想必不少人聽說過javaagent,但是很少人聽說Instrumentation,其實Instrumentation就是javaagent的實現機制,說到Instrumentation,就必須想了解java的attach機制,那就先說下attach的實現。
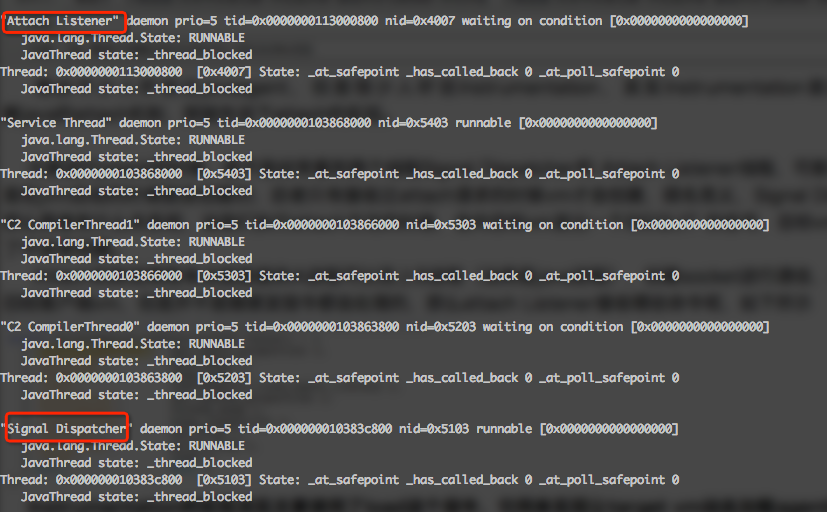
大家進行jstack的時候,是不是經常看到兩個線程Signal Dispatcher和 Attach Listener線程,可能不知道是干嘛的吧,這兩個線程是實現attach的關鍵所在,其中前者是在jvm啟動的時候就會創建的,后者只有接收過attach請求的時候vm才會創建,顧名思義,Signal Dispatcher是分發信號的, Attach Listener 是處理attach請求的,那么兩者有什么關系呢,當我們執行attach方法的時候,會向目標vm發出一個SIGQUIT 的信號,目標vm收到這個信號之后就會創建Attach Listener線程了,當然jvm保證了不會多創建。
1 path = findSocketFile(pid);
2 if (path == null) {
3 File f = new File(tmpdir, ".attach_pid" + pid);
4 createAttachFile(f.getPath());
5 try {
6 sendQuitTo(pid);
7
8 // give the target VM time to start the attach mechanism
9 int i = 0;
10 long delay = 200;
11 int retries = (int)(attachTimeout() / delay);
12 do {
13 try {
14 Thread.sleep(delay);
15 } catch (InterruptedException x) { }
16 path = findSocketFile(pid);
17 i++;
18 } while (i <= retries && path == null);
19 if (path == null) {
20 throw new AttachNotSupportedException(
21 "Unable to open socket file: target process not responding " +
22 "or HotSpot VM not loaded");
23 }
24 } finally {
25 f.delete();
26 }
27 }
Attach機制說得簡單點就是提供A進程可以連上B進程(當然是java進程),創建socket進行通信,A通過發命令給B,B然后對命令進行截取從自己的vm中獲取信息發回給客戶端vm,但是并不是隨便發指令都會處理的,那么attach Listener接收哪些命令呢,如下所示
static AttachOperationFunctionInfo funcs[] = {
{ "agentProperties", get_agent_properties },
{ "datadump", data_dump },
{ "dumpheap", dump_heap },
{ "load", JvmtiExport::load_agent_library },
{ "properties", get_system_properties },
{ "threaddump", thread_dump },
{ "inspectheap", heap_inspection },
{ "setflag", set_flag },
{ "printflag", print_flag },
{ "jcmd", jcmd },
{ NULL, NULL }
};
Instrumentation的實現其實主要使用了load這個指令,它用來實現讓target vm動態加載agentlib,Instrumentation的實現在一個名為libinstrument.dylib的動態lib庫,linux下是libinstrument.so,它是基于jvmti接口實現的,因此在對其進行load的時候會創建一個agent實例,并往jvmti環境注冊一些回調方法,比如監聽類文件加載的事件,vm初始化完成事件等,執行Agent_OnAttach,這里會創建一個Instrumentation實例并返回給用戶供大家擴展Instrumentation,比如增加一些transform。并會執行Instrumentation實例的loadClassAndCallAgentmain方法,該方法主要執行agent的MF文件里定義的 Agent-Class類的agentmain方法,當vm初始化完畢之后,會調用loadClassAndCallPremain方法,該方法主要執行agent的MF文件里定義的 Agent-Class類的pre main方法。在類進行加載的時候會調用Instrumentation的transform方法,可以看看參數里有個byte數組,這個數組其實就是正在加載的class字節碼,所以如果要字節碼增強在這里就可以入手啦,甚至可以實現偷天換日.
posted @
2013-04-12 22:38 你假笨 閱讀(2206) |
評論 (0) |
編輯 收藏
最近在忙一個項目,使用的是Flex+Spring+Hibernate,期間碰到一個問題,有必要在此記錄一下,也方便有相似問題的來者參考下
問題描述:有一個用戶表和一個用戶詳情表,這兩個表是一個一對一的單向關聯關系,即在用戶表中一個外鍵引用用戶詳情表,我在UserInfo的映射文件中使用的是many-to-one,設置了unique="true"表示一對一關系,設置了cascade="save-update"表示的是在保存useInfo對象的時候會自動保存與之關聯的userDetails臨時對象,即我希望的是先執行一個在用戶詳情表中的插入語句然后再執行一個在用戶表中的插入語句,userInfo對象是從flex端傳過來的,當然也設置了userDetails屬性的值,在userInfo的dao文件中save方法是這樣的
public IvUserInfo save(IvUserInfo transientInstance) {
log.debug("saving IvUserInfo instance");
try {
getHibernateTemplate().save(transientInstance);
log.debug("save successful");
} catch (RuntimeException re) {
log.error("save failed", re);
throw re;
}
return transientInstance;
}
后面發現執行的sql語句只有一條插入語句,就是在用戶表中的一個插入,由于外鍵的關聯作用,是用戶表的這條插入也無法執行,這就是問題所在了。
問題解決:這個問題我也沒有具體研究Hibernate的源碼,我先寫了個測試類,發現僅僅在java中執行操作的話是可以正確執行兩條插入語句的,但是通過flex傳過來就有問題了,那說明是flex端傳參數過來的問題,于是我試著修改UserInfo的save方法:
public IvUserInfo save(IvUserInfo transientInstance) {
log.debug("saving IvUserInfo instance");
try {
IvUserDetails ud=new IvUserDetails();
ud.setQq(transientInstance.getIvUserDetails().getQq());
transientInstance.setIvUserDetails(ud);
getHibernateTemplate().save(transientInstance);
log.debug("save successful");
} catch (RuntimeException re) {
log.error("save failed", re);
throw re;
}
return transientInstance;
}
這樣一來問題解決了,順利執行了兩條插入語句。
如果朋友知道具體原因的話希望給我留言了,同時也希望該記錄能幫助碰到此類問題的朋友。
posted @
2010-06-22 11:20 你假笨 閱讀(1576) |
評論 (0) |
編輯 收藏
歡迎光臨筆者博客
http://www.lovestblog.cn
最近兩天本人在為本博實現rss發布和訂閱,本來是想在前端實現xml的生成和修改,因為用as3的E4X操作xml比較方便,但是后面發現不能為元素設置CDATA值,于是只好作罷,便只能依靠后臺的java來實現此功能了,當然操作xml的話,我首先想到了dom4j,dom4j操作xml還是比較方便的,即可以輕松實現我們的CDATA設置,也可以為我們任意位置插入元素提供了實現,對于在指定位置新增節點開始我有點蒙了,后面通過網上搜索資源加之自己的一些理解,而實現了此功能,下面展示了部分代碼供今后參考吧:
-

 public static int createXMLFile(String filename,List list)
public static int createXMLFile(String filename,List list) {
{

 /** *//** 返回操作結果, 0表失敗, 1表成功 */
/** *//** 返回操作結果, 0表失敗, 1表成功 */
 int returnValue = 0;
int returnValue = 0;
Document document = DocumentHelper.createDocument();
Element rssElement = document.addElement("rss");
rssElement.addAttribute("version", "2.0");
Element channelElement = rssElement.addElement("channel");
Element titleElement = channelElement.addElement("title");
titleElement.setText("你假笨(nijiaben)心情技術博客");
Element linkElement = channelElement.addElement("link");
linkElement.setText("http://www.lovestblog.cn");
Element descriptionElement = channelElement.addElement("description");
descriptionElement.setText("專注于Java,Flex技術開發研究");
Element languageElement = channelElement.addElement("language");
languageElement.setText("zh-cn");
Element lastBuildDateElement = channelElement.addElement("lastBuildDate");
lastBuildDateElement.setText(new java.text.SimpleDateFormat("yyyy-mm-dd hh:mm:ss",Locale.CHINA).format(((ArticleInfo)(list.get(0))).getCreateTime()));
for(int i=list.size()-1;i>0;i--){
ArticleInfo ainfo=(ArticleInfo)(list.get(i));
Element itemElement = channelElement.addElement("item");
Element title1Element = itemElement.addElement("title");
title1Element.setText(ainfo.getTitle());
Element description1Element = itemElement.addElement("description");
int maxLen=5000;
if(ainfo.getRssContent().length()<5000){
maxLen=ainfo.getRssContent().length();
 }
}
description1Element.addCDATA(ainfo.getRssContent().substring(0, maxLen));
Element pubDate=itemElement.addElement("pubDate");
pubDate.setText(new java.text.SimpleDateFormat("yyyy-mm-dd hh:mm:ss",Locale.CHINA).format(ainfo.getCreateTime()));
Element link1Element=itemElement.addElement("link");
link1Element.setText("http://www.lovestblog.cn");
}
try{
/** *//** 將document中的內容寫入文件中 */
XMLWriter writer = new XMLWriter(new FileOutputStream(path+filename));
writer.write(document);
writer.close();
/** *//** 執行成功,需返回1 */
returnValue = 1;
}catch(Exception ex){
ex.printStackTrace();
}
return returnValue;
 }
}

posted @
2010-04-01 12:14 你假笨 閱讀(3093) |
評論 (1) |
編輯 收藏 本文最新發布于http://www.lovestblog.cn,歡迎轉載該文,但請注明文章出處,謝謝合作。
mysql的from從句用來指定參與查詢的表,當然也可以是生成的中間表,在表前我們有時需要指定數據庫,這主要是用在我們需要訪問當前數據庫之外的數據庫中的表的情況,在這中情況下我們采用"."操作符來進行,如userdb.user,其實userdb為數據庫名,user為表名,這是對mysql數據庫而言的,對于DB2和Oracle就不是通過指定數據庫名了,而是指定sql用戶了,這就是說不同sql用戶可以建立相同名字的表,但是同一個sql用戶只能建立唯一名字的表。這就是它們在這表規范上面的區別。對于列規范,mysql可以在需要查詢的列則可以采用如下形式進行訪問:“數據庫名.表名.列名”。對于多個表的規范,也就是涉及查詢多個表的情況下,執行的過程是采用笛卡爾積的形式進行的。也就是說生成的中間表的列數為兩個表中列數的總和,而行的總數等于一個表中的行的數量與另外一個表中行的數量的乘積。
對于from從句中使用假名的情況,比如select u.id,name,age,a.account from utb as u,atb as a where u.id=a.user_id,在我們使用假名之后,那么在該sql語句的任何地方都只能使用假名,不能使用真實的表名,同時上面的as關鍵字也是可以省略的,也就是說對于上面的語句不能用atb來取代a,utb來取代u了。雖然from從句不是我們指定的第一條語句,但是絕對是第一個被處理的語句,所以在聲明假名前使用假名不會導致錯誤。如果一條from從句引用到兩個有著相同名稱的表,則必須使用假名。如:
1select p.playerno
2from players as p,players as par
3where par.fn="jp" and par.ln="l" and p.birth_date<par.birth_date
對于多個表間的連接處理可能會導致有相同的結果,即有重復的結果,sql并不會自動從最終結果中刪除重復的行,這是如果我們不希望在結果中出現重復的行,那么我們可以在select后直接指定distinct。如:
1select distinct T.playerno
2from teams as T,penalties as pen
3where T.playerno=pen.playerno。
接下來說說連接哈,對于內連接,如果是兩個表的話,就取兩個表的一個交集,如果是左外連接的話,那就是左邊的表全取,右邊沒有的用null替代,弱國是右外連接的話,那就是右邊的表全取,左邊沒有的用null表示。下面看看一個具體的例子:
1--表stu --表exam
2id name id grade
31, Jack 1, 56
42, Tom 2, 76
53, Kity 11, 89
64, nono
內連接 (顯示兩表id匹配的)
1select stu.id,exam.id,stu.name, exam.grade from stu (inner) join exam on stu.id=exam.id
2--------------------------------
31 1 Jack 56
42 2 Tom 76
左連接(顯示join 左邊的表的所有數據,exam只有兩條記錄,所以stu.id,grade 都用NULL 顯示)
1select stu.id,exam.id,stu.name, exam.grade from stu left (outer) join exam on stu.id=exam.id
21 1 Jack 56
32 2 Tom 76
43 NULL Kity NULL
54 NULL nono NULL
右連接(與作連接相反,顯示join右邊表的所有數據)
1select stu.id,exam.id,stu.name, exam.grade from stu right join exam on stu.id=exam.id
21 1 Jack 56
32 2 Tom 76
4NULL 11 NULL 89
內連接取交集,外連接分左和右,
左連接左邊的全取,
右連接右邊的全取
對于連接的列的名稱相同的話,那么可以使用using來替代條件,如上面的內連接可以這樣改寫:
1 select stu.id,exam.id,stu.name, exam.grade from stu inner join exam using(id)。
對于左外連接使用的情況一般是當左表的連接列中存在未出現在右表的連接列中的值時,左外連接才有用。
還有個全外連接的,也就是說只要在兩個表中出現的記錄都會在中間表中出現,當右表有而左表沒有或當左表有而右表沒有的時候用null表示。具體語法如下:select stu.id,exam.id,stu.name, exam.grade from stu full join exam using(id)。
交叉連接:就是顯示求表的笛卡爾積,select * from teams cross join penalties.這句完全等價于select teams.*,penalties.* from teams,penalties.
