#
作者 張龍 發布于 2010年8月27日 上午12時59分
- .NET,
- Java
- 主題
- 性能和可伸縮性
- 標簽
- 性能和擴展性 ,
- 性能評估 ,
- 性能調優
今年5月底,瑞士計算機世界雜志上刊登了Web性能診斷專家Bernd Greifeneder的一篇文章,文章列舉了其在過去幾年工作中所遇到的服務器端編程的十大性能問題。Andreas Grabner則在自己的博客上對這些性能問題給出了進一步閱讀的鏈接。希望這些問題與相關的延伸閱讀能為廣大的InfoQ讀者帶來一定的啟示。
問題一:過多的數據庫調用
我們發現經常出現的一個問題就是在每次請求/事務中存在過多的數據庫查詢。有如下三個場景作為佐證:
- 在一次事務上下文中所請求的數據比實際需要的數據多出很多。比如說:請求所有的賬戶信息而不是僅僅查詢出當前需要顯示的信息。
- 多次請求同樣的數據。這種情況通常發生在相同事務中的不同組件之間是彼此獨立的,而每個組件都會請求同樣的數據。我們并不清楚當前上下文中已經加載了哪些數據,最后只得多次發出同樣的查詢。
- 發出多個查詢語句以獲得某一數據集。通常這是由于沒有充分利用到復雜的SQL語句、存儲過程等在一次批處理中獲取需要的數據所導致的。
延伸閱讀:Blog on Linq2Sql Performance Issues on Database、Video on Performance Anti-Patterns
問題二:過多地使用同步
毫無疑問,同步對于應用中共享數據的保護來說是至關重要的舉措。但有很多開發者卻過度使用同步,比如在超大段的代碼中使用同步。在低負載的情況下,這么做倒沒什么問題;但在高負載或是產品環境下,過度的同步會導致嚴重的性能與可伸縮性問題。
延伸閱讀: How to identify synchronization problems under load
問題三:過度使用遠程調用
很多庫都使用了遠程通信。對于開發者來說,遠程調用與本地調用似乎沒什么區別,但如果不清楚遠程調用的本質就會鑄成大錯,因為每一次遠程調用都會涉及到延遲、序列化、網絡堵塞以及內存使用等問題。如果沒有經過深思熟慮而盲目使用這些遠程技術就會導致嚴重的性能與可伸縮性問題。
延伸閱讀: Performance Considerations in Distributed Applications
問題四:錯誤地使用對象關系映射
對象關系映射為開發者解決了很多負擔,比如從數據庫中加載對象以及將對象持久化到數據庫中。但與其他任何框架一樣,對象關系映射也有很多配置選項需要優化,只有這樣才能適應于當前應用的需要。錯誤的配置與不正確的使用都會導致始料不及的性能問題。在使用對象關系映射框架前,請務必保證熟悉所有的配置,如果有機會,請深入到所用框架的內核,這樣使用起來才有保障。
延伸閱讀:Understanding Hibernate Session Cache、Understanding the Query Cache、Understanding the Second Level Cache
問題五:內存泄漏
托管的運行時環境(如Java和.NET)可以通過垃圾收集器進行內存管理。但垃圾收集器無法避免內存泄漏問題。“被遺忘”的對象依舊會占據著內存,最終將會導致內存泄漏問題。當對象不再需要時,請盡快釋放掉對象引用。
延伸閱讀:Understanding and finding Memory Leaks
問題六:使用有問題的第三方代碼/組件
沒有人會從頭編寫應用的全部功能。我們都會使用第三方程序庫來加快開發進程。這么做不僅會加速產出,也增加了性能上的風險。雖然大多數框架都具有良好的文檔并且經過了充分的測試,但沒人能夠保證這些框架在任何時候都會像預期的那樣好。因此,在使用這些第三方框架時,事先一定要做好充分的調研。
延伸閱讀: Top SharePoint Performance Mistakes
問題七:對稀缺資源的使用存在浪費的情況
內存、CPU、I/O以及數據庫等資源屬于稀缺資源。在使用這些資源時如果存在浪費的情況就會造成嚴重的性能與可伸縮性問題。比如說,有人會長時間打開數據庫連接而不關閉。連接應該只在需要的時候才使用,使用完畢后就應該放回到連接池中。我們經常看到有人在請求一開始就去獲取連接,直到最后才釋放,這么做會導致性能瓶頸。
延伸閱讀: Resource Leak detection in .NET Applications
問題八:膨脹的Web前端
由于現在的Web速度越來越快,用戶的網絡體驗也越來越好。在這個趨勢下,很多應用的前端都提供了太多的內容,但這么做會導致差勁的瀏覽體驗。很多圖片都太大了,沒有利用好或是錯誤地使用了瀏覽器緩存、過度地使用JavaScript/AJAX等,所有這一切都會導致瀏覽器的性能問題。
延伸閱讀: How Better Caching would help speed up Frankfurt Airport Web Site、Best Practices on Web Performance Optimization
問題九:錯誤的緩存策略導致過度的垃圾收集
將對象緩存在內存中可以避免每次都向數據庫發出請求,這么做可以提升性能。但如果緩存了太多的對象,或是緩存了很多不常使用的對象則會將緩存的這種優勢變成劣勢,因為這會導致過高的內存使用率及過多的垃圾收集活動。在實現緩存策略前,請想好哪些對象需要緩存,哪些對象不需要緩存,進而避免這類性能與可伸縮性問題。
延伸閱讀:Java Memory Problems、Identify GC Bottlenecks in Distributed Applications
問題十:間歇性問題
間歇性問題很難發現。通常這類問題與特定的輸入參數有關,或是發生在某個負載條件下。完全的測試覆蓋率及負載與性能測試能在這些問題產生前就發現他們。
延伸閱讀:Tracing Intermittent Errors by Lucy Monahan from Novell、How to find invisible performance problems
最近因為解析socket 于是就遇到二進制這些東西,在學校沒學好而且以前不是很理解,所有重新開始溫故了一些基本概念,
首先是進制的概念,所謂的進制就是數學計算的具體多少而進位的一種算法。比如二進制,就只有0和1 他們基本是到2就進位。
而現實生活中也有各種進位方式,比如常用的十進制,我們基本貨幣計算就是這種方式,因此還有八進位,十六進位等等,
下面我把這些進位對應的英文也列出來,以為在編程的時候 常常看到的命名是相關英文而非中文,理解這樣英文便于你的具體
應用或者查看別人API。
十進制數(Decimal)
二進制數(Binary)
七進制數(septenary)
八進制數(Octal)
十六進制數(Hex)
六十進位制數(Sixty binary)
其實本身這些進制都是機器可讀的語言,對應同樣的東西 他們只是表達的方式不一樣,表達的都是同一個東西,
那么本身進制直接可能通過操作相互轉化,這個轉化就比較枯燥,一般語言都提供API來封裝了這個轉化過程。
進制數我剛才說了,我理解為機器可讀的標識,那么對應人的話,一般我們看到的都是圖形化的東西,因此最早老美提出了
ASCII,因為是老美提出來的,所以他只講他們的語言的基本元素A B C D...
ASCII里面分顯示字符和控制字符,一般控制字符不能顯示在頁面。
具體可以參考
http://zh.wikipedia.org/zh/ASCII
隨著全球化的進程,ASCII太局限了,因此Unicode更為普及。
理解了基本原理: 我們調用apache Codec 的api 來看看
org.apache.commons.codec.binary
Class BinaryCodec:
Translates between byte arrays and strings of "0"s and "1"s.
例子
String s ="00011111";
BinaryCodec bc = new BinaryCodec();
byte[] b = bc.toByteArray(s); //b 調試結果為 [31] 其實就是acii 上面描述的十進制表示
String t = new String(b); //t 不能看到 因為這是控制字符
System.out.println(t);
如果
String s ="00100001";
BinaryCodec bc = new BinaryCodec();
byte[] b = bc.toByteArray(s); //b 調試結果為 [33] 其實就是acii 上面描述的十進制表示
String t = new String(b); //t 能看到 是字符!
