我們一般關(guān)注邏輯讀的次數(shù),當(dāng)多個(gè)表聯(lián)合查詢時(shí),這里會(huì)現(xiàn)時(shí)每一個(gè)表的IO信息,當(dāng)某個(gè)表的邏輯讀的次數(shù)很大時(shí),你就要重點(diǎn)關(guān)注和分析這個(gè)表了,是不是查詢時(shí)涉及到這個(gè)表中的記錄條數(shù)過多,是不是沒有合理使用到Index,是不是可以增加其它的過濾條件來減少相關(guān)的記錄集合等等。下面是簡(jiǎn)單說明:
| 輸出項(xiàng) | 含義 |
| Table | 表的名稱。 |
| Scan count | 執(zhí)行的索引或表掃描數(shù)。 |
| logical reads | 從數(shù)據(jù)緩存讀取的頁數(shù)。 |
| physical reads | 從磁盤讀取的頁數(shù)。 |
| read-ahead reads | 為進(jìn)行查詢而放入緩存的頁數(shù)。 |
| lob logical reads | 從數(shù)據(jù)緩存讀取的 text、ntext、image 或大值類型 (varchar(max)、nvarchar(max)、varbinary(max)) 頁的數(shù)目。 |
| lob physical reads | 從磁盤讀取的 text、ntext、image 或大值類型頁的數(shù)目。 |
| lob read-ahead reads | 為進(jìn)行查詢而放入緩存的 text、ntext、image 或大值類型頁的數(shù)目。 |
磁盤IO相關(guān)信息先介紹到這里,另外一個(gè)參考數(shù)據(jù)是使用 set statistics time on 參考顯示分析、編譯和執(zhí)行語句所需的毫秒數(shù)。具體的使用方法同set statistics io on 基本相同,只不過顯示的是本次查詢所使用的分析編譯、執(zhí)行等的時(shí)間信息。聰明的你一定一看就明白了。在此不再贅述。
1、使用 set statistics profile on 參考顯示當(dāng)前語句執(zhí)行的配置文件信息,執(zhí)行步驟等信息,使用方法同上。
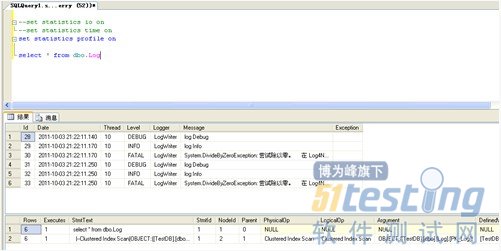
執(zhí)行查詢后,除了顯示所執(zhí)行的結(jié)果集合外,還另外顯示本次sql語句執(zhí)行的相關(guān)配置信息,采用記錄樹的形式顯示,對(duì)應(yīng)執(zhí)行計(jì)劃中的各個(gè)步驟,比如某個(gè)步驟使用的索引類型,評(píng)估行數(shù),IO信息,時(shí)間信息等。這些信息都可以用來參考,以確定該段sql語句的問題在哪里。
參考當(dāng)前語句的估計(jì)的執(zhí)行計(jì)劃或?qū)嶋H的執(zhí)行計(jì)劃,分析當(dāng)前語句執(zhí)行時(shí)SQL Server 查詢優(yōu)化器所選擇的數(shù)據(jù)檢索方法。
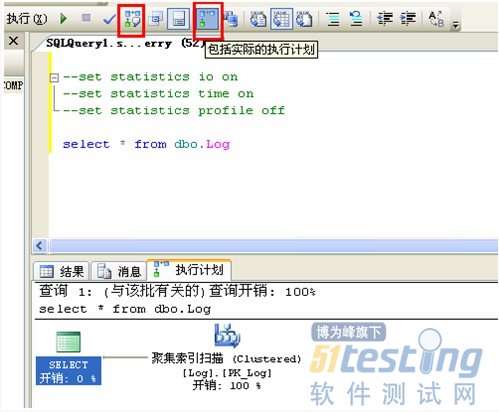
