* 什么是依賴注入(Dependency Injection)
* 如何保證類和依賴注入友好性
* 依賴注入有助于單元測試
閱讀全文
]]>
Elliotte Harold
(elharo@metalab.unc.edu), Adjunct Professor, Polytechnic University
26 Sep 2006
Fuzz testing is a simple technique that can have a profound effect on your code quality. In this article, Elliotte Rusty Harold shows what happens when he deliberately injects random bad data into an application to see what breaks. He also explains how to use defensive coding techniques such as checksums, XML data storage, and code verification to harden your programs against random data. He concludes with an exercise in thinking like a code cracker -- a crucial technique for defending your code.
For years, I've been astounded by the number of corrupt files that can crash Microsoft Word. A few bytes out of place and the whole application goes down in flames. On older, non-memory-protected operating systems, the whole computer usually went down with it. Why can't Word recognize when it's received bad data and simply put up an error message? Why does it corrupt its own stack and heap just because a few bits got twiddled? Of course, Word is hardly the only program that behaves atrociously in the face of malformed files.
This article introduces you to a technique that attempts to avert just this sort of disaster. In fuzz testing, you attack a program with random bad data (aka fuzz), then wait to see what breaks. The trick of fuzz testing is that it isn't logical: Rather than attempting to guess what data is likely to provoke a crash (as a human tester might do), an automated fuzz test simply throws as much random gibberish at a program as possible. The failure modes identified by such testing usually come as a complete shock to programmers because no logical person would ever conceive of them.
Fuzz testing is a simple technique, but it can nonetheless reveal important bugs in your programs. It can identify real-world failure modes and signal potential avenues of attack that should be plugged before your software ships.
Fuzz testing is a very simple procedure to implement:
- Prepare a correct file to input to your program.
- Replace some part of the file with random data.
- Open the file with the program.
- See what breaks.
You can vary the random data in any number of ways. For example, you might randomize the entire file rather than replacing just a part of it. You could limit the file to ASCII text or non-zero bytes. Any way you slice it, the key is to throw a lot of random data at an application and see what fails.
|
|
|
While you can do initial tests manually, you should really automate fuzzing for maximum effect. In this case, you first need to define the proper error behavior for the application when faced with corrupt input. (If you discover the program hasn't bothered to define what happens when the input data is corrupt, well, there's your first bug.) Then you simply pass random data into the program until you find a file that doesn't trigger the proper error dialog, message, exception, etc. Store and log that file so you can reproduce the problem later. Repeat.
Although fuzz testing usually requires some manual coding, there are tools that can help. For example, Listing 1 shows a simple Java? class that randomly modifies a certain length of a file. I usually like to start fuzzing somewhere after the first few bytes because programs seem more likely to notice an early mistake than a later one. (You want to find the errors the program doesn't check, not the ones it does.)
Listing 1. A class that replaces part of a file with random data
import java.io.*;
import java.security.SecureRandom;
import java.util.Random;
public class Fuzzer {
private Random random = new SecureRandom();
private int count = 1;
public File fuzz(File in, int start, int length) throws IOException
{
byte[] data = new byte[(int) in.length()];
DataInputStream din = new DataInputStream(new FileInputStream(in));
din.readFully(data);
fuzz(data, start, length);
String name = "fuzz_" + count + "_" + in.getName();
File fout = new File(name);
FileOutputStream out = new FileOutputStream(fout);
out.write(data);
out.close();
din.close();
count++;
return fout;
}
// Modifies byte array in place
public void fuzz(byte[] in, int start, int length) {
byte[] fuzz = new byte[length];
random.nextBytes(fuzz);
System.arraycopy(fuzz, 0, in, start, fuzz.length);
}
}
|
|
|
|
Fuzzing the file is easy. Passing it to the application is normally not much harder. Scripting languages like AppleScript or Perl are often the best choice for writing this part of the fuzz test. For GUI programs, the hardest part can be recognizing whether the application indicated the right failure mode. Sometimes it's simplest to have a human sit in front of the program and mark each test as pass or fail. Be sure to individually name and save all the random test cases generated so you can reproduce any failures you detect with this procedure.
Solid code follows this fundamental principle: Never accept external data into your program without verifying it for consistency and sanity.
If you read a number from a file and expect it to be positive, check that it is before further processing with that number. If you expect a string to contain only ASCII letters, be sure that it does. If you think a file contains an integral multiple of four bytes, then check that. Never assume that any characteristic of externally-supplied data is as you expect.
The most common mistake is to assume that because an instance of your program wrote the data out, it can read that data back in again without verifying it. This is dangerous! The data could have been overwritten on disk by another program. It could have been corrupted by a failing disk or a bad network transfer. It could have been modified by another program that had a bug. It could even have been deliberately modified in an effort to subvert your program's security. Assume nothing. Verify everything.
Of course, error handling and verification is ugly, annoying, inconvenient, and thoroughly despised by programmers the world over. Sixty years into the computer age, we still aren't checking basic things like the success of opening a file or whether memory allocation succeeds. Asking programmers to test each byte and every invariant when reading a file seems hopeless -- but failing to do so leaves your programs vulnerable to fuzz. Fortunately, help is available. Properly used, modern tools and technologies can significantly alleviate the pain of hardening your applications. In particular, three techniques stand out:
- Checksums
- Grammar based formats such as XML
- Verified code such as Java
The simplest thing you can do to protect against fuzzing is add a checksum to your data. For example, you can sum up all the bytes in the file and then take the remainder when dividing by 256. Store the resulting value in one extra byte at the end of the file. Then, before trusting the input data, verify that the checksum matches. This very simple scheme reduces the risk of undetected accidental failure to about 1 in 256.
Robust checksum algorithms like MD5 and SHA do much more than simply take the remainder when dividing by 256. In the Java language, the java.security.DigestInputStream and java.security.DigestOutputStream classes provide convenient means for attaching a checksum to your data. Using one of these checksum algorithms reduces the chance of accidental corruption to less than one in a billion (though deliberate attacks are still a possibility, as you'll see).
Storing your data in XML is an excellent way to avoid problems with data corruption. While XML was originally intended for Web pages, books, poems, articles, and similar documents, it has found broad success in almost every field ranging from financial data to vector graphics to serialized objects.
|
|
|
The key characteristic that makes XML formats resistant to fuzz is that an XML parser assumes nothing about the input. This is precisely what you want in a robust file format. XML parsers are designed so that any input (well-formed or not, valid or not) is handled in a defined way. An XML parser can process any byte stream. If your data first passes through an XML parser, all you need to be ready for is whatever the parser can give you. For instance, you don't need to check whether the data contains null characters because an XML parser will never pass you a null. If the XML parser sees a null character in its input, it throws an exception and stops processing. You still need to handle this exception of course, but writing a catch block to handle a detected error is much simpler than writing code to detect all possible errors.
For further security you can validate your document with a DTD and/or a schema. This checks not only that the XML is well-formed, but that it's at least close to what you expect. Validation will rarely tell you everything you need to know about a document, but it makes it easy to write a lot of simple checks. With XML, it is very straightforward to strictly limit the documents you accept to the formats you know how to handle.
Still, there will be pieces of the code you can't validate with a DTD or schema. For example, you can't test whether the price of an item in an invoice is the same as the price for that item in your inventory database. When receiving an order document from a customer that contains the price, whether in XML or any other format, you should always check to make sure the customer hasn't modified the price before submitting it. However, you can implement these last checks with custom code.
One characteristic that makes XML so fuzz-resistant is that the format is carefully and formally defined using a Backus-Naur Form (BNF) grammar. Many parsers are built directly from this grammar using parser-generator tools such as JavaCC or Bison. The nature of such a tool is to read an arbitrary input stream and determine whether or not it satisfies the grammar.
If XML is not appropriate for your file format, you can still get the robustness of a parser-based solution. You'll have to write your own grammar for the file format, however, and then develop your own parser to read it. Rolling your own is a lot more work than just using an off-the-shelf XML parser. Nonetheless, it is a far more robust solution than simply loading the data into memory without formally verifying it against a grammar.
Many of the crashes resulting from fuzz testing are direct results of memory allocation mistakes and buffer overflows. Writing your application in a safe, garbage-collected language that executes in a virtual machine such as Java or managed C# eliminates many potential problems. Even if you're writing your code in C or C++, you should use a reliable garbage-collection library. In 2006, no desktop or server programmers should be managing their own memory.
The Java runtime features an additional layer of protection for its own code. Before a .class file is loaded into the virtual machine, it is verified by a bytecode verifier and optionally a SecurityManager. Java does not assume that the compiler that created the .class file was non-buggy or behaving correctly. The Java language was designed from day one to allow the execution of untrusted, potentially malicious code in a secure sandbox. It doesn't even trust the code it, itself, has compiled. After all, someone could have changed the bytecode manually with a hex editor to attempt to trigger a buffer overflow. We should all have this level of paranoia about input to our programs.
|
|
|
Each of the previous techniques goes a long way toward preventing accidental damage. Taken together and implemented properly, they reduce the chance of undetected, unintentional damage to essentially zero. (Well, not quite zero, but of the same order of magnitude as the chance of a stray cosmic ray causing your CPU to add 1+1 and come up with 3.) But not all data corruption is unintentional. What if someone is deliberately introducing bad data in the hopes of breaching your program's security? Thinking like a cracker is the next step in defending your code.
Switching back to an attacker's mode of thinking, let's suppose the application you're attacking is written in the Java programming language, uses non-native code, and stores all external data in XML, which is thoroughly validated before acceptance. Can you still attack it successfully? Yes, you can. A naive approach that randomly changes bytes in the file is unlikely to succeed, however. You need a more sophisticated approach that accounts for the program's built-in error-detection mechanisms and routes around them.
When you're testing a fuzz-resistant application, you can't do pure blackbox testing, but with some obvious modifications, the basic ideas still apply. For example, consider checksums. If a file format contains a checksum, then you simply modify the checksum so it matches your random data before passing the file to the application.
For XML, try fuzzing individual element content and attribute values rather than selecting a random section of the bytes in the document to replace. Be careful to replace data with legal XML characters rather than random bytes, because even a hundred bytes of random data is almost certain to be malformed. You can change element and attribute names too, as long as you're careful to make sure the resulting document is still well formed. If the XML document is checked against a very restrictive schema, you'll need to figure out what the schema isn't checking to determine where you can productively fuzz.