System.out.println(t);
而這個s 必須是1 0表示的二進制。toByteArray這個應該表示將二進制顯示的字符串轉化為真正的顯示意義上的二進制。
String s ="00100001";
BinaryCodec bc = new BinaryCodec();
byte[] b = bc.toByteArray(s); //b=[33]
char[] d = bc.toAsciiChars(b); //d= [0, 0, 1, 0, 0, 0, 0, 1]
String str = bc.toAsciiString(b);//str = 00100001
byte[] e = bc.toAsciiBytes(b); //e = [48, 48, 49, 48, 48, 48, 48, 49]
BinaryCodec bc = new BinaryCodec();
char[] c = {'0','0','1','0','0','0','0','1'};
byte[] b = bc.fromAscii(c); //[33]
如果
char[] c = {'0','0','1','J','0','0','0','1'}; //表示二進制
還是//[33] 這說明除了1所有的char 在該API都認為是0,來處理二進制
如果是
char[] c = {'0','0','1','J','0','0','0'}; //七位
那么b 就為空[]
如果是九位
char[] c = {'0','0','1','J','0','0','0','0'}; //九位
如果最后一位為1 那么結果 b=[65]
如果為非1 比如0 或者其他char 那么結果b=[64]
方法
static byte[] fromAscii(byte[] ascii) 和上面的
static byte[] fromAscii(char[] ascii) 一樣
比如
byte[] i = {'0','0','1','J','0','0','0','0','l'};
byte[] b = bc.fromAscii(i); //b的結果仍然是b=[64]
但是 在調試看到i 顯示為 i=[48, 48, 49, 74, 48, 48, 48, 48, 108]
////////////////解碼
byte[] decode(byte[] ascii) 將1,0 表示的byte數組解碼為相應的byte
比如:
BinaryCodec bc = new BinaryCodec();
byte[] i = {'0','0','1','J','0','0','0','0','l'}; //i=[48, 48, 49, 74, 48, 48, 48, 48, 108]
byte[] b = bc.decode(i); //b=[64]
再比如:Object decode(Object ascii) :
String s ="00011111";
BinaryCodec bc = new BinaryCodec();
try {
Object t =bc.decode(s); //t=[31]
System.out.println(t);
} catch (DecoderException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
/////////////////編碼
將byte轉化為1,0 表示的byte數組
byte[] encode(byte[] raw)
Object encode(Object raw)
例如:
String s ="00011111";
BinaryCodec bc = new BinaryCodec();
try {
Object t =bc.encode(s);
System.out.println(t);
} catch (EncoderException e) {
// TODO Auto-generated catch block
e.printStackTrace(); //會拋出e:org.apache.commons.codec.EncoderException: argument not a byte array
}
如果
byte[] i = {'!'};
BinaryCodec bc = new BinaryCodec();
Object t =bc.encode(i); //t=[48, 48, 49, 48, 48, 48, 48, 49]
System.out.println(t);
事件管道模型
很多人知道事件驅動模式,那么事件管道(Event Pipeline)模式是什么?下面我們一起來探討
event 的出現是設計為一個對象的狀態的改變即就通知對該對象感興趣的其他對象。
一般產生一個event總是有個發源地,我們可以把這個發源地叫做Event Generators而在java的EventObject interface中其實應該就是指的
source參數。
通常我們事件驅動模式是在一個本機上做,其實這個模式在分布式環境中也可以采用事件驅動模式。從整個模式上看,本地的事件驅動模型(local event)
和遠程的事件驅動模型(remote event)沒有什么本質區別,但有幾點需要注意
1.local event:所有的對象都在本地包括需要通知的對象。
remote event:Event Generators在一段,remote event 有Event Generators產生后通知另外遠端的entity。
2.因為有遠端那么就涉及到網絡通信,因此通常不能保證網絡通信一直通暢,所有remote event的模式可能或出現event丟失不能達到對方的情況。
3.local event 在本地,所以往往event很快,相應的處理的反饋也快,因此你會發現本地的event模式通常都類似于http的握手模式,也就是一個event觸發
通常就直接通知給所有監聽器。
而remote event 是遠程event的傳送,那么在網絡通信其實消耗大量的時間,那么我認為client端多event的發送,server端統一處理一批event可能是節省資源
比較好的方式。
因此我們這里引入Event Pipeline,他是對server端接收到的event進行管理,將event 放入管道進行各自策略的處理。
另外我們把遠端的Event Listener叫做Remote Event Listener,其實本質是一樣的,只是為了區分。
當許多remote events 在同一個管道的時候,那么我們需要根據不同的需要來定制event的策略,下面列舉以下一些策略
a.In-order delivery
events按照某種順序傳遞
b. Efficient delivery
多個event 合并為一個event
c. Store and forward
event 暫停在管道中,等待某個條件出現再繼續傳遞
d. Filtering of events
根據條件過濾相應event
e. Grouping of events
多個event 被一個event代替
PipeLine 流程:
Event Generator ---> Event pipeLine -->Event Consumer
其中pipeLine中可以動態地設置一個或者多個策略。
1.Channel
channel 是負責數據讀,寫的對象,有點類似于老的io里面的stream,他和stream的區別,channel是雙向的
既可以write 也可以read,而stream要分outstream和inputstream。而且在NIO中用戶不應該直接從channel中讀寫數據,
而是應該通過buffer,通過buffer再將數據讀寫到channel中。
一個channel 可以提供給用戶下面幾個信息
(1)channel的當前狀態,比如open 還是closed
(2)ChannelConfig對象,表示channel的一些參數,比如bufferSize
(3)channel支持的所有i/o操作(比如read,write,connect.bind)以及ChannelPipeLine(下面解釋)
2.ChannelConfig
channel的參數,以Map 數據結構來存儲
3.ChannelEvent
ChannelEvent廣義的認為Channel相關的事件,他是否分Upstream events和downstream events兩大塊,這里需要注意的,讓是server為
主體的話,從client的數據到server的過程是Upstream;而server到client的數據傳輸過程叫downstream;而如果以client為主體
的話,從server到client的過程對client來說是Upstream,而client到server的過程對client來說就是downstream。
Upstream events包括:
messageReceived:信息被接受時 ---MessageEvent
exceptionCaught:產生異常時 ---ExceptionEvent
channelOpen:channel被開啟時 ---ChannelStateEvent
channelClosed:channel被關閉時 ---ChannelStateEvent
channelBound:channel被開啟并準備去連接但還未連接上的時候 ---ChannelStateEvent
channelUnbound:channel被開啟不準備去連接時候 ---ChannelStateEvent
channelConnected:channel被連接上的時候 ---ChannelStateEvent
channelDisconnected:channel連接斷開的時候 ---ChannelStateEvent
channelInterestChanged:Channel的interestOps被改變的時候 ------ChannelStateEvent
writeComplete:寫到遠程端完成的時候 --WriteCompletionEvent
Downstream events包括:
write:發送信息給channel的時候 --MessageEvent
bind:綁定一個channel到指定的本地地址 --ChannelStateEvent
unbind:解除當前本地端口的綁定--ChannelStateEvent
connect:將channel連接到遠程的機 --ChannelStateEvent
disconnect:將channel與遠程的機連接斷開 --ChannelStateEvent
close:關閉channel --ChannelStateEvent
需要注意的是,這里沒有open event,這是因為當一個channel被channelFactory創建的話,channel總是已經被打開了。
此外還有兩個事件類型是當父channel存在子channel的情況
childChannelOpen:子channel被打開 ---ChannelStateEvent
childChannelClosed:子channel被關閉 ---ChannelStateEvent
4.ChannelHandler
channel是負責傳送數據的載體,那么數據肯定需要根據要求進行加工處理,那么這個時候就用到ChannelHandler
不同的加工可以構建不同的ChannelHandler,然后放入ChannelPipeline中
此外需要有ChannelEvent觸發后才能到達ChannelHandler,因此根據event不同有下面兩種的sub接口ChannelUpstreamHandler
和ChannelDownstreamHandler。
一個ChannelHandler通常需要存儲一些狀態信息作為判斷信息,常用做法定義一個變量
比如
public class DataServerHandler extends {@link SimpleChannelHandler} {
*
* <b>private boolean loggedIn;</b>
*
* {@code @Override}
* public void messageReceived({@link ChannelHandlerContext} ctx, {@link MessageEvent} e) {
* {@link Channel} ch = e.getChannel();
* Object o = e.getMessage();
* if (o instanceof LoginMessage) {
* authenticate((LoginMessage) o);
* <b>loggedIn = true;</b>
* } else (o instanceof GetDataMessage) {
* if (<b>loggedIn</b>) {
* ch.write(fetchSecret((GetDataMessage) o));
* } else {
* fail();
* }
* }
* }
* ...
* }
// Create a new handler instance per channel.
* // See {@link Bootstrap#setPipelineFactory(ChannelPipelineFactory)}.
* public class DataServerPipelineFactory implements {@link ChannelPipelineFactory} {
* public {@link ChannelPipeline} getPipeline() {
* return {@link Channels}.pipeline(<b>new DataServerHandler()</b>);
* }
* }
除了這種,每個ChannelHandler都可以從ChannelHandlerContext中獲取或設置數據,那么下面的做法就是利用ChannelHandlerContext
設置變量
* {@code @Sharable}
* public class DataServerHandler extends {@link SimpleChannelHandler} {
*
* {@code @Override}
* public void messageReceived({@link ChannelHandlerContext} ctx, {@link MessageEvent} e) {
* {@link Channel} ch = e.getChannel();
* Object o = e.getMessage();
* if (o instanceof LoginMessage) {
* authenticate((LoginMessage) o);
* <b>ctx.setAttachment(true)</b>;
* } else (o instanceof GetDataMessage) {
* if (<b>Boolean.TRUE.equals(ctx.getAttachment())</b>) {
* ch.write(fetchSecret((GetDataMessage) o));
* } else {
* fail();
* }
* }
* }
* ...
* }
* public class DataServerPipelineFactory implements {@link ChannelPipelineFactory} {
*
* private static final DataServerHandler <b>SHARED</b> = new DataServerHandler();
*
* public {@link ChannelPipeline} getPipeline() {
* return {@link Channels}.pipeline(<b>SHARED</b>);
* }
* }
這兩種做法還是有區別的,上面的變量做法,每個new的handler 對象,變量是不共享的,而下面的ChannelHandlerContext是共享的
如果需要不同的handler之間共享數據,那怎么辦,那就用ChannelLocal
例子:
public final class DataServerState {
*
* <b>public static final {@link ChannelLocal}<Boolean> loggedIn = new {@link ChannelLocal}<Boolean>() {
* protected Boolean initialValue(Channel channel) {
* return false;
* }
* }</b>
* ...
