【IT168 技術文檔】作為一名開發人員,大多情況下都會認真的做好功能測試,但是卻常常忽略了軟件開發之后的壓力測試,尤其是在面向大量用戶同時使用的Web應用系統的開發過程,壓力測試往往是不夠充分的。近期我在一個求職招聘型的網站項目中就對壓力測試的重要性體會頗深。
在項目中,我負責開發職位信息的搜索部分,但是由于缺乏壓力測試,倉促將搜素部分的功能提交到生產環境,結果當并發量稍稍到達一定程度時,數據庫系統便已經不堪重負。無奈之下向網上資源查詢解決方法,其中一個就是對現有的應用做足夠到位的壓力測試。
壓力測試有著很豐富的內容,而這里,我只針對應用中所遇到的問題以及解決方法做一個簡單的描述,希望對以后遇到同樣問題的朋友能夠起到些許幫助作用。
我自己做的例子使用的環境是:
測試工具:JMeter 2.3.1
數據庫:Oracle 10G
其他環境:JDK 1.6.0_05(也可以使用JDK1.4及以上版本)
1.創建好的JMeter測試計劃樹形結構圖如下:
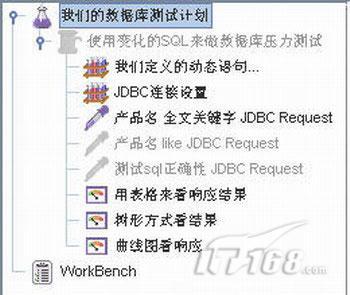
2.在剛打開JMeter的時候,默認會存在兩個節點,一個是“Test Plan”,點擊這個節點,在右邊的屬性頁面中,命名為“我們的數據庫測試計劃”
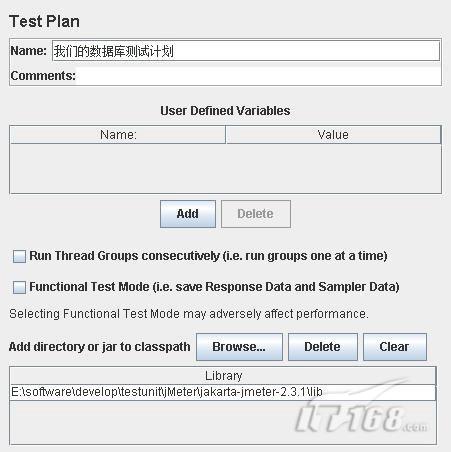
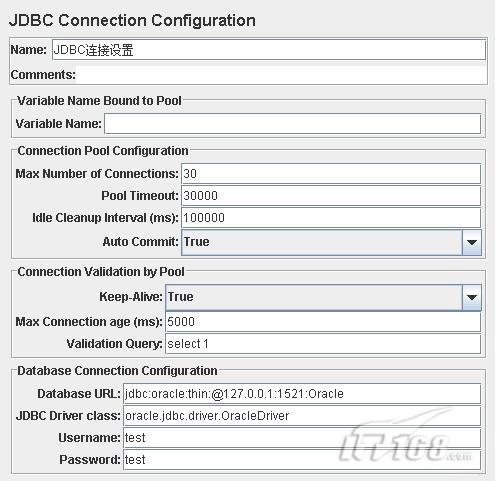
在屬性頁的最下面,我們看到設置jar包所在路徑的選項,默認存在一個選項"E:\software\develop\testunit\jMeter \jakarta-jmeter-2.3.1\lib",這個是我的機器中JMeter的lib目錄,在這個例子中,Oracle的jdbc驅動也已經拷貝到該目錄下。
內容導航 3.新增一個“Thread Group”,重命名為“使用變化的SQL來做數據庫壓力測試”。其中,“Number of Threads”表示的是JMeter會同時創建多少個線程來進行壓力測試,對于一個網站而言,也就是模擬一次存在多少個用戶來訪問該網站;而“Ramp-Up Period(in seconds)”表示JMeter每個多少秒發動并發;“Loop Count”則是指配置好的并發情形發生多少次。
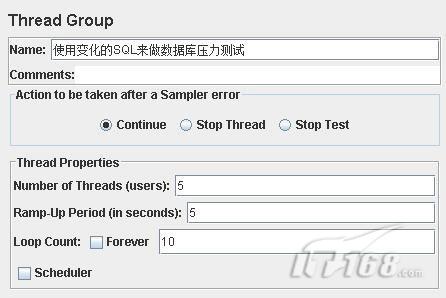
4.在“Thead Group”下創建一個“User Defined Variables”,即用戶自定義變量,重命名為“我們定義的動態語句部分”,這里我們使用它來生成動態SQL語句,讓用戶每次訪問數據庫的SQL語句都不一樣,這樣減少Oracle數據庫對相同SQL語句的緩存對測試結果所帶來的影響。
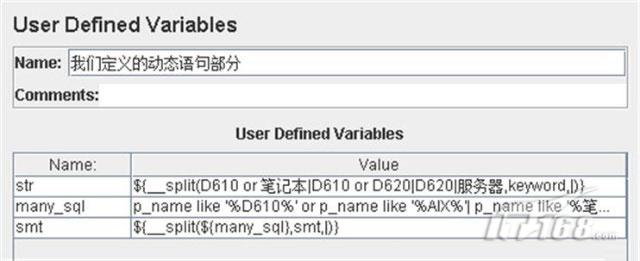
