摘要: 提起Java內部類(Inner Class)可能很多人不太熟悉,實際上類似的概念在C++里也有,那就是嵌套類(Nested Class),關于這兩者的區別與聯系,在下文中會有對比。內部類從表面上看,就是在類中又定義了一個類(下文會看到,內部類可以在很多地方定義),而實際上并沒有那么簡單,乍看上去內部類似乎有些多余,它的用處對于初學者來說可能并不是那么顯著,但是隨著對它的深入了解,你會發現Java的...
閱讀全文
posted @
2010-06-30 14:26 J2EE學習筆記 閱讀(312) |
評論 (0) |
編輯 收藏在JScript的眾多運算符里,提供了三個邏輯運算符&&、||和!,噢?! 是高級語言都提供的 。按我們對邏輯運算的正常認識,邏輯運算的結果因該是ture或者false。但是JScript的邏輯運算卻不完全是這么定義的,這里只有!運算符總是返回true|false,而||和&&運算比較的好玩。
。按我們對邏輯運算的正常認識,邏輯運算的結果因該是ture或者false。但是JScript的邏輯運算卻不完全是這么定義的,這里只有!運算符總是返回true|false,而||和&&運算比較的好玩。
JScript對于邏輯運算的true|false是這么定義的:
- 所有對象都被認為是 true。
- 字符串當且僅當為空(""或'')時才被認為是 false。
- null 和未定義的均被認為是 false。
- 數字當且僅當為 0 時才是 false。
可是邏輯運算符||和&&雖然遵循上面的定義規則,但是它們返回的值卻很有意思。
對于&&運算,按照上面的規則,表達式 if ( 'abc' && '123' && new Date() ) 是執行true分支,可是這個表達式如果寫成:
 var value = 'abc' && '123' && new Date();
var value = 'abc' && '123' && new Date();
結果value=Fri Jan 21 00:01:17 UTC+0800 2005,原它從左到右檢測,如果到了最后一個表達式也是為true的,就返回那個表達式。
對于||運算同理,對于下面的表達式:
var value1 = 'abc' || '123' || null || false;
var value2 = null || '' || false || 'ok';
結果value1='abc',value2='ok'。這是因為||運算會有"短路"特性,他也是從左向右檢測,只不過它是一但發現有為true的值,就立即返回該表達式。
這樣的特性可以幫組我們寫出精簡的代碼,可是同時也帶來代碼不便于閱讀維護的問題。
由于我手頭暫時沒有NS和moz什么的瀏覽器,不知道標準JavaScript是否也是這樣支持的?如果您方便的話,請告如我運行后的結果
posted @
2010-05-13 15:11 J2EE學習筆記 閱讀(192) |
評論 (0) |
編輯 收藏有時你可能需要對變量進行類型檢查,或者判斷變量是否已定義。有兩種方法可以使用:typeof函數與constructor屬性。
typeof函數的用法可能不用我多說,大家都知道怎么用。而constructor屬性大家可能就陌生點。在《精通JavaScript》這本書中有提到construct的用法,但我用自己的幾個瀏覽器(IE7.0 / Firefox1.9 / Opera9.50)測試的結果卻和書上說的不一樣。但是仍然是有辦法通過constructor屬性來檢查變量類型的。
這里先補充一下,為什么明明有typeof函數可以很方便地用來檢測類型,還要用constructor呢?
