北北 發(fā)表于 2006-8-21 20:46:15
前言:
半年前我對(duì)正則表達(dá)式產(chǎn)生了興趣,在網(wǎng)上查找過(guò)不少資料,看過(guò)不少的教程,最后在使用一個(gè)正則表達(dá)式工具RegexBuddy時(shí)發(fā)現(xiàn)他的教程寫(xiě)的非常好,可以說(shuō)是我目前見(jiàn)過(guò)最好的正則表達(dá)式教程。于是一直想把他翻譯過(guò)來(lái)。這個(gè)愿望直到這個(gè)五一長(zhǎng)假才得以實(shí)現(xiàn),結(jié)果就有了這篇文章。關(guān)于本文的名字,使用“深入淺出”似乎已經(jīng)太俗。但是通讀原文以后,覺(jué)得只有用“深入淺出”才能準(zhǔn)確的表達(dá)出該教程給我的感受,所以也就不能免俗了。
本文是Jan Goyvaerts為RegexBuddy寫(xiě)的教程的譯文,版權(quán)歸原作者所有,歡迎轉(zhuǎn)載。但是為了尊重原作者和譯者的勞動(dòng),請(qǐng)注明出處!謝謝!
?1.什么是正則表達(dá)式
基本說(shuō)來(lái),正則表達(dá)式是一種用來(lái)描述一定數(shù)量文本的模式。Regex代表Regular Express。本文將用<<regex>>來(lái)表示一段具體的正則表達(dá)式。
一段文本就是最基本的模式,簡(jiǎn)單的匹配相同的文本。
?2.不同的正則表達(dá)式引擎
正則表達(dá)式引擎是一種可以處理正則表達(dá)式的軟件。通常,引擎是更大的應(yīng)用程序的一部分。在軟件世界,不同的正則表達(dá)式并不互相兼容。本教程會(huì)集中討論P(yáng)erl 5 類型的引擎,因?yàn)檫@種引擎是應(yīng)用最廣泛的引擎。同時(shí)我們也會(huì)提到一些和其他引擎的區(qū)別。許多近代的引擎都很類似,但不完全一樣。例如.NET正則庫(kù),JDK正則包。
?3.文字符號(hào)
最基本的正則表達(dá)式由單個(gè)文字符號(hào)組成。如<<a>>,它將匹配字符串中第一次出現(xiàn)的字符“a”。如對(duì)字符串“Jack is a boy”。“J”后的“a”將被匹配。而第二個(gè)“a”將不會(huì)被匹配。
正則表達(dá)式也可以匹配第二個(gè)“a”,這必須是你告訴正則表達(dá)式引擎從第一次匹配的地方開(kāi)始搜索。在文本編輯器中,你可以使用“查找下一個(gè)”。在編程語(yǔ)言中,會(huì)有一個(gè)函數(shù)可以使你從前一次匹配的位置開(kāi)始繼續(xù)向后搜索。
類似的,<<cat>>會(huì)匹配“About cats and dogs”中的“cat”。這等于是告訴正則表達(dá)式引擎,找到一個(gè)<<c>>,緊跟一個(gè)<<a>>,再跟一個(gè)<<t>>。
要注意,正則表達(dá)式引擎缺省是大小寫(xiě)敏感的。除非你告訴引擎忽略大小寫(xiě),否則<<cat>>不會(huì)匹配“Cat”。
?· 特殊字符
對(duì)于文字字符,有11個(gè)字符被保留作特殊用途。他們是:
[ ] \ ^ $ . | ? * + ( )
這些特殊字符也被稱作元字符。
如果你想在正則表達(dá)式中將這些字符用作文本字符,你需要用反斜杠“\”對(duì)其進(jìn)行換碼 (escape)。例如你想匹配“1+1=2”,正確的表達(dá)式為<<1\+1=2>>.
需要注意的是,<<1+1=2>>也是有效的正則表達(dá)式。但它不會(huì)匹配“1+1=2”,而會(huì)匹配“123+111=234”中的“111=2”。因?yàn)椤?”在這里表示特殊含義(重復(fù)1次到多次)。
在編程語(yǔ)言中,要注意,一些特殊的字符會(huì)先被編譯器處理,然后再傳遞給正則引擎。因此正則表達(dá)式<<1\+2=2>>在C++中要寫(xiě)成“1\\+1=2”。為了匹配“C:\temp”,你要用正則表達(dá)式<<C:\\temp>>。而在C++中,正則表達(dá)式則變成了“C:\\\\temp”。
?·不可顯示字符
可以使用特殊字符序列來(lái)代表某些不可顯示字符:
<<\t>>代表Tab(0x09)
<<\r>>代表回車符(0x0D)
<<\n>>代表?yè)Q行符(0x0A)
要注意的是Windows中文本文件使用“\r\n”來(lái)結(jié)束一行而Unix使用“\n”。
?4.正則表達(dá)式引擎的內(nèi)部工作機(jī)制
知道正則表達(dá)式引擎是如何工作的有助于你很快理解為何某個(gè)正則表達(dá)式不像你期望的那樣工作。
有兩種類型的引擎:文本導(dǎo)向(text-directed)的引擎和正則導(dǎo)向(regex-directed)的引擎。Jeffrey Friedl把他們稱作DFA和NFA引擎。本文談到的是正則導(dǎo)向的引擎。這是因?yàn)橐恍┓浅S杏玫奶匦裕纭岸栊浴绷吭~(lazy quantifiers)和反向引用(backreferences),只能在正則導(dǎo)向的引擎中實(shí)現(xiàn)。所以毫不意外這種引擎是目前最流行的引擎。
你可以輕易分辨出所使用的引擎是文本導(dǎo)向還是正則導(dǎo)向。如果反向引用或“惰性”量詞被實(shí)現(xiàn),則可以肯定你使用的引擎是正則導(dǎo)向的。你可以作如下測(cè)試:將正則表達(dá)式<<regex|regex not>>應(yīng)用到字符串“regex not”。如果匹配的結(jié)果是regex,則引擎是正則導(dǎo)向的。如果結(jié)果是regex not,則是文本導(dǎo)向的。因?yàn)檎齽t導(dǎo)向的引擎是“猴急”的,它會(huì)很急切的進(jìn)行表功,報(bào)告它找到的第一個(gè)匹配 。
?·正則導(dǎo)向的引擎總是返回最左邊的匹配
這是需要你理解的很重要的一點(diǎn):即使以后有可能發(fā)現(xiàn)一個(gè)“更好”的匹配,正則導(dǎo)向的引擎也總是返回最左邊的匹配。
當(dāng)把<<cat>>應(yīng)用到“He captured a catfish for his cat”,引擎先比較<<c>>和“H”,結(jié)果失敗了。于是引擎再比較<<c>>和“e”,也失敗了。直到第四個(gè)字符,<<c>>匹配了“c”。<<a>>匹配了第五個(gè)字符。到第六個(gè)字符<<t>>沒(méi)能匹配“p”,也失敗了。引擎再繼續(xù)從第五個(gè)字符重新檢查匹配性。直到第十五個(gè)字符開(kāi)始,<<cat>>匹配上了“catfish”中的“cat”,正則表達(dá)式引擎急切的返回第一個(gè)匹配的結(jié)果,而不會(huì)再繼續(xù)查找是否有其他更好的匹配。
?5.字符集
字符集是由一對(duì)方括號(hào)“[]”括起來(lái)的字符集合。使用字符集,你可以告訴正則表達(dá)式引擎僅僅匹配多個(gè)字符中的一個(gè)。如果你想匹配一個(gè)“a”或一個(gè)“e”,使用<<[ae]>>。你可以使用<<gr[ae]y>>匹配gray或grey。這在你不確定你要搜索的字符是采用美國(guó)英語(yǔ)還是英國(guó)英語(yǔ)時(shí)特別有用。相反,<<gr[ae]y>>將不會(huì)匹配graay或graey。字符集中的字符順序并沒(méi)有什么關(guān)系,結(jié)果都是相同的。
你可以使用連字符“-”定義一個(gè)字符范圍作為字符集。<<[0-9]>>匹配0到9之間的單個(gè)數(shù)字。你可以使用不止一個(gè)范圍。<<[0-9a-fA-F] >>匹配單個(gè)的十六進(jìn)制數(shù)字,并且大小寫(xiě)不敏感。你也可以結(jié)合范圍定義與單個(gè)字符定義。<<[0-9a-fxA-FX]>>匹配一個(gè)十六進(jìn)制數(shù)字或字母X。再次強(qiáng)調(diào)一下,字符和范圍定義的先后順序?qū)Y(jié)果沒(méi)有影響。
?·字符集的一些應(yīng)用
查找一個(gè)可能有拼寫(xiě)錯(cuò)誤的單詞,比如<<sep[ae]r[ae]te>> 或 <<li[cs]en[cs]e>>。
查找程序語(yǔ)言的標(biāo)識(shí)符,<<A-Za-z_][A-Za-z_0-9]*>>。(*表示重復(fù)0或多次)
查找C風(fēng)格的十六進(jìn)制數(shù)<<0[xX][A-Fa-f0-9]+>>。(+表示重復(fù)一次或多次)
?·取反字符集
在左方括號(hào)“[”后面緊跟一個(gè)尖括號(hào)“^”,將會(huì)對(duì)字符集取反。結(jié)果是字符集將匹配任何不在方括號(hào)中的字符。不像“.”,取反字符集是可以匹配回車換行符的。
需要記住的很重要的一點(diǎn)是,取反字符集必須要匹配一個(gè)字符。<<q[^u]>>并不意味著:匹配一個(gè)q,后面沒(méi)有u跟著。它意味著:匹配一個(gè)q,后面跟著一個(gè)不是u的字符。所以它不會(huì)匹配“Iraq”中的q,而會(huì)匹配“Iraq is a country”中的q和一個(gè)空格符。事實(shí)上,空格符是匹配中的一部分,因?yàn)樗且粋€(gè)“不是u的字符”。
如果你只想匹配一個(gè)q,條件是q后面有一個(gè)不是u的字符,我們可以用后面將講到的向前查看來(lái)解決。
?·字符集中的元字符
需要注意的是,在字符集中只有4個(gè) 字符具有特殊含義。它們是:“] \ ^ -”。“]”代表字符集定義的結(jié)束;“\”代表轉(zhuǎn)義;“^”代表取反;“-”代表范圍定義。其他常見(jiàn)的元字符在字符集定義內(nèi)部都是正常字符,不需要轉(zhuǎn)義。例如,要搜索星號(hào)*或加號(hào)+,你可以用<<[+*]>>。當(dāng)然,如果你對(duì)那些通常的元字符進(jìn)行轉(zhuǎn)義,你的正則表達(dá)式一樣會(huì)工作得很好,但是這會(huì)降低可讀性。
在字符集定義中為了將反斜杠“\”作為一個(gè)文字字符而非特殊含義的字符,你需要用另一個(gè)反斜杠對(duì)它進(jìn)行轉(zhuǎn)義。<<[\\x]>>將會(huì)匹配一個(gè)反斜杠和一個(gè)X。“]^-”都可以用反斜杠進(jìn)行轉(zhuǎn)義,或者將他們放在一個(gè)不可能使用到他們特殊含義的位置。我們推薦后者,因?yàn)檫@樣可以增加可讀性。比如對(duì)于字符“^”,將它放在除了左括號(hào)“[”后面的位置,使用的都是文字字符含義而非取反含義。如<<[x^]>>會(huì)匹配一個(gè)x或^。<<[]x]>>會(huì)匹配一個(gè)“]”或“x”。<<[-x]>>或<<[x-]>>都會(huì)匹配一個(gè)“-”或“x”。
?·字符集的簡(jiǎn)寫(xiě)
因?yàn)橐恍┳址浅3S茫杂幸恍┖?jiǎn)寫(xiě)方式。
<<\d>>代表<<[0-9]>>;
<<\w>>代表單詞字符。這個(gè)是隨正則表達(dá)式實(shí)現(xiàn)的不同而有些差異。絕大多數(shù)的正則表達(dá)式實(shí)現(xiàn)的單詞字符集都包含了<<A-Za-z0-9_]>>。
<<\s>>代表“白字符”。這個(gè)也是和不同的實(shí)現(xiàn)有關(guān)的。在絕大多數(shù)的實(shí)現(xiàn)中,都包含了空格符和Tab符,以及回車換行符<<\r\n>>。
字符集的縮寫(xiě)形式可以用在方括號(hào)之內(nèi)或之外。<<\s\d>>匹配一個(gè)白字符后面緊跟一個(gè)數(shù)字。<<[\s\d]>>匹配單個(gè)白字符或數(shù)字。<<[\da-fA-F]>>將匹配一個(gè)十六進(jìn)制數(shù)字。
取反字符集的簡(jiǎn)寫(xiě)
<<[\S]>> = <<[^\s]>>
<<[\W]>> = <<[^\w]>>
<<[\D]>> = <<[^\d]>>
·字符集的重復(fù)
如果你用“?*+”操作符來(lái)重復(fù)一個(gè)字符集,你將會(huì)重復(fù)整個(gè)字符集。而不僅是它匹配的那個(gè)字符。正則表達(dá)式<<[0-9]+>>會(huì)匹配837以及222。
如果你僅僅想重復(fù)被匹配的那個(gè)字符,可以用向后引用達(dá)到目的。我們以后將講到向后引用。
?6.使用?*或+ 進(jìn)行重復(fù)
?:告訴引擎匹配前導(dǎo)字符0次或一次。事實(shí)上是表示前導(dǎo)字符是可選的。
+:告訴引擎匹配前導(dǎo)字符1次或多次
*:告訴引擎匹配前導(dǎo)字符0次或多次
<[A-Za-z][A-Za-z0-9]*>匹配沒(méi)有屬性的HTML標(biāo)簽,“<”以及“>”是文字符號(hào)。第一個(gè)字符集匹配一個(gè)字母,第二個(gè)字符集匹配一個(gè)字母或數(shù)字。
我們似乎也可以用<[A-Za-z0-9]+>。但是它會(huì)匹配<1>。但是這個(gè)正則表達(dá)式在你知道你要搜索的字符串不包含類似的無(wú)效標(biāo)簽時(shí)還是足夠有效的。
?·限制性重復(fù)
許多現(xiàn)代的正則表達(dá)式實(shí)現(xiàn),都允許你定義對(duì)一個(gè)字符重復(fù)多少次。詞法是:{min,max}。min和max都是非負(fù)整數(shù)。如果逗號(hào)有而max被忽略了,則max沒(méi)有限制。如果逗號(hào)和max都被忽略了,則重復(fù)min次。
因此{(lán)0,}和*一樣,{1,}和+ 的作用一樣。
你可以用<<\b[1-9][0-9]{3}\b>>匹配1000~9999之間的數(shù)字(“\b”表示單詞邊界)。<<\b[1-9][0-9]{2,4}\b>>匹配一個(gè)在100~99999之間的數(shù)字。
?·注意貪婪性
假設(shè)你想用一個(gè)正則表達(dá)式匹配一個(gè)HTML標(biāo)簽。你知道輸入將會(huì)是一個(gè)有效的HTML文件,因此正則表達(dá)式不需要排除那些無(wú)效的標(biāo)簽。所以如果是在兩個(gè)尖括號(hào)之間的內(nèi)容,就應(yīng)該是一個(gè)HTML標(biāo)簽。