A really restrictive schema combined with code-level verification of the remaining data may leave you with no room to maneuver. As a developer, this is what you should strive for. The application should be able to process meaningfully any stream of bytes you send it that it does not reject as de jure invalid.
|
|
|
Fuzz testing can demonstrate the presence of bugs in a program. It doesn't prove that no such bugs exist. Nonetheless, passing a fuzz test greatly improves your confidence that an application is robust and secure against unexpected input. If you've fuzzed your program for 24 hours and it's still standing, then it's unlikely that further attacks of the same sort will compromise it. (Not impossible, mind you, just less likely.) If fuzz testing does reveal bugs in your programs, you should fix them. Rather than plugging random bugs as they appear, it may be more productive to fundamentally harden the file format through the judicious use of checksums, XML, garbage collection, and/or grammar-based file formats.
Fuzz testing is a crucial tool for identifying real errors in programs, and one that all security-aware and robustness-oriented programmers should have in their toolboxes.
Learn
-
In pursuit of code quality
: Want more? There's an entire developerWorks series devoted to today's code testing techniques.
- "The Java XML validation API" (Elliotte Rusty Harold, developerWorks, August 2006): Find out what the Java 5 XML validation API can do for you.
- "Test before you code" (Gary Pollice, developerWorks, June 2004): A useful overview of test-first programming concepts and methods.
- "Macintosh stories: Monkey Lives" (Andy Hertzfeld, Folklore): Describes fuzz testing the first Macintosh (though the term had yet to be invented back then).
- "An Empirical Study of the Reliability of UNIX Utilities" (B.P. Miller, L. Fredriksen, B. So; Communications of the ACM 33, December 1990): First used the word fuzz to describe random data-based testing.
- "Fuzz Testing of Application Reliability": The original fuzz testing Web site.
- "Obscuring XML" (Elliotte Rusty Harold, Extreme Markup Languages 2005): This paper introduced a tool for randomizing XML data while maintaining well-formedness. The goal then was to aid in bug reporting, but the same techniques could be used to fuzz test XML.
-
Java I/O, Chapter 12
(Elliotte Rusty Harold, O'Reilly, 2006): Discusses the calculation of checksum in Java using the
DigestInputStreamandDigestOutputStreamclasses. -
Wikipedia: Fuzz testing
: A customarily excellent entry.
-
The Java technology zone
: Hundreds of articles about every aspect of Java programming.
-
developerWorks technical events and webcasts
: Keeping you current.
Get products and technologies
-
Fuzzers: The ultimate list
: Various open source fuzz testing tools collected by Jack Koziol.
Discuss
- Improve Your Code Quality : Andrew Glover brings his considerable expertise as a consultant focused on improving code quality to this moderated discussion forum.
|
|
||
|
|
|
Elliotte Rusty Harold is originally from New Orleans, to which he returns periodically in search of a decent bowl of gumbo. However, he resides in the Prospect Heights neighborhood of Brooklyn with his wife Beth and cats Charm (named after the quark) and Marjorie (named after his mother-in-law). He's an adjunct professor of computer science at Polytechnic University, where he teaches Java and object-oriented programming. His Cafe au Lait Web site has become one of the most popular independent Java sites on the Internet, and his spin-off site, Cafe con Leche, has become one of the most popular XML sites. His most recent book is Java I/O, 2nd edition. He's currently working on the XOM API for processing XML, the Jaxen XPath engine, and the Jester test coverage tool. |

]]>
SCA規范和SDO規范將成為專門提供編程模型的標準,開發人員可以在創建Web服務時使用SCA和SDO規范,盡管此時SCA規范和SDO規范還沒有完全成熟,達到標準水平,但是2007年他們一定能夠成為SOA標準。
2006年7月,希望曾到來過,有消息表明SCA規范和SDO規范有望在去年圣誕節時正式成為SOA標準。開放SOA(OSOA)組織,一個由多家提供商包括IBM、 BEA Systems Inc、和Oracle Corp等公司自發成立的組織,目前正在致力于SCA和SDO規范晉升成為SOA標準的工作。去年夏天OSOA組織預測SCA和SDO規范將于2006年底正式成為SOA標準。現在看來,這似乎會是2007年的某一天。
在回復詢問關于SCA和SDO規范更新情況的電子郵件中,IBM 的SOA合作伙伴、項目經理、規范編寫人之一Graham J Barber這樣答到:“我們希望在2007年第一季度將SCA規范的主要部分作為第一版推出。之后,我們希望將兩個規范與已發布的V2.1 SDO規范放到一起,申請成為SOA標準。”
不論SCA規范是否已經完善或是否能成為SOA標準,SCA都是已被廣大提供商應用于產品的SOA技術。甲骨文工具與中間件副總裁兼首席架構師Ted Farrell說,SCA規范是一種實用的技術。目前甲骨文的WebCenter Suite 就使用了SCA規范,使開發人員方便開發SOA和Web 2.0項目,他說。
Rogue Wave Software,Quovadx, Inc.的一家分公司,本月初宣布開始使用SDO規范,并將SDO加入產品名稱,公司的SOA工具套裝將被稱為HydraSDO。
甲骨文的Farrell說,正式發布SOA標準是一件好事,他希望正式標準盡早出臺,不過他真正關心的是在工具和應用程序開發中如何有效地使用SCA/SDO技術。
“我們對SCA何時成為標準十分感興趣,現在我們叫它SCA偽標準,”他說。“我們不希望有所有權問題,因為采用開放結構會有許多好處。”
但是Farrell說,最重要的是,一個標準需要適用于應用程序,并有廣泛的行業支持。
“SCA規范更趨于點對點模式,”他說。“IBM和BEA在推廣一些標準的時候受到一些挫折,所以他們開始成立開放SOA組織。甲骨文以及其他一些提供商加入了該組織。盡管它不是以前的標準組織,但是它在不斷發展,不斷進步,其實我們最為企業軟件提供商真的希望把這些規范變為一種軟件標準,希望能夠為SOA的發展獻出一份力量。”
