 QueryRunner run = new QueryRunner(dataSource);// Use the BeanHandler implementation to convert the first// ResultSet row into a Person JavaBean.ResultSetHandler<Person> h = new BeanHandler<Person>(Person.class);// Execute the SQL statement with one replacement parameter and// return the results in a new Person object generated by the BeanHandler.Person p = run.query( "SELECT * FROM Person WHERE name=?", h, "John Doe");
QueryRunner run = new QueryRunner(dataSource);// Use the BeanHandler implementation to convert the first// ResultSet row into a Person JavaBean.ResultSetHandler<Person> h = new BeanHandler<Person>(Person.class);// Execute the SQL statement with one replacement parameter and// return the results in a new Person object generated by the BeanHandler.Person p = run.query( "SELECT * FROM Person WHERE name=?", h, "John Doe");ҳqҷйҮҢжңүдёӘең°ж–№жңүзәҰжқҹпјҢһ®ұжҳҜиҰҒжұӮҪCЮZҫӢдёӯзҡ„JavaBeanҫc»Personдёӯзҡ„еӯ—ж®өе®ҡд№үиҰҒе’Ңж•°жҚ®еә“зҡ„еӯ—ж®өе®ҡд№үдёҖиҮҙгҖӮJavaзҡ„е‘ҪеҗҚд№ жғҜдёҖиҲ¬жҳҜйӘҶеі°еҶҷжі•еQҢдҫӢеҰӮuserIdеQҢйӮЈд№Ҳж•°жҚ®еә“дёӯе°ұеҝ…йЎ»е®ҡд№үдёәuserIdеQҢиҖҢй—®йўҳеңЁдәҺпјҡжңүж—¶еҖҷжҲ‘们йңҖиҰҒж•°жҚ®еә“дёӯеӯ—ҢDлҠҡ„е®ҡд№үж јејҸдёҺJavaBeanзҡ„е‘ҪеҗҚдёҚдёҖж шPјҢжҜ”еҰӮж•°жҚ®еә“е®ҡд№үдШ“еQҡuser_idеQҢиҖҢJavaBeanеҲҷе®ҡд№үдШ“userId
зңӢжәҗд»Јз ҒеҸҜиғҪжңүзӮ№иҙТҺ(guЁ©)—¶й—Я_јҢеңЁе®ҳж–№зҡ„exampleҷеөйқўзҡ„жңҖдёӢйқўжһң然жңүдёҖҢDөе…ідәҺиҮӘе®ҡд№үBeanProcessorзҡ„жҢҮеј•гҖӮж‘ҳеҪ•еҮәжқҘпјҡ
BasicRowProcessor uses a BeanProcessor to convert ResultSet columns into JavaBean properties. You can subclass and override processing steps to handle datatype mapping specific to your application. The provided implementation delegates datatype conversion to the JDBC driver.
BeanProcessor maps columns to bean properties as documented in the BeanProcessor.toBean() javadoc. Column names must match the bean's property names case insensitively. For example, the firstname column would be stored in the bean by calling its setFirstName() method. However, many database column names include characters that either can't be used or are not typically used in Java method names. You can do one of the following to map these columns to bean properties:
1. Alias the column names in the SQL so they match the Java names: select social_sec# as socialSecurityNumber from person