聯合連接:select * from teams union join penalties,這個其實很容易理解,產生結果所包含的列為兩個表所有的列和,對于數據的列出,首先列出左表的數據,對于屬于右表的列,用null表示,接下來列出右表的數據,對于屬于左表的列用null表示。
自然連接:select * from teams nature inner join penalties where division='first';此句完全等同與select t.playerno,t.teamno,t.division,pen.paymentno,pen.payment_date,pen.amount from teams as t inner join penalties as pen on t.playerno=pen.playerno where dividion='first'.相比就知道,我們無須顯示指出必須要連接到哪些列,sql會自動查找兩表中是否有相同名稱的列,且假設他們必須在連接條件中使用。此處的on或using從句是多余的,因此不允許使用。
下面看個例子創建一個稱為towns的虛擬表:
1select *
2from (select 'Stratford' as town,4 as number
3 union
4 select 'Plymouth',6
5 union
6 select 'Inglewood',1
7 union
8 select 'Douglas',2) as towns
9order by town;
結果為:
1town number
2----------------------
3Douglas 2
4Inglewood 1
5Plymouth 6
6Stratford 4
posted @
2009-09-24 15:51 你假笨 閱讀(2030) |
評論 (0) |
編輯 收藏
本文最先發布于
http://www.lovestblog.cn,請轉載的該文者注明文章出處,謝謝合作。
下面簡單介紹幾種標量函數,也是常用的,我們可以通過類似select abs(-123);的語句來看到我們標量函數的效果。
abs:該函數返回一個數值表達式的絕對值。如abs(-123);
adddate:該函數將一個時間間隔(參數2)添加到時戳或時戳表達式(參數1)中,與此函數同功能的還有date_add。如adddate('2009-01-01',4);結果為2009-01-05。adddate(2009-01-01,interval 5 month);結果為2009-06-01。adddate(timestamp('2009-01-01'),interval 5 month);結果為2009-06-01 00:00:00。adddate('2009-01-01 12:00:00',interval 5 day);結果為2009-01-06 12:00:00。
addtime:把兩個時間表達式加起來。如addtime('100:00:00','200:02:04');結果為300:02:04。
ascii:該函數返回一個字符串表達式的第一個字符的ASCII值。
bin:該函數將參數的數值轉換為二進制值。
bit_count:該函數顯示表示參數的值的位數。如bit_count(3)結果為2。
bit_length:該函數返回字符串值的位長度。如bit_length(bin(2));結果為16
ceiling:該函數返回大于或等于參數值的最大整數。如ceiling(11.11);->12。ceicling(-11.11);->-11
char:該函數返回數值參數的字符串字符,與此函數同功能的還有chr函數。如char(82)+char(105)+char(99)+char(107);->'Rich'
character_length:該函數返回一個字符串表達式的長度,此方法同功能的還有char_length函數。
charset:該函數返回字符串參數的字符集的名稱。
coalesce:該函數接受多個參數,返回第一個非null值的參數的值。如coalesce(null,null,'ljp');->'ljp';
concat:該函數合并兩個字符串的值。
conv:該函數將一基數為參數2的值(參數1)轉換為另一個以參數3為基數的值。如conv(1110,10,16)表示將以10進制的數1110轉換成16進制值為456。后面兩個參數必須介于2~36之間,否則結果為null,此外參數1的值應該匹配參數2的基數,否則結果為0。
convert:該函數轉換參數1的數據類型為參數2指定的類型。參數2必須是一種數據類型,包括binary,char,date,datetime,time,signed,signed integer,unsigned,unsigned integer,varchar。如convert('12.56',unsigned integer);->13。
database:該函數顯示當前數據庫的名稱。
date:該函數將參數變換為一個日期值。如date('2009-01-01 12:00:00');->'2009-01-01'。
datediff:該函數計算兩個日期或時間戳表達式間的天數。第一個參數減去第二個參數。
date_sub:該函數從一個日期或時間戳表達式(參數一)中減去一個時間間隔(參數2),與才函數同功能的還有subdate函數。
day:該函數從一個日期或時間戳表達式中返回月的天數,結果總是介于1~31之間的整數,與此函數同功能的還有dayofmonth。
dayname:該函數從一個日期或時間戳表達式中返回一周中某天的名稱。
dayofweek:該函數返回一個日期或時間戳表達式中返回某周的天數的序號。該結果總是介于1~7之間的整數。
dayofyear:該函數返回一個日期或時間戳表達式中返回一年中某日的序號。
default:該函數返回參數指定的某列的默認值。
floor:該函數返回小于或等于參數值的最小整數,與ceiling相對。
exp:該函數返回e的x次幕的結果。
format:該函數將一個數值的格式設置為nn,nnn,nnn.nnn的格式。第二個參數表示小數點后的數字個數。
greatest:該函數返回一系列參數中的最大值,和least相對。
hex:如果參數為數字,那么就返回該數字的十六進制表示;如果是字符串,那么將返回每個字符對應的ASCII碼。