因為typeof會把所有的數組類型以及用戶自定義類型判斷為object,從而無法知道更確切的信息。而constructor卻可以解決這個問題。
ok,明白了我們為什么要用constructor,現在讓我帶大家一步步認識一下typeof和constructor用法之間的差異吧~
首先我們運行一下下面這段代碼:
var i;
alert(typeof(i));
alert(i.constructor);
這3行代碼告訴你什么情況下可以用constructor。
你可以看到第2行返回了字符串'undefined',而第三行則發生了錯誤,原因是i變量還沒有類型定義,自然也沒有constructor的存在。
從這一點上看,typeof可以檢查到變量是否有定義,而construct只能檢查已定義變量的類型。
再運行一下下面這段代碼:
var i = 2;
alert(typeof(i));
alert(i.constructor);
alert(typeof(i.constructor));
你會看到第2行返回了字符串'number’,第3行返回了一串類似函數定義的代碼字符串(這就是跟《精通JavaScript》一書中介紹的不一樣的地方)。
我們再用typeof檢查一下constructor到底是個什么樣類型的屬性,第4行返回結果'function',也就是說,實際上constructor是一個函數,更確切地說是一個構造函數。這時你就可以知道,為什么constructor可以檢查出各種類型了。
有經驗的程序員看到這里應該知道要怎么利用constructor來檢查變量類型了。方法有多種,這里提供一種比較容易理解的方法。
其實想法很簡單,就是把construcor轉化為字符串,通過尋找匹配字符串(function名)來確定是否指定類型。如下例子:

 function user()
function user()  {};
{};
var i = new user();
alert((i.constructor+'').match(/user/) == null);
這僅僅是個簡單的例子。如果返回true則變量i不是user類型,返回false則變量是user類型。
當然,這樣檢測是不夠精確的,比如其實他是一個myuser類型的時候,同樣會被認為是user類。所以你需要書寫更精確的正則表達式去進行匹配。
可以這樣簡單改進你的正則表達式:
/function user\(\)/
替換上面代碼段中的/user/。當然,如果你的構造函數原型是user(a),那么應該這樣書寫你的正則表達式:
/function user\(a\)/
到這里你應該知道怎樣使用constructor類型去檢查變量類型了吧?
ok,最后再提個醒,如果你要用基于constructor的方法去檢查一些基本類型,如
Object / Array / Function / String / Number / Boolean
在你的正則表達式中,一定要將這些單詞的首字母大寫!!而如果該類型是自定義類型,則根據你定義的時候標識符的寫法確定。
posted @
2010-04-14 14:30 J2EE學習筆記 閱讀(325) |
評論 (0) |
編輯 收藏/** *//**
 使用三種Callback接口作為參數的query方法的返回值不同:
使用三種Callback接口作為參數的query方法的返回值不同:
以ResultSetExtractor作為方法參數的query方法返回Object型結果,要使用查詢結果,我們需要對其進行強制轉型;
以RowMapper接口作為方法參數的query方法直接返回List型的結果;
以RowCallbackHandler作為方法參數的query方法,返回值為void;
RowCallbackHandler和RowMapper才是我們最常用的選擇
* @author Administrator
*
 */
*/
public class SpringTest {

 /** *//**
/** *//**
* 返回結果是List里裝Map,使用參數,使用回調 RowMapperResultSetExtractor用于處理單行記錄,
* 它內部持有一個RowMapper實例的引用,當處理結果集的時候, 會將單行數據的處理委派給其所持有的RowMapper實例,而其余工作它負責
 */
*/
public void getListRowMapperResultSetExtractor() {
ApplicationContext context = new FileSystemXmlApplicationContext(
"src/database_config.xml");
// E:\demoworkspace\spring 為工程主目錄
JdbcTemplate jt = new JdbcTemplate((DataSource) context
.getBean("oracleDataSourceTest")); // 測試用的方法
Object[] arg = new Object[] { 10 };
List list = (ArrayList) jt.query("select * from region where rownum<?",
arg, new RowMapperResultSetExtractor(new RowMapper() {
public Object mapRow(ResultSet rs, int index)
throws SQLException {
Map u = new HashMap(); //可以是自己的JavaBean值對象(簡單Java對象POJO)
u.put("region_id", rs.getString("region_id"));
u.put("region_name", rs.getString("region_name"));
return u;
}
}));
Iterator it = list.iterator();
while (it.hasNext()) {
Map map = (Map) it.next();
System.out.println(map.toString());
}
}
/** *//**返回結果是List里裝Map,不使用參數,使用回調
使用RowMapper比直接使用ResultSetExtractor要方便的多,只負責處理單行結果就行,現在,我們只需要將單行的結果組裝后返回就行,
剩下的工作,全部都是JdbcTemplate內部的事情了。 實際上,JdbcTemplae內部會使用一個ResultSetExtractor實現類來做其余的工作,
畢竟,該做的工作還得有人做不是?!