許多正則表達(dá)式的新手會(huì)首先想到用正則表達(dá)式<< <.+> >>,他們會(huì)很驚訝的發(fā)現(xiàn),對(duì)于測(cè)試字符串,“This is a <EM>first</EM> test”,你可能期望會(huì)返回<EM>,然后繼續(xù)進(jìn)行匹配的時(shí)候,返回</EM>。
但事實(shí)是不會(huì)。正則表達(dá)式將會(huì)匹配“<EM>first</EM>”。很顯然這不是我們想要的結(jié)果。原因在于“+”是貪婪的。也就是說(shuō),“+”會(huì)導(dǎo)致正則表達(dá)式引擎試圖盡可能的重復(fù)前導(dǎo)字符。只有當(dāng)這種重復(fù)會(huì)引起整個(gè)正則表達(dá)式匹配失敗的情況下,引擎會(huì)進(jìn)行回溯。也就是說(shuō),它會(huì)放棄最后一次的“重復(fù)”,然后處理正則表達(dá)式余下的部分。
和“+”類似,“?*”的重復(fù)也是貪婪的。
?·深入正則表達(dá)式引擎內(nèi)部
讓我們來(lái)看看正則引擎如何匹配前面的例子。第一個(gè)記號(hào)是“<”,這是一個(gè)文字符號(hào)。第二個(gè)符號(hào)是“.”,匹配了字符“E”,然后“+”一直可以匹配其余的字符,直到一行的結(jié)束。然后到了換行符,匹配失敗(“.”不匹配換行符)。于是引擎開(kāi)始對(duì)下一個(gè)正則表達(dá)式符號(hào)進(jìn)行匹配。也即試圖匹配“>”。到目前為止,“<.+”已經(jīng)匹配了“<EM>first</EM> test”。引擎會(huì)試圖將“>”與換行符進(jìn)行匹配,結(jié)果失敗了。于是引擎進(jìn)行回溯。結(jié)果是現(xiàn)在“<.+”匹配“<EM>first</EM> tes”。于是引擎將“>”與“t”進(jìn)行匹配。顯然還是會(huì)失敗。這個(gè)過(guò)程繼續(xù),直到“<.+”匹配“<EM>first</EM”,“>”與“>”匹配。于是引擎找到了一個(gè)匹配“<EM>first</EM>”。記住,正則導(dǎo)向的引擎是“急切的”,所以它會(huì)急著報(bào)告它找到的第一個(gè)匹配。而不是繼續(xù)回溯,即使可能會(huì)有更好的匹配,例如“<EM>”。所以我們可以看到,由于“+”的貪婪性,使得正則表達(dá)式引擎返回了一個(gè)最左邊的最長(zhǎng)的匹配。
?·用懶惰性取代貪婪性
一個(gè)用于修正以上問(wèn)題的可能方案是用“+”的惰性代替貪婪性。你可以在“+”后面緊跟一個(gè)問(wèn)號(hào)“?”來(lái)達(dá)到這一點(diǎn)。“*”,“{}”和“?”表示的重復(fù)也可以用這個(gè)方案。因此在上面的例子中我們可以使用“<.+?>”。讓我們?cè)賮?lái)看看正則表達(dá)式引擎的處理過(guò)程。
再一次,正則表達(dá)式記號(hào)“<”會(huì)匹配字符串的第一個(gè)“<”。下一個(gè)正則記號(hào)是“.”。這次是一個(gè)懶惰的“+”來(lái)重復(fù)上一個(gè)字符。這告訴正則引擎,盡可能少的重復(fù)上一個(gè)字符。因此引擎匹配“.”和字符“E”,然后用“>”匹配“M”,結(jié)果失敗了。引擎會(huì)進(jìn)行回溯,和上一個(gè)例子不同,因?yàn)槭嵌栊灾貜?fù),所以引擎是擴(kuò)展惰性重復(fù)而不是減少,于是“<.+”現(xiàn)在被擴(kuò)展為“<EM”。引擎繼續(xù)匹配下一個(gè)記號(hào)“>”。這次得到了一個(gè)成功匹配。引擎于是報(bào)告“<EM>”是一個(gè)成功的匹配。整個(gè)過(guò)程大致如此。
?·惰性擴(kuò)展的一個(gè)替代方案
我們還有一個(gè)更好的替代方案。可以用一個(gè)貪婪重復(fù)與一個(gè)取反字符集:“<[^>]+>”。之所以說(shuō)這是一個(gè)更好的方案在于使用惰性重復(fù)時(shí),引擎會(huì)在找到一個(gè)成功匹配前對(duì)每一個(gè)字符進(jìn)行回溯。而使用取反字符集則不需要進(jìn)行回溯。
最后要記住的是,本教程僅僅談到的是正則導(dǎo)向的引擎。文本導(dǎo)向的引擎是不回溯的。但是同時(shí)他們也不支持惰性重復(fù)操作。
?7.使用“.”匹配幾乎任意字符
在正則表達(dá)式中,“.”是最常用的符號(hào)之一。不幸的是,它也是最容易被誤用的符號(hào)之一。
“.”匹配一個(gè)單個(gè)的字符而不用關(guān)心被匹配的字符是什么。唯一的例外是新行符。在本教程中談到的引擎,缺省情況下都是不匹配新行符的。因此在缺省情況下,“.”等于是字符集[^\n\r](Window)或[^\n]( Unix)的簡(jiǎn)寫(xiě)。
這個(gè)例外是因?yàn)闅v史的原因。因?yàn)樵缙谑褂谜齽t表達(dá)式的工具是基于行的。它們都是一行一行的讀入一個(gè)文件,將正則表達(dá)式分別應(yīng)用到每一行上去。在這些工具中,字符串是不包含新行符的。因此“.”也就從不匹配新行符。
現(xiàn)代的工具和語(yǔ)言能夠?qū)⒄齽t表達(dá)式應(yīng)用到很大的字符串甚至整個(gè)文件上去。本教程討論的所有正則表達(dá)式實(shí)現(xiàn)都提供一個(gè)選項(xiàng),可以使“.”匹配所有的字符,包括新行符。在RegexBuddy, EditPad Pro或PowerGREP等工具中,你可以簡(jiǎn)單的選中“點(diǎn)號(hào)匹配新行符”。在Perl中,“.”可以匹配新行符的模式被稱作“單行模式”。很不幸,這是一個(gè)很容易混淆的名詞。因?yàn)檫€有所謂“多行模式”。多行模式只影響行首行尾的錨定(anchor),而單行模式只影響“.”。
其他語(yǔ)言和正則表達(dá)式庫(kù)也采用了Perl的術(shù)語(yǔ)定義。當(dāng)在.NET Framework中使用正則表達(dá)式類時(shí),你可以用類似下面的語(yǔ)句來(lái)激活單行模式:Regex.Match(“string”,”regex”,RegexOptions.SingleLine)
?·保守的使用點(diǎn)號(hào)“.”
點(diǎn)號(hào)可以說(shuō)是最強(qiáng)大的元字符。它允許你偷懶:用一個(gè)點(diǎn)號(hào),就能匹配幾乎所有的字符。但是問(wèn)題在于,它也常常會(huì)匹配不該匹配的字符。
我會(huì)以一個(gè)簡(jiǎn)單的例子來(lái)說(shuō)明。讓我們看看如何匹配一個(gè)具有“mm/dd/yy”格式的日期,但是我們想允許用戶來(lái)選擇分隔符。很快能想到的一個(gè)方案是<<\d\d.\d\d.\d\d>>。看上去它能匹配日期“02/12/03”。問(wèn)題在于02512703也會(huì)被認(rèn)為是一個(gè)有效的日期。
<<\d\d[-/.]\d\d[-/.]\d\d>>看上去是一個(gè)好一點(diǎn)的解決方案。記住點(diǎn)號(hào)在一個(gè)字符集里不是元字符。這個(gè)方案遠(yuǎn)不夠完善,它會(huì)匹配“99/99/99”。而<<[0-1]\d[-/.][0-3]\d[-/.]\d\d>>又更進(jìn)一步。盡管他也會(huì)匹配“19/39/99”。你想要你的正則表達(dá)式達(dá)到如何完美的程度取決于你想達(dá)到什么樣的目的。如果你想校驗(yàn)用戶輸入,則需要盡可能的完美。如果你只是想分析一個(gè)已知的源,并且我們知道沒(méi)有錯(cuò)誤的數(shù)據(jù),用一個(gè)比較好的正則表達(dá)式來(lái)匹配你想要搜尋的字符就已經(jīng)足夠。
?8.字符串開(kāi)始和結(jié)束的錨定
錨定和一般的正則表達(dá)式符號(hào)不同,它不匹配任何字符。相反,他們匹配的是字符之前或之后的位置。“^”匹配一行字符串第一個(gè)字符前的位置。<<^a>>將會(huì)匹配字符串“abc”中的a。<<^b>>將不會(huì)匹配“abc”中的任何字符。
類似的,$匹配字符串中最后一個(gè)字符的后面的位置。所以<<c$>>匹配“abc”中的c。
?·錨定的應(yīng)用
在編程語(yǔ)言中校驗(yàn)用戶輸入時(shí),使用錨定是非常重要的。如果你想校驗(yàn)用戶的輸入為整數(shù),用<<^\d+$>>。
用戶輸入中,常常會(huì)有多余的前導(dǎo)空格或結(jié)束空格。你可以用<<^\s*>>和<<\s*$>>來(lái)匹配前導(dǎo)空格或結(jié)束空格。
?·使用“^”和“$”作為行的開(kāi)始和結(jié)束錨定
如果你有一個(gè)包含了多行的字符串。例如:“first line\n\rsecond line”(其中\(zhòng)n\r表示一個(gè)新行符)。常常需要對(duì)每行分別處理而不是整個(gè)字符串。因此,幾乎所有的正則表達(dá)式引擎都提供一個(gè)選項(xiàng),可以擴(kuò)展這兩種錨定的含義。“^”可以匹配字串的開(kāi)始位置(在f之前),以及每一個(gè)新行符的后面位置(在\n\r和s之間)。類似的,$會(huì)匹配字串的結(jié)束位置(最后一個(gè)e之后),以及每個(gè)新行符的前面(在e與\n\r之間)。
在.NET中,當(dāng)你使用如下代碼時(shí),將會(huì)定義錨定匹配每一個(gè)新行符的前面和后面位置:Regex.Match("string", "regex", RegexOptions.Multiline)
應(yīng)用:string str = Regex.Replace(Original, "^", "> ", RegexOptions.Multiline)--將會(huì)在每行的行首插入“> ”。
· 絕對(duì)錨定
<<\A>>只匹配整個(gè)字符串的開(kāi)始位置,<<\Z>>只匹配整個(gè)字符串的結(jié)束位置。即使你使用了“多行模式”,<<\A>>和<<\Z>>也從不匹配新行符。
即使\Z和$只匹配字符串的結(jié)束位置,仍然有一個(gè)例外的情況。如果字符串以新行符結(jié)束,則\Z和$將會(huì)匹配新行符前面的位置,而不是整個(gè)字符串的最后面。這個(gè)“改進(jìn)”是由Perl引進(jìn)的,然后被許多的正則表達(dá)式實(shí)現(xiàn)所遵循,包括Java,.NET等。如果應(yīng)用<<^[a-z]+$>>到“joe\n”,則匹配結(jié)果是“joe”而不是“joe\n”。
radic 發(fā)表于 2006-12-15 12:24:05
作者:Radic???? 來(lái)源:sun
評(píng)論數(shù):5 點(diǎn)擊數(shù):592???? 投票總得分:6 投票總?cè)舜?2
關(guān)鍵字:Java;安全編碼
摘要:
本文是來(lái)自Sun官方站點(diǎn)的一篇關(guān)于如何編寫(xiě)安全的Java代碼的指南,開(kāi)發(fā)者在編寫(xiě)一般代碼時(shí),可以參照本文的指南
本文是來(lái)自Sun官方站點(diǎn)的一篇關(guān)于如何編寫(xiě)安全的Java代碼的指南,開(kāi)發(fā)者在編寫(xiě)一般代碼時(shí),可以參照本文的指南:
?????????靜態(tài)字段
?????????縮小作用域
?????????公共方法和字段
?????????保護(hù)包
?????????equals方法
?????????如果可能使對(duì)象不可改變
?????????不要返回指向包含敏感數(shù)據(jù)的內(nèi)部數(shù)組的引用
?????????不要直接存儲(chǔ)用戶提供的數(shù)組
?????????序列化
?????????原生函數(shù)
?????????清除敏感信息靜態(tài)字段?????????避免使用非final的公共靜態(tài)變量
應(yīng)盡可能地避免使用非final公共靜態(tài)變量,因?yàn)闊o(wú)法判斷代碼有無(wú)權(quán)限改變這些變量值。
?????????一般地,應(yīng)謹(jǐn)慎使用易變的靜態(tài)狀態(tài),因?yàn)檫@可能導(dǎo)致設(shè)想中相互獨(dú)立的子系統(tǒng)之間發(fā)生不可預(yù)知的交互。
縮小作用域作為一個(gè)慣例,盡可能縮小方法和字段的作用域。檢查包訪問(wèn)權(quán)限的成員能否改成私有的,保護(hù)類型的成員可否改成包訪問(wèn)權(quán)限的或者私有的,等等。
公共方法/字段避免使用公共變量,而是使用訪問(wèn)器方法訪問(wèn)這些變量。用這種方式,如果需要,可能增加集中安全控制。
對(duì)于任何公共方法,如果它們能夠訪問(wèn)或修改任何敏感內(nèi)部狀態(tài),務(wù)必使它們包含安全控制。
參考如下代碼段,該代碼段中不可信任代碼可能設(shè)置TimeZone的值:
private static TimeZone??defaultZone = null;
??????public static synchronized void setDefault(TimeZone zone)
??????{
??????????defaultZone = zone;
??????}
保護(hù)包有時(shí)需要在全局防止包被不可信任代碼訪問(wèn),本節(jié)描述了一些防護(hù)技術(shù):
?????????防止包注入:如果不可信任代碼想要訪問(wèn)類的包保護(hù)成員,可以嘗試在被攻擊的包內(nèi)定義自己的新類用以獲取這些成員的訪問(wèn)權(quán)。防止這類攻擊的方式有兩種:
1.????????通過(guò)向java.security.properties文件中加入如下文字防止包內(nèi)被注入惡意類。
??????????...
