數也就越少,頁數少了進行索引查找時需要檢索的頁自然也就少了,檢索頁數少了IO開銷也就隨之減少,查詢效率自然也就高了。
認識索引的二叉樹級數
SQL Server中所有的索引都是平衡二叉樹結構,平衡樹的意思是所有葉子節點到根節點的距離都相同,SQL Server進行索引查找時總是從索引的根節點開始,并從根跳到下一級的相應頁,并繼續從一個級別跳到下一個級別,直到達把可以查找鍵的葉子頁。所有葉級節點到底跟的距離都是相同的,這意味著一次查找操作在葉讀取上的成本正好是頁的級數。索引級數大多為2級到4級,2級索引大約包含幾千行,3級索引大約4 000 000行,4級索引能容納約4 000 000 000 行,這點上聚集索引和非聚集索引上是一樣的。一般來說對于小表來說索引通常只有2級,對于大表通常包含3級或4級。
索引級數也就意味著一次索引查找的最小開銷,比如我們建立一個User表
CREATE TABLE Users
(
UserID INT IDENTITY,
UserName nvarchar(50),
Age INT,
Gender BIT,
CreateTime DateTime
) --在UserID列上創建聚集索引 IX_UserID
CREATE UNIQUE CLUSTERED INDEX IX_UserID ON dbo.Users(UserID)
--插入示例數據
insert into Users(UserName,Age,Gender,CreateTime)
select N'Bob',20,1,'2012-5-1'
union all
select N'Jack',23,0,'2012-5-2'
union all
select N'Robert',28,1,'2012-5-3'
union all
select N'Janet',40,0,'2012-5-9'
union all
select N'Michael',22,1,'2012-5-2'
union all
select N'Laura',16,1,'2012-5-1'
union all
select N'Anne',36,1,'2012-5-7' |
我們執行查詢
| SELECT * FROM dbo.Users WHERE UserID=1 |
可以看到輸出信息為
(1 行受影響)
表 'Users'。掃描計數 0,邏輯讀取 2 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 |
當表數據量增多至幾千條時,執行上述查詢邏輯讀依然為2,當數據量到達百萬級別時邏輯讀會變成3,當到達千萬、億級別時,邏輯讀就會變成4,有興趣的童鞋可以親自去試驗下。
認識書簽查找的開銷
當使用非聚集索引時,若查詢條件沒有實現索引覆蓋就會形成書簽查找,那么一次書簽查找的開銷是多少呢?答案是不一定,一般為1到4次邏輯讀,對于堆表(無聚集索引的表)來說,一次書簽查找只需要一次邏輯讀,對于非堆表(有聚集索引的表)來說一次書簽查找的邏輯讀次數為聚集索引的級數,在索引結構我們簡單說了下大多數聚集索引的級數為2-4級,也就是說對于非堆表來說一次邏輯讀的開銷為2-4次邏輯讀,下面我們做具體測試
創建非聚集索引 IX_UserName
| CREATE INDEX IX_UserName ON dbo.Users(UserName) |
執行查詢
| SELECT UserID,UserName FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName =('Bob') |
由于我們的查詢實現了索引覆蓋,沒有書簽查找,獲取一條數據需要2次邏輯讀

(1 行受影響)
表 'Users'。掃描計數 1,邏輯讀取 2 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) |
修改查詢,返回列中增加CreateTime,這樣就無法實現索引覆蓋
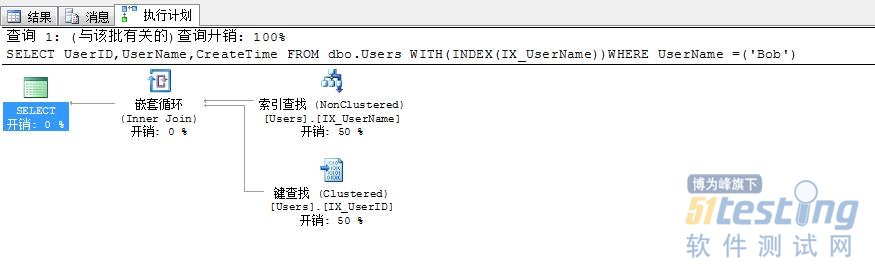
| SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName =('Bob') |
可以看到這時發生了書簽查找,同樣返回一條數據,邏輯讀達到了4次(索引查找2次,書簽查找2次),由于我們的表Users為非堆表,故一次書簽查找需要2次(聚集索引IS_UserID的級數為2)邏輯讀
(1 行受影響)
表 'Users'。掃描計數 1,邏輯讀取 4 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) |
然后我們繼續測試堆表的書簽查找開銷,刪除表Users的聚集索引IX_UserID,使其變為堆表
| DROP INDEX IX_UserID ON dbo.Users |
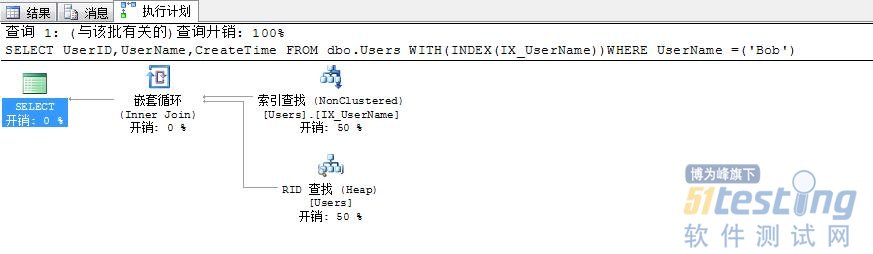
再次執行我們的查詢,可以看到邏輯讀變成了3次(索引查找2次,書簽查找1次),想想為什么堆表的書簽查找次數少呢?
| SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName =('Bob') |
(1 行受影響)
表 'Users'。掃描計數 1,邏輯讀取 3 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) |
使用索引時的隨機讀
嗯,關于隨機讀我現在也有些迷糊,只是大概的知道發生隨即讀時即便需要的數據就存在同一頁上,也會發生多次讀取,而不是一次拿到整頁數據后進行篩選。當進行where in查找或發生書簽查找時,一定會使用隨機讀
首先我們看看聚集索引的隨即讀表現
--創建聚集索引IX_UserID
CREATE UNIQUE CLUSTERED INDEX IX_UserID ON dbo.Users(UserID) |
執行如下查詢,可以發現在聚集索引上面使用where in時不管有沒有找到記錄都會進行聚集索引查找,而且查找次數固定為where in里面的條件數*索引級數,不知道為什么明明索引掃描有著更高的效率,查詢優化器還是選擇聚集索引查找,有知道的朋友還請告知下哈
--這個聚集索引掃描,返回記錄7條,邏輯讀2次
SELECT * FROM dbo.Users
--這個聚集索引查找,返回記錄3條,邏輯讀2次
SELECT * FROM dbo.Users WHERE UserID<=2
--這個聚集索引查找,返回記錄3條,邏輯讀6次
SELECT * FROM dbo.Users WHERE UserID IN(1,2)
--這個聚集索引查找,返回記錄0條,邏輯讀6次
SELECT * FROM dbo.Users WHERE UserID IN(10,20,22) |

(7 行受影響)
表 'Users'。掃描計數 1,邏輯讀取 2 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) (3 行受影響)
表 'Users'。掃描計數 1,邏輯讀取 2 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) (3 行受影響)
表 'Users'。掃描計數 3,邏輯讀取 6 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) (0 行受影響)
表 'Users'。掃描計數 3,邏輯讀取 6 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) |
我們再來看下非聚集索引的隨機讀,當然我這里為了演示特意使用了索引提示,實際應用中沒事千萬別加索引提示,當使用非聚集索引時查詢優化器發現使用索引后效率更低時會放棄索引轉為使用表掃描,我們這個例子中若去掉索引提示的話使用表掃描僅需要2次邏輯讀就可以完成查詢,這里僅僅是為了演示
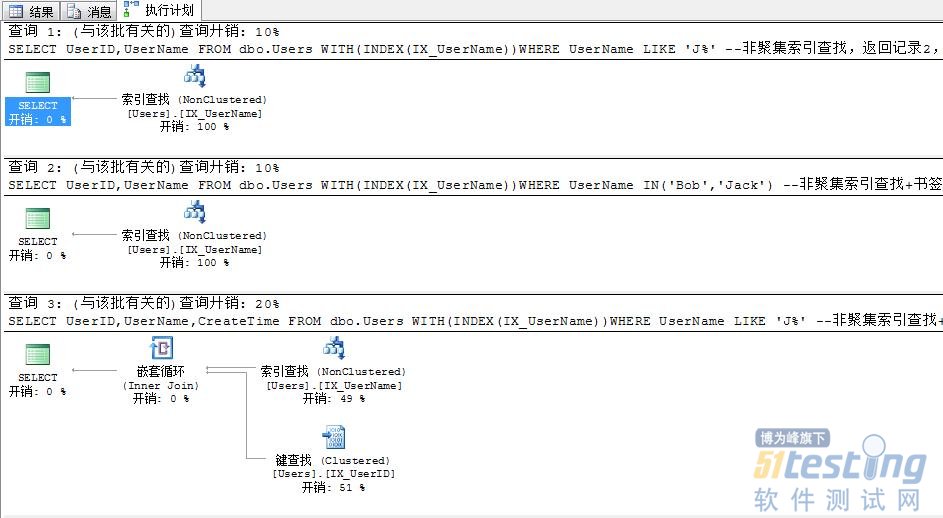
--非聚集索引查找,返回記錄2,邏輯讀2
SELECT UserID,UserName FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName LIKE 'J%'
--非聚集索引查找,返回記錄2,邏輯讀4