*/
public void getListRowMapper() {
ApplicationContext context = new FileSystemXmlApplicationContext(
"src/database_config.xml");
JdbcTemplate jt = new JdbcTemplate((DataSource) context
.getBean("oracleDataSourceTest"));
List list = jt.query(
"select * from region where rownum<10", new RowMapper() {
public Object mapRow(ResultSet rs, int index)
throws SQLException {
Map u = new HashMap();
u.put("region_id", rs.getString("region_id"));
u.put("region_name", rs.getString("region_name"));
return u;
}
});
Iterator it = list.iterator();
while (it.hasNext()) {
Map map = (Map) it.next();
System.out.println(map.toString());
}
}
// 返回記錄集
/** *//**
RowCallbackHandler雖然與RowMapper同是處理單行數據,不過,除了要處理單行結果,它還得負責最終結果的組裝和獲取工作,
在這里我們是使用當前上下文聲明的List取得最終查詢結果, 不過,我們也可以單獨聲明一個RowCallbackHandler實現類,
在其中聲明相應的集合類,這樣,我們可以通過該RowCallbackHandler實現類取得最終查詢結果
*/
public void getListRowCallbackHandler() {
ApplicationContext context = new FileSystemXmlApplicationContext(
"src/database_config.xml");
JdbcTemplate jt = new JdbcTemplate((DataSource) context
.getBean("oracleDataSourceTest"));
String sql = "select * from region where region_id>?";
final List<Map> list=new ArrayList<Map>(); //一定要用final定義
Object[] params = new Object[] { 0 };
jt.query(sql, params, new RowCallbackHandler() {
public void processRow(ResultSet rs) throws SQLException {
Map u = new HashMap();
u.put("region_id", rs.getString("region_id"));
u.put("region_name", rs.getString("region_name"));
list.add(u);
}
});
Iterator it = list.iterator();
while (it.hasNext()) {
Map map = (Map) it.next();
System.out.println(map.toString());
}
}
posted @
2010-03-10 10:27 J2EE學習筆記 閱讀(574) |
評論 (0) |
編輯 收藏
摘要: 1.springJdbcContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
&nb...
閱讀全文
posted @
2010-03-09 19:10 J2EE學習筆記 閱讀(2023) |
評論 (0) |
編輯 收藏很多朋友在深入的接觸JAVA語言后就會發現這樣兩個詞:反射(Reflection)和內省(Introspector),經常搞不清楚這到底是怎么回事,在什么場合下應用以及如何使用?今天把這二者放在一起介紹,因為它們二者是相輔相成的。
反射
相對而言,反射比內省更容易理解一點。用一句比較白的話來概括,反射就是讓你可以通過名稱來得到對象(類,屬性,方法)的技術。例如我們可以通過類名來生成一個類的實例;知道了方法名,就可以調用這個方法;知道了屬性名就可以訪問這個屬性的值。
還是寫兩個例子讓大家更直觀的了解反射的使用方法:
// 通過類名來構造一個類的實例
Class cls_str = Class.forName( "java.lang.String" );
// 上面這句很眼熟,因為使用過 JDBC 訪問數據庫的人都用過 J
Object str = cls_str.newInstance();
// 相當于 String str = new String();
// 通過方法名來調用一個方法
String methodName = "length" ;
Method m = cls_str.getMethod(methodName, null );
System.out.println( "length is " + m.invoke(str, null ));
// 相當于 System.out.println(str.length());
上面的兩個例子是比較常用方法。看到上面的例子就有人要發問了:為什么要這么麻煩呢?本來一條語句就完成的事情干嗎要整這么復雜?沒錯,在上面的例子中確實沒有必要這么麻煩。不過你想像這樣一個應用程序,它支持動態的功能擴展,也就是說程序不重新啟動但是可以自動加載新的功能,這個功能使用一個具體類來表示。首先我們必須為這些功能定義一個接口類,然后我們要求所有擴展的功能類必須實現我指定的接口,這個規定了應用程序和可擴展功能之間的接口規則,但是怎么動態加載呢?我們必須讓應用程序知道要擴展的功能類的類名,比如是test.Func1,當我們把這個類名(字符串)告訴應用程序后,它就可以使用我們第一個例子的方法來加載并啟用新的功能。這就是類的反射,請問你有別的選擇嗎?