package.definition=Package#1 [,Package#2,...,Package#n]
...
這會(huì)導(dǎo)致當(dāng)試圖在包內(nèi)定義新類時(shí)類裝載器的defineClass方法會(huì)拋出異常,除非賦予代碼一下權(quán)限:
...
RuntimePermission("defineClassInPackage."+package)
...
2.????????另一種方式是通過(guò)將包內(nèi)的類加入到封裝的Jar文件里。
(參看http://java.sun.com/j2se/sdk/1.2/docs/guide/extensions/spec.html)
????通過(guò)使用這種技巧,代碼無(wú)法獲得擴(kuò)展包的權(quán)限,因此也無(wú)須修改java.security.properties文件。
?????????防止包訪問(wèn):通過(guò)限制包訪問(wèn)并僅賦予特定代碼訪問(wèn)權(quán)限防止不可信任代碼對(duì)包成員的訪問(wèn)。通過(guò)向java.security.properties文件中加入如下文字可以達(dá)到這一目的:
??????...
package.access=Package#1 [,Package#2,...,Package#n]
...
這會(huì)導(dǎo)致當(dāng)試圖在包內(nèi)定義新類時(shí)類裝載器的defineClass方法會(huì)拋出異常,除非賦予代碼一下權(quán)限:
...
RuntimePermission("defineClassInPackage."+package)
...
如果可能使對(duì)象不可改變如果可能,使對(duì)象不可改變。如果不可能,使得它們可以被克隆并返回一個(gè)副本。如果返回的對(duì)象是數(shù)組、向量或哈希表等,牢記這些對(duì)象不能被改變,調(diào)用者修改這些對(duì)象的內(nèi)容可能導(dǎo)致安全漏洞。此外,因?yàn)椴挥蒙湘i,不可改變性能夠提高并發(fā)性。參考Clear sensitive information了解該慣例的例外情況。
不要返回指向包含敏感數(shù)據(jù)的內(nèi)部數(shù)組的引用該慣例僅僅是不可變慣例的變型,在這兒提出是因?yàn)槌3T谶@里犯錯(cuò)。即使數(shù)組中包含不可變的對(duì)象(如字符串),也要返回一個(gè)副本這樣調(diào)用者不能修改數(shù)組中的字符串。不要傳回一個(gè)數(shù)組,而是數(shù)組的拷貝。
不要直接在用戶提供的數(shù)組里存儲(chǔ)該慣例僅僅是不可變慣例的另一個(gè)變型。使用對(duì)象數(shù)組的構(gòu)造器和方法,比如說(shuō)PubicKey數(shù)組,應(yīng)當(dāng)在將數(shù)組存儲(chǔ)到內(nèi)部之前克隆數(shù)組,而不是直接將數(shù)組引用賦給同樣類型的內(nèi)部變量。缺少這個(gè)警惕,用戶對(duì)外部數(shù)組做得任何變動(dòng)(在使用討論中的構(gòu)造器創(chuàng)建對(duì)象后)可能意外地更改對(duì)象的內(nèi)部狀態(tài),即使該對(duì)象可能是無(wú)法改變的
序列化當(dāng)對(duì)對(duì)象序列化時(shí),直到它被反序列化,它不在Java運(yùn)行時(shí)環(huán)境的控制之下,因此也不在Java平臺(tái)提供的安全控制范圍內(nèi)。
在實(shí)現(xiàn)Serializable時(shí)務(wù)必將以下事宜牢記在心:
?????????transient
在包含系統(tǒng)資源的直接句柄和相對(duì)地址空間信息的字段前使用transient關(guān)鍵字。 如果資源,如文件句柄,不被聲明為transient,該對(duì)象在序列化狀態(tài)下可能會(huì)被修改,從而使得被反序列化后獲取對(duì)資源的不當(dāng)訪問(wèn)。
?????????特定類的序列化/反序列化方法
為了確保反序列化對(duì)象不包含違反一些不變量集合的狀態(tài),類應(yīng)該定義自己的反序列化方法并使用ObjectInputValidation接口驗(yàn)證這些變量。
如果一個(gè)類定義了自己的序列化方法,它就不能向任何DataInput/DataOuput方法傳遞內(nèi)部數(shù)組。所有的DataInput/DataOuput方法都能被重寫(xiě)。注意默認(rèn)序列化不會(huì)向DataInput/DataOuput字節(jié)數(shù)組方法暴露私有字節(jié)數(shù)組字段。
如果Serializable類直接向DataOutput(write(byte [] b))方法傳遞了一個(gè)私有數(shù)組,那么黑客可以創(chuàng)建ObjectOutputStream的子類并覆蓋write(byte [] b)方法,這樣他可以訪問(wèn)并修改私有數(shù)組。下面示例說(shuō)明了這個(gè)問(wèn)題。
你的類:
??????public class YourClass implements Serializable {
????????????private byte [] internalArray;
....
private synchronized void writeObject(ObjectOutputStream stream) {
...
?????????????? stream.write(internalArray);
????????????????...
}
}黑客代碼
?????? public class HackerObjectOutputStream extends ObjectOutputStream{
????????????public void write (byte [] b) {
?????????????? Modify b
??????}
}
...
???????????? YourClass yc = new YourClass();
??????????????...
???????????? HackerObjectOutputStream hoos = new HackerObjectOutputStream();
??????????????hoos.writeObject(yc);?????????字節(jié)流加密
保護(hù)虛擬機(jī)外的字節(jié)流的另一方式是對(duì)序列化包產(chǎn)生的流進(jìn)行加密。字節(jié)流加密防止解碼或讀取被序列化的對(duì)象的私有狀態(tài)。如果決定加密,應(yīng)該管理好密鑰,密鑰的存放地點(diǎn)以及將密鑰交付給反序列化程序的方式等。
?????????需要提防的其他事宜
如果不可信任代碼無(wú)法創(chuàng)建對(duì)象,務(wù)必確保不可信任代碼也不能反序列化對(duì)象。切記對(duì)對(duì)象反序列化是創(chuàng)建對(duì)象的另一途徑。
比如說(shuō),如果一個(gè)applet創(chuàng)建了一個(gè)frame,在該frame上創(chuàng)建了警告標(biāo)簽。如果該frame被另一應(yīng)用程序序列化并被一個(gè)applet反序列化,務(wù)必使該frame出現(xiàn)時(shí)帶有同一個(gè)警告標(biāo)簽。
原生方法應(yīng)從以下幾個(gè)方面檢查原生方法:
?????????它們返回什么
?????????它們需要什么參數(shù)
?????????它們是否繞過(guò)了安全檢查
?????????它們是否是公共的,私有的等
?????????它們是否包含能繞過(guò)包邊界的方法調(diào)用,從而繞過(guò)包保護(hù)
清除敏感信息當(dāng)保存敏感信息時(shí),如機(jī)密,盡量保存在如數(shù)組這樣的可變數(shù)據(jù)類型中,而不是保存在字符串這樣的不可變對(duì)象中,這樣使得敏感信息可以盡早顯式地被清除。不要指望Java平臺(tái)的自動(dòng)垃圾回收來(lái)做這種清除,因?yàn)榛厥掌骺赡懿粫?huì)清除這段內(nèi)存,或者很久后才會(huì)回收。盡早清除信息使得來(lái)自虛擬機(jī)外部的堆檢查攻擊變得困難。
MySQL從3.23.15版本以后提供數(shù)據(jù)庫(kù)復(fù)制功能。利用該功能可以實(shí)現(xiàn)兩個(gè)數(shù)據(jù)庫(kù)同步,主從模式,互相備份模式的功能
數(shù)據(jù)庫(kù)同步復(fù)制功能的設(shè)置都在mysql的設(shè)置文件中體現(xiàn)。mysql的配置文件(一般是my.cnf),在unix環(huán)境下在/etc/mysql/my.cnf 或者在mysql用戶的home目錄下的my.cnf。
window環(huán)境中,如果c:根目錄下有my.cnf文件則取該配置文件。當(dāng)運(yùn)行mysql的winmysqladmin.exe工具時(shí)候,該工具會(huì)把c:根目錄下的my.cnf 命名為mycnf.bak。并在winnt目錄下創(chuàng)建my.ini。mysql服務(wù)器啟動(dòng)時(shí)候會(huì)讀該配置文件。所以可以把my.cnf中的內(nèi)容拷貝到my.ini文件中,用my.ini文件作為mysql服務(wù)器的配置文件。
設(shè)置方法:
設(shè)置范例環(huán)境:
操作系統(tǒng):window2000 professional
mysql:4.0.4-beta-max-nt-log
A ip:10.10.10.22
B ip:10.10.10.53
A:設(shè)置
1.增加一個(gè)用戶最為同步的用戶帳號(hào):
GRANT FILE ON *.* TO backup@'10.10.10.53' IDENTIFIED BY ‘1234’
|
2.增加一個(gè)數(shù)據(jù)庫(kù)作為同步數(shù)據(jù)庫(kù):
B:設(shè)置
1.增加一個(gè)用戶最為同步的用戶帳號(hào):
GRANT FILE ON *.* TO backup@'10.10.10.22' IDENTIFIED BY ‘1234’
|
2.增加一個(gè)數(shù)據(jù)庫(kù)作為同步數(shù)據(jù)庫(kù):
主從模式:A->B
A為master
修改A mysql的my.ini文件。在mysqld配置項(xiàng)中加入下面配置:
server-id=1log-bin#設(shè)置需要記錄log 可以設(shè)置log-bin=c:mysqlbakmysqllog 設(shè)置日志文件的目錄,#其中mysqllog是日志文件的名稱,mysql將建立不同擴(kuò)展名,文件名為mysqllog的幾個(gè)日志文件。binlog-do-db=backup #指定需要日志的數(shù)據(jù)庫(kù)
重起數(shù)據(jù)庫(kù)服務(wù)。
用show master status 命令看日志情況。
B為slave
修改B mysql的my.ini文件。在mysqld配置項(xiàng)中加入下面配置:
server-id=2master-host=10.10.10.22master-user=backup
|
#同步用戶帳號(hào)
master-password=1234master-port=3306master-connect-retry=60
|
預(yù)設(shè)重試間隔60秒replicate-do-db=backup 告訴slave只做backup數(shù)據(jù)庫(kù)的更新
重起數(shù)據(jù)庫(kù)
用show slave status看同步配置情況。
注意:由于設(shè)置了slave的配置信息,mysql在數(shù)據(jù)庫(kù)目錄下生成master.info,所以如有要修改相關(guān)slave的配置要先刪除該文件。否則修改的配置不能生效。
雙機(jī)互備模式。
如果在A加入slave設(shè)置,在B加入master設(shè)置,則可以做B->A的同步。
在A的配置文件中 mysqld 配置項(xiàng)加入以下設(shè)置:
master-host=10.10.10.53master-user=backupmaster-password=1234replicate-do-db=
backupmaster-connect-retry=10
|
在B的配置文件中 mysqld 配置項(xiàng)加入以下設(shè)置:
log-bin=c:mysqllogmysqllogbinlog-do-db=backup
|
注意:當(dāng)有錯(cuò)誤產(chǎn)生時(shí)*.err日志文件。同步的線程退出,當(dāng)糾正錯(cuò)誤后要讓同步機(jī)制進(jìn)行工作,運(yùn)行slave start
重起AB機(jī)器,則可以實(shí)現(xiàn)雙向的熱備。
測(cè)試:
向B批量插入大數(shù)據(jù)量表AA(1872000)條,A數(shù)據(jù)庫(kù)每秒鐘可以更新2500條數(shù)據(jù)。
優(yōu)化數(shù)據(jù)庫(kù)的思想:
? ================
? 1、關(guān)鍵字段建立索引。
? 2、使用存儲(chǔ)過(guò)程,它使SQL變得更加靈活和高效。
? 3、備份數(shù)據(jù)庫(kù)和清除垃圾數(shù)據(jù)。
? 4、SQL語(yǔ)句語(yǔ)法的優(yōu)化。(可以用Sybase的SQL Expert,可惜我沒(méi)找到unexpired的
序列號(hào))
? 5、清理刪除日志。
? SQL語(yǔ)句優(yōu)化的原則: ?
? ==================
? 1、使用索引來(lái)更快地遍歷表。
? 缺省情況下建立的索引是非群集索引,但有時(shí)它并不是最佳的。在非群集索引下,數(shù)據(jù)在物理上隨機(jī)存放在數(shù)據(jù)頁(yè)上。合理的索引設(shè)計(jì)要建立在對(duì)各種查詢的分析和預(yù)測(cè)上。一般來(lái)說(shuō):
? ①.有大量重復(fù)值、且經(jīng)常有范圍查詢
? (between, > ,< ,> =,< =)和order by、group by發(fā)生的列,可考慮建立群集索引;
? ②.經(jīng)常同時(shí)存取多列,且每列都含有重復(fù)值可考慮建立組合索引;
? ③.組合索引要盡量使關(guān)鍵查詢形成索引覆蓋,其前導(dǎo)列一定是使用最頻繁的列。索引雖有助于提高性能但不是索引越多越好,恰好相反過(guò)多的索引會(huì)導(dǎo)致系統(tǒng)低效。用戶在表中每加進(jìn)一個(gè)索引,維護(hù)索引集合就要做相應(yīng)的更新工作。
? 2、IS NULL 與 IS NOT NULL
? 不能用null作索引,任何包含null值的列都將不會(huì)被包含在索引中。即使索引有多列這樣的情況下,只要這些列中有一列含有null,該列就會(huì)從索引中排除。也就是說(shuō)如果某列存在空值,即使對(duì)該列建索引也不會(huì)提高性能。任何在where子句中使用is null或is not null的語(yǔ)句優(yōu)化器是不允許使用索引的。
? 3、IN和EXISTS
? EXISTS要遠(yuǎn)比IN的效率高。里面關(guān)系到full table scan和range scan。幾乎將所有的IN操作符子查詢改寫(xiě)為使用EXISTS的子查詢。
? 4、在海量查詢時(shí)盡量少用格式轉(zhuǎn)換。
? 5、當(dāng)在SQL SERVER 2000中,如果存儲(chǔ)過(guò)程只有一個(gè)參數(shù),并且是OUTPUT類型的,必須在調(diào)用這個(gè)存儲(chǔ)過(guò)程的時(shí)候給這個(gè)參數(shù)一個(gè)初始的值,否則會(huì)出現(xiàn)調(diào)用錯(cuò)誤。
? 6、ORDER BY和GROPU BY
? 使用ORDER BY和GROUP BY短語(yǔ),任何一種索引都有助于SELECT的性能提高。注意如果索引列里面有NULL值,Optimizer將無(wú)法優(yōu)化。
? 7、任何對(duì)列的操作都將導(dǎo)致表掃描,它包括數(shù)據(jù)庫(kù)函數(shù)、計(jì)算表達(dá)式等等,查詢時(shí)要盡可能將操作移至等號(hào)右邊。
? 8、IN、OR子句常會(huì)使用工作表,使索引失效。如果不產(chǎn)生大量重復(fù)值,可以考慮把子句拆開(kāi)。拆開(kāi)的子句中應(yīng)該包含索引。
? 9、SET SHOWPLAN_ALL ON 查看執(zhí)行方案。DBCC檢查數(shù)據(jù)庫(kù)數(shù)據(jù)完整性。
? DBCC(DataBase Consistency Checker)是一組用于驗(yàn)證 SQL Server 數(shù)據(jù)庫(kù)完整性的程序。
? 10、慎用游標(biāo)
? 在某些必須使用游標(biāo)的場(chǎng)合,可考慮將符合條件的數(shù)據(jù)行轉(zhuǎn)入臨時(shí)表中,再對(duì)臨時(shí)表定義游標(biāo)進(jìn)行操作,這樣可使性能得到明顯提高。
? 總結(jié):
? 所謂優(yōu)化即WHERE子句利用了索引,不可優(yōu)化即發(fā)生了表掃描或額外開(kāi)銷。經(jīng)驗(yàn)顯示,SQL Server性能的最大改進(jìn)得益于邏輯的數(shù)據(jù)庫(kù)設(shè)計(jì)、索引設(shè)計(jì)和查詢?cè)O(shè)計(jì)方面。反過(guò)來(lái)說(shuō),最大的性能問(wèn)題常常是由其中這些相同方面中的不足引起的。其實(shí)SQL優(yōu)化的實(shí)質(zhì)就是在結(jié)果正確的前提下,用優(yōu)化器可以識(shí)別的語(yǔ)句,充份利用索引,減少表掃描的I/O次數(shù),盡量避免表搜索的發(fā)生。其實(shí)SQL的性能優(yōu)化是一個(gè)復(fù)雜的過(guò)程,上述這些只是在應(yīng)用層次的一種體現(xiàn),深入研究還會(huì)涉及數(shù)據(jù)庫(kù)層的資源配置、網(wǎng)絡(luò)層的流量控制以及操作系統(tǒng)層的總體設(shè)計(jì)。?
關(guān)注beanaction時(shí),查到的資料,順便做個(gè)備份
多數(shù)IT 組織都必須解決三個(gè)主要問(wèn)題:1.幫助組織減少成本 2.增加并且保持客戶 3.加快業(yè)務(wù)效率。完成這些問(wèn)題一般都需要實(shí)現(xiàn)對(duì)多個(gè)業(yè)務(wù)系統(tǒng)的數(shù)據(jù)和業(yè)務(wù)邏輯的無(wú)縫訪問(wèn),也就是說(shuō),要實(shí)施系統(tǒng)集成工程,以便聯(lián)結(jié)業(yè)務(wù)流程、實(shí)現(xiàn)數(shù)據(jù)的訪問(wèn)與共享。
JpetStore 4.0是ibatis的最新示例程序,基于Struts MVC框架(注:非傳統(tǒng)Struts開(kāi)發(fā)模式),以ibatis作為持久化層。該示例程序設(shè)計(jì)優(yōu)雅,層次清晰,可以學(xué)習(xí)以及作為一個(gè)高效率的編程模型參考。本文是在其基礎(chǔ)上,采用Spring對(duì)其中間層(業(yè)務(wù)層)進(jìn)行改造。使開(kāi)發(fā)量進(jìn)一步減少,同時(shí)又擁有了Spring的一些好處…
1. 前言
JpetStore 4.0是ibatis的最新示例程序。ibatis是開(kāi)源的持久層產(chǎn)品,包含SQL Maps 2.0 和 Data Access Objects 2.0 框架。JpetStore示例程序很好的展示了如何利用ibatis來(lái)開(kāi)發(fā)一個(gè)典型的J2EE web應(yīng)用程序。JpetStore有如下特點(diǎn):
- ibatis數(shù)據(jù)層
- POJO業(yè)務(wù)層
- POJO領(lǐng)域類
- Struts MVC
- JSP 表示層
以下是本文用到的關(guān)鍵技術(shù)介紹,本文假設(shè)您已經(jīng)對(duì)Struts,SpringFramewok,ibatis有一定的了解,如果不是,請(qǐng)首先查閱附錄中的參考資料。
- Struts 是目前Java Web MVC框架中不爭(zhēng)的王者。經(jīng)過(guò)長(zhǎng)達(dá)五年的發(fā)展,Struts已經(jīng)逐漸成長(zhǎng)為一個(gè)穩(wěn)定、成熟的框架,并且占有了MVC框架中最大的市場(chǎng)份額。但是Struts某些技術(shù)特性上已經(jīng)落后于新興的MVC框架。面對(duì)Spring MVC、Webwork2 這些設(shè)計(jì)更精密,擴(kuò)展性更強(qiáng)的框架,Struts受到了前所未有的挑戰(zhàn)。但站在產(chǎn)品開(kāi)發(fā)的角度而言,Struts仍然是最穩(wěn)妥的選擇。本文的原型例子JpetStore 4.0就是基于Struts開(kāi)發(fā)的,但是不拘泥于Struts的傳統(tǒng)固定用法,例如只用了一個(gè)自定義Action類,并且在form bean類的定義上也是開(kāi)創(chuàng)性的,令人耳目一新,稍后將具體剖析一下。
- Spring Framework 實(shí)際上是Expert One-on-One J2EE Design and Development 一書(shū)中所闡述的設(shè)計(jì)思想的具體實(shí)現(xiàn)。Spring Framework的功能非常多。包含AOP、ORM、DAO、Context、Web、MVC等幾個(gè)部分組成。Web、MVC暫不用考慮,JpetStore 4.0用的是更成熟的Struts和JSP;DAO由于目前Hibernate、JDO、ibatis的流行,也不考慮,JpetStore 4.0用的就是ibatis。因此最需要用的是AOP、ORM、Context。Context中,最重要的是Beanfactory,它能將接口與實(shí)現(xiàn)分開(kāi),非常強(qiáng)大。目前AOP應(yīng)用最成熟的還是在事務(wù)管理上。
- ibatis 是一個(gè)功能強(qiáng)大實(shí)用的SQL Map工具,不同于其他ORM工具(如hibernate),它是將SQL語(yǔ)句映射成Java對(duì)象,而對(duì)于ORM工具,它的SQL語(yǔ)句是根據(jù)映射定義生成的。ibatis 以SQL開(kāi)發(fā)的工作量和數(shù)據(jù)庫(kù)移植性上的讓步,為系統(tǒng)設(shè)計(jì)提供了更大的自由空間。有ibatis代碼生成的工具,可以根據(jù)DDL自動(dòng)生成ibatis代碼,能減少很多工作量。
2. JpetStore簡(jiǎn)述
2.1. 背景
最初是Sun公司的J2EE petstore,其最主要目的是用于學(xué)習(xí)J2EE,但是其缺點(diǎn)也很明顯,就是過(guò)度設(shè)計(jì)了。接著Oracle用J2EE petstore來(lái)比較各應(yīng)用服務(wù)器的性能。微軟推出了基于.Net平臺(tái)的 Pet shop,用于競(jìng)爭(zhēng)J2EE petstore。而JpetStore則是經(jīng)過(guò)改良的基于struts的輕便框架J2EE web應(yīng)用程序,相比來(lái)說(shuō),JpetStore設(shè)計(jì)和架構(gòu)更優(yōu)良,各層定義清晰,使用了很多最佳實(shí)踐和模式,避免了很多"反模式",如使用存儲(chǔ)過(guò)程,在java代碼中嵌入SQL語(yǔ)句,把HTML存儲(chǔ)在數(shù)據(jù)庫(kù)中等等。最新版本是JpetStore 4.0。
2.2. JpetStore開(kāi)發(fā)運(yùn)行環(huán)境的建立
1、開(kāi)發(fā)環(huán)境
- Java SDK 1.4.2
- Apache Tomcat 4.1.31
- Eclipse-SDK-3.0.1-win32
- HSQLDB 1.7.2
2、Eclipse插件
- EMF SDK 2.0.1:Eclipse建模框架,lomboz插件需要,可以使用runtime版本。
- lomboz 3.0:J2EE插件,用來(lái)在Eclipse中開(kāi)發(fā)J2EE應(yīng)用程序
- Spring IDE 1.0.3:Spring Bean配置管理插件
- xmlbuddy_2.0.10:編輯XML,用免費(fèi)版功能即可
- tomcatPluginV3:tomcat管理插件
- Properties Editor:編輯java的屬性文件,并可以預(yù)覽以及自動(dòng)存盤(pán)為Unicode格式。免去了手工或者ANT調(diào)用native2ascii的麻煩。
3、示例源程序
- ibatis示例程序JpetStore 4.0 http://www.ibatis.com/jpetstore/jpetstore.html
- 改造后的源程序(+spring)(源碼鏈接)
2.3. 架構(gòu)
圖1 JpetStore架構(gòu)圖
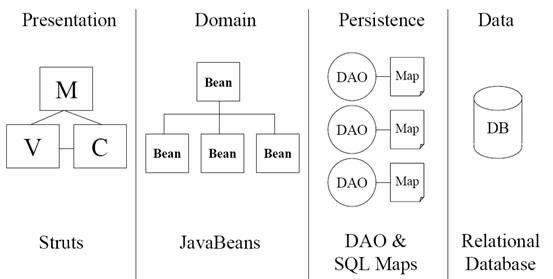
圖1 是JPetStore架構(gòu)圖,更詳細(xì)的內(nèi)容請(qǐng)參見(jiàn)JPetStore的白皮書(shū)。參照這個(gè)架構(gòu)圖,讓我們稍微剖析一下源代碼,得出JpetStore 4.0的具體實(shí)現(xiàn)圖(見(jiàn)圖2),思路一下子就豁然開(kāi)朗了。前言中提到的非傳統(tǒng)的struts開(kāi)發(fā)模式,關(guān)鍵就在struts Action類和form bean類上。
struts Action類只有一個(gè):BeanAction。沒(méi)錯(cuò),確實(shí)是一個(gè)!與傳統(tǒng)的struts編程方式很不同。再仔細(xì)研究BeanAction類,發(fā)現(xiàn)它其實(shí)是一個(gè)通用類,利用反射原理,根據(jù)URL來(lái)決定調(diào)用formbean的哪個(gè)方法。BeanAction大大簡(jiǎn)化了struts的編程模式,降低了對(duì)struts的依賴(與struts以及WEB容器有關(guān)的幾個(gè)類都放在com.ibatis.struts包下,其它的類都可以直接復(fù)用)。利用這種模式,我們會(huì)很容易的把它移植到新的框架如JSF,spring。
這樣重心就轉(zhuǎn)移到form bean上了,它已經(jīng)不是普通意義上的form bean了。查看源代碼,可以看到它不僅僅有數(shù)據(jù)和校驗(yàn)/重置方法,而且已經(jīng)具有了行為,從這個(gè)意義上來(lái)說(shuō),它更像一個(gè)BO(Business Object)。這就是前文講到的,BeanAction類利用反射原理,根據(jù)URL來(lái)決定調(diào)用form bean的哪個(gè)方法(行為)。form bean的這些方法的簽名很簡(jiǎn)單,例如:
public String myActionMethod() {
//..work
return "success";
}
|
方法的返回值直接就是字符串,對(duì)應(yīng)的是forward的名稱,而不再是ActionForward對(duì)象,創(chuàng)建ActionForward對(duì)象的任務(wù)已經(jīng)由BeanAction類代勞了。
另外,程序還提供了ActionContext工具類,該工具類封裝了request 、response、form parameters、request attributes、session attributes和 application attributes中的數(shù)據(jù)存取操作,簡(jiǎn)單而線程安全,form bean類使用該工具類可以進(jìn)一步從表現(xiàn)層框架解耦。
在這里需要特別指出的是,BeanAction類是對(duì)struts擴(kuò)展的一個(gè)有益嘗試,雖然提供了非常好的應(yīng)用開(kāi)發(fā)模式,但是它還非常新,一直在發(fā)展中。
