掃描與查找操作均是SQL Server從表或索引中讀取數據采用的迭代器,這些也是SQL Server支持的最基本的運算.幾乎在每一個查詢計劃中都可以找到,因此理解它們的不同是很重要的,掃描是在整張表上進行處理,而索引是在整個頁級上進行處理,而查找則返回特定謂詞上一個或多個范圍內的數據行.
下面讓我們看一個掃描的例子(這里使用Northwind數據庫)
SELECT [OrderId] FROM [Orders] WHERE [RequiredDate] = '1998-03-26'
在Orders表中,并不存在對RequiredDate列的索引,因此,SQL Server必須讀取Orders表的每一行來估計每一行的RequiredDate謂詞,如果滿足該謂詞條件(即找到包含’1998-03-26’的記錄),則返回該行數據.
為了最大化提升性能,SQL Server盡可能地使用掃描迭代器來估計該謂詞,然而,如果該謂詞過于復雜或開銷過大,SQL Server或許使用別的篩選迭代器來估計.以下是WHERE關鍵字中的文本計劃的過程:
|--Clustered Index Scan(OBJECT:([Orders].[PK_Orders]),
WHERE:([Orders].[RequiredDate]='1998-03-26'))
下圖描述了該操作的流程圖:
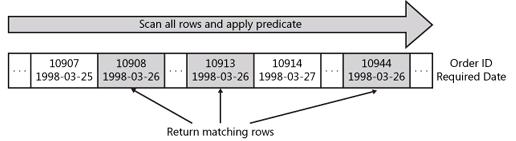
由于掃描表的每一行數據,不論滿足與否,因此,其查詢開銷對表中的總記錄數是均衡的
,當表中的數據很少或滿足謂詞的行比較多時,采用掃描操作有效,如果表中
數據量比較大或滿足謂詞的行較少時,使用掃描將讀取更多的頁面或執行更多的I/O操作來獲取數據,這顯而不是最有效的方法.
下面讓我們看一個關于索引查找的例子,下面的例子在OrderdDate列上創建了索引:
SELECT [OrderId] FROM [Orders] WHERE [OrderDate] = '1998-02-26'
這次SQL Server能夠使用索引查找來直接找到滿足謂詞的那些記錄行,這里稱該謂詞為"查找"謂詞.大多數情況下,SQL Server并不顯式地估計"查找"謂詞,而索引確保了"查找"操作僅返回滿足的數據行,以下是"查找"謂詞的文本計劃:
|--Index Seek(OBJECT:([Orders].[OrderDate]),
SEEK:([Orders].[OrderDate]=CONVERT_IMPLICIT(datetime,[@1],0)) ORDERED FORWARD)
注意:SQL Server自動使用@1參數替換查詢文本中的參數
由此看來,
查找僅掃描滿足該謂詞的數據頁,其查詢開銷顯然要比表中總記錄數的開銷低,因此,
對于高選擇度的查詢謂詞操作,查找通常是最有效的策略.也就是說,對于估計大表中的數據時,使用查找謂詞是比較有效率的.
SQL Server將掃描與查找進行區分,如同將在堆(無聚集索引的對象)上掃描,聚集索引上的掃描,非聚集索引上的掃描進行分區.下表說明了這些出現在的查詢計劃中的掃描與查找運算.
|
|
掃描
|
查找
|
|
堆
|
表掃描
|
|
|
聚集索引
|
聚集索引找描
|
聚集索引查找
|
|
非聚集索引
|
索引掃描
|
索引查找
|
可查找的謂詞與覆蓋列
SQL Server在執行索引查找之前,它需要確定索引的鍵是否滿足查詢中的謂詞,我們稱該謂詞為"可查找的謂詞",SQL Server必須確定該索引是否包含或"覆蓋"查詢中引用的列集合.下面描述了如何確定哪個謂詞是可查找的,哪個謂詞不是可查找的,哪些列需要索引覆蓋.
單列索引
在單列索引上判斷謂詞是否是可查找的是很容易的,SQL Server使用單列索引來響應多數簡單的比較(包括相等和不等(大于,小于等))或者更復雜的表達式,如在列上運算的函數和LIKE %謂詞,這些運算符將阻止SQL Server使用索引查找.
例如,假設我們在Col1列上創建了單列索引,可以在以下謂詞上進行索引查找:
Ø [Col1] = 3.14
Ø [Col1] > 100
Ø [Col1] BETWEEN 0 AND 99
Ø [Col1] LIKE 'abc%'
Ø [Col1] IN (2, 3, 5, 7)
然頁,在以下謂詞上將不能使用索引查找:
Ø ABS([Col1]) = 1
Ø [Col1] + 1 = 9
Ø [Col1] LIKE '%abc'
下面我通過一些例子來介紹單列索引:
首先創建一些架構對象:
create table person
(id int, last_name varchar(30), first_name varchar(30))
create unique clustered index person_id
on person (id)
create index person_name
on person (last_name, first_name)
以下是三個查詢及其各自的文本查詢計劃,第一個查詢在person_name索引上進行查找,第二個查詢
首先在第一個鍵列上進行索引查找,然后使用residual謂詞來估計first_name,第三個查詢不能使用索引查找,而是使用了索引掃描來處理residual謂詞.
select id from person where last_name = 'Doe' and first_name = 'John'
|--Index Seek(OBJECT:([person].[person_name]), SEEK:([person].[last_name]='Doe'
AND [person].[first_name]='John'))
select id from person where
last_name > 'Doe' and first_name = 'John'
|--Index Seek(OBJECT:([person].[person_name]), SEEK:([person].[last_name] > 'Doe'),
WHERE:([person].[first_name]='John'))
select id from person where last_name like '%oe' and first_name = 'John'
|--Index
Scan(OBJECT:([person].[person_name]),
WHERE:([person].[first_name]='John'
AND [person].[last_name] like '%oe'))
上面三條查詢的圖形查詢計劃:
