有機(jī)會(huì)做了一次
性能測試工作,主要是預(yù)研性質(zhì)的工作。開發(fā)人員有必要再提交給測試做性能測試之前,做一次比較粗糙的性能測試工作。
1)走通性能測試流程,從造數(shù)據(jù)到測試,可以走通,方可交由測試同學(xué)。畢竟開發(fā)(相對性能測試人員而非功能測試)對業(yè)務(wù)邏輯更了解一些。
2)測試一些顯而易見的bug;
3)建立性能方面的信心;
4)可在測試的同學(xué)做完測試以后做一個(gè)對比,不至于偏離太過離譜。
參照測試部門的意見,我把這次的性能測試總結(jié)了如下幾個(gè)步驟:
1、測試目標(biāo)和范圍:根據(jù)需要滿足的非功能需求,確定上線功能點(diǎn)哪些需要測試。測試性能、穩(wěn)定性、最大壓力。
2、測試方案準(zhǔn)備:包括施壓方式,環(huán)境配置,環(huán)境依賴,資源監(jiān)控,整理方案文檔。
3、環(huán)境準(zhǔn)備:準(zhǔn)備壓力測試環(huán)境,一般是壓力測試機(jī)配置,壓力測試數(shù)據(jù)庫配置。
4、數(shù)據(jù)準(zhǔn)備:根據(jù)線上預(yù)估數(shù)據(jù),對數(shù)據(jù)庫數(shù)據(jù)進(jìn)行準(zhǔn)備和模擬。
5、測試準(zhǔn)備:包括需要編寫的程序,如其他系統(tǒng)間依賴可寫mock程序。另外編寫jmeter的測試計(jì)劃等。嘗試測試,并確保一個(gè)請求或處理過程能順利通過。
6、進(jìn)行測試:通過客戶端施壓服務(wù)器,監(jiān)控器各方面資源利用。
7、進(jìn)行測試分析總結(jié):寫測試報(bào)告。TPS,吞吐量,CPU占比等。對異常現(xiàn)象記錄,如內(nèi)存溢出等。
8、根據(jù)測試報(bào)告對程序進(jìn)行優(yōu)化或重構(gòu)。
做技術(shù)還是有做技術(shù)的天性,我們開發(fā)最關(guān)心的也就是5-8的步驟。我們的應(yīng)用主要以hessian接口的形式向外面暴露,另外的就是任務(wù)在后臺(tái)處理接口推送過來的數(shù)據(jù)。所以,我們的測試主要集中在接口測試和任務(wù)測試。比一般網(wǎng)頁的性能測試更簡單一些。
我們選用的施壓客戶端是開源的jmeter,文檔較為豐富,且操作極為方便,擴(kuò)展性好。服務(wù)器端性能監(jiān)控工具,均采用linux的shell命令和jvm自帶的工具或命令。jvm的工具已經(jīng)夠強(qiáng)大了,測試團(tuán)隊(duì)也是利用linux的命令采集服務(wù)器端資源,然后把消息發(fā)送到自己編寫的一些資源監(jiān)控工具上,其實(shí)都是利用了原生的shell命令和jvm命令來周期性采集并繪圖的。
JMeter沒有現(xiàn)成的sampler施壓hessian的接口,所以我們需要利用它極具擴(kuò)展性的java請 求sampler來施壓hessian接口。我們查看jmeter安裝目錄下的lib>ext下可以發(fā)現(xiàn)其他多種類型的sampler。其他的種類 都可以由javasampler來實(shí)現(xiàn)。我們只需要繼承org.apache.jmeter.protocol.java.sampler. AbstractJavaSamplerClient該類,在runTest方法中調(diào)用hessian接口,并封裝返回值即可。然后把工程打成jar包, 放到j(luò)meter安裝目錄下的lib>ext下。啟動(dòng)jemter,在利用javasampler就可以定為到我們編寫的擴(kuò)展測試程序了。
在壓力測試過程中,包括兩部分的資源檢測,jvm的資源占用。一般利用jdk自帶工具集
1、jps
常用的幾個(gè)參數(shù):
-l輸出java應(yīng)用程序的mainclass的完整包
-q僅顯示pid,不顯示其它任何相關(guān)信息
-m輸出傳遞給main方法的參數(shù)
-v輸出傳遞給JVM的參數(shù)。在診斷JVM相關(guān)問題的時(shí)候,這個(gè)參數(shù)可以查看JVM相關(guān)參數(shù)的設(shè)置
2、jstat-JavaVirtualMachineStatisticsMonitoringTool
jstat[Options]vmid[interval][count]
Options--選項(xiàng),我們一般使用-gcutil查看gc情況還有其他選項(xiàng)如:
-class-compiler-gc-gccapacity-gccause-gcnew-gcnewcapacity-gcold-gcoldcapacity-gcpermcapacity-gcutil-printcompilation
vmid--VM的進(jìn)程號(hào),即當(dāng)前運(yùn)行的java進(jìn)程號(hào)
interval--間隔時(shí)間,單位為毫秒
count--打印次數(shù),如果缺省則打印無數(shù)次
-----------------------------------------------jstat-gcutil[pid]輸出解釋
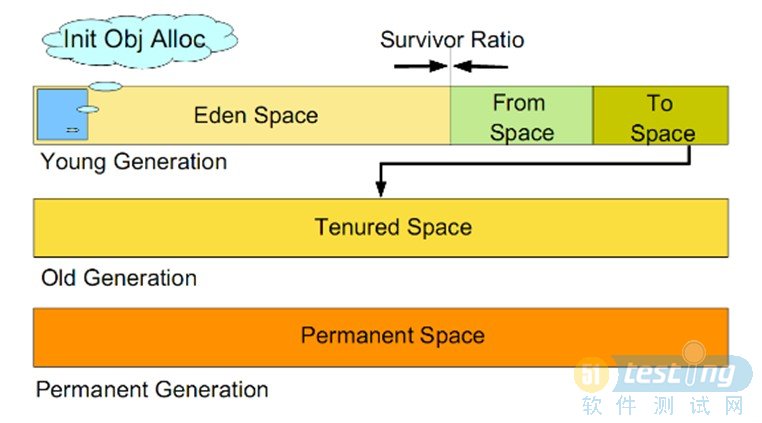
