大多數數據庫都自帶了同步方案,但通常是同步到同一類型的數據庫。在一些特定的情況下�,我們可能希望把數據從一種數據庫�����,同步到另一種數據庫����,以便進行數據分析、統計、挖掘等�����,或是完成實時監控����、實時搜索等服務。
本文介紹的就是這樣一個方案����,把數據從NoSQL數據庫ttserver同步到MySQL上�。
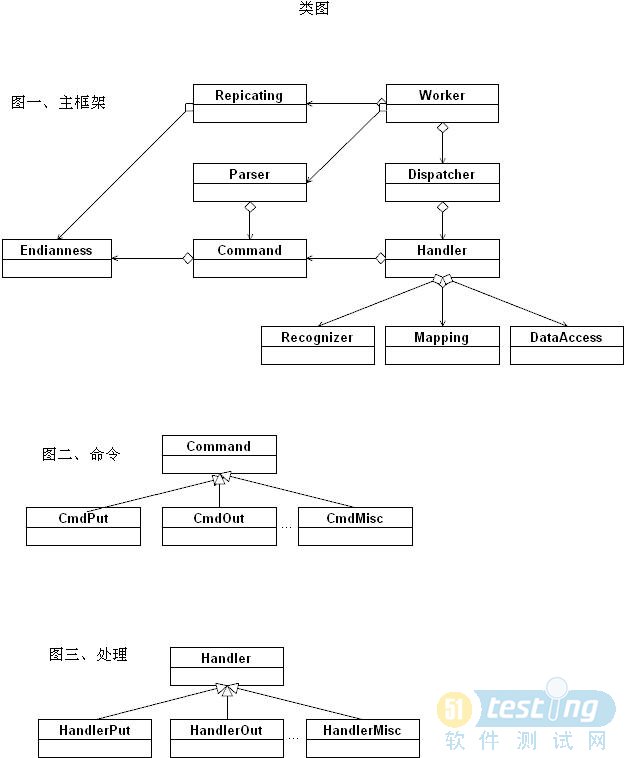
數據的同步過程基本上可以分解成:獲取����、解析�����、識別��、處理。
獲取同步(replicating)過程基本上就是處理高性能網絡交互�、各層通信協議�、基于安全考慮的身份驗證等問題的過程�����。解析(parsing)過程主要處理具體數據結構��,由分派器(dispatcher)分派給具體的識別器(recognizer)進行識別。最終由處理器調用數據訪問層完成整個過程���。基本過程可見下方草圖:

以上只是一個簡化的草圖�����,實際完成的時候��,還有很多細節需要處理�����,如�,
1)快照點的選擇�����,以及生成快照點的方案。不穩定的數據是沒用的�����;
2)協議���、數據結構的可配置化��。不同的場景下只需要簡單配置���,就能滿足具體業務����;
3)對前后端數據服務的抽象�����。只有抽象化���,才能讓它成為一個有生命力的方案��;
4)高處理能力。異步����、非阻塞�����、多worker、操作合并�����;
5)考慮對協議升級的兼容方案�����;
6)可支持前后端數據遷移、數據分片;
7)前后端多實例同時使用;
8)全局同步與增量同步方案同時支持��,新同步點支持�;
9)各種可能的出錯:網絡、數據、服務等處理��、監控��、告警���;
10)穩定性�����、可用性;
11)完備的統計數據��。方案做得怎么樣�,總要有數據才好說話吧:)
順帶把部分初期概念設計圖放出來。后來已經有一些演變�,但只是少數環節上����。在大部分的環節上��,基本思路沒有太大的變化���。
經過一段時間的奮戰把方案實現出來�����,功能驗證也比較順利通過了,實戰又將跑得怎么樣?具體業務及性能數字未經同意不準備在此公布�,但可說側面說一下�。目前�,該方案上線應該已經將近一年,除了少數幾次前端遷移以外,未停過服��。性能方面�����,一年后�,在業務已經有量級發展的情況下�����,該方案仍能滿足需求�。
另外�,雖然命名為tt2mysql,我從未把該方案當成是數據庫之前的同步方案����。以前說過會把東西總結出來����,一直太懶����,翻到了就寫一下。