2. Subclass BeanProcessor and override the mapColumnsToProperties() method to strip out the offending characters.
еӨ§жҰӮж„ҸжҖқе°ұжҳҜжҸҗдҫӣдәҢҝUҚж–№ејҸпјҡдёҖҝUҚе°ұжҳҜжңҖзӣҙжҺҘзҡ„пјҢз”Ёasе…ій”®еӯ—жҠҠcolNameйҮҚе‘ҪеҗҚпјҢеҸҰдёҖҝUҚж–№ејҸе°ұжҳҜз‘фжүҝBeanProcessorҫc»пјҢйҮҚеҶҷmapColumnsToProperties()ж–ТҺ(guЁ©)і•гҖ?br /> йӮЈеҪ“然жҳҜҪW¬дәҢҝUҚж–№ејҸжӣҙеҠ е…·жңүд»ЈиЎЁжҖ§гҖӮе°қиҜ•дәҶдёҖдёӢгҖӮд»Јз ҒеҰӮдёӢпјҡ
1 public class CustomBeanProcessor extends BeanProcessor {
public class CustomBeanProcessor extends BeanProcessor {
2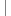
3 @Override
4 protected int[] mapColumnsToProperties(ResultSetMetaData rsmd,
5 PropertyDescriptor[] props) throws SQLException {
PropertyDescriptor[] props) throws SQLException {
6 int cols = rsmd.getColumnCount();
7 int columnToProperty[] = new int[cols + 1];
8 Arrays.fill(columnToProperty, PROPERTY_NOT_FOUND);
9
10 for (int col = 1; col <= cols; col++) {
11 String columnName = rsmd.getColumnLabel(col);
12 if (null == columnName || 0 == columnName.length()) {
13 columnName = rsmd.getColumnName(col);
14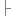 }
}
15 columnName = colNameConvent(columnName); // еңЁиҝҷйҮҢиҝӣиЎҢж•°жҚ®еә“иЎЁcolumnNameзҡ„зү№ҢDҠеӨ„зҗ?/span>
16 for (int i = 0; i < props.length; i++) {
17
18 if (columnName.equalsIgnoreCase(props[i].getName())) {
19 columnToProperty[col] = i;
20 break;
21 }
22 }
23 }
24 return columnToProperty;
25 }
26
27 /**
28 * ж•°жҚ®еә“еҲ—еҗҚйҮҚж–°зәҰе®?br />
29 * @param columnName
30 * @return
31 */
32 private String colNameConvent(String columnName) {
33 String[] strs = columnName.split("_");
34 String conventName = "";
35 for (int i = 0; i < strs.length; i++) {
36 conventName += StringUtils.capitalize(strs[i]);
37 }
38 StringUtils.uncapitalize(conventName);
39 return conventName;
40 }
41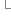 }
}
public class CustomBeanProcessor extends BeanProcessor {

2
3
@Override4
protected int[] mapColumnsToProperties(ResultSetMetaData rsmd,5
PropertyDescriptor[] props) throws SQLException { PropertyDescriptor[] props)