if:如果第一個參數值為true,那么函數返回第二個參數的值,否則返回第三個參數的值。如if((1>2),"ljp","st");將返回st。
ifnull:如果參數1的值為null,那么返回參數2的值,否則返回參數1的值。如ifnull(null,"ljp");返回"ljp"。
insert:參數4的值放在參數1中由參數2指定的位置,參數3表示參數1中從參數2指定的位置開始接下來的幾個字符將被參數4取代。如insert('abcdefgh',4,3,'zzz');->'abczzzgh'。insert('abcdefgh',,4,2,'zzz');->'abczzzfgh'。insert('abcdefgh',4,0,'zzz');->'abczzzdefgh'。insert('abcdefgh',4,-1,'zzz');->'abczzz'。insert('abcdefgh',1,5,'zzz');->'zzzfgh'。
instr:該函數返回參數1內參數2的起始位置。如果為找到,則返回0。如instr('12345',4);->4。
interval:該函數第一個參數指定要插入的值,接下來的參數組成一個升序序列,看第一個參數該插入哪個位置。該函數就是返回該位置。如interval(5,0,1,2,3,6,7);->4表示要把5放在第四個位置(此位置上值為3)之后。
isnull:如果參數值為null,那么返回1,否則返回0。
last_day:該函數返回參數指定的日期或時間戳表達式中月的最后一天,如last_day('2009-01-09');->'2009-01-31'。
lcase:該函數將參數的值的所有大寫字母轉換為小寫字母,與lower同義,與ucase相對。
left:該函數返回一個字符串值參數1的左側部分,該部分的長度由第二個參數指定。如left("hello world",3);->'hel'。
length:該函數返回一個字符串值的字節長度。如length(null);->null。
ln:該函數返回參數的自然對數,與log同義。
localtime:該函數返回系統日期和時間,localtimestamp與只同義。
locate:該函數返回參數1在參數2內的起點位置。如果參數1在參數2內未出現,則返回0。參數3表示開始搜索的位置。注意instr函數的區別,instr函數是返回參數1內參數2的開始位置。
log2:返回參數以2為底的對數。如log2(64);->6
log10:返回參數以10為底的對數。
lpad:參數3的值填充在參數1的左側,直到該值的總長度等于參數2的長度。如果最大長度小于參數1的長度,則參數1在左側被截取。如lpad('data',6,'base');->'badata'。lpad('data',2,'base');->'da'。
ltrim:該函數刪除出現在參數前的所有空白,rtrim表示刪除參數末尾的所以空白。
makedate:參數2表示天數,他們被添加到參數1中。如makedate(2009,10);->'2009-01-10'。
maketime:三參數分別表示小時,分鐘,秒鐘。其中分鐘和秒鐘必須在0~59之間,否則會返回null。
mid:該函數提取參數1中的部分字符串值,參數2標識開始位置,參數3標識字符數。如mid('database',5);->'base'。mid('database',5,2);->'ba'。mid('database',-6);-> 'tabase'。mid('database',-6,3);->'tab'。
minute:該函數從一個時間或時間戳表達式中返回分鐘數。
mod:該函數返回兩參數相除的余數。如mod(15.4,4,4);->2.2
month:返回時間戳中的月份數,值介于1~12之間。
monthname:該函數從一個日期或時間戳表達式中返回月的名稱。如monthname('2009-01-01');->‘April’。
now:返回系統日期和時間。
nullif:如果參數1的值等于參數2的值,那么函數返回null。否則返回參數1的值。
oct:該函數返回八進制參數1的十進制數。如oct(8);->10
ord:該函數返回參數指定的字符串表達式的第一個字符的字符集位置。如ord('Das');->68。
period_add:該函數將月數添加到一個指定的日期,日期格式必須為YYYYMM或YYMM。結果格式為YYYYMM。如period_add('200901',3);->200904。
period_diff:該函數返回兩個日期間的月數。如period_diff('200908','200901');->7
PI:返回圓周率。
power:返回參數1的參數2次冪。
quarter:該函數從一個日期或時間戳表達式中返回季度值。結果的值總是介于1~4之間。不過和我們日常生活中的季度不同1~3月為1,4~6月為2,7~9月為3,10~12月為4。
rand:該函數返回0.0和1.0之間的一個隨機數。參數表示下一個隨機值的計算起點。使用相同的參數值重復調用該函數,結果總是相同的。如cast(rand()*1000 as unsigned integer);
repeat:該函數將參數1的值重復參數2給定的次數。
replace:該函數使參數1指定的字符串中由參數2指定的值替換為參數3指定的值。如replace('data','a','e');->'dete'。
reverse:該函數顛倒一個字符串值中的字符的順序。
right:該函數返回參數1的右側部分。該部分長度由第二個參數指定。
round:該函數將一個數字的精度舍入到指定的位數。如round(123.4,-1);->100;round(183.4,-2);->200。
rpad:將參數3的值填充到參數1的右側,知道值的總長度等于參數2指定的長度,與lpad相對。rpad('data',2,'base')->'da'。
second:該函數返回一個時間或時間戳表達式中的秒數。
sec_to_time:該函數將秒數變換為時間。如sec_to_time((24*60*60)-1);->23:59:59
sign:該函數返回一個數值的字符。sign(50);->1;sign(0)->0;sign(-50)->-1;
space:該函數生成一個空格行,空格個數為參數指定的值。
sqrt:返回參數的平方根值。