內省
內省是Java語言對Bean類屬性、事件的一種缺省處理方法。例如類A中有屬性name,那我們可以通過getName,setName來得到其值或者設置新的值。通過getName/setName來訪問name屬性,這就是默認的規則。Java中提供了一套API用來訪問某個屬性的getter/setter方法,通過這些API可以使你不需要了解這個規則(但你最好還是要搞清楚),這些API存放于包java.beans中。
一般的做法是通過類Introspector來獲取某個對象的BeanInfo信息,然后通過BeanInfo來獲取屬性的描述器(PropertyDescriptor),通過這個屬性描述器就可以獲取某個屬性對應的getter/setter方法,然后我們就可以通過反射機制來調用這些方法。下面我們來看一個例子,這個例子把某個對象的所有屬性名稱和值都打印出來:
/**//*
* Created on 2004-6-29
*/
package demo;
import java.beans.BeanInfo;
import java.beans.Introspector;
import java.beans.PropertyDescriptor;
/** *//**
* 內省演示例子
* @author liudong
*/
public class IntrospectorDemo {
String name;
public static void main(String[] args) throws Exception{
IntrospectorDemo demo = new IntrospectorDemo();
demo.setName( "Winter Lau" );
// 如果不想把父類的屬性也列出來的話,
// 那 getBeanInfo 的第二個參數填寫父類的信息
BeanInfo bi = Introspector.getBeanInfo(demo.getClass(), Object. class );
PropertyDescriptor[] props = bi.getPropertyDescriptors();
for ( int i=0;i<props.length;i++){
System.out.println(props[i].getName()+ "=" +
props[i].getReadMethod().invoke(demo, null ));
}
}
public String getName() {
return name;
}
public void setName(String name) {
this .name = name;
}
}
Web開發框架Struts中的FormBean就是通過內省機制來將表單中的數據映射到類的屬性上,因此要求FormBean的每個屬性要有getter/setter方法。但也并不總是這樣,什么意思呢?就是說對一個Bean類來講,我可以沒有屬性,但是只要有getter/setter方法中的其中一個,那么Java的內省機制就會認為存在一個屬性,比如類中有方法setMobile,那么就認為存在一個mobile的屬性,這樣可以方便我們把Bean類通過一個接口來定義而不用去關系具體實現,不用去關系Bean中數據的存儲。比如我們可以把所有的getter/setter方法放到接口里定義,但是真正數據的存取則是在具體類中去實現,這樣可提高系統的擴展性。
總結
將Java的反射以及內省應用到程序設計中去可以大大的提供程序的智能化和可擴展性。有很多項目都是采取這兩種技術來實現其核心功能,例如我們前面提到的Struts,還有用于處理XML文件的Digester項目,其實應該說幾乎所有的項目都或多或少的采用這兩種技術。在實際應用過程中二者要相互結合方能發揮真正的智能化以及高度可擴展性。
posted @
2010-02-04 13:42 J2EE學習筆記 閱讀(381) |
評論 (1) |
編輯 收藏
摘要: 原文出處:http://blog.chenlb.com/2008/11/join-or-countdownlatch-make-main-thread-wait-all-sub-thread.html
在編寫多線程的工作中,有個常見的問題:主線程(main) 啟動好幾個子線程(task)來完成并發任務,主線程要等待所有的子線程完成之后才繼續執行main的其它任務。
默認主線程退出時其它子線程不...
閱讀全文
posted @
2010-01-26 18:00 J2EE學習筆記 閱讀(1211) |
評論 (0) |
編輯 收藏這是jQuery里常用的2個方法。
他們2者功能是完全不同的,而初學者往往會被誤導。
首先 我們看.find()方法:
現在有一個頁面,里面HTML代碼為:
<div class="css">
<p class="rain">測試1</p>
</div>
<div class="rain">
<p>測試2</p>
</div>
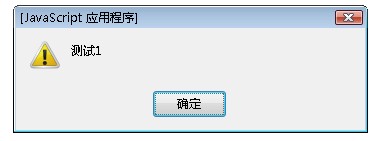
如果我們使用find()方法:
var $find = $("div").find(".rain");
alert( $find.html() );
將會輸出:
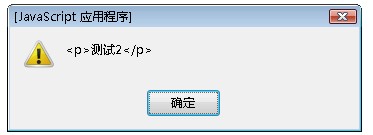