實(shí)際的執(zhí)行計(jì)劃顯示了本次執(zhí)行所使用的執(zhí)行計(jì)劃。該圖應(yīng)該從右向左看,由下向上看,如果是多個(gè)表連接查詢的話,這里也會(huì)顯示多個(gè)執(zhí)行步驟,你可以檢查每一個(gè)步驟相關(guān)的操作相關(guān)信息,如IO開銷,CPU開銷,估計(jì)的行數(shù),有沒有使用到Index,以及使用的何種Index等信息。行數(shù)過多則需要留意了。所使用的Indexl類型也是需要關(guān)注的信息之一。
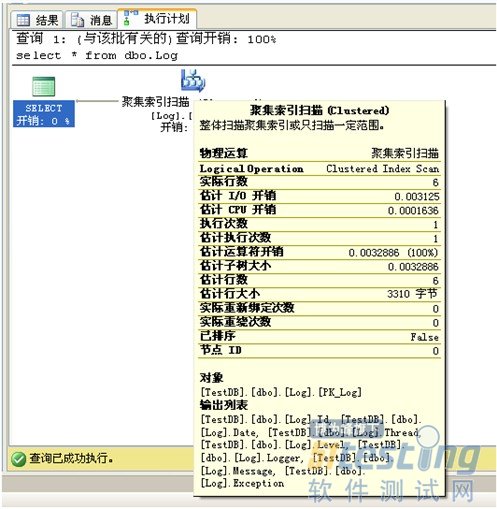
下面是執(zhí)行計(jì)劃中一些概念的簡(jiǎn)單說明:
| 工具提示項(xiàng) | 說明 |
Physical Operation | 使用的物理運(yùn)算符,例如 Hash Join 或 Nested Loops。以紅色顯示的物理運(yùn)算符表示查詢優(yōu)化器已發(fā)出警告,例如丟失列統(tǒng)計(jì)信息或丟失聯(lián)接謂詞。這可能導(dǎo)致查詢優(yōu)化器選擇比預(yù)期的效率低的查詢計(jì)劃。有關(guān)列統(tǒng)計(jì)信息的詳細(xì)信息,請(qǐng)參閱使用統(tǒng)計(jì)信息提高查詢性能。 當(dāng)圖形執(zhí)行計(jì)劃建議創(chuàng)建統(tǒng)計(jì)信息、更新統(tǒng)計(jì)信息或創(chuàng)建索引時(shí),使用 SQL Server Management Studio 對(duì)象資源管理器中的快捷菜單可以立即創(chuàng)建或更新丟失的列統(tǒng)計(jì)信息和索引。有關(guān)詳細(xì)信息,請(qǐng)參閱索引操作指南主題。 |
Logical Operation | 與物理運(yùn)算符匹配的邏輯運(yùn)算符,如 Inner Join 運(yùn)算符。邏輯運(yùn)算符列在物理運(yùn)算符之后,兩者均位于工具提示的頂部。 |
Estimated Row Size | 操作符生成的行的估計(jì)大小(字節(jié))。 |
Estimated I/O Cost | 用于執(zhí)行操作的所有 I/O 活動(dòng)的估計(jì)開銷。此值應(yīng)盡可能低。 |
Estimated CPU Cost | 用于執(zhí)行操作的所有 CPU 活動(dòng)的估計(jì)開銷。 |
Estimated Operator Cost | 用于執(zhí)行此操作的查詢優(yōu)化器的開銷。此操作的開銷以占查詢總開銷的百分比的形式顯示在括號(hào)中。由于查詢引擎選擇最高效的操作來執(zhí)行查詢或執(zhí)行語句,因此此值應(yīng)盡可能低。 |
Estimated Subtree Cost | 查詢優(yōu)化器執(zhí)行此操作及同一子樹內(nèi)位于此操作之前的所有操作的總開銷。 |
Estimated Number of Rows | 運(yùn)算符生成的行數(shù)。 |
綜合以上介紹的幾種參考信息的方法,一般都可以確定問題sql的問題所在,然后對(duì)癥下藥,剩下的就是進(jìn)行針對(duì)性的修改了,這里只是拋磚引玉,聰明的你一定會(huì)有方法解決的。