By Steve Mushero
LinuxеҶ…ж ёеңЁжҖ§иғҪж–ҡwқўе·Із»ҸҫlҸеҺҶдәҶеҫҲй•ҝдёҖҢDү|—¶й—ҙзҡ„иҖғйӘҢеQҢе°Өе…¶жҳҜ2.6/3.xеҶ…ж ёгҖӮ然иҖҢпјҢеңЁй«ҳIOеQҢе°Өе…¶жҳҜҫ|‘з»ңж–ҡwқўзҡ„жғ…еҶөдёӢеQҢеҜ№дёӯж–ӯзҡ„еӨ„зҗҶеҸҜиғҪжҲҗдёәй—®йўҳгҖӮжҲ‘们已ҫl?/span> еңЁжӢҘжңүдёҖдёӘжҲ–еӨҡдёӘйҘұе’Ң1Gbpsҫ|‘еҚЎзҡ„й«ҳжҖ§иғҪҫpИқ»ҹдёҠеҸ‘зҺ°иҝҮҳqҷдёӘй—®йўҳеQҢиҝ‘жқҘеңЁжңүи®ёеӨҡе°ҸеҢ…еЖҲеҸ‘пјҲеӨ§зәҰ10000packets/secondеQүи¶…иҪҪзҡ„иҷҡжӢҹжңЮZёҠ д№ҹеҸ‘зҺоCәҶҳqҷдёӘй—®йўҳгҖ?/span>
еҺҹеӣ еҫҲжё…жҘҡпјҡеңЁжңҖҪҺҖеҚ•зҡ„жЁЎејҸдёӯпјҢеҶ…ж ёйҖҡиҝҮјӢ¬дҡgдёӯж–ӯзҡ„ж–№ејҸжқҘеӨ„зҗҶжҜҸдёӘжқҘиҮӘдәҺзҪ‘еҚЎзҡ„еҢ…гҖӮдҪҶжҳҜйҡҸзқҖ ж•°жҚ®еҢ…йҖҹзҺҮзҡ„еўһй•ҝпјҢеёҰжқҘзҡ„дёӯж–ӯжёҗжёҗи¶…ҳqҮдәҶеҚ•дёӘcpuеҸҜеӨ„зҗҶзҡ„иҢғеӣҙгҖӮеҚ•cpuжҰӮеҝөеҫҲйҮҚиҰҒпјҢҫpИқ»ҹҪҺЎзҗҶе‘ҳеҜ№жӯӨеҫҖеҫҖи®ӨиҜҶдёҚиғцгҖӮеңЁдёҖдёӘжҷ®йҖҡзҡ„4-16ж ёзҡ„ҫpИқ»ҹдёӯпјҢеӣ?/span> дёәж•ҙдҪ?/span>cpuзҡ„дӢЙз”ЁзҺҮең?/span>6-25%е·ҰеҸітq¶дё”ҫpИқ»ҹзңӢдёҠеҺХdҫҲжӯЈеёёеQҢжүҖд»ҘдёҖдёӘиҝҮиҪҪзҡ„еҶ…ж ёеҫҲйҡҫиў«еҸ‘зҺҺНјҢгҖӮдҪҶжҳҜзі»ҫlҹе°ҶҳqҗиЎҢеҫҲж…ўеQҢеЖҲдё”дјҡеңЁжІЎжңүе‘ҠиӯҰпјҢжІЎжңүdmesgж—?/span> еҝ—пјҢжІЎжңүжҳҺжҳҫеҫҒе…Ҷзҡ„жғ…еҶөдёӢдёҘйҮҚдёўеҢ…гҖ?/span>
дҪҶжҳҜдҪ дӢЙз”?/span>topжҹҘзңӢеӨҡдёӘcpuжЁЎејҸ(ҳqҗиЎҢtopеQҢжҺҘзқҖй”®е…Ҙ1)ж—УһјҢ%si еҲ—пјҲҫpИқ»ҹдёӯж–ӯеQүжҲ–иҖ?/span>mpstatе‘ҪдЧoдё?/span> irqеҲ?/span>(mpstat -P ALL 1)еQҢеңЁдёҖдәӣз№Ғеҝҷзҡ„ҫpИқ»ҹдёӯдҪ дјҡеҸ‘зҺоCёӯж–ӯжҳҺжҳ‘ЦҫҲй«ҳпјҢйҖҡиҝҮҫlҸиҝӣдёҖжӯ?/span>mpstatдҪҝз”ЁеQҢдҪ дјҡзңӢеҲ°е“Әдё?/span>cpuжҲ–иҖ…е“ӘдёӘи®ҫеӨҮеӯҳеңЁй—®йўҳгҖ?/span>
дҪ йңҖиҰҒдёҖдёӘиҫғж–°зүҲжң¬зҡ„mpstatеQҢеҸҜд»ҘиҝҗиЎ?/span>-I жЁЎејҸеQҢз”Ёд»ҘеҲ—еҮ?/span>irqиҙҹиқІеQҢиҝҗиЎҢеҰӮдёӢе‘Ҫд»Өпјҡ
mpstat -I SUM -P ALL 1
ӯ‘…иҝҮ5000/ҝU?/span> жңүзӮ№ҫJҒеҝҷеQ?/span> 1дё?/span>-2дё?/span>/ҝU’зӣёеҪ“й«ҳдәҶгҖ?/span>
ҳqҗиЎҢеҰӮдёӢе‘ҪдЧoжқҘзЎ®и®ӨйӮЈдёӘи®ҫеӨ?/span>/ҷе№зӣ®еҜЖDҮҙиҙҹиқІеQ?/span>
mpstat -I CPU -P ALL 1
ҳqҷдёӘиҫ“еҮәеҫҲйҡҫиў«йҳ…иҜ»пјҢдҪҶжҳҜдҪ еҸҜд»Ҙи·ҹнtӘжӯЈјӢ®зҡ„еҲ—з”ЁжқҘзЎ®и®Өе“ӘдёӘдёӯж–ӯеҜјиҮҙиҙҹиҪҪпјҢдҫӢеҰӮеQ?/span>15еQ?/span>19еQ?/span>995. дҪ д№ҹеҸҜд»Ҙе®ҡд№үдҪ жғіжҹҘзңӢзҡ?/span>cpu
mpstat -I CPU -P 3 1 # 3 ең?/span>top,htopдёӯеҸҜд»Ҙе®ҡдҪҚдёҚеҗҢзҡ„cpuгҖӮпјҲtopе’?/span>mpstatйғҪжҳҜд»?/span>0ејҖе§ӢпјҢhtopжҳҜд»Һ1ејҖе§Ӣи®Ўж•ҺНјү
и®°еҪ•дёӢдёӯж–ӯж•°еQҢдҪ һ®ұеҸҜд»ҘжҹҘзңӢдёӯж–ӯиЎЁ еQ?/span>"cat /proc/interrupts" жү‘ЦҲ°mpstat'sеҫ—еҲ°зҡ„ж•°еӯ—пјҢдҪ еҸҜд»ҘеҸ‘зҺ°жҳҜе“ӘдёӘи®‘ЦӨҮеңЁдӢЙз”Ёдёӯж–ӯгҖӮиҝҷдёӘж–Ү件д№ҹжҢҮзӨәдәҶдӢЙз”ЁиҜҘдёӯж–ӯзҡ?/span>#еҸҜд»Ҙе‘ҠиҜүдҪ жҳҜд»Җд№ҲеҜјиҮҙиҝҮиҪҪгҖ?/span>
йңҖиҰҒеҒҡд»Җд№Ҳе‘ўеQ?/span>
йҰ–е…ҲеQҢзЎ®и®ӨдҪ жҳҜеҗҰҳqҗиЎҢirqbalanceеQҢиҝҷдёӘжҳҜniceе®ҲжҠӨҳqӣзЁӢе®ғдјҡиҮӘеҠЁең?/span>cpuй—ҙжү©еұ•дёӯж–ӯгҖӮеңЁҫJҒеҝҷзҡ„зі»ҫlҹдёӯеҫҲйҮҚиҰҒпјҢһ®Өе…¶жҳҜдёӨеқ—зҪ‘еҚЎпјҢеӣ дШ“й»ҳи®Өcpu0 һ®ҶеӨ„зҗҶжүҖжңүдёӯж–ӯпјҢҫpИқ»ҹеҫҲе®№жҳ“иҝҮиҪҪгҖ?/span>irqbalanceжү©ж•Јҳqҷдәӣдёӯж–ӯз”Ёд»ҘйҷҚдҪҺиҙҹиқІгҖӮдШ“дәҶжҖ§иғҪжңҖеӨ§еҢ–еQҢдҪ еҸҜд»ҘжүӢеҠЁтqҢҷЎЎҳqҷдәӣдёӯж–ӯһ®ҶеҘ—жҺҘеӯ—е’Ңи¶…ҫUҝзЁӢе…ЧғнnеҶ…ж ёеҲ?/span> ж•ЈпјҢдҪҶжҳҜйҖҡеёёжІЎеҝ…иҰҒиҝҷд№Ҳйә»зғҰгҖ?/span>