PropertyDescriptor[] props) 6
int cols = rsmd.getColumnCount();7
int columnToProperty[] = new int[cols + 1];8
Arrays.fill(columnToProperty, PROPERTY_NOT_FOUND);9
10
for (int col = 1; col <= cols; col++) {11
String columnName = rsmd.getColumnLabel(col); 12
if (null == columnName || 0 == columnName.length()) {13
columnName = rsmd.getColumnName(col);14
}15
columnName = colNameConvent(columnName); // еңЁиҝҷйҮҢиҝӣиЎҢж•°жҚ®еә“иЎЁcolumnNameзҡ„зү№ҢDҠеӨ„зҗ?/span>16
for (int i = 0; i < props.length; i++) {17
18
if (columnName.equalsIgnoreCase(props[i].getName())) {19
columnToProperty[col] = i;20
break;21
}22
}23
}24
return columnToProperty;25
}26
27
/**28
* ж•°жҚ®еә“еҲ—еҗҚйҮҚж–°зәҰе®?br />
29 * @param columnName30
* @return31
*/32
private String colNameConvent(String columnName) {33
String[] strs = columnName.split("_");34
String conventName = "";35
for (int i = 0; i < strs.length; i++) {36
conventName += StringUtils.capitalize(strs[i]);37
}38
StringUtils.uncapitalize(conventName);39
return conventName;40
}41
}жіЁж„ҸmapColumnsToPropertiesж–ТҺ(guЁ©)і•зҡ„йҖ»иҫ‘жҳҜд»ҺзҲ¶зұ»зҡ„ж–№жі•дёӯзӣҙжҺҘеӨҚеҲ¶еҮәжқҘзҡ„пјҢ然еҗҺеңЁз¬¬15иЎҢйӮЈйҮҢеҸҳдәҶдёӘжҲҸжі•еQҢиҝҷйҮҢзҡ„columnNameһ®ұжҳҜд»Һж•°жҚ®еә“дёӯиҜ»еҮәжқҘзҡ„пјҢиҮӘе®ҡд№үдёҖдёӘprivateж–ТҺ(guЁ©)і•з”ЁдәҺиҪ¬жҚўе‘ҪеҗҚеQҢиҝҷйҮҢдҪ һ®ұеҸҜд»Ҙж·»еҠ иҮӘе·Юqҡ„е‘ҪеҗҚҫUҰжқҹгҖӮдҫӢеҰӮдёҠйқўе°ұжҳҜжҠҠ user_id иҪ¬еҢ–дёәJavaзҡ„йӘҶеі°еҶҷжі•пјҡuserId
еҶҚж·ұе…ҘдёҖеұӮжҖқиҖғпјҢдҪ еҸҜд»ҘеңЁҳqҷйҮҢҳqӣиЎҢжӣҙеӨҡжү©еұ•еQҢд»Ҙдҫҝи®©иҮӘе·ұеҸҜд»ҘйҖүжӢ©дёҚеҗҢзҡ„е‘ҪеҗҚиқ{жҚўж–№ејҸгҖӮе®ҡд№үдәҶҳqҷдёӘProcessorд№ӢеҗҺеQҢдёӢйқўзңӢзңӢеҰӮдҪ•и°ғз”Ёпјҡ
Connection conn = ConnectionManager.getInstance().getConnection();QueryRunner qr = new QueryRunner();CustomBeanProcessor convert = new CustomBeanProcessor();RowProcessor rp = new BasicRowProcessor(convert);BeanHandler<User> bh = new BeanHandler<User>(User.class, rp);User u = qr.query(conn, sql, bh, params);DbUtils.close(conn); 1protected <T> List<T> selectBeanList(Connection conn, String sql, Class<T> type,
2 Object[] params) throws Exception {
3 log.debug("select sql:[" + sql + "]");