Farrell說SCA/SDO規范似乎在走業務處理執行語言(BPEL)的發展道路。業務處理執行語言(BPEL)最初由IBM和微軟共同努力開發出第一個版本,之后BEA、 SAP AG和 Siebel Systems先后使用BPEL,現在甲骨文也開始使用BPEL。2003年,這些提供商正式將BPEL提交給開放標準組織OASIS標準化,2003年4月6日,OASIS組織用WS-BPEL的名字吸納了BPEL標準。2003年5月3日,SAP/SIEBEL加入并共同推出WS-BPEL1.1版。2003年5月16日, WS-BPEL2.0的草案也在當時被納入議事日程。
SOA項目的開發人員和架構師應該從現在開始就接觸這些規范,不應該等著它們成熟成為正式標準,Harte-Hanks (HHS) 公司Aberdeen Group 企業集成副總裁Peter S. Kastner說。他認為SOA的工作人員都應該熟悉這些規范,并促進它們的發展。
“在未來幾年,將迅速推出一批與SOA相關的標準,所以對用戶來說,最好簡要地使用這些標準,從某種意義上說,這是可能的,”他說。“基本上,變化是不可避免的,所以勇于面對變化,適應變化。如果要等到所有標準都完善,之后出臺,我像那你會瘋掉,這大概需要十年的時間。”
]]>
UML在版本升級到2.0以后,原來的UML工具的大哥大Rational從風行到被收購,現在幾乎沒有了聲音。
建模工具沒有太顯著的變化,倒是開發工具出現了從原來的百花齊放到現在只有少數巨頭競爭的局面。其中最耀眼的當屬誕生于IBM,后在開源社區得到快速發展的Eclipse,目前它已進入嵌入式開發領域。另一個就是微軟攜其強大財力與人力打造的VSTS開發工具平臺,它將成為可以貫穿整個軟件開發生命周期和扮演不同的角色的平臺,在最近也有不俗表現。此外還有Sun的NetBean IDE開發工具和BEA的WorkShop開發工具等。
這些開發工具平臺都可以進入整個軟件開發生命周期,并且可以在其上進行各種不同應用的開發,說白了就是兼容性足夠強。
開發與應用
不論使用何種工具,真正最活躍的仍然是應用與開發。JavaEE5的發布,EJB3.0標準的落地,標注取代部署描述符,實體即是POJO等,也許這些改變對Java進行輕量級應用開發的復雜性會有所改變。在軟件開發界最流行的框架,包括Struts、Spring、Hibernate等,這些分布在Web容器和EJB容器中的各種應用框架變得讓人眼花繚亂,要選擇最適合自己的看來越來越困難了。由于JavaEE5的發布,著名的JBoss應用服務器的結構也發生了較大的變化。微軟.NET的2.0平臺和下一代操作系統Window Vista桌面版發布,同時提供給廣大用戶的WinFX平臺,不僅給開發者而且給用戶帶來了挑戰。
由Ruby和Retail的聯姻,AJAX的新瓶裝舊灑,再加上Web2.0應用概念上的炒作,腳本語言、Web開發與應用在今年著時火了一把,因此今年搭上順風車的PHP也要求能夠同Java應用交互,克服語言與平臺的障礙。
桌面與企業服務器的開發應用也有相當發展,中間件市場、數據庫、ERP等各種應用隨著SOA得到市場的認可,各種技術與應用以及SOA的產品也逐漸多了起來。隨著3G時代的到來,智能手機占有率的提升,手機平臺的開發市場正進一步;不僅是手機,數字電視、各種電器和消費類電子產品的智能化發展也促使嵌入式領域的開發發生了很大變化,如:IP機頂盒、基于GPS全球定位系統的設備、工業自動化和醫療設備等,商業平臺與開源Liunx平臺共存。
開源、互聯網及其他
開源軟件逐漸挺進企業主流應用,不僅是Linux,還有Boss中間件、Mysql數據庫、EnterpriseDB數據庫等,而且還有各種應用軟件,包括:Open office辦公套件、Firefox瀏覽器、ERP、CRM等等。開源力量的加入也使得非常多的應用進入到微軟平臺上,在微軟的.Net平臺上也出現了大量的開源應用軟件。
互聯網最大的應用與技術就是搜索、軟件服務化(Software as a Service)。不管是通用搜索還是行業垂直搜索,不管是互聯網搜索還是企業搜索,都已經不僅針對文本而且開始向音視頻搜索發展了。
最后不要忘了,由于人們對應用要求的提高,測試在這幾年顯得越來越重要了,測試工具與測試理論都有很大發展,這一點也值得關注。
手機軟件開發將與PC趨同
王權平
資深程序員,供職于威盛電子(中國)有限公司,從事GSM/GPRS芯片組的開發,主要工作包括協議軟件設計、開發與測試,以及智能手機平臺通信中間件的設計與開發。
2006年出現了很多叫好也叫座的手機產品,這些成功手機的背后,都明顯地揭示出了手機軟件開發技術的若干發展趨勢。2007年手機軟件技術將繼續迅速發展,無論單處理器平臺或是雙處理器平臺,網絡應用和多媒體應用都將是主要的開發方向,而C++和Java將是首選的開發語言。
未來,傳統的單處理器手機平臺仍將在低價手機和特色手機市場上保持不可替代的優勢。其軟件通常都由芯片廠商和手機設計公司來提供,除了J2ME平臺外,缺乏開放和標準的API是其固有的缺陷。因此幾乎沒有來自第三方的原生的面向其處理器和編譯平臺優化的軟件,用戶自行擴展的能力較差。展望未來,除了集成更多的應用軟件(如電子郵件、電子書和多媒體播放程序等)外,單處理器平臺上的軟件開發工作主要集中在新硬件模塊的驅動程序以及圖形用戶界面的創新和提高上。就開發語言而言,C和C++仍然是首選;在底層通信軟件尤其是協議棧的實現上,C語言仍將繼續居統治地位;當然在驅動程序中,匯編語言也是不可或缺的。單處理器平臺上第三方開發人員的開發空間在于J2ME平臺,但是各個解決方案對Java語言支撐能力的差異,使得Java程序很難達到真正的與平臺無關。不過,隨著硬件能力的與提高和Java虛擬機的改善,特別是硬件級Java加速和ARM平臺Java優化指令等特性的引入,可以預料J2ME將會成為單處理解決方案的基礎軟件平臺。
雙處理器平臺由運行通信協議的基帶處理器和運行用戶界面程序的應用處理器組成,是智能手機的基礎平臺。未來智能手機平臺的軟件開發中,中間件和應用程序都有很大的發展空間和需求。中間件主要包括圖形庫和通信庫兩部分。圖形庫重點在于提供更加華麗和友善的用戶界面,增強用戶的操作體驗,據稱WinCE6.0即將提供Vista風格的界面;3D加速將是繼2D加速后的第二個亮點;另外,圖形庫也將重點支持硬件級的多媒體加速技術,從而支持包括移動音頻和視頻,特別是手機電視的應用。通信庫部分將重點在統一的框架內整合各種廣域、局域乃至個域通信技術。應用程序部分,網絡應用將會是2007年的發展重點。就開發技術而言,J2ME在智能手機上的性能優于單處理平臺,因此筆者看好基于J2ME平臺的手機游戲和網絡應用;而基于C++的網絡編程和多媒體編程仍將繼續是Symbian平臺、WinCE平臺,以及Linux上Qt平臺的的主要開發領域;另外PC平臺上的基礎軟件組件,如數據庫技術等,將逐漸移植到手機平臺上,提供其嵌入式的版本,以適應手機平臺的硬件和軟件限制。但是由于三大平臺存在的巨大差異,軟件的可移植性將成為一個重要的問題。
核心觀點
隨著中間件的加強,手機應用軟件開發將逐漸與PC趨同,將出現大量的個人軟件開發者和第三方軟件開發商,手機軟件產業勢必會有很大的發展。
注重測試需求 做好流程建設
戴金龍
注冊PMP,GB/GJB/ISO/CMMI內審員。原嫦娥工程地面應用系統質量組專家。歷任某外企測試技術經理、項目經理及運營經理。對當代軟件測試理論及工程實踐有較好的領悟。
當前,測試作為一項職業吸引了越來越多的優秀人才;測試作為控制軟件質量的有效手段,融入到了越來越多企業高層的管理理念中;測試作為一門學科,獲得了前所未有的壯大。但在測試技術蓬勃發展的另一方面,測試行業也在迅速地積累著各種問題,在接下來的一年里某些隱藏的問題可能會表現得很顯著。
第一個問題是如何讓測試更有效地鍥入到不規范的軟件開發過程中。提出這個問題恐怕會有不少人大吃一驚:這類企業為什么不先規范軟件的開發過程呢?這是不是一個偽問題?其實,目前有不少軟件企業都處在這種狀態。但這些企業的管理層并不承認自己的開發過程不規范,反而認為這是一種靈活的、有個人特色的高效管理。這樣的氛圍造成軟件質量低下自是意料中的事情。
即使企業管理層了解到測試是解決質量問題的有效途徑,實施軟件測試也是需要代價的。目前的測試學科所提供的技術、流程、管理及方法論都是假設是在良好的(至少規范的)開發過程、管理氛圍及測試環境中實施的,并沒有提供在不規范軟件開發過程中做測試的解決方案,這樣就出現了所謂“理論”與“實踐”的偏差。解決的辦法有兩個:一種是變革企業文化,規范開發過程,建立測試所需的相關環境,從而實施規范、嚴格、有序的軟件測試;另一種就是拓展測試理論,針對不規范開發過程的特點,找到彌補、折衷的解決辦法。根據筆者對國內軟件企業的了解,后者將是今后一段時間國內軟件企業關注的熱點話題。
第二個問題是如何清晰地定義軟件測試需求,使測試工作目標明確、有的放矢。這個問題是以前的測試學科沒有回答清楚的,非常需要深入研究,它將會是今后若干年的研究熱點。可能有讀者會感到費解:測試需求不就是軟件需求嗎?其實不然。軟件需求用于指導后續設計的展開。而測試需求則是直接源自于客戶的質量要求。測試需求的源頭非常繁雜,如何刪繁就簡,拿捏得當,目前沒有現成的方法,仍需要做大量理論研究和實踐探索。
第三個問題是如何規范軟件測試流程以持續提高測試團隊的績效。這個問題目前已有一些答案。如“制定測試計劃-設計測試-執行測試-測試分析與總結”等等。從執行的角度而言,這類粗略的階段劃分或許已經夠用,沒有進一步研究的必要。但對于控制測試過程而言,對于測試服務型企業通過CMMI認證而言,尤其是對于改進軟件測試過程而言,幾乎是沒有幫助的。
核心觀點
在測試技術蓬勃發展的另一方面,測試行業也在迅速地積累著各種問題。
網絡安全軟件開發趨勢
李洋
中國科學院計算技術研究所博士,資深程序員。從事計算機網絡信息安全領域的研發工作,曾參與“國家自然科學基金”、“國家863重大專項”、“國家242信息安全計劃”、“國家973計劃”等多項國家重點項目、信息安全系統和企業信息系統的研發工作。
從當前國際上安全產品的研發情況來看,以防火墻和IDS為主導,以密碼技術為基礎的產品已經取得了飛速的發展,并在實際應用中發揮了很大的效應,使得網絡安全產品的研究及應用工作不斷向前推進。2007年,對于網絡安全軟件開發人員來說,如下幾項新的技術值得大家期待:
1.基于開源軟件的開發技術
以Linux為代表的開源軟件及其開發模式已經深入人心。網絡安全軟件中最為著名的就是輕量級的入侵檢測系統Snort,它已成為眾多安全廠商和科研院校研發的重要參照物。縱觀網絡安全軟件的發展趨勢,以優秀的開源軟件為基礎進行研發已成為網絡安全界的首選技術途徑。
2.嵌入式安全開發技術
隨著移動計算和無線網絡的普及,以及普適計算概念的提出和應用,移動、無線和無處不在的計算已成為新世紀IT的絕對熱點。這些需求都要求在上述條件下進行信息處理和計算,因而以J2ME為代表的嵌入式開發技術也成為很大看點。