如果使用filter()方法:
var $filter = $("div").filter(".rain");
alert( $filter.html() );
將會輸出:
也許你已經看出它們的區別了。
find()會在div元素內 尋找 class為rain 的元素。
而filter()則是篩選div的class為rain的元素。
一個是對它的子集操作,一個是對自身集合元素篩選。
另外find()其實還可以用選擇器表示:
var $select = $("div .rain");
posted @
2009-11-09 16:00 J2EE學習筆記 閱讀(382) |
評論 (0) |
編輯 收藏以前在Windows上ssh登錄一直都是用putty,雖然它簡單小巧,但畢竟缺少很多特性。今天試了一下SecureCRT,感覺用起來比Putty好多了,但SecureCRT默認的字體超難看,而且中文字體設置也比較麻煩一點,在這里記錄一下以后可能還用得到。
- 在“會話選項”的“終端->仿真”里面選“Linux”,如果需要顯示顏色的話需要把“ANSI顏色”選上
- 在“外觀->字體”中選擇喜歡的字體,但這里對字體是有要求的,只有等寬字體才行。如果要正常顯示中文的話,所選擇的字體還必須包含中文字符。
- 另外就是根據你要登錄的主機的字符編碼選擇字符編碼,一般是 “UTF-8″
簡單的幾步下來就設置好了,如果還有亂碼的話就退出然后重新登陸一下。如果你想所有的連接都使用這個默認配置,可以在“全局選項”中設置“默認的會話選項”,這樣以后新建的連接會自動應用上面的設置了。
PS:
以前用putty的時候,字體就直接用我在Linux最愛的Monaco,但在SecureCRT中用Monaco字體的話,中文會顯示為亂碼,這是因為Monaco字體中不包含中文字符,而SecureCRT也不會自動的選擇系統默認的中文字體。
為了解決這個問題,我們只要去找一個包含中文的等寬字體來用,我從網上找了一個Consolas和雅黑的混合字體,雖然沒有Monaco好看,但效果也還不錯。這里有個地方需要注意一下,在選擇這個字體的字體選擇對話框中,字體的默認字符集是“西方”,需要改成CHINESE_GB2312。
如果你也想用這個字體的話,可以從這里下載。
posted @
2009-09-14 14:14 J2EE學習筆記 閱讀(6066) |
評論 (0) |
編輯 收藏這些操作對經常使用hibernate的同學已經很熟悉了,我也經常用但一些細節并不了解,
最近遇到問題才開始有看了一下。
在讀完robbin的這兩個精華貼的時候,感覺清晰了很多,確實好文章。
http://www.javaeye.com/topic/2712
http://www.javaeye.com/topic/1604?page=1
還有這個精華貼
http://www.javaeye.com/topic/7484
也很不錯。
里面總結的很好了,我結合以上三個帖子、自己的試驗(版本hibernate-3.0.5)和Hibernate文檔也總結了一點,加深理解。希望對剛開始學Hibernate的同學有所幫助。
一、saveorUpdate與unsaved-value
到底是sava還是update
Hibernate需要判斷被操作的對象究竟是一個已經持久化過的持久對象還是臨時對象。
1).主鍵Hibernate的id generator產生
<id name="id" type="java.lang.Long">
<column name="ID" precision="22" scale="0" />
<generator class="increment" />
</id>
Project project = new Project();
project.setId(XXX);
this.projectDao.saveOrUpdate(project);
1、默認unsaved-value="null"
主鍵是對象類型,hebernate判斷project的主鍵是否位null,來判斷project是否已被持久化
是的話,對project對象發送save(project),
若自己設置了主鍵則直接生成update的sql,發送update(project),即便數據庫里沒有那條記錄。
主鍵是基本類型如int/long/double/
自己設置unsaved-null="0"。
所以這樣的話save和update操作肯定不會報錯。
2、unsaved-value="none",
由于不論主鍵屬性為任何值,都不可能為none,因此Hibernate總是對project對象發送update(project)
3、unsaved-value="any"
由于不論主鍵屬性為任何值,都肯定為any,因此Hibernate總是對project對象發送save(project),hibernate生成主鍵。
Hibernate文檔中寫到
saveOrUpdate()完成了如下工作:
如果對象已經在這個session中持久化過了,什么都不用做
如果對象沒有標識值,調用save()來保存它
如果對象的標識值與unsaved-value中的條件匹配,調用save()來保存它
如果對象使用了版本(version或timestamp),那么除非設置unsaved-value="undefined",版本檢查會發生在標識符檢查之前.