strcmp:該函數比較兩個字符串表達式的值。如果參數值相等,那么結果為0,如果參數1的值較小,那么返回-1,否則結果為1。
substring:該函數從參數1中減去部分字符串值,參數2給出起始點,參數3給出子付數。如substring('database',5,2);->'ba'。
substring_index:該函數查找參數2表示的值在參數1中的第參數3此出現。如果參數3為正表示從左側查找,返回從左側開始找到的該次出現。如果參數3為負,則從右側開始查找。如substring_index('database','a',3);->'datab';substring_index('database','a',-3);->'tabase';substring_index('database','data',1);->'';substring_index('database','data',-1);->'base'
subtime:該函數對兩個時間表達式執行相減操作并返回一個新時間,timediff與此函數功能相似。
time:該函數返回一個時間或時間戳表達式的時間部分。如time('12:13');->12:13:00
time_to_sec:該函數將時間變換為秒數。如time_to_sec('00:16:40');->1000
timestampdiff:該函數計算兩個日期或時間戳表達式間的時間。參數1表示時間間隔單元,如day,month,year,quarter,week,hour,minute,second,frac_second,參數2和參數3形成兩個表達式。如timestampdiff(day,'2009-01-01','2009-01-04');->4.
timestamp:該函數將參數1變換為一個時間戳,如果指定了參數2,則它應該是一個時間表達式,且會被添加到參數1的值中。
timestampadd:該函數將時間間隔添加到一個日期或時間戳表達式。參數1表示時間間隔的單元,參數2表示天數或月數等,參數3表示時間間隔添加到的表達式。如timestampadd(DAY,2,'2009-01-01');->'2009-01-03';timestampadd(MONTH,2,'2009-01-01');->"2009-03-01"。
trim:該函數刪除參數1表示的字符串值中開始和最后的所有空格。
truncate:該函數將數字截斷到指定的小數位數,注意和round的區別,round是四舍五入,而truncate是截斷。如truncate(123.45,-1);->120。truncate(123.375,1);->123.3。
unhex:與hex相對,將十六進制表示的參數轉換為相應的字符。如unhex(hex('hello'))'->hello
ucase:類似upper,都是將參數中的所有小寫字母轉換為大寫字母。
week:該函數從一個日期或時間戳表達式中返回周數,類似的函數還有weekofyear。結果介于1~53之間的一個整數。如week('2009-06-07');->23
weekday:該函數返回一周中的天數。結果為介于0~6之間的數。0表示星期一。
year:該函數從一個日期或時間戳表達式中返回年數。
yearweek:如果指定參數1,則該函數從一個時間戳或日期表達式中返回格式為YYYYWW的年份及周數。周數的范圍為01~52之間。如yearweek('2009-07-06');->200927
posted @
2009-09-23 16:54 你假笨 閱讀(1480) |
評論 (1) |
編輯 收藏
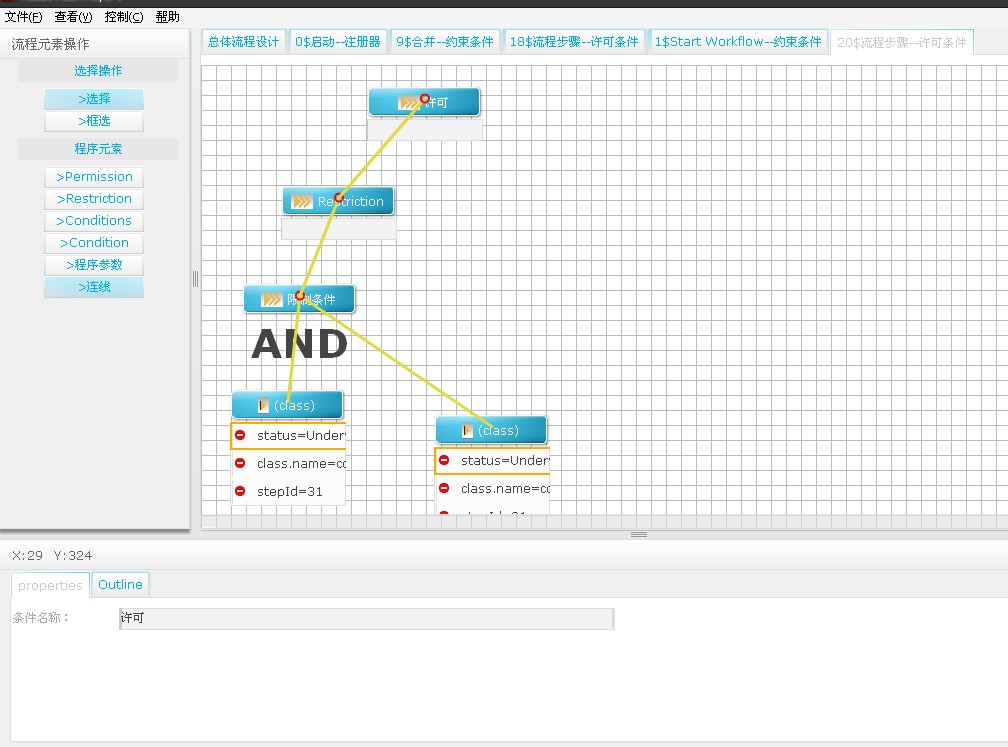
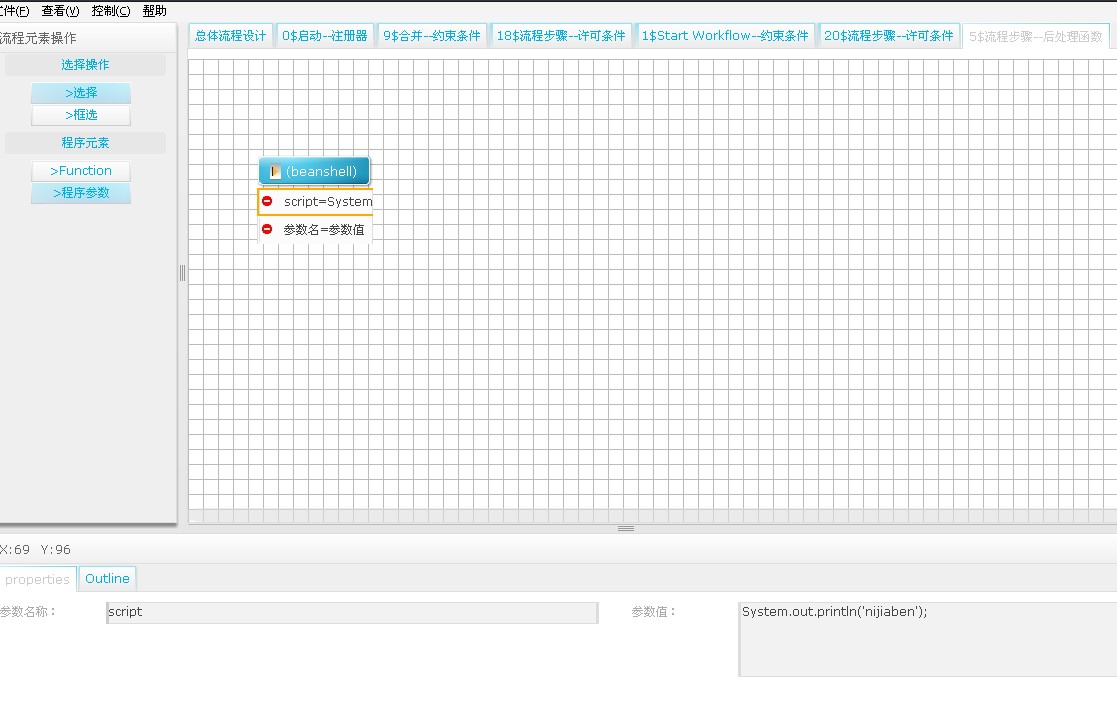
(為了方便java學習者使用OsWorkflow,特用flex設計了此設計器,歡迎大家下載使用。亦歡迎大家光臨我的個人博客http://www.lovestblog.cn)前兩天和一網友聊天的時候,他強烈建議我把這個工作流設計器好好完善下,本來學校項目的需求基本已經滿足了,但是離完善實在差距太遠,于是花了兩天時間在原有基礎上進行了下改進,現在得工作流設計器比以前的版本多了幾個功能:
1. 導出文件請選擇文件-->>導出選項,導出文件保存時請您務必加上xml的后綴
2. 鼠標移到直線上的時候,直線會初始化顯示為綠色,按住鼠標不放,拖動鼠標,將會在直線上出現一個拐點,該拐點可以隨便拖動,雙擊拐點會自動刪除該拐點,也可用框選選中拐點進行刪除,選中的拐點,初始顏色為藍色,您可以自由設置,移開時直線會恢復為粉紅色
3. 可用框選選中組件進行刪除,如果為半透明狀態,則表明為選中,您同時可以按住ctrl鍵,選中其他沒有被選中的組件,從而進行進行加選
4. 如果您本選中了某組件,然后按住ctrl鍵再將其框選,則該組件會被取消選中
5. 點擊鼠標右鍵有備選菜單進行操作
6. 下面的Outline是臨時生成的xml文件,您可以在不導出文件的情況下查看現有的xml文件
7. 選擇子元素步驟操作之后,只有當鼠標在開始節點或步驟節點下面的action列表中點擊時才會新增一個action操作
8. 合并節點只能有一個無條件連接進行連出,合分支節點只能連出無條件連接,且可多個
9.根據導入的文件生成得流程圖不具備定位的功能,因為我覺得是多余的,只要它們之間的關系明確得話,那你再在界面上進行拖拉成你喜歡得樣式就可以了,所以當你導入文件的時候,看到的會是每個節點隨機選擇位置。
以上是我在此版本中進行的系統說明,請見關于--》系統說明。
再您下載我附件的同時,請先到
http://get.adobe.com/cn/air/處下載AdobeAIRInstaller.exe文件進行安裝,使您系統能進行AIR文件的安裝,附件為AIR格式文件。
/Files/nijiaben/OsWorkflow.rar
posted @
2009-09-05 18:28 你假笨 閱讀(1939) |
評論 (1) |
編輯 收藏
歡迎大家提出意見,多余的話就不多說了,花了10天的作品,辛苦啊由于有400多k,所以大家在看到下面效果前,先給大家幾張截圖哈,如果感興趣再去搗鼓一下那東西呵。也歡迎各位到我個人博客上留言哈,
http://www.lovestblog.cn
這里好像不能插入flash,如果大家有興趣的話,可以去