尤為值得關注的是,人們在獲得上述便利的同時,也在經受著自己的隱密數據隨時有可能被竊取和破壞的威脅。那么,如何在當前的嵌入式技術當中綜合采用密碼理論、PKI基礎架構以及其他信息安全技術來提高嵌入式系統的安全性,為未來輕量級的嵌入式計算保駕護航,也必將成為網絡安全工作者和軟件開發人員關注的一個熱點問題。
3.高性能計算服務開發技術
網絡帶寬的日益增長和單機處理能力已經極不對稱。諸如早期的防火墻、IDS等都已經不能滿足現實的需求。
因此,采用并行處理技術以及研究和開發高性能網絡協議處理技術來緩解上述問題帶來的壓力是不錯的選擇。并且,隨著64位計算的到來,如何在該硬件平臺上進行并行開發、編譯等,都是網絡安全軟件研發人員期待和需要解決的問題。值得期待的是,當今的UTM(統一威脅管理)技術試圖在上述各方面取得突破,建立一套高性能、高可靠、完善的網絡威脅防范機制,我們拭目以待。
4.可信編程技術
對于安全要求較高的場合,可信計算平臺能夠為用戶提供更加有效的安全防護。而據統計,在網絡安全領域,80%以上的網絡威脅和漏洞來源于系統自身的Bug,而這些Bug則來源于設計思路以及程序實現。那么,在積極防御外來攻擊的同時,提高網絡安全軟件研發人員自身編程的可靠性,軟件開發平臺在軟件編程中可能出現漏洞(比如最常見的緩沖區溢出等)的地方進行提醒和標注,就可以極大地減少程序實現的硬傷。我們不妨借用可信計算的名號稱其為可信編程技術,相信也將是軟件研發人員關心的技術,不但可以提高軟件可靠性,更能避免用于查找大量重復出現的系統Bug所需的人力和物力。
核心觀點
基于開源軟件的開發技術、嵌入式安全開發技術、高性能計算服務開發技術、可信編程技術將是未來網絡安全軟件開發的四大趨勢。
降低開發復雜性
程勇
Java開放源碼軟件咨詢顧問,Huihoo.org開源軟件社區共同創始人,北京中流科技有限公司CTO。
Java技術的發展已經走過11個年頭,在企業級應用開發領域占領主導地位的JavaEE技術也伴隨著Java自身的演變,在2006年發生了許多新的變遷。 隨著系統開發復雜度的上升,需要一種更好的解決方案來分解系統的復雜,并簡化應用開發的過程。基于眾多的因素,選擇企業應用開發的架構平臺時都需要考慮很多約束,它必須最小化對應用開發本身的影響。因此,一個好的技術平臺和應用框架應該具備如下特性:提供應用開發的一致性;提供高端和低端特性;提供管理逐步增長的應用系統的具體方法;為高級開發人員提供指導;能夠使不同框架的特性和優點集成到一起進行工作;能夠快速進行應用開發,保證產品按市場的需求發布;能夠降低項目開發的風險,提升企業的投資回報。
由此,我們不難發現,現在大量涌現的新技術體系和框架,都是在朝著簡化應用開發的方向而努力,這些技術包括:
● AJAX AJAX并非一種編程語言,它是使用XHTML或HTML,JavaScript以及XML來建立互動網絡應用程序的一種模式。
● 腳本語言 Ruby的發展,使得在Java 語言中使用動態機制成為可能,使用Ruby的動態機制,用戶能夠改變腳本類的定義。這些Ruby對象允許直接使用方法管理它的狀態和行為。
● 應用框架 以Spring為代表JavaEE應用框架是在JavaEE技術體系之上快速構建應用的支撐平臺,應用框架通過整合的技術架構,將眾多的優秀開源框架融合在一起,為應用開發提供了一個完整的技術解決方案。
● JavaEE 5.0 JavaEE 5.0 是新一代的Java EE技術規范,其中包括JSF、EJB 3.0等十多項全新的技術體系。它的多項新特性為JavaEE應用開發帶來了更多的便利。
核心觀點
選擇企業應用開發的架構平臺時都需要考慮很多約束,它必須最小化對應用開發本身的影響。
工作流: 國內國際兩極分化
胡長城
網名“銀狐999”,就職于TIBCO。國內J2EE開源應用的支持者,有過6年的J2EE應用和產品開發及架構經驗,是huihoo開源組織的成員。
與眾多新技術相比,工作流的知名度也許會小一些,但工作流也一直處于不斷創新之中。所不同的是,在這個領域新技術的應用是被隱藏在應用理念和架構體系之下的。對于工作流的發展趨勢,這里分開兩條線來闡述。
第一條線就是單純從工作流技術應用的發展趨勢來探索。在這方面國際上應用水平已經遠超越國內,這就是這兩年的龍卷風—— BPM(Business Process Management)。很多國際化的大企業已經把BPM定位于一種解決方案。在這一整套解決方案中,工作流技術已經成為流程的服務,圍繞這個服務,有各種模塊和應用相輔助。BPM解決方案儼然成為一種參考架構: 一方面是以SOA為主導的技術架構,另一方面則包含了一整套的服務。
實際上,BPM的發展是很多年的流程和工作流發展的必然結果。在這個領域的供應商有的由早期的工作流廠商發展而來,如Staffware公司(現已經被Tibco收購); 有的由早期的EAI提供商發展而來,如Tibco; 有的由應用服務器提供商發展而來,如BEA等。在它們的BPM藍圖中有很多相似之處,比如以BPEL規范闡述Business Process。
第二條線從國內工作流應用和技術趨勢來分析。這兩年已經有部分國內企業采用EAI或BPM技術進行系統整合方面的應用,但大規模地采用BPM解決方案還是很少,不過這是一個趨勢。國內目前工作流技術的應用還主要以“辦公或業務流程的人工信息化處理”為主,畢竟國內企業和政府的一個很大特征是“以人為主”,而不是“以制度化為主”。在一些集團性的企業和跨省市集中管理性的系統中,分布式流程應用逐漸顯現出來。而伴隨著國內幾年來工作流市場的積淀,早期的一些工作流廠商在尋求“流程分析和監控”方面的突破,而這方面的客戶需求也日漸多起來。但短時間內,很難由國內工作流廠商自己取得一些突破,發展起BPM產品。
上述這兩條發展線也代表了兩極分化。但第一條戰線的BPM 解決方案肯定是未來大規模應用的趨勢,雖然短時間內對國內工作流應用市場沖擊很小,但是政府和國內軟件廠商卻不應該小覷這個發展趨勢。
核心觀點
國際大廠商對工作流的研究重點是把它作為BPM的一部分,為流程服務,而國內還主要以“辦公或業務流程的人工信息化處理”為主,短時間內,國內還很難有所突破,推出自己的BPM產品。
Java走上開源之路
孟冬冬
中科軟科技股份有限公司金融保險部系統分析師、軟件架構師。9年軟件設計開發和6年項目管理經驗,精通基于J2EE架構的企業應用系統開發技術。先后在普天、中軟等多家軟件公司任系統分析員、軟件架構師及項目經理。
2006年11月13日,Sun公司宣布將Java轉為開源。預計到2007年3月份,除了一部分所有權不屬于Sun的源代碼之外,幾乎全部Java技術的源代碼都將按照GNU GPL自由軟件許可授權協議公開。Java在和.net經歷了兩年的競爭后已顯疲態,相比5歲的.net以及新生的動態語言Ruby,11歲的Java已略顯復雜臃腫,甚至在網上還有“Java將死”的論調。Sun選擇在此時將Java開源,不管是否是Sun迫不得已、在日薄西山前的最后博弈,但影響之深遠卻絕對不可小視。它引發的“蝴蝶效應”無疑會使Java技術的生命力更強,走得更遠,更可贏得在開發語言競爭中起決定作用的更多程序員的芳心,相信未來Java領域將出現更多令人驚奇的開源產品。
另外Sun還趕在圣誕節前發布了JDK的6.0 Release版本。對JDK而言,“成敗皆在應用服務器廠商”。市場占用率最大的應用服務器Weblogic8、WebSphere5成就了1.4,但也限制了JDK5的普及。在JDK5還沒有用熱時,JDK6就來了。不過,這倒也是好事,可以直接跳過JDK 5去研究JDK6的應用了。
JDK6對筆者的最大吸引力是它在JVM性能上的提升和對XML和Web服務的支持。性能方面,無論是運行時分析功能還是用戶對性能情況的反饋,尤其是在Swing方面,JDK6對JIT都有了卓有成效的提升。
一直以來,相對于微軟的.net,Java對Web Services的支持復雜得難以接受,也因此產生了優秀的Axis和XFire框架。而在JDK6下,Java程序員也能享受到這種待遇了,不用針對Web服務另外加入額外的工具,不使用任何框架也能寫出Web Services程序了。JDK6中固化了XML、Web Services的標準,如StAX、JAXB2、JSR181等。JDK 6在語法方面沒有太大改變,最明顯的就是添加了對腳本語言的支持,如JavaScript、Ruby、PHP。JDK6 中實現了JSR 223,提供了讓腳本語言來訪問Java 內部的方法。它可以在運行的時候找到腳本引擎,然后調用這個引擎去執行腳本,這個腳本API 允許程序員為腳本語言提供Java 支持。
另外在JDK6中內置實現了JDBC4支持的Derby數據庫,為測試和小型系統的發布提供了便利條件。最后,JDK 6 中對內存泄漏增強了分析以及診斷能力,當遇到Java.lang.OutOfMemory 異常的時候,可以得到一個完整的堆棧信息,并且當堆已滿時,會產生一個日志文件來記錄這個致命錯誤。
如果說談到JDK 6更多的是對未來的一種希望的話,Java full-stack(Java full-stack,意指集成了全部所需功能的Java快速開發框架)則是一種已經可以見到的東西。
很長時間以來,作為一個Java程序員,幸福的是從表現層到持久層都有眾多的框架可供選擇,痛苦的是在這些框架中挑選出適合自己的框架,而且還要付出將不同層次的框架粘合在一起的設計成本和時間,而架構的穩定性和實用性則往往取決于架構師的設計理念和經驗。Ruby on Rails的流行再一次證明了在軟件開發領域“簡約至上”的真理,它使得諸多Java開發人員把目光放到了“提供最方便好用的Java full-stack框架”上面,因此Java開源社區如雨后春筍般地出現了一批又一批的full-stack框架,如Appfuse、SpringSide、JBoss Seam、RIFE、Grails、Trails、Rife等。Java領域也從此開始走向full-stack的快速開發道路。筆者就非常喜歡國外的JBoss Seam和國內的SpringSide。
核心觀點
Sun選擇在2006年歲末將Java開源,不管是不是Sun的最后博弈,其影響絕對不可估量。從此以后,全世界所有的開發人員都可以對Java源代碼進行修改、優化、除錯,同時Java也將變為一種真正免費的技術。
網絡技術融入軟件平臺
智雨青
北京理工大學計算機碩士,8年的電信行業軟件開發經歷,曾在億陽信通、北京朗新科技公司供職,中國聯通第一版CRM的主要設計與開發者,參與聯通多個省級OSS/BSS系統的研發與實施。
2006年年初有專家曾經說過,今年軟件發展技術很有可能進入到一個無熱點時代。的確,我們非常熟悉的網絡應用技術、搜索技術、應用行業軟件技術等等,已經發展到一個非常成熟的階段,每一次升級能帶給我們的驚喜越來越少。不過,2006年雖沒大的“翻天覆地”,卻仍涌現出了不少亮點,而這些亮點極有可能會決定今后兩三年的應用潮流。
1. Web2.0
Web2.0是2003年之后互聯網的熱門概念之一。Web2.0技術主要包括: 博客、RSS、百科全書(Wiki)、網摘 、社會網絡(SNS)、P2P、即時信息(IM)等。由于這些技術有不同程度的網絡營銷價值,因此Web2.0在網絡營銷中的應用已經成為熱門領域。盡管對于究竟什么是Web 2.0還有很多的討論,但有一點可以肯定,Web2.0是以人為核心線索的網。提供更方便用戶“織網”的工具,鼓勵提供內容;根據用戶在互聯網上留下的痕跡,組織瀏覽的線索,提供相關的服務,給用戶創造新的價值,給整個互聯網帶來新的價值,才是Web2.0商業之道。
