Java中文&編碼問題小結(jié)
笨笨
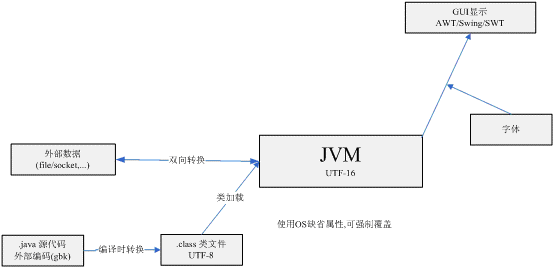
Java字符編碼轉(zhuǎn)換過程說明
常見問題
JVM
JVM啟動后,JVM會設(shè)置一些系統(tǒng)屬性以表明JVM的缺省區(qū)域。
user.language,user.region,file.encoding等。 可以使用System.getProperties()詳細查看所有的系統(tǒng)屬性。
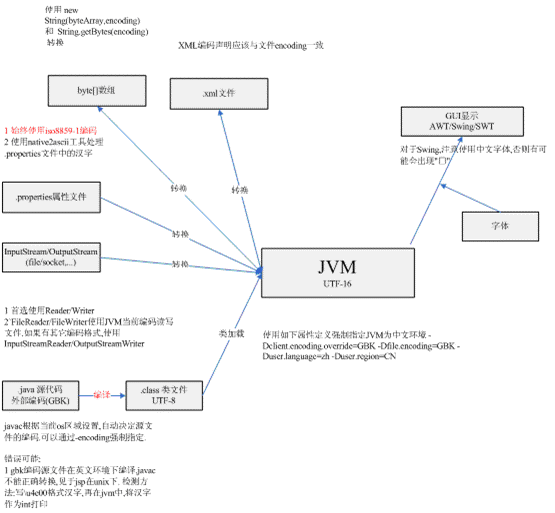
如在英文操作系統(tǒng)(如UNIX)下,可以使用如下屬性定義強制指定JVM為中文環(huán)境 -Dclient.encoding.override=GBK -Dfile.encoding=GBK -Duser.language=zh -Duser.region=CN
.java-->.class編譯
說明:一般javac根據(jù)當(dāng)前os區(qū)域設(shè)置,自動決定源文件的編碼.可以通過-encoding強制指定.
錯誤可能:
1 gbk編碼源文件在英文環(huán)境下編譯,javac不能正確轉(zhuǎn)換.曾見于java/jsp在英文unix下. 檢測方法:寫\u4e00格式的漢字,繞開javac編碼,再在jvm中,將漢字作為int打印,看值是否相等;或直接以UTF-8編碼打開.class文件,看看常量字符串是否正確保存漢字。
文件讀寫
外部數(shù)據(jù)如文件經(jīng)過讀寫和轉(zhuǎn)換兩個步驟,轉(zhuǎn)為jvm所使用字符。InputStream/OutputStream用于讀寫原始外部數(shù)據(jù),Reader/Writer執(zhí)行讀寫和轉(zhuǎn)換兩個步驟。
1 文件讀寫轉(zhuǎn)換由java.io.Reader/Writer執(zhí)行;輸入輸出流 InputStream/OutputStream 處理漢字不合適,應(yīng)該首選使用Reader/Writer,如 FileReader/FileWriter。
2 FileReader/FileWriter使用JVM當(dāng)前編碼讀寫文件.如果有其它編碼格式,使用InputStreamReader/OutputStreamWriter
3 PrintStream有點特殊,它自動使用jvm缺省編碼進行轉(zhuǎn)換。
讀取.properties文件
.propeties文件由Properties類以iso8859-1編碼讀取,因此不能在其中直接寫漢字,需要使用JDK 的native2ascii工具轉(zhuǎn)換漢字為\uXXXX格式。命令行:native2ascii –encoding GBK inputfile outputfile
讀取XML文件
1 XML文件讀寫同于文件讀寫,但應(yīng)注意確保XML頭中聲明如<? xml version=”1.0” encoding=”gb2312” ?>與文件編碼保持一致。
2 javax.xml.SAXParser類接受InputStream作為輸入?yún)?shù),對于Reader,需要用org.xml.sax.InputSource包裝一下,再給SAXParser。
3 對于UTF-8編碼 XML,注意防止編輯器自動加上\uFFFE BOM頭, xml parser會報告content is not allowed in prolog。
字節(jié)數(shù)組
1 使用 new String(byteArray,encoding) 和 String.getBytes(encoding) 在字節(jié)數(shù)組和字符串之間進行轉(zhuǎn)換
也可以用ByteArrayInputStream/ByteArrayOutputStream轉(zhuǎn)為流后再用InputStreamReader/OutputStreamWriter轉(zhuǎn)換。
錯誤編碼的字符串(iso8859-1轉(zhuǎn)碼gbk)
如果我們得到的字符串是由錯誤的轉(zhuǎn)碼方式產(chǎn)生的,例如:對于gbk中文,由iso8859-1方式轉(zhuǎn)換,此時如果用調(diào)試器看到的字符串一般是 的樣子,長度一般為文本的字節(jié)長度,而非漢字個數(shù)。
可以采用如下方式轉(zhuǎn)為正確的中文:
text = new String( text.getBytes(“iso8859-1”),”gbk”);
JDBC
轉(zhuǎn)換過程由JDBC Driver執(zhí)行,取決于各JDBC數(shù)據(jù)庫實現(xiàn)。對此經(jīng)驗尚積累不夠。
1 對于ORACLE數(shù)據(jù)庫,需要數(shù)據(jù)庫創(chuàng)建時指定編碼方式為gbk,否則會出現(xiàn)漢字轉(zhuǎn)碼錯誤
2 對于 SQL Server 2000 ,最好以nvarchar/nchar類型存放文本,即不存在中文/編碼轉(zhuǎn)換問題。
3 連接 Mysql,將 connectionString 設(shè)置成 encoding 為 gb2312:
String connectionString = "jdbc:mysql://localhost/test?useUnicode=true&characterEncoding=gb2312";
WEB/Servlet/JSP
1 對于JSP,確定頭部加上 <%@ page contentType="text/html;charset=gb2312"%>這樣的標(biāo)簽。
2 對于Servlet,確定 設(shè)置setContentType (“text/html; charset=gb2312”),以上兩條用于使得輸出漢字沒有問題。
3 為輸出HTML head中加一個 <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> ,讓瀏覽器正確確定HTML編碼。
4 為Web應(yīng)用加一個Filter,確保每個Request明確調(diào)用setCharacterEncoding方法,讓輸入漢字能夠正確解析。
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.UnavailableException;
import javax.servlet.http.HttpServletRequest;
/**
* Example filter that sets the character encoding to be used in parsing the
* incoming request
*/
public class SetCharacterEncodingFilter
implements Filter {
public SetCharacterEncodingFilter()
{}
protected boolean debug = false;
protected String encoding = null;
protected FilterConfig filterConfig = null;
public void destroy() {
this.encoding = null;
this.filterConfig = null;
}
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
// if (request.getCharacterEncoding() == null)
// {
// String encoding = getEncoding();
// if (encoding != null)
// request.setCharacterEncoding(encoding);
//
// }
request.setCharacterEncoding(encoding);
if ( debug ){
System.out.println( ((HttpServletRequest)request).getRequestURI()+"setted to "+encoding );
}
chain.doFilter(request, response);
}
public void init(FilterConfig filterConfig) throws ServletException {
this.filterConfig = filterConfig;
this.encoding = filterConfig.getInitParameter("encoding");
this.debug = "true".equalsIgnoreCase( filterConfig.getInitParameter("debug") );
}
protected String getEncoding() {
return (this.encoding);
}
}
web.xml中加入:
<filter>
<filter-name>LocalEncodingFilter</filter-name>
<display-name>LocalEncodingFilter</display-name>
<filter-class>com.ccb.ectipmanager.request.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>gb2312</param-value>
</init-param>
<init-param>
<param-name>debug</param-name>
<param-value>false</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>LocalEncodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
5 用于Weblogic(vedor-specific):
其一:在web.xml里加上如下腳本:
<context-param>
<param-name>weblogic.httpd.inputCharset./*</param-name>
<param-value>GBK</param-value>
</context-param>
其二(可選)在weblogic.xml里加上如下腳本:
<charset-params>
<input-charset>
<resource-path>/*</resource-path>
<java-charset-name>GBK</java-charset-name>
</input-charset>
</charset-params>
SWING/AWT/SWT
對于SWING/AWT,Java會有些缺省字體如Dialog/San Serif,這些字體到系統(tǒng)真實字體的映射在$JRE_HOME/lib/font.properties.XXX文件中指定。排除字體顯示問題時,首先需要確定JVM的區(qū)域為zh_CN,這樣font.properties.zh_CN文件才會發(fā)生作用。對于 font.properties.zh_CN , 需要檢查是否映射缺省字體到中文字體如宋體。
在Swing中,Java自行解釋TTF字體,渲染顯示;對于AWT,SWT顯示部分交由操作系統(tǒng)。首先需要確定系統(tǒng)裝有中文字體。
1 漢字顯示為”□”,一般為顯示字體沒有使用中文字體,因為Java對于當(dāng)前字體顯示不了的字符,不會像Windows一樣再采用缺省字體顯示。
2 部分不常見漢字不能顯示,一般為顯示字庫中漢字不全,可以換另外的中文字體試試。
3 對于AWT/SWT,首先確定JVM運行環(huán)境的區(qū)域設(shè)置為中文,因為此處設(shè)計JVM與操作系統(tǒng)api調(diào)用的轉(zhuǎn)換問題,再檢查其它問題。
JNI
JNI中jstring以UTF-8編碼給我們,需要我們自行轉(zhuǎn)為本地編碼。對于Windows,可以采用WideCharToMultiByte/MultiByteToWideChar函數(shù)進行轉(zhuǎn)換,對于Unix,可以采用iconv庫。
這里從SUN jdk 1.4 源代碼中找到一段使用jvm String 對象的getBytes的轉(zhuǎn)換方式,相對簡單和跨平臺,不需要第三方庫,但速度稍慢。函數(shù)原型如下:
/* Convert between Java strings and i18n C strings */
JNIEXPORT jstring
NewStringPlatform(JNIEnv *env, const char *str);
JNIEXPORT const char *
GetStringPlatformChars(JNIEnv *env, jstring jstr, jboolean *isCopy);
JNIEXPORT jstring JNICALL
JNU_NewStringPlatform(JNIEnv *env, const char *str);
JNIEXPORT const char * JNICALL
JNU_GetStringPlatformChars(JNIEnv *env, jstring jstr, jboolean *isCopy);
JNIEXPORT void JNICALL
JNU_ReleaseStringPlatformChars(JNIEnv *env, jstring jstr, const char *str);
附件jni_util.h,jni_util.c
TUXEDO/JOLT
JOLT對于傳遞的字符串需要用如下進行轉(zhuǎn)碼
new String(ls_tt.getBytes("GBK"),"iso8859-1")
對于返回的字符串
new String(error_message.getBytes("iso8859-1"),"GBK");
jolt 的系統(tǒng)屬性 bea.jolt.encoding不應(yīng)該設(shè)置,如果設(shè)置,JSH會報告說錯誤的協(xié)議.
JDK1.4/1.5新增部分
字符集相關(guān)類(Charset/CharsetEncoder/CharsetDecoder)
jdk1.4開始,對字符集的支持在java.nio.charset包中實現(xiàn)。
常用功能:
1 列出jvm所支持字符集:Charset.availableCharsets()
2 能否對看某個Unicode字符編碼,CharsetEncoder.canEncode()
Unicode Surrogate/CJK EXT B
Unicode 范圍一般所用為\U0000-\UFFFF范圍,jvm使用1個char就可以表示,對于CJK EXT B區(qū)漢字,范圍大于\U20000,則需要采用2個char方能表示,此即Unicode Surrogate。這2個char的值范圍 落在Character.SURROGATE 區(qū)域內(nèi),用Character.getType()來判斷。
jdk 1.4尚不能在Swing中正確處理surrogate區(qū)的Unicode字符,jdk1.5可以。對于CJK EXT B區(qū)漢字,目前可以使用的字庫為”宋體-方正超大字符集”,隨Office安裝。
常見問題
在JVM下,用System.out.println不能正確打印中文,顯示為???
