下午配置成功了Nutch0.9.截圖記錄一下。
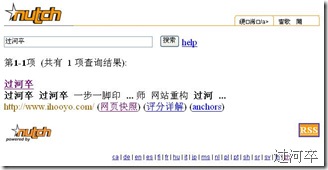
網絡上面介紹這個配置的比較多,我就不重復勞動了。
推薦文檔如下:Nutch Version 0.8x tutorial ,還有就是這里的篇日志。
我在這里記錄一下遇到的幾個錯誤和解決辦法,大家可能有用。
如執行如下命令:
./nutch crawl ../urls.txt -dir ../ihooyo -depth 5 -topN 100
參數說明:
-url 就是剛才我們創建的url文件,存放我們要抓取的網址
-dir 指定抓取內容所存放的目錄,如上存在mydir中
-threads 指定并發的線程數
-depth 表示以要抓取網站頂級網址為起點的爬行深度
-topN 表示獲取前多少條記錄,可省
可能錯誤1:
Generator: jobtracker is 'local', generating exactly one partition.
Generator: 0 records selected for fetching, exiting ...
Stopping at depth=0 - no more URLs to fetch.
No URLs to fetch - check your seed list and URL filters.
crawl finished: sina5
說明:指定要抓取的網址(url.txt)經過(crawl-urlfilters.xml)過濾后,已經沒有可抓取對象了,檢查兩者的匹配即可。
可能錯誤2:
Dedup: starting
Dedup: adding indexes in: ../ihooyo/indexes
Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:604)
at org.apache.nutch.indexer.DeleteDuplicates.dedup(DeleteDuplicates.java:439)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:135)
說明:一般為./conf/nutch-site.xml文件配置有錯誤。請參考如下配置修改。
[xml]
<property>
<name>http.agent.name</name>
<value>ihooyo</value>
<description></description>
</property>
<property>
<name>http.agent.description</name>
<value>apersonblog</value>
<description></description>
</property>
<property>
<name>http.agent.url</name>
<value>www.ihooyo.com</value>
<description></description>
</property>
<property>
<name>http.agent.email</name>
<value>pjuneye@qq.com</value>
<description></description>
</property>
[/xml]
這種配置錯誤,在log日志中可找到提示。
可能錯誤3:
Injector: Converting injected urls to crawl db entries.
Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:604)
at org.apache.nutch.crawl.Injector.inject(Injector.java:162)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:115)
說明:一般為crawl-urlfilters.txt中配置問題,比如過濾條件應為
+^http://www.ihooyo.com ,而配置成了 http://www.ihooyo.com 這樣的情況就引起如上錯誤。
好了寫完了。
平凡而簡單的人一個,無權無勢也無牽無掛。一路廝殺,只進不退,死而后已,豈不爽哉!
收起對“車”日行千里的羨慕;收起對“馬”左右逢緣的感嘆;目標記在心里面,向前進。一次一步,一步一腳印,跬步千里。
這個角色很適合現在的我。
posted on 2008-04-01 17:11
過河卒 閱讀(1609)
評論(0) 編輯 收藏 所屬分類:
Java/Java框架