大家使用多線程無非是為了提高性能,但如果多線程使用不當,不但性能提升不明顯,而且會使得資源消耗更大。下面列舉一下可能會造成多線程性能問題的點:
下面分別解析以上性能隱患
死鎖
關于死鎖,我們在學習操作系統的時候就知道它產生的原因和危害,這里就不從原理上去累述了,可以從下面的代碼和圖示重溫一下死鎖產生的原因:
- public class LeftRightDeadlock {
- private final Object left = new Object();
- private final Object right = new Object();
- public void leftRight() {
- synchronized (left) {
- synchronized (right) {
- doSomething();
- }
- }
- }
- public void rightLeft() {
- synchronized (right) {
- synchronized (left) {
- doSomethingElse();
- }
- }
- }
- }

預防和處理死鎖的方法:
1)盡量不要在釋放鎖之前競爭其他鎖
一般可以通過細化同步方法來實現,只在真正需要保護共享資源的地方去拿鎖,并盡快釋放鎖,這樣可以有效降低在同步方法里調用其他同步方法的情況
2)順序索取鎖資源
如果實在無法避免嵌套索取鎖資源,則需要制定一個索取鎖資源的策略,先規劃好有哪些鎖,然后各個線程按照一個順序去索取,不要出現上面那個例子中不同順序,這樣就會有潛在的死鎖問題
3)嘗試定時鎖
Java 5提供了更靈活的鎖工具,可以顯式地索取和釋放鎖。那么在索取鎖的時候可以設定一個超時時間,如果超過這個時間還沒索取到鎖,則不會繼續堵塞而是放棄此次任務,示例代碼如下:
- public boolean trySendOnSharedLine(String message,
- long timeout, TimeUnit unit)
- throws InterruptedException {
- long nanosToLock = unit.toNanos(timeout)
- - estimatedNanosToSend(message);
- if (!lock.tryLock(nanosToLock, NANOSECONDS))
- return false;
- try {
- return sendOnSharedLine(message);
- } finally {
- lock.unlock();
- }
- }
這樣可以有效打破死鎖條件。
4)檢查死鎖
JVM采用thread dump的方式來識別死鎖的方式,可以通過操作系統的命令來向JVM發送thread dump的信號,這樣可以查詢哪些線程死鎖。
過多串行化
用多線程實際上就是想并行地做事情,但這些事情由于某些依賴性必須串行工作,導致很多環節得串行化,這實際上很局限系統的可擴展性,就算加CPU加線程,但性能卻沒有線性增長。有個Amdahl定理可以說明這個問題:
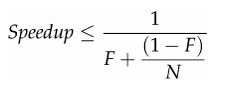
其中,F是串行化比例,N是處理器數量,由上可知,只有盡可能減少串行化,才能最大化地提高可擴展能力。降低串行化的關鍵就是降低鎖競爭,當很多并行任務掛在鎖的獲取上,就是串行化的表現
過多鎖競爭
過多鎖競爭的危害是不言而喻的,那么看看有哪些辦法來降低鎖競爭
1)縮小鎖的范圍
前面也談到這一點,盡量縮小鎖保護的范圍,快進快出,因此盡量不要直接在方法上使用synchronized關鍵字,而只是在真正需要線程安全保護的地方使用
2)減小鎖的粒度
Java 5提供了顯式鎖后,可以更為靈活的來保護共享變量。synchronized關鍵字(用在方法上)是默認把整個對象作為鎖,實際上很多時候沒有必要用這么大一個鎖,這會導致這個類所有synchronized都得串行執行。可以根據真正需要保護的共享變量作為鎖,也可以使用更為精細的策略,目的就是要在真正需要串行的時候串行,舉一個例子:
- public class StripedMap {
- // Synchronization policy: buckets[n] guarded by locks[n%N_LOCKS]
- private static final int N_LOCKS = 16;
- private final Node[] buckets;
- private final Object[] locks;
- private static class Node { ... }
- public StripedMap(int numBuckets) {
- buckets = new Node[numBuckets];
- locks = new Object[N_LOCKS];
- for (int i = 0; i < N_LOCKS; i++)
- locks[i] = new Object();
- }
- private final int hash(Object key) {
- return Math.abs(key.hashCode() % buckets.length);
- }
- public Object get(Object key) {
- int hash = hash(key);
- synchronized (locks[hash % N_LOCKS]) {
- for (Node m = buckets[hash]; m != null; m = m.next)
- if (m.key.equals(key))
- return m.value;
- }
- return null;
- }
- public void clear() {
- for (int i = 0; i < buckets.length; i++) {
- synchronized (locks[i % N_LOCKS]) {
- buckets[i] = null;
- }
- }
- }
- ...
- }
上面這個例子是通過hash算法來把存取的值所對應的hash值來作為鎖,這樣就只需要對hash值相同的對象存取串行化,而不是像HashTable那樣對任何對象任何操作都串行化。
3)減少共享資源的依賴
共享資源是競爭鎖的源頭,在多線程開發中盡量減少對共享資源的依賴,比如對象池的技術應該慎重考慮,新的JVM對新建對象以做了足夠的優化,性能非常好,如果用對象池不但不能提高多少性能,反而會因為鎖競爭導致降低線程的可并發性。
4)使用讀寫分離鎖來替換獨占鎖
Java 5提供了一個讀寫分離鎖(ReadWriteLock)來實現讀-讀并發,讀-寫串行,寫-寫串行的特性。這種方式更進一步提高了可并發性,因為有些場景大部分是讀操作,因此沒必要串行工作。關于ReadWriteLock的具體使用可以參加一下示例:
- public class ReadWriteMap<K,V> {
- private final Map<K,V> map;
- private final ReadWriteLock lock = new ReentrantReadWriteLock();
- private final Lock r = lock.readLock();
- private final Lock w = lock.writeLock();
- public ReadWriteMap(Map<K,V> map) {
- this.map = map;
- }
- public V put(K key, V value) {
- w.lock();
- try {
- return map.put(key, value);
- } finally {
- w.unlock();
- }
- }
- // Do the same for remove(), putAll(), clear()
- public V get(Object key) {
- r.lock();
- try {
- return map.get(key);
- } finally {
- r.unlock();
- }
- }
- // Do the same for other read-only Map methods
- }
切換上下文
線程比較多的時候,操作系統切換線程上下文的性能消耗是不能忽略的,在構建高性能web之路------web服務器長連接 可以看出在進程切換上的代價,當然線程會更輕量一些,不過道理是類似的
內存同步
當使用到synchronized、volatile或Lock的時候,都會為了保證可見性導致更多的內存同步,這就無法享受到JMM結構帶來了性能優化。