圖2 JpetStore 4.0具體實(shí)現(xiàn)
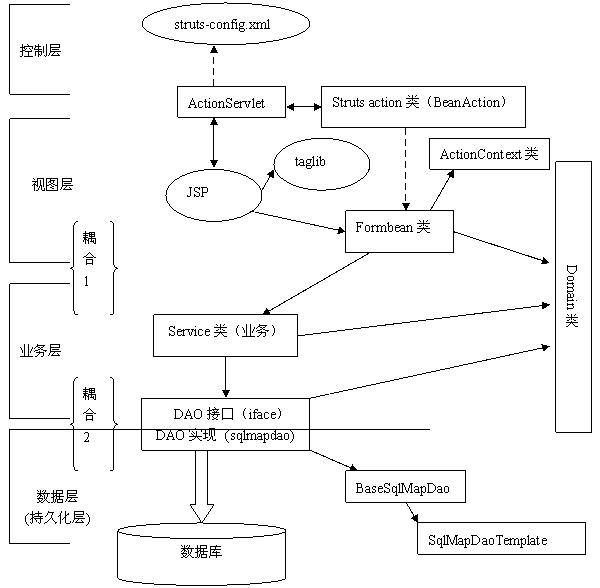
2.4. 代碼剖析
下面就讓我們開(kāi)始進(jìn)一步分析JpetStore4.0的源代碼,為下面的改造鋪路。
- BeanAction.java是唯一一個(gè)Struts action類,位于com.ibatis.struts包下。正如上文所言,它是一個(gè)通用的控制類,利用反射機(jī)制,把控制轉(zhuǎn)移到form bean的某個(gè)方法來(lái)處理。詳細(xì)處理過(guò)程參考其源代碼,簡(jiǎn)單明晰。
-
Form bean類位于com.ibatis.jpetstore.presentation包下,命名規(guī)則為***Bean。Form bean類全部繼承于BaseBean類,而B(niǎo)aseBean類實(shí)際繼承于ActionForm,因此,F(xiàn)orm bean類就是Struts的 ActionForm,F(xiàn)orm bean類的屬性數(shù)據(jù)就由struts框架自動(dòng)填充。而實(shí)際上,JpetStore4.0擴(kuò)展了struts中ActionForm的應(yīng)用: Form bean類還具有行為,更像一個(gè)BO,其行為(方法)由BeanAction根據(jù)配置(struts-config.xml)的URL來(lái)調(diào)用。雖然如此,我們還是把Form bean類定位于表現(xiàn)層。
Struts-config.xml的配置里有3種映射方式,來(lái)告訴BeanAction把控制轉(zhuǎn)到哪個(gè)form bean對(duì)象的哪個(gè)方法來(lái)處理。
以這個(gè)請(qǐng)求連接為例http://localhost/jpetstore4/shop/viewOrder.do
1. URL Pattern
<action path="/shop/viewOrder" type="com.ibatis.struts.BeanAction"
name="orderBean" scope="session"
validate="false">
<forward name="success" path="/order/ViewOrder.jsp"/>
</action>
|
此種方式表示,控制將被轉(zhuǎn)發(fā)到"orderBean"這個(gè)form bean對(duì)象 的"viewOrder"方法(行為)來(lái)處理。方法名取"path"參數(shù)的以"/"分隔的最后一部分。
2. Method Parameter
<action path="/shop/viewOrder" type="com.ibatis.struts.BeanAction"
name="orderBean" parameter="viewOrder" scope="session"
validate="false">
<forward name="success" path="/order/ViewOrder.jsp"/>
</action>
|
此種方式表示,控制將被轉(zhuǎn)發(fā)到"orderBean"這個(gè)form bean對(duì)象的"viewOrder"方法(行為)來(lái)處理。配置中的"parameter"參數(shù)表示form bean類上的方法。"parameter"參數(shù)優(yōu)先于"path"參數(shù)。
3. No Method call
<action path="/shop/viewOrder" type="com.ibatis.struts.BeanAction"
name="orderBean" parameter="*" scope="session"
validate="false">
<forward name="success" path="/order/ViewOrder.jsp"/>
</action>
|
此種方式表示,form bean上沒(méi)有任何方法被調(diào)用。如果存在"name"屬性,則struts把表單參數(shù)等數(shù)據(jù)填充到form bean對(duì)象后,把控制轉(zhuǎn)發(fā)到"success"。否則,如果name為空,則直接轉(zhuǎn)發(fā)控制到"success"。
這就相當(dāng)于struts內(nèi)置的org.apache.struts.actions.ForwardAction的功能
<action path="/shop/viewOrder" type="org.apache.struts.actions.ForwardAction"
parameter="/order/ViewOrder.jsp " scope="session" validate="false">
</action>
|
- Service類位于com.ibatis.jpetstore.service包下,屬于業(yè)務(wù)層。這些類封裝了業(yè)務(wù)以及相應(yīng)的事務(wù)控制。Service類由form bean類來(lái)調(diào)用。
- com.ibatis.jpetstore.persistence.iface包下的類是DAO接口,屬于業(yè)務(wù)層,其屏蔽了底層的數(shù)據(jù)庫(kù)操作,供具體的Service類來(lái)調(diào)用。DaoConfig類是工具類(DAO工廠類),Service類通過(guò)DaoConfig類來(lái)獲得相應(yīng)的DAO接口,而不用關(guān)心底層的具體數(shù)據(jù)庫(kù)操作,實(shí)現(xiàn)了如圖2中{耦合2}的解耦。
- com.ibatis.jpetstore.persistence.sqlmapdao包下的類是對(duì)應(yīng)DAO接口的具體實(shí)現(xiàn),在JpetStore4.0中采用了ibatis來(lái)實(shí)現(xiàn)ORM。這些實(shí)現(xiàn)類繼承BaseSqlMapDao類,而B(niǎo)aseSqlMapDao類則繼承ibatis DAO 框架中的SqlMapDaoTemplate類。ibatis的配置文件存放在com.ibatis.jpetstore.persistence.sqlmapdao.sql目錄下。這些類和配置文件位于數(shù)據(jù)層
- Domain類位于com.ibatis.jpetstore.domain包下,是普通的javabean。在這里用作數(shù)據(jù)傳輸對(duì)象(DTO),貫穿視圖層、業(yè)務(wù)層和數(shù)據(jù)層,用于在不同層之間傳輸數(shù)據(jù)。
剩下的部分就比較簡(jiǎn)單了,請(qǐng)看具體的源代碼,非常清晰。
2.5. 需要改造的地方
JpetStore4.0的關(guān)鍵就在struts Action類和form bean類上,這也是其精華之一(雖然該實(shí)現(xiàn)方式是試驗(yàn)性,待擴(kuò)充和驗(yàn)證),在此次改造中我們要保留下來(lái),即控制層一點(diǎn)不變,表現(xiàn)層獲取相應(yīng)業(yè)務(wù)類的方式變了(要加載spring環(huán)境),其它保持不變。要特別關(guān)注的改動(dòng)是業(yè)務(wù)層和持久層,幸運(yùn)的是JpetStore4.0設(shè)計(jì)非常好,需要改動(dòng)的地方非常少,而且由模式可循,如下:
1. 業(yè)務(wù)層和數(shù)據(jù)層用Spring BeanFactory機(jī)制管理。
2. 業(yè)務(wù)層的事務(wù)由spring 的aop通過(guò)聲明來(lái)完成。
3. 表現(xiàn)層(form bean)獲取業(yè)務(wù)類的方法改由自定義工廠類來(lái)實(shí)現(xiàn)(加載spring環(huán)境)。
3. JPetStore的改造
3.1. 改造后的架構(gòu)
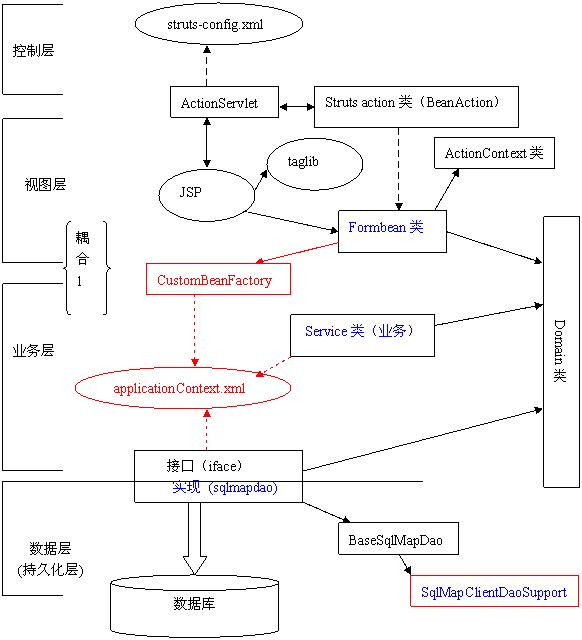
其中紅色部分是要增加的部分,藍(lán)色部分是要修改的部分。下面就讓我們逐一剖析。
3.2. Spring Context的加載
為了在Struts中加載Spring Context,一般會(huì)在struts-config.xml的最后添加如下部分:
<plug-in className="org.springframework.web.struts.ContextLoaderPlugIn">
<set-property property="contextConfigLocation"
value="/WEB-INF/applicationContext.xml" />
</plug-in>
|
Spring在設(shè)計(jì)時(shí)就充分考慮到了與Struts的協(xié)同工作,通過(guò)內(nèi)置的Struts Plug-in在兩者之間提供了良好的結(jié)合點(diǎn)。但是,因?yàn)樵谶@里我們一點(diǎn)也不改動(dòng)JPetStore的控制層(這是JpetStore4.0的精華之一),所以本文不準(zhǔn)備采用此方式來(lái)加載ApplicationContext。我們利用的是spring framework 的BeanFactory機(jī)制,采用自定義的工具類(bean工廠類)來(lái)加載spring的配置文件,從中可以看出Spring有多靈活,它提供了各種不同的方式來(lái)使用其不同的部分/層次,您只需要用你想用的,不需要的部分可以不用。
具體的來(lái)說(shuō),就是在com.ibatis.spring包下創(chuàng)建CustomBeanFactory類,spring的配置文件applicationContext.xml也放在這個(gè)目錄下。以下就是該類的全部代碼,很簡(jiǎn)單:
public final class CustomBeanFactory {
static XmlBeanFactory factory = null;
static {
Resource is = new
InputStreamResource( CustomBeanFactory.class.getResourceAsStream("applicationContext.xml"));
factory = new XmlBeanFactory(is);
}
public static Object getBean(String beanName){
return factory.getBean(beanName);
}
}
|
實(shí)際上就是封裝了Spring 的XMLBeanFactory而已,并且Spring的配置文件只需要加載一次,以后就可以直接用CustomBeanFactory.getBean("someBean")來(lái)獲得需要的對(duì)象了(例如someBean),而不需要知道具體的類。CustomBeanFactory類用于{耦合1}的解耦。
CustomBeanFactory類在本文中只用于表現(xiàn)層的form bean對(duì)象獲得service類的對(duì)象,因?yàn)槲覀儧](méi)有把form bean對(duì)象配置在applicationContext.xml中。但是,為什么不把表現(xiàn)層的form bean類也配置起來(lái)呢,這樣就用不著這CustomBeanFactory個(gè)類了,Spring會(huì)幫助我們創(chuàng)建需要的一切?問(wèn)題的答案就在于form bean類是struts的ActionForm類!如果大家熟悉struts,就會(huì)知道ActionForm類是struts自動(dòng)創(chuàng)建的:在一次請(qǐng)求中,struts判斷,如果ActionForm實(shí)例不存在,就創(chuàng)建一個(gè)ActionForm對(duì)象,把客戶提交的表單數(shù)據(jù)保存到ActionForm對(duì)象中。因此formbean類的對(duì)象就不能由spring來(lái)創(chuàng)建,但是service類以及數(shù)據(jù)層的DAO類可以,所以只有他們?cè)趕pring中配置。
所以,很自然的,我們就創(chuàng)建了CustomBeanFactory類,在表現(xiàn)層來(lái)銜接struts和spring。就這么簡(jiǎn)單,實(shí)現(xiàn)了另一種方式的{耦合一}的解耦。
3.3. 表現(xiàn)層
上 面分析到,struts和spring是在表現(xiàn)層銜接起來(lái)的,那么表現(xiàn)層就要做稍微的更改,即所需要的service類的對(duì)象創(chuàng)建上。以表現(xiàn)層的AccountBean類為例:
原來(lái)的源代碼如下
private static final AccountService accountService = AccountService.getInstance();
private static final CatalogService catalogService = CatalogService.getInstance();
|
改造后的源代碼如下
private static final AccountService accountService = (AccountService)CustomBeanFactory.getBean("AccountService");
private static final CatalogService catalogService = (CatalogService)CustomBeanFactory.getBean("CatalogService");
|
其他的幾個(gè)presentation類以同樣方式改造。這樣,表現(xiàn)層就完成了。關(guān)于表現(xiàn)層的其它部分如JSP等一概不動(dòng)。也許您會(huì)說(shuō),沒(méi)有看出什么特別之處的好處啊?你還是額外實(shí)現(xiàn)了一個(gè)工廠類。別著急,帷幕剛剛開(kāi)啟,spring是在表現(xiàn)層引入,但您發(fā)沒(méi)發(fā)現(xiàn):
- presentation類僅僅面向service類的接口編程,具體"AccountService"是哪個(gè)實(shí)現(xiàn)類,presentation類不知道,是在spring的配置文件里配置。(本例中,為了最大限度的保持原來(lái)的代碼不作變化,沒(méi)有抽象出接口)。Spring鼓勵(lì)面向接口編程,因?yàn)槭侨绱说姆奖愫妥匀唬?dāng)然您也可以不這么做。
- CustomBeanFactory這個(gè)工廠類為什么會(huì)如此簡(jiǎn)單,因?yàn)槠渲苯邮褂昧薙pring的BeanFactory。Spring從其核心而言,是一個(gè)DI容器,其設(shè)計(jì)哲學(xué)是提供一種無(wú)侵入式的高擴(kuò)展性的框架。為了實(shí)現(xiàn)這個(gè)目標(biāo),Spring 大量引入了Java 的Reflection機(jī)制,通過(guò)動(dòng)態(tài)調(diào)用的方式避免硬編碼方式的約束,并在此基礎(chǔ)上建立了其核心組件BeanFactory,以此作為其依賴注入機(jī)制的實(shí)現(xiàn)基礎(chǔ)。org.springframework.beans包中包括了這些核心組件的實(shí)現(xiàn)類,核心中的核心為BeanWrapper和BeanFactory類。
3.4. 持久層
在討論業(yè)務(wù)層之前,我們先看一下持久層,如下圖所示:
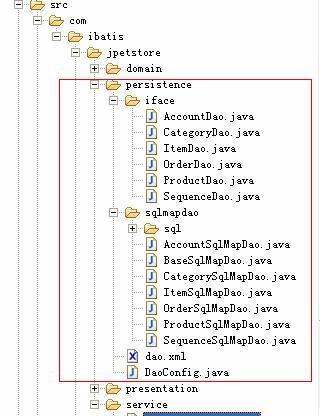
在上文中,我們把iface包下的DAO接口歸為業(yè)務(wù)層,在這里不需要做修改。ibatis的sql配置文件也不需要改。要改的是DAO實(shí)現(xiàn)類,并在spring的配置文件中配置起來(lái)。
1、修改基類
所有的DAO實(shí)現(xiàn)類都繼承于BaseSqlMapDao類。修改BaseSqlMapDao類如下:
public class BaseSqlMapDao extends SqlMapClientDaoSupport {
protected static final int PAGE_SIZE = 4;
protected SqlMapClientTemplate smcTemplate = this.getSqlMapClientTemplate();
public BaseSqlMapDao() {
}
}
|
使BaseSqlMapDao類改為繼承于Spring提供的SqlMapClientDaoSupport類,并定義了一個(gè)保護(hù)屬性smcTemplate,其類型為SqlMapClientTemplate。關(guān)于SqlMapClientTemplate類的詳細(xì)說(shuō)明請(qǐng)參照附錄中的"Spring中文參考手冊(cè)"
2、修改DAO實(shí)現(xiàn)類
所有的DAO實(shí)現(xiàn)類還是繼承于BaseSqlMapDao類,實(shí)現(xiàn)相應(yīng)的DAO接口,但其相應(yīng)的DAO操作委托SqlMapClientTemplate來(lái)執(zhí)行,以AccountSqlMapDao類為例,部分代碼如下:
public List getUsernameList() {
return smcTemplate.queryForList("getUsernameList", null);
}
public Account getAccount(String username, String password) {
Account account = new Account();
account.setUsername(username);
account.setPassword(password);
return (Account) smcTemplate.queryForObject("getAccountByUsernameAndPassword", account);
}
public void insertAccount(Account account) {
smcTemplate.update("insertAccount", account);
smcTemplate.update("insertProfile", account);
smcTemplate.update("insertSignon", account);
}
|
就這么簡(jiǎn)單,所有函數(shù)的簽名都是一樣的,只需要查找替換就可以了!
3、除去工廠類以及相應(yīng)的配置文件
除去DaoConfig.java這個(gè)DAO工廠類和相應(yīng)的配置文件dao.xml,因?yàn)镈AO的獲取現(xiàn)在要用spring來(lái)管理。
4、DAO在Spring中的配置(applicationContext.xml)
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName">
<value>org.hsqldb.jdbcDriver</value>
</property>
<property name="url">
<value>jdbc:hsqldb:hsql://localhost/xdb</value>
</property>
<property name="username">
<value>sa</value>
</property>
<property name="password">
<value></value>
</property>
</bean>
<!-- ibatis sqlMapClient config -->
<bean id="sqlMapClient"
class="org.springframework.orm.ibatis.SqlMapClientFactoryBean">
<property name="configLocation">
<value>
classpath:com\ibatis\jpetstore\persistence\sqlmapdao\sql\sql-map-config.xml
</value>
</property>
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
<!-- Transactions -->
<bean id="TransactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
<!-- persistence layer -->
<bean id="AccountDao"
class="com.ibatis.jpetstore.persistence.sqlmapdao.AccountSqlMapDao">
<property name="sqlMapClient">
<ref local="sqlMapClient"/>
</property>
</bean>
|
具體的語(yǔ)法請(qǐng)參照附錄中的"Spring中文參考手冊(cè)"。在這里只簡(jiǎn)單解釋一下:
1. 我們首先創(chuàng)建一個(gè)數(shù)據(jù)源dataSource,在這里配置的是hsqldb數(shù)據(jù)庫(kù)。如果是ORACLE數(shù)據(jù)庫(kù),driverClassName的值是"oracle.jdbc.driver.OracleDriver",URL的值類似于"jdbc:oracle:thin:@wugfMobile:1521:cdcf"。數(shù)據(jù)源現(xiàn)在由spring來(lái)管理,那么現(xiàn)在我們就可以去掉properties目錄下database.properties這個(gè)配置文件了;還有不要忘記修改sql-map-config.xml,去掉<properties resource="properties/database.properties"/>對(duì)它的引用。
2. sqlMapClient節(jié)點(diǎn)。這個(gè)是針對(duì)ibatis SqlMap的SqlMapClientFactoryBean配置。實(shí)際上配置了一個(gè)sqlMapClient的創(chuàng)建工廠類。configLocation屬性配置了ibatis映射文件的名稱。dataSource屬性指向了使用的數(shù)據(jù)源,這樣所有使用sqlMapClient的DAO都默認(rèn)使用了該數(shù)據(jù)源,除非在DAO的配置中另外顯式指定。
3. TransactionManager節(jié)點(diǎn)。定義了事務(wù),使用的是DataSourceTransactionManager。
4. 下面就可以定義DAO節(jié)點(diǎn)了,如AccountDao,它的實(shí)現(xiàn)類是com.ibatis.jpetstore.persistence.sqlmapdao.AccountSqlMapDao,使用的SQL配置從sqlMapClient中讀取,數(shù)據(jù)庫(kù)連接沒(méi)有特別列出,那么就是默認(rèn)使用sqlMapClient配置的數(shù)據(jù)源datasource。
這樣,我們就把持久層改造完了,其他的DAO配置類似于AccountDao。怎么樣?簡(jiǎn)單吧。這次有接口了:) AccountDao接口->AccountSqlMapDao實(shí)現(xiàn)。
3.5. 業(yè)務(wù)層
業(yè)務(wù)層的位置以及相關(guān)類,如下圖所示:
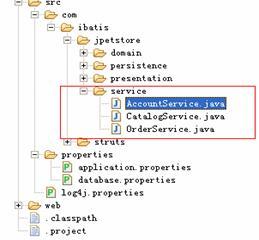
在這個(gè)例子中只有3個(gè)業(yè)務(wù)類,我們以O(shè)rderService類為例來(lái)改造,這個(gè)類是最復(fù)雜的,其中涉及了事務(wù)。
1、在ApplicationContext配置文件中增加bean的配置:
<bean id="OrderService"
class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager">
<ref local="TransactionManager"></ref>
</property>
<property name="target">
<bean class="com.ibatis.jpetstore.service.OrderService">
<property name="itemDao">
<ref bean="ItemDao"/>
</property>
<property name="orderDao">
<ref bean="OrderDao"/>
</property>
<property name="sequenceDao">
<ref bean="SequenceDao"/>
</property>
</bean>
</property>
<property name="transactionAttributes">
<props>
<prop key="insert*">PROPAGATION_REQUIRED</prop>
</props>
</property>
</bean>
|
定義了一個(gè)OrderService,還是很容易懂的。為了簡(jiǎn)單起見(jiàn),使用了嵌套bean,其實(shí)現(xiàn)類是com.ibatis.jpetstore.service.OrderService,分別引用了ItemDao,OrderDao,SequenceDao。該bean的insert*實(shí)現(xiàn)了事務(wù)管理(AOP方式)。TransactionProxyFactoryBean自動(dòng)創(chuàng)建一個(gè)事務(wù)advisor, 該advisor包括一個(gè)基于事務(wù)屬性的pointcut,因此只有事務(wù)性的方法被攔截。
2、業(yè)務(wù)類的修改
以O(shè)rderService為例:
public class OrderService {
/* Private Fields */
private ItemDao itemDao;
private OrderDao orderDao;
private SequenceDao sequenceDao;
/* Constructors */
public OrderService() {
}
/**
* @param itemDao 要設(shè)置的 itemDao。
*/
public final void setItemDao(ItemDao itemDao) {
this.itemDao = itemDao;
}
/**
* @param orderDao 要設(shè)置的 orderDao。
*/
public final void setOrderDao(OrderDao orderDao) {
this.orderDao = orderDao;
}
/**
* @param sequenceDao 要設(shè)置的 sequenceDao。
*/
public final void setSequenceDao(SequenceDao sequenceDao) {
this.sequenceDao = sequenceDao;
}
//剩下的部分
…….
}
|
紅色部分為修改部分。Spring采用的是Type2的設(shè)置依賴注入,所以我們只需要定義屬性和相應(yīng)的設(shè)值函數(shù)就可以了,ItemDao,OrderDao,SequenceDao的值由spring在運(yùn)行期間注入。構(gòu)造函數(shù)就可以為空了,另外也不需要自己編寫(xiě)代碼處理事務(wù)了(事務(wù)在配置中聲明),daoManager.startTransaction();等與事務(wù)相關(guān)的語(yǔ)句也可以去掉了。和原來(lái)的代碼比較一下,是不是處理精簡(jiǎn)了很多!可以更關(guān)注業(yè)務(wù)的實(shí)現(xiàn)。
4. 結(jié)束語(yǔ)
ibatis是一個(gè)功能強(qiáng)大實(shí)用的SQL Map工具,可以直接控制SQL,為系統(tǒng)設(shè)計(jì)提供了更大的自由空間。其提供的最新示例程序JpetStore 4.0,設(shè)計(jì)優(yōu)雅,應(yīng)用了迄今為止很多最佳實(shí)踐和設(shè)計(jì)模式,非常適于學(xué)習(xí)以及在此基礎(chǔ)上創(chuàng)建輕量級(jí)的J2EE WEB應(yīng)用程序。JpetStore 4.0是基于struts的,本文在此基礎(chǔ)上,最大程度保持了原有設(shè)計(jì)的精華以及最小的代碼改動(dòng)量,在業(yè)務(wù)層和持久化層引入了Spring。在您閱讀了本文以及改造后的源代碼后,會(huì)深切的感受到Spring帶來(lái)的種種好處:自然的面向接口的編程,業(yè)務(wù)對(duì)象的依賴注入,一致的數(shù)據(jù)存取框架和聲明式的事務(wù)處理,統(tǒng)一的配置文件…更重要的是Spring既是全面的又是模塊化的,Spring有分層的體系結(jié)構(gòu),這意味著您能選擇僅僅使用它任何一個(gè)獨(dú)立的部分,就像本文,而它的架構(gòu)又是內(nèi)部一致。
因了需要用到這些信息,所以總結(jié)一下,方便以后參閱
通過(guò)request.getHeader("User-Agent")大致可以取得用戶瀏覽器的信息
如果里面包含:
"msie"-->MicroSoft?