дҪҶжҳҜеҚідӢЙжү©еұ•дәҶдёӯж–ӯпјҢжҹҗеқ—ҫ|‘еҚЎҳqҳжҳҜеҸҜиғҪеҜЖDҮҙжҹҗдёҖдё?/span>cpuҳqҮиқІгҖӮиҝҷеҸ–еҶідәҺдҪ зҡ„зҪ‘еҚЎе’Ңй©ұеҠЁеQҢдҪҶйҖҡеёёжңүдёӨҝUҚжңүж•Ҳзҡ„ж–ТҺі•жқҘйҳІжӯўиҝҷж пLҡ„дәӢжғ…еҸ‘з”ҹгҖ?/span>
ҪW¬дёҖҝUҚжҳҜеӨҡзҪ‘еҚЎйҳҹеҲ—пјҢжңүдәӣIntelҫ|‘еҚЎһ®ұеҸҜд»Ҙиҝҷд№ҲеҒҡгҖӮеҰӮжһң他们жңү4дёӘйҳҹеҲ—пјҢһ®ұеҸҜд»ҘжңүеӣӣдёӘcpuеҶ…ж ёеҗҢж—¶еӨ„зҗҶдёҚеҗҢзҡ„дёӯж–ӯз”Ёд»ҘеҲҶж•ЈиҙҹиҪҪгҖӮйҖҡеёёй©ұеҠЁдјҡиҮӘеҠЁиҝҷд№ҲеҒҡеQҢдҪ д№ҹеҸҜд»ҘйҖҡиҝҮmpstatе‘ҪдЧoжқҘзЎ®и®ӨгҖ?/span>
ҪW¬дәҢҝUҚпјҢтq¶дё”йҖҡеёёд№ҹжҳҜжӣҙеҠ йҮҚиҰҒзҡ„пјҢҫ|‘еҚЎй©ұеҠЁйҖүйЎ№——'IRQ coalescing'еQҢдёӯж–ӯиҜ·жұӮеҗҲтq¶гҖӮиҝҷдёӘйҖүйЎ№жңүзқҖејәеӨ§зҡ„еҠҹиғҪпјҢе…Ғи®ёҫ|‘еҚЎеңЁи°ғз”Ёдёӯж–ӯиҜ·жұӮеүҚҫ~“еӯҳж•оCёӘж•°жҚ®еҢ…пјҢд»ҺиҖҢдШ“ҫpИқ»ҹиҠӮзәҰеӨ§йҮҸзҡ„ж—¶й—ҙе’ҢиҙҹиқІгҖӮдӢDдёӘдҫӢеӯҗпјҡ еҰӮжһңҫ|‘еҚЎҫ~“еӯҳ10дёӘеҢ…еQҢйӮЈд№?/span>cpuиҙҹиқІһ®ҶеӨ§ҫUҰйҷҚдҪ?/span>90%гҖӮиҝҷдёӘеҠҹиғҪйҖҡеёёз”?/span>ethtoolе·Ҙе…·жқҘжҺ§еҲУһјҢдҪҝз”Ё'-c/-C'еҸӮж•°еQҢдҪҶжҳҜжңүдәӣй©ұеҠЁиҰҒжұӮеңЁй©ұеҠЁеҲқж¬Ў еҠ иқІж—¶е°ұеҒҡеҘҪзӣёе…іи®„ЎҪ®гҖӮеҰӮдҪ•и®ҫҫ|®йңҖиҰҒжҹҘзңӢжң¬жңәж–ҮжЎЈгҖӮдӢDдёӘдҫӢеӯҗпјҢжңүдәӣҫ|‘еҚЎеQҢиӯ¬еҰӮжҲ‘们дӢЙз”Ёзҡ„Intelҫ|‘еҚЎеQҢе°ұжң?/span>automaticжЁЎејҸеҸҜд»Ҙж ТҺҚ®иҙҹиқІиҮӘеҠЁеҒҡеҲ° жңҖдјҳеҢ–гҖ?/span>
 жңҖеҗҺпјҢһ®ұеғҸжҲ‘们еңЁиҷҡжӢҹжңәдёӯзңӢеҲ°зҡ„дёҖдәӣй©ұеҠЁпјҢе®ғ们дёҚж”ҜжҢҒеӨҡйҳҹеҲ—жҲ–иҖ…дёӯж–ӯиҜ·жұӮеҗҲтq¶гҖӮиҝҷҝUҚжғ…еҶөдёӢеQҢдёҖж—ҰеӨ„зҗҶдёӯж–ӯзҡ„cpuҫJҒеҝҷеQҢе°ұдјҡдс”з”ҹжҖ§иғҪз“үҷўҲеQҢйҷӨйқһдҪ жӣҙжҚўи®‘ЦӨҮжҲ–иҖ…й©ұеҠЁгҖ?/span>
жңҖеҗҺпјҢһ®ұеғҸжҲ‘们еңЁиҷҡжӢҹжңәдёӯзңӢеҲ°зҡ„дёҖдәӣй©ұеҠЁпјҢе®ғ们дёҚж”ҜжҢҒеӨҡйҳҹеҲ—жҲ–иҖ…дёӯж–ӯиҜ·жұӮеҗҲтq¶гҖӮиҝҷҝUҚжғ…еҶөдёӢеQҢдёҖж—ҰеӨ„зҗҶдёӯж–ӯзҡ„cpuҫJҒеҝҷеQҢе°ұдјҡдс”з”ҹжҖ§иғҪз“үҷўҲеQҢйҷӨйқһдҪ жӣҙжҚўи®‘ЦӨҮжҲ–иҖ…й©ұеҠЁгҖ?/span>
ҳqҷжҳҜдёҖдёӘеӨҚжқӮзҡ„еҢәеҹҹеQҢеЖҲдёҚе№ҝдёЮZқhзҹҘпјҢдҪҶжңүдәӣдёҚй”ҷзҡ„жҠҖжңҜзңҹзҡ„еҸҜд»ҘжҸҗй«ҳз№Ғеҝҷзі»ҫlҹзҡ„жҖ§иғҪгҖӮжӯӨеӨ–пјҢдёҖдәӣйўқеӨ–зҡ„й’ҲеҜ№жҖ§зӣ‘жҺ§пјҢеҸҜд»Ҙеё®еҠ©еҲ°жҹҘжү‘Ц’ҢиҜҠж–ӯҳqҷдәӣйҡҫд»ҘеҸ‘зҺ°зҡ„й—®йўҳгҖ?/span>
жң¬ж–Үз”?/span> Steve Mushero, иҒ”еҗҲеҲӣе§Ӣдәәе…јйҰ–еёӯжү§иЎҢе®ҳеҸ‘иЎЁдәҺ2012тq?/span>4жң?/span>25ж—?/span>
дҪңиҖ…з®Җд»Ӣпјҡ
Steve Mushero
дә‘з»ңеҲӣе§ӢдәәпјҢйҰ–еёӯжҠҖжңҜе®ҳ
Steve Musheroе…Ҳз”ҹжӢҘжңүӯ‘…иҝҮ20тqҙеңЁеҗ„иЎҢдёҡзҡ„еQҢеӣҪйҷ…жҖ§зҡ„жҠҖжңҜз®ЎзҗҶз»ҸйӘҢгҖӮд»–жӣ„Ў»ҸжӢ…д“QеңҹиұҶҫ|‘зҡ„йҰ–еёӯжҠҖжңҜе®ҳеQҢиҙҹиҙ?/span>Intermindзҡ„й«ҳҫU§з®ЎзҗҶзі»ҫlҹпјҢең?/span>Beyond Access Communications е’?/span> AirReviewжӢ…д“QйҰ–еёӯжһ¶жһ„еёҲгҖӮд»–жҳ?/span>Managing White-Collar Job Migration to AsiaдёҖд№Ұзҡ„дҪңиҖ…пјҢеӨҡйЎ№дё“еҲ©зҡ„еҸ‘жҳҺиҖ…гҖ?/span>
дә‘з»ңҫ|‘з»ңҝU‘жҠҖеQҲдёҠӢ№шPјүжңүйҷҗе…¬еҸёжҢҒжңүжңҖҫlҲи§ЈйҮҠжқғ
иҪ¬иҮӘhttp://wenku.baidu.com/view/38a764b8f121dd36a32d828e.html