S0--Heap上的Survivorspace0區(qū)已使用空間的百分比
S1--Heap上的Survivorspace1區(qū)已使用空間的百分比
E--Heap上的Edenspace區(qū)已使用空間的百分比
O--Heap上的Oldspace區(qū)已使用空間的百分比
P--Permspace區(qū)已使用空間的百分比
YGC--從應(yīng)用程序啟動(dòng)到采樣時(shí)發(fā)生YoungGC的次數(shù)
YGCT--從應(yīng)用程序啟動(dòng)到采樣時(shí)YoungGC所用的時(shí)間(單位秒)
FGC--從應(yīng)用程序啟動(dòng)到采樣時(shí)發(fā)生FullGC的次數(shù)
FGCT--從應(yīng)用程序啟動(dòng)到采樣時(shí)FullGC所用的時(shí)間(單位秒)
GCT--從應(yīng)用程序啟動(dòng)到采樣時(shí)用于垃圾回收的總時(shí)間(單位秒)
3、jhat-JavaHeapAnalysisTool用于內(nèi)存快照文件的分析,當(dāng)然還有很多類似工具
4、jstatd-VirtualMachinejstatDaemon
5、jinfo-ConfigurationInfo
6、jvisualvm-JavaVirtualMachineMonitoring,Troubleshooting,andProfilingTool
7、jconsole-JavaMonitoringandManagementConsole
8、jmap-MemoryMapjvm內(nèi)存分析工具,得到最普遍的使用。
jmap-histo<pid>b。log輸出內(nèi)存類占用,對比各時(shí)段的內(nèi)存類,可方便知道回收情況和占用情況。
jmap-dump:format=b,file=heap。dump<pid>輸出內(nèi)存快照,可用許多開源工具分析內(nèi)存快照。
jprofile太耗內(nèi)存,如果靜態(tài)分析能得出結(jié)論的可避免使用
9、jstack-StackTrace打印線程的堆棧跟蹤信息
10、btrace-sun提供的檢測工具,很好很強(qiáng)大,用于檢測函數(shù)耗時(shí)等,微浸入。
而服務(wù)器端的資源監(jiān)控多用Linux的shell命令如:top,free,vmstat,iostat,uptime等,詳細(xì)用法不累述。
本次測試過程中遇到的幾個(gè)誤區(qū)和犯的錯(cuò)誤:
1、jmeter關(guān)于線程組的線程數(shù)和ramp-up值的設(shè)置,如果設(shè)置ramp-up為1秒,線程數(shù)為10,我錯(cuò)誤的理解為這就是一秒內(nèi)的請求量。其實(shí)是jmeter一秒內(nèi)啟動(dòng)了10個(gè)線程,這10個(gè)線程分別發(fā)送請求,知道服務(wù)器端返回后,再次發(fā)送。
這個(gè)錯(cuò)誤的理解直接導(dǎo)致我們的一個(gè)異步接口(接口把數(shù)據(jù)保存在一個(gè)無上限queue中,另外起線程來消費(fèi))在壓力測試過程中,被壓垮,以為是內(nèi)存泄露問題,其實(shí)只是我們的服務(wù)器沒能力處理這樣一個(gè)數(shù)據(jù)量。
2、在一個(gè)日志處理模塊中的生產(chǎn)和消費(fèi)者模型中,產(chǎn)生的線程過多。后經(jīng)過配置修改了消費(fèi)者和生產(chǎn)者的比例。但是在定位問題時(shí),產(chǎn)生很多困難,因?yàn)椴恢朗鞘裁淳€程出現(xiàn)這么多。程序中所有的線程必須命名才方便工具的觀察,需要開發(fā)中規(guī)范和定義好。
3、對于任務(wù)類型的性能測試沒有返回值,我們怎么觀察任務(wù)處理一條記錄的時(shí)間,或單位時(shí)間內(nèi)處理記錄的條數(shù)呢?開發(fā) 人員習(xí)慣在源代碼中去修改,并做trace,更好的方法是采用btrace工具來跟蹤方法的進(jìn)出。它在監(jiān)控方法的耗時(shí),查看某些方法的參數(shù)值,監(jiān)控內(nèi)存使 用情況等一系列場合中使用。
4、開發(fā)錯(cuò)誤的理解org。springframework。scheduling。concurrent。 ThreadPoolTaskExecutor類的corePoolSize和maxPoolSize和queueCapacity三者的關(guān)系。原以為 corePoolSize是啟動(dòng)時(shí)變初始化的核心線程數(shù),如果還有任務(wù)需要執(zhí)行,那么就會(huì)新建線程到線程池中,直到達(dá)到最大maxPoolSize的大 小。然后放不下的任務(wù)才浸入queueCapacity中存儲(chǔ)。而實(shí)際情況確是:任務(wù)到達(dá)corePoolSize之后,就放入 queueCapacity的queue中了。造成我們的配置錯(cuò)誤,引起串行的任務(wù)執(zhí)行。
的確在開發(fā)功能測試中沒有發(fā)現(xiàn)的問題,通過性能測試暴露了出來。除了這些bug之外,我們還確認(rèn)了我們接口的性能,任務(wù)的性能和穩(wěn)定性。