jdom解析
JDOM是一種使用 XML 的獨(dú)特 Java 工具包,用于快速開發(fā) XML 應(yīng)用程序。它的設(shè)計(jì)包含 Java 語(yǔ)言的語(yǔ)法乃至語(yǔ)義。 JDOM是一個(gè)開源項(xiàng)目,它基于樹型結(jié)構(gòu),利用純JAVA的技術(shù)對(duì)XML文檔實(shí)現(xiàn)解析、生成、序列化以及多種操作。(http://jdom.org)
JDOM 直接為JAVA編程服務(wù)。它利用更為強(qiáng)有力的JAVA語(yǔ)言的諸多特性(方法重載、集合概念等),把SAX和DOM的功能有效地結(jié)合起來。 DOM是用Java語(yǔ)言讀、寫、操作XML的新API函數(shù)。在直接、簡(jiǎn)單和高效的前提下,這些API函數(shù)被最大限度的優(yōu)化。 在使用設(shè)計(jì)上盡可能地隱藏原來使用XML過程中的復(fù)雜性。利用JDOM處理XML文檔將是一件輕松、簡(jiǎn)單的事。 JDOM 主要用來彌補(bǔ)DOM及SAX在實(shí)際應(yīng)用當(dāng)中的不足之處。這些不足之處主要在于SAX沒有文檔修改、隨機(jī)訪問以及輸出的功能,而對(duì)于DOM來說,JAVA程序員在使用時(shí)來用起來總覺得不太方便。 DOM的缺點(diǎn)主要是由于DOM是一個(gè)接口定義語(yǔ)言(IDL),它的任務(wù)是在不同語(yǔ)言實(shí)現(xiàn)中的一個(gè)最低的通用標(biāo)準(zhǔn),并不是為JAVA特別設(shè)計(jì)的。 在 JDOM 中,XML 元素就是 Element 的實(shí)例,XML 屬性就是 Attribute 的實(shí)例,XML 文檔本身就是 Document 的實(shí)例.JDOM 是作為一種輕量級(jí) API 被制定的,最主要的是它是以 Java 為中心的。它在遵循 DOM 主要規(guī)則的基礎(chǔ)上除去了dom本身的缺點(diǎn) 。
因?yàn)?nbsp;JDOM 對(duì)象就是像 Document、Element 和 Attribute 這些類的直接實(shí)例,因此創(chuàng)建一個(gè)新 JDOM 對(duì)象就如在 Java 語(yǔ)言中使用 new 操作符一樣容易。JDOM 的使用是直截了當(dāng)?shù)摹?nbsp;JDOM 使用標(biāo)準(zhǔn)的 Java 編碼模式。只要有可能,它使用 Java new 操作符而不使用復(fù)雜的工廠模式,使對(duì)象操作即便對(duì)于初學(xué)用戶也很方便。
JDOM是由以下幾個(gè)包組成的
–org.jdom包含了所有的xml文檔要素的java類
–org.jdom.adapters包含了與dom適配的java類
–org.jdom.filter包含了xml文檔的過濾器類
–org.jdom.input包含了讀取xml文檔的類
–org.jdom.output包含了寫入xml文檔的類
–org.jdom.transform包含了將jdomxml文檔接口轉(zhuǎn)換為其他xml文檔接口
–org.jdom.xpath包含了對(duì)xml文檔xpath操作的類
org.jdom這個(gè)包里的類是你解析xml文件后所要用到的所有數(shù)據(jù)類型。 –Attribute –CDATA –Coment –DocType –Document –Element –EntityRef –Namespace –ProscessingInstruction
–Text
Jdom主要使用方法:
1.Document類
Document的操作方法:
Element root = new Element("GREETING");
Document doc = new Document(root);
root.setText("Hello JDOM!");
或者簡(jiǎn)單的使用
Document doc=new Document(new Element("GREETING").setText("Hello JDOM!t"));
2.這點(diǎn)和DOM不同。Dom則需要更為復(fù)雜的代碼,如下:
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder =factory.newDocumentBuilder();
Document doc = builder.newDocument();
Element root =doc.createElement("root");
Text text = doc.createText("This is the root");