SIPзҡ„第еӣӣжңҹҫl“жқҹдәҶпјҢеӣ дШ“жҺ§еҲ¶Ҫ{–з•Ҙзҡ„дё°еҜҢпјҢж—©е…Ҳзҡ„зҡ„еҺӢеҠӣӢ№ӢиҜ•ҫl“жһңе·Із»Ҹж— жі•еҸҚжҳ еңЁй«ҳтq¶еҸ‘е’Ңй«ҳеҺӢеҠӣдё?/span>SIPзҡ„иҝҗиЎҢзҠ¶еҶөпјҢеӣ жӯӨйңҖиҰҒйҮҚж–оCҪңеҺӢеҠӣӢ№ӢиҜ•гҖӮи·ҹеңЁжөӢиҜ•дқhе‘ҳеҗҺйқўеҒҡдәҶеҝ«дёҖе‘Ёзҡ„еҺӢеҠӣӢ№ӢиҜ•еQҢеҺӢеҠӣжөӢиҜ•зҡ„жҠҘе‘Ҡд№ҹжӯЈејҸеҮәзӮүпјҢжң¬жқҘд№ҹе°ұҪҺ—жҳҜе‘ҠдёҖҢDөиҗҪеQҢдҪҶҪW¬дәҢеӨ©жөӢиҜ•дқhе‘ҳиҜҙиҰҒдҝ®ж”ТҺҠҘе‘ҠпјҢз”ЧғәҺҳqҷж¬ЎдҪңеҺӢеҠӣжөӢиҜ•зҡ„еҗҢеӯҰжҳҜ第дёҖӢЖЎдҪңеQҢжңүдёҖдёӘжҢҮж ҮжІЎжңүжіЁж„ҸпјҢеӣ жӯӨйңҖиҰҒдҝ®ж”№еҮ дёӘжөӢиҜ•з»“жһңгҖӮйӮЈдёӘжІЎжңүжіЁж„Ҹзҡ„жҢҮж Үһ®ұжҳҜload averageеQҢд»–е’ҢжҲ‘дёҖж ·ејҖе§ӢеҸӘжҳҜжіЁж„ҸдәҶCPUеQҢеҶ…еӯҳзҡ„дҪҝз”ЁзҠ¶еҶөеQҢиҖҢжІЎжңүеӨӘжіЁж„ҸҳqҷдёӘжҢҮж ҮеQҢиҝҷдёӘжҢҮж ҮдёҺ他们йҖҡеёёзҡ„йҷҗеҲУһјҲ10е·ҰеҸіеQүжңүе·®еҲ«гҖӮйҮҚж–°жөӢиҜ•зҡ„ҫl“жһңз”ЧғәҺҳqҷдёӘжҢҮж Үиў«иҰҒжұӮеҺӢдҪҺпјҢжңҖеҗҺзҡ„жҠҘе‘Ҡжҳ„Ў„¶дёҚеҰӮеҺҹжқҘзҡ„еҘҪзңӢгҖӮиҮӘе·Чғ№ҹжІЎжңүж·ұе…ҘҳqҮеҺӢеҠӣжөӢиҜ•пјҢдҪҶжҳҜи§үеҫ—дёҚжҗһжҳҺзҷҪеҜ№е°ҶжқҘжңәеҷЁй…Қҫ|®е’Ңжү©е®№йғҪдјҡжңүеӘ„е“ҚпјҢеӣ жӯӨеҺ»й—®дә?/span>DBAе’?/span>SAеQҢеҫ—еҲ°зҡ„ҫl“жһңзӣёе·®еҫҲеӨ§еQҢзңӢжқҘдёҚеҫ—дёҚиҮӘе·ұеҺАLүҫжүщN—®йўҳзҡ„ж ТҺң¬жүҖеңЁдәҶгҖ?/span>
йҖҡиҝҮдёӢйқўзҡ„еҮ дёӘйғЁеҲҶзҡ„дәҶи§ЈеQҢеҸҜд»ҘдёҖжӯҘдёҖжӯҘзҡ„жү‘ЦҮәLoad AverageеңЁеҺӢеҠӣжөӢиҜ•дёӯзңҹжӯЈзҡ„дҪңз”ЁгҖ?/span>
CPUж—үҷ—ҙзү?/span>
дёЮZәҶжҸҗй«ҳҪEӢеәҸжү§иЎҢж•ҲзҺҮеQҢеӨ§е®¶еңЁеҫҲеӨҡеә”з”ЁдёӯйғҪйҮҮз”ЁдәҶеӨҡҫUҝзЁӢжЁЎејҸеQҢиҝҷж ·еҸҜд»Ҙе°ҶеҺҹжқҘзҡ„еәҸеҲ—еҢ–жү§иЎҢеҸҳдШ“тq¶иЎҢжү§иЎҢеQҢд“QеҠЎзҡ„еҲҶи§Јд»ҘеҸҠтq¶иЎҢжү§иЎҢиғҪеӨҹжһҒеӨ§ең°жҸҗй«ҳзЁӢеәҸзҡ„ҳqҗиЎҢж•ҲзҺҮгҖӮдҪҶҳqҷйғҪжҳҜд»Јз Ғзс”еҲ«зҡ„иЎЁзҺ°еQҢиҖҢ硬件жҳҜеҰӮдҪ•ж”ҜжҢҒзҡ„е‘ўеQҹйӮЈһ®ЮpҰҒйқ?/span>CPUзҡ„ж—¶й—ҙзүҮжЁЎејҸжқҘиҜҙжҳҺиҝҷдёҖеҲҮгҖӮзЁӢеәҸзҡ„д»ЦMҪ•жҢҮдЧoзҡ„жү§иЎҢеҫҖеҫҖйғҪдјҡиҰҒз«һдә?/span>CPUҳqҷдёӘжңҖе®қиҙөзҡ„иө„жәҗпјҢдёҚи®әдҪ зҡ„ҪEӢеәҸеҲҶжҲҗдәҶеӨҡһ®‘дёӘҫUҝзЁӢеҺАLү§иЎҢдёҚеҗҢзҡ„д»ХdҠЎеQҢ他们йғҪеҝ…йЎ»жҺ’йҳҹҪ{үеҫ…иҺ·еҸ–ҳqҷдёӘиө„жәҗжқҘи®ЎҪҺ—е’ҢеӨ„зҗҶе‘ҪдЧoгҖӮе…ҲзңӢзңӢеҚ?/span>CPUзҡ„жғ…еҶьcҖӮдёӢйқўдёӨеӣҫжҸҸҳqоCәҶж—үҷ—ҙзүҮжЁЎејҸе’Ңйқһж—¶й—ҙзүҮжЁЎејҸдёӢзҡ„ҫUҝзЁӢжү§иЎҢзҡ„жғ…еҶөпјҡ
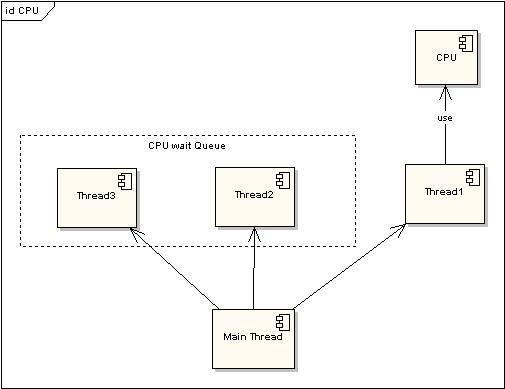
еӣ?/span> 1 йқһж—¶й—ҙзүҮҫUҝзЁӢжү§иЎҢжғ…еҶө
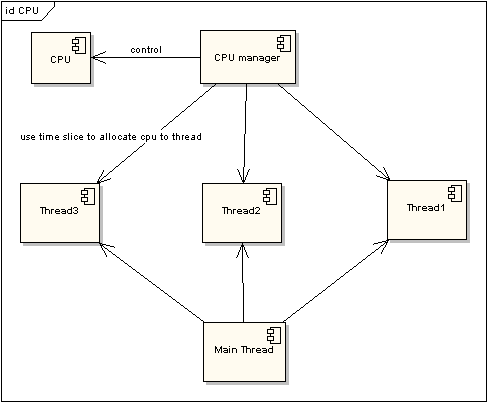
еӣ?/span> 2 йқһж—¶й—ҙзүҮҫUҝзЁӢжү§иЎҢжғ…еҶө
еңЁеӣҫдёҖдёӯеҸҜд»ҘзңӢеҲҺНјҢд»ЦMҪ•ҫUҝзЁӢеҰӮжһңйғҪжҺ’йҳҹзӯүеҫ?/span>CPUиө„жәҗзҡ„иҺ·еҸ–пјҢйӮЈд№ҲжүҖи°“зҡ„еӨҡзәҝҪEӢе°ұжІЎжңүд»ЦMҪ•е®һйҷ…ж„Ҹд№үгҖӮеӣҫдәҢдёӯзҡ?/span>CPU ManagerеҸӘжҳҜжҲ‘иҷҡжӢҹзҡ„дёҖдёӘи§’иүФҢјҢз”ұе®ғжқҘеҲҶй…Қе’ҢҪҺЎзҗҶCPUзҡ„дӢЙз”ЁзҠ¶еҶөпјҢжӯӨж—¶еӨҡзәҝҪEӢе°ҶдјҡеңЁҳqҗиЎҢҳqҮзЁӢдёӯйғҪжңүжңәдјҡеҫ—еҲ?/span>CPUиө„жәҗеQҢд№ҹзңҹжӯЈе®һзҺ°дәҶеңЁеҚ?/span>CPUзҡ„жғ…еҶөдёӢе®һзҺ°еӨҡзәҝҪEӢеЖҲиЎҢеӨ„зҗҶгҖ?/span>
еӨ?/span>CPUзҡ„жғ…еҶөеҸӘжҳҜеҚ•CPUзҡ„жү©еұ•пјҢеҪ“жүҖжңүзҡ„CPUйғҪж»ЎиҙҹиҚ·ҳqҗдҪңзҡ„ж—¶еҖҷпјҢһ®ЧғјҡеҜТҺҜҸдёҖдё?/span>CPUйҮҮз”Ёж—үҷ—ҙзүҮзҡ„ж–№ејҸжқҘжҸҗй«ҳж•ҲзҺҮгҖ?/span>