* }
*
* {@code @Sharable}
* public class DataServerHandler extends {@link SimpleChannelHandler} {
*
* {@code @Override}
* public void messageReceived({@link ChannelHandlerContext} ctx, {@link MessageEvent} e) {
* Channel ch = e.getChannel();
* Object o = e.getMessage();
* if (o instanceof LoginMessage) {
* authenticate((LoginMessage) o);
* <b>DataServerState.loggedIn.set(ch, true);</b>
* } else (o instanceof GetDataMessage) {
* if (<b>DataServerState.loggedIn.get(ch)</b>) {
* ctx.getChannel().write(fetchSecret((GetDataMessage) o));
* } else {
* fail();
* }
* }
* }
* ...
* }
*
* // Print the remote addresses of the authenticated clients:
* {@link ChannelGroup} allClientChannels = ...;
* for ({@link Channel} ch: allClientChannels) {
* if (<b>DataServerState.loggedIn.get(ch)</b>) {
* System.out.println(ch.getRemoteAddress());
* }
* }
* </pre>
5.ChannelPipeline
channelPipeline是一系列channelHandler的集合,他參照J2ee中的Intercepting Filter模式來實現的,
讓用戶完全掌握如果在一個handler中處理事件,同時讓pipeline里面的多個handler可以相互交互。
Intercepting Filter:http://java.sun.com/blueprints/corej2eepatterns/Patterns/InterceptingFilter.html
對于每一個channel都需要有相應的channelPipeline,當為channel設置了channelPipeline后就不能再為channel重新設置
channelPipeline。此外建議的做法的通過Channels 這個幫助類來生成ChannelPipeline 而不是自己去構建ChannelPipeline
通常pipeLine 添加多個handler,是基于業務邏輯的
比如下面
{@link ChannelPipeline} p = {@link Channels}.pipeline();
* p.addLast("1", new UpstreamHandlerA());
* p.addLast("2", new UpstreamHandlerB());
* p.addLast("3", new DownstreamHandlerA());
* p.addLast("4", new DownstreamHandlerB());
* p.addLast("5", new SimpleChannelHandler());
upstream event 執行的handler按順序應該是 125
downstream event 執行的handler按順序應該是 543
SimpleChannelHandler 是同時實現了 ChannelUpstreamHandler和ChannelDownstreamHandler的類
上面只是具有邏輯,如果數據需要通過格式來進行編碼的話,那需要這些寫
* {@link ChannelPipeline} pipeline = {@link Channels#pipeline() Channels.pipeline()};
* pipeline.addLast("decoder", new MyProtocolDecoder());
* pipeline.addLast("encoder", new MyProtocolEncoder());
* pipeline.addLast("executor", new {@link ExecutionHandler}(new {@link OrderedMemoryAwareThreadPoolExecutor}(16, 1048576, 1048576)));
* pipeline.addLast("handler", new MyBusinessLogicHandler());
其中:
Protocol Decoder - 將binary轉換為java對象
Protocol Encoder - 將java對象轉換為binary
ExecutionHandler - applies a thread model.
Business Logic Handler - performs the actual business logic(e.g. database access)
雖然不能為channel重新設置channelPipeline,但是channelPipeline本身是thread-safe,因此你可以在任何時候為channelPipeline添加刪除channelHandler
需要注意的是,下面的代碼寫法不能達到預期的效果
* public class FirstHandler extends {@link SimpleChannelUpstreamHandler} {
*
* {@code @Override}
* public void messageReceived({@link ChannelHandlerContext} ctx, {@link MessageEvent} e) {
* // Remove this handler from the pipeline,
* ctx.getPipeline().remove(this);
* // And let SecondHandler handle the current event.
* ctx.getPipeline().addLast("2nd", new SecondHandler());
* ctx.sendUpstream(e);
* }
* }
前提現在Pipeline只有最后一個FirstHandler,
上面明顯是想把FirstHandler從Pipeline中移除,然后添加SecondHandler。而pipeline需要只要有一個Handler,因此如果想到到達這個效果,那么可以
先添加SecondHandler,然后在移除FirstHandler。
6.ChannelFactory
channel的工廠類,也就是用來生成channel的類,ChannelFactory根據指定的通信和網絡來生成相應的channel,比如
NioServerSocketChannelFactory生成的channel是基于NIO server socket的。
當一個channel創建后,ChannelPipeline將作為參數附屬給該channel。
對于channelFactory的關閉,需要做兩步操作
第一,關閉所有該factory產生的channel包括子channel。通常調用ChannelGroup#close()。
第二,釋放channelFactory的資源,調用releaseExternalResources()
7.ChannelGroup
channel的組集合,他包含一個或多個open的channel,closed channel會自動從group中移除,一個channel可以在一個或者多個channelGroup
如果想將一個消息廣播給多個channel,可以利用group來實現
比如:
{@link ChannelGroup} recipients = new {@link DefaultChannelGroup}()
recipients.add(channelA);
recipients.add(channelB);
recipients.write(ChannelBuffers.copiedBuffer("Service will shut down for maintenance in 5 minutes.",CharsetUtil.UTF_8));
當ServerChannel和非ServerChannel同時都在channelGroup中的時候,任何io請求的操作都是先在ServerChannel中執行再在其他Channel中執行。
這個規則對關閉一個server非常適用。
8.ChannelFuture
在netty中,所有的io傳輸都是異步,所有那么在傳送的時候需要數據+狀態來確定是否全部傳送成功,而這個載體就是ChannelFuture。
9.ChannelGroupFuture
針對一次ChannelGroup異步操作的結果,他和ChannelFuture一樣,包括數據和狀態。不同的是他由channelGroup里面channel的所有channelFuture
組成。
10.ChannelGroupFutureListener
針對ChannelGroupFuture的監聽器,同樣建議使用ChannelGroupFutureListener而不是await();
11.ChannelFutureListener
ChannelFuture監聽器,監聽channelFuture的結果。
12.ChannelFutureProgressListener
監聽ChannelFuture處理過程,比如一個大文件的傳送。而ChannelFutureListener只監聽ChannelFuture完成未完成
13.ChannelHandlerContext
如何讓handler和他的pipeLine以及pipeLine中的其他handler交換,那么就要用到ChannelHandlerContext,
ChannelHandler可以通過ChannelHandlerContext的sendXXXstream(ChannelEvent)將event傳給最近的handler
可以通過ChannelHandlerContext的getPipeline來得到Pipeline,并修改他,ChannelHandlerContext還可以存放一下狀態信息attments。
一個ChannelHandler實例可以有一個或者多個ChannelHandlerContext
14.ChannelPipelineFactory
產生ChannelPipe的工廠類
15.ChannelState
記載channel狀態常量
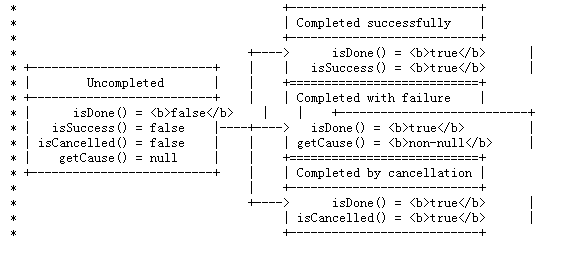
Netty 是JBoss旗下的io傳輸的框架,他利用java里面的nio來實現高效,穩定的io傳輸。
作為io傳輸,就會有client和server,下面我們看看用netty怎樣寫client和server
Client:
需要做的事情:
1.配置client啟動類
ClientBootstrap bootstrap = new ClientBootstrap(..)
2.根據不同的協議或者模式為client啟動類設置pipelineFactory。
這里telnet pipline Factory 在netty中已經存在,所有直接用
bootstrap.setPipelineFactory(new TelnetClientPipelineFactory());
也可以自己定義
bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
public ChannelPipeline getPipeline() throws Exception {
return Channels.pipeline(
new DiscardClientHandler(firstMessageSize));
}
});
這里DiscardClientHandler 就是自己定義的handler,他需要
public class DiscardServerHandler extends SimpleChannelUpstreamHandler
繼承SimpleChannelUpstreamHandler 來實現自己的handler。這里DiscardClientHandler
是處理自己的client端的channel,他的
public void messageReceived(ChannelHandlerContext ctx, MessageEvent e) {
// Server is supposed to send nothing. Therefore, do nothing.
}
可以看到Discard client不需要接受任何信息
3.連接server
ChannelFuture future = bootstrap.connect(new InetSocketAddress(host, port));
這里解釋一下channelFuture:
在Netty中所有的io操作都是異步的,這也就是意味任何io訪問,那么就立即返回處理,并且不能確保
返回的數據全部完成。因此就出現了channelFuture,channelFuture在傳輸數據時候包括數據和狀態兩個
部分。他只有Uncompleted和Completed
既然netty io是異步的,那么如何知道channel傳送完成有兩種方式,一種添加監聽器
addListener(ChannelFutureListener) 還有一種直接調用await()方法,這兩種方式
有下面的區別
監聽器:是以事件模式的,因此代碼就需要用事件模式的樣式去寫,相當復雜,但他是non-blocking模式的
性能方面要比await方法好,而且不會產生死鎖情況
await(): 直接方法調用,使用簡單,但是他是blocking模式,性能方面要弱而且會產生死鎖情況
不要在ChannelHandler 里面調用await(),這是因為通常在channelHandler里的event method是被i/o線程調用的
(除非ChannelPipeline里面有個ExecutionHandler),那么如果這個時候用await就容易產生死鎖。
錯誤樣例:
// BAD - NEVER DO THIS
* {@code @Override}
* public void messageReceived({@link ChannelHandlerContext} ctx, {@link MessageEvent} e) {
* if (e.getMessage() instanceof GoodByeMessage) {
* {@link ChannelFuture} future = e.getChannel().close();
* future.awaitUninterruptibly();
* // Perform post-closure operation
* // ...