http://www.lovestblog.cn/articlePicture/84/84.1.swf體驗下真實的效果。
posted @
2009-07-31 23:52 你假笨 閱讀(6781) |
評論 (44) |
編輯 收藏
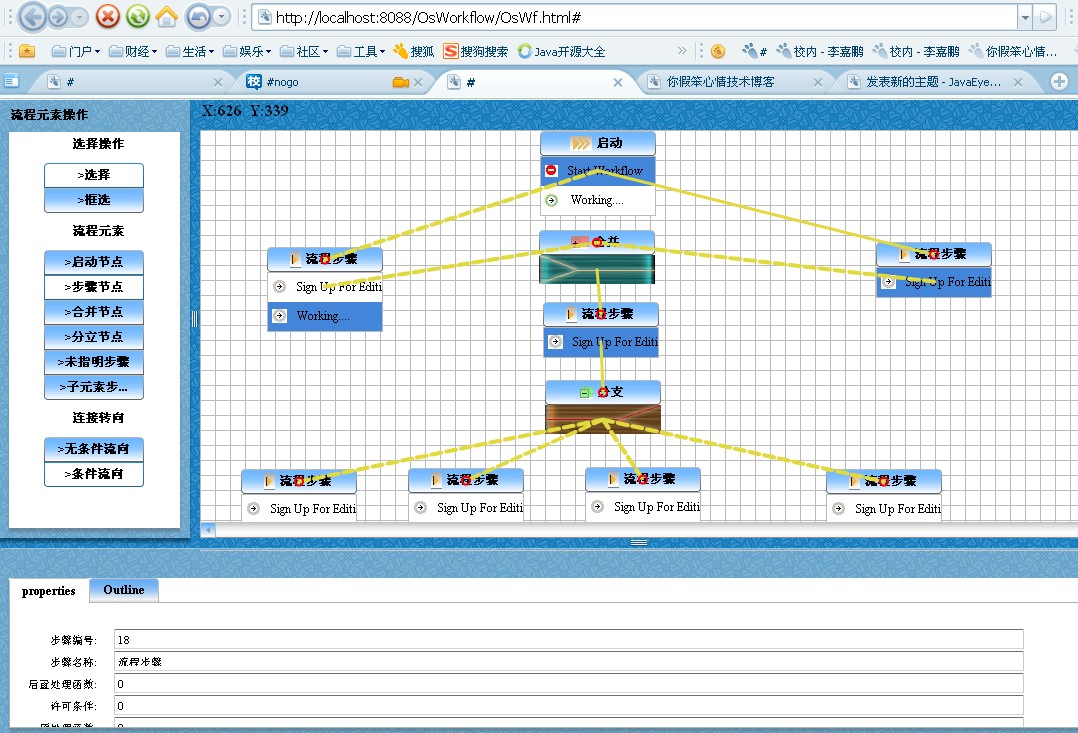
這個暑假本來打算去廣州一公司實習的,結果接到老師的一個項目,是關于工作流的,實現一個文件審批的流程,起初也不知道是怎么回事,老師也有些事情,就拋下一句話“去下載OSWorkflow的客戶端下來看看”,結果下載下來才知道是怎么回事,要求用Flex實現它,我的媽呀,這個可是一個不小的工程,還得我一個人完成,上面這個項目也批下來了,錢都撥下來了,不完成不行啊,巧合的是自己這個暑假又有一個培訓,根本沒什么時間去做呀,就在前幾天突然決定暫時放棄培訓,先把這個完成再說,在做的時候沒什么底,不知道自己能不能完成,因為感覺很多東西我都不會。不管怎樣還是要試一下不,我就喜歡嘗試下,往往在嘗試中能發現點什么,這不從19號開始就衣食住行都在學校實驗室了,到今天界面上的功能基本實現了大部分了,至少能拖組件,然后在組件間能按照一定的要求進行連接,比如說從合并節點出來的只能是無條件連接到節點或這操作,每個操作最多只能有一個非條件連接,連線的終點只能是節點等等,我沒有研究過OsWorkflow的源碼,但是我從提供給我的客戶端以及生成的xml文件推斷出一些規則,于是經過不久的思考就開始動工了,慢慢的雛形也就出來了,當中碰到了不少問題,當然也慢慢解決了,等完成之后再把代碼優化下,到時覺得可以的話,可以開源,上次我那博客
http://www.lovestblog.cn本來也打算開源的,但是確實有點擔心,怕放上來,被高人們唾罵,怕承受不了巨大的打擊,就還是先放放了,再者也沒時間去優化代碼,所以等有時間了再整理下再拿出來挨批了,呵呵,好了說了那么多廢話了,還是把這個工作流的一個截圖拿出來曬曬吧,等全部完成之后在拿出來,希望能聽到大家寶貴的意見。
posted @
2009-07-24 23:30 你假笨 閱讀(2168) |
評論 (2) |
編輯 收藏
本文最先發布于本人個人博客
http://www.lovestblog.cn
下面簡單的說說歸并排序,所謂歸并排序就是說把輸入數組分成兩組當然也可以大于2組,一般我們是等量的分成2組,通過遞歸我們可以把長度為n的數組分成n個數組,我們通過一定的關鍵字比較把兩兩結合成一個有序的數組,然后回溯到原數組大小的有序數組,具體的我就不多說了,因為比較簡單,到網上可以找些相關文章看看什么是歸并排序,歸并排序算法可以再O(nlogn)的時間內對長度為n的序列完成排序,至于合并兩個有序數組,假如這兩個數組的長度分別為m和n,那么我們只需要O(n+m)的時間久可以完成對這兩個有序數組的合并,下面還是代碼說明之:
package org.rjb.Sort;
/** *//**
* 歸并排序(升序排列)
* @author ljp
*
*/
public class MergeSort {
/** *//**
* 對原始數組進行平等劃分為兩個子數組
* @param nums
*/
public static void sort(int[] nums){
int n=nums.length;
if(n<=1)
return;
int nums1[]=new int[n/2];
int nums2[]=new int[n-n/2];
for(int i=0,j=nums1.length;j<nums.length;i++,j++){
if(i<nums1.length){
nums1[i]=nums[i];
}
nums2[i]=nums[j];
}
//遞歸對子數組進行劃分
sort(nums1);
sort(nums2);
//把子數組排序后的結果進行合并
merge(nums,nums1,nums2);
}
/** *//**
* 合并兩個有序的子數組為一個有序的數組
* @param nums 合并之后的數組
* @param num1 有序的子數組
* @param num2 有序的子數組
*/
public static void merge(int[] nums,int num1[],int num2[]){
int n1=num1.length-1;
int n2=num2.length-1;
int k=0;
int k1=0,k2=0;
while(k1<=n1||k2<=n2){
int e=0;
if(k1>n1){//如果第一個數組已經全部比較完了,那么我們只要直接復制第二個數組的條目到合并數組中即可
e=num2[k2++];
}else if(k2>n2){//如果第二個數組已經全部比較完了,那么我們只要直接復制第一個數組的條目到合并數組中即可
e=num1[k1++];
}else if(num1[k1]>num2[k2]){//把比較的兩個條目中關鍵值小的放到合并數組中
e=num2[k2++];
}else{
e=num1[k1++];
}
nums[k++]=e;
}
}
/** *//**
* 主函數
* @param args
*/
public static void main(String args[]){
int[] nums={10,2,3,7,4,9,1};
sort(nums);
for(int i=0;i<nums.length;i++){
System.out.print(nums[i]+" ");
}System.out.println();
}
}
posted @
2009-05-29 16:55 你假笨 閱讀(1228) |
評論 (0) |
編輯 收藏
摘要: 本文最先發布在我的個人博客http://www.lovestblog.cn
文字轉載自http://jaskell.blogbus.com/logs/3272503.html,代碼是自己寫的一個測試類。
&nbs...
閱讀全文
posted @
2009-05-28 22:14 你假笨 閱讀(1261) |
評論 (0) |
編輯 收藏
摘要: 本文最先發表在本人的個人博客http://www.lovestblog.cn
先把題目曬出來,這個題目不是很難,但是當時僅僅因為輸出的問題折騰了我大半天,在ACM提供的運行環境中只有到最后才能把結果輸出,不能在中途就把結果輸...