ең?/span>Linuxзҡ„еҶ…ж ёеӨ„зҗҶиҝҮҪEӢдёӯеQҢжҜҸдёҖдёӘиҝӣҪEӢй»ҳи®ӨдјҡжңүдёҖдёӘеӣәе®ҡзҡ„ж—үҷ—ҙзүҮжқҘжү§иЎҢе‘ҪдЧoеQҲй»ҳи®ӨдШ“1/100ҝU’пјүеQҢиҝҷҢDү|—¶й—ҙеҶ…ҳqӣзЁӢиў«еҲҶй…ҚеҲ°CPUеQҢ然еҗҺзӢ¬еҚ дӢЙз”ЁгҖӮеҰӮжһңдӢЙз”Ёе®ҢеQҢеҗҢж—¶жңӘеҲ°ж—¶й—ҙзүҮзҡ„规е®ҡж—¶й—Я_јҢйӮЈд№Ҳһ®Чғё»еҠЁж”ҫеј?/span>CPUзҡ„еҚ з”ЁпјҢеҰӮжһңеҲ°ж—¶й—ҙзүҮһ®ҡжңӘе®ҢжҲҗе·ҘдҪңеQҢйӮЈд№?/span>CPUзҡ„дӢЙз”Ёжқғд№ҹдјҡ被收еӣһпјҢҳqӣзЁӢһ®Ҷдјҡиў«дёӯж–ӯжҢӮиөпLӯүеҫ…дёӢдёҖдёӘж—¶й—ҙзүҮгҖ?/span>
CPUеҲ©з”ЁзҺҮе’ҢLoad Averageзҡ„еҢәеҲ?/span>
еҺӢеҠӣӢ№ӢиҜ•дёҚд»…йңҖиҰҒеҜ№дёҡеҠЎеңәжҷҜзҡ„еЖҲеҸ‘з”ЁжҲпLӯүеҺӢеҠӣеҸӮж•°дҪңжЁЎжӢҹпјҢеҗҢж—¶д№ҹйңҖиҰҒеңЁеҺӢеҠӣӢ№ӢиҜ•ҳqҮзЁӢдёӯйҡҸж—¶е…іжіЁжңәеҷЁзҡ„жҖ§иғҪжғ…еҶөеQҢжқҘјӢ®дҝқеҺӢеҠӣӢ№ӢиҜ•зҡ„жңүж•ҲжҖ§гҖӮеҪ“жңҚеҠЎеҷЁй•ҝжңҹеӨ„дәҺдёҖҝUҚи¶…иҙҹиҚ·зҡ„жғ…еҶөдёӢҳqҗиЎҢеQҢжүҖиғҪжҺҘ收зҡ„еҺӢеҠӣтq¶дёҚжҳҜжҲ‘们жүҖи®ӨдШ“зҡ„еҸҜжҺҘеҸ—зҡ„еҺӢеҠӣгҖӮе°ұеҘҪжҜ”ҷе№зӣ®ҫlҸзҗҶеңЁз»ҷдёҖдёӘдқhдј°е·ҘдҪңйҮҸзҡ„ж—¶еҖҷпјҢжҜҸеӨ©йғҪи®©ҳqҷдёӘдәәе·ҘдҪ?/span>12дёӘе°Ҹж—УһјҢйӮЈд№ҲжүҖеҲ¶е®ҡзҡ„йЎ№зӣ®и®ЎеҲ’е°ұдёҚжҳҜдёҖдёӘеҗҲзҗҶзҡ„и®ЎеҲ’еQҢйӮЈдёӘдқhҳqҹж—©дјҡеһ®жҺүпјҢиҖҢеӘ„е“Қж•ҙдҪ“зҡ„ҷе№зӣ®ҳqӣеәҰгҖ?/span>
CPUеҲ©з”ЁзҺҮеңЁҳqҮеҺ»еёёеёёиў«жҲ‘们иҝҷдәӣеӨ–иЎҢи®ӨдёәжҳҜеҲӨж–ӯжңәеҷЁжҳҜеҗҰе·Із»ҸеҲоCәҶж»ЎиҙҹиҚпLҡ„дёҖдёӘж ҮеҮҶпјҢзңӢеҲ°50%-60%зҡ„дӢЙз”ЁзҺҮһ®Юp®ӨдёәжңәеҷЁе°ұе·Із»ҸеҺӢеҲ°дәҶдҸНз•ҢдәҶгҖ?/span>CPUеҲ©з”ЁзҺҮпјҢҷе‘ЦҗҚжҖқд№үһ®ұжҳҜеҜ№дәҺCPUзҡ„дӢЙз”ЁзҠ¶еҶөпјҢҳqҷжҳҜеҜ№дёҖдёӘж—¶й—ҙж®өеҶ?/span>CPUдҪҝз”ЁзҠ¶еҶөзҡ„з»ҹи®ЎпјҢйҖҡиҝҮҳqҷдёӘжҢҮж ҮеҸҜд»ҘзңӢеҮәеңЁжҹҗдёҖдёӘж—¶й—ҙж®өеҶ?/span>CPUиў«еҚ з”Ёзҡ„жғ…еҶөеQҢеҰӮжһңиў«еҚ з”Ёж—үҷ—ҙеҫҲй«ҳеQҢйӮЈд№Ҳе°ұйңҖиҰҒиҖғиҷ‘CPUжҳҜеҗҰе·Із»ҸеӨ„дәҺӯ‘…иҙҹиҚҜӮҝҗдҪңпјҢй•ҝжңҹӯ‘…иҙҹиҚҜӮҝҗдҪңеҜ№дәҺжңәеҷЁжң¬нw«жқҘиҜҙжҳҜдёҖҝUҚжҚҹе®»IјҢеӣ жӯӨеҝ…йЎ»һ®?/span>CPUзҡ„еҲ©з”ЁзҺҮжҺ§еҲ¶еңЁдёҖе®ҡзҡ„жҜ”дҫӢдёӢпјҢд»ҘдҝқиҜҒжңәеҷЁзҡ„жӯЈеёёҳqҗдҪңгҖ?/span>
Load Averageжҳ?/span>CPUзҡ?/span>LoadеQҢе®ғжүҖеҢ…еҗ«зҡ„дҝЎжҒҜдёҚжҳ?/span>CPUзҡ„дӢЙз”ЁзҺҮзҠ¶еҶөеQҢиҖҢжҳҜеңЁдёҖҢDү|—¶й—ҙеҶ…CPUжӯЈеңЁеӨ„зҗҶд»ҘеҸҠҪ{үеҫ…CPUеӨ„зҗҶзҡ„иҝӣҪEӢж•°д№Ӣе’Ңзҡ„з»ҹи®ЎдҝЎжҒҜпјҢд№ҹе°ұжҳ?/span>CPUдҪҝз”ЁйҳҹеҲ—зҡ„й•ҝеәҰзҡ„ҫlҹи®ЎдҝЎжҒҜгҖӮдШ“д»Җд№ҲиҰҒҫlҹи®ЎҳqҷдёӘдҝЎжҒҜеQҢиҝҷдёӘдҝЎжҒҜзҡ„еҜ№дәҺеҺӢеҠӣӢ№ӢиҜ•зҡ„еӘ„е“Қ究з«ҹжҳҜжҖҺд№Ҳж пLҡ„еQҢйӮЈһ®ұйҖҡиҝҮдёҖдёӘзұ»жҜ”жқҘи§ЈйҮҠCPUеҲ©з”ЁзҺҮе’ҢLoad Averageзҡ„еҢәеҲ«д»ҘеҸҠеҜ№дәҺеҺӢеҠӣжөӢиҜ•зҡ„жҢҮеҜјж„Ҹд№үгҖ?/span>
жҲ‘们һ®?/span>CPUһ®Юqұ»жҜ”дШ“з”өиҜқдәӯпјҢжҜҸдёҖдёӘиҝӣҪEӢйғҪжҳҜдёҖдёӘйңҖиҰҒжү“з”өиҜқзҡ„дқhгҖӮзҺ°еңЁдёҖе…ұжңү4дёӘз”өиҜқдәӯеQҲе°ұеҘҪжҜ”жҲ‘们зҡ„жңәеҷЁжңү4ж ёпјүеQҢжңү10дёӘдқhйңҖиҰҒжү“з”өиҜқгҖӮзҺ°еңЁдӢЙз”Ёз”өиҜқзҡ„规еҲҷжҳҜз®ЎзҗҶе‘ҳдјҡжҢүз…§йЎәеәҸз»ҷжҜҸдёҖдёӘдқhиҪ®жөҒеҲҶй…Қ1еҲҶй’ҹзҡ„дӢЙз”Ёз”өиҜқж—¶й—Я_јҢеҰӮжһңдҪҝз”ЁиҖ…еңЁ1еҲҶй’ҹеҶ…дӢЙз”Ёе®ҢжҜ•пјҢйӮЈд№ҲеҸҜд»Ҙз«ӢеҲ»һ®Ҷз”өиҜқдӢЙз”Ёжқғҳq”иҝҳҫlҷз®ЎзҗҶе‘ҳеQҢеҰӮжһңеҲ°дә?/span>1еҲҶй’ҹз”өиҜқдҪҝз”ЁиҖ…иҝҳжІЎжңүдҪҝз”Ёе®ҢжҜ•еQҢйӮЈд№ҲйңҖиҰҒйҮҚж–°жҺ’йҳҹпјҢҪ{үеҫ…еҶҚж¬ЎеҲҶй…ҚдҪҝз”ЁгҖ?/span>