4 QueryRunner qr = new QueryRunner();
5 CustomBeanProcessor convert = new CustomBeanProcessor();
6 RowProcessor rp = new BasicRowProcessor(convert);
7 ResultSetHandler<List<T>> bh = new BeanListHandler<T>(type, rp);
8 List<T> list = qr.query(conn, sql, bh, params);
9 return list;
10 }
protected <T> List<T> selectBeanList(Connection conn, String sql, Class<T> type,2
Object[] params) throws Exception {3
log.debug("select sql:[" + sql + "]");4
QueryRunner qr = new QueryRunner();5
CustomBeanProcessor convert = new CustomBeanProcessor();6
RowProcessor rp = new BasicRowProcessor(convert);7
ResultSetHandler<List<T>> bh = new BeanListHandler<T>(type, rp);8
List<T> list = qr.query(conn, sql, bh, params);9
return list;10
}иҮідәҺдёЮZ»Җд№Ҳжү©еұ•иҝҷдёӘж–№жі•е°ұеҸҜд»Ҙе®һзҺ°ҳqҷдёӘйҖ»иҫ‘һ®ұеҫ—еҺ»и·ҹжәҗд»Јз ҒзңӢе®ғзҡ„еҶ…йғЁе®һзҺ°еQҢз”ЁдәҶдёҖдәӣJavaBeanзҡ„еӨ„зҗҶе’ҢеҸҚжҳ зҡ„жҠҖе·§жқҘеҒҡзҡ„гҖӮе…·дҪ“е°ұдёҚиҜҙгҖ?br /> жҖИқ»“еQҡcommonsҫl„дҡgйғҪи®ҫи®Ўеҫ—йқһеёёеҘҪпјҢеҸҜжү©еұ•жҖ§е’Ңе®һз”ЁжҖ§йғҪйқһеёёй«ҳгҖӮиҷҪ然дёҠйқўдӢDдҫӢе®һзҺоCәҶиҪ¬жҚўйҖ»иҫ‘зҡ„жӣҝжҚўпјҢдҪҶжҳҜд»Қ然йңҖиҰҒејҖеҸ‘дқhе‘ҳеңЁи®ҫи®Ўж•°жҚ®еә“зҡ„ж—¶еҖҷе’ҢеҶҷJavaBeanж—үҷғҪиҰҒдёҘж јеҒҡеҘҪ规иҢғпјҢйҒҝе…Қдә§з”ҹдёҚеҝ…иҰҒзҡ„й—®йўҳгҖӮиҝҷж–ҡwқўRuby On Railsһ®ЮqӣҙжҺҘеҶ…йғЁе®һзҺҺНјҢеҠЁжҖҒиҜӯӯaҖзҡ„дјҳзӮ№зү№еҲ«иғҪдҪ“зҺ°еQҢеҗҢж—¶ејәеҲ¶дҪ еңЁи®ҫи®Ўж—¶еҝ…йЎ»з”ЁиҝҷҝUҚж–№ејҸпјҢе…ёеһӢзҡ„зәҰе®ҡдјҳдәҺй…Қҫ|®еҺҹеҲҷгҖӮеҪ“з„УһјҢеңЁdbutilsйҮҢдҪ ж„ҝж„ҸдәҢз§Қеӯ—ж®өеҗҚйғҪдёҖж ·д№ҹж— еҸҜеҺҡйқһгҖ?br /> ҫ~әзӮ№еQҡBeanProcessorжҳҜдёҚж”ҜжҢҒе…ҢҷҒ”жҹҘиҜўзҡ„пјҢжүҖд»ҘдёҠйқўзҡ„ж–№ејҸд№ҹеҸӘиғҪеұҖйҷҗдәҺеҚ•иЎЁзҡ„иқ{жҚўпјҢҳqҷзӮ№һ®ЧғёҚеҰӮmyBatisе’ҢHibernateеQҢеҪ“然用ҳqҷдәҢдёӘе°ұеј•е…ҘдәҶдёҖдәӣеӨҚжқӮжҖ§пјҢеҰӮдҪ•жқғиЎЎйңҖиҰҒиҮӘе·ЮpЎЎйҮҸпјҢе“ӘдёӘз”Ёеҫ—еҘҪйғҪдёҖж —чҖӮжң¬дәәе°ұдёҚе–ңӢЖўmyBatisйӮЈз§ҚжҠҠSQLеҶҷеҲ°XMLдёӯзҡ„ж–№ејҸеQҢи§ҒҳqҮеӨӘеӨҚжқӮзҡ„SQLжңҖҫlҲеңЁXMLйҮҢйқўеҸҳеҫ—йқўзӣ®е…ЁйқһеQҢеҰӮжһңжҳҜжҺҘжүӢеҲ«дқhзҡ„д»Јз ҒпјҢжҳҜеҫҲз—ӣиӢҰзҡ„пјҢиҖҢдё”дҪ ж— жі•йҒҝе…ҚеҸӘдҝ®ж”№XMLиҖҢдёҚж”№JavaеQҢ既然дәҢиҖ…йғҪиҰҒж”№еQҢйӮЈзӣҙжҺҘеҶҷJavaйҮҢеҸҲжңүд»Җд№ҲеҢәеҲ«пјҹҪҺҖеҚ•е°ұжҳҜзҫҺгҖӮж јејҸе’ҢжіЁйҮҠеҶҷеҘҪдёҖзӮ№еҗҢж ·еҫҲе®ТҺ(guЁ©)ҳ“зҗҶи§ЈеQ?