2. 嵌入式移動開發技術
嵌入式開發技術的發展推動了嵌入式操作系統跨越式發展,也成為現代及未來移動技術發展的重要保障,以微軟Windows CE系列、PalmSource公司PalmOS、Nokia公司Symbian等為代表的嵌入式操作系統已在各種移動設備上大量應用。尤為值得一提的是作為行業領先者的微軟2006年5月發布了Windows CE 6,憑借重新設計的操作系統(OS)內核架構以及增強的并發處理能力和新集成的工具集,提供了一個更加集成化的嵌入式開發環境,允許開發者將大量更為復雜的應用集成到比以往更加智能的設備中,從而提供高性能的多媒體、Web服務和無線網絡連接應用。
3. 中間件技術
隨著Internet的快速發展,中間件的定義正在走出其狹義空間,逐步形成更為廣義的內涵。其發展主要呈現出兩方面的技術趨勢: 一方面,支撐軟件越來越多地向運行層滲透,提供更強的對系統實現的支持;另一方面,中間件也開始考慮對高層設計和運行部署等開發工作的支持。而這兩個技術趨勢從本質上說正是源于軟件體系結構和軟件構件等技術的發展和應用。從廣義的角度看,中間件代表了處于系統軟件和應用軟件之間的中間層次的軟件,其主要目的是對應用軟件的開發和運行提供更為直接和高效的支撐。中間件技術已成為軟件技術的研究熱點。
4. 即時通信技術
現在即時通信市場不再只有一種聲音,騰訊、微軟、IBM、Avaya、Skype、中國移動紛紛將觸角伸向了這塊市場,誘惑這些大佬們的是即時通信市場的爆發式增長和隨之而來的豐厚利潤。而移動即時通信作為一項數據業務更是被視為未來3G時代的一大“金礦”。待3G牌照發放,捆綁于移動即時通信之上的包括彩信、彩鈴、圖片、博客、手機電視等應用都會得到充分發掘。
5. 下一代搜索技術
搜索引擎發展到今天已經增添了很多新的特征,其特色主要體現在“概念集群”和“動態分類”,它通過分析網頁之間的關聯,建立一種類似人的思維的更智能化的概念分類方式,通過模仿人的思維模式,對要查找的概念進行關鍵字聯想和分類。除了概念集群和動態分類,新一代搜索引擎還更多地體現在個性化方面,這在以前的搜索里是很難做到的。概念集群又分為大眾化概念集群和個性化概念集群,通過搜索記錄,下一代搜索技術能夠幫助每個人建立自己個性化的搜索功能,而且信息是可以分享的。
核心觀點
基于新一代網絡技術的各種應用的融合是大勢所趨,網絡新技術與軟件新技術的相互促進將為人類創造一個更為燦爛的IT世界。
互聯網將更社區化
康威
新華社高級工程師,Lotus技術專家。曾任后勤指揮學院教員,獲全軍科技進步二等獎一次、三等獎四次,2002年7月轉業到新華社技術局,是新華社多媒體數據庫系統核心成員。
互聯網的飛速發展成就了搜索引擎今天的地位,同時也推動了網絡視頻的發展,而Web 2.0又推動了全民的參與性、主動性和互動性,密切了人與人之間的聯系,由此形成了線上與線下互動的各種模式,反過來又推動了互聯網的壯大。
1. 互聯網搜索
2006年的中國互聯網搜索依然是百度、Google雙頭壟斷,百度的勢頭略有提升,垂直搜索成為耀眼的明星,移動搜索也有了一定的發展。未來搜索引擎將會更精準化、智能化、人性化、垂直化和社區化,會以更快的速度為計算機和其他智能終端用戶服務。
筆者認為,2007年的中國搜索市場將是一個分水嶺,其競爭將達到前所從未有的規模,雅虎、搜狐磨刀霍霍,微軟臥薪嘗膽,不過雙頭壟斷局面不會改變,走向國際化的百度依然會是龍頭老大,而能滿足大家特定需求、具有差異化特征的垂直搜索和生活搜索是未來的市場增長點,其搜索商業模式也會更加豐富。2007年,搜索行業的發展必將進一步促進互聯網商業模式的創新以及相關技術的提高,成為互聯網發展的重要支柱。
2. P2P流媒體
P2P流媒體行業一直都被認為是下一個可能產生井噴效應的互聯網領域。P2P體現了真正的“互聯網精神”——我為人人,人人為我,但市場是理智而殘酷的,在短暫的狂歡過后,P2P流媒體行業所面臨的問題與挑戰也逐步顯露,商業模式不清晰、盜版泛濫、國家政策不明朗等問題不得不令人深思。
網絡視頻是中國未來幾年的熱點,目前只有兩個方向可以賺大錢: 流媒體巨頭與內容大鱷的聯姻和微視頻,依靠盜版的視頻直播與共享只可能是小富即安。只有少數幾家有資金、有技術、有影響的流媒體廠商(包括門戶網站)才能獲得內容大鱷的青睞,留給眾多中小型流媒體廠商的只能是微視頻。
微視頻是指短則30秒,長則不超過20分鐘,內容廣泛,視頻形態多樣,涵蓋小電影、紀錄短片、DV短片、視頻剪輯、廣告片段等,可通過PC、手機、DV、DC、MP4等多種視頻終端攝錄或播放的視頻短片的統稱。短、快、精、大眾參與性、隨時隨地是微視頻的最大特點。微視頻規避了版權的威脅,降低了帶寬的成本,易形成社區,具有一定的贏利模式,隨著網絡融合的加快,3G和寬帶的發展,只要走專業化、特色化、差異化道路,一定大有“錢”途。
3. 互聯網社區化
互聯網社區化有三種形式: 情感的歸屬與宣泄,人們可以不受空間限制地自由溝通、發表見解、結交朋友、宣泄情感; 線上與線下的互動,互聯網使得人們能夠以最快捷的方式廣結交天下朋友,很多社區型網站都定期舉行各種線下活動; 智慧和經驗的共享,充分體現了P2P精神,人們信息需求的滿足,需要越來越多地依靠其他用戶的力量來滿足,社區化的搜索是最好的例子。
社區化的搜索能更好地滿足用戶的需求,也可以更好地發揮用戶的價值。首先他們會享受其他用戶貢獻的智慧,同時他們在自己使用的過程中幾乎不會察覺到在給整個互聯網做出貢獻。2006年7月13日正式推出以“搜索+博客”為理念的產品——百度空間,這是百度繼貼吧、知道、百科后推出的第四個社區類產品,具備個人空間、個人門戶等基本特征。這一產品的推出,不僅進一步深化了百度的社區化搜索服務,并憑借其在中國互聯網的巨大影響力,進一步推動了中國互聯網社區化發展的進程。
核心觀點
未來的互聯網將更能體現P2P精神,將更視頻化和社區化(當然文字仍會像傳統報紙一樣不可替代),同時,在互聯網的進化過程中,搜索技術將會改變人們的生活習慣。
應用推動軟件技術創新
張濤
鄭州航空工業管理學院畢業,一直從事計算機應用軟件的分析、設計、開發以及項目的實施,主持開發的軟件包括河南省縣級供電企業營銷MIS、河南省在建水利工程移民資金輔助管理系統。
今天的企業信息化面臨著更加具體的問題,比如終端數據如何快速采集傳輸; 缺乏軟件應用標準,行業應用深度不夠; 系統間交互性差、各自為戰,資源共享程度不高; 系統具有一定規模后,維護、升級困難。由于企業在這些方面的需求非常迫切,未來各個軟硬件廠商必定在這方面有所作為,基于此,筆者以為2007年以下這些技術將會有比較大的突破。
1. 數據采集自動化、便捷化
隨著MCU(多點控制單元)應用范圍的不斷擴大,以往的各類硬件終端,比如電力、燃氣、水等終端數據采集或檢測設備,已經逐步從簡單的計數、指示功能,向智能數據采集終端轉變,而且傳統裝置經過簡單的改造,也可實現終端數據的采集和存儲,這不僅讓人從數據采集的工作中解放出來,更可以通過相對廉價的手段解決采用人工采集數據所帶來的一些問題。
正是基于這種前提,微軟Office辦公套件的新成員InfoPath讓我們眼前一亮,借助它可以快速、方便地設計出具有超強表現力的電子憑單,以滿足信息采集、企業內部和企業之間的信息傳遞。更令人稱道的是,它不僅可以使用傳統的數據庫作為數據源,更可以使用XML作為數據的存儲格式,讓不同系統之間的數據交互更加暢通有效。
2. 軟件插件化、框架化
大凡用過Eclipse的程序員都會被它的靈活和開放性所打動,而目前部分行業欠缺軟件應用標準就是擺在開發商面前的諸多問題之一。類似權限管理、自定義查詢、自定義報表、組織業務功能等應用系統必備的功能,完全可以通過抽象形成框架,提高代碼重用度和穩定性。同時,采用軟件框架進行系統的開發,不僅可以讓系統分析和設計人員把主要精力放到業務模型的建立上,縮短項目周期,更可以讓系統用戶和開發商體會到系統穩定、維護方便、升級簡單的方便。
在此必須要提的是Java,如果說Java的誕生是為了網絡,那么可以說它已經不辱使命,而且在推動著網絡技術的發展,開源性使得它的追隨者們努力工作,Struts、Spring等優秀的、基于框架的作品紛至沓來,逐步讓我們脫離繁雜的技術旋渦,把時間和精力投入到業務分析領域,使軟件的插件化、框架化不再是海市蜃樓。
3. SOA
近幾年SOA(Service-Oriented Architecture,面向服務架構)概念的提出,使得用戶和軟件開發商對系統建設有了新的認識。筆者認為SOA不僅是架構模型,更是一種應用思想的體現。對于軟件功能粒度的劃分、軟件功能的部署、系統驅動模式等都會由于SOA而產生較大的影響。
企業通過應用SOA,不僅可以在成本沒有太大增幅的條件下,讓用戶使用已經成熟的組件增強B2B的有效性,還可以讓開發商最大限度地復用代碼,把軟件產品變成真正的服務。此外,SOA的實施更可以加速行業標準的制訂和執行,因為只有大家遵循同樣的標準和接口,才可能營造出業務共享和跨系統業務交互的良好氛圍。
4. 虛擬軟件
有時一些系統尤其是比較老的,對OS或DBMS有特定要求的系統,或系統在兼容性方面與新版本有差距,這時虛擬機就是最好的選擇,不僅可以節省用戶的硬件資源減少維護和管理成本,更可以讓原有應用正常運行,為應用系統的升級換代贏得時間。與VMWore相比,微軟的Virtual PC也在緊追不舍,筆者認為盡管較VMWare還有一定距離,但是無論產品孰優孰劣,最終受益的還是用戶。
核心觀點
行業特點決定行業應用,行業應用需要軟件相關技術手段提供支持,而行業應用又會引發技術的創新。
]]>
其實,Struts 1.x在此部分已經做得相當不錯了。它極大地簡化了我們程序員在做國際化時所需的工作,例如,如果您要輸出一條國際化的信息,只需在代碼包中加入FILE-NAME_xx_XX.properties(其中FILE-NAME為默認資源文件的文件名),然后在struts-config.xml中指明其路徑,再在頁面用<bean:message>標志輸出即可。
不過,所謂“沒有最好,只有更好”。Struts 2.0并沒有在這部分止步,而是在原有的簡單易用的基礎上,將其做得更靈活、更強大。
國際化Hello World
下面讓我們看一個例子——HelloWorld。這個例子演示如何根據用戶瀏覽器的設置輸出相應的HelloWorld。
- 在Eclipse創建工程配置開發和運行環境(如果對這個步驟有問題,可以參考我早前的文章《為Struts 2.0做好準備》)。
- 在src文件夾中加入struts.properties文件,內容如下: struts.custom.i18n.resources=globalMessages

Struts 2.0有兩個配置文件,struts.xml和struts.properties都是放在WEB-INF/classes/下。 - struts.xml用于應用程序相關的配置
- struts.properties用于Struts 2.0的運行時(Runtime)的配置
- 在src文件夾中加入globalMessages_en_US.properties文件,內容如下:HelloWorld=Hello World!