"opera" -->Opera Software
"mozilla"-->Netscape Communications
如果取瀏覽器版本信息
String str = request.getHeader("User-Agent");
MS :? str.substring(str.indexOf("msie") + 5);
Other :
tmpString = (str.substring(tmpPos = (str.indexOf("/")) + 1, tmpPos + str.indexOf(" "))).trim(); ?//沒(méi)有親自試
操作系統(tǒng)部分,不啰嗦了
private void setOs()
{
if (this.userAgent.indexOf("win") > -1){
? if (this.userAgent.indexOf("windows 95") > -1 || this.userAgent.indexOf("win95") > -1){
???? this.os = "Windows 95";
? }
? if (this.userAgent.indexOf("windows 98") > -1 || this.userAgent.indexOf("win98") > -1){
???? this.os = "Windows 98";
? }
? if (this.userAgent.indexOf("windows nt") > -1 || this.userAgent.indexOf("winnt") > -1){
????? this.os = "Windows NT";
? }
? if (this.userAgent.indexOf("win16") > -1 || this.userAgent.indexOf("windows 3.") > -1){
????? this.os = "Windows 3.x";
? }
?}
}
獲取語(yǔ)言request.getHeader("Accept-Language");
詳細(xì)信息可以再分解....
Lucene 是基于 Java 的全文信息檢索包,它目前是 Apache Jakarta 家族下面的一個(gè)開(kāi)源項(xiàng)目。在這篇文章中,我們首先來(lái)看如何利用 Lucene 實(shí)現(xiàn)高級(jí)搜索功能,然后學(xué)習(xí)如何利用 Lucene 來(lái)創(chuàng)建一個(gè)健壯的 Web 搜索應(yīng)用程序。
在本篇文章中,你會(huì)學(xué)習(xí)到如何利用 Lucene 實(shí)現(xiàn)高級(jí)搜索功能以及如何利用 Lucene 來(lái)創(chuàng)建 Web 搜索應(yīng)用程序。通過(guò)這些學(xué)習(xí),你就可以利用 Lucene 來(lái)創(chuàng)建自己的搜索應(yīng)用程序。
架構(gòu)概覽
通常一個(gè) Web 搜索引擎的架構(gòu)分為前端和后端兩部分,就像圖一中所示。在前端流程中,用戶在搜索引擎提供的界面中輸入要搜索的關(guān)鍵詞,這里提到的用戶界面一般是一個(gè)帶有輸入框的 Web 頁(yè)面,然后應(yīng)用程序?qū)⑺阉鞯年P(guān)鍵詞解析成搜索引擎可以理解的形式,并在索引文件上進(jìn)行搜索操作。在排序后,搜索引擎返回搜索結(jié)果給用戶。在后端流程中,網(wǎng)絡(luò)爬蟲(chóng)或者機(jī)器人從因特網(wǎng)上獲取 Web 頁(yè)面,然后索引子系統(tǒng)解析這些 Web 頁(yè)面并存入索引文件中。如果你想利用 Lucene 來(lái)創(chuàng)建一個(gè) Web 搜索應(yīng)用程序,那么它的架構(gòu)也和上面所描述的類似,就如圖一中所示。
Figure 1. Web 搜索引擎架構(gòu)

利用 Lucene 實(shí)現(xiàn)高級(jí)搜索
Lucene 支持多種形式的高級(jí)搜索,我們?cè)谶@一部分中會(huì)進(jìn)行探討,然后我會(huì)使用 Lucene 的 API 來(lái)演示如何實(shí)現(xiàn)這些高級(jí)搜索功能。
布爾操作符
大多數(shù)的搜索引擎都會(huì)提供布爾操作符讓用戶可以組合查詢,典型的布爾操作符有 AND, OR, NOT。Lucene 支持 5 種布爾操作符,分別是 AND, OR, NOT, 加(+), 減(-)。接下來(lái)我會(huì)講述每個(gè)操作符的用法。
-
OR: 如果你要搜索含有字符 A 或者 B 的文檔,那么就需要使用 OR 操作符。需要記住的是,如果你只是簡(jiǎn)單的用空格將兩個(gè)關(guān)鍵詞分割開(kāi),其實(shí)在搜索的時(shí)候搜索引擎會(huì)自動(dòng)在兩個(gè)關(guān)鍵詞之間加上 OR 操作符。例如,“Java OR Lucene” 和 “Java Lucene” 都是搜索含有 Java 或者含有 Lucene 的文檔。
-
AND: 如果你需要搜索包含一個(gè)以上關(guān)鍵詞的文檔,那么就需要使用 AND 操作符。例如,“Java AND Lucene” 返回所有既包含 Java 又包含 Lucene 的文檔。
-
NOT: Not 操作符使得包含緊跟在 NOT 后面的關(guān)鍵詞的文檔不會(huì)被返回。例如,如果你想搜索所有含有 Java 但不含有 Lucene 的文檔,你可以使用查詢語(yǔ)句 “Java NOT Lucene”。但是你不能只對(duì)一個(gè)搜索詞使用這個(gè)操作符,比如,查詢語(yǔ)句 “NOT Java” 不會(huì)返回任何結(jié)果。
-
加號(hào)(+): 這個(gè)操作符的作用和 AND 差不多,但它只對(duì)緊跟著它的一個(gè)搜索詞起作用。例如,如果你想搜索一定包含 Java,但不一定包含 Lucene 的文檔,就可以使用查詢語(yǔ)句“+Java Lucene”。
-
減號(hào)(-): 這個(gè)操作符的功能和 NOT 一樣,查詢語(yǔ)句 “Java -Lucene” 返回所有包含 Java 但不包含 Lucene 的文檔。
接下來(lái)我們看一下如何利用 Lucene 提供的 API 來(lái)實(shí)現(xiàn)布爾查詢。清單1 顯示了如果利用布爾操作符進(jìn)行查詢的過(guò)程。
清單1:使用布爾操作符
//Test boolean operator
public void testOperator(String indexDirectory) throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
String[] searchWords = {"Java AND Lucene", "Java NOT Lucene", "Java OR Lucene",
"+Java +Lucene", "+Java -Lucene"};
Analyzer language = new StandardAnalyzer();
Query query;
for(int i = 0; i < searchWords.length; i++){
query = QueryParser.parse(searchWords[i], "title", language);
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results for query " + searchWords[i]);
}
}
|
域搜索(Field Search)
Lucene 支持域搜索,你可以指定一次查詢是在哪些域(Field)上進(jìn)行。例如,如果索引的文檔包含兩個(gè)域,Title 和 Content,你就可以使用查詢 “Title: Lucene AND Content: Java” 來(lái)返回所有在 Title 域上包含 Lucene 并且在 Content 域上包含 Java 的文檔。清單 2 顯示了如何利用 Lucene 的 API 來(lái)實(shí)現(xiàn)域搜索。
清單2:實(shí)現(xiàn)域搜索
//Test field search
public void testFieldSearch(String indexDirectory) throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
String searchWords = "title:Lucene AND content:Java";
Analyzer language = new StandardAnalyzer();
Query query = QueryParser.parse(searchWords, "title", language);
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results for query " + searchWords);
}
|
通配符搜索(Wildcard Search)
Lucene 支持兩種通配符:?jiǎn)柼?hào)(?)和星號(hào)(*)。你可以使用問(wèn)號(hào)(?)來(lái)進(jìn)行單字符的通配符查詢,或者利用星號(hào)(*)進(jìn)行多字符的通配符查詢。例如,如果你想搜索 tiny 或者 tony,你就可以使用查詢語(yǔ)句 “t?ny”;如果你想查詢 Teach, Teacher 和 Teaching,你就可以使用查詢語(yǔ)句 “Teach*”。清單3 顯示了通配符查詢的過(guò)程。
清單3:進(jìn)行通配符查詢
//Test wildcard search
public void testWildcardSearch(String indexDirectory)throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
String[] searchWords = {"tex*", "tex?", "?ex*"};
Query query;
for(int i = 0; i < searchWords.length; i++){
query = new WildcardQuery(new Term("title",searchWords[i]));
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results for query " + searchWords[i]);
}
}
|
模糊查詢
Lucene 提供的模糊查詢基于編輯距離算法(Edit distance algorithm)。你可以在搜索詞的尾部加上字符 ~ 來(lái)進(jìn)行模糊查詢。例如,查詢語(yǔ)句 “think~” 返回所有包含和 think 類似的關(guān)鍵詞的文檔。清單 4 顯示了如果利用 Lucene 的 API 進(jìn)行模糊查詢的代碼。
清單4:實(shí)現(xiàn)模糊查詢
//Test fuzzy search
public void testFuzzySearch(String indexDirectory)throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
String[] searchWords = {"text", "funny"};
Query query;
for(int i = 0; i < searchWords.length; i++){
query = new FuzzyQuery(new Term("title",searchWords[i]));
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results for query " + searchWords[i]);
}
}
|
范圍搜索(Range Search)
范圍搜索匹配某個(gè)域上的值在一定范圍的文檔。例如,查詢 “age:[18 TO 35]” 返回所有 age 域上的值在 18 到 35 之間的文檔。清單5顯示了利用 Lucene 的 API 進(jìn)行返回搜索的過(guò)程。
清單5:測(cè)試范圍搜索
//Test range search
public void testRangeSearch(String indexDirectory)throws Exception{
Directory dir = FSDirectory.getDirectory(indexDirectory,false);
IndexSearcher indexSearcher = new IndexSearcher(dir);
Term begin = new Term("birthDay","20000101");
Term end = new Term("birthDay","20060606");
Query query = new RangeQuery(begin,end,true);
Hits results = indexSearcher.search(query);
System.out.println(results.length() + "search results is returned");
}
|
在 Web 應(yīng)用程序中集成 Lucene
接下來(lái)我們開(kāi)發(fā)一個(gè) Web 應(yīng)用程序利用 Lucene 來(lái)檢索存放在文件服務(wù)器上的 HTML 文檔。在開(kāi)始之前,需要準(zhǔn)備如下環(huán)境:
- Eclipse 集成開(kāi)發(fā)環(huán)境
- Tomcat 5.0
- Lucene Library
- JDK 1.5
這個(gè)例子使用 Eclipse 進(jìn)行 Web 應(yīng)用程序的開(kāi)發(fā),最終這個(gè) Web 應(yīng)用程序跑在 Tomcat 5.0 上面。在準(zhǔn)備好開(kāi)發(fā)所必需的環(huán)境之后,我們接下來(lái)進(jìn)行 Web 應(yīng)用程序的開(kāi)發(fā)。
1、創(chuàng)建一個(gè)動(dòng)態(tài) Web 項(xiàng)目
- 在 Eclipse 里面,選擇 File > New > Project,然后再?gòu)棾龅拇翱谥羞x擇動(dòng)態(tài) Web 項(xiàng)目,如圖二所示。
圖二:創(chuàng)建動(dòng)態(tài)Web項(xiàng)目

- 在創(chuàng)建好動(dòng)態(tài) Web 項(xiàng)目之后,你會(huì)看到創(chuàng)建好的項(xiàng)目的結(jié)構(gòu),如圖三所示,項(xiàng)目的名稱為 sample.dw.paper.lucene。
圖三:動(dòng)態(tài) Web 項(xiàng)目的結(jié)構(gòu)

2. 設(shè)計(jì) Web 項(xiàng)目的架構(gòu)
在我們的設(shè)計(jì)中,把該系統(tǒng)分成如下四個(gè)子系統(tǒng):
-
用戶接口: 這個(gè)子系統(tǒng)提供用戶界面使用戶可以向 Web 應(yīng)用程序服務(wù)器提交搜索請(qǐng)求,然后搜索結(jié)果通過(guò)用戶接口來(lái)顯示出來(lái)。我們用一個(gè)名為 search.jsp 的頁(yè)面來(lái)實(shí)現(xiàn)該子系統(tǒng)。
-
請(qǐng)求管理器: 這個(gè)子系統(tǒng)管理從客戶端發(fā)送過(guò)來(lái)的搜索請(qǐng)求并把搜索請(qǐng)求分發(fā)到搜索子系統(tǒng)中。最后搜索結(jié)果從搜索子系統(tǒng)返回并最終發(fā)送到用戶接口子系統(tǒng)。我們使用一個(gè) Servlet 來(lái)實(shí)現(xiàn)這個(gè)子系統(tǒng)。
-
搜索子系統(tǒng): 這個(gè)子系統(tǒng)負(fù)責(zé)在索引文件上進(jìn)行搜索并把搜索結(jié)構(gòu)傳遞給請(qǐng)求管理器。我們使用 Lucene 提供的 API 來(lái)實(shí)現(xiàn)該子系統(tǒng)。
-
索引子系統(tǒng): 這個(gè)子系統(tǒng)用來(lái)為 HTML 頁(yè)面來(lái)創(chuàng)建索引。我們使用 Lucene 的 API 以及 Lucene 提供的一個(gè) HTML 解析器來(lái)創(chuàng)建該子系統(tǒng)。
圖4
顯示了我們?cè)O(shè)計(jì)的詳細(xì)信息,我們將用戶接口子系統(tǒng)放到 webContent 目錄下面。你會(huì)看到一個(gè)名為 search.jsp 的頁(yè)面在這個(gè)文件夾里面。請(qǐng)求管理子系統(tǒng)在包 sample.dw.paper.lucene.servlet 下面,類 SearchController 負(fù)責(zé)功能的實(shí)現(xiàn)。搜索子系統(tǒng)放在包 sample.dw.paper.lucene.search 當(dāng)中,它包含了兩個(gè)類,SearchManager 和 SearchResultBean,第一個(gè)類用來(lái)實(shí)現(xiàn)搜索功能,第二個(gè)類用來(lái)描述搜索結(jié)果的結(jié)構(gòu)。索引子系統(tǒng)放在包 sample.dw.paper.lucene.index 當(dāng)中。類 IndexManager 負(fù)責(zé)為 HTML 文件創(chuàng)建索引。該子系統(tǒng)利用包 sample.dw.paper.lucene.util 里面的類 HTMLDocParser 提供的方法 getTitle 和 getContent 來(lái)對(duì) HTML 頁(yè)面進(jìn)行解析。
圖四:項(xiàng)目的架構(gòu)設(shè)計(jì)

3. 子系統(tǒng)的實(shí)現(xiàn)
在分析了系統(tǒng)的架構(gòu)設(shè)計(jì)之后,我們接下來(lái)看系統(tǒng)實(shí)現(xiàn)的詳細(xì)信息。
-
用戶接口: 這個(gè)子系統(tǒng)有一個(gè)名為 search.jsp 的 JSP 文件來(lái)實(shí)現(xiàn),這個(gè) JSP 頁(yè)面包含兩個(gè)部分。第一部分提供了一個(gè)用戶接口去向 Web 應(yīng)用程序服務(wù)器提交搜索請(qǐng)求,如圖5所示。注意到這里的搜索請(qǐng)求發(fā)送到了一個(gè)名為 SearchController 的 Servlet 上面。Servlet 的名字和具體實(shí)現(xiàn)的類的對(duì)應(yīng)關(guān)系在 web.xml 里面指定。
圖5:向Web服務(wù)器提交搜索請(qǐng)求

這個(gè)JSP的第二部分負(fù)責(zé)顯示搜索結(jié)果給用戶,如圖6所示:
圖6:顯示搜索結(jié)果

-
請(qǐng)求管理器: 一個(gè)名為