如果這個session中有另外一個對象具有同樣的標識符,拋出一個異常
2).主鍵由自己來賦值
<id name="id" type="java.lang.Long">
<column name="ID" precision="22" scale="0" />
<generator class="assigned" />
</id>
Project project = new Project();
project.setId(XXX);
this.projectDao.saveOrUpdate(project);
1、默認unsaved-value="null"
這時有所不同,hibernate會根據主鍵產生一個select,來判斷此對象是否已被持久化
已被持久化則update,未被持久化則save。
2、unsaved-value="none",update對象,同上
3、unsaved-value="any" ,save對象,
如果自己自己設置的ID在數據庫中已存在,則報錯。
二、save與update操作
顯式的使用session.save()或者session.update()操作一個對象的時候,實際上是用不到unsaved-value的
在同一Session,save沒什么可說得
update對象時, 最直接的更改一個對象的方法就是load()它,保持Session打開,然后直接修改即可:
Session s =…
Project p = (Project) sess.load(Project.class, id) );
p.setName(“test”);
s.flush();
不用調用s.update(p);hibernate能察覺到它的變化,會自動更新。當然顯示調用的話也不會錯
Hibernate文檔中寫到
update()方法在下列情形下使用:
程序在前面的session中裝載了對象
對象被傳遞到UI(界面)層
對該對象進行了一些修改
對象被傳遞回業務層
應用程序在第二個session中調用update()保存修改
三、delete操作
刪除時直接自己構造一個project即可刪除
this.projectDao.delete(preojct);
以前刪除我是這樣寫的
public void deleteProject(String id) {
Project project = (Project) this.projectDao.get(Project.class, id);
if (project != null) {
this.projectDao.delete(project);
}
即這樣也是可以的
Project project = new Project();
project.setId(id);
this.projectDao.delete(project).
如果有級聯關系,需要把級聯的子類也構造出來add進去,同樣可以刪除。
好了,羅嗦的夠多了。
posted @
2009-08-27 14:44 J2EE學習筆記 閱讀(502) |
評論 (0) |
編輯 收藏
Session session = ;
Transaction tx = ;
Parent parent = (Parent); session.load(Parent.class, id);;
Child child = new Child();;
child.setParent(parent);;
child.setName("sun");;
parent.addChild(child);;
s.update(parent);;
s.flush();;
tx.commit();;
s.close();;
在上例中,程序并沒有顯式的session.save(child); 那么Hibernate需要知道child究竟是一個臨時對象,還是已經在數據庫中有的持久對象。如果child是一個新創建的臨時對象(本例中就是這種情況),那么Hibernate應該自動產生session.save(child)這樣的操作,如果child是已經在數據庫中有的持久對象,那么Hibernate應該自動產生session.update(child)這樣的操作。
因此我們需要暗示一下Hibernate,究竟child對象應該對它自動save還是update。在上例中,顯然我們應該暗示Hibernate對child自動save,而不是自動update。那么Hibernate如何判斷究竟對child是save還是update呢?它會取一下child的主鍵屬性 child.getId() ,這里假設id是 java.lang.Integer類型的。如果取到的Id值和hbm映射文件中指定的unsave-value相等,那么Hibernate認為child是新的內存臨時對象,發送save,如果不相等,那么Hibernate認為child是已經持久過的對象,發送update。
unsaved-value="null" (默認情況,適用于大多數對象類型主鍵 Integer/Long/String/...)
當Hibernate取一下child的Id,取出來的是null(在上例中肯定取出來的是null),和unsaved-value設定值相等,發送save(child)
當Hibernate取一下child的id,取出來的不是null,那么和unsaved-value設定值不相等,發送update(child)
例如下面的情況:
Session session = ;
Transaction tx = ;
Parent parent = (Parent); session.load(Parent.class, id);;
Child child = (Child); session.load(Child.class, childId);;
child.setParent(parent);;
child.setName("sun");;
parent.addChild(child);;
s.update(parent);;
s.flush();;
tx.commit();;
s.close();;
child已經在數據庫中有了,是一個持久化的對象,不是新創建的,因此我們希望Hibernate發送update(child),在該例中,Hibernate取一下child.getId(),和unsave-value指定的null比對一下,發現不相等,那么發送update(child)。
BTW: parent對象不需要操心,因為程序顯式的對parent有load操作和update的操作,不需要Hibernate自己來判斷究竟是save還是update了。我們要注意的只是child對象的操作。另外unsaved-value是定義在Child類的主鍵屬性中的。