閱讀全文
posted @
2009-05-26 11:00 你假笨 閱讀(1748) |
評論 (0) |
編輯 收藏
這兩天接了一個網站,比較簡單兩三天就基本搞定了,但是其中碰到最難的就是flex的一個中文問題了,下面我主要想講講三種不同的現象。
- 第一種: Image組件的源地址是中文的,比如resources/數學/高等數學/math.jpg;
tomcat中的server.xml中配置端口的那段加上 URIEncoding="utf-8";
直接訪問資源地址如:http://localhost:8080/WebTest/resources/數學/高等數學/math.jpg;
這種情況下Image組件不能顯示出來,下面直接訪問的地址能訪問到數據。
- 第二種: Image組件的源地址是GBK的,比如比如resources/數學/高等數學/math.jpg;
tomcat中的server.xml中配置端口的那段加上 URIEncoding="GBK";
直接訪問資源地址如:http://localhost:8080/WebTest/resources/數學/高等數學/math.jpg;
這種情況下Image組件式能顯示出來的,但是直接訪問的那個地址是不能訪問到數據的。
- 第三種: mage組件的源地址是utf-8的,比如resources/%E6%95%B0%E5%AD%A6/%E9%AB%98%E7%AD%89%E6%95%B0%E5%AD%A6/math.jpg;
tomcat中的server.xml中配置端口的那段加上 URIEncoding="utf-8";
直接訪問資源地址如:http://localhost:8080/WebTest/resources/數學/高等數學/math.jpg;
這種情況下Image組件式能顯示出來的,直接訪問的那個地址是也能訪問到數據。
原因分析:
瀏覽器默認的編碼方式是utf-8的,flex中地址默認是采用utf-8的,而tomcat默認的編碼方式是ISO-8859-1的,即我們訪問的地址都是iso-8859-1編碼的,如果不設置tomcat中的編碼方式即為默認的iso-8859-1方式,那么瀏覽器中的請求地址中的中文是不能被解析的,所以請求不到資源,因此,我們通過設置tomcat的編碼方式為utf-8即可以通過瀏覽器訪問到含有中文名的資源。同理默認情況下flex組件也訪問不到帶有中文路徑的資源;
如果tomcat設置為utf-8的,我們可以訪問http://localhost:8088/EncodingTest/resource/未命名.jpg類似的地址,但是對于flex中<mx:Image source="resources/體育/足球/1.jpg" />這樣的組件還是顯示不出來(這點我也疑惑,還望高人指點),但是我們設置為<mx:Image source="resources/%E4%BD%93%E8%82%B2/%E8%B6%B3%E7%90%83/1.jpg" />這樣我們就能訪問到了。
如果tomcat編碼方式設置為GBK的話,對于flex組件<mx:Image source="resources/體育/足球/1.jpg" />我們是可以訪問到的,但是對于<mx:Image source="resources/%E4%BD%93%E8%82%B2/%E8%B6%B3%E7%90%83/1.jpg" />這樣的我們是訪問不到的,對于瀏覽器中的地址http://localhost:8088/EncodingTest/resource/未命名.jpg,我們是訪問不到的,但是對于我們把未命名進行GBK編碼之后的%CE%B4%C3%FC%C3%FB替換了,即http://localhost:8088/EncodingTest/resource/%CE%B4%C3%FC%C3%FB.jpg就能訪問了。至于如何取得中文的GBK編碼我們可以通過java方法取得,比如String s="未命名.jpg";s=java.net.URLEncoder.encode(s,"GBK");這樣就取得了“未命名.jpg”的GBK編碼了。
總結如下:
總結出了一個基本解決中文編碼的方法,即tomcat中設置編碼為utf-8,flex中組件要訪問資源的路徑如果帶有中文那么我們去把中文轉換成utf-8格式的在賦值給組件的source屬性,對于瀏覽器中訪問的地址就可以是帶有中文的訪問地址了。
posted @
2009-04-30 01:35 你假笨 閱讀(1705) |
評論 (1) |
編輯 收藏
本文最初發布于本人的flex博客http://www.lovestblog.cn/,歡迎大家光臨。(轉載的請不要刪除該行,謝謝合作)
我們都知道jQUery對象中有一個類數組的元素包裝集,該集合類似js中的數組一樣擁有length屬性,因此我們稱此為類數組,下面我們就來總結下這個jQuery對象中的類數組時如何進行操作的,看看我們的jQuery為我們都提供了哪些可用的方法:
size():很明顯,它應該是返回包裝集中的元素個數,如$('a').size()表示鏈接元素的個數;
get(index):當沒指定index時就默認取包裝集中所有元素,并以js中的數組形式返回,如果指定了index,則返回下標為index對應的元素,如$('img[title]').get(0)返回包含屬性title的第一個img元素,其也等效于$('img[title]')[0];
index(elem):在包裝集中返回元素elem所在的下標,如果沒找到該元素則返回-1;
add(String|elem|Array):把參數中的元素添加到包裝集中,如果參數是jQuery選擇器,那么將把所有匹配的對象都添加到集合中,如果是html元素那就通過clean方法得到的元素數組添加到集合中,如果是dom元素或dom元素數組,那就直接添加到集合了;注意返回的是添加后的包裝集;如$('img[alt]','img[title]')等效于$('img[alt]').add('img[title]')即返回包含了alt屬性的img元素或包含了title屬性的img元素;
not(String|elem|Array):把包裝集中滿足參數條件的元素刪除,注意參數只能是篩選表達式,即以"["或者":"開頭的表達式,如$('img[title]').not('title*=puy')即返回包含title屬性的img元素,并且這些元素的title屬性中包含有puy文本;返回的是篩選之后的包裝集;
filter(String|function):如果傳入的參數是String類型的話,那么該表達式必須也是篩選表達式,用于從包裝集里刪除所有與選擇器不匹配的元素;如果傳入的是一個函數的話,那么包裝集中的每個元素都調用這個函數,若這個函數返回false則把這個元素從包裝集中刪除,而在函數中可以通過this關鍵字來調用當時包裝集中調用方法的元素;如$('td').filter(function(){return this.innerHTML.match(/^"d+$/)})返回td中的內容為數字的所有td元素;
slice(begin,end):創建并返回新的包裝集,該包裝集是原來包裝集的連續的一部分,且新包裝集的第一個元素是原包裝集中的begin位置的元素,而最后一個元素是end位置元素的前一元素,當然end可以不指定,那么將延伸到原始包裝集的末尾;如$('*').slice(2,3)這個語句選擇頁面上的所有元素,然后生存包含原始包裝集的第三個元素的新包裝集,注意這個$('*').get(2)不同,這個返回的是元素,而slice方法返回的是包裝集,從而擁有包裝集的操作;
childen():返回原始包裝集元素的所有不同子元素所組成的新包裝集(不包含文本節點),如$('div').children()返回所有div元素下的子元素所組成的新包裝集;如果指定了參數,那么該參數也是篩選表達式;
contents():返回原始包裝集元素的內容新包裝集(可以包含文本節點);注意此方法不能接受參數進行過濾;
next():返回原始包裝集元素的所有唯一的下一個兄弟元素所組成的新包裝集;如果指定了參數,那么該參數也是篩選表達式;如$('div#someDiv').next()返回包含id為someDiv的div元素的下一個兄弟元素的包裝集;如果指定了參數,那么該參數也是篩選表達式;