SELECT UserID,UserName FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName IN('Bob','Jack') --非聚集索引查找+書簽查找,返回記錄2,邏輯讀6
SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName LIKE 'J%' --非聚集索引查找+書簽查找,返回記錄0,邏輯讀2(索引查找2*1+書簽查找2*0)
SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName IN('Rabbit')
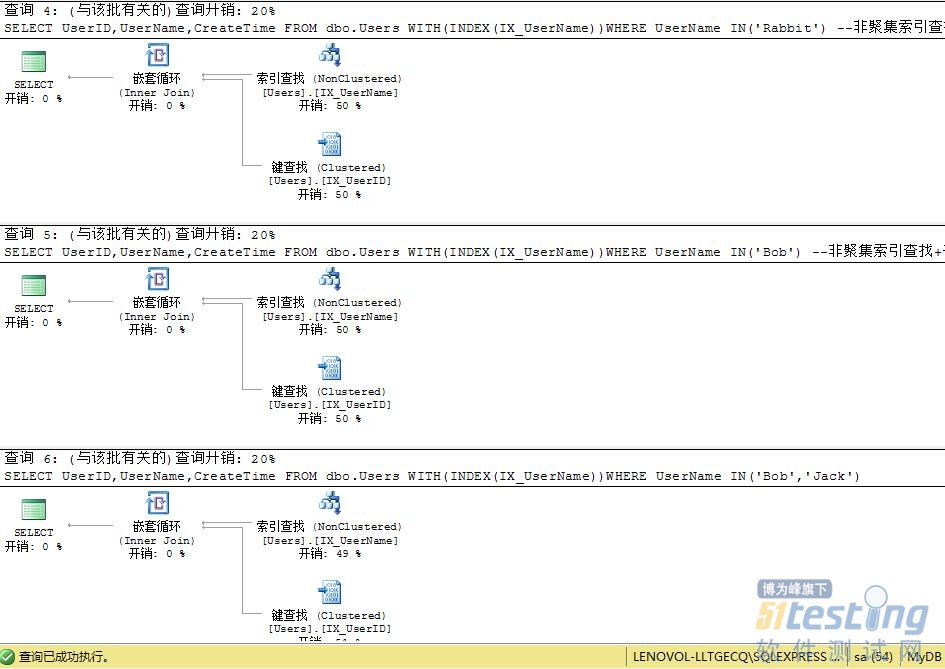
--非聚集索引查找+書簽查找,返回記錄1,邏輯讀4(索引查找2*1+書簽查找2*1)
SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName IN('Bob')
--非聚集索引查找+書簽查找,返回記錄2,邏輯讀8(索引查找2*2+書簽查找2*2)
SELECT UserID,UserName,CreateTime FROM dbo.Users WITH(INDEX(IX_UserName))WHERE UserName IN('Bob','Jack') |
(2 行受影響)
表 'Users'。掃描計數 1,邏輯讀取 2 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) (2 行受影響)
表 'Users'。掃描計數 2,邏輯讀取 4 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) (2 行受影響)
表 'Users'。掃描計數 1,邏輯讀取 6 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) (0 行受影響)
表 'Worktable'。掃描計數 0,邏輯讀取 0 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
表 'Users'。掃描計數 1,邏輯讀取 2 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) (1 行受影響)
表 'Users'。掃描計數 1,邏輯讀取 4 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) (2 行受影響)
表 'Users'。掃描計數 2,邏輯讀取 8 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。 (1 行受影響) |
總結:
認識書索引的查找開銷、書簽查找的開銷、隨機讀的影響對我們具體創建索引和編寫SQL有著積極的影響,畢竟對查詢的的認識更加清楚了,我們在寫索引和SQL時候才有更有針對性,最起碼我們又知道了一個盡量不適用where in的理由,為什么要盡量規避書簽查找,聚集索引查找不見得就一定高效,順便留個問題:聚集索引掃描和非聚集索引掃描哪個有著更高的效率,什么情況下會發生非聚集索引掃描?
嗯,暫且寫到這里,還是腦子里的墨水太少了,寫點東西就感覺腦子里空蕩蕩的......
原文出自:http://www.cnblogs.com/lzrabbit/archive/2012/06/11/2517963.html