在JBoss Rules 學習(一):什么是Rule中�����,我們介紹了JBoss Rules中對Rule的表示�,其中提到了JBoss Rule中主要采用的RETE算法來進行規則匹配�����。下面將詳細的介紹一下RETE算法在JBoss Rule中的實現���,最后隨便提一下JBoss Rules中也可以使用的另一種規則匹配算法Leaps。
1.Rete
算法
:
Rete
在拉丁語中是
”net”
�,有網絡的意思���。
RETE
算法可以分為兩部分:規則編譯(
rule compilation
)和運行時執行(
runtime execution
)��。
編譯算法描述了規則如何在
Production
Memory
中產生一個有效的辨別網絡���。用一個非技術性的詞來說���,一個辨別網絡就是用來過濾數據��。方法是通過數據在網絡中的傳播來過濾數據��。在頂端節點將會有很多匹配的數據。當我們順著網絡向下走�,匹配的數據將會越來越少��。在網絡的最底部是終端節點(
terminal nodes
)��。在
Dr Forgy
的
1982
年的論文中�����,他描述了
4
種基本節點:
root , 1-input, 2-input and
terminal
。下圖是
Drools
中的
RETE
節點類型:
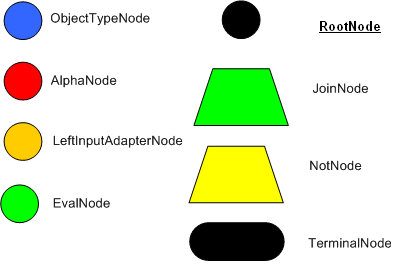
?
Figure 1.
Rete Nodes
根節點(
RootNode
)是所有的對象進入網絡的入口����。然后�����,從根節點立即進入到
ObjectTypeNode
。
ObjectTypeNode
的作用是使引擎只做它需要做的事情�。例如�����,我們有兩個對象集:
Account
和
Order
。如果規則引擎需要對每個對象都進行一個周期的評估��,那會浪費很多的時間�。為了提高效率,引擎將只讓匹配
object type
的對象通過到達節點��。通過這種方法�����,如果一個應用
assert
一個新的
account
���,它不會將
Order
對象傳遞到節點中���。很多現代
RETE
實現都有專門的
ObjectTypeNode
。在一些情況下,
ObjectTypeNode
被用散列法進一步優化�����。
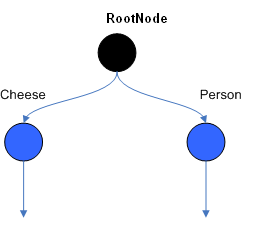
Figure 2 .?ObjectTypeNodes
ObjectTypeNode
能夠傳播到
AlphaNodes,
LeftInputAdapterNodes
和
BetaNodes
���。
1-input
節點通常被稱為
AlphaNode
���。
AlphaNodes
被用來評估字面條件(
literal conditions
)�。雖然,
1982
年的論文只提到了相等條件(指的字面上相等)���,很多
RETE
實現支持其他的操作���。例如�,
Account.name
= = “Mr Trout”
是一個字面條件��。當一條規則對于一種
object type
有多條的字面條件���,這些字面條件將被鏈接在一起��。這是說,如果一個應用
assert
一個
account
對象��,在它能到達下一個
AlphaNode
之前��,它必須先滿足第一個字面條件�����。在
Dr. Forgy
的論文中,他用
IntraElement conditions
來表述���。下面的圖說明了
Cheese
的
AlphaNode
組合(
name = = “cheddar”
,
strength = = “strong”
):

Figure 3.?AlphaNodes
Drools
通過散列法優化了從
ObjectTypeNode
到
AlphaNode
的傳播。每次一個
AlphaNode
被加到一個
ObjectTypeNode
的時候,就以字面值(
literal value
)作為
key
,以
AlphaNode
作為
value
加入
HashMap
��。當一個新的實例進入
ObjectTypeNode
的時候��,不用傳遞到每一個
AlphaNode
,它可以直接從
HashMap
中獲得正確的
AlphaNode
���,避免了不必要的字面檢查。
2-input
節點通常被稱為
BetaNode
����。
Drools
中有兩種
BetaNode
:
JoinNode
和
NotNode
��。
BetaNodes
被用來對
2
個對象進行對比。這兩個對象可以是同種類型,也可以是不同類型��。
我們約定
BetaNodes
的
2
個輸入稱為左邊(
left
)和右邊(
right
)��。一個
BetaNode
的左邊輸入通常是
a list of objects
��。在
Drools
中,這是一個數組。右邊輸入是
a single object
�����。兩個
NotNode
可以完成‘
exists
’檢查���。
Drools
通過將索引應用在
BetaNodes
上擴展了
RETE
算法����。下圖展示了一個
JoinNode
的使用:

Figure 4 .?JoinNode
注意到圖中的左邊輸入用到了一個
LeftInputAdapterNode
,這個節點的作用是將一個
single Object
轉化為一個單對象數組(
single Object Tuple
)��,傳播到
JoinNode
節點�����。因為我們上面提到過左邊輸入通常是
a list of objects
�����。
Terminal nodes
被用來表明一條規則已經匹配了它的所有條件(
conditions
)���。
在這點�,我們說這條規則有了一個完全匹配(
full match
)。在一些情況下��,一條帶有“或”條件的規則可以有超過一個的
terminal node
��。
Drools
通過節點的共享來提高規則引擎的性能��。因為很多的規則可能存在部分相同的模式,節點的共享允許我們對內存中的節點數量進行壓縮�,以提供遍歷節點的過程�����。下面的兩個規則就共享了部分節點:
rule
????when
????????Cheese(?$chedddar?:?name?
==
?
"
cheddar
"
?)
????????$person?:?Person(?favouriteCheese?
==
?$cheddar?)
????then
????????System.out.println(?$person.getName()?
+
?
"
?likes?cheddar
"
?);
end
rule
????when
????????Cheese(?$chedddar?:?name?
==
?
"
cheddar
"
?)
????????$person?:?Person(?favouriteCheese?
!=
?$cheddar?)
????then
????????System.out.println(?$person.getName()?
+
?
"
?does?likes?cheddar
"
?);
end
這里我們先不探討這兩條
rule
到的是什么意思,單從一個直觀的感覺�����,這兩條
rule
在它們的
LHS
中基本都是一樣的,只是最后的
favouriteCheese
�����,一條規則是等于
$cheddar
����,而另一條規則是不等于
$cheddar
。下面是這兩條規則的節點圖:

Figure 5 .?Node
Sharing
從圖上可以看到��,編譯后的
RETE
網絡中�����,
AlphaNode
是共享的,而
BetaNode
不是共享的�����。上面說的相等和不相等就體現在
BetaNode
的不同�。然后這兩條規則有各自的
Terminal Node
。
RETE
算法的第二個部分是運行時(
runtime
)��。當一個應用
assert
一個對象�,引擎將數據傳遞到
root
node
。從那里�����,它進入
ObjectTypeNode
并沿著網絡向下傳播�����。當數據匹配一個節點的