<class name="Child" table="child">
<id column="id" name="id" type="integer" unsaved-value="null">
<generator class="identity"/>
</id>
</class>
如果主鍵屬性不是對象型,而是基本類型,如int/long/double/...,那么你需要指定一個數值型的unsaved-value,例如:
unsaved-value="0"
在此提醒大家,很多人以為對主鍵屬性定義為int/long,比定義為Integer/Long運行效率來得高,認為基本類型不需要進行對象的封裝和解構操作,因此喜歡把主鍵定義為int/long的。但實際上,Hibernate內部總是把主鍵轉換為對象型進行操作的,就算你定義為int/long型的,Hibernate內部也要進行一次對象構造操作,返回給你的時候,還要進行解構操作,效率可能反而低也說不定。因此大家一定要扭轉一個觀點,在Hibernate中,主鍵屬性定義為基本類型,并不能夠比定義為對象型效率來的高,而且也多了很多麻煩,因此建議大家使用對象型的Integer/Long定義主鍵。
unsaved-value="none"和
unsaved-value="any"
主主要用在主鍵屬性不是通過Hibernate生成,而是程序自己setId()的時候。
在這里多說一句,強烈建議使用Hibernate的id generator,或者你可以自己擴展Hibernate的id generator,特別注意不要使用有實際含義的字段當做主鍵來用!例如用戶類User,很多人喜歡用用戶登陸名稱做為主鍵,這是一個很不好的習慣,當用戶類和其他實體類有關聯關系的時候,萬一你需要修改用戶登陸名稱,一改就需要改好幾張表中的數據。偶合性太高,而如果你使用無業務意義的id generator,那么修改用戶名稱,就只修改user表就行了。
由這個問題引申出來,如果你嚴格按照這個原則來設計數據庫,那么你基本上是用不到手工來setId()的,你用Hibernate的id generator就OK了。因此你也不需要了解當
unsaved-value="none"和
unsaved-value="any"
究竟有什么含義了。如果你非要用assigned不可,那么繼續解釋一下:
unsaved-value="none" 的時候,由于不論主鍵屬性為任何值,都不可能為none,因此Hibernate總是對child對象發送update(child)
unsaved-value="any" 的時候,由于不論主鍵屬性為任何值,都肯定為any,因此Hibernate總是對child對象發送save(child)
大多數情況下,你可以避免使用assigned,只有當你使用復合主鍵的時候不得不手工setId(),這時候需要你自己考慮究竟怎么設置unsaved-value了,根據你自己的需要來定。
BTW: Gavin King強烈不建議使用composite-id,強烈建議使用UserType。
因此,如果你在系統設計的時候,遵循如下原則:
1、使用Hibernate的id generator來生成無業務意義的主鍵,不使用有業務含義的字段做主鍵,不使用assigned。
2、使用對象類型(String/Integer/Long/...)來做主鍵,而不使用基礎類型(int/long/...)做主鍵
3、不使用composite-id來處理復合主鍵的情況,而使用UserType來處理該種情況。
那么你永遠用的是unsaved-value="null" ,不可能用到any/none/..了。
posted @
2009-08-17 22:41 J2EE學習筆記 閱讀(947) |
評論 (0) |
編輯 收藏
如果我們編譯運行下面這個程序會看到什么?
public class Test {
public static void main(String args[]) {
System.out.println(0.05 + 0.01);
System.out.println(1.0 - 0.42);
System.out.println(4.015 * 100);
System.out.println(123.3 / 100);
}
}
你沒有看錯!結果確實是
0.060000000000000005
0.5800000000000001
401.49999999999994
1.2329999999999999
Java中的簡單浮點數類型float和double不能夠進行運算。不光是Java,在其它很多編程語言中也有這樣的問題。在大多數情況下,計算的結果是準確的,但是多試幾次(可以做一個循環)就可以試出類似上面的錯誤。現在終于理解為什么要有BCD碼了。
這個問題相當嚴重,如果你有9.999999999999元,你的計算機是不會認為你可以購買10元的商品的。
在有的編程語言中提供了專門的貨幣類型來處理這種情況,但是Java沒有。現在讓我們看看如何解決這個問題。
四舍五入
我們的第一個反應是做四舍五入。Math類中的round方法不能設置保留幾位小數,我們只能象這樣(保留兩位):
public double round(double value) {
return Math.round(value * 100) / 100.0;
}
非常不幸,上面的代碼并不能正常工作,給這個方法傳入4.015它將返回4.01而不是4.02,如我們在上面看到的
4.015*100=401.49999999999994
因此如果我們要做到精確的四舍五入,不能利用簡單類型做任何運算
java.text.DecimalFormat也不能解決這個問題:
System.out.println(new java.text.DecimalFormat("0.00").format(4.025));
輸出是4.02
BigDecimal
在《Effective Java》這本書中也提到這個原則,float和double只能用來做科學計算或者是工程計算,在商業計算中我們要用java.math.BigDecimal。BigDecimal一共有4個夠造方法,我們不關心用BigInteger來夠造的那兩個,那么還有兩個,它們是:
BigDecimal(double val)
Translates a double into a BigDecimal.
BigDecimal(String val)
Translates the String repre sentation of a BigDecimal into a BigDecimal.