nextAll():返回包含原始包裝集元素的所有后續兄弟的新包裝集;如$('div#someDiv').nextAll()返回包含id為someDiv的div元素的后面兄弟元素的新包裝集;如果指定了參數,那么該參數也是篩選表達式;
parent():返回原始包裝集所有元素的唯一直接父元素的新包裝集;如果指定了參數,那么該參數也是篩選表達式;
parents():返回原始包裝集所有元素的祖先元素的新包裝集;如果指定了參數,那么該參數也是篩選表達式;
prev():返回原始包裝集元素的所有唯一的上一個兄弟元素組成的新包裝集;如果指定了參數,那么該參數也是篩選表達式;
prevAll():返回包含原始包裝集元素的所有前面兄弟元素的新包裝集;如果指定了參數,那么該參數也是篩選表達式;
siblings():返回包含原始包裝集元素中的所有唯一兄弟元素所組成的新包裝集;如果指定了參數,那么該參數也是篩選表達式;
find(String):返回包含原始包裝集里與傳入的選擇器表達式相匹配的所有元素的新包裝集,并且原始包裝集中的元素的后代也會被傳入新的包裝集;
contains(text):返回包含text參數所傳入的文本字符串的元素所組成的新包裝集;
is(String):如果包裝集中含有String匹配的元素,那么返回true,否則返回false;
clone(copyHandle):如果傳入的參數為true,那么會連帶事件一起拷貝,否則不拷貝事件,形成一個新的包裝集;
end():在jQuery命令鏈內調用,以便返回退到前一個包裝集;
andSelf():合并命令鏈內最近產生的兩個包裝集;
對于包裝元素的操作就總結到這里,如果哪里不對的還請各位指出來方便大家參考學習。
posted @
2009-04-22 10:50 你假笨 閱讀(2393) |
評論 (0) |
編輯 收藏
jQuery選擇器其實是一個有些地方比較費解的,如果沒有經過多次實驗的話,很難得出它的每個操作符到底是干什么的,很容易出錯,經過我的多次測試,終于對一些比較難理解或容易出錯的選擇操作進行總結,既方便自己將來查詢又方便初學者學習。如果哪里有不對的還望大家幫我指出來,這里是一個相互學習的地方。
1. 先說說通過位置選擇的幾個操作:
- :first:默認情況下是相對整個頁面來說的第一個,如:li:first表示整個頁面的第一個li元素,而ul li:first表示整個頁面的第一個li元素,并且是在ul下的子元素;
- :last:同上了,只是是最后一個而已;
- :first-child:為每個父元素匹配第一個子元素,如li:first-child返回每個ul的第一個li元素。可以這樣理解,頁面中的元素有相同的父元素的,并且里面又包含li元素的,那么就取第一個li元素,每個子類集合都要進行判斷,直到找出所有符合要求的li元素;
- :last-child:這個也與上面相對了,只是取的是最后一個;
- :only-child:返回所有沒有兄弟節點的元素,注意,文本元素不是,也就是說類似這樣的<div>hello<a href="">jquery</a></div>,對于這段會選出<a>元素;對于$(”label:only-child“)會選出是label元素,同時它是它父類唯一的子元素的label元素;
- :nth-child(n):返回第n個子節點,n從1開始,如果n取0,那么就會選擇所有的元素。如:[*]li:nth-child(2)返回li元素,并且該元素是其父元素的第二個子元素;
- :nth-child(even|odd):返回偶數或奇數的子節點;
- :nth-child(An+B):返回滿足表達式An+B的所有子節點,比如3n+1返回所處位置為父節點子元素的是3的倍數加1的那個子元素;
- :even:頁面范圍內的處于偶數位置的元素,如:li:even返回全部偶數li元素;
- :odd:頁面范圍內的處于奇數位置的元素;
- :eq(n):第n個匹配的元素(n從0開始),如:li:eq(3)返回整個頁面的第四個li元素,ul li:eq(1)返回頁面中第一個ul元素下的第二個li元素,注意:只匹配一次就返回了;
- :gt(n):第n個匹配元素(不包括)之后的元素(n從0開始),如:ul:gt(2)返回從第3個ul開始的所有ul元素(含第三個);
- :lt(n):第n個匹配元素(不包括)之前的元素(n從0開始),如:ul:lt(2)返回從第0個和第1個ul元素;
2. 利用css選擇器進行選擇:
- 元素標簽名:比如說$(”a“)會選出所有鏈接元素;
- #id:通過元素id進行選擇,比如說$("#form1")會選擇id為form1的元素;
- .class:通過元素的CSS類來選擇,比如說$(".boldstyle")會選擇CSS為boldstyle類的元素;
- 標簽名#id.class:通過某類元素的id屬性和class屬性來選擇,如:$(a#blog.boldStyle)會選擇id為blog并且CSS類型為.boldStyle類型的鏈接元素(<a id='blog' class='.boldStyle'>);
- 父標簽名 子標簽名.class:通過選擇父標簽下的某種CSS類型的子元素,如:$(p a.redStyle)會選擇p段落元素中的鏈接子元素a,且其css類型為.redStyle;
3. 通過子選擇器,容器選擇器和屬性選擇器進行選擇:
- *:匹配所有的元素,比如說:$(*)會把頁面中的所有元素都返回;
- E:匹配標簽名為E的所有元素,如$("a")返回所有鏈接元素;
- E F:匹配父元素E下的標簽名為F的所有子元素(F可以為E的子類的子類,甚至更遠);
- E>F:匹配父元素E下的所有標簽名為F的直接子元素;
- E+F:匹配所有標簽名為F的元素,并且有E類型的兄弟節點在該F元素之前(E,F緊挨著);
- E~F:匹配前面是任何兄弟節點E的所有元素F(E,F不必緊挨著);
- E:has(F):匹配標簽名為E,至少有一個標簽名為F的后代節點的所有元素E;
- E.C:匹配帶有類名C的所有元素E。.C等效于*.C;
- E#I:匹配id為I的所有元素E,#I等效于*#I;
- E[A]:匹配帶有屬性A的所有元素E;
- E[A=V]:匹配所有屬性A的值為V的元素E;
- E[A^=V]:匹配所有元素E,且A的屬性值是V開頭的;
- E[A$=V]:匹配所有元素E,且A的屬性值是V結尾的;
- E[A*=V]:匹配所有元素E,且A的屬性值中包含有V;
4.利用jQuery自定義的選擇器進行選擇:
- :button:選擇任何按鈕類型的元素,包括input[type=submit]等等;
- :checkbox:選擇復選框元素;
- :file:選擇所有文件類型元素,即input[type=file];
- :image:選擇表單中的圖像元素,即input[type=image],注意此處和前面根據標簽名img選擇圖像有點不同哈;
- :input:選擇表單元素,如<input>,<select>,<textarea>,<button>等;
- :radio:選擇單選按鈕元素;
- :reset:選擇復位按鈕元素,如input[type=reset],button[type=reset];
- :submit:選擇提交按鈕元素;
- :text:選擇文本字段元素,即input[type=text];
- :animated:選擇當前處于動態控制下的元素;
- :contains(hello):選擇包含文本hello的元素;
- :header:選擇標題元素,如<h1>;
- :parent:選擇擁有后代節點(包括文本)的元素,而排除空元素;
- :selected:選擇已選中的選項元素;
- :visible:選擇可見元素;
- :enable:選擇界面上已經可以使用的表單元素;
- :disabled:選擇界面上被禁用的表單元素;
- :checked:選擇已選中的復選框或單選按鈕;
主要還是要多練習,多寫點例子熟悉下,東西其實也不是很多哈,希望能給大家帶來幫助;
posted @
2009-04-21 12:17 你假笨 閱讀(5315) |
評論 (1) |
編輯 收藏
摘要: 嘿,先向大家宣傳下我站啊,http://www.lovestblog.cn/,這是我的個人博客,希望大家常來我博客坐坐呢,相信大家也會有所收益的,不過我也不會放棄javaeye的,我也會一直在這里寫東西的。 (轉載的請不要刪除該段,謝謝合作)
&nbs...
閱讀全文
posted @
2009-04-11 17:52 你假笨 閱讀(7791) |
評論 (14) |
編輯 收藏