- 在src文件夾中加入globalMessages_zh_CN.properties文件,內容如下:HelloWorld=你好,世界!
在此想和大家分享一個不錯的編寫properties文件的Eclipse插件(plugin),有了它我們在編輯一些簡體中文、繁體中文等Unicode文本時,就不必再使用native2ascii編碼了。您可以通過Eclipse中的軟件升級(Software Update)安裝此插件,步驟如下: 1、展開Eclipse的Help菜單,將鼠標移到Software Update子項,在出現的子菜單中點擊Find and Install;
2、在Install/Update對話框中選擇Search for new features to install,點擊Next;
3、在Install對話框中點擊New Remote Site;
4、在New Update Site對話框的Name填入“PropEdit”或其它任意非空字符串,在URL中填入http://propedit.sourceforge.jp/eclipse/updates/;
5、在Site to include to search列表中,除上一步加入的site外的其它選項去掉,點擊Finsih;
6、在彈出的Updates對話框中的Select the features to install列表中將所有結尾為“3.1.x”的選項去掉(適用于Eclipse 3.2版本的朋友);
7、點擊Finish關閉對話框;
8、在下載后,同意安裝,再按提示重啟Eclipse,在工具條看到形似vi的按鈕表示安裝成功,插件可用。此時,Eclpise中所有properties文件的文件名前有綠色的P的圖標作為標識。 - 在WebContent文件夾下加入HelloWorl.jsp文件,內容如下:<%@ page ?contentType="text/html; charset=UTF-8"%>
<%@taglib prefix="s" uri="/struts-tags"%>
<html>
<head>
? ? <title>Hello World</title>
</head>
<body>
? ? <h2><s:text name="HelloWorld"/></h2>
? ? <h2><s:property value="%{getText('HelloWorld')}"/></h2>
</body>
</html> - 發布運行應用程序,在瀏覽器地址欄中輸入http://localhost:8080/Struts2_i18n/HelloWorld.jsp ,出現圖1所示頁面。
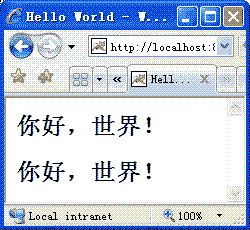
圖1 中文輸出 - 將瀏覽器的默認語言改為“英語(美國)”,刷新頁面,出現圖2所示頁面。
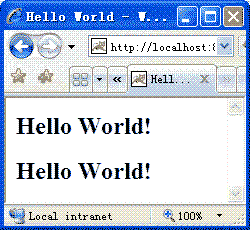
圖2 英文輸出
資源文件查找順序
之所以說Struts 2.0的國際化更靈活是因為它可以能根據不同需要配置和獲取資源(properties)文件。在Struts 2.0中有下面幾種方法:
- 使用全局的資源文件,方法如上例所示。這適用于遍布于整個應用程序的國際化字符串,它們在不同的包(package)中被引用,如一些比較共用的出錯提示;
- 使用包范圍內的資源文件。做法是在包的根目錄下新建名的package.properties和package_xx_XX.properties文件。這就適用于在包中不同類訪問的資源;
- 使用Action范圍的資源文件。做法為Action的包下新建文件名(除文件擴展名外)與Action類名同樣的資源文件。它只能在該Action中訪問。如此一來,我們就可以在不同的Action里使用相同的properties名表示不同的值。例如,在ActonOne中title為“動作一”,而同樣用title在ActionTwo表示“動作二”,節省一些命名工夫;
- 使用<s:i18n>標志訪問特定路徑的properties文件。使用方法請參考我早前的文章《常用的Struts 2.0的標志(Tag)介紹》。在您使用這一方法時,請注意<s:i18n>標志的范圍。在<s:i18n name="xxxxx">到</s:i18n>之間,所有的國際化字符串都會在名為xxxxx資源文件查找,如果找不到,Struts 2.0就會輸出默認值(國際化字符串的名字)。
上面我列舉了四種配置和訪問資源的方法,它們的范圍分別是從大到小,而Struts 2.0在查找國際化字符串所遵循的是特定的順序,如圖3所示:

圖3 資源文件查找順序圖
假設我們在某個ChildAction中調用了getText("user.title"),Struts 2.0的將會執行以下的操作:
- 查找ChildAction_xx_XX.properties文件或ChildAction.properties;
- 查找ChildAction實現的接口,查找與接口同名的資源文件MyInterface.properties;
- 查找ChildAction的父類ParentAction的properties文件,文件名為ParentAction.properties;
- 判斷當前ChildAction是否實現接口ModelDriven。如果是,調用getModel()獲得對象,查找與其同名的資源文件;
- 查找當前包下的package.properties文件;
- 查找當前包的父包,直到最頂層包;
- 在值棧(Value Stack)中,查找名為user的屬性,轉到user類型同名的資源文件,查找鍵為title的資源;
- 查找在struts.properties配置的默認的資源文件,參考例1;
- 輸出user.title。
參數化國際化字符串
許多情況下,我們都需要在動行時(runtime)為國際化字符插入一些參數,例如在輸入驗證提示信息的時候。在Struts 2.0中,我們通過以下兩種方法做到這點:
- 在資源文件的國際化字符串中使用OGNL,格式為${表達式},例如:validation.require=${getText(fileName)} is required
- 使用java.text.MessageFormat中的字符串格式,格式為{ 參數序號(從0開始), 格式類形(number | date | time | choice), 格式樣式},例如:validation.between=Date must between {0, date, short} and {1, date, short}
- 使用標志的value0、value1...valueN的屬性,如:<s:text name="validation.required" value0="User Name"/>
- 使用param子元素,這些param將按先后順序,代入到國際化字符串的參數中,例如:<s:text name="validation.required">
? ?<s:param value="User Name"/>
</s:text>
讓用戶方便地選擇語言
開發國際化的應用程序時,有一個功能是必不可少的——讓用戶快捷地選擇或切換語言。在Struts 2.0中,通過ActionContext.getContext().setLocale(Locale arg)可以設置用戶的默認語言。不過,由于這是一個比較普遍的應用場景(Scenario),所以Struts 2.0為您提供了一個名i18n的攔截器(Interceptor),并在默認情況下將其注冊到攔截器鏈(Interceptor chain)中。它的原理為在執行Action方法前,i18n攔截器查找請求中的一個名為"request_locale"的參數。如果其存在,攔截器就將其作為參數實例化Locale對象,并將其設為用戶默認的區域(Locale),最后,將此Locale對象保存在session的名為“WW_TRANS_I18N_LOCALE”的屬性中。
下面,我將提供一完整示例演示它的使用方法。
 package tutorial;import java.util.Hashtable;import java.util.Locale;import java.util.Map;
package tutorial;import java.util.Hashtable;import java.util.Locale;import java.util.Map;
 publicclass Locales
publicclass Locales  {
{
 ? ?public Map<String, Locale> getLocales() {
? ?public Map<String, Locale> getLocales() { ? ? ? ?Map<String, Locale> locales =new Hashtable<String, Locale>(2); ? ? ? ?locales.put("American English", Locale.US); ? ? ? ?locales.put("Simplified Chinese", Locale.CHINA); ? ? ? ?return locales;
? ? ? ?Map<String, Locale> locales =new Hashtable<String, Locale>(2); ? ? ? ?locales.put("American English", Locale.US); ? ? ? ?locales.put("Simplified Chinese", Locale.CHINA); ? ? ? ?return locales; ? ?}
? ?} }
}<script type="text/javascript">
<!--
? ? function langSelecter_onChanged() {
? ? ? ? document.langForm.submit();
? ? }
//-->
</script>
<s:set name="SESSION_LOCALE" value="#session['WW_TRANS_I18N_LOCALE']"/>
<s:bean id="locales" name="tutorial.Locales"/>
<form action="<s:url includeParams="get" encode="true"/>" name="langForm"?
? ? style="background-color: powderblue; padding-top: 4px; padding-bottom: 4px;">
? ? Language: <s:select label="Language"?
? ? ? ? list="#locales.locales" listKey="value" ? ?listValue="key"
? ? ? ? value="#SESSION_LOCALE == null ? locale : #SESSION_LOCALE"
? ? ? ? name="request_locale" id="langSelecter"?