SearchController 的 servlet 用來(lái)實(shí)現(xiàn)該子系統(tǒng)。清單6給出了這個(gè)類的源代碼。
清單6:請(qǐng)求管理器的實(shí)現(xiàn)
package sample.dw.paper.lucene.servlet;
import java.io.IOException;
import java.util.List;
import javax.servlet.RequestDispatcher;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import sample.dw.paper.lucene.search.SearchManager;
/**
* This servlet is used to deal with the search request
* and return the search results to the client
*/
public class SearchController extends HttpServlet{
private static final long serialVersionUID = 1L;
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
String searchWord = request.getParameter("searchWord");
SearchManager searchManager = new SearchManager(searchWord);
List searchResult = null;
searchResult = searchManager.search();
RequestDispatcher dispatcher = request.getRequestDispatcher("search.jsp");
request.setAttribute("searchResult",searchResult);
dispatcher.forward(request, response);
}
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException{
doPost(request, response);
}
}
|
在清單6中,doPost 方法從客戶端獲取搜索詞并創(chuàng)建類 SearchManager 的一個(gè)實(shí)例,其中類 SearchManager 在搜索子系統(tǒng)中進(jìn)行了定義。然后,SearchManager 的方法 search 會(huì)被調(diào)用。最后搜索結(jié)果被返回到客戶端。
-
搜索子系統(tǒng): 在這個(gè)子系統(tǒng)中,我們定義了兩個(gè)類:
SearchManager 和 SearchResultBean。第一個(gè)類用來(lái)實(shí)現(xiàn)搜索功能,第二個(gè)類是個(gè)JavaBean,用來(lái)描述搜索結(jié)果的結(jié)構(gòu)。清單7給出了類 SearchManager 的源代碼。
清單7:搜索功能的實(shí)現(xiàn)
package sample.dw.paper.lucene.search;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import sample.dw.paper.lucene.index.IndexManager;
/**
* This class is used to search the
* Lucene index and return search results
*/
public class SearchManager {
private String searchWord;
private IndexManager indexManager;
private Analyzer analyzer;
public SearchManager(String searchWord){
this.searchWord = searchWord;
this.indexManager = new IndexManager();
this.analyzer = new StandardAnalyzer();
}
/**
* do search
*/
public List search(){
List searchResult = new ArrayList();
if(false == indexManager.ifIndexExist()){
try {
if(false == indexManager.createIndex()){
return searchResult;
}
} catch (IOException e) {
e.printStackTrace();
return searchResult;
}
}
IndexSearcher indexSearcher = null;
try{
indexSearcher = new IndexSearcher(indexManager.getIndexDir());
}catch(IOException ioe){
ioe.printStackTrace();
}
QueryParser queryParser = new QueryParser("content",analyzer);
Query query = null;
try {
query = queryParser.parse(searchWord);
} catch (ParseException e) {
e.printStackTrace();
}
if(null != query >> null != indexSearcher){
try {
Hits hits = indexSearcher.search(query);
for(int i = 0; i < hits.length(); i ++){
SearchResultBean resultBean = new SearchResultBean();
resultBean.setHtmlPath(hits.doc(i).get("path"));
resultBean.setHtmlTitle(hits.doc(i).get("title"));
searchResult.add(resultBean);
}
} catch (IOException e) {
e.printStackTrace();
}
}
return searchResult;
}
}
|
在清單7中,注意到在這個(gè)類里面有三個(gè)私有屬性。第一個(gè)是 searchWord,代表了來(lái)自客戶端的搜索詞。第二個(gè)是 indexManager,代表了在索引子系統(tǒng)中定義的類 IndexManager 的一個(gè)實(shí)例。第三個(gè)是 analyzer,代表了用來(lái)解析搜索詞的解析器。現(xiàn)在我們把注意力放在方法 search 上面。這個(gè)方法首先檢查索引文件是否已經(jīng)存在,如果已經(jīng)存在,那么就在已經(jīng)存在的索引上進(jìn)行檢索,如果不存在,那么首先調(diào)用類 IndexManager 提供的方法來(lái)創(chuàng)建索引,然后在新創(chuàng)建的索引上進(jìn)行檢索。搜索結(jié)果返回后,這個(gè)方法從搜索結(jié)果中提取出需要的屬性并為每個(gè)搜索結(jié)果生成類 SearchResultBean 的一個(gè)實(shí)例。最后這些 SearchResultBean 的實(shí)例被放到一個(gè)列表里面并返回給請(qǐng)求管理器。
在類 SearchResultBean 中,含有兩個(gè)屬性,分別是 htmlPath 和 htmlTitle,以及這個(gè)兩個(gè)屬性的 get 和 set 方法。這也意味著我們的搜索結(jié)果包含兩個(gè)屬性:htmlPath 和 htmlTitle,其中 htmlPath 代表了 HTML 文件的路徑,htmlTitle 代表了 HTML 文件的標(biāo)題。
-
索引子系統(tǒng): 類
IndexManager 用來(lái)實(shí)現(xiàn)這個(gè)子系統(tǒng)。清單8 給出了這個(gè)類的源代碼。
清單8:索引子系統(tǒng)的實(shí)現(xiàn)
package sample.dw.paper.lucene.index;
import java.io.File;
import java.io.IOException;
import java.io.Reader;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import sample.dw.paper.lucene.util.HTMLDocParser;
/**
* This class is used to create an index for HTML files
*
*/
public class IndexManager {
//the directory that stores HTML files
private final String dataDir = "c:\\dataDir";
//the directory that is used to store a Lucene index
private final String indexDir = "c:\\indexDir";
/**
* create index
*/
public boolean createIndex() throws IOException{
if(true == ifIndexExist()){
return true;
}
File dir = new File(dataDir);
if(!dir.exists()){
return false;
}
File[] htmls = dir.listFiles();
Directory fsDirectory = FSDirectory.getDirectory(indexDir, true);
Analyzer analyzer = new StandardAnalyzer();
IndexWriter indexWriter = new IndexWriter(fsDirectory, analyzer, true);
for(int i = 0; i < htmls.length; i++){
String htmlPath = htmls[i].getAbsolutePath();
if(htmlPath.endsWith(".html") || htmlPath.endsWith(".htm")){
addDocument(htmlPath, indexWriter);
}
}
indexWriter.optimize();
indexWriter.close();
return true;
}
/**
* Add one document to the Lucene index
*/
public void addDocument(String htmlPath, IndexWriter indexWriter){
HTMLDocParser htmlParser = new HTMLDocParser(htmlPath);
String path = htmlParser.getPath();
String title = htmlParser.getTitle();
Reader content = htmlParser.getContent();
Document document = new Document();
document.add(new Field("path",path,Field.Store.YES,Field.Index.NO));
document.add(new Field("title",title,Field.Store.YES,Field.Index.TOKENIZED));
document.add(new Field("content",content));
try {
indexWriter.addDocument(document);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* judge if the index exists already
*/
public boolean ifIndexExist(){
File directory = new File(indexDir);
if(0 < directory.listFiles().length){
return true;
}else{
return false;
}
}
public String getDataDir(){
return this.dataDir;
}
public String getIndexDir(){
return this.indexDir;
}
}
|
這個(gè)類包含兩個(gè)私有屬性,分別是 dataDir 和 indexDir。dataDir 代表存放等待進(jìn)行索引的 HTML 頁(yè)面的路徑,indexDir 代表了存放 Lucene 索引文件的路徑。類 IndexManager 提供了三個(gè)方法,分別是 createIndex, addDocument 和 ifIndexExist。如果索引不存在的話,你可以使用方法 createIndex 去創(chuàng)建一個(gè)新的索引,用方法 addDocument 去向一個(gè)索引上添加文檔。在我們的場(chǎng)景中,一個(gè)文檔就是一個(gè) HTML 頁(yè)面。方法 addDocument 會(huì)調(diào)用由類 HTMLDocParser 提供的方法對(duì) HTML 文檔進(jìn)行解析。你可以使用最后一個(gè)方法 ifIndexExist 來(lái)判斷 Lucene 的索引是否已經(jīng)存在。
現(xiàn)在我們來(lái)看一下放在包 sample.dw.paper.lucene.util 里面的類 HTMLDocParser。這個(gè)類用來(lái)從 HTML 文件中提取出文本信息。這個(gè)類包含三個(gè)方法,分別是 getContent,getTitle 和 getPath。第一個(gè)方法返回去除了 HTML 標(biāo)記的文本內(nèi)容,第二個(gè)方法返回 HTML 文件的標(biāo)題,最后一個(gè)方法返回 HTML 文件的路徑。清單9 給出了這個(gè)類的源代碼。
清單9:HTML 解析器
package sample.dw.paper.lucene.util;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.io.UnsupportedEncodingException;
import org.apache.lucene.demo.html.HTMLParser;
public class HTMLDocParser {
private String htmlPath;
private HTMLParser htmlParser;
public HTMLDocParser(String htmlPath){
this.htmlPath = htmlPath;
initHtmlParser();
}
private void initHtmlParser(){
InputStream inputStream = null;
try {
inputStream = new FileInputStream(htmlPath);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
if(null != inputStream){
try {
htmlParser = new HTMLParser(new InputStreamReader(inputStream, "utf-8"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
}
public String getTitle(){
if(null != htmlParser){
try {
return htmlParser.getTitle();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return "";
}
public Reader getContent(){
if(null != htmlParser){
try {
return htmlParser.getReader();
} catch (IOException e) {
e.printStackTrace();
}
}
return null;
}
public String getPath(){
return this.htmlPath;
}
}
|
5.在 Tomcat 5.0 上運(yùn)行應(yīng)用程序
現(xiàn)在我們可以在 Tomcat 5.0 上運(yùn)行開(kāi)發(fā)好的應(yīng)用程序。
- 右鍵單擊 search.jsp,然后選擇 Run as > Run on Server,如圖7所示。
圖7:配置 Tomcat 5.0

- 在彈出的窗口中,選擇 Tomcat v5.0 Server 作為目標(biāo) Web 應(yīng)用程序服務(wù)器,然后點(diǎn)擊 Next,如圖8 所示:
圖8:選擇 Tomcat 5.0

- 現(xiàn)在需要指定用來(lái)運(yùn)行 Web 應(yīng)用程序的 Apache Tomcat 5.0 以及 JRE 的路徑。這里你所選擇的 JRE 的版本必須和你用來(lái)編譯 Java 文件的 JRE 的版本一致。配置好之后,點(diǎn)擊 Finish。如 圖9 所示。
圖9:完成Tomcat 5.0的配置

- 配置好之后,Tomcat 會(huì)自動(dòng)運(yùn)行,并且會(huì)對(duì) search.jsp 進(jìn)行編譯并顯示給用戶。如 圖10 所示。
圖10:用戶界面

- 在輸入框中輸入關(guān)鍵詞 “information” 然后單擊 Search 按鈕。然后這個(gè)頁(yè)面上會(huì)顯示出搜索結(jié)果來(lái),如 圖11 所示。
圖11:搜索結(jié)果

- 單擊搜索結(jié)果的第一個(gè)鏈接,頁(yè)面上就會(huì)顯示出所鏈接到的頁(yè)面的內(nèi)容。如 圖12 所示.
圖12:詳細(xì)信息

現(xiàn)在我們已經(jīng)成功的完成了示例項(xiàng)目的開(kāi)發(fā),并成功的用Lucene實(shí)現(xiàn)了搜索和索引功能。你可以下載這個(gè)項(xiàng)目的源代碼(下載)。
總結(jié)
Lucene 提供了靈活的接口使我們更加方便的設(shè)計(jì)我們的 Web 搜索應(yīng)用程序。如果你想在你的應(yīng)用程序中加入搜索功能,那么 Lucene 是一個(gè)很好的選擇。在設(shè)計(jì)你的下一個(gè)帶有搜索功能的應(yīng)用程序的時(shí)候可以考慮使用 Lucene 來(lái)提供搜索功能。