System.out.println是PrintStream,它采用jvm缺省字符集進行轉(zhuǎn)碼工作,如果jvm的缺省字符集為iso8859-1,則中文顯示會有問題。此問題常見于Unix下,jvm的區(qū)域沒有明確指定的情況。
在英文UNIX環(huán)境下,用System.out.println能夠正確打印漢字,但是內(nèi)部處理錯誤
可能是漢字在輸入轉(zhuǎn)換時,就沒有正確轉(zhuǎn)碼:
即gbk文本à(iso8859-1轉(zhuǎn)碼)àjvm char(iso8859-1編碼漢字)à (iso8859-1轉(zhuǎn)碼)à輸出。
gbk漢字經(jīng)過兩次錯誤轉(zhuǎn)碼,原封不動的被傳遞到輸出,但是在jvm中,并未以正確的unicode編碼表示,而是以一個漢字字節(jié)一個char的方式表示,從而導(dǎo)致此類錯誤。
GB2312-80,GBK,GB18030-2000 漢字字符集
GB2312-80 是在國內(nèi)計算機漢字信息技術(shù)發(fā)展初始階段制定的,其中包含了大部分常用的一、二級漢字,和 9 區(qū)的符號。該字符集是幾乎所有的中文系統(tǒng)和國際化的軟件都支持的中文字符集,這也是最基本的中文字符集。其編碼范圍是高位0xa1-0xfe,低位也是 0xa1-0xfe;漢字從 0xb0a1 開始,結(jié)束于 0xf7fe;
GBK 是 GB2312-80 的擴展,是向上兼容的。它包含了 20902 個漢字,其編碼范圍是 0x8140-0xfefe,剔除高位 0x80 的字位。其所有字符都可以一對一映射到 Unicode 2.0,也就是說 JAVA 實際上提供了 GBK 字符集的支持。這是現(xiàn)階段 Windows 和其它一些中文操作系統(tǒng)的缺省字符集,但并不是所有的國際化軟件都支持該字符集,感覺是他們并不完全知道 GBK 是怎么回事。值得注意的是它不是國家標(biāo)準(zhǔn),而只是規(guī)范。隨著 GB18030-2000國標(biāo)的發(fā)布,它將在不久的將來完成它的歷史使命。
GB18030-2000(GBK2K) 在 GBK 的基礎(chǔ)上進一步擴展了漢字,增加了藏、蒙等少數(shù)民族的字形。GBK2K 從根本上解決了字位不夠,字形不足的問題。它有幾個特點,
它并沒有確定所有的字形,只是規(guī)定了編碼范圍,留待以后擴充。
編碼是變長的,其二字節(jié)部分與 GBK 兼容;四字節(jié)部分是擴充的字形、字位,其編碼范圍是首字節(jié) 0x81-0xfe、二字節(jié)0x30-0x39、三字節(jié) 0x81-0xfe、四字節(jié)0x30-0x39。
UTF-8/UTF-16/UTF-32
UTF,即Unicode Transformer Format,是Unicode代碼點(code point)的實際表示方式,按其基本長度所用位數(shù)分為UTF-8/16/32。它也可以認為是一種特殊的外部數(shù)據(jù)編碼,但能夠與Unicode代碼點做一一對應(yīng)。
UTF-8是變長編碼,每個Unicode代碼點按照不同范圍,可以有1-3字節(jié)的不同長度。
UTF-16長度相對固定,只要不處理大于\U200000范圍的字符,每個Unicode代碼點使用16位即2字節(jié)表示,超出部分使用兩個UTF-16即4字節(jié)表示。按照高低位字節(jié)順序,又分為UTF-16BE/UTF-16LE。
UTF-32長度始終固定,每個Unicode代碼點使用32位即4字節(jié)表示。按照高低位字節(jié)順序,又分為UTF-32BE/UTF-32LE。
UTF編碼有個優(yōu)點,即盡管編碼字節(jié)數(shù)不等,但是不像gb2312/gbk編碼一樣,需要從文本開始尋找,才能正確對漢字進行定位。在UTF編碼下,根據(jù)相對固定的算法,從當(dāng)前位置就能夠知道當(dāng)前字節(jié)是否是一個代碼點的開始還是結(jié)束,從而相對簡單的進行字符定位。不過定位問題最簡單的還是UTF-32,它根本不需要進行字符定位,但是相對的大小也增加不少。
關(guān)于GCJ JVM
GCJ并未完全依照sun jdk的做法,對于區(qū)域和編碼問題考慮尚不夠周全。GCJ啟動時,區(qū)域始終設(shè)為en_US,編碼也缺省為iso8859-1。但是可以用Reader/Writer做正確編碼轉(zhuǎn)換。