變量定義的完整內容如下:

注:${__split(...)} 是JMeter中自帶的拆分字符串為數組的函數,可以通過JMeter工具欄"Options"->"Function Helper Dialog"來打開函數代碼輔助工具生成我們所需的函數調用。
另外有個需要注意的問題是:在${__split(...)} 中,如果拆分字符串中的內容包含有符號",",一定得用符號"\"進行轉義,否則可能被JMeter誤認為是參數分隔符,會導致無法正確生成字符串數組。
內容導航 5.接下來是配置JDBC連接設置
6.創建一個具體的JDBC請求
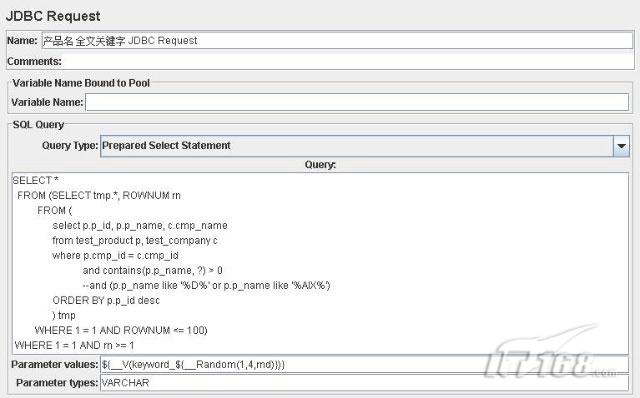
"Query Type"中選擇的是預編譯語句;
SQL語句當中,動態內容的代碼行是"and contains(p.p_name,?) > 0",這里的"?"就是預編譯語句中的動態參數,在屬性頁下面的"Parameter Values"和"Parameter types"來指定,由于預編譯語句在Java教程已有很多講解,這里不再贅述。
注:這里有一個JMeter的函數"__V..."沒有提到,將在后面說明另外一個JDBC調用測試的時候進行補充。
內容導航 7.創建三個監聽器,可以從三個不同的層面來觀察響應結果

執行一下測試計劃,我們來看看三個監聽器所返回的結果是怎樣的。
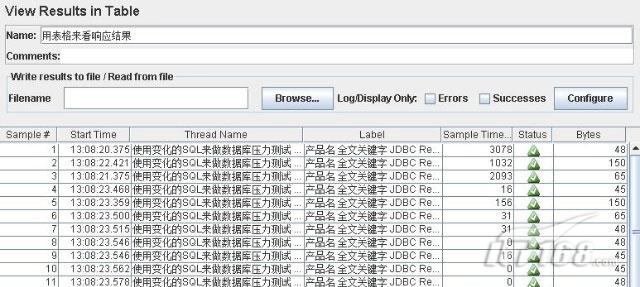
以上是表格方式查看響應結果的情況,可以看到通過表格可以查看某個范圍內的響應時間和響應狀態是否正常;
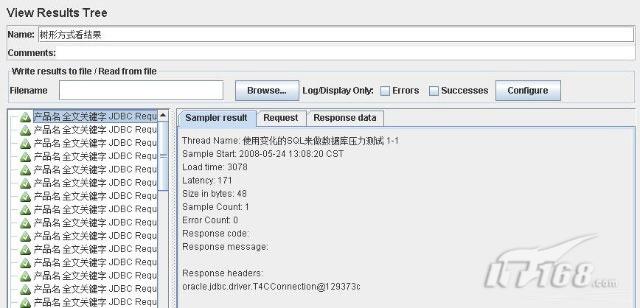
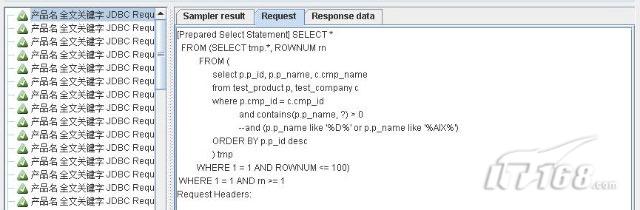

以上三幅截圖則是來自樹形監聽器,樹形監聽器在幾種監聽器中應該是最細致的,可以查看響應狀態、時間、以及執行的SQL語句,乃至返回的結果均能進行驗證。
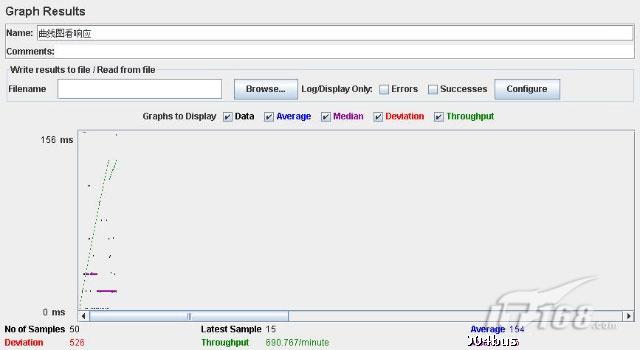
至于上面的圖形監聽器,可以宏觀的觀察SQL語句在壓力測試下響應的平滑度,并且有一定的統計信息,能夠觀察平均響應時間等。
現在我們來看另外一種方式編寫我們的JDBC調用。就是使用JMeter提供的函數動態生成我們所需要不斷變化的SQL語句部分。之所以需要這么做是為了方便我們觀察執行的SQL語句內容。
在前面使用預編譯的方式,傳遞動態參數的SQL語句執行的結果,大家已經看到過,在樹形監聽器中,我們觀察到到執行過的SQL語句是:
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/SELECT *
FROM (SELECT tmp.*, ROWNUM rn
FROM (