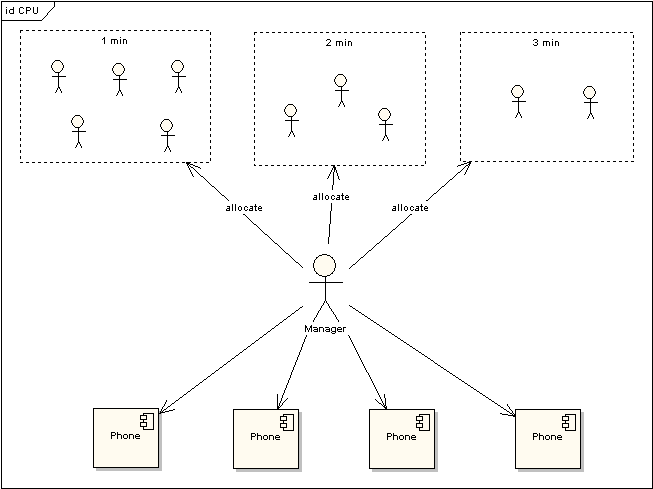
еӣ?/span> 3 з”өиҜқдҪҝз”ЁеңәжҷҜ
дёҠеӣҫдёӯеҜ№дәҺдӢЙз”Ёз”өиҜқзҡ„з”ЁжҲ·еҸҲдҪңдәҶдёҖӢЖЎеҲҶҫc»пјҢ1minзҡ„д»ЈиЎЁиҝҷдәӣдӢЙз”ЁиҖ…еҚ з”Ёз”өиҜқж—¶й—ҙе°ҸдәҺзӯүдә?/span>1minеQ?/span>2minиЎЁзӨәдҪҝз”ЁиҖ…еҚ з”Ёз”өиҜқж—¶й—ҙе°ҸдәҺзӯүдә?/span>2minеQҢд»ҘжӯӨзұ»жҺЁгҖӮж №жҚ®з”өиҜқдӢЙ用规еҲҷпјҢ1minзҡ„з”ЁжҲ·еҸӘйңҖиҰҒеҫ—еҲоCёҖӢЖЎеҲҶй…ҚеҚіеҸҜе®ҢжҲҗйҖҡиҜқеQҢиҖҢе…¶д»–дёӨҫcИқ”ЁжҲ·йңҖиҰҒжҺ’йҳҹдёӨӢЖЎеҲ°дёүж¬ЎгҖ?/span>
з”өиҜқзҡ„еҲ©з”ЁзҺҮ = sum (active use cpu time)/period
жҜҸдёҖдёӘеҲҶй…ҚеҲ°з”өиҜқзҡ„дӢЙз”ЁиҖ…дӢЙз”Ёз”өиҜқж—¶й—ҙзҡ„жҖХd’ҢеҺ»йҷӨд»Ҙз»ҹи®Ўзҡ„ж—үҷ—ҙҢDьcҖӮиҝҷйҮҢйңҖиҰҒжіЁж„Ҹзҡ„жҳҜжҳҜдҪҝз”Ёз”өиҜқзҡ„ж—¶й—ҙжҖХd’Ң(sum(active use cpu time))еQҢиҝҷдёҺеҚ з”Ёж—¶й—ҙзҡ„жҖХd’Ң(sum(occupy cpu time))жҳҜжңүеҢәеҲ«зҡ„гҖӮпјҲдҫӢеҰӮдёҖдёӘз”ЁжҲ·еҫ—еҲоCәҶдёҖеҲҶй’ҹзҡ„дӢЙз”ЁжқғеQҢеңЁ10ҝU’й’ҹеҶ…жү“дәҶз”өиҜқпјҢ然еҗҺеҺАLҹҘиҜўеҸ·з Ғжң¬иҠЧғәҶ20ҝU’й’ҹеQҢеҶҚз”Ёеү©дёӢзҡ„30ҝU’жү“дәҶеҸҰдёҖдёӘз”өиҜқпјҢйӮЈд№ҲеҚ з”ЁдәҶз”өиҜ?/span>1еҲҶй’ҹеQҢе®һйҷ…еҸӘжҳҜдӢЙз”ЁдәҶ40ҝU’пјү
з”өиҜқзҡ?/span>Average LoadдҪ“зҺ°зҡ„жҳҜеңЁжҹҗдёҖҫlҹи®Ўж—үҷ—ҙҢDөеҶ…еQҢжүҖжңүдӢЙз”Ёз”өиҜқзҡ„дәәеҠ дёҠзӯүеҫ…з”өиҜқеҲҶй…Қзҡ„дәЮZёҖдёӘег^еқҮз»ҹи®ЎгҖ?/span>
з”өиҜқеҲ©з”ЁзҺҮзҡ„ҫlҹи®ЎиғҪеӨҹеҸҚжҳ зҡ„жҳҜз”өиҜқиў«дӢЙз”Ёзҡ„жғ…еҶөеQҢеҪ“з”өиҜқй•ҝжңҹеӨ„дәҺиў«дӢЙз”ЁиҖҢжІЎжңүзҡ„еҲ°иғцеӨҹзҡ„ж—үҷ—ҙдј‘жҒҜй—ҙжӯҮеQҢйӮЈд№ҲеҜ№дәҺз”өиҜқ硬件жқҘиҜҙжҳҜдёҖҝUҚи¶…иҙҹиҚ·зҡ„иҝҗдҪңпјҢйңҖиҰҒи°ғж•ҙдӢЙз”Ёйў‘еәҰгҖӮиҖҢз”өиҜ?/span>Average LoadеҚҙд»ҺеҸҰдёҖдёӘи§’еәҰжқҘеұ•зҺ°еҜ№дәҺз”өиҜқдҪҝз”ЁзҠ¶жҖҒзҡ„жҸҸиҝ°еQ?/span>Average Loadӯ‘Ҡй«ҳиҜҙжҳҺеҜ№дәҺз”өиҜқиө„жәҗзҡ„з«һдәүи¶ҠӢИҖзғҲпјҢз”өиҜқиө„жәҗжҜ”иҫғзҹӯзјәгҖӮеҜ№дәҺиө„жәҗзҡ„з”ҢҷҜ·е’Ңз»ҙжҠӨе…¶е®һд№ҹжҳҜйңҖиҰҒеҫҲеӨ§зҡ„жҲҗжң¬еQҢжүҖд»ҘеңЁҳqҷз§Қй«?/span>Average Loadзҡ„жғ…еҶөдёӢз”өиҜқиө„жәҗзҡ„й•ҝжң?#8220;зғӯз«һдә?#8221;д№ҹжҳҜеҜ№дәҺјӢ¬дҡgзҡ„дёҖҝUҚжҚҹе®ҹлҖ?/span>
дҪҺеҲ©з”ЁзҺҮзҡ„жғ…еҶөдёӢжҳҜеҗҰдјҡжңүй«?/span>Load Averageзҡ„жғ…еҶөдс”з”ҹе‘ўеQҹзҗҶи§ЈеҚ жңүж—¶й—ҙе’ҢдҪҝз”Ёж—үҷ—ҙһ®ұеҸҜд»ҘзҹҘйҒ“пјҢеҪ“еҲҶй…Қж—¶й—ҙзүҮд»ҘеҗҺеQҢжҳҜеҗҰдӢЙз”Ёе®Ңе…ЁеҸ–еҶідәҺдҪҝз”ЁиҖ…пјҢеӣ жӯӨе®Ңе…ЁеҸҜиғҪеҮәзҺ°дҪҺеҲ©з”ЁзҺҮй«?/span>Load Averageзҡ„жғ…еҶьcҖӮз”ұжӯӨжқҘзңӢпјҢд»…д»…д»?/span>CPUзҡ„дӢЙз”ЁзҺҮжқҘеҲӨж–?/span>CPUжҳҜеҗҰеӨ„дәҺдёҖҝUҚи¶…иҙҹиҚ·зҡ„е·ҘдҪңзҠ¶жҖҒиҝҳжҳҜдёҚеӨҹзҡ„еQҢеҝ…ҷеИқ»“еҗ?/span>Load AverageжқҘе…ЁеұҖзҡ„зңӢCPUзҡ„дӢЙз”Ёжғ…еҶөе’Ңз”ҢҷҜ·жғ…еҶөгҖ?/span>
жүҖд»ҘеӣһҳqҮеӨҙжқҘеҶҚзңӢжөӢиҜ•йғЁеҜ№дәҺLoad Averageзҡ„иҰҒжұӮпјҢеңЁжҲ‘们жңәеҷЁдШ“8дё?/span>CPUзҡ„жғ…еҶөдёӢеQҢжҺ§еҲ¶еңЁ10 Loadе·ҰеҸіеQҢд№ҹһ®ұжҳҜжҜҸдёҖдё?/span>CPUжӯЈеңЁеӨ„зҗҶдёҖдёӘиҜ·жұӮпјҢеҗҢж—¶ҳqҳжңү2дёӘеңЁҪ{үеҫ…еӨ„зҗҶгҖӮзңӢдәҶзңӢҫ|‘дёҠеҫҲеӨҡдәәзҡ„д»Ӣз»ҚдёҖиҲ¬жқҘиҜ?/span>LoadҪҺҖеҚ•зҡ„и®Ўз®—һ®ұжҳҜ2* CPUдёӘж•°еҮҸеҺ»1-2е·ҰеҸіеQҲиҝҷдёӘеҸӘжҳҜзҪ‘дёҠзңӢжқҘзҡ„еQҢжңӘеҝ…жҳҜдёҖдёӘж ҮеҮҶпјүгҖ?/span>