? ? ? ? onchange="langSelecter_onChanged()" theme="simple"/>
</form>
上述代碼的原理為,LangSelector.jsp先實例化一個Locales對象,并把對象的Map類型的屬性locales賦予下拉列表(select) 。如此一來,下拉列表就獲得可用語言的列表。大家看到LangSelector有<s:form>標志和一段Javascript腳本,它們的作用就是在用戶在下拉列表中選擇了后,提交包含“reqeust_locale”變量的表單到Action。在打開頁面時,為了下拉列表的選中的當前區域,我們需要到session取得當前區域(鍵為“WW_TRANS_I18N_LOCALE”的屬性),而該屬性在沒有設置語言前是為空的,所以通過值棧中locale屬性來取得當前區域(用戶瀏覽器所設置的語言)。
你可以把LangSelector.jsp作為一個控件使用,方法是在JSP頁面中把它包含進來,代碼如下所示:在例1中的HellloWorld.jsp中<body>后加入上述代碼,并在struts.xml中新建Action,代碼如下:
? ? <result>/HelloWorld.jsp</result>
</action>
或者,如果你多個JSP需要實現上述功能,你可以使用下面的通用配置,而不是為每一個JSP頁面都新建一個Action。
? ? <result>/{1}.jsp</result>
</action>
分布運行程序,在瀏覽器的地址欄中輸入http://localhost:8080/Struts2_i18n/HelloWorld.action,出現圖4所示頁面:
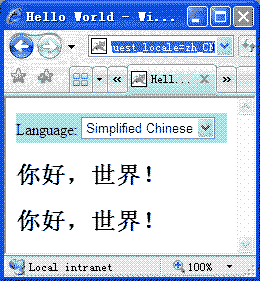
圖3 HelloWorld.action
在下拉列表中,選擇“American English”,出現圖5所示頁面:
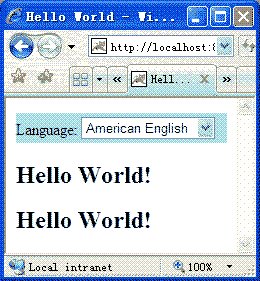
圖4 HelloWorld.action
| 可能大家會問為什么一定要通過Action來訪問頁面呢? 你可以試一下不用Action而直接用JSP的地址來訪問頁面,結果會是無論你在下拉列表中選擇什么,語言都不會改變。這表示不能正常運行的。其原因為如果直接使用JSP訪問頁面,Struts 2.0在web.xml的配置的過濾器(Filter)就不會工作,所以攔截器鏈也不會工作。 |
]]>
俗話說:世上難買后悔藥。所以凡事講究個“三思而后行”,但總常見有人做“痛心疾首”狀:當初我要是……。如果真的有《大話西游》中能時光倒流的“月光寶盒”,那這世上也許會少一些傷感與后悔——當然這只能是癡人說夢了。
但是在我們手指下的程序世界里,卻有的后悔藥買。今天我們要講的備忘錄模式便是程序世界里的“月光寶盒”。
二、定義與結構
備忘錄(Memento)模式又稱標記(Token)模式。GOF給備忘錄模式的定義為:在不破壞封裝性的前提下,捕獲一個對象的內部狀態,并在該對象之外保存這個狀態。這樣以后就可將該對象恢復到原先保存的狀態。
在講命令模式的時候,我們曾經提到利用中間的命令角色可以實現undo、redo的功能。從定義可以看出備忘錄模式是專門來存放對象歷史狀態的,這對于很好的實現undo、redo功能有很大的幫助。所以在命令模式中undo、redo功能可以配合備忘錄模式來實現。
其實單就實現保存一個對象在某一時刻的狀態的功能,還是很簡單的——將對象中要保存的屬性放到一個專門管理備份的對象中,需要的時候則調用約定好的方法將備份的屬性放回到原來的對象中去。但是你要好好看看為了能讓你的備份對象訪問到原對象中的屬性,是否意味著你就要全部公開或者包內公開對象原本私有的屬性呢?如果你的做法已經破壞了封裝,那么就要考慮重構一下了。
備忘錄模式只是GOF對“恢復對象某時的原有狀態”這一問題提出的通用方案。因此在如何保持封裝性上——由于受到語言特性等因素的影響,備忘錄模式并沒有詳細描述,只是基于C++闡述了思路。那么基于Java的應用應該怎樣來保持封裝呢?我們將在實現一節里面討論。
來看下“月光寶盒”備忘錄模式的組成部分:
1) 備忘錄(Memento)角色:備忘錄角色存儲“備忘發起角色”的內部狀態。“備忘發起角色”根據需要決定備忘錄角色存儲“備忘發起角色”的哪些內部狀態。為了防止“備忘發起角色”以外的其他對象訪問備忘錄。備忘錄實際上有兩個接口,“備忘錄管理者角色”只能看到備忘錄提供的窄接口——對于備忘錄角色中存放的屬性是不可見的。“備忘發起角色”則能夠看到一個寬接口——能夠得到自己放入備忘錄角色中屬性。
2) 備忘發起(Originator)角色:“備忘發起角色”創建一個備忘錄,用以記錄當前時刻它的內部狀態。在需要時使用備忘錄恢復內部狀態。
3) 備忘錄管理者(Caretaker)角色:負責保存好備忘錄。不能對備忘錄的內容進行操作或檢查。
備忘錄模式的類圖真是再簡單不過了:
 |
三、舉例
按照定義中的要求,備忘錄角色要保持完整的封裝。最好的情況便是:備忘錄角色只應該暴露操作內部存儲屬性的的接口給“備忘發起角色”。而對于其他角色則是不可見的。GOF在書中以C++為例進行了探討。但是在Java中沒有提供類似于C++中友元的概念。在Java中怎樣才能保持備忘錄角色的封裝呢?
下面對三種在Java中可保存封裝的方法進行探討。
第一種就是采用兩個不同的接口類來限制訪問權限。這兩個接口類中,一個提供比較完備的操作狀態的方法,我們稱它為寬接口;而另一個則可以只是一個標示,我們稱它為窄接口。備忘錄角色要實現這兩個接口類。這樣對于“備忘發起角色”采用寬接口進行訪問,而對于其他的角色或者對象則采用窄接口進行訪問。
這種實現比較簡單,但是需要人為的進行規范約束——而這往往是沒有力度的。
第二種方法便很好的解決了第一種的缺陷:采用內部類來控制訪問權限。將備忘錄角色作為“備忘發起角色”的一個私有內部類。好處我不詳細解釋了,看看代碼吧就明白了。下面的代碼是一個完整的備忘錄模式的教學程序。它便采用了第二種方法來實現備忘錄模式。
還有一點值得指出的是,在下面的代碼中,對于客戶程序來說“備忘錄管理者角色”是不可見的,這樣簡化了客戶程序使用備忘錄模式的難度。下面采用“備忘發起角色”來調用訪問“備忘錄管理者角色”,也可以參考門面模式在客戶程序與備忘錄角色之間添加一個門面角色。
| class Originator{ //這個是要保存的狀態 private int state= 90; //保持一個“備忘錄管理者角色”的對象 private Caretaker c = new Caretaker(); //讀取備忘錄角色以恢復以前的狀態 public void setMemento(){ Memento memento = (Memento)c.getMemento(); state = memento.getState(); System.out.println("the state is "+state+" now"); } //創建一個備忘錄角色,并將當前狀態屬性存入,托給“備忘錄管理者角色”存放。 public void createMemento(){ c.saveMemento(new Memento(state)); } //this is other business methods... //they maybe modify the attribute state public void modifyState4Test(int m){ state = m; System.out.println("the state is "+state+" now"); } //作為私有內部類的備忘錄角色,它實現了窄接口,可以看到在第二種方法中寬接口已經不再需要 //注意:里面的屬性和方法都是私有的 private class Memento implements MementoIF{ private int state ; private Memento(int state){ this.state = state ; } private int getState(){ return state; } } } //測試代碼——客戶程序 public class TestInnerClass{ public static void main(String[] args){ Originator o = new Originator(); o.createMemento(); o.modifyState4Test(80); o.setMemento(); } } //窄接口 interface MementoIF{} //“備忘錄管理者角色” class Caretaker{ private MementoIF m ; public void saveMemento(MementoIF m){ this.m = m; } public MementoIF getMemento(){ return m; } } |
第三種方式是不太推薦使用的:使用clone方法來簡化備忘錄模式。由于Java提供了clone機制,這使得復制一個對象變得輕松起來。使用了clone機制的備忘錄模式,備忘錄角色基本可以省略了,而且可以很好的保持對象的封裝。但是在為你的類實現clone方法時要慎重啊。
在上面的教學代碼中,我們簡單的模擬了備忘錄模式的整個流程。在實際應用中,我們往往需要保存大量“備忘發起角色”的歷史狀態。這時就要對我們的“備忘錄管理者角色”進行改造,最簡單的方式就是采用容器來按照順序存放備忘錄角色。這樣就可以很好的實現undo、redo功能了。
四、適用情況
從上面的討論可以看出,使用了備忘錄模式來實現保存對象的歷史狀態可以有效地保持封裝邊界。使用備忘錄可以避免暴露一些只應由“備忘發起角色”管理卻又必須存儲在“備忘發起角色”之外的信息。把“備忘發起角色”內部信息對其他對象屏蔽起來, 從而保持了封裝邊界。
但是如果備份的“備忘發起角色”存在大量的信息或者創建、恢復操作非常頻繁,則可能造成很大的開銷。
GOF在《設計模式》中總結了使用備忘錄模式的前提:
1) 必須保存一個對象在某一個時刻的(部分)狀態, 這樣以后需要時它才能恢復到先前的狀態。
2) 如果一個用接口來讓其它對象直接得到這些狀態,將會暴露對象的實現細節并破壞對象的封裝性。
五、總結
介紹了怎樣來使用備忘錄模式實現存儲對象歷史狀態的功能,并對基于Java的實現進行了討論。歡迎大家指正。
]]>
說明:
通常,客戶類(clients of class)通過類的接口訪問它提供的服務。有時,現有的類(existing class)可以提供客戶類的功能需要,但是它所提供的接口不一定是客戶類所期望的。這是由于現有的接口太詳細或者缺乏詳細或接口的名稱與客戶類所查找的不同等諸多不同原因導致的。
在這種情況下,現有的接口需要轉化(convert)為客戶類期望的接口,這樣保證了對現有類的重用。如果不進行這樣的轉化,客戶類就不能利用現有類所提供的功能。適配器模式(Adapter Pattern)可以完成這樣的轉化。適配器模式建議定義一個包裝類,包裝有不兼容接口的對象。這個包裝類指的就是適配器(Adapter),它包裝的對象就是適配者(Adaptee)。適配器提供客戶類需要的接口,適配器接口的實現是把客戶類的請求轉化為對適配者的相應接口的調用。換句話說:當客戶類調用適配器的方法時,在適配器類的內部調用適配者類的方法,這個過程對客戶類是透明的,客戶類并不直接訪問適配者類。因此,適配器可以使由于借口不兼容而不能交互的類可以一起工作(work together)。
在上面討論的接口:
(1) 不是指在JAVA編程語言中接口的概念,雖然類的接口可以通過JAVA借擴來定義。
(2) 不是指由窗體和GUI控件所組成的GUI應用程序的用戶接口。
(3) 而是指類所報漏的,被其他類調用的編程接口,
類適配器(Class Adapter)VS對象適配器(Object Adapter)
適配器總體上可以分為兩類??類適配器(Class Adapter)VS對象適配器(Object Adapter)
類適配器:
類適配器是通過繼承類適配者類(Adaptee Class)實現的,另外類適配器實現客戶類所需要的接口。當客戶對象調用適配器類方法的時候,適配器內部調用它所繼承的適配者的方法。
對象適配器:
對象適配器包含一個適配器者的引用(reference),與類適配器相同,對象適配器也實現了客戶類需要的接口。當客戶對象調用對象適配器的方法的時候,對象適配器調它所包含的適配器者實例的適當方法。
下表是類適配器(Class Adapter)和對象適配器(Object Adapter)的詳細不同:

類適配器(Class Adapter) 對象適配器(Object Adapter)
基于繼承概念 利用對象合成
只能應用在適配者是接口,不能利用它子類的接口,當類適配器建立時,它就靜態地與適配者關聯 可以應用在適配者是接口和它的所有子類
因為適配器是作為適配者的子類,所以適配器可能會重載適配者的一些行為。
注意:在JAVA中,子類不能重載父類中聲明為final的方法。 不能重載適配者的方法。
注意:字面上,不能重栽只是因為沒有繼承。但是適配器提供包裝方法可以按需要改變行為。
客戶類對適配者中聲明為public的接口是可見的, 客戶類和適配者是完全不關聯的,只有適配器才能感知適配者接口。
在JAVA應用程序中:
適用于期待的接口是JAVA接口的形式,而不是抽象地或具體地類的形式。這是因為
JAVA編程語言只允許單繼承。因此,類適配器設計成適配者的子類。 在JAVA應用程序中:
適用于當客戶對象期望的接口是抽象類的形式,同時也可以應用于期望接口是Java接口的形式。
例子:
讓我們建立一個驗證給定客戶地址的應用。這個應用是作為大的客戶數據管理應用的一部分。
讓我們定義一個Customer類:
Customer

Figure 20.1: Customer Class
Listing 20.1: Customer Class
- class Customer {
- public static final String US = "US";
- public static final String CANADA = "Canada";
- private String address;
- private String name;
- private String zip, state, type;
- public boolean isValidAddress() {
- …
- …
- }
- public Customer(String inp_name, String inp_address,
- String inp_zip, String inp_state,
- String inp_type) {
- name = inp_name;
- address = inp_address;
- zip = inp_zip;
- state = inp_state;
- type = inp_type;
- }
- }//end of class
不同的客戶對象創建Customer對象并調用(invoke)isValidAddress方法驗證客戶地址的有效性。為了驗證客戶地址的有效性,Customer類期望利用一個地址驗證類(address validator class),這個驗證類提供了在接口AddressValidator中聲明的接口。
Listing 20.2: AddressValidator as an Interface
讓我們定義一個USAddress的驗證類,來驗證給定的U.S地址。
Listing 20.3: USAddress Class
- class USAddress implements AddressValidator {
- public boolean isValidAddress(String inp_address,
- String inp_zip, String inp_state) {
- if (inp_address.trim().length() < 10)
- return false;
- if (inp_zip.trim().length() < 5)
- return false;
- if (inp_zip.trim().length() > 10)
- return false;
- if (inp_state.trim().length() != 2)
- return false;
- return true;
- }
- }//end of class
USAddress類實現AddressValidator接口,因此Customer對象使用USAddress實例作為驗證客戶地址過程的一部分是沒有任何問題的。
Listing 20.4: Customer Class Using the USAddress Class
- class Customer {
- …
- …
- public boolean isValidAddress() {
- //get an appropriate address validator
- AddressValidator validator = getValidator(type);
- //Polymorphic call to validate the address
- return validator.isValidAddress(address, zip, state);
- }
- private AddressValidator getValidator(String custType) {
- AddressValidator validator = null;
- if (custType.equals(Customer.US)) {
- validator = new USAddress();
- }
- return validator;
- }
- }//end of class

Figure 20.2: Customer/USAddress Validator?Class Association
但是當驗證來自加拿大的客戶時,就要對應用進行改進。這需要一個驗證加拿大客戶地址的驗證類。讓我們假設已經存在一個用來驗證加拿大客戶地址的使用工具類CAAddress,。
從下面的CAAdress類的實現,可以發現CAAdress提供了客戶類Customer類所需要的驗證服務。但是它所提供的接口不用于客戶類Customer所期望的。
Listing 20.5: CAAdress Class with Incompatible Interface
CAAdress類提供了一個isValidCanadianAddr方法,但是Customer期望一個聲明在AddressValidator接口中的isValidAddress方法。
接口的不兼容使得Customer對象利用現有的CAAdress類是困難的。一種意見是改變CAAdress類的接口,但是可能會有其他的應用正在使用CAAdress類的這種形式。改變CAAdress類接口會影響現在使用CAAdress類的客戶。
應用適配器模式,類適配器CAAdressAdapter可以繼承CAAdress類實現AddressValidator接口。

Figure 20.3: Class Adapter for the CAAddress Class
Listing 20.6: CAAddressAdapter as a Class Adapter
因為適配器CAAdressAdapter實現了AddressValidator接口,客戶端對象訪問適配器CAAdressAdapter對象是沒有任何問題的。當客戶對象調用適配器實例的isValidAddress方法的時候,適配器在內部把調用傳遞給它繼承的isValidCanadianAddr方法。
在Customer類內部,getValidator私有方法需要擴展,以至于它可以在驗證加拿大客戶的時候返回一個CAAdressAdapter實例。返回的對象是多態的,USAddress和CAAddressAdapter都實現了AddressValidator接口,所以不用改變。
Listing 20.7: Customer Class Using the CAAddressAdapter Class
- class Customer {
- …
- …
- public boolean isValidAddress() {
- //get an appropriate address validator
- AddressValidator validator = getValidator(type);
- //Polymorphic call to validate the address
- return validator.isValidAddress(address, zip, state);
- }
- private AddressValidator getValidator(String custType) {
- AddressValidator validator = null;
- if (custType.equals(Customer.US)) {
- validator = new USAddress();
- }
- if (type.equals(Customer.CANADA)) {
- validator = new CAAddressAdapter();
- }
- return validator;
- }
- }//end of class
CAAddressAdapter設計和對AddressValidator(聲明期望的接口)對象的多態調用使Customer可以利用接口不兼容CAAddress類提供的服務。
The class diagram in Figure 20.4 shows the overall class association.

Figure 20.4: Address Validation Application?Using Class Adapter
The sequence diagram in Figure 20.5 depicts the message flow when the CAAddressAdapter is designed as a class adapter.

Figure 20.5: Address Validation Message Flow?Using Class Adapter
作為對象適配器的地址適配器
當討論以類適配器來實現地址適配器時,我們說客戶類期望的AddressValidator接口是Java接口形式。現在,讓我們假設客戶類期望AddressValidator接口是抽象類而不是java接口。因為適配器CAAdapter必須提供抽象類AddressValidatro中聲明的接口,適配器必須是AddressValidator抽象類的子類、實現抽象方法。
- Listing 20.8: AddressValidator as an Abstract Class
- public abstract class AddressValidator {
- public abstract boolean isValidAddress(String inp_address,
- String inp_zip, String inp_state);
- }//end of class
- Listing 20.9: CAAddressAdapter Class
- class CAAddressAdapter extends AddressValidator {
- …
- …
- public CAAddressAdapter(CAAddress address) {
- objCAAddress = address;
- }
- public boolean isValidAddress(String inp_address,
- String inp_zip, String inp_state) {
- …
- …
- }
- }//end of class
因為多繼承在JAVA中不支持,現在適配器CAAddressAdapter不能繼承現有的CAAddress類,它已經使用了唯一一次繼承其他類的機會。
應用對象適配器模式,CAAddressAdapter可以包含一個適配者CAAddress的一個實例。當適配器第一次創建的時候,這個適配者的實例通過客戶端傳遞給適配器。通常,適配者實例可以通過下面兩種方式提供給包裝它的適配器。
(1) 對象適配器的客戶端可以傳遞一個適配者的實例給適配器。這種方式在選擇類的形式上有很大的靈活性,但是客戶端感知了適配者或者適配過程。這種方法在適配器不但需要適配者對象行為而且需要特定狀態時很適合。
(2) 適配器可以自己創建適配者實例。這種方法相對來說缺乏靈活性。適用于適配器只需要適配者對象的行為而不需要適配者對象的特定狀態的情況。

Figure 20.6: Object Adapter for the CAAddress Class
Listing 20.10: CAAddressAdapter as an Object Adapter
- class CAAddressAdapter extends AddressValidator {
- private CAAddress objCAAddress;
- public CAAddressAdapter(CAAddress address) {
- objCAAddress = address;
- }
- public boolean isValidAddress(String inp_address,
- String inp_zip, String inp_state) {
- return objCAAddress.isValidCanadianAddr(inp_address,
- inp_zip, inp_state);
- }
- }//end of class
當客戶對象調用CAAddressAdapter(adapter)上的isValidAddress方法時, 適配器在內部調用CAAddress(adaptee)上的isValidCanadianAddr方法。
The class diagram in Figure 20.7 shows the overall class association when the address adapter is designed as an object adapter.

Figure 20.7: Address Validation Application?Using Object Adapter
從這個例子可以看出,適配器可以使Customer(client)類訪問借口不兼容的CAAddress(adaptee)所提供的服務!
The sequence diagram in Figure 20.8 shows the message flow when the adapter CAAddressAdapter is designed as an object adapter.

Figure 20.8: Address Validation Message Flow?Using Object Adapter
附件為原文和代碼:
[img]附件:24.rar(17K) 附件:Chapter_20.doc(267K)
]]>
]]>