* }
* }
*
正確樣例:
* // GOOD
* {@code @Override}
* public void messageReceived({@link ChannelHandlerContext} ctx, {@link MessageEvent} e) {
* if (e.getMessage() instanceof GoodByeMessage) {
* {@link ChannelFuture} future = e.getChannel().close();
* future.addListener(new {@link ChannelFutureListener}() {
* public void operationComplete({@link ChannelFuture} future) {
* // Perform post-closure operation
* // ...
* }
* });
* }
* }
雖然await調用比較危險,但是你確保不是在一個i/o 線程中調用該方法,畢竟await方法還是很簡潔方便的,如果
調用該方法是在一個i/o 線程,那么就會拋出 IllegalStateException
await的timeout和i/o timeout區別
需要注意的是這兩個timeout是不一樣的, #await(long),#await(long, TimeUnit), #awaitUninterruptibly(long),
#awaitUninterruptibly(long, TimeUnit) 這里面的timeout也i/o timeout 沒有任何關系,如果io timeout,那么
channelFuture 將被標記為completed with failure,而await的timeout 與future完全沒有關系,只是await動作的
timeout。
錯誤代碼
* // BAD - NEVER DO THIS
* {@link ClientBootstrap} b = ...;
* {@link ChannelFuture} f = b.connect(...);
* f.awaitUninterruptibly(10, TimeUnit.SECONDS);
* if (f.isCancelled()) {
* // Connection attempt cancelled by user
* } else if (!f.isSuccess()) {
* // You might get a NullPointerException here because the future
* // might not be completed yet.
* f.getCause().printStackTrace();
* } else {
* // Connection established successfully
* }
*
正確代碼
* // GOOD
* {@link ClientBootstrap} b = ...;
* // Configure the connect timeout option.
* <b>b.setOption("connectTimeoutMillis", 10000);</b>
* {@link ChannelFuture} f = b.connect(...);
* f.awaitUninterruptibly();
*
* // Now we are sure the future is completed.
* assert f.isDone();
*
* if (f.isCancelled()) {
* // Connection attempt cancelled by user
* } else if (!f.isSuccess()) {
* f.getCause().printStackTrace();
* } else {
* // Connection established successfully
* }
4.等待或監聽數據全部完成
如: future.getChannel().getCloseFuture().awaitUninterruptibly();
5.釋放連接等資源
bootstrap.releaseExternalResources();
Server:
1.配置server
ServerBootstrap bootstrap = new ServerBootstrap(
new NioServerSocketChannelFactory(
Executors.newCachedThreadPool(),
Executors.newCachedThreadPool()));
2.設置pipeFactory
bootstrap.setPipelineFactory(new ChannelPipelineFactory() {
public ChannelPipeline getPipeline() throws Exception {
return Channels.pipeline(new EchoServerHandler());
}
});
或者
bootstrap.setPipelineFactory(new HttpServerPipelineFactory());
3.綁定sever端端口
bootstrap.bind(new InetSocketAddress(8080));
org.jboss.netty.bootstrap
本身 Netty 可以作為一個server存在的,因此他存在啟動入口,他具有client啟動,server啟動以及connectionless 啟動(比如UDP)
1.基類bootstrap:他包含ChannelFactory,ChannelPipeline,ChannelPipelineFactory。
ClientBootstrap: 有connect()方法
ConnectionlessBootstrap:有connect(),bind()方法
ServerBootstrap:有bind()方法
2.org.jboss.netty.buffer
netty自己提供了buffer 來取代nio 中的java.nio.ByteBuffer,他與nio中的byteBuffer相比,有下面的幾個特點
1>可以根據自己需要自己定義buffer type
2>只是buffer type改變而不拷貝buffer的內容,這樣可以減少開銷
3>動態大小的buffer type 類似于stringbuffer
4>不需要調用flip()方法
5>更快的性能
3.org.jboss.netty.channel
channel的核心api,包括異步和事件驅動等各種傳送接口
org.jboss.netty.channel.group
channel group,里面包含一系列open的channel
org.jboss.netty.channel.local
一種虛擬的運輸方式,能允許同一個虛擬機上的兩個部分可以互相通信
org.jboss.netty.channel.socket
TCP,UDP端口接口,主要繼承channel
org.jboss.netty.channel.socket.nio
基于nio端口channel的具體實現
org.jboss.netty.channel.socket.oio
基于老的io端口的channel的具體實現
org.jboss.netty.channel.socket.http
基于http的客戶端和相應的server端的實現,可以在有防火墻的情況下進行工作
需要做的事情
a. 將http tunnel 作為servlet進行配置
web.xml
<servlet>
* <servlet-name>NettyTunnelingServlet</servlet-name>
* <servlet-class>org.jboss.netty.channel.socket.http.HttpTunnelingServlet</servlet-class>
* <!--
* The name of the channel, this should be a registered local channel.
* See LocalTransportRegister.
* -->
* <init-param>
* <param-name>endpoint</param-name>
* <param-value>local:myLocalServer</param-value>
* </init-param>
* <load-on-startup>1</load-on-startup>
* </servlet>
*
* <servlet-mapping>
* <servlet-name>NettyTunnelingServlet</servlet-name>
* <url-pattern>/netty-tunnel</url-pattern>
* </servlet-mapping>
接下來需要將你的基于netty的server app綁定到上面的http servlet
你可以這樣寫
*
* public class LocalEchoServerRegistration {
*
* private final ChannelFactory factory = new DefaultLocalServerChannelFactory();
* private volatile Channel serverChannel;
*
* public void start() {
* ServerBootstrap serverBootstrap = new ServerBootstrap(factory);
* EchoHandler handler = new EchoHandler();
* serverBootstrap.getPipeline().addLast("handler", handler);
*
* // Note that "myLocalServer" is the endpoint which was specified in web.xml.
* serverChannel = serverBootstrap.bind(new LocalAddress("myLocalServer"));
* }
*
* public void stop() {
* serverChannel.close();
* }
* }
然后在Ioc framework(JBoss Microcontainer,Guice,Spring)中定義bean
<bean name="my-local-echo-server"
class="org.jboss.netty.example.http.tunnel.LocalEchoServerRegistration" />
這樣http servlet 就可以了
b. 連接http tunnel
構造client
* ClientBootstrap b = new ClientBootstrap(
* new HttpTunnelingClientSocketChannelFactory(
* new NioClientSocketChannelFactory(...)));
*
* // Configure the pipeline (or pipeline factory) here.
* ...
*
* // The host name of the HTTP server
* b.setOption("serverName", "example.com");
* // The path to the HTTP tunneling Servlet, which was specified in in web.xml
* b.setOption("serverPath", "contextPath/netty-tunnel");
* b.connect(new InetSocketAddress("example.com", 80);
4.org.jboss.netty.container
各種容器的兼容
org.jboss.netty.container.microcontainer
JBoss Microcontainer 整合接口
org.jboss.netty.container.osgi
OSGi framework 整合接口
org.jboss.netty.container.spring
Spring framework 整合接口
5.org.jboss.netty.handler
處理器
org.jboss.netty.handler.codec.base64
Base64 編碼
org.jboss.netty.handler.codec.compression
壓縮格式
org.jboss.netty.handler.codec.embedder
嵌入模式下編碼和解碼,即使沒有真正的io環境也能使用
org.jboss.netty.handler.codec.frame
可擴展的接口,重新評估基于流的數據的排列和內容
org.jboss.netty.handler.codec.http.websocket
websocket相關的編碼和解碼,
參考
http://en.wikipedia.org/wiki/Web_Sockets
org.jboss.netty.handler.codec.http
http的編碼解碼以及類型信息
org.jboss.netty.handler.codec.oneone
一個對象到另一對象的自定義抽象接口,如果有自己編碼需要繼承該抽象類
org.jboss.netty.handler.codec.protobuf
Google Protocol Buffers的編碼解碼
Google Protocol Buffers參考下面
http://code.google.com/p/protobuf/
org.jboss.netty.handler.codec.replay
org.jboss.netty.handler.codec.rtsp
Real_Time_Streaming_Protocol的編碼解碼
Real_Time_Streaming_Protocol 參考下面wiki
http://en.wikipedia.org/wiki/Real_Time_Streaming_Protocol
org.jboss.netty.handler.codec.serialization
將序列化的對象轉換到byte buffer的相關實現
org.jboss.netty.handler.codec.string
字符串編碼解碼,比如utf8編碼等,繼承oneone包的接口
org.jboss.netty.handler.execution
基于java.util.concurrent.Executor的實現
org.jboss.netty.handler.queue
將event存入內部隊列的處理
org.jboss.netty.handler.ssl
基于javax.net.ssl.SSLEngine的SSL以及TLS實現
參考
http://en.wikipedia.org/wiki/Transport_Layer_Security
org.jboss.netty.handler.stream
異步寫入大數據,不會產生outOfMemory 也不會花費很多內存
org.jboss.netty.handler.timeout
通過jboss.netty.util.Timer來對讀寫超時或者閑置鏈接的通知
6.org.jboss.netty.logging
根據不同的log framework 實現的類
7.org.jboss.netty.util
nettyutil類
org.jboss.netty.util.internal
netty內部util類,不被外部使用
JSF 探索 (1)
雖然JSF已經出來好久了,而且好像感覺不是很潮流的框架了,然后當我看見他的時候,我覺得他的思想很好,而且隨著手機等client多樣化的出現,我相信人們
必將重新拾起JSF的思想。
JSF說白了是事件驅動,web以前的時代我估計大部分都是事件驅動的開發模式,而web的出現,使人們更多關注瀏覽器上面的渲染,以及servlet和http的操作上。
web2.0的出現,使人們感覺在瀏覽器上的操作更像以前c/s結構的操作,而手機client的熱捧更能體現未來多種客戶端訪問server的模式即將到來,也許大家開始
在想如何做新的框架,其實這種想法已經out了,JSF里面早就有這個思想了,你只需要去關注JSF不就ok了?