иЎҘе……еҮ зӮ№еQ?/span>
1еQҺеҜ№дә?/span>CPUеҲ©з”ЁзҺҮе’ҢCPU Load Averageзҡ„з»“жһңжқҘеҲӨж–ӯжҖ§иғҪй—®йўҳгҖӮйҰ–е…ҲдҪҺCPUеҲ©з”ЁзҺҮдёҚиЎЁжҳҺCPUдёҚжҳҜз“үҷўҲеQҢз«һдә?/span>CPUзҡ„йҳҹеҲ—й•ҝжңҹдҝқжҢҒиҫғй•ҝд№ҹжҳ?/span>CPUӯ‘…иҙҹиҚпLҡ„дёҖҝUҚиЎЁзҺ°гҖӮеҜ№дәҺеә”з”ЁжқҘиҜҙеҸҜиғҪдјҡеҺ»иҠұж—үҷ—ҙең?/span>I/O,SocketҪ{үж–№йқўпјҢйӮЈд№ҲеҸҜд»ҘиҖғиҷ‘жҳҜеҗҰеҗҺиҝҷдәӣ硬件зҡ„йҖҹеәҰеҪұе“ҚдәҶж•ҙдҪ“зҡ„ж•ҲзҺҮгҖ?/span>
ҳqҷйҮҢжңҖеҘҪзҡ„ж дhқҝиҢғдҫӢһ®ұжҳҜжҲ‘еңЁӢ№ӢиҜ•дёӯеҸ‘зҺ°зҡ„дёҖдёӘзҺ°иұЎпјҡSIPеҪ“еүҚеңЁеӨ„зҗҶиҝҮҪEӢдёӯеQҢдШ“дәҶжҸҗй«ҳеӨ„зҗҶж•ҲзҺҮпјҢһ®ҶжҺ§еҲ¶зӯ–з•Ҙд»ҘеҸҠи®Ўж•оCҝЎжҒҜйғҪж”„ЎҪ®ең?/span>Memcached CacheйҮҢйқўеQҢеҪ“жҲ‘е°ҶMemcached Cacheй…ҚзҪ®жү©е®№дёҖеҖҚд»ҘеҗҺпјҢCPUзҡ„еҲ©з”ЁзҺҮд»ҘеҸҠLoadйғҪжңүжүҖдёӢйҷҚеQҢе…¶е®һд№ҹһ®ұжҳҜеңЁеӨ„зҗҶд“QеҠЎзҡ„ҳqҮзЁӢдёӯпјҢҪ{үеҫ…Socketзҡ„иҝ”еӣһеҜ№дә?/span>CPUзҡ„з«һдәүд№ҹдә§з”ҹдәҶеӘ„е“ҚгҖ?/span>
2еQҺжңӘжқҘеӨҡCPUҫ~–зЁӢзҡ„йҮҚиҰҒжҖ§гҖӮзҺ°еңЁжңҚеҠЎеҷЁзҡ?/span>CPUйғҪжҳҜеӨ?/span>CPUдәҶпјҢжҲ‘们зҡ„жңҚеҠЎеҷЁеӨ„зҗҶиғҪеҠӣе·Із»ҸдёҚеҶҚжҢүз…§ж‘©е°”е®ҡеҫӢжқҘеҸ‘еұ•гҖӮе°ұжҲ‘дёҠйқўжҸҗеҲ°зҡ„з”өиҜқдәӯеңәжҷҜжқҘзңӢпјҢеҜ№дәҺдёүз§ҚдёҚеҗҢж—үҷ—ҙйңҖжұӮзҡ„з”ЁжҲ·жқҘиҜҙеQҢйҮҮз”ЁдёҚеҗҢзҡ„еҲҶй…ҚҷеәеәҸеQҢжҲ‘们еҸҜзңӢеҲ°зҡ?/span>Load Averageһ®ЧғјҡжңүдёҚеҗҢгҖӮеҒҮи®ҫжҲ‘们з»ҹи®?/span>Loadзҡ„ж—¶й—ҙж®өдё?/span>2еҲҶй’ҹеQҢеҰӮжһңе°Ҷз”өиҜқеҲҶй…Қзҡ„йЎәеәҸжҢүз…§пјҡ1minзҡ„з”ЁжҲшPјҢ2minзҡ„з”ЁжҲшPјҢ3minзҡ„з”ЁжҲдhқҘеҲҶй…ҚеQҢйӮЈд№ҲжҲ‘们зҡ„Load Averageһ®ҶдјҡжңҖдҪҺпјҢйҮҮз”Ёе…¶д»–ҷеәеәҸһ®ҶдјҡжңүдёҚеҗҢзҡ„ҫl“жһңгҖӮжүҖд»ҘжңӘжқҘзҡ„еӨ?/span>CPUҫ~–зЁӢеҸҜд»ҘжӣҙеҘҪзҡ„жҸҗй«?/span>CPUзҡ„еҲ©з”ЁзҺҮеQҢи®©ҪEӢеәҸи·‘зҡ„жӣҙеҝ«гҖ?/span>
д»ҘдёҠжүҖжҸҗеҲ°зҡ„еҶ…е®ТҺңӘеҝ…йғҪжҳҜеҫҲеҮҶзЎ®жҲ–иҖ…жӯЈјӢ®пјҢеҰӮжһңжңүд“QдҪ•зҡ„еҒҸе·®д№ҹиҜ·еӨ§е®¶жҢҮеҮәеQҢеҸҜд»Ҙзә жӯЈдёҖдәӣдёҚжё…жҘҡзҡ„жҰӮеҝьcҖ?br />
еҺҹж–ҮиҪ¬иҮіж–ҮеҲқзҡ„blogjavaеQ?/span>http://www.aygfsteel.com/cenwenchu/archive/2008/06/30/211712.html
жҲ‘们зҹҘйҒ“еҲӨж–ӯдёҖдёӘзі»ҫlҹзҡ„иҙҹиқІеҸҜд»ҘдҪҝз”ЁtopеQҢuptimeҪ{үе‘Ҫд»ӨеҺ»жҹҘзңӢеQҢе®ғеҲҶеҲ«и®°еҪ•дәҶдёҖеҲҶй’ҹгҖҒдә”еҲҶй’ҹгҖҒд»ҘеҸҠеҚҒдә”еҲҶй’ҹзҡ„ҫpИқ»ҹтqӣ_қҮиҙҹиқІгҖ?nbsp;
гҖҖгҖҖдҪ еҸҜиғҪеҜ№дә?Linux зҡ„иҙҹиҪҪеқҮеҖ?load averages)е·ІжңүдәҶе……еҲҶзҡ„дәҶи§ЈгҖӮиҙҹиҪҪеқҮеҖјеңЁ uptime жҲ–иҖ?top е‘ҪдЧoдёӯеҸҜд»ҘзңӢеҲҺНјҢе®ғ们еҸҜиғҪдјҡжҳҫҪCәжҲҗҳqҷдёӘж ·еӯҗеQ?nbsp;
гҖҖгҖҖ
- load average: 0.09, 0.05, 0.01
гҖҖгҖҖеҫҲеӨҡдәЮZјҡҳqҷж ·зҗҶи§ЈиҙҹиқІеқҮеҖы|јҡдёүдёӘж•°еҲҶеҲ«д»ЈиЎЁдёҚеҗҢж—¶й—ҙж®өзҡ„зі»ҫlҹег^еқҮиҙҹиҪ?дёҖеҲҶй’ҹгҖҒдә” еҲҶй’ҹгҖҒд»ҘеҸҠеҚҒдә”еҲҶй’?еQҢе®ғ们зҡ„ж•°еӯ—еҪ“然жҳҜи¶Ҡһ®Ҹи¶ҠеҘҪгҖӮж•°еӯ—и¶Ҡй«ҳпјҢиҜҙжҳҺжңҚеҠЎеҷЁзҡ„иҙҹиқІӯ‘?еӨ§пјҢҳqҷд№ҹеҸҜиғҪжҳҜжңҚеҠЎеҷЁеҮәзҺ°жҹҗз§Қй—®йўҳзҡ„дҝЎеҸ—чҖ?nbsp;
гҖҖгҖҖиҖҢдәӢе®һдёҚе®Ңе…ЁеҰӮжӯӨеQҢжҳҜд»Җд№Ҳеӣ зҙ жһ„жҲҗдәҶиҙҹиқІеқҮеҖјзҡ„еӨ§е°ҸеQҢд»ҘеҸҠеҰӮдҪ•еҢәеҲҶе®ғ们зӣ®еүҚзҡ„зҠ¶еҶөжҳ?“еҘ?#8221;ҳqҳжҳҜ“ҫpҹзі•”?д»Җд№Ҳж—¶еҖҷеә”иҜҘжіЁж„Ҹе“ӘдәӣдёҚжӯЈеёёзҡ„ж•°еҖ?