select p.p_id, p.p_name, c.cmp_name
from test_product p, test_company c
where p.cmp_id = c.cmp_id
and contains(p.p_name, ?) > 0
--and (p.p_name like '%D%' or p.p_name like '%AIX%')
ORDER BY p.p_id desc
) tmp
WHERE 1 = 1 AND ROWNUM <= 100)
WHERE 1 = 1 AND rn >= 1 這樣導致我們無法看出參數"?"當中表示的具體值是什么,這對我們在某些情況下確定SQL語句的性能是相當不利的。所以我們這里需要使用JMeter的動態函數特性。
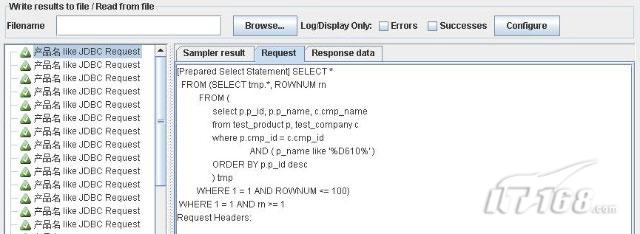
我們創建第二個"JDBC Request"節點,而后禁用"產品名 全文關鍵字 JDBC Request",將新創建的"JDBC Request"重命名為"產品名 like JDBC Request",將其中的SQL語句改寫為:
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/ SELECT *
FROM (SELECT tmp.*, ROWNUM rn
FROM (
select p.p_id, p.p_name, c.cmp_name
from test_product p, test_company c
where p.cmp_id = c.cmp_id
AND ( ${__V(smt_${__Random(1,4,rnd)})} )
ORDER BY p.p_id desc
) tmp
WHERE 1 = 1 AND ROWNUM <= 100)
WHERE 1 = 1 AND rn >= 1 這里核心的部分就是代碼行"AND ${__V(smt_${__Random(1,4,rnd)})} "。"${__Random(1,4,rnd)}"用來生成隨機數,取值范圍在1到4之間,而"__V(...)"函數幫助我們轉義"smt_${__Random(1,4,rnd)}"生成的內容,很類似于JavaScript中的"eval"函數。
例如"${__Random(1,4,rnd)}"生成隨機數為1,則"smt_${__Random(1,4,rnd)}"對應的內容為"smt_1","__V"將獲取數組變量"smt"中的第一個元素,于是生成的SQL語句如下:
這里我們可以清楚的看到所執行的SQL語句。
后記
本例中我們使用了JMeter附帶的函數"__split"和"__V","__Random"等等,文章對于這些函數的描述可能不夠完整,亦可能不夠準確,更多詳盡的解釋,大家可以參考JMeter官方文檔。