任何《* in action》的書總是讓programmer 興奮,同樣JSF in Action也是一本不錯的書,讓我們一起去看看它把。
1.JSF 關鍵詞
UI component :靜態對象,它保存在server端,其實本身UI Component是javabean對象,他具有javabean具備的屬性,methods和events。通常多個component被組織為一個頁面的視圖
Renderer:渲染器,renderer被用作渲染component,以及將用戶的輸入轉換為component的值。特別當不同類型的client端,比如手機,那么對應的就有手機相應格式的renderer。
Validator:負責驗證用戶輸入值的可靠性,單個UI component可以對應一個或多個Validator.
Backing beans:后臺的javabean,做一些邏輯處理什么的,存儲component的值,實現事件監聽器,他可以引用component。
Converter:顯示轉換器,比如時間格式的顯示,一個component可以對應一個converter
Events and listeners:事件和監聽器
Messages:顯示給用戶的信息
Navigation:一個頁面到另外一個頁面的向導。
2.JSF請求的六個階段
Phase 1: Restore View
構建視圖頁面供用戶輸入或查看
Phase 2: Apply Request Values
獲取請求值
Phase 3: Process Validations
可以對請求值進行驗證
Phase 4: Update Model Values
更新back bean 的值
Phase 5: Invoke Application
調用應用,執行相應的監聽器
Phase 6: Render Response
將response根據要求進行包裝后返回給用戶,這里的包裝是指知道的頁面技術,比如html,比如手機展現技術
3.client and server component id
server component id可以在component 的id屬性中顯性填寫id,以便在服務端能唯一標識該組件
client id 是繼承server component id,他最后體現的也是html 中的標簽,而id也為對應標簽的id,與server component id不同的是,他有繼承關系,比如
<form id="myForm" method="post"
action="/jia-standard-components/client_ids.jsf"
enctype="application/x-www-form-urlencoded">
<p>
<input type="text" name="myForm:_id1" />
</p>
<p>
<input id="myForm:inputText" type="text" name="myForm:inputText" />
</p>
...
</form>
而對應的服務端
<p>
<h:outputText id="outputText" value="What are you looking at?"/>
</p>
<h:form id="myForm">
<p>
<h:inputText/>
</p>
<p>
<h:inputText id="inputText"/>
</p>
...
</h:form>
4.JSF EL 表達語言: 他是基于JSTL的描述
此外Jsp中application,session,page 四個scoped變量,只有page jsf中不支持
除了上面三個scoped變量,jsf還有下面一些隱性的變量
applicationScope:從application中獲取對象,比如#{applicationScope.myVariable} myVariable對象存放在application中
cookie:從cookie中獲取數據
facesContext:這個jsp2.0中沒有,當前請求的faceContext實例
header:http head頭信息,比如#{header['User-Agent']}
headerValues:多個head頭信息的載體 比如#{headerValues['Accept-Encoding'][3]}
initParam:初始化的一些參數比如servlet context initialization parameters 可以這樣使用#{initParam.adminEmail}
param:等同jsp中的request.getParameter() 用法#{param.address}
paramValues:等同jsp中的request.getParameterValues 用法#{param.address[2]}
requestScope等同于jsp中reqeust 用法#{requestScope.user-Preferences}
sessionScope等同于jsp中session 用法#{sessionScope['user']}
view 這個變量jsp2.0中沒有,它表示當前視圖,它有三個屬性viewId,renderKitId, and locale 用法#{view.locale}
5.需要的jar包和文件
構建jsf環境需要jsf-api.jar,jsf-impl.jar,jstl.jar,standard.jar 以及配置文件faces-config.xml
需要在web.xml 中配置faceservlet
<web-app>
...
<servlet>
<servlet-name>Faces Servlet</servlet-name>
<servlet-class>javax.faces.webapp.FacesServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>Faces Servlet</servlet-name>
<url-pattern>/faces/*</url-pattern>
</servlet-mapping>
...
</web-app>
web.xml 中jsf定義的上下文的參數有
javax.faces.CONFIG_FILES
javax.faces.DEFAULT_SUFFIX
javax.faces.LIFECYCLE_ID
javax.faces.STATE_SAVING_METHOD
RI-specific configuration parameters:
com.sun.faces.NUMBER_OF_VIEWS_IN_SESSION
com.sun.faces.validateXml
com.sun.faces.verifyObjects
比如
<web-app>
...
<context-param>
<param-name>javax.faces.STATE_SAVING_METHOD</param-name>
<param-value>server</param-value>
</context-param>
<context-param>
<param-name>javax.faces.CONFIG_FILES</param-name>
<param-value>/WEB-INF/navigation.xml,/WEB-INF/RegistrationWizard.xml</
param-value>
</context-param>
...
<web-app>
除了web.xml jsf相關的參數,本身jsf具有faces-config.xml 具體里面的配置屬性可以查看配置文件,可以找可視化工具進行配置。
Java 理論與實踐: 正確使用 Volatile 變量
volatile 變量使用指南
簡介: Java™ 語言包含兩種內在的同步機制:同步塊(或方法)和 volatile 變量。這兩種機制的提出都是為了實現代碼線程的安全性。其中 Volatile 變量的同步性較差(但有時它更簡單并且開銷更低),而且其使用也更容易出錯。在這期的 Java 理論與實踐 中,Brian Goetz 將介紹幾種正確使用 volatile 變量的模式,并針對其適用性限制提出一些建議。
查看本系列更多內容
發布日期: 2007 年 7 月 05 日
級別: 中級
訪問情況 237 次瀏覽
建議: 0 (添加評論)
Java 語言中的 volatile 變量可以被看作是一種 “程度較輕的 synchronized”;與 synchronized 塊相比,volatile 變量所需的編碼較少,并且運行時開銷也較少,但是它所能實現的功能也僅是 synchronized 的一部分。本文介紹了幾種有效使用 volatile 變量的模式,并強調了幾種不適合使用 volatile 變量的情形。
鎖提供了兩種主要特性:互斥(mutual exclusion) 和可見性(visibility)。互斥即一次只允許一個線程持有某個特定的鎖,因此可使用該特性實現對共享數據的協調訪問協議,這樣,一次就只有一個線程能夠使用該共享數據。可見性要更加復雜一些,它必須確保釋放鎖之前對共享數據做出的更改對于隨后獲得該鎖的另一個線程是可見的 —— 如果沒有同步機制提供的這種可見性保證,線程看到的共享變量可能是修改前的值或不一致的值,這將引發許多嚴重問題。
Volatile 變量
Volatile 變量具有 synchronized 的可見性特性,但是不具備原子特性。這就是說線程能夠自動發現 volatile 變量的最新值。Volatile 變量可用于提供線程安全,但是只能應用于非常有限的一組用例:多個變量之間或者某個變量的當前值與修改后值之間沒有約束。因此,單獨使用 volatile 還不足以實現計數器、互斥鎖或任何具有與多個變量相關的不變式(Invariants)的類(例如 “start <=end”)。
出于簡易性或可伸縮性的考慮,您可能傾向于使用 volatile 變量而不是鎖。當使用 volatile 變量而非鎖時,某些習慣用法(idiom)更加易于編碼和閱讀。此外,volatile 變量不會像鎖那樣造成線程阻塞,因此也很少造成可伸縮性問題。在某些情況下,如果讀操作遠遠大于寫操作,volatile 變量還可以提供優于鎖的性能優勢。
正確使用 volatile 變量的條件
您只能在有限的一些情形下使用 volatile 變量替代鎖。要使 volatile 變量提供理想的線程安全,必須同時滿足下面兩個條件:
- 對變量的寫操作不依賴于當前值。
- 該變量沒有包含在具有其他變量的不變式中。
實際上,這些條件表明,可以被寫入 volatile 變量的這些有效值獨立于任何程序的狀態,包括變量的當前狀態。
第一個條件的限制使 volatile 變量不能用作線程安全計數器。雖然增量操作(x++)看上去類似一個單獨操作,實際上它是一個由讀取-修改-寫入操作序列組成的組合操作,必須以原子方式執行,而 volatile 不能提供必須的原子特性。實現正確的操作需要使 x 的值在操作期間保持不變,而 volatile 變量無法實現這點。(然而,如果將值調整為只從單個線程寫入,那么可以忽略第一個條件。)
大多數編程情形都會與這兩個條件的其中之一沖突,使得 volatile 變量不能像 synchronized 那樣普遍適用于實現線程安全。清單 1 顯示了一個非線程安全的數值范圍類。它包含了一個不變式 —— 下界總是小于或等于上界。
清單 1. 非線程安全的數值范圍類
@NotThreadSafe
public class NumberRange {
private int lower, upper;
public int getLower() { return lower; }
public int getUpper() { return upper; }
public void setLower(int value) {
if (value > upper)
throw new IllegalArgumentException(...);
lower = value;
}
public void setUpper(int value) {
if (value < lower)
throw new IllegalArgumentException(...);
upper = value;
}
}
|