root.appendChild(text);
doc.appendChild(root);
3.可以使用SAXBuilder的build方法來解析一個(gè)流從而得到一個(gè)Document對(duì)象
–Document build(java.io.File file)
–Document build(org.xml.sax.InputSource in)
–Document build(java.io.InputStream in)
–Document build(java.net.URL url)
4.DOM的Document和JDOM的Document之間的相互轉(zhuǎn)換使用方法
DOMBuilder builder = new DOMBuilder();
org.jdom.Document jdomDocument = builder.build(domDocument);
–DOMOutputter converter = new DOMOutputter();// work with the JDOM document…
–org.w3c.dom.Document domDocument = converter.output(jdomDocument);
–// work with the DOM document…
5.XMLOutPutter類:
JDOM的輸出非常靈活,支持很多種io格式以及風(fēng)格的輸出
Document doc = new Document(...);
XMLOutputter outp = new XMLOutputter();
outp.output(doc, fileOutputStream); // Raw output
outp.setTextTrim(true); // Compressed output
outp.output(doc, socket.getOutputStream());
outp.setIndent(" ");// Pretty output
outp.setNewlines(true);
outp.output(doc, System.out);
DOM4J解析
DOM4J 是dom4j.org 出品的一個(gè)開源XML解析包,它是一個(gè)易用的、開源的庫(kù),用于XML,XPath 和XSLT。它應(yīng)用于Java 平臺(tái),采用了Java 集合框架并完全支持DOM,SAX 和JAXP。DOM4J 使用起來非常簡(jiǎn)單。只要你了解基本的XML-DOM 模型,就能使用。
它的主要接口都在org.dom4j 這個(gè)包里定義:
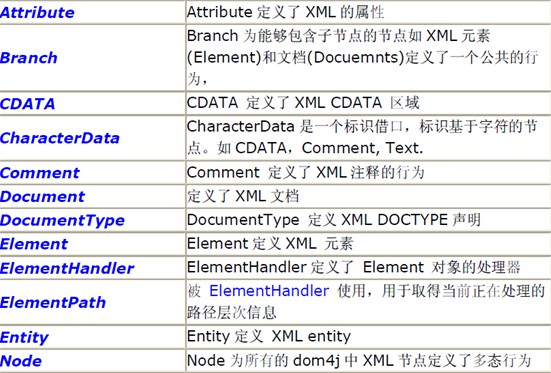
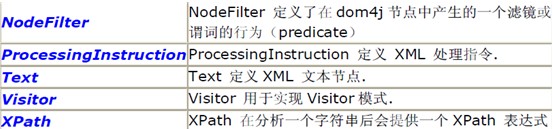
看名字大致就知道它們的涵義如何了。下面咱一一看一下:
一.Document對(duì)象,三種創(chuàng)建方法
1.讀取XML文件,獲得document對(duì)象.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
2.解析XML格式的字符串,獲得document對(duì)象.
String text = "<members></members>";
Document document = DocumentHelper.parseText(text);
3.創(chuàng)建document空對(duì)象.
Document document = DocumentHelper.createDocument();
Element root = document.addElement("members");// 創(chuàng)建根節(jié)點(diǎn),只有空DOCUMENT對(duì)象才能創(chuàng)建ROOT結(jié)點(diǎn)
二.節(jié)點(diǎn)控制
1.獲取文檔的根節(jié)點(diǎn).
Element root = document.getRootElement();
2.取得節(jié)點(diǎn)的文本
String text=memberElm.getText();
也可以用:
String text=root.elementText("name"); //這個(gè)是取得根節(jié)點(diǎn)下的name字節(jié)點(diǎn)的文字;可以類推任何節(jié)點(diǎn)下的文本
3.設(shè)置節(jié)點(diǎn)文字.
ageElm.setText("29");
4.父節(jié)點(diǎn)下獲得單個(gè)子節(jié)點(diǎn)對(duì)象.
