2012年2月21日
版權(quán)信息: 可以任意轉(zhuǎn)載, 轉(zhuǎn)載時(shí)請(qǐng)務(wù)必以超鏈接形式標(biāo)明文章原文出處, 即下面的聲明.
原文出處:http://blog.chenlb.com/2009/06/java-classloader-architecture.html
jvm classLoader architecture:
- Bootstrap ClassLoader/啟動(dòng)類加載器
主要負(fù)責(zé)jdk_home/lib目錄下的核心 api 或 -Xbootclasspath 選項(xiàng)指定的jar包裝入工作。 - Extension ClassLoader/擴(kuò)展類加載器
主要負(fù)責(zé)jdk_home/lib/ext目錄下的jar包或 -Djava.ext.dirs 指定目錄下的jar包裝入工作。 - System ClassLoader/系統(tǒng)類加載器
主要負(fù)責(zé)java -classpath/-Djava.class.path所指的目錄下的類與jar包裝入工作。 - User Custom ClassLoader/用戶自定義類加載器(java.lang.ClassLoader的子類)
在程序運(yùn)行期間, 通過java.lang.ClassLoader的子類動(dòng)態(tài)加載class文件, 體現(xiàn)java動(dòng)態(tài)實(shí)時(shí)類裝入特性。
類加載器的特性:
- 每個(gè)ClassLoader都維護(hù)了一份自己的名稱空間, 同一個(gè)名稱空間里不能出現(xiàn)兩個(gè)同名的類。
- 為了實(shí)現(xiàn)java安全沙箱模型頂層的類加載器安全機(jī)制, java默認(rèn)采用了 " 雙親委派的加載鏈 " 結(jié)構(gòu)。

classloader-architecture

classloader-class-diagram
類圖中, BootstrapClassLoader是一個(gè)單獨(dú)的java類, 其實(shí)在這里, 不應(yīng)該叫他是一個(gè)java類。因?yàn)椋呀?jīng)完全不用java實(shí)現(xiàn)了。它是在jvm啟動(dòng)時(shí), 就被構(gòu)造起來的, 負(fù)責(zé)java平臺(tái)核心庫。
自定義類加載器加載一個(gè)類的步驟

classloader-load-class
ClassLoader 類加載邏輯分析, 以下邏輯是除 BootstrapClassLoader 外的類加載器加載流程:
- // 檢查類是否已被裝載過
- Class c = findLoadedClass(name);
- if (c == null ) {
- // 指定類未被裝載過
- try {
- if (parent != null ) {
- // 如果父類加載器不為空, 則委派給父類加載
- c = parent.loadClass(name, false );
- } else {
- // 如果父類加載器為空, 則委派給啟動(dòng)類加載加載
- c = findBootstrapClass0(name);
- }
- } catch (ClassNotFoundException e) {
- // 啟動(dòng)類加載器或父類加載器拋出異常后, 當(dāng)前類加載器將其
- // 捕獲, 并通過findClass方法, 由自身加載
- c = findClass(name);
- }
- }
線程上下文類加載器
java默認(rèn)的線程上下文類加載器是 系統(tǒng)類加載器(AppClassLoader)。
- // Now create the class loader to use to launch the application
- try {
- loader = AppClassLoader.getAppClassLoader(extcl);
- } catch (IOException e) {
- throw new InternalError(
- "Could not create application class loader" );
- }
-
- // Also set the context class loader for the primordial thread.
- Thread.currentThread().setContextClassLoader(loader);
以上代碼摘自sun.misc.Launch的無參構(gòu)造函數(shù)Launch()。
使用線程上下文類加載器, 可以在執(zhí)行線程中, 拋棄雙親委派加載鏈模式, 使用線程上下文里的類加載器加載類.
典型的例子有, 通過線程上下文來加載第三方庫jndi實(shí)現(xiàn), 而不依賴于雙親委派.
大部分java app服務(wù)器(jboss, tomcat..)也是采用contextClassLoader來處理web服務(wù)。
還有一些采用 hotswap 特性的框架, 也使用了線程上下文類加載器, 比如 seasar (full stack framework in japenese).
線程上下文從根本解決了一般應(yīng)用不能違背雙親委派模式的問題.
使java類加載體系顯得更靈活.
隨著多核時(shí)代的來臨, 相信多線程開發(fā)將會(huì)越來越多地進(jìn)入程序員的實(shí)際編碼過程中. 因此,
在編寫基礎(chǔ)設(shè)施時(shí), 通過使用線程上下文來加載類, 應(yīng)該是一個(gè)很好的選擇。
當(dāng)然, 好東西都有利弊. 使用線程上下文加載類, 也要注意, 保證多根需要通信的線程間的類加載器應(yīng)該是同一個(gè),
防止因?yàn)椴煌念惣虞d器, 導(dǎo)致類型轉(zhuǎn)換異常(ClassCastException)。
為什么要使用這種雙親委托模式呢?
- 因?yàn)檫@樣可以避免重復(fù)加載,當(dāng)父親已經(jīng)加載了該類的時(shí)候,就沒有必要子ClassLoader再加載一次。
- 考慮到安全因素,我們?cè)囅胍幌拢绻皇褂眠@種委托模式,那我們就可以隨時(shí)使用自定義的String來動(dòng)態(tài)替代java核心api中定義類型,這樣會(huì)存在非常大的安全隱患,而雙親委托的方式,就可以避免這種情況,因?yàn)镾tring已經(jīng)在啟動(dòng)時(shí)被加載,所以用戶自定義類是無法加載一個(gè)自定義的ClassLoader。
java動(dòng)態(tài)載入class的兩種方式:
- implicit隱式,即利用實(shí)例化才載入的特性來動(dòng)態(tài)載入class
- explicit顯式方式,又分兩種方式:
- java.lang.Class的forName()方法
- java.lang.ClassLoader的loadClass()方法
用Class.forName加載類
Class.forName使用的是被調(diào)用者的類加載器來加載類的。
這種特性, 證明了java類加載器中的名稱空間是唯一的, 不會(huì)相互干擾。
即在一般情況下, 保證同一個(gè)類中所關(guān)聯(lián)的其他類都是由當(dāng)前類的類加載器所加載的。
- public static Class forName(String className)
- throws ClassNotFoundException {
- return forName0(className, true , ClassLoader.getCallerClassLoader());
- }
-
- /** Called after security checks have been made. */
- private static native Class forName0(String name, boolean initialize,
- ClassLoader loader)
- throws ClassNotFoundException;
上面中 ClassLoader.getCallerClassLoader 就是得到調(diào)用當(dāng)前forName方法的類的類加載器
static塊在什么時(shí)候執(zhí)行?
- 當(dāng)調(diào)用forName(String)載入class時(shí)執(zhí)行,如果調(diào)用ClassLoader.loadClass并不會(huì)執(zhí)行.forName(String,false,ClassLoader)時(shí)也不會(huì)執(zhí)行.
- 如果載入Class時(shí)沒有執(zhí)行static塊則在第一次實(shí)例化時(shí)執(zhí)行.比如new ,Class.newInstance()操作
- static塊僅執(zhí)行一次
各個(gè)java類由哪些classLoader加載?
- java類可以通過實(shí)例.getClass.getClassLoader()得知
- 接口由AppClassLoader(System ClassLoader,可以由ClassLoader.getSystemClassLoader()獲得實(shí)例)載入
- ClassLoader類由bootstrap loader載入
NoClassDefFoundError和ClassNotFoundException
- NoClassDefFoundError:當(dāng)java源文件已編譯成.class文件,但是ClassLoader在運(yùn)行期間在其搜尋路徑load某個(gè)類時(shí),沒有找到.class文件則報(bào)這個(gè)錯(cuò)
- ClassNotFoundException:試圖通過一個(gè)String變量來創(chuàng)建一個(gè)Class類時(shí)不成功則拋出這個(gè)異常
一:使用場景
1)使用的地方:樹形結(jié)構(gòu),分支結(jié)構(gòu)等
2)使用的好處:降低客戶端的使用,為了達(dá)到元件與組合件使用的一致性,增加了元件的編碼
3)使用后的壞處:代碼不容易理解,需要你認(rèn)真去研究,發(fā)現(xiàn)元件與組合件是怎么組合的
二:一個(gè)實(shí)際的例子
畫圖形,這個(gè)模式,稍微要難理解一點(diǎn),有了例子就說明了一切,我畫的圖是用接口做的,代碼實(shí)現(xiàn)是抽象類為基類,你自己選擇了,接口也可以。

1)先建立圖形元件
package com.mike.pattern.structure.composite;
/**
* 圖形元件
*
* @author taoyu
*
* @since 2010-6-23
*/
public abstract class Graph {
/**圖形名稱*/
protected String name;
public Graph(String name){
this.name=name;
}
/**畫圖*/
public abstract void draw()throws GraphException;
/**添加圖形*/
public abstract void add(Graph graph)throws GraphException;
/**移掉圖形*/
public abstract void remove(Graph graph)throws GraphException;
}
2)建立基礎(chǔ)圖形圓
package com.mike.pattern.structure.composite;
import static com.mike.util.Print.print;
/**
* 圓圖形
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Circle extends Graph {
public Circle(String name){
super(name);
}
/**
* 圓添加圖形
* @throws GraphException
*/
@Override
public void add(Graph graph) throws GraphException {
throw new GraphException("圓是基礎(chǔ)圖形,不能添加");
}
/**
* 圓畫圖
*/
@Override
public void draw()throws GraphException {
print(name+"畫好了");
}
/**
* 圓移掉圖形
*/
@Override
public void remove(Graph graph)throws GraphException {
throw new GraphException("圓是基礎(chǔ)圖形,不能移掉");
}
}
3)建立基礎(chǔ)圖形長方形
package com.mike.pattern.structure.composite;
import static com.mike.util.Print.print;
/**
* 長方形
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Rectangle extends Graph {
public Rectangle(String name){
super(name);
}
/**
* 長方形添加
*/
@Override
public void add(Graph graph) throws GraphException {
throw new GraphException("長方形是基礎(chǔ)圖形,不能添加");
}
/**
* 畫長方形
*/
@Override
public void draw() throws GraphException {
print(name+"畫好了");
}
@Override
public void remove(Graph graph) throws GraphException {
throw new GraphException("長方形是基礎(chǔ)圖形,不能移掉");
}
}
4)最后簡歷組合圖形
package com.mike.pattern.structure.composite;
import java.util.ArrayList;
import java.util.List;
import static com.mike.util.Print.print;
/**
* 圖形組合體
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Picture extends Graph {
private List<Graph> graphs;
public Picture(String name){
super(name);
/**默認(rèn)是10個(gè)長度*/
graphs=new ArrayList<Graph>();
}
/**
* 添加圖形元件
*/
@Override
public void add(Graph graph) throws GraphException {
graphs.add(graph);
}
/**
* 圖形元件畫圖
*/
@Override
public void draw() throws GraphException {
print("圖形容器:"+name+" 開始創(chuàng)建");
for(Graph g : graphs){
g.draw();
}
}
/**
* 圖形元件移掉圖形元件
*/
@Override
public void remove(Graph graph) throws GraphException {
graphs.remove(graph);
}
}
5)最后測試
public static void main(String[] args)throws GraphException {
/**畫一個(gè)圓,圓里包含一個(gè)圓和長方形*/
Picture picture=new Picture("立方體圓");
picture.add(new Circle("圓"));
picture.add(new Rectangle("長方形"));
Picture root=new Picture("怪物圖形");
root.add(new Circle("圓"));
root.add(picture);
root.draw();
}
6)使用心得:的確降低了客戶端的使用情況,讓整個(gè)圖形可控了,當(dāng)是你要深入去理解,才真名明白采用該模式的含義,不太容易理解。
一:使用場景
1)使用的地方:我想使用兩個(gè)不同類的方法,這個(gè)時(shí)候你需要把它們組合起來使用
2)目前使用的情況:我會(huì)把兩個(gè)類用戶組合的方式放到一起,編程思想think in java里已經(jīng)提到個(gè),能盡量用組合就用組合,繼承一般考慮再后。
3)使用后的好處:你不需要改動(dòng)以前的代碼,只是新封裝了一新類,由這個(gè)類來提供兩個(gè)類的方法,這個(gè)時(shí)候:一定會(huì)想到facade外觀模式,本來是多個(gè)類使用的情況,我新封裝成一個(gè)類來使用,而這個(gè)類我采用組合的方式來包裝新的方法。我的理解是,設(shè)計(jì)模式本身就是為了幫助解決特定的業(yè)務(wù)場景而故意把模式劃分對(duì)應(yīng)的模式類別,其實(shí)大多數(shù)情況,都解決了同樣的問題,這個(gè)時(shí)候其實(shí)沒有必要過多的糾纏到模式的名字上了,你有好的注意,你甚至取一個(gè)新的名字來概括這樣的使用場景。
4)使用的壞處:適配器模式,有兩種方式來實(shí)現(xiàn)。一個(gè)是組合一個(gè)是繼承,我覺得,首先應(yīng)該考慮組合,能用組合就不要用繼承,這是第一個(gè)。第二個(gè),你采用繼承來實(shí)現(xiàn),那肯定會(huì)加大繼承樹結(jié)構(gòu),如果你的繼承關(guān)系本身就很復(fù)雜了,這肯定會(huì)加大繼承關(guān)系的維護(hù),不有利于代碼的理解,或則更加繁瑣。繼承是為了解決重用的為題而出現(xiàn)的,所以我覺得不應(yīng)該濫用繼承,有機(jī)會(huì)可以考慮同樣別的方案。
二:一個(gè)實(shí)際的例子
關(guān)聯(lián)營銷的例子,用戶購買完商品后,我又推薦他相關(guān)別的商品
由于減少代碼,方法我都不采用接口,直接由類來提供,代碼只是一個(gè)范例而已,都精簡了。
1)創(chuàng)建訂單信息
public class Order {
private Long orderId;
private String nickName;
public Order(Long orderId,String nickName){
this.orderId=orderId;
this.nickName=nickName;
}
/**
* 用戶下訂單
*/
public void insertOrder(){
}
}
2)商品信息
public class Auction {
/**商品名稱*/
private String name;
/**制造商*/
private String company;
/**制造日期*/
private Date date;
public Auction(String name,String company, Date date){
this.name=name;
this.company=company;
this.date=date;
}
/**
* 推廣的商品列表
*/
public void commendAuction(){
}
}
3)購物
public class Trade {
/**用戶訂單*/
private Order order;
/**商品信息*/
private Auction auction;
public Trade(Order order ,Auction auction){
this.order=order;
this.auction=auction;
}
/**
* 用戶產(chǎn)生訂單以及后續(xù)的事情
*/
public void trade(){
/**下訂單*/
order.insertOrder();
/**關(guān)聯(lián)推薦相關(guān)的商品*/
auction.commendAuction();
}
}
4)使用心得:其實(shí)外面采用了很多繼承的方式,order繼承auction之后,利用super .inserOrder()再加一個(gè)auction.recommendAuction(),實(shí)際上大同小異,我到覺得采用組合更容易理解以及代碼更加優(yōu)美點(diǎn)。
一:使用場景
1)使用到的地方:如果你想創(chuàng)建類似汽車這樣的對(duì)象,首先要?jiǎng)?chuàng)建輪子,玻璃,桌椅,發(fā)動(dòng)機(jī),外廓等,這些部件都創(chuàng)建好后,最后創(chuàng)建汽車成品,部件的創(chuàng)建和汽車的組裝過程本身都很復(fù)雜的情況,希望把部件的創(chuàng)建和成品的組裝分開來做,這樣把要做的事情分割開來,降低對(duì)象實(shí)現(xiàn)的復(fù)雜度,也降低以后成本的維護(hù),把汽車的部件創(chuàng)建和組裝過程獨(dú)立出兩個(gè)對(duì)應(yīng)的工廠來做,有點(diǎn)類似建立兩個(gè)對(duì)應(yīng)的部件創(chuàng)建工廠和汽車組裝工廠兩個(gè)工廠,而工廠只是創(chuàng)建一個(gè)成品,并沒有把里面的步驟也獨(dú)立出來,應(yīng)該說Builder模式比工廠模式又進(jìn)了一步。
2)采用Builder模式后的好處:把一個(gè)負(fù)責(zé)的對(duì)象的創(chuàng)建過程分解,把一個(gè)對(duì)象的創(chuàng)建分成兩個(gè)對(duì)象來負(fù)責(zé)創(chuàng)建,代碼更有利于維護(hù),可擴(kuò)性比較好。
3)采用Builder模式后的壞處:實(shí)現(xiàn)起來,對(duì)應(yīng)的接口以及部件的對(duì)象的創(chuàng)建比較多,代碼相對(duì)來講,比較多了,估計(jì)剛開始你會(huì)有點(diǎn)暈,這個(gè)可以考慮代碼精簡的問題,增加代碼的可讀性。
二:一個(gè)實(shí)際的例子
汽車的組裝
1)首先創(chuàng)建汽車這個(gè)成品對(duì)象,包含什么的成員
public class Car implements Serializable{
/**
* 汽車序列號(hào)
*/
private static final long serialVersionUID = 1L;
/**汽車輪子*/
private Wheel wheel;
/**汽車發(fā)動(dòng)機(jī)*/
private Engine engine;
/**汽車玻璃*/
private Glass glass;
/**汽車座椅*/
private Chair chair;
public Wheel getWheel() {
return wheel;
}
public void setWheel(Wheel wheel) {
this.wheel = wheel;
}
public Engine getEngine() {
return engine;
}
public void setEngine(Engine engine) {
this.engine = engine;
}
public Glass getGlass() {
return glass;
}
public void setGlass(Glass glass) {
this.glass = glass;
}
public Chair getChair() {
return chair;
}
public void setChair(Chair chair) {
this.chair = chair;
}
}
2)創(chuàng)建對(duì)應(yīng)汽車零部件
public class Wheel {
public Wheel(){
print("--汽車輪子構(gòu)建完畢--");
}
}
public class Engine {
public Engine(){
print("--汽車發(fā)動(dòng)機(jī)構(gòu)建完畢--");
}
}
public class Glass {
public Glass(){
print("--汽車玻璃構(gòu)建完畢--");
}
}
public class Chair {
public Chair(){
print("--汽車座椅構(gòu)建完畢--");
}
}
3)開始重點(diǎn)了,汽車成品的組裝過程
public interface Builder {
/**組裝汽車輪子*/
public void buildWheel();
/**組裝汽車發(fā)動(dòng)機(jī)*/
public void buildEngine();
/**組裝汽車玻璃*/
public void buildGlass();
/**組裝汽車座椅*/
public void buildChair();
/**返回組裝好的汽車*/
public Car getCar();
}
以及實(shí)現(xiàn)類
public class CarBuilder implements Builder {
/**汽車成品*/
private Car car;
public CarBuilder(){
car=new Car();
}
/**組裝汽車輪子*/
@Override
public void buildChair() {
car.setChair(new Chair());
}
/**組裝汽車發(fā)動(dòng)機(jī)*/
@Override
public void buildEngine() {
car.setEngine(new Engine());
}
/**組裝汽車玻璃*/
@Override
public void buildGlass() {
car.setGlass(new Glass());
}
/**組裝汽車座椅*/
@Override
public void buildWheel() {
car.setWheel(new Wheel());
}
/**返回組裝好的汽車*/
@Override
public Car getCar() {
buildChair();
buildEngine();
buildGlass();
buildWheel();
print("--整個(gè)汽車構(gòu)建完畢--");
return car;
}
}
4)最后汽車創(chuàng)建測試
public static void main(String[] args) {
/**創(chuàng)建汽車組裝*/
Builder carBuilder=new CarBuilder();
Car car=carBuilder.getCar();
}
最后輸出:
--汽車座椅構(gòu)建完畢--
--汽車發(fā)動(dòng)機(jī)構(gòu)建完畢--
--汽車玻璃構(gòu)建完畢--
--汽車輪子構(gòu)建完畢--
--整個(gè)汽車構(gòu)建完畢--
5)體會(huì)心得:Builder模式實(shí)際的重點(diǎn)就把汽車的組裝過程和零部件的生產(chǎn)分開來實(shí)現(xiàn),零部件的生成主要靠自己的對(duì)象來實(shí)現(xiàn),我上面只是在構(gòu)造函數(shù)里創(chuàng)建了,比較簡單,而重點(diǎn)汽車的組裝則交給CarBuilder來實(shí)現(xiàn),最終由builder來先負(fù)責(zé)零部件的創(chuàng)建,最后返回出成品的汽車。
一:使用場景
1)經(jīng)常使用的地方:一個(gè)類只有一個(gè)實(shí)例,eg:頁面訪問統(tǒng)計(jì)pv,統(tǒng)計(jì)的個(gè)數(shù)就只能保證一個(gè)實(shí)例的統(tǒng)計(jì)。
2)我們目前使用的情況:比如我想創(chuàng)建一個(gè)對(duì)象,這個(gè)對(duì)象希望只有一份實(shí)例的維護(hù),在內(nèi)存的保存也只有一份,也就是在同一個(gè)jvm的java堆里只保存一份實(shí)例對(duì)象,所以你會(huì)想一辦法,在創(chuàng)建這個(gè)對(duì)象的時(shí)候,就已經(jīng)能保證只有一份。
3)怎么改進(jìn):定義該對(duì)象的時(shí)候,就保證是同一份實(shí)例,比如:定義為私有構(gòu)造函數(shù),防止通過new的方式可以創(chuàng)建對(duì)象,然后在對(duì)象里定義一個(gè)靜態(tài)的私有成員(本身對(duì)象的一個(gè)實(shí)例),然后再創(chuàng)建一個(gè)外面訪問該對(duì)象的方法就好了。
4)改進(jìn)的好處:代碼在編譯代碼這個(gè)級(jí)別就被控制了,不至于在jvm里運(yùn)行的時(shí)候才來保證,把唯一實(shí)例的創(chuàng)建保證在編譯階段;jvm里內(nèi)存只有一份,從而內(nèi)存占有率更低,以及更方便java垃圾回收
5)改進(jìn)后的壞處:只能是代碼稍微需要更多點(diǎn),其實(shí)大家最后發(fā)現(xiàn)改進(jìn)后的壞處,都是代碼定義比之間要多一點(diǎn),但以后的維護(hù)代碼就降下來了,也短暫的代碼量偏大來換取以后代碼的精簡。
二:一個(gè)實(shí)際的例子
總體的例子
package com.mike.pattern.singleton;
/**
* 總統(tǒng)
*
* @author taoyu
*
* @since 2010-6-22
*/
public class President {
private President(){
System.out.println("總統(tǒng)已經(jīng)選舉出來了");
}
/**總統(tǒng)只有一個(gè)*/
private static President president=new President();
/**
* 返回總統(tǒng)
*/
public static President getPresident(){
return president;
}
/**
* 總統(tǒng)宣布選舉成功
*/
public void announce(){
System.out.println("偉大的中國人民,我將成你們新的總統(tǒng)");
}
}
/**
* @param args
*/
public static void main(String[] args) {
President president=President.getPresident();
president.announce();
}
1.使用場景
1)子類過多,不容易管理;構(gòu)造對(duì)象過程過長;精簡代碼創(chuàng)建;
2)目前我們代碼情況: 編寫代碼的時(shí)候,我們經(jīng)常都在new對(duì)象,創(chuàng)建一個(gè)個(gè)的對(duì)象,而且還有很多麻煩的創(chuàng)建方式,eg:HashMap<String,Float> grade=new HashMap<String,Float>(),這樣的代碼創(chuàng)建方式太冗長了,難道你沒有想過把這個(gè)創(chuàng)建變的短一點(diǎn)么,比如:HashMap<String,Float>grade=HashMapFactory.new(),可以把你創(chuàng)建精簡一點(diǎn);你也可以還有別的需求,在創(chuàng)建對(duì)象的時(shí)候,你需要不同的情況,創(chuàng)建統(tǒng)一種類別的對(duì)象,eg:我想生成不同的汽車,創(chuàng)建小轎車,創(chuàng)建卡車,創(chuàng)建公交汽車等等,都屬于同種類別:汽車,你難道沒有想過,我把這些創(chuàng)建的對(duì)象在一個(gè)工廠里來負(fù)責(zé)創(chuàng)建,我把創(chuàng)建分開化,交給一人來負(fù)責(zé),這樣可以讓代碼更加容易管理,創(chuàng)建方式也可以簡單點(diǎn)。
比如:Car BMW=CarFactory.create(bmw); 把創(chuàng)建new由一個(gè)統(tǒng)一負(fù)責(zé),這樣管理起來相當(dāng)方便
3)怎么改進(jìn):這個(gè)時(shí)候,你會(huì)想到,創(chuàng)建這樣同類別的東西,我把這個(gè)權(quán)利分出去,讓一個(gè)人來單獨(dú)管理,它只負(fù)責(zé)創(chuàng)建我的對(duì)象這個(gè)事情,所以你單獨(dú)簡歷一個(gè)對(duì)象來創(chuàng)建同類的對(duì)象,這個(gè)時(shí)候,你想這個(gè)東西有點(diǎn)像工廠一樣,生成同樣的產(chǎn)品,所以取了個(gè)名字:工廠模式,顧名思義,只負(fù)責(zé)對(duì)象的創(chuàng)建
4)改進(jìn)后的好處:代碼更加容易管理了,代碼的創(chuàng)建要簡潔很多。
5)改進(jìn)后的壞處:那就是你需要單獨(dú)加一個(gè)工廠對(duì)象來負(fù)責(zé)創(chuàng)建,多需要寫點(diǎn)代碼。
2.一個(gè)實(shí)際的例子
創(chuàng)建寶馬汽車與奔馳汽車的例子
1)先提取出一個(gè)汽車的公用接口Car
public interface Car{
/**行駛*/
public void drive();
}
2)寶馬和奔馳汽車對(duì)象
public class BMWCar implements Car {
/**
* 汽車發(fā)動(dòng)
*/
public void drive(){
System.out.println("BMW Car drive");
}
}
public class BengCar implements Car {
/**
* 汽車發(fā)動(dòng)
*/
public void drive(){
System.out.println("BengChi Care drive");
}
}
3)單獨(dú)一個(gè)汽車工廠來負(fù)責(zé)創(chuàng)建
public class FactoryCar {
/**
* 制造汽車
*
* @param company 汽車公司
* @return 汽車
* @throws CreateCarException 制造汽車失敗異常
*/
public static Car createCar(Company company)throws CreateCarException{
if(company==Company.BMW){
return new BMWCar();
}else if(company==Company.Beng){
return new BengCar();
}
return null;
}
}
4)最后的代碼實(shí)現(xiàn):
Car BMWCar=FactoryCar.createCar(Company.BMW);
BMWCar.drive();
1. 我說下我對(duì)設(shè)計(jì)模式的理解:任何一樣事物都是因?yàn)橛行枨蟮尿?qū)動(dòng)才誕生的,所以設(shè)計(jì)模式也不例外,我們平時(shí)在編寫代碼的時(shí)候,隨著時(shí)間的深入,發(fā)現(xiàn)很多代碼很難維護(hù),可擴(kuò)展性級(jí)差,以及代碼的效率也比較低,這個(gè)時(shí)候你肯定會(huì)想辦法讓代碼變的優(yōu)美又能解決你項(xiàng)目中的問題,所以在面向?qū)ο笳Z言里,你肯定會(huì)去發(fā)現(xiàn)很多可以重用的公用的方法,比如:接口的存在,你自然就想到了,讓你定義的方法與你的實(shí)現(xiàn)分開,也可以很方便把不同的類與接口匹配起來,形成了一個(gè)公用的接口,你會(huì)發(fā)現(xiàn)這樣做,好處會(huì)是非常多的,解決了你平時(shí)想把代碼的申明與邏輯實(shí)現(xiàn)的分開。
2. 這個(gè)時(shí)候,你發(fā)現(xiàn)了,本身面向?qū)ο蟮恼Z言里,已經(jīng)暗藏了很多好處,你肯定會(huì)仔細(xì)去分析面向?qū)ο筮@個(gè)語言,認(rèn)真去挖掘里面更多的奧秘,最后,你發(fā)現(xiàn)了,原來你可以把面向?qū)ο蟮奶匦蕴崛〕梢粋€(gè)公用的實(shí)現(xiàn)案例,這些案例里能幫助你解決你平時(shí)編寫代碼的困擾,而這樣一群人,就是所謂gof的成員,他們從平時(shí)設(shè)計(jì)建筑方面找到了靈感,建筑的設(shè)計(jì)也可以公用化以及重用化,所以他們也提取了相關(guān)的軟件設(shè)計(jì)方面的公用案例,也就有了下面的相關(guān)的所謂23種設(shè)計(jì)模式,而里面這么多模式,你也可以把他們歸類起來,最后發(fā)現(xiàn)就幾類模式:創(chuàng)建,結(jié)構(gòu),行為等模式類別,而這些現(xiàn)成的方案,也可以在實(shí)際應(yīng)用中充分發(fā)揮作用,隨著大家的使用以及理解,發(fā)現(xiàn)其實(shí)這些所謂的模式里,你的確可以讓你的代碼變的更加優(yōu)美與簡練。
3. 我比較喜歡把代碼變的更加優(yōu)美與簡練,優(yōu)美的代碼就是一看就懂,結(jié)構(gòu)很清晰,而簡歷就是一目了然,又可以解決你的問題,就是代碼又少效率又高,所以平時(shí)要養(yǎng)成寫java doc的習(xí)慣,這樣的代碼才為清晰,所以才會(huì)更加優(yōu)美。
4. 這些就是我對(duì)設(shè)計(jì)模式的理解,所以這么好的寶貝,我們不去深入的了解,的確可惜了,這就叫站到巨人的肩膀上.....
一:網(wǎng)絡(luò)配置
1.關(guān)掉防火墻
1) 重啟后生效
開啟: chkconfig iptables on
關(guān)閉: chkconfig iptables off
2) 即時(shí)生效,重啟后失效
開啟: service iptables start
關(guān)閉: service iptables stop
2.下載軟件
wget curl
3.安裝和解壓
安裝 rpm -ivh
升級(jí) rpm -Uvh
卸載 rpm -e
tar -zxvf
二:網(wǎng)卡設(shè)置
1、 設(shè)置ip地址(即時(shí)生效,重啟失效)
#ifconfig eth0 ip地址 netmask 子網(wǎng)掩碼
2、 設(shè)置ip地址(重啟生效,永久生效)
#setup
3、 通過配置文件設(shè)置ip地址(重啟生效,永久生效)
#vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 #設(shè)備名,與文件同名。
ONBOOT=yes #在系統(tǒng)啟動(dòng)時(shí),啟動(dòng)本設(shè)備。
BOOTPROTO=static
IPADDR=202.118.75.91 #此網(wǎng)卡的IP地址
NETMASK=255.255.255.0 #子網(wǎng)掩碼
GATEWAY=202.118.75.1 #網(wǎng)關(guān)IP
MACADDR=00:02:2D:2E:8C:A8 #mac地址
4、 重啟網(wǎng)絡(luò)服務(wù)
#service network restart //重啟所有網(wǎng)卡
5、 禁用網(wǎng)卡,啟動(dòng)網(wǎng)卡
#ifdown eth0
#ifup eth0
6、 屏蔽網(wǎng)卡,顯示網(wǎng)卡
#ifconfig eth0 down
#ifconfig eth0 up
7、 配置DNS客戶端(最多三個(gè))
#vi /etc/resolv.conf
nameserver 202.99.96.68
8、更改主機(jī)名(即時(shí)生效)
#hostname 主機(jī)名
9、更改主機(jī)名(重啟計(jì)算機(jī)生效,永久生效)
#vi /etc/sysconfig/network
HOSTNAME=主機(jī)名
三:兩臺(tái)linux拷貝命令:scp
1.安裝scp:yum install openssh-clients
2.scp -r 本地用戶名@IP地址:文件名1 遠(yuǎn)程用戶名@IP地址:文件名2
摘要: 作者:NetSeek http://www.linuxtone.org (IT運(yùn)維專家網(wǎng)|集群架構(gòu)|性能調(diào)優(yōu))歡迎轉(zhuǎn)載,轉(zhuǎn)載時(shí)請(qǐng)務(wù)必以超鏈接形式標(biāo)明文章原始出處和作者信息及本聲明.首發(fā)時(shí)間: 2008-11-25 更新時(shí)間:2009-1-14目 錄一、 Nginx 基礎(chǔ)知識(shí)二、 Nginx 安裝及調(diào)試三、 Nginx Rewrite四、 Nginx Redirect五、 Nginx 目錄自動(dòng)加斜線...
閱讀全文
一:quartz簡介 OpenSymphony 的Quartz提供了一個(gè)比較完美的任務(wù)調(diào)度解決方案。 Quartz 是個(gè)開源的作業(yè)調(diào)度框架,定時(shí)調(diào)度器,為在 Java 應(yīng)用程序中進(jìn)行作業(yè)調(diào)度提供了簡單卻強(qiáng)大的機(jī)制。
Quartz中有兩個(gè)基本概念:作業(yè)和觸發(fā)器。作業(yè)是能夠調(diào)度的可執(zhí)行任務(wù),觸發(fā)器提供了對(duì)作業(yè)的調(diào)度
二:quartz spring配置詳解- 為什么不適用java.util.Timer結(jié)合java.util.TimerTask
1.主要的原因,適用不方便,特別是制定具體的年月日時(shí)分的時(shí)間,而quartz使用類似linux上的cron配置,很方便的配置每隔時(shí)間執(zhí)行觸發(fā)。
2.其次性能的原因,使用jdk自帶的Timer不具備多線程,而quartz采用線程池,性能上比timer高出很多。
在spring里主要分為兩種使用方式:第一種,也是目前使用最多的方式,spring提供的MethodInvokingJobDetailFactoryBean代理類,通過雷利類直接調(diào)用任務(wù)類的某個(gè)函數(shù);第二種,程序里實(shí)現(xiàn)quartz接口,quartz通過該接口進(jìn)行調(diào)度。
主要講解通過spring提供的代理類MethodInvokingJobDetailFactoryBean 1.業(yè)務(wù)邏輯類:業(yè)務(wù)邏輯是獨(dú)立的,本身就與quartz解耦的,并沒有深入進(jìn)去,這對(duì)業(yè)務(wù)來講是很好的一個(gè)方式。
public class TestJobTask{ /**
*業(yè)務(wù)邏輯處理
*/ public void service(){
/**業(yè)務(wù)邏輯*/ 
..
}
}
2.增加一個(gè)線程池 <!-- 線程執(zhí)行器配置,用于任務(wù)注冊(cè) --><bean id="executor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="10" />
<property name="maxPoolSize" value="100" />
<property name="queueCapacity" value="500" />
</bean>
3.定義業(yè)務(wù)邏輯類
<!-- 業(yè)務(wù)對(duì)象 --><bean id="testJobTask" class="com.mike.scheduling.TestJobTask" />
4.增加quartz調(diào)用業(yè)務(wù)邏輯
<!-- 調(diào)度業(yè)務(wù) --><bean id="jobDetail" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="testJobTask" />
<property name="targetMethod" value="service" />
</bean>
5.增加調(diào)用的觸發(fā)器,觸發(fā)的時(shí)間,有兩種方式:
第一種觸發(fā)時(shí)間,采用類似linux的cron,配置時(shí)間的表示發(fā)出豐富 <bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean"> <property name="jobDetail" ref="jobDetail" />
<property name="cronExpression" value="10 0/1 * * * ?" />
</bean>
Cron表達(dá)式“10 */1 * * * ?”意為:從10秒開始,每1分鐘執(zhí)行一次 第二種,采用比較簡話的方式,申明延遲時(shí)間和間隔時(shí)間
<bean id="taskTrigger" class="org.springframework.scheduling.quartz.SimpleTriggerBean"> <property name="jobDetail" ref="jobDetail" />
<property name="startDelay" value="10000" />
<property name="repeatInterval" value="60000" />
</bean>
延遲10秒啟動(dòng),然后每隔1分鐘執(zhí)行一次 6.開始調(diào)用
<!-- 設(shè)置調(diào)度 --><bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref bean="cronTrigger" />
</list>
</property>
<property name="taskExecutor" ref="executor" />
</bean>
7.結(jié)束:啟動(dòng)容器即可,已經(jīng)將spring和quartz結(jié)合完畢。 Cron常用的表達(dá)式 "0 0 12 * * ?" 每天中午12點(diǎn)觸發(fā)"0 15 10 ? * *" 每天上午10:15觸發(fā)
"0 15 10 * * ?" 每天上午10:15觸發(fā)
"0 15 10 * * ? *" 每天上午10:15觸發(fā)
"0 15 10 * * ? 2005" 2005年的每天上午10:15觸發(fā)
"0 * 14 * * ?" 在每天下午2點(diǎn)到下午2:59期間的每1分鐘觸發(fā)
"0 0/5 14 * * ?" 在每天下午2點(diǎn)到下午2:55期間的每5分鐘觸發(fā)
"0 0/5 14,18 * * ?" 在每天下午2點(diǎn)到2:55期間和下午6點(diǎn)到6:55期間的每5分鐘觸發(fā)
"0 0-5 14 * * ?" 在每天下午2點(diǎn)到下午2:05期間的每1分鐘觸發(fā)
"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44觸發(fā)
"0 15 10 ? * MON-FRI" 周一至周五的上午10:15觸發(fā)
"0 15 10 15 * ?" 每月15日上午10:15觸發(fā)
"0 15 10 L * ?" 每月最后一日的上午10:15觸發(fā)
"0 15 10 ? * 6L" 每月的最后一個(gè)星期五上午10:15觸發(fā)
"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一個(gè)星期五上午10:15觸發(fā)
"0 15 10 ? * 6#3" 每月的第三個(gè)星期五上午10:15觸發(fā)
三:quartz原理
根據(jù)上面spring的配置,我們就比較清楚quartz的內(nèi)部情況,下面我們主要詳解配置涉及到的每個(gè)點(diǎn) 1.我們先從最后一個(gè)步驟看起,
SchedulerFactoryBean ,scheduler的工廠實(shí)現(xiàn),里面可以生產(chǎn)出對(duì)應(yīng)的多個(gè)jobDetail和trigger,每個(gè)jobDetail對(duì)應(yīng)trigger代表一個(gè)任務(wù)
Quartz的SchedulerFactory是標(biāo)準(zhǔn)的工廠類,不太適合在Spring環(huán)境下使用。此外,為了保證Scheduler能夠感知 Spring容器的生命周期,完成自動(dòng)啟動(dòng)和關(guān)閉的操作,必須讓Scheduler和Spring容器的生命周期相關(guān)聯(lián)。以便在Spring容器啟動(dòng)后, Scheduler自動(dòng)開始工作,而在Spring容器關(guān)閉前,自動(dòng)關(guān)閉Scheduler。為此,Spring提供 SchedulerFactoryBean,這個(gè)FactoryBean大致?lián)碛幸韵碌墓δ埽?nbsp; 1)以更具Bean風(fēng)格的方式為Scheduler提供配置信息;
2)讓Scheduler和Spring容器的生命周期建立關(guān)聯(lián),相生相息;
3)通過屬性配置部分或全部代替Quartz自身的配置文件。
2.jobDetail,表示一個(gè)可執(zhí)行的業(yè)務(wù)調(diào)用
3.trigger:調(diào)度的時(shí)間計(jì)劃,什么時(shí)候,每隔多少時(shí)間可執(zhí)行等時(shí)間計(jì)劃
4.ThreadPoolTaskExecutor,線程池,用來并行執(zhí)行每個(gè)對(duì)應(yīng)的job,提高效率,這也是上面提到不推薦使用jdk自身timer的一個(gè)很重要的原因
一:事務(wù)的概念
事務(wù)必須服從ISO/IEC所制定的ACID原則。ACID是原子性(atomicity)、一致性(consistency)、隔離性(isolation)和持久性(durability)的縮寫 事務(wù)的原子性:表示事務(wù)執(zhí)行過程中的任何失敗都將導(dǎo)致事務(wù)所做的任何修改失效。
一致性表示當(dāng)事務(wù)執(zhí)行失敗時(shí),所有被該事務(wù)影響的數(shù)據(jù)都應(yīng)該恢復(fù)到事務(wù)執(zhí)行前的狀態(tài)。
隔離性表示在事務(wù)執(zhí)行過程中對(duì)數(shù)據(jù)的修改,在事務(wù)提交之前對(duì)其他事務(wù)不可見。
持久性表示已提交的數(shù)據(jù)在事務(wù)執(zhí)行失敗時(shí),數(shù)據(jù)的狀態(tài)都應(yīng)該正確。 二:事務(wù)的場景
1.與銀行相關(guān)的業(yè)務(wù),重要的數(shù)據(jù),與錢相關(guān)的內(nèi)容不能出任何錯(cuò)。
2.系統(tǒng)內(nèi)部認(rèn)為重要的數(shù)據(jù),都需要事務(wù)的支持,防止重要數(shù)據(jù)的不一致。
3.具體的業(yè)務(wù)場景:銀行業(yè)務(wù),支付業(yè)務(wù),交易業(yè)務(wù)等。
三:事務(wù)的實(shí)現(xiàn)方式
首先說一下事務(wù)的類型,主要包含一下三種:JDBC事務(wù),JTA事務(wù),容器事務(wù)
1、JDBC事務(wù) JDBC 事務(wù)是用 Connection 對(duì)象控制的。JDBC Connection 接口( java.sql.Connection )提供了兩種事務(wù)模式:自動(dòng)提交和手工提交。 java.sql.Connection 提供了以下控制事務(wù)的方法: public void setAutoCommit(boolean) public boolean getAutoCommit() public void commit() public void rollback() 使用 JDBC 事務(wù)界定時(shí),您可以將多個(gè) SQL 語句結(jié)合到一個(gè)事務(wù)中。JDBC 事務(wù)的一個(gè)缺點(diǎn)是事務(wù)的范圍局限于一個(gè)數(shù)據(jù)庫連接。一個(gè) JDBC 事務(wù)不能跨越多個(gè)數(shù)據(jù)庫。 2、JTA(Java Transaction API)事務(wù) JTA是一種高層的,與實(shí)現(xiàn)無關(guān)的,與協(xié)議無關(guān)的API,應(yīng)用程序和應(yīng)用服務(wù)器可以使用JTA來訪問事務(wù)。 JTA允許應(yīng)用程序執(zhí)行分布式事務(wù)處理--在兩個(gè)或多個(gè)網(wǎng)絡(luò)計(jì)算機(jī)資源上訪問并且更新數(shù)據(jù),這些數(shù)據(jù)可以分布在多個(gè)數(shù)據(jù)庫上。JDBC驅(qū)動(dòng)程序的JTA支持極大地增強(qiáng)了數(shù)據(jù)訪問能力。 如果計(jì)劃用 JTA 界定事務(wù),那么就需要有一個(gè)實(shí)現(xiàn) javax.sql.XADataSource 、 javax.sql.XAConnection 和 javax.sql.XAResource 接口的 JDBC 驅(qū)動(dòng)程序。一個(gè)實(shí)現(xiàn)了這些接口的驅(qū)動(dòng)程序?qū)⒖梢詤⑴c JTA 事務(wù)。一個(gè) XADataSource 對(duì)象就是一個(gè) XAConnection 對(duì)象的工廠。 XAConnection s 是參與 JTA 事務(wù)的 JDBC 連接。 您將需要用應(yīng)用服務(wù)器的管理工具設(shè)置 XADataSource 。從應(yīng)用服務(wù)器和 JDBC 驅(qū)動(dòng)程序的文檔中可以了解到相關(guān)的指導(dǎo)。 J2EE 應(yīng)用程序用 JNDI 查詢數(shù)據(jù)源。一旦應(yīng)用程序找到了數(shù)據(jù)源對(duì)象,它就調(diào)用 javax.sql.DataSource.getConnection() 以獲得到數(shù)據(jù)庫的連接。 XA 連接與非 XA 連接不同。一定要記住 XA 連接參與了 JTA 事務(wù)。這意味著 XA 連接不支持 JDBC 的自動(dòng)提交功能。同時(shí),應(yīng)用程序一定不要對(duì) XA 連接調(diào)用 java.sql.Connection.commit() 或者 java.sql.Connection.rollback() 。相反,應(yīng)用程序應(yīng)該使用 UserTransaction.begin()、 UserTransaction.commit() 和 serTransaction.rollback() 。 3、容器事務(wù) 容器事務(wù)主要是J2EE應(yīng)用服務(wù)器提供的,容器事務(wù)大多是基于JTA完成,這是一個(gè)基于JNDI的,相當(dāng)復(fù)雜的API實(shí)現(xiàn)。相對(duì)編碼實(shí)現(xiàn)JTA事務(wù)管理,我們可以通過EJB容器提供的容器事務(wù)管理機(jī)制(CMT)完成同一個(gè)功能,這項(xiàng)功能由J2EE應(yīng)用服務(wù)器提供。這使得我們可以簡單的指定將哪個(gè)方法加入事務(wù),一旦指定,容器將負(fù)責(zé)事務(wù)管理任務(wù)。這是我們土建的解決方式,因?yàn)橥ㄟ^這種方式我們可以將事務(wù)代碼排除在邏輯編碼之外,同時(shí)將所有困難交給J2EE容器去解決。使用EJB CMT的另外一個(gè)好處就是程序員無需關(guān)心JTA API的編碼,不過,理論上我們必須使用EJB。 四、三種事務(wù)差異 1、JDBC事務(wù)控制的局限性在一個(gè)數(shù)據(jù)庫連接內(nèi),但是其使用簡單。 2、JTA事務(wù)的功能強(qiáng)大,事務(wù)可以跨越多個(gè)數(shù)據(jù)庫或多個(gè)DAO,使用也比較復(fù)雜。 3、容器事務(wù),主要指的是J2EE應(yīng)用服務(wù)器提供的事務(wù)管理,局限于EJB應(yīng)用使用。
五:詳解事務(wù)
1.首先看一下目前使用最多的spring事務(wù),目前spring配置分為聲明式事務(wù)和編程式事務(wù)。
1)編程式事務(wù)
主要是實(shí)現(xiàn)接口PlatformTransactionManager
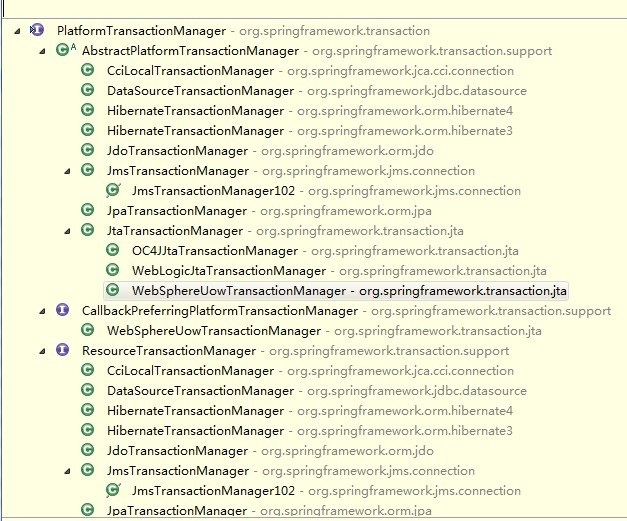
實(shí)現(xiàn)了事務(wù)管理的接口有非常多,這里主要講DataSourceTransactionManager和數(shù)據(jù)庫jdbc相關(guān)的事務(wù)處理方式
之前有接觸過hadoop,但都比較淺顯,對(duì)立面的東東不是很清楚!
打算后面在hadoop上花時(shí)間把里面的內(nèi)容,好好學(xué)學(xué),這篇博客將在后面陸續(xù)更新hadoop學(xué)習(xí)筆記。
一:Mina概要 Apache Mina是一個(gè)能夠幫助用戶開發(fā)高性能和高伸縮性網(wǎng)絡(luò)應(yīng)用程序的框架。它通過Java nio技術(shù)基于TCP/IP和UDP/IP協(xié)議提供了抽象的、事件驅(qū)動(dòng)的、異步的API。
如下的特性:
1、 基于Java nio的TCP/IP和UDP/IP實(shí)現(xiàn)
基于RXTX的串口通信(RS232)
VM 通道通信
2、通過filter接口實(shí)現(xiàn)擴(kuò)展,類似于Servlet filters
3、low-level(底層)和high-level(高級(jí)封裝)的api:
low-level:使用ByteBuffers
High-level:使用自定義的消息對(duì)象和解碼器
4、Highly customizable(易用的)線程模式(MINA2.0 已經(jīng)禁用線程模型了):
單線程
線程池
多個(gè)線程池
5、基于java5 SSLEngine的SSL、TLS、StartTLS支持
6、負(fù)載平衡
7、使用mock進(jìn)行單元測試
8、jmx整合
9、基于StreamIoHandler的流式I/O支持
10、IOC容器的整合:Spring、PicoContainer
11、平滑遷移到Netty平臺(tái)
二:實(shí)踐 首先講一下客戶端的通信過程:
1.通過SocketConnector同服務(wù)器端建立連接
2.鏈接建立之后I/O的讀寫交給了I/O Processor線程,I/O Processor是多線程的
3.通過I/O Processor讀取的數(shù)據(jù)經(jīng)過IoFilterChain里所有配置的IoFilter,IoFilter進(jìn)行消息的過濾,格式的轉(zhuǎn)換,在這個(gè)層面可以制定一些自定義的協(xié)議
4.最后IoFilter將數(shù)據(jù)交給Handler進(jìn)行業(yè)務(wù)處理,完成了整個(gè)讀取的過程
5.寫入過程也是類似,只是剛好倒過來,通過IoSession.write寫出數(shù)據(jù),然后Handler進(jìn)行寫入的業(yè)務(wù)處理,處理完成后交給IoFilterChain,進(jìn)行消息過濾和協(xié)議的轉(zhuǎn)換,最后通過I/O Processor將數(shù)據(jù)寫出到socket通道
IoFilterChain作為消息過濾鏈
1.讀取的時(shí)候是從低級(jí)協(xié)議到高級(jí)協(xié)議的過程,一般來說從byte字節(jié)逐漸轉(zhuǎn)換成業(yè)務(wù)對(duì)象的過程
2.寫入的時(shí)候一般是從業(yè)務(wù)對(duì)象到字節(jié)byte的過程
IoSession貫穿整個(gè)通信過程的始終
客戶端通信過程

1.創(chuàng)建服務(wù)器
package com.gewara.web.module.base;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.charset.Charset;
import org.apache.mina.core.service.IoAcceptor;
import org.apache.mina.filter.codec.ProtocolCodecFilter;
import org.apache.mina.filter.codec.textline.TextLineCodecFactory;
import org.apache.mina.filter.logging.LoggingFilter;
import org.apache.mina.transport.socket.nio.NioSocketAcceptor;
/**
* Mina服務(wù)器
*
* @author mike
*
* @since 2012-3-15
*/
public class HelloServer {
private static final int PORT = 8901;// 定義監(jiān)聽端口
public static void main(String[] args) throws IOException{
// 創(chuàng)建服務(wù)端監(jiān)控線程
IoAcceptor acceptor = new NioSocketAcceptor();
// 設(shè)置日志記錄器
acceptor.getFilterChain().addLast("logger", new LoggingFilter());
// 設(shè)置編碼過濾器
acceptor.getFilterChain().addLast("codec",new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 指定業(yè)務(wù)邏輯處理器
acceptor.setHandler(new HelloServerHandler());
// 設(shè)置端口號(hào)
acceptor.setDefaultLocalAddress(new InetSocketAddress(PORT));
// 啟動(dòng)監(jiān)聽線程
acceptor.bind();
}
}
2.創(chuàng)建服務(wù)器端業(yè)務(wù)邏輯
package com.gewara.web.module.base;
import org.apache.mina.core.service.IoHandlerAdapter;
import org.apache.mina.core.session.IoSession;
/**
* 服務(wù)器端業(yè)務(wù)邏輯
*
* @author mike
*
* @since 2012-3-15
*/public class HelloServerHandler
extends IoHandlerAdapter {
@Override
/**
* 連接創(chuàng)建事件
*/ public void sessionCreated(IoSession session){
// 顯示客戶端的ip和端口
System.out.println(session.getRemoteAddress().toString());
}
@Override
/**
* 消息接收事件
*/ public void messageReceived(IoSession session, Object message)
throws Exception{
String str = message.toString();
if (str.trim().equalsIgnoreCase("quit")){
// 結(jié)束會(huì)話
session.close(
true);
return;
}
// 返回消息字符串
session.write("Hi Client!");
// 打印客戶端傳來的消息內(nèi)容
System.out.println("Message written
" + str);
}
}
3.創(chuàng)建客戶端
package com.gewara.web.module.base;
import java.net.InetSocketAddress;
import java.nio.charset.Charset;
import org.apache.mina.core.future.ConnectFuture;
import org.apache.mina.filter.codec.ProtocolCodecFilter;
import org.apache.mina.filter.codec.textline.TextLineCodecFactory;
import org.apache.mina.filter.logging.LoggingFilter;
import org.apache.mina.transport.socket.nio.NioSocketConnector;
/**
* Mina客戶端
*
* @author mike
*
* @since 2012-3-15
*/
public class HelloClient {
public static void main(String[] args){
// 創(chuàng)建客戶端連接器.
NioSocketConnector connector = new NioSocketConnector();
// 設(shè)置日志記錄器
connector.getFilterChain().addLast("logger", new LoggingFilter());
// 設(shè)置編碼過濾器
connector.getFilterChain().addLast("codec",
new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 設(shè)置連接超時(shí)檢查時(shí)間
connector.setConnectTimeoutCheckInterval(30);
// 設(shè)置事件處理器
connector.setHandler(new HelloClientHandler());
// 建立連接
ConnectFuture cf = connector.connect(new InetSocketAddress("192.168.2.89", 8901));
// 等待連接創(chuàng)建完成
cf.awaitUninterruptibly();
// 發(fā)送消息
cf.getSession().write("Hi Server!");
// 發(fā)送消息
cf.getSession().write("quit");
// 等待連接斷開
cf.getSession().getCloseFuture().awaitUninterruptibly();
// 釋放連接
connector.dispose();
}
}
4.客戶端業(yè)務(wù)邏輯
package com.gewara.web.module.base;
import org.apache.mina.core.service.IoHandlerAdapter;
import org.apache.mina.core.session.IoSession;
public class HelloClientHandler extends IoHandlerAdapter {
@Override
/**
* 消息接收事件
*/
public void messageReceived(IoSession session, Object message) throws Exception{
//顯示接收到的消息
System.out.println("server message:"+message.toString());
}
}
5.先啟動(dòng)服務(wù)器端,然后啟動(dòng)客戶端
2012-03-15 14:45:41,456 INFO logging.LoggingFilter - CREATED
/192.168.2.89:2691
2012-03-15 14:45:41,456 INFO logging.LoggingFilter - OPENED
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - RECEIVED: HeapBuffer[pos=0 lim=11 cap=2048: 48 69 20 53 65 72 76 65 72 21 0A]
2012-03-15 14:45:41,487 DEBUG codec.ProtocolCodecFilter - Processing a MESSAGE_RECEIVED
for session 1
Message written
Hi Server!
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - SENT: HeapBuffer[pos=0 lim=0 cap=0: empty]
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - RECEIVED: HeapBuffer[pos=0 lim=5 cap=2048: 71 75 69 74 0A]
2012-03-15 14:45:41,487 DEBUG codec.ProtocolCodecFilter - Processing a MESSAGE_RECEIVED
for session 1
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - CLOSED
1.首先看服務(wù)器
// 創(chuàng)建服務(wù)端監(jiān)控線程
IoAcceptor acceptor = new NioSocketAcceptor();
// 設(shè)置日志記錄器
acceptor.getFilterChain().addLast("logger", new LoggingFilter());
// 設(shè)置編碼過濾器
acceptor.getFilterChain().addLast("codec",new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 指定業(yè)務(wù)邏輯處理器
acceptor.setHandler(new HelloServerHandler());
// 設(shè)置端口號(hào)
acceptor.setDefaultLocalAddress(new InetSocketAddress(PORT));
// 啟動(dòng)監(jiān)聽線程
acceptor.bind();
1)先創(chuàng)建NioSocketAcceptor nio的接收器,談到Socket就要說到Reactor模式 當(dāng)前分布式計(jì)算 Web Services盛行天下,這些網(wǎng)絡(luò)服務(wù)的底層都離不開對(duì)socket的操作。他們都有一個(gè)共同的結(jié)構(gòu):1. Read request2. Decode request3. Process service 4. Encode reply5. Send reply 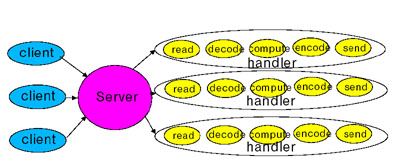
但這種模式在用戶負(fù)載增加時(shí),性能將下降非常的快。我們需要重新尋找一個(gè)新的方案,保持?jǐn)?shù)據(jù)處理的流暢,很顯然,事件觸發(fā)機(jī)制是最好的解決辦法,當(dāng)有事件發(fā)生時(shí),會(huì)觸動(dòng)handler,然后開始數(shù)據(jù)的處理。
Reactor模式類似于AWT中的Event處理。
Reactor模式參與者
1.Reactor 負(fù)責(zé)響應(yīng)IO事件,一旦發(fā)生,廣播發(fā)送給相應(yīng)的Handler去處理,這類似于AWT的thread
2.Handler 是負(fù)責(zé)非堵塞行為,類似于AWT ActionListeners;同時(shí)負(fù)責(zé)將handlers與event事件綁定,類似于AWT addActionListener
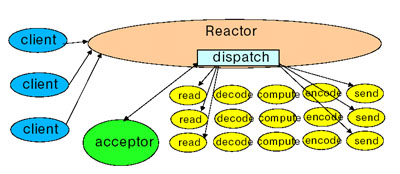
并發(fā)系統(tǒng)常采用reactor模式,簡稱觀察者模式,代替常用的多線程處理方式,利用有限的系統(tǒng)的資源,提高系統(tǒng)的吞吐量。
可以看一下這篇文章,講解的很生動(dòng)具體,一看就明白reactor模式的好處
http://daimojingdeyu.iteye.com/blog/828696 Reactor模式是編寫高性能網(wǎng)絡(luò)服務(wù)器的必備技術(shù)之一,它具有如下的優(yōu)點(diǎn): 1)響應(yīng)快,不必為單個(gè)同步時(shí)間所阻塞,雖然Reactor本身依然是同步的; 2)編程相對(duì)簡單,可以最大程度的避免復(fù)雜的多線程及同步問題,并且避免了多線程/進(jìn)程的切換開銷; 3)可擴(kuò)展性,可以方便的通過增加Reactor實(shí)例個(gè)數(shù)來充分利用CPU資源; 4)可復(fù)用性,reactor框架本身與具體事件處理邏輯無關(guān),具有很高的復(fù)用性; 2)其次,再說說NIO的基本原理和使用 NIO 有一個(gè)主要的類Selector,這個(gè)類似一個(gè)觀察者,只要我們把需要探知的socketchannel告訴Selector,我們接著做別的事情,當(dāng)有事件發(fā)生時(shí),他會(huì)通知我們,傳回一組 SelectionKey,我們讀取這些Key,就會(huì)獲得我們剛剛注冊(cè)過的socketchannel,然后,我們從這個(gè)Channel中讀取數(shù)據(jù),放心,包準(zhǔn)能夠讀到,接著我們可以處理這些數(shù)據(jù)。
Selector內(nèi)部原理實(shí)際是在做一個(gè)對(duì)所注冊(cè)的channel的輪詢?cè)L問,不斷的輪詢(目前就這一個(gè)算法),一旦輪詢到一個(gè)channel有所注冊(cè)的事情發(fā)生,比如數(shù)據(jù)來了,他就會(huì)站起來報(bào)告,交出一把鑰匙,讓我們通過這把鑰匙(SelectionKey表示 SelectableChannel 在 Selector 中的注冊(cè)的標(biāo)記。 )來讀取這個(gè)channel的內(nèi)容。
一:基本原理 主要是要實(shí)現(xiàn)網(wǎng)絡(luò)之間的通訊,
網(wǎng)絡(luò)通信需要做的就是將流從一臺(tái)計(jì)算機(jī)傳輸?shù)搅硗庖慌_(tái)計(jì)算機(jī),基于傳輸協(xié)議和網(wǎng)絡(luò)IO來實(shí)現(xiàn),其中傳輸協(xié)議比較出名的有http、 tcp、udp等等,http、tcp、udp都是在基于Socket概念上為某類應(yīng)用場景而擴(kuò)展出的傳輸協(xié)議,網(wǎng)絡(luò)IO,主要有bio、nio、aio 三種方式,所有的分布式應(yīng)用通訊都基于這個(gè)原理而實(shí)現(xiàn)。
二:實(shí)踐
在分布式服務(wù)框架中,一個(gè)最基礎(chǔ)的問題就是遠(yuǎn)程服務(wù)是怎么通訊的,在Java領(lǐng)域中有很多可實(shí)現(xiàn)遠(yuǎn)程通訊的技術(shù):RMI、MINA、ESB、Burlap、Hessian、SOAP、EJB和JMS
既然引入出了這么多技術(shù),那我們就順道深入挖掘下去,了解每個(gè)技術(shù)框架背后的東西:
1.首先看RMI
RMI主要包含如下內(nèi)容:
遠(yuǎn)程服務(wù)的接口定義
·遠(yuǎn)程服務(wù)接口的具體實(shí)現(xiàn) ·樁(Stub)和框架(Skeleton)文件 ·一個(gè)運(yùn)行遠(yuǎn)程服務(wù)的服務(wù)器 ·一個(gè)RMI命名服務(wù),它允許客戶端去發(fā)現(xiàn)這個(gè)遠(yuǎn)程服務(wù) ·類文件的提供者(一個(gè)HTTP或者FTP服務(wù)器) ·一個(gè)需要這個(gè)遠(yuǎn)程服務(wù)的客戶端程序 來看下基于RMI的一次完整的遠(yuǎn)程通信過程的原理:
1)客戶端發(fā)起請(qǐng)求,請(qǐng)求轉(zhuǎn)交至RMI客戶端的stub類;
2)stub類將請(qǐng)求的接口、方法、參數(shù)等信息進(jìn)行序列化;
3)基于tcp/ip將序列化后的流傳輸至服務(wù)器端;
4)服務(wù)器端接收到流后轉(zhuǎn)發(fā)至相應(yīng)的skelton類;
5)skelton類將請(qǐng)求的信息反序列化后調(diào)用實(shí)際的處理類;
6)處理類處理完畢后將結(jié)果返回給skelton類;
7)Skelton類將結(jié)果序列化,通過tcp/ip將流傳送給客戶端的stub;
8)stub在接收到流后反序列化,將反序列化后的Java Object返回給調(diào)用者。
RMI應(yīng)用級(jí)協(xié)議內(nèi)容:
1、傳輸?shù)臉?biāo)準(zhǔn)格式是什么?
2、怎么樣將請(qǐng)求轉(zhuǎn)化為傳輸?shù)牧鳎?/div>
基于Java串行化機(jī)制將請(qǐng)求的java object信息轉(zhuǎn)化為流。
根據(jù)采用的協(xié)議啟動(dòng)相應(yīng)的監(jiān)聽端口,當(dāng)有流進(jìn)入后基于Java串行化機(jī)制將流進(jìn)行反序列化,并根據(jù)RMI協(xié)議獲取到相應(yīng)的處理對(duì)象信息,進(jìn)行調(diào)用并處理,處理完畢后的結(jié)果同樣基于java串行化機(jī)制進(jìn)行返回。
tcp/ip。
原理講了,開始實(shí)踐:
創(chuàng)建RMI程序的6個(gè)步驟: 1、定義一個(gè)遠(yuǎn)程接口的接口,該接口中的每一個(gè)方法必須聲明它將產(chǎn)生一個(gè)RemoteException異常。 2、定義一個(gè)實(shí)現(xiàn)該接口的類。 3、使用RMIC程序生成遠(yuǎn)程實(shí)現(xiàn)所需的殘根和框架。 4、創(chuàng)建一個(gè)服務(wù)器,用于發(fā)布2中寫好的類。 5. 創(chuàng)建一個(gè)客戶程序進(jìn)行RMI調(diào)用。 6、啟動(dòng)rmiRegistry并運(yùn)行自己的遠(yuǎn)程服務(wù)器和客戶程序 1)首先創(chuàng)建遠(yuǎn)程接口:
/** * 遠(yuǎn)程接口
*
* @author mike
*
* @since 2012-3-14
*/
public interface Hello extends Remote {
/**
* 測試rmi
*
* @return hello
* @throws RemoteException
*/
public String hello()throws RemoteException;
}
2)創(chuàng)建接口實(shí)現(xiàn)
package com.gewara.rmi;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
/**
* 遠(yuǎn)程接口實(shí)現(xiàn)
*
* @author mike
*
* @since 2012-3-14
*/
public class HelloImpl extends UnicastRemoteObject implements Hello {
/**
* seria id
*/
private static final long serialVersionUID = -7931720891757437009L;
protected HelloImpl() throws RemoteException {
super();
}
/**
* hello實(shí)現(xiàn)
*
* @return hello world
* @throws RemoteException
*/
public String hello() throws RemoteException {
return "hello world";
}
}
3)創(chuàng)建服務(wù)器端
package com.gewara.rmi;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
public class Server {
private static final String RMI_URL="rmi://192.168.2.89:10009/server";
/**
* RMI Server
*/
public Server() {
try {
//創(chuàng)建遠(yuǎn)程對(duì)象
Hello hello=new HelloImpl();
//啟動(dòng)注冊(cè)表
LocateRegistry.createRegistry(10009);
//將名稱綁定到對(duì)象
Naming.bind(RMI_URL, hello);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* @param args
*/
public static void main(String[] args) {
new Server();
}
}
4)創(chuàng)建客服端
package com.gewara.rmi;
import java.rmi.Naming;
public class Client {
private static final String RMI_URL="rmi://192.168.2.89:10009/server";
/**
* @param args
*/
public static void main(String[] args) {
try {
String result=((Hello)Naming.lookup(RMI_URL)).hello();
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
5)先啟動(dòng)服務(wù)器端,然后再啟動(dòng)客戶端
顯示結(jié)果:hello world
由于涉及到的內(nèi)容比較多,打算每一篇里講一個(gè)遠(yuǎn)程通訊框架,繼續(xù)詳解RMI
三:詳解RMI內(nèi)部原理
1. RMI基本結(jié)構(gòu):包含兩個(gè)獨(dú)立的程序,服務(wù)器和客戶端,服務(wù)器創(chuàng)建多個(gè)遠(yuǎn)程對(duì)象,讓遠(yuǎn)程對(duì)象能夠被引用,等待客戶端調(diào)用這些遠(yuǎn)程對(duì)象的方法。客戶端從服務(wù)器獲取到一個(gè)或則多個(gè)遠(yuǎn)程對(duì)象的引用,然后調(diào)用遠(yuǎn)程對(duì)象方法,主要涉及到RMI接口、回調(diào)等技術(shù)。
2.RMI回調(diào):服務(wù)器提供遠(yuǎn)程對(duì)象引用供客戶端調(diào)用,客戶端主動(dòng)調(diào)用服務(wù)器,如果服務(wù)器主動(dòng)打算調(diào)用客戶端,這就叫回調(diào)。
3.命名遠(yuǎn)程對(duì)象:客戶端通過一個(gè)命名或則一個(gè)查找服務(wù)找到遠(yuǎn)程服務(wù),遠(yuǎn)程服務(wù)包含Java的命名和查找接口(Java Naming and Directory Interface)JNDI
RMI提供了一種服務(wù):RMI注冊(cè)rmiregistry,默認(rèn)端口:1099,主機(jī)提供遠(yuǎn)程服務(wù),接受服務(wù),啟動(dòng)注冊(cè)服務(wù)的命令:start rmiregistry
客戶端使用一個(gè)靜態(tài)類Naming到達(dá)RMI注冊(cè)處,通過方法lookup()方法,客戶來詢問注冊(cè)。
一:spring概要 簡單來說,Spring是一個(gè)輕量級(jí)的控制反轉(zhuǎn)(IoC)和面向切面(AOP)的容器框架。
◆
控制反轉(zhuǎn)——Spring通過一種稱作控制反轉(zhuǎn)(IoC)的技術(shù)促進(jìn)了松耦合。當(dāng)應(yīng)用了IoC,一個(gè)對(duì)象依賴的其它對(duì)象會(huì)通過被動(dòng)的方式傳遞進(jìn)來,而不是這個(gè)對(duì)象自己創(chuàng)建或者查找依賴對(duì)象。你可以認(rèn)為IoC與JNDI相反——不是對(duì)象從容器中查找依賴,而是容器在對(duì)象初始化時(shí)不等對(duì)象請(qǐng)求就主動(dòng)將依賴傳遞給它。
◆
面向切面——Spring提供了
面向切面編程的豐富支持,允許通過分離應(yīng)用的業(yè)務(wù)邏輯與系統(tǒng)級(jí)服務(wù)(例如審計(jì)(auditing)和事務(wù)(transaction)管理)進(jìn)行內(nèi)聚性的開發(fā)。應(yīng)用對(duì)象只實(shí)現(xiàn)它們應(yīng)該做的——完成業(yè)務(wù)邏輯——僅此而已。它們并不負(fù)責(zé)(甚至是意識(shí))其它的系統(tǒng)級(jí)關(guān)注點(diǎn),例如日志或事務(wù)支持。
◆
容器——Spring包含并管理應(yīng)用對(duì)象的配置和生命周期,在這個(gè)意義上它是一種容器,你可以配置你的每個(gè)bean如何被創(chuàng)建——基于一個(gè)可配置
原型(prototype),你的bean可以創(chuàng)建一個(gè)單獨(dú)的實(shí)例或者每次需要時(shí)都生成一個(gè)新的實(shí)例——以及它們是如何相互關(guān)聯(lián)的。然而,Spring不應(yīng)該被混同于傳統(tǒng)的重量級(jí)的EJB容器,它們經(jīng)常是龐大與笨重的,難以使用。
◆
框架——Spring可以將簡單的組件配置、組合成為復(fù)雜的應(yīng)用。在Spring中,應(yīng)用對(duì)象被聲明式地組合,典型地是在一個(gè)XML文件里。Spring也提供了很多基礎(chǔ)功能(事務(wù)管理、持久化框架集成等等),將應(yīng)用邏輯的開發(fā)留給了你。
所有Spring的這些特征使你能夠編寫更干凈、更可管理、并且更易于測試的代碼。它們也為Spring中的各種模塊提供了基礎(chǔ)支持。
二:spring的整個(gè)生命周期 首先說一下spring的整個(gè)初始化過程,web應(yīng)用中創(chuàng)建spring容器有兩種方式: 第一種:在web.xml里直接配置spring容器,servletcontextlistener
第二種:通過load-on-startup servlet實(shí)現(xiàn)。
主要就說一下第一種方式:
spring提供了ServletContextListener的實(shí)現(xiàn)類ContextLoaderListener,該類作為listener使用,在創(chuàng)建時(shí)自動(dòng)查找WEB-INF目錄下的applicationContext.xml,該文件是默認(rèn)查找的,如果只有一個(gè)就不需要配置初始化xml參數(shù),如果需要配置,設(shè)置contextConfigLocation為application的xml文件即可。可以好好閱讀一下ContextLoaderListener的源代碼,就可以很清楚的知道spring的整個(gè)加載過程。
spring容器的初始化代碼如下:
/** * Initialize the root web application context.
*/
public void contextInitialized(ServletContextEvent event) {
this.contextLoader = createContextLoader();
if (this.contextLoader == null) {
this.contextLoader = this;
}
this.contextLoader.initWebApplicationContext(event.getServletContext());//contextLoader初始化web應(yīng)用容器
}
繼續(xù)分析initWebApplicationContext做了什么事情:
/**
* Initialize Spring's web application context for the given servlet context,
* according to the "{@link #CONTEXT_CLASS_PARAM contextClass}" and
* "{@link #CONFIG_LOCATION_PARAM contextConfigLocation}" context-params.
* @param servletContext current servlet context
* @return the new WebApplicationContext
* @see #CONTEXT_CLASS_PARAM
* @see #CONFIG_LOCATION_PARAM
*/
public WebApplicationContext initWebApplicationContext(ServletContext servletContext) {
//首先創(chuàng)建一個(gè)spring的父容器,類似根節(jié)點(diǎn)root容器,而且只能是一個(gè),如果已經(jīng)創(chuàng)建,拋出對(duì)應(yīng)的異常
if (servletContext.getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE) != null) {
throw new IllegalStateException(
"Cannot initialize context because there is already a root application context present - " +
"check whether you have multiple ContextLoader* definitions in your web.xml!");
}
Log logger = LogFactory.getLog(ContextLoader.class);
servletContext.log("Initializing Spring root WebApplicationContext");
if (logger.isInfoEnabled()) {
logger.info("Root WebApplicationContext: initialization started");
}
long startTime = System.currentTimeMillis();
try {
// Determine parent for root web application context, if any.
ApplicationContext parent = loadParentContext(servletContext);//創(chuàng)建通過web.xml配置的父容器
具體里面的代碼是怎么實(shí)現(xiàn)的,就不在這里進(jìn)行詳解了
// Store context in local instance variable, to guarantee that
// it is available on ServletContext shutdown.
this.context = createWebApplicationContext(servletContext, parent);//主要的創(chuàng)建過程都在改方法內(nèi),可以自己去看源代碼
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context);
//把spring初始好的容器加載到servletcontext內(nèi),相當(dāng)于servletcontext包含webapplicationcontext
ClassLoader ccl = Thread.currentThread().getContextClassLoader();
if (ccl == ContextLoader.class.getClassLoader()) {
currentContext = this.context;
}
else if (ccl != null) {
currentContextPerThread.put(ccl, this.context);
}
if (logger.isDebugEnabled()) {
logger.debug("Published root WebApplicationContext as ServletContext attribute with name [" +
WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE + "]");
}
if (logger.isInfoEnabled()) {
long elapsedTime = System.currentTimeMillis() - startTime;
logger.info("Root WebApplicationContext: initialization completed in " + elapsedTime + " ms");
}
return this.context;
}
catch (RuntimeException ex) {
logger.error("Context initialization failed", ex);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, ex);
throw ex;
}
catch (Error err) {
logger.error("Context initialization failed", err);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, err);
throw err;
}
}
看到這里基本已經(jīng)清楚了整個(gè)spring容器的加載過程,如果還想了解更加深入,請(qǐng)查看我紅色標(biāo)注的方法體。
其次再說一下spring的IOC和AOP使用的場景,由于原理大家都很清楚了,那就說一下它們使用到的地方:
IOC使用的場景:
管理bean的依賴關(guān)系,目前主流的電子商務(wù)網(wǎng)站基本都采用spring管理業(yè)務(wù)層代碼的依賴關(guān)系,包括:淘寶,支付寶,阿里巴巴,百度等公司。
一:struts2概要 以WebWork優(yōu)秀設(shè)計(jì)思想為核心,吸收了struts1的部分優(yōu)點(diǎn)。
二:struts2詳解 主要就是詳解struts2與struts1之間的區(qū)別,以及為什么要采用webwork重新設(shè)計(jì)新框架,以及吸收了struts1的哪部分優(yōu)點(diǎn)。
首先將區(qū)別:- 最大的區(qū)別是與servlet成功解耦,不在依賴容器來初始化HttpServletRequest和HttpServletResponse
struts1里依賴的核心控制器為ActionServlet而struts2依賴ServletDispatcher,一個(gè)是servlet一個(gè)是filter,正是采用了filter才不至于和servlet耦合,所有的數(shù)據(jù) 都是通過攔截器來實(shí)現(xiàn),如下圖顯示:

- web層表現(xiàn)層的豐富,struts2已經(jīng)可以使用jsp、velocity、freemarker
- 線程模式方面:struts1的action是單例模式而且必須是線程安全或同步的,是struts2的action對(duì)每一個(gè)請(qǐng)求都產(chǎn)生一個(gè)新的實(shí)例,因此沒有線程安全問 題。
- 封裝請(qǐng)求參數(shù):是struts1采用ActionForm封裝請(qǐng)求參數(shù),都必須繼承ActionForm基類,而struts2通過bean的屬性封裝,大大降低了耦合。
- 類型轉(zhuǎn)換:struts1封裝的ActionForm都是String類型,采用Commons- Beanutils進(jìn)行類型轉(zhuǎn)換,每個(gè)類一個(gè)轉(zhuǎn)換器;struts2采用OGNL進(jìn)行類型轉(zhuǎn) 換,支持基本數(shù)據(jù)類型和封裝類型的自動(dòng)轉(zhuǎn)換。
- 數(shù)據(jù)校驗(yàn):struts1在ActionForm中重寫validate方法;struts2直接重寫validate方法,直接在action里面重寫即可,不需要繼承任何基類,實(shí)際的調(diào)用順序是,validate()-->execute(),會(huì)在執(zhí)行execute之前調(diào)用validate,也支持xwork校驗(yàn)框架來校驗(yàn)。
其次,講一下為什么要采用webwork來重新設(shè)計(jì)struts2
首先的從核心控制器談起,struts2的FilterDispatcher,這里我們知道是一個(gè)filter而不是一個(gè)servlet,講到這里很多人還不是很清楚web.xml里它們之間的聯(lián)系,先簡短講一下它們的加載順序,context-param(應(yīng)用范圍的初始化參數(shù))-->listener(監(jiān)聽?wèi)?yīng)用端的任何修改通知)-->filter(過濾)-->servlet。
filter在執(zhí)行servlet之間就以及調(diào)用了,所以才有可能解脫完全依賴servlet的局面,那我們來看看這個(gè)filter做了什么事情:
/** * Process an action or handle a request a static resource.
* <p/>
* The filter tries to match the request to an action mapping.
* If mapping is found, the action processes is delegated to the dispatcher's serviceAction method.
* If action processing fails, doFilter will try to create an error page via the dispatcher.
* <p/>
* Otherwise, if the request is for a static resource,
* the resource is copied directly to the response, with the appropriate caching headers set.
* <p/>
* If the request does not match an action mapping, or a static resource page,
* then it passes through.
*
* @see javax.servlet.Filter#doFilter(javax.servlet.ServletRequest, javax.servlet.ServletResponse, javax.servlet.FilterChain)
*/
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) req;
HttpServletResponse response = (HttpServletResponse) res;
ServletContext servletContext = getServletContext();
String timerKey = "FilterDispatcher_doFilter: ";
try {
// FIXME: this should be refactored better to not duplicate work with the action invocation
ValueStack stack = dispatcher.getContainer().getInstance(ValueStackFactory.class).createValueStack();
ActionContext ctx = new ActionContext(stack.getContext());
ActionContext.setContext(ctx);
UtilTimerStack.push(timerKey);
request = prepareDispatcherAndWrapRequest(request, response);
ActionMapping mapping;
try {
mapping = actionMapper.getMapping(request, dispatcher.getConfigurationManager());
} catch (Exception ex) {
log.error("error getting ActionMapping", ex);
dispatcher.sendError(request, response, servletContext, HttpServletResponse.SC_INTERNAL_SERVER_ERROR, ex);
return;
}
if (mapping == null) {
// there is no action in this request, should we look for a static resource?
String resourcePath = RequestUtils.getServletPath(request);
if ("".equals(resourcePath) && null != request.getPathInfo()) {
resourcePath = request.getPathInfo();
}
if (staticResourceLoader.canHandle(resourcePath)) {
staticResourceLoader.findStaticResource(resourcePath, request, response);
} else {
// this is a normal request, let it pass through
chain.doFilter(request, response);
}
// The framework did its job here
return;
}
dispatcher.serviceAction(request, response, servletContext, mapping);//過濾用戶請(qǐng)求,攔截器執(zhí)行,把對(duì)應(yīng)的action請(qǐng)求轉(zhuǎn)到業(yè)務(wù)action執(zhí)行 }
finally {
try {
ActionContextCleanUp.cleanUp(req);
} finally {
UtilTimerStack.pop(timerKey);
}
}
}
對(duì)應(yīng)的action參數(shù)由攔截器獲取。
解耦servlet是struts2采用webwork思路的最重要的一個(gè)原因,也迎合了整個(gè)技術(shù)的一個(gè)發(fā)展方向,解耦一直貫穿于整個(gè)框架。
JVM specification對(duì)JVM內(nèi)存的描述
首先我們來了解JVM specification中的JVM整體架構(gòu)。如下圖:
.jpg)
主要包括兩個(gè)子系統(tǒng)和兩個(gè)組件: Class loader(類裝載器) 子系統(tǒng),Execution engine(執(zhí)行引擎) 子系統(tǒng);Runtime data area (運(yùn)行時(shí)數(shù)據(jù)區(qū)域)組件, Native interface(本地接口)組件。
Class loader子系統(tǒng)的作用 :根據(jù)給定的全限定名類名(如 java.lang.Object)來裝載class文件的內(nèi)容到 Runtime data area中的method area(方法區(qū)域)。Javsa程序員可以extends java.lang.ClassLoader類來寫自己的Class loader。
Execution engine子系統(tǒng)的作用 :執(zhí)行classes中的指令。任何JVM specification實(shí)現(xiàn)(JDK)的核心是Execution engine, 換句話說:Sun 的JDK 和IBM的JDK好壞主要取決于他們各自實(shí)現(xiàn)的Execution engine的好壞。每個(gè)運(yùn)行中的線程都有一個(gè)Execution engine的實(shí)例。
Native interface組件 :與native libraries交互,是其它編程語言交互的接口。
Runtime data area 組件:這個(gè)組件就是JVM中的內(nèi)存
- 運(yùn)行時(shí)數(shù)據(jù)組件的詳解介紹:
-內(nèi)存管理.jpg)
Runtime data area 主要包括五個(gè)部分:Heap (堆), Method Area(方法區(qū)域), Java Stack(java的棧), Program Counter(程序計(jì)數(shù)器), Native method stack(本地方法棧)。Heap 和Method Area是被所有線程的共享使用的;而Java stack, Program counter 和Native method stack是以線程為粒度的,每個(gè)線程獨(dú)自擁有。
Heap
Java程序在運(yùn)行時(shí)創(chuàng)建的所有類實(shí)或數(shù)組都放在同一個(gè)堆中。而一個(gè)Java虛擬實(shí)例中只存在一個(gè)堆空間,因此所有線程都將共享這個(gè)堆。每一個(gè)java程序獨(dú)占一個(gè)JVM實(shí)例,因而每個(gè)java程序都有它自己的堆空間,它們不會(huì)彼此干擾。但是同一java程序的多個(gè)線程都共享著同一個(gè)堆空間,就得考慮多線程訪問對(duì)象(堆數(shù)據(jù))的同步問題。 (這里可能出現(xiàn)的異常java.lang.OutOfMemoryError: Java heap space)
JVM堆一般又可以分為以下三部分:
-堆.jpg)
Ø Perm
Perm代主要保存class,method,filed對(duì)象,這部門的空間一般不會(huì)溢出,除非一次性加載了很多的類,不過在涉及到熱部署的應(yīng)用服務(wù)器的時(shí)候,有時(shí)候會(huì)遇到java.lang.OutOfMemoryError : PermGen space 的錯(cuò)誤,造成這個(gè)錯(cuò)誤的很大原因就有可能是每次都重新部署,但是重新部署后,類的class沒有被卸載掉,這樣就造成了大量的class對(duì)象保存在了perm中,這種情況下,一般重新啟動(dòng)應(yīng)用服務(wù)器可以解決問題。
Ø Tenured
Tenured區(qū)主要保存生命周期長的對(duì)象,一般是一些老的對(duì)象,當(dāng)一些對(duì)象在Young復(fù)制轉(zhuǎn)移一定的次數(shù)以后,對(duì)象就會(huì)被轉(zhuǎn)移到Tenured區(qū),一般如果系統(tǒng)中用了application級(jí)別的緩存,緩存中的對(duì)象往往會(huì)被轉(zhuǎn)移到這一區(qū)間。
Ø Young
Young區(qū)被劃分為三部分,Eden區(qū)和兩個(gè)大小嚴(yán)格相同的Survivor區(qū),其中Survivor區(qū)間中,某一時(shí)刻只有其中一個(gè)是被使用的,另外一個(gè)留做垃圾收集時(shí)復(fù)制對(duì)象用,在Young區(qū)間變滿的時(shí)候,minor GC就會(huì)將存活的對(duì)象移到空閑的Survivor區(qū)間中,根據(jù)JVM的策略,在經(jīng)過幾次垃圾收集后,任然存活于Survivor的對(duì)象將被移動(dòng)到Tenured區(qū)間。
Method area
在Java虛擬機(jī)中,被裝載的class的信息存儲(chǔ)在Method area的內(nèi)存中。當(dāng)虛擬機(jī)裝載某個(gè)類型時(shí),它使用類裝載器定位相應(yīng)的
class文件,然后讀入這個(gè)class文件內(nèi)容并把它傳輸?shù)教摂M機(jī)中。緊接著虛擬機(jī)提取其中的類型信息,并將這些信息存儲(chǔ)到方法區(qū)。該類型中的類(靜態(tài))變量同樣也存儲(chǔ)在方法區(qū)中。與Heap 一樣,method area是多線程共享的,因此要考慮多線程訪問的同步問題。比如,假設(shè)同時(shí)兩個(gè)線程都企圖訪問一個(gè)名為Lava的類,而這個(gè)類還沒有內(nèi)裝載入虛擬機(jī),那么,這時(shí)應(yīng)該只有一個(gè)線程去裝載它,而另一個(gè)線程則只能等待。 (這里可能出現(xiàn)的異常java.lang.OutOfMemoryError: PermGen full)
Java stack
Java stack以幀為單位保存線程的運(yùn)行狀態(tài)。虛擬機(jī)只會(huì)直接對(duì)Java stack執(zhí)行兩種操作:以幀為單位的壓棧或出棧。每當(dāng)線程調(diào)用一個(gè)方法的時(shí)候,就對(duì)當(dāng)前狀態(tài)作為一個(gè)幀保存到
java stack中(壓棧);當(dāng)一個(gè)方法調(diào)用返回時(shí),從java stack彈出一個(gè)幀(出棧)。棧的大小是有一定的限制,這個(gè)可能出現(xiàn)StackOverFlow問題。 下面的程序可以說明這個(gè)問題。
public class TestStackOverFlow {
public static void main(String[] args) {
Recursive r = new Recursive();
r.doit(10000);
// Exception in thread "main" java.lang.StackOverflowError
}
}
class Recursive {
public int doit(int t) { if (t <= 1) { return 1;
}
return t + doit(t - 1);
}
}
Program counter
每個(gè)運(yùn)行中的Java程序,每一個(gè)線程都有它自己的PC寄存器,也是該線程啟動(dòng)時(shí)創(chuàng)建的。PC寄存器的內(nèi)容總是指向下一條將被執(zhí)行指令的餓“地址”,這里的“地址”可以是一個(gè)本地指針,也可以是在方法區(qū)中相對(duì)應(yīng)于該方法起始指令的偏移量。
Native method stack
對(duì)于一個(gè)運(yùn)行中的Java程序而言,它還能會(huì)用到一些跟本地方法相關(guān)的數(shù)據(jù)區(qū)。當(dāng)某個(gè)線程調(diào)用一個(gè)本地方法時(shí),它就進(jìn)入了一個(gè)全新的并且不再受虛擬機(jī)限制的世界。本地方法可以通過本地方法接口來訪問虛擬機(jī)的運(yùn)行時(shí)數(shù)據(jù)區(qū),不止與此,它還可以做任何它想做的事情。比如,可以調(diào)用寄存器,或在操作系統(tǒng)中分配內(nèi)存等。總之,本地方法具有和JVM相同的能力和權(quán)限。 (這里出現(xiàn)JVM無法控制的內(nèi)存溢出問題native heap OutOfMemory )
JVM提供了相應(yīng)的參數(shù)來對(duì)內(nèi)存大小進(jìn)行配置。
-堆參數(shù).jpg)
正如上面描述,JVM中堆被分為了3個(gè)大的區(qū)間,同時(shí)JVM也提供了一些選項(xiàng)對(duì)Young,Tenured的大小進(jìn)行控制。
Ø Total Heap
-Xms :指定了JVM初始啟動(dòng)以后初始化內(nèi)存
-Xmx:指定JVM堆得最大內(nèi)存,在JVM啟動(dòng)以后,會(huì)分配-Xmx參數(shù)指定大小的內(nèi)存給JVM,但是不一定全部使用,JVM會(huì)根據(jù)-Xms參數(shù)來調(diào)節(jié)真正用于JVM的內(nèi)存
-Xmx -Xms之差就是三個(gè)Virtual空間的大小
Ø Young Generation
-XX:NewRatio=8意味著tenured 和 young的比值8:1,這樣eden+2*survivor=1/9
堆內(nèi)存
-XX:SurvivorRatio=32意味著eden和一個(gè)survivor的比值是32:1,這樣一個(gè)Survivor就占Young區(qū)的1/34.
-Xmn 參數(shù)設(shè)置了年輕代的大小
Ø Perm Generation
-XX:PermSize=16M -XX:MaxPermSize=64M
Thread Stack
-XX:Xss=128K
1.數(shù)據(jù)量大以及訪問量很大的表,必須建立索引
2.不要在建立了索引的字段上做以下操作: ◆避免對(duì)索引字段進(jìn)行計(jì)算操作
◆避免在索引列上使用IS NULL和IS NOT NULL
◆避免在索引列上出現(xiàn)數(shù)據(jù)類型轉(zhuǎn)換
◆避免建立索引的列中使用空值
3.避免復(fù)雜的操作:
◆sql語句里出現(xiàn)多重查詢嵌套
◆避免建立過多的表關(guān)聯(lián),較少關(guān)聯(lián)關(guān)系
4.減少模糊查詢:避免使用like語句,盡量把結(jié)果比較放到應(yīng)用服務(wù)器端,通過java代碼過濾5.WHERE的使用
◆避免對(duì)where條件采用計(jì)算
◆避免在where條件中使用in,not in,or或則havin,可以使用 exist 和not exist代替 in和not in
◆不要以字符格式聲明數(shù)字,要以數(shù)字格式聲明字符值,否則索引將失效
6.采用臨時(shí)表
數(shù)據(jù)庫端性能非常低- 優(yōu)化數(shù)據(jù)庫服務(wù)器端的配置參數(shù)
- 應(yīng)用服務(wù)器端數(shù)據(jù)連接池的配置參數(shù)修改
- 應(yīng)用服務(wù)器端的sql審核,建立更好的索引以及修改不好的sql語句:關(guān)聯(lián)表過多,查詢的數(shù)據(jù)量過大,表設(shè)計(jì)不合理等
- 應(yīng)用服務(wù)器端拆解過大的表,分為多張表,甚至把一個(gè)數(shù)據(jù)庫分為多個(gè)數(shù)據(jù)庫
- 數(shù)據(jù)庫服務(wù)器端拆解為讀/寫分離,Master/Slave方式,一臺(tái)寫主機(jī)對(duì)應(yīng)兩臺(tái)或則多臺(tái)讀的備用機(jī)器
應(yīng)用服務(wù)器端- 訪問壓力過大,1臺(tái)機(jī)器不能承受,該為多臺(tái)機(jī)器,應(yīng)用服務(wù)器配置為集群模式
1. 多線程概念:
線程是指進(jìn)程中的一個(gè)執(zhí)行流程,一個(gè)進(jìn)程中可以運(yùn)行多個(gè)線程。比如java.exe進(jìn)程中可以運(yùn)行很多線程。線程總是屬于某個(gè)進(jìn)程,進(jìn)程中的多個(gè)線程共享進(jìn)程的內(nèi)存。
- 多線程的實(shí)現(xiàn)方式和啟動(dòng)
- 多線程是依靠什么方式解決資源競爭
- 多線程的各種狀態(tài)以及優(yōu)先級(jí)
- 多線程的暫停方式
2. 多線程詳解 1)多線程的實(shí)現(xiàn)方式和啟動(dòng):- 繼承Thread和是實(shí)現(xiàn)Runnable接口,重寫run方法
- 啟動(dòng)只有一種方式:通過start方法,虛擬機(jī)會(huì)調(diào)用run方法
2) 多線程依靠什么解決資源競爭- 鎖機(jī)制:分為對(duì)象鎖和類鎖,在多個(gè)線程調(diào)用的情況,每個(gè)對(duì)象鎖都是唯一的,只有獲取了鎖才能調(diào)用synchronized方法
- synchronize同步:分為同步方法和同步方法塊
- 什么時(shí)候獲取鎖:每次調(diào)用到synchronize方法,這個(gè)時(shí)候去獲取鎖資源,如果線程獲取到鎖則別的線程只有等到同步方法介紹后,釋放鎖后,別的線程 才能繼續(xù)使用
3)線程的幾種狀態(tài)- 主要分為:新狀態(tài)(還沒有調(diào)用start方法),可執(zhí)行狀態(tài)(調(diào)用start方法),阻塞狀態(tài),死亡狀態(tài)
默認(rèn)優(yōu)先級(jí)為normal(5),優(yōu)先級(jí)數(shù)值在1-10之間
4) 多線程的暫停方式- sleep:睡眠單位為毫秒
- wait,waitAll,notify,notifyAll,wait等待,只有通過wait或者waitAll喚醒
- yield:cpu暫時(shí)停用
- join
- HashSet概要:
- 采用HashMap存儲(chǔ),key直接存取值,value存儲(chǔ)一個(gè)object
- 存儲(chǔ)的key值是唯一的
- HashSet中元素的順序是隨機(jī)的,包括添加(add())和輸出都是無序的
代碼就不具體詳解了,主要就是通過封裝HashMap組成。
1.Hashtable概要:實(shí)現(xiàn)Map接口的同步實(shí)現(xiàn)- 線程安全
- 不能存儲(chǔ)null到key和value
- HashTable中hash數(shù)組默認(rèn)大小是11,增加的方式是 old*2+1。HashMap中hash數(shù)組的默認(rèn)大小是16,而且一定是2的指數(shù)
區(qū)別 | Hashtable | Hashmap |
繼承、實(shí)現(xiàn) | Hashtable extends Dictionaryimplements Map, Cloneable,Serializable | HashMap extends AbstractMap implements Map, Cloneable,Serializable |
線程同步 | 已經(jīng)同步過的可以安全使用 | 未同步的,可以使用Colletcions進(jìn)行同步Map Collections.synchronizedMap(Map m) |
對(duì)null的處理
| Hashtable table = new Hashtable(); table.put(null, "Null"); table.put("Null", null); table.contains(null); table.containsKey(null); table.containsValue(null); 后面的5句話在編譯的時(shí)候不會(huì)有異常,可在運(yùn)行的時(shí)候會(huì)報(bào)空指針異常具體原因可以查看源代碼 public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } | HashMap map = new HashMap();
map.put(null, "Null"); map.put("Null", null); map.containsKey(null); map.containsValue(null); 以上這5條語句無論在編譯期,還是在運(yùn)行期都是沒有錯(cuò)誤的. 在HashMap中,null可以作為鍵,這樣的鍵只有一個(gè);可以有一個(gè)或多個(gè)鍵所對(duì)應(yīng)的值為null。當(dāng)get()方法返回null值時(shí),即可以表示 HashMap中沒有該鍵,也可以表示該鍵所對(duì)應(yīng)的值為null。因此,在HashMap中不能由get()方法來判斷HashMap中是否存在某個(gè)鍵,而應(yīng)該用containsKey()方法來判斷。 |
增長率 | protected void rehash() { int oldCapacity = table.length; Entry[] oldMap = table; int newCapacity = oldCapacity * 2 + 1; Entry[] newMap = new Entry[newCapacity]; modCount++; threshold = (int)(newCapacity * loadFactor); table = newMap; for (int i = oldCapacity ; i-- > 0 ;) { for (Entry old = oldMap[i] ; old != null ; ) { Entry e = old; old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = newMap[index]; newMap[index] = e; } } }
| void addEntry(int hash, K key, V value, int bucketIndex) { Entry e = table[bucketIndex]; table[bucketIndex] = new Entry(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length); }
|
哈希值的使用 | HashTable直接使用對(duì)象的hashCode,代碼是這樣的: public synchronized booleancontainsKey(Object key) { Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry e = tab[index] ; e !=null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return true; } } return false; } | HashMap重新計(jì)算hash值,而且用與代替求模 public boolean containsKey(Object key) { Object k = maskNull(key); int hash = hash(k.hashCode()); int i = indexFor(hash, table.length); Entry e = table[i]; while (e != null) { if (e.hash == hash && eq(k, e.key)) return true; e = e.next; } return false; } |
主站蜘蛛池模板:
东乡|
辽宁省|
天门市|
普宁市|
北票市|
宜丰县|
澄城县|
女性|
忻城县|
邢台县|
木兰县|
沁阳市|
彭水|
奎屯市|
南部县|
普兰县|
兴义市|
商丘市|
界首市|
城步|
大化|
兴仁县|
木兰县|
房山区|
康定县|
滨海县|
威远县|
兴城市|
镇雄县|
靖远县|
湘阴县|
石嘴山市|
德昌县|
深州市|
亳州市|
宁南县|
康乐县|
马公市|
龙胜|
宁河县|
建湖县|