這種方式限制了范圍的狀態變量,因此將 lower 和 upper 字段定義為 volatile 類型不能夠充分實現類的線程安全;從而仍然需要使用同步。否則,如果湊巧兩個線程在同一時間使用不一致的值執行 setLower 和 setUpper 的話,則會使范圍處于不一致的狀態。例如,如果初始狀態是 (0, 5),同一時間內,線程 A 調用 setLower(4) 并且線程 B 調用 setUpper(3),顯然這兩個操作交叉存入的值是不符合條件的,那么兩個線程都會通過用于保護不變式的檢查,使得最后的范圍值是 (4, 3) —— 一個無效值。至于針對范圍的其他操作,我們需要使 setLower() 和 setUpper() 操作原子化 —— 而將字段定義為 volatile 類型是無法實現這一目的的。
性能考慮
使用 volatile 變量的主要原因是其簡易性:在某些情形下,使用 volatile 變量要比使用相應的鎖簡單得多。使用 volatile 變量次要原因是其性能:某些情況下,volatile 變量同步機制的性能要優于鎖。
很難做出準確、全面的評價,例如 “X 總是比 Y 快”,尤其是對 JVM 內在的操作而言。(例如,某些情況下 VM 也許能夠完全刪除鎖機制,這使得我們難以抽象地比較 volatile 和 synchronized 的開銷。)就是說,在目前大多數的處理器架構上,volatile 讀操作開銷非常低 —— 幾乎和非 volatile 讀操作一樣。而 volatile 寫操作的開銷要比非 volatile 寫操作多很多,因為要保證可見性需要實現內存界定(Memory Fence),即便如此,volatile 的總開銷仍然要比鎖獲取低。
volatile 操作不會像鎖一樣造成阻塞,因此,在能夠安全使用 volatile 的情況下,volatile 可以提供一些優于鎖的可伸縮特性。如果讀操作的次數要遠遠超過寫操作,與鎖相比,volatile 變量通常能夠減少同步的性能開銷。
正確使用 volatile 的模式
很多并發性專家事實上往往引導用戶遠離 volatile 變量,因為使用它們要比使用鎖更加容易出錯。然而,如果謹慎地遵循一些良好定義的模式,就能夠在很多場合內安全地使用 volatile 變量。要始終牢記使用 volatile 的限制 —— 只有在狀態真正獨立于程序內其他內容時才能使用 volatile —— 這條規則能夠避免將這些模式擴展到不安全的用例。
模式 #1:狀態標志
也許實現 volatile 變量的規范使用僅僅是使用一個布爾狀態標志,用于指示發生了一個重要的一次性事件,例如完成初始化或請求停機。
很多應用程序包含了一種控制結構,形式為 “在還沒有準備好停止程序時再執行一些工作”,如清單 2 所示:
清單 2. 將 volatile 變量作為狀態標志使用
volatile boolean shutdownRequested;
...
public void shutdown() { shutdownRequested = true; }
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}
|
很可能會從循環外部調用 shutdown() 方法 —— 即在另一個線程中 —— 因此,需要執行某種同步來確保正確實現 shutdownRequested變量的可見性。(可能會從 JMX 偵聽程序、GUI 事件線程中的操作偵聽程序、通過 RMI 、通過一個 Web 服務等調用)。然而,使用synchronized 塊編寫循環要比使用清單 2 所示的 volatile 狀態標志編寫麻煩很多。由于 volatile 簡化了編碼,并且狀態標志并不依賴于程序內任何其他狀態,因此此處非常適合使用 volatile。
這種類型的狀態標記的一個公共特性是:通常只有一種狀態轉換;shutdownRequested 標志從 false 轉換為 true,然后程序停止。這種模式可以擴展到來回轉換的狀態標志,但是只有在轉換周期不被察覺的情況下才能擴展(從 false 到 true,再轉換到 false)。此外,還需要某些原子狀態轉換機制,例如原子變量。
模式 #2:一次性安全發布(one-time safe publication)
缺乏同步會導致無法實現可見性,這使得確定何時寫入對象引用而不是原語值變得更加困難。在缺乏同步的情況下,可能會遇到某個對象引用的更新值(由另一個線程寫入)和該對象狀態的舊值同時存在。(這就是造成著名的雙重檢查鎖定(double-checked-locking)問題的根源,其中對象引用在沒有同步的情況下進行讀操作,產生的問題是您可能會看到一個更新的引用,但是仍然會通過該引用看到不完全構造的對象)。
實現安全發布對象的一種技術就是將對象引用定義為 volatile 類型。清單 3 展示了一個示例,其中后臺線程在啟動階段從數據庫加載一些數據。其他代碼在能夠利用這些數據時,在使用之前將檢查這些數據是否曾經發布過。
清單 3. 將 volatile 變量用于一次性安全發布
public class BackgroundFloobleLoader {
public volatile Flooble theFlooble;
public void initInBackground() {
// do lots of stuff
theFlooble = new Flooble(); // this is the only write to theFlooble
}
}
public class SomeOtherClass {
public void doWork() {
while (true) {
// do some stuff...
// use the Flooble, but only if it is ready
if (floobleLoader.theFlooble != null)
doSomething(floobleLoader.theFlooble);
}
}
}
|
如果 theFlooble 引用不是 volatile 類型,doWork() 中的代碼在解除對 theFlooble 的引用時,將會得到一個不完全構造的 Flooble。
該模式的一個必要條件是:被發布的對象必須是線程安全的,或者是有效的不可變對象(有效不可變意味著對象的狀態在發布之后永遠不會被修改)。volatile 類型的引用可以確保對象的發布形式的可見性,但是如果對象的狀態在發布后將發生更改,那么就需要額外的同步。
模式 #3:獨立觀察(independent observation)
安全使用 volatile 的另一種簡單模式是:定期 “發布” 觀察結果供程序內部使用。例如,假設有一種環境傳感器能夠感覺環境溫度。一個后臺線程可能會每隔幾秒讀取一次該傳感器,并更新包含當前文檔的 volatile 變量。然后,其他線程可以讀取這個變量,從而隨時能夠看到最新的溫度值。
使用該模式的另一種應用程序就是收集程序的統計信息。清單 4 展示了身份驗證機制如何記憶最近一次登錄的用戶的名字。將反復使用 lastUser 引用來發布值,以供程序的其他部分使用。
清單 4. 將 volatile 變量用于多個獨立觀察結果的發布
public class UserManager {
public volatile String lastUser;
public boolean authenticate(String user, String password) {
boolean valid = passwordIsValid(user, password);
if (valid) {
User u = new User();
activeUsers.add(u);
lastUser = user;
}
return valid;
}
}
|
該模式是前面模式的擴展;將某個值發布以在程序內的其他地方使用,但是與一次性事件的發布不同,這是一系列獨立事件。這個模式要求被發布的值是有效不可變的 —— 即值的狀態在發布后不會更改。使用該值的代碼需要清楚該值可能隨時發生變化。
模式 #4:“volatile bean” 模式
volatile bean 模式適用于將 JavaBeans 作為“榮譽結構”使用的框架。在 volatile bean 模式中,JavaBean 被用作一組具有 getter 和/或 setter 方法 的獨立屬性的容器。volatile bean 模式的基本原理是:很多框架為易變數據的持有者(例如 HttpSession)提供了容器,但是放入這些容器中的對象必須是線程安全的。
在 volatile bean 模式中,JavaBean 的所有數據成員都是 volatile 類型的,并且 getter 和 setter 方法必須非常普通 —— 除了獲取或設置相應的屬性外,不能包含任何邏輯。此外,對于對象引用的數據成員,引用的對象必須是有效不可變的。(這將禁止具有數組值的屬性,因為當數組引用被聲明為 volatile 時,只有引用而不是數組本身具有 volatile 語義)。對于任何 volatile 變量,不變式或約束都不能包含 JavaBean 屬性。清單 5 中的示例展示了遵守 volatile bean 模式的 JavaBean:
清單 5. 遵守 volatile bean 模式的 Person 對象
@ThreadSafe
public class Person {
private volatile String firstName;
private volatile String lastName;
private volatile int age;
public String getFirstName() { return firstName; }
public String getLastName() { return lastName; }
public int getAge() { return age; }
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public void setAge(int age) {
this.age = age;
}
}
|
volatile 的高級模式
前面幾節介紹的模式涵蓋了大部分的基本用例,在這些模式中使用 volatile 非常有用并且簡單。這一節將介紹一種更加高級的模式,在該模式中,volatile 將提供性能或可伸縮性優勢。
volatile 應用的的高級模式非常脆弱。因此,必須對假設的條件仔細證明,并且這些模式被嚴格地封裝了起來,因為即使非常小的更改也會損壞您的代碼!同樣,使用更高級的 volatile 用例的原因是它能夠提升性能,確保在開始應用高級模式之前,真正確定需要實現這種性能獲益。需要對這些模式進行權衡,放棄可讀性或可維護性來換取可能的性能收益 —— 如果您不需要提升性能(或者不能夠通過一個嚴格的測試程序證明您需要它),那么這很可能是一次糟糕的交易,因為您很可能會得不償失,換來的東西要比放棄的東西價值更低。
模式 #5:開銷較低的讀-寫鎖策略
目前為止,您應該了解了 volatile 的功能還不足以實現計數器。因為 ++x 實際上是三種操作(讀、添加、存儲)的簡單組合,如果多個線程湊巧試圖同時對 volatile 計數器執行增量操作,那么它的更新值有可能會丟失。
然而,如果讀操作遠遠超過寫操作,您可以結合使用內部鎖和 volatile 變量來減少公共代碼路徑的開銷。清單 6 中顯示的線程安全的計數器使用 synchronized 確保增量操作是原子的,并使用 volatile 保證當前結果的可見性。如果更新不頻繁的話,該方法可實現更好的性能,因為讀路徑的開銷僅僅涉及 volatile 讀操作,這通常要優于一個無競爭的鎖獲取的開銷。
清單 6. 結合使用 volatile 和 synchronized 實現 “開銷較低的讀-寫鎖”
@ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatile int value;
public int getValue() { return value; }
public synchronized int increment() {
return value++;
}
}
|