]]>
1public Map<String, Object> toMap(ResultSet rs) throws SQLException {
2 Map<String, Object> result = new CaseInsensitiveHashMap();
3 ResultSetMetaData rsmd = rs.getMetaData();
4 int cols = rsmd.getColumnCount();
5
6 for (int i = 1; i <= cols; i++) {
7 result.put(rsmd.getColumnName(i), rs.getObject(i));
8 }
9
10 return result;
11 }
CaseInsensitiveHashMapжҳҜdbutilsиҮӘе®ҡд№үзҡ„дёҖдёӘMapеQҢеҝҪз•Ҙй”®еӨ§е°ҸеҶҷзҡ„K-Vеӯ—е…ёеQҢдҪҶжҳҜkeyдҪҝз”Ёзҡ„жҳҜResultSetMetaData.getColumnName()еQҢжҲ‘жғій—®йўҳеӨ§жҰӮеҮәеңЁиҝҷйҮҢпјҢдәҺжҳҜи®ӨзңҹҫҳЦMәҶҫҳ»javaзҡ„apiж–ҮжЎЈеQҲејҖеҸ‘еҒҡд№…дәҶе®ТҺ(guЁ©)ҳ“йҒ—еҝҳеҹәзЎҖеQүпјҢжһң然еQҢеҺҹжқ?strong>getColumnName()жҳҜпјҡиҺ·еҸ–жҢҮе®ҡеҲ—зҡ„еҗҚз§°еQ?/span>иҖҢasе…ій”®еӯ—д№ӢеҗҺпјҢдҪҝеҲ—еҗҚз§°еҸҳжҲҗз”ЁдәҺжҳ„ЎӨәзҡ„ж„Ҹд№үпјҢҳqҷдёӘж—¶еҖҷеә”иҜҘдӢЙз”?strong>getColumnLabel()еQ?span style="color: #339966">иҺ·еҸ–з”ЁдәҺжү“еҚ°иҫ“еҮәе’ҢжҳҫҪCәзҡ„жҢҮе®ҡеҲ—зҡ„е»шҷ®®ж ҮйўҳгҖӮеҫҸи®®ж ҮйўҳйҖҡеёёз”?SQL public Map<String, Object> toMap(ResultSet rs) throws SQLException {2
Map<String, Object> result = new CaseInsensitiveHashMap();3
ResultSetMetaData rsmd = rs.getMetaData();4
int cols = rsmd.getColumnCount();5
6
for (int i = 1; i <= cols; i++) {7
result.put(rsmd.getColumnName(i), rs.getObject(i));8
}9
10
return result;11
}AS еӯҗеҸҘжқҘжҢҮе®ҡгҖӮеҰӮжһңжңӘжҢҮе®ҡ SQL ASеQҢеҲҷд»?getColumnLabel ҳq”еӣһзҡ„еҖје°Ҷе’?getColumnName ж–ТҺ(guЁ©)і•ҳq”еӣһзҡ„еҖјзӣёеҗ?/span>гҖӮиҮӘе·ұжүӢеҠЁиҜ•йӘҢдәҶдёҖдёӢпјҢжһң然еҰӮжүҖж–ҷпјҢй—®йўҳһ®ұеҮәеңЁиҝҷйҮҢгҖ?br />
жүҖд»Ҙе‘ўеQҢеҰӮжһңжғіиҰҒdbutilsеңЁиҮӘеҠЁиқ{жҚўMapеҸҠMapListж—¶иғҪиҜҶеҲ«иҒҡеҗҲеҮҪж•°зҡ„еҲ—еҗҚпјҢйӮЈд№ҲжңҖеҘҪзҡ„еҒҡжі•һ®ұжҳҜйҮҚиқІҳqҷз§Қж–№ејҸеQҢжҮ’дёҖзӮ№зҡ„еQҢдҪ һ®ұе№Іи„Ҷдҝ®ж”№дёҠйқўйӮЈҢDөд»Јз ҒпјҢи®©е®ғеҲӨж–ӯжҳҜеҗҰдҪҝз”ЁдәҶasе…ій”®еӯ—гҖӮдёӘдәәжҡӮж—¶жҗһдёҚжё…жҘҡе®ҳж–№дШ“д»Җд№ҲжІЎжңүиҖғиҷ‘ҳqҷдёҖжӯҘпјҢжңүж—¶й—ҙеҶҚжҖқиҖғдёҖдёӢпјҒ
]]>