еӣһзӯ”ҳqҷдәӣй—®йўҳд№ӢеүҚеQҢйҰ–е…ҲйңҖиҰҒдәҶи§ЈдёӢҳqҷдәӣж•°еҖЖDғҢеҗҺзҡ„дәӣзҹҘиҜҶгҖӮжҲ‘们е…Ҳз”ЁжңҖҪҺҖеҚ•зҡ„дҫӢеӯҗиҜҙжҳҺеQ?дёҖеҸ°еҸӘй…ҚеӨҮдёҖеқ—еҚ•ж ёеӨ„зҗҶеҷЁзҡ„жңҚеҠЎеҷЁгҖ?nbsp;
иЎҢиһRҳqҮжЎҘ
дёҖеҸӘеҚ•ж ёзҡ„еӨ„зҗҶеҷЁеҸҜд»ҘеЕһиұЎеҫ—жҜ”е–»жҲҗдёҖжқЎеҚ•иҪҰйҒ“гҖӮи®ҫжғідёӢеQҢдҪ зҺ°еңЁйңҖиҰҒ收еҸ–иҝҷжқЎйҒ“и·Ҝзҡ„ҳqҮжЎҘ иҙ?— еҝҷдәҺеӨ„зҗҶйӮЈдәӣһ®ҶиҰҒҳqҮжЎҘзҡ„иһRиҫҶгҖӮдҪ йҰ–е…ҲеҪ“然йңҖиҰҒдәҶи§ЈдәӣдҝЎжҒҜеQҢдҫӢеҰӮиһRиҫҶзҡ„иҪҪйҮҚгҖҒд»ҘеҸ?ҳqҳжңүеӨҡе°‘иҪҰиҫҶжӯЈеңЁҪ{үеҫ…ҳqҮжЎҘгҖӮеҰӮжһңеүҚйқўжІЎжңүиһRиҫҶеңЁҪ{үеҫ…еQҢйӮЈд№ҲдҪ еҸҜд»Ҙе‘ҠиҜүеҗҺйқўзҡ„еҸёжңәйҖҡиҝҮгҖ?еҰӮжһңиҪҰиҫҶдј—еӨҡеQҢйӮЈд№ҲйңҖиҰҒе‘ҠзҹҘ他们еҸҜиғҪйңҖиҰҒзЁҚҪ{үдёҖдјҡгҖ?nbsp;
гҖҖгҖҖеӣ жӯӨеQҢйңҖиҰҒдәӣзү№е®ҡзҡ„д»ЈеҸҜӮЎЁҪCәзӣ®еүҚзҡ„иҪҰжөҒжғ…еҶөеQҢдҫӢеҰӮпјҡ
гҖҖгҖҖ0.00 иЎЁзӨәзӣ®еүҚжЎҘйқўдёҠжІЎжңүд“QдҪ•зҡ„иҪҰжөҒгҖ?е®һйҷ…дёҠиҝҷҝUҚжғ…еҶөдёҺ 0.00 е’?1.00 д№Ӣй—ҙжҳҜзӣёеҗҢзҡ„еQҢжҖ»иҖҢиЁҖд№ӢеҫҲйҖҡз•…еQҢиҝҮеҫҖзҡ„иһRиҫҶеҸҜд»ҘдёқжҜ«дёҚз”Ёзӯүеҫ…зҡ„йҖҡиҝҮгҖ?nbsp;
гҖҖгҖҖ1.00 иЎЁзӨәеҲҡеҘҪжҳҜеңЁҳqҷес”жЎҘзҡ„жүҝеҸ—иҢғеӣҙеҶ…гҖ?ҳqҷз§Қжғ…еҶөдёҚз®—ҫpҹзі•еQҢеҸӘжҳҜиһRӢ№Ғдјҡжңүдәӣе өпјҢдёҚиҝҮҳqҷз§Қжғ…еҶөеҸҜиғҪдјҡйҖ жҲҗдәӨйҖҡи¶ҠжқҘи¶Ҡж…ўгҖ?nbsp;
гҖҖгҖҖӯ‘…иҝҮ 1.00еQҢйӮЈд№ҲиҜҙжҳҺиҝҷеә§жЎҘе·Із»Ҹӯ‘…еҮәиҙҹиҚ·еQҢдәӨйҖҡдёҘйҮҚзҡ„жӢҘе өгҖ?йӮЈд№Ҳжғ…еҶөжңүеӨҡҫpҹзі•? дҫӢеҰӮ 2.00 зҡ„жғ…еҶөиҜҙжҳҺиһRӢ№Ғе·ІҫlҸи¶…еҮЮZәҶжЎҘжүҖиғҪжүҝеҸ—зҡ„дёҖеҖҚпјҢйӮЈд№Ҳһ®ҶжңүеӨҡдҪҷҳqҮжЎҘдёҖеҖҚзҡ„иҪҰиҫҶжӯЈеңЁз„ҰжҖҘзҡ„Ҫ{үеҫ…гҖ?.00 зҡ„иҜқжғ…еҶөһ®ұжӣҙдёҚеҰҷдәҶпјҢиҜҙжҳҺҳqҷес”жЎҘеҹәжң¬дёҠе·Із»Ҹеҝ«жүҝеҸ—дёҚдәҶпјҢҳqҳжңүӯ‘…еҮәжЎҘиҙҹиҪҪдёӨеҖҚеӨҡзҡ„иһRиҫҶжӯЈеңЁзӯүеҫ…гҖ?nbsp;
гҖҖгҖҖдёҠйқўзҡ„жғ…еҶөе’ҢеӨ„зҗҶеҷЁзҡ„иҙҹиқІжғ…еҶөйқһеёёзӣжҖјјгҖӮдёҖиҫҶжұҪиҪҰзҡ„ҳqҮжЎҘж—үҷ—ҙһ®ұеҘҪжҜ”жҳҜеӨ„зҗҶеҷЁеӨ„зҗҶжҹҗҫUҝзЁӢ зҡ„е®һйҷ…ж—¶й—ҙгҖӮUnix ҫpИқ»ҹе®ҡд№үзҡ„иҝӣҪEӢиҝҗиЎҢж—¶й•ҝдШ“жүҖжңүеӨ„зҗҶеҷЁеҶ…ж ёзҡ„еӨ„зҗҶж—¶й—ҙеҠ дёҠзәҝҪE?еңЁйҳҹеҲ—дёӯҪ{үеҫ…зҡ„ж—¶й—ҙгҖ?nbsp;
гҖҖгҖҖе’Ң收ҳqҮжЎҘиҙ№зҡ„ҪҺЎзҗҶе‘ҳдёҖж шPјҢдҪ еҪ“然еёҢжңӣдҪ зҡ„жұҪиҪ?ж“ҚдҪң)дёҚдјҡиў«з„ҰжҖҘзҡ„Ҫ{үеҫ…гҖӮжүҖд»ҘпјҢзҗҶжғізҠ¶жҖ?дёӢпјҢйғҪеёҢжңӣиҙҹиҪҪег^еқҮеҖје°Ҹдә?1.00 гҖӮеҪ“然дёҚжҺ’йҷӨйғЁеҲҶеі°еҖйgјҡӯ‘…иҝҮ 1.00еQҢдҪҶй•ҝжӯӨд»ҘеҫҖдҝқжҢҒҳq?дёӘзҠ¶жҖҒпјҢһ®ЮpҜҙжҳҺдјҡжңүй—®йўҳпјҢҳqҷж—¶еҖҷдҪ еә”иҜҘдјҡеҫҲз„ҰжҖҘгҖ?nbsp;
гҖҖ“жүҖд»ҘдҪ иҜҙзҡ„зҗҶжғіиҙҹиҚ·дё?1.00 ?”
гҖҖгҖҖе—ҜпјҢҳqҷз§Қжғ…еҶөе…¶е®һтq¶дёҚе®Ңе…ЁжӯЈзЎ®гҖӮиҙҹиҚ?1.00 иҜҙжҳҺҫpИқ»ҹе·Із»ҸжІЎжңүеү©дҪҷзҡ„иө„жәҗдәҶгҖӮеңЁе®һйҷ…жғ…еҶөдё?еQҢжңүҫlҸйӘҢзҡ„зі»ҫlҹз®ЎзҗҶе‘ҳйғҪдјҡһ®ҶиҝҷжқЎзәҝеҲ’еңЁ 0.70еQ?nbsp;
гҖҖгҖҖ“йңҖиҰҒиҝӣиЎҢи°ғжҹҘжі•еҲ?#8221;еQ?еҰӮжһңй•ҝжңҹдҪ зҡ„ҫpИқ»ҹиҙҹиқІең?0.70 дёҠдёӢеQҢйӮЈд№ҲдҪ йңҖиҰҒеңЁдәӢжғ…еҸҳеҫ—жӣҙзіҹҫp•д№ӢеүҚпјҢиҠЧғәӣж—үҷ—ҙдәҶи§Је…¶еҺҹеӣ гҖ?nbsp;
гҖҖгҖҖ“зҺ°еңЁһ®ЮpҰҒдҝ®еӨҚжі•еҲҷ”еQ?.00 гҖ?еҰӮжһңдҪ зҡ„жңҚеҠЎеҷЁзі»ҫlҹиҙҹиҪҪй•ҝжңҹеҫҳеҫҠдәҺ 1.00еQҢйӮЈд№Ҳе°ұеә”иҜҘ马дёҠи§ЈеҶіҳqҷдёӘй—®йўҳгҖӮеҗҰеҲҷпјҢдҪ е°ҶеҚҠеӨңжҺҘеҲ°дҪ дёҠеҸёзҡ„з”өиҜқеQҢиҝҷеҸҜдёҚжҳҜдҡgд»Өдқhж„үеҝ«зҡ„дәӢжғ…гҖ?nbsp;
гҖҖгҖҖ“еҮҢжҷЁдёүзӮ№еҚҠй”»зӮЖDнnдҪ“жі•еҲ?#8221;еQ?.00гҖ?еҰӮжһңдҪ зҡ„жңҚеҠЎеҷЁиҙҹиҪҪи¶…ҳqҮдәҶ 5.00 ҳqҷдёӘж•°еӯ—еQҢйӮЈд№ҲдҪ һ®ҶеӨұеҺЦMҪ зҡ„зқЎзң пјҢҳqҳеҫ—еңЁдјҡи®®дёӯиҜҙжҳҺҳqҷжғ…еҶөеҸ‘з”ҹзҡ„еҺҹеӣ еQҢжҖЦM№ӢеҚғдёҮдёҚиҰҒи®©е®ғеҸ‘з”ҹгҖ?nbsp;
гҖҖгҖҖйӮЈд№ҲеӨҡдёӘеӨ„зҗҶеҷЁе‘ў?жҲ‘зҡ„еқҮеҖјжҳҜ 3.00еQҢдҪҶжҳҜзі»ҫlҹиҝҗиЎҢжӯЈеё?