之所以將這種技術稱之為 “開銷較低的讀-寫鎖” 是因為您使用了不同的同步機制進行讀寫操作。因為本例中的寫操作違反了使用 volatile 的第一個條件,因此不能使用 volatile 安全地實現計數器 —— 您必須使用鎖。然而,您可以在讀操作中使用 volatile 確保當前值的可見性,因此可以使用鎖進行所有變化的操作,使用 volatile 進行只讀操作。其中,鎖一次只允許一個線程訪問值,volatile 允許多個線程執行讀操作,因此當使用 volatile 保證讀代碼路徑時,要比使用鎖執行全部代碼路徑獲得更高的共享度 —— 就像讀-寫操作一樣。然而,要隨時牢記這種模式的弱點:如果超越了該模式的最基本應用,結合這兩個競爭的同步機制將變得非常困難。
結束語
與鎖相比,Volatile 變量是一種非常簡單但同時又非常脆弱的同步機制,它在某些情況下將提供優于鎖的性能和伸縮性。如果嚴格遵循 volatile 的使用條件 —— 即變量真正獨立于其他變量和自己以前的值 —— 在某些情況下可以使用 volatile 代替 synchronized 來簡化代碼。然而,使用 volatile 的代碼往往比使用鎖的代碼更加容易出錯。本文介紹的模式涵蓋了可以使用 volatile 代替synchronized 的最常見的一些用例。遵循這些模式(注意使用時不要超過各自的限制)可以幫助您安全地實現大多數用例,使用 volatile 變量獲得更佳性能。
參考資料
學習
討論
關于作者
Java NIO---Channel部分
Channel 是連接buffer和Io設備之間的管道,當然channel也可以一頭連接channel
Basic Channel Interface:
public interface Channel
{
public boolean isOpen( );
public void close( ) throws IOException;
}
1.open channel
channel作為i/o 設備的管道,分為兩種,一種文件(file),另一種是端口(Socket)
file相關的只有fileChannel
socket相關的有SocketChannel, ServerSocketChannel和DatagramChannel.
socket channel可以通過factory創建新的socket channel
比如
SocketChannel sc = SocketChannel.open( );
sc.connect (new InetSocketAddress ("somehost", someport));
ServerSocketChannel ssc = ServerSocketChannel.open( );
ssc.socket( ).bind (new InetSocketAddress (somelocalport));
而fileChannel 則不能這樣,他是在一個打開的andomAccessFile, FileInputStream或者FileOutputStream
對象上getChannel()
比如
RandomAccessFile raf = new RandomAccessFile ("somefile", "r");
FileChannel fc = raf.getChannel( );
2.Using Channels
三個接口:
public interface ReadableByteChannel
extends Channel
{
public int read (ByteBuffer dst) throws IOException;
}
public interface WritableByteChannel
extends Channel
{
public int write (ByteBuffer src) throws IOException;
}
public interface ByteChannel
extends ReadableByteChannel, WritableByteChannel
{
}
需要注意的是 fileChannel 雖然也有write,read方法,但是他們能否調用write read方法是由file相關的訪問權限決定的。
channel 有blocking和nonblocking兩種模式,nonblocking是指永遠不會將一個正在調用的線程sleep,他們被請求的結果要么
立刻完成,要么返回一個nothing的結果。
只有stream-oriented的channels(比如sockets and pipes)可以用nonblocking模式
3.Closing Channels
和buffer不一樣,channel不能被重用,用完之后一定要close,此外當一個線程被設置為interrupt狀態,當該線程試圖訪問某個channel
的話,該channel將立刻關閉。
4.Scatter/Gather
當我們在多個buffer上執行一個i/O操作的時候,我們需要將多個buffer放在一個buffer數組一并讓channel來處理
Scatter/Gather interface:
public interface ScatteringByteChannel
extends ReadableByteChannel
{
public long read (ByteBuffer [] dsts)
throws IOException;
public long read (ByteBuffer [] dsts, int offset, int length)
throws IOException;
}
public interface GatheringByteChannel
extends WritableByteChannel
{
public long write(ByteBuffer[] srcs)
throws IOException;
public long write(ByteBuffer[] srcs, int offset, int length)
throws IOException;
}
例子:
ByteBuffer header = ByteBuffer.allocateDirect (10);
ByteBuffer body = ByteBuffer.allocateDirect (80);
ByteBuffer [] buffers = { header, body };
int bytesRead = channel.read (buffers);
5.File Channels
filechannel 只能是blocking模式也就是被鎖住模式,不能是nonblocking模式
public abstract class FileChannel
extends AbstractChannel
implements ByteChannel, GatheringByteChannel, ScatteringByteChannel
{
// This is a partial API listing
public abstract void truncate (long size)
public abstract void force (boolean metaData)
}
fileChannel 中有truncate和force 兩個方法
truncate (long size)是以給定的size來切斷file
force (boolean metaData) file屬性的修改立刻影響到disk上
6.File Locking
file 鎖雖然在fileChannel中提出,但是需要注意本身lock是和file相關,而且不同的操作系統提供的file也有不同,和channel無關的
public abstract class FileChannel
extends AbstractChannel
implements ByteChannel, GatheringByteChannel, ScatteringByteChannel
{
// This is a partial API listing
public final FileLock lock( )
public abstract FileLock lock (long position, long size,
boolean shared)
public final FileLock tryLock( )
public abstract FileLock tryLock (long position, long size,
boolean shared)
}
lock 有三個參數,第一個是開始鎖住的file的postion, 第二個是鎖住的file大小,前面這兩個參數就能定義了一塊lock范圍,第三個是
顯示lock是shared(true)類型還是exclusive(false)類型,
沒有參數的lock()其實等同于fileChannel.lock (0L, Long.MAX_VALUE, false);
FileLock 本身是線程安全的,可以多個線程同時訪問
tryLock() 和Lock()相似,當某個lock因為其他原因不能被獲取,那么就要用tryLock() 這個時候就返回null
FileLock總關聯一個特定的channel,可以通過channel()獲取相關聯的channel,當FileLock release(),那么對于的channel也就相應的close();
7.Memory-Mapped Files
Memory-mapped files 一般效率更高,而且因為他是和操作系統相關的,所有他不會消費jvm分配的內存
通過map()來建立MappedByteBuffer,
mapped buffers和lock有點不同,lock和產生它的channel綁定,如果channel closed那么lock也就消失
而mapped buffers本身也沒有ummap方法,他是通過自身不再被引用然后被系統垃圾回收的。
8.Channel-to-Channel Transfers
channel直接的傳輸可以提供更好的效率
public abstract class FileChannel
extends AbstractChannel
implements ByteChannel, GatheringByteChannel, ScatteringByteChannel
{
// This is a partial API listing
public abstract long transferTo (long position, long count,
WritableByteChannel target)
Java NIO
90
public abstract long transferFrom (ReadableByteChannel src,
long position, long count)
}
這個是能在filechannel之間使用,兩個socketchannel之間不能直接使用transferTo和transferFrom,但是因為socketchannel繼承WritableByteChannel and ReadableByteChannel,所有可以將一個文件的內容transferTo socketChannel或直接通過transferFrom從socketChannel中讀取數據
9.Socket Channels
對應以前一般一個線程對應一個socket,而在NIO中可以一個線程對應成百上千的socket,同時沒有性能降低的問題
三種socket channel(DatagramChannel,SocketChannel, and ServerSocketChannel)
DatagramChannel和SocketChannel 有read和write的方法
而ServerSocketChannel 則是監聽connection和創建SocketChannel,他本身不參與數據的傳輸
這三個channel都可以通過socket()方法獲取到對應的Socket,ServerSocket,DatagramSocket
需要說明的是,socket不一樣要綁定channel,通過傳統的new 創建socket,那么getChannel()就會返回null
SocketChannel 有Nonblocking和blocking 兩種模式
SocketChannel sc = SocketChannel.open( );
sc.configureBlocking (false); // nonblocking
...
if ( ! sc.isBlocking( )) {
doSomething (cs);
}
可以通過configureBlocking 來設置,true表示blocking mode 而false 表示nonblocking mode
對應大型應用并發處理的 建議使用nonblocking mode
看看下面的例子:
Socket socket = null;
Object lockObj = serverChannel.blockingLock( );
// have a handle to the lock object, but haven't locked it yet
// may block here until lock is acquired
synchronize (lockObj)
{
// This thread now owns the lock; mode can't be changed
boolean prevState = serverChannel.isBlocking( );
serverChannel.configureBlocking (false);
socket = serverChannel.accept( );
serverChannel.configureBlocking (prevState);
}
// lock is now released, mode is allowed to change
if (socket != null) {
doSomethingWithTheSocket (socket);
}
體驗一下 blockingLock()和lock()的區別
SocketChannel 可以通過finishConnect( ),isConnectPending( ), or isConnected( )獲取當前connection的狀態
socket是面向流的,datagram是面向packet的
因此DatagramChannel 就是面向packet協議的channel,比如UDP/IP
10.pipe 方式 可以研究一下
Java NIO---buffer部分
最近想建一個網絡傳輸的平臺,查看到了Jboss 的Netty,而他們核心的傳輸是用了JDK 1.4以后的
NIO特性,因此借機會學習一下NIO
NIO主要有下面幾大部分
Buffer:Io的操作少不了緩存,通過Buffer能大大提高傳輸的效率,同樣NIO中也有Buffer的這部分
Buffer針對數據類型有相應的子類,他們都是繼承Buffer class
比如CharBuffer,IntBuffer等等
需要說明的子類MappedByteBuffer 通過命名可以看出這個MappedByteBuffer有mapped+byte+Buffer組成
據我理解 這么mapped 是指memory-mapped
這里解釋一下memory-mapped, 以為我們說的buffer 可能就是指物理上的內存,包括jdk 以前的io
一般情況下,buffer指物理上的內存沒什么問題,可以物理內存畢竟比較有限,當需要很大buffer存放數據的時候
物理內存就不夠,那么就引出一個虛擬內存的概念,就像現在的os 一樣,也有虛擬內存的概念,虛擬內存本質上
是存在硬盤上的,只是物理內存存放的不是具體的數據而是虛擬內存上的地址,而具體的數據則是在虛擬內存上,這樣
物理內存只是存放很多地址,這樣就大大增加了buffer的size。當然如果你buffer的數據很小,也可以知道放入物理內存
因此我認為 這個memory-mapped 是指的用虛擬內存的哪種緩存模式
A.Buffer的 attribute
1.Capacity:buffer的大小,一個buffer按照某個Capacity創建后就不能修改
2.Limit:用了多少buffer
3.Position:指針,獲取下一個元素的位置,操作get(),put(),這個position會自動更新(和iterator相似)
4.Mark:被標記的指針位置 通過mark()操作可以使mark = position 通過reset() 可以使position = mark
上面這幾個屬性應該符合下面條件
0 <= mark <= position <= limit <= capacity
B. fill:插入數據
用put() 方法可以插入一段數據 但是這個時候postion 在插入這段數據的尾部
C. flip:彈出數據
因為上面寫入數據后,指針在尾部不是從0開始,那么我們需要
buffer.limit(buffer.position( )).position(0);
將limit 設置為當前的postion,limit 可以告訴方法這段數據什么時候結束,而具體可以調用方法
hasRemaining( ) 來判斷是否數據結束。
同時將當前指針設置為0
NIO 提供了方法buffer.flip()完成上面的動作
另外方法rewind( )和flip相似 只是區別在于flip要修改limit,而rewind不修改limit
rewind 用處可以在已經flip后,還能重讀這段數據
Buffer不是線程安全的,如果你想要多線程同時訪問,那么需要用synchronization
D. Mark:讓buffer記住某個指針,已備后面之用。
調用mark()就能將當前指針mark住
而調用reset()就能將當前指針回到mark了的指針位置,如果mark未定義,那么調用reset就會報InvalidMarkException
此外rewind( ), clear( ), and flip( )這些操作將會拋棄mark,這樣clear()和reset()區別
clear表示清空buffer 而reset表示能將當前指針回到mark了的指針位置
E:Comparing:buffer 也是java的object sub class,所有buffer也能對象進行比較
public abstract class ByteBuffer
extends Buffer implements Comparable
{
// This is a partial API listing
public boolean equals (Object ob)
public int compareTo (Object ob)
}
兩個buffer 認為相等,需要具備下面條件
1.buffer 類型相同
2.buffer里面保留的元素數量相同,buffer capacities不需要相同,這里需要注意保留的元素是指有效的元素,不是指buffer里面有的元素。
其實就從position到limit這段的元素,當然當前的postion和limit值都可以不相同,但這段數據要相同
3.remaining data 的數據順序要相同,可以通過get()來循環獲取出來后判斷每個element都相同
如果同時符合上面三個條件,那么就表示buffer object 相等
F:Bulk Moves
如何在buffer中大塊的數據移動,對性能起到關鍵作用
他的做法是get的時候,將一塊數據取出放入數組里面,這樣比起循環get()一個byte要效率高多了,那么對于塊狀數據總是有個指定的長度
這個長度就是指定數組的長度
public CharBuffer get (char [] dst, int offset, int length)
這里就是length。
如果只有參數為數組buffer.get (myArray);
那么其實也是指定了長度,只是長度為數組的長度,上面的語句等同于
buffer.get (myArray, 0, myArray.length);
針對上面,有可能buffer的data 小于myArray.length,這個時候如果取buffer 那么會報錯
所以需要下面的寫法
char [] bigArray = new char [1000];
// Get count of chars remaining in the buffer
int length = buffer.remaining( );
// Buffer is known to contain < 1,000 chars
buffer.get (bigArrray, 0, length);
// Do something useful with the data
processData (bigArray, length);
這是buffer<length
如果buffer>length 那需要loop:
char [] smallArray = new char [10];
while (buffer.hasRemaining( )) {
int length = Math.min (buffer.remaining( ), smallArray.length);
buffer.get (smallArray, 0, length);
processData (smallArray, length);
}
同樣操作put是將array中的數據放入buffer,他同樣有上面length的問題,需要用remaining來判斷
G:創建Buffer: buffer class 不能直接new創建,他們都是abstract class,但是他們都有static factory,通過factory可以創建instances
比如
public abstract class CharBuffer
extends Buffer implements CharSequence, Comparable
{
// This is a partial API listing
public static CharBuffer allocate (int capacity)
public static CharBuffer wrap (char [] array)
public static CharBuffer wrap (char [] array, int offset,
int length)
public final boolean hasArray( )
public final char [] array( )
public final int arrayOffset( )
}
可以通過allocation或者wrapping來創建buffer
Alloction:允許分配私有buffer
CharBuffer charBuffer = CharBuffer.allocate (100);
wrapping:不允許分配私有buffer,顯性提供存儲
char [] myArray = new char [100];
CharBuffer charbuffer = CharBuffer.wrap (myArray);
而myArray 叫做buffer的backing array
通過hasArray( ) 判斷buffer是否存在backing array
如果為true,可通過array()得到array的引用
H:Duplicating Buffers 復制buffer
Duplicat() 創建一個和原來一樣的新的buffer,他們都有各自的postion,limit,mark, 但是共享同樣的數據,也就是說任何一個buffer被修改了
他們看到的數據也就修改了。創建的新buffer繼承了老buffer的屬性,比如如果老buffer為readonly,那么新的也是readonly
asReadOnlyBuffer( ) 和Duplicat()相似,只是區別asReadOnlyBuffer( ) 創建的buffer總是readonly
slice() 和Duplicat()也相似,不同之處在于slice() 將修改buffer的capacity=(limit - position),同時新buffer以老buffer的當前postion作為開始
指針。
I:Byte Buffers 可以獲取不同類型的buffer,另外byte本身也能排序
J:Direct Buffers: 對于操作系統來說,內存存儲的數據不一定是連續的。而Direct buffer直接用于和io設備進行交互,對于io設備操作的buffer只能是
direct buffer,如果是nondirect ByteBuffer需要寫入設備,那么他首先是創建一個臨時的direct byteBuffer,然后將內容考入這個臨時direct buffer,
接著進行底層的io操作,完成io操作后,臨時buffer將被垃圾回收。
ByteBuffer.allocateDirect()創建direct buffer,isDirect( )則判斷buffer是否是direct buffer
K:View Buffers 當一堆數據被收到后需要先查看他,然后才能確定是send還是怎么處理,這個時候就要引入View buffer
View Buffer擁有自己的屬性,比如postion,limit,mark,但是他是和初始buffer共享數據的,這個和duplicated,sliced相似,但是view Buffer
能將raw bytes 映射為指定的基礎類型buffer,這個也是查看的具體內容了,我們也可以認為是byte buffer向其他基礎類型buffer的轉換
public abstract class ByteBuffer
extends Buffer implements Comparable
{
// This is a partial API listing
public abstract CharBuffer asCharBuffer( );
public abstract ShortBuffer asShortBuffer( );
public abstract IntBuffer asIntBuffer( );
public abstract LongBuffer asLongBuffer( );
public abstract FloatBuffer asFloatBuffer( );
public abstract DoubleBuffer asDoubleBuffer( );
}