Element memberElm=root.element("member"); // "member"是節(jié)點(diǎn)名
5.取得父節(jié)點(diǎn)下遍歷名為"member"的所有子節(jié)點(diǎn).
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
// do something
}
6.父節(jié)點(diǎn)下的遍歷所有子節(jié)點(diǎn)進(jìn)行.
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
// do something
}
7.父節(jié)點(diǎn)下添加子節(jié)點(diǎn).
Element ageElm = newMemberElm.addElement("age");
8.父節(jié)點(diǎn)下刪除子節(jié)點(diǎn).
parentElm.remove(childElm);// childElm是待刪除的節(jié)點(diǎn),parentElm是其父節(jié)點(diǎn)
三.屬性相關(guān).
1.取得某節(jié)點(diǎn)下的某屬性
Element root=document.getRootElement();
Attribute attribute=root.attribute("size");// 屬性名name
2.取得屬性的文字
String text=attribute.getText();
也可以用:
String text2=root.element("name").attributeValue("firstname");這個(gè)是取得根節(jié)點(diǎn)下name字節(jié)點(diǎn)的屬性firstname的值.
3.遍歷某節(jié)點(diǎn)的所有屬性
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
4.設(shè)置某節(jié)點(diǎn)的屬性和文字.
newMemberElm.addAttribute("name", "sitinspring");
5.設(shè)置屬性的文字
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
6.刪除某屬性
Attribute attribute=root.attribute("size");// 屬性名name
root.remove(attribute);
四.將文檔寫入XML文件.
1.文檔中全為英文,不設(shè)置編碼,直接寫入的形式.
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();
2.文檔中含有中文,設(shè)置編碼格式寫入的形式.
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("GBK"); // 指定XML編碼
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"),format);
writer.write(document);
writer.close();
五.字符串與XML的轉(zhuǎn)換
1.將字符串轉(zhuǎn)化為XML
String text = "<members> <member>sitinspring</member> </members>";
Document document = DocumentHelper.parseText(text);
2.將文檔或節(jié)點(diǎn)的XML轉(zhuǎn)化為字符串.
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();
六.使用XPath快速找到節(jié)點(diǎn).
讀取的XML文檔示例
<?xml version="1.0" encoding="UTF-8"?>
<projectDescription>
<name>MemberManagement</name>
<comment></comment>
<projects>
<project>PRJ1</project>
<project>PRJ2</project>
<project>PRJ3</project>
<project>PRJ4</project>
</projects>
<buildSpec>
<buildCommand>
<name>org.eclipse.jdt.core.javabuilder</name>
<arguments>
</arguments>
</buildCommand>
</buildSpec>
<natures>
<nature>org.eclipse.jdt.core.javanature</nature>
</natures>
</projectDescription>
使用XPath快速找到節(jié)點(diǎn)project.
public static void main(String[] args){
SAXReader reader = new SAXReader();
try{
Document doc = reader.read(new File("sample.xml"));
List projects=doc.selectNodes("/projectDescription/projects/project");
//Element nodes0=xmlDoc.selectSingleNode("/bookstore"); //采用相對(duì)路徑,即當(dāng)前結(jié)點(diǎn)(包括當(dāng)前結(jié)點(diǎn))開始查找,與下列結(jié)果相同.
//Element nodes=nodes0.selectNodes("book"); ////采用絕對(duì)路徑,即當(dāng)前結(jié)點(diǎn)(包括當(dāng)前結(jié)點(diǎn))開始查找,
//XPATH語(yǔ)法詳見: http://www.w3school.com.cn/xpath/xpath_syntax.asp
Iterator it=projects.iterator();
while(it.hasNext()){
Element elm=(Element)it.next();
System.out.println(elm.getText());
}
}
catch(Exception ex){
ex.printStackTrace();
}
}
推薦閱讀:
Java程序員從笨鳥到菜鳥之(二十八)Javascript總結(jié)之語(yǔ)言基礎(chǔ)