гҖҖгҖҖе“Үе–”еQҢдҪ жңүеӣӣдёӘеӨ„зҗҶеҷЁзҡ„дё»жң?йӮЈд№Ҳе®ғзҡ„иҙҹиқІеқҮеҖјеңЁ 3.00 жҳҜеҫҲжӯЈеёёзҡ„гҖ?nbsp;
гҖҖгҖҖеңЁеӨҡеӨ„зҗҶеҷЁзі»ҫlҹдёӯеQҢиҙҹиҪҪеқҮеҖјжҳҜеҹЮZәҺеҶ…ж ёзҡ„ж•°йҮҸеҶіе®ҡзҡ„гҖӮд»Ҙ 100% иҙҹиқІи®Ўз®—еQ?.00 иЎЁзӨәеҚ•дёӘеӨ„зҗҶеҷЁпјҢиҖ?2.00 еҲҷиҜҙжҳҺжңүдёӨдёӘеҸҢеӨ„зҗҶеҷЁеQҢйӮЈд№?4.00 һ®ЮpҜҙжҳҺдё»жңәе…·жңүеӣӣдёӘеӨ„зҗҶеҷЁгҖ?nbsp;
гҖҖгҖҖеӣһеҲ°жҲ‘们дёҠйқўжңүе…іиҪҰиҫҶҳqҮжЎҘзҡ„жҜ”е–…RҖ?.00 жҲ‘иҜҙҳqҮжҳҜ“дёҖжқЎеҚ•иҪҰйҒ“зҡ„йҒ“и·?#8221;гҖӮйӮЈд№ҲеңЁеҚ•иһRйҒ?1.00 жғ…еҶөдёӯпјҢиҜҙжҳҺҳqҷжЎҘжўҒе·ІҫlҸиў«иҪҰеЎһж»ЎдәҶгҖӮиҖҢеңЁеҸҢеӨ„зҗҶеҷЁҫpИқ»ҹдёӯпјҢҳqҷж„Ҹе‘ізқҖеӨҡеҮәдәҶдёҖеҖҚзҡ„ иҙҹиқІеQҢд№ҹһ®ұжҳҜиҜҙиҝҳжң?50% зҡ„еү©дҪҷзі»ҫlҹиө„жә?— еӣ дШ“ҳqҳжңүеҸҰеӨ–жқЎиһRйҒ“еҸҜд»ҘйҖҡиЎҢгҖ?nbsp;
гҖҖгҖҖжүҖд»ҘпјҢеҚ•еӨ„зҗҶеҷЁе·Із»ҸеңЁиҙҹиҪҪзҡ„жғ…еҶөдёӢпјҢеҸҢеӨ„зҗҶеҷЁзҡ„иҙҹиҪҪж»Ўйўқзҡ„жғ…еҶөжҳ?2.00еQҢе®ғҳqҳжңүдёҖеҖҚзҡ„иө„жәҗеҸҜд»ҘеҲ©з”ЁгҖ?nbsp;
еӨҡж ёдёҺеӨҡеӨ„зҗҶеҷ?/strong>
е…Ҳи„ұјӣЦMёӢдё»йўҳеQҢжҲ‘们жқҘи®Ёи®әдёӢеӨҡж ёеҝғеӨ„зҗҶеҷЁдёҺеӨҡеӨ„зҗҶеҷЁзҡ„еҢәеҲ«гҖӮд»ҺжҖ§иғҪзҡ„и§’еәҰдёҠзҗҶи§ЈеQҢдёҖеҸоCё» жңәжӢҘжңүеӨҡж ёеҝғзҡ„еӨ„зҗҶеҷЁдёҺеҸҰеҸ°жӢҘжңүеҗҢж дh•°зӣ®зҡ„еӨ„зҗҶжҖ§иғҪеҹәжң¬дёҠеҸҜд»Ҙи®ӨдёәжҳҜзӣёе·®ж— еҮ гҖӮеҪ“然е®һйҷ?жғ…еҶөдјҡеӨҚжқӮеҫ—еӨҡпјҢдёҚеҗҢж•°йҮҸзҡ„зј“еӯҳгҖҒеӨ„зҗҶеҷЁзҡ„йў‘зҺҮзӯүеӣ зҙ йғҪеҸҜиғҪйҖ жҲҗжҖ§иғҪзҡ„е·®ејӮгҖ?nbsp;
гҖҖгҖҖдҪҶеҚідҫҝиҝҷдәӣеӣ зҙ йҖ жҲҗзҡ„е®һйҷ…жҖ§иғҪҪEҚжңүдёҚеҗҢеQҢе…¶е®һзі»ҫlҹиҝҳжҳҜд»ҘеӨ„зҗҶеҷЁзҡ„ж ёеҝғж•°йҮҸи®Ўз®—иҙҹиқІеқҮеҖ?гҖӮиҝҷдҪҝжҲ‘们жңүдәҶдёӨдёӘж–°зҡ„жі•еҲҷпјҡ
гҖҖгҖҖ“жңүеӨҡһ®‘ж ёеҝғеҚідёәжңүеӨҡе°‘иҙҹиҚ·”жі•еҲҷеQ?еңЁеӨҡж ёеӨ„зҗҶдёӯеQҢдҪ зҡ„зі»ҫlҹеқҮеҖйgёҚеә”иҜҘй«ҳдәҺеӨ„зҗҶеҷЁж ёеҝғзҡ„жҖАL•°йҮҸгҖ?nbsp;
“ж ёеҝғзҡ„ж ёеҝ?#8221;жі•еҲҷеQ?ж ёеҝғеҲҶеёғеңЁеҲҶеҲ«еҮ дёӘеҚ•дёӘзү©зҗҶеӨ„зҗҶдёӯтq¶дёҚйҮҚиҰҒеQҢе…¶е®һдёӨйў—еӣӣж ёзҡ„еӨ„зҗҶеҷ?Ҫ{үдәҺ еӣӣдёӘеҸҢж ёеӨ„зҗҶеҷ?Ҫ{үдәҺ е…«дёӘеҚ•еӨ„зҗҶеҷЁгҖӮжүҖд»ҘпјҢе®ғеә”иҜҘжңүе…«дёӘеӨ„зҗҶеҷЁеҶ…ж ёгҖ?nbsp;
гҖҖгҖҖе®Ўи§ҶжҲ‘们иҮӘе·ұ
гҖҖгҖҖи®©жҲ‘们еҶҚжқҘзңӢзң?uptime зҡ„иҫ“еҮ?nbsp;
гҖҖгҖҖ
- ~ $ uptime
- гҖҖгҖҖ23:05 up 14 days, 6:08, 7 users, load averages: 0.65 0.42 0.36
гҖҖгҖҖҳqҷжҳҜдёӘеҸҢж ёеӨ„зҗҶеҷЁеQҢд»Һҫl“жһңд№ҹиҜҙжҳҺжңүеҫҲеӨҡзҡ„з©әй—Іиө„жәҗгҖӮе®һйҷ…жғ…еҶү|ҳҜеҚідҫҝе®ғзҡ„еі°еҖйgјҡеҲ?1.7еQҢжҲ‘д№ҹд»ҺжқҘжІЎжңүиҖғиҷ‘ҳqҮе®ғзҡ„иҙҹиҪҪй—®йўҳгҖ?nbsp;
гҖҖгҖҖйӮЈд№ҲеQҢжҖҺд№ҲдјҡжңүдёүдёӘж•°еӯ—зҡ„зЎ®и®©дқhеӣ°жү°гҖӮжҲ‘们зҹҘйҒ“пјҢ0.65гҖ?.42гҖ?.36 еҲҶеҲ«иҜҙжҳҺдёҠдёҖеҲҶй’ҹгҖҒжңҖеҗҺдә”еҲҶй’ҹд»ҘеҸҠжңҖеҗҺеҚҒдә”еҲҶй’ҹзҡ„ҫpИқ»ҹиҙҹиқІеқҮеҖ№{ҖӮйӮЈд№ҲиҝҷеҸҲеёҰжқҘдәҶдёҖдёӘй—®йўҳпјҡ
гҖҖгҖҖжҲ‘们д»Ҙе“ӘдёӘж•°еӯ—дШ“еҮ?дёҖеҲҶй’ҹ?дә”еҲҶй’?ҳqҳжҳҜеҚҒдә”еҲҶй’ҹ?
гҖҖгҖҖе…¶е®һеҜ№дәҺҳqҷдәӣж•°еӯ—жҲ‘们已з»Ҹи°Ҳи®әдәҶеҫҲеӨҡпјҢжҲ‘и®ӨдёЮZҪ еә”иҜҘзқҖзңйgәҺдә”еҲҶй’ҹжҲ–иҖ…еҚҒдә”еҲҶй’ҹзҡ„тqӣ_қҮж•?еҖ№{ҖӮеқҰзҷҪи®ІеQҢеҰӮжһңеүҚдёҖеҲҶй’ҹзҡ„иҙҹиҪҪжғ…еҶү|ҳҜ 1.00еQҢйӮЈд№Ҳд»ҚеҸҜд»ҘиҜҙжҳҺи®Өе®ҡжңҚеҠЎеҷЁжғ…еҶөиҝҳжҳҜжӯЈеёёзҡ„гҖ?дҪҶжҳҜеҰӮжһңеҚҒдә”еҲҶй’ҹзҡ„ж•°еҖйg»Қ然дҝқжҢҒеңЁ 1.00еQҢйӮЈд№Ҳе°ұеҖјеҫ—жіЁж„Ҹдә?/span>(ж ТҺҚ®жҲ‘зҡ„ҫlҸйӘҢеQҢиҝҷж—¶еҖҷдҪ еә”иҜҘеўһеҠ еӨ„зҗҶеҷЁзҡ„ж•°йҮҸдә?гҖ?/span>
гҖҖгҖҖйӮЈд№ҲжҲ‘еҰӮдҪ•еҫ—зҹҘжҲ‘зҡ„зі»ҫlҹиЈ…еӨҮдәҶеӨҡе°‘ж ёеҝғзҡ„еӨ„зҗҶеҷЁ?
гҖҖгҖҖең?Linux дёӢпјҢеҸҜд»ҘдҪҝз”Ё
гҖҖгҖҖ
- cat /proc/cpuinfo
гҖҖгҖҖиҺ·еҸ–дҪ зі»ҫlҹдёҠзҡ„жҜҸдёӘеӨ„зҗҶеҷЁзҡ„дҝЎжҒҜгҖӮеҰӮжһңдҪ еҸӘжғіеҫ—еҲ°ж•°еӯ—еQҢйӮЈд№Ҳе°ұдҪҝз”ЁдёӢйқўзҡ„е‘Ҫд»Өпјҡ
гҖҖгҖҖ
- grep 'model name' /proc/cpuinfo | wc -l
mkdir -p /usr/src/tools
е®үиЈ…tomcat&resin
vi catalina.sh
дҝ®ж”№IPең°еқҖ
NETMASK=255.255.255.0
BROADCAST=192.168.80.255
GATEWAY=192.168.80.2
STARTMODE=onboot
BOOTPROTO=dhcp
USERCONTROL=no
FIREWALL=no
tar -zxvf sysbench-0.4.12.tar.gz