上面的API簡要描述相當的明確,而且通常情況下,上面的那一個使用起來要方便一些。我們可能想都不想就用上了,會有什么問題呢?等到出了問題的時候,才發現上面哪個夠造方法的詳細說明中有這么一段:
Note: the results of this constructor can be somewhat unpredictable. One might assume that new BigDecimal(.1) is exactly equal to .1, but it is actually equal to .1000000000000000055511151231257827021181583404541015625. This is so because .1 cannot be represented exactly as a double (or, for that matter, as a binary fraction of any finite length). Thus, the long value that is being passed in to the constructor is not exactly equal to .1, appearances nonwithstanding.
The (String) constructor, on the other hand, is perfectly predictable: new BigDecimal(".1") is exactly equal to .1, as one would expect. Therefore, it is generally recommended that the (String) constructor be used in preference to this one.
原來我們如果需要精確計算,非要用String來夠造BigDecimal不可!在《Effective Java》一書中的例子是用String來夠造BigDecimal的,但是書上卻沒有強調這一點,這也許是一個小小的失誤吧。
解決方案
現在我們已經可以解決這個問題了,原則是使用BigDecimal并且一定要用String來夠造。
但是想像一下吧,如果我們要做一個加法運算,需要先將兩個浮點數轉為String,然后夠造成BigDecimal,在其中一個上調用add方法,傳入另一個作為參數,然后把運算的結果(BigDecimal)再轉換為浮點數。你能夠忍受這么煩瑣的過程嗎?下面我們提供一個工具類Arith來簡化操作。它提供以下靜態方法,包括加減乘除和四舍五入:
public static double add(double v1,double v2)
public static double sub(double v1,double v2)
public static double mul(double v1,double v2)
public static double div(double v1,double v2)
public static double div(double v1,double v2,int scale)
public static double round(double v,int scale)
附錄
源文件Arith.java:
import java.math.BigDecimal;
public class Arith {
//默認除法運算精度
private static final int DEF_DIV_SCALE = 10;
//這個類不能實例化
private Arith()
{
;
}
/** *//**
* 提供精確的加法運算。
* @param v1 被加數
* @param v2 加數
* @return 兩個參數的和
*/
public static double add(double v1,double v2)
{
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.add(b2).doubleValue();
}
/** *//**
* 提供精確的減法運算。
* @param v1 被減數
* @param v2 減數
* @return 兩個參數的差
*/
public static double sub(double v1,double v2){
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.subtract(b2).doubleValue();
}
/** *//**
* 提供精確的乘法運算。
* @param v1 被乘數
* @param v2 乘數
* @return 兩個參數的積
*/
public static double mul(double v1,double v2)
{
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.multiply(b2).doubleValue();
}
/** *//**
* 提供(相對)精確的除法運算,當發生除不盡的情況時,精確到
* 小數點以后10位,以后的數字四舍五入。
* @param v1 被除數
* @param v2 除數
* @return 兩個參數的商
*/
public static double div(double v1,double v2)
{
return div(v1,v2,DEF_DIV_SCALE);
}
/** *//**
* 提供(相對)精確的除法運算。當發生除不盡的情況時,由scale參數指
* 定精度,以后的數字四舍五入。
* @param v1 被除數
* @param v2 除數
* @param scale 表示表示需要精確到小數點以后幾位。
* @return 兩個參數的商
*/
public static double div(double v1,double v2,int scale)
{
if(scale<0)
{
throw new IllegalArgumentException("The scale must be a positive integer or zero");
}
BigDecimal b1 = new BigDecimal(Double.toString(v1));
BigDecimal b2 = new BigDecimal(Double.toString(v2));
return b1.divide(b2,scale,BigDecimal.ROUND_HALF_UP).doubleValue();
}
/** *//**
* 提供精確的小數位四舍五入處理。
* @param v 需要四舍五入的數字
* @param scale 小數點后保留幾位
* @return 四舍五入后的結果
*/
public static double round(double v,int scale)
{
if(scale<0)
{
throw new IllegalArgumentException("The scale must be a positive integer or zero");
}
BigDecimal b = new BigDecimal(Double.toString(v));
BigDecimal one = new BigDecimal("1");
return b.divide(one,scale,BigDecimal.ROUND_HALF_UP).doubleValue();
}
}
posted @
2009-05-07 11:33 J2EE學習筆記 閱讀(1201) |
評論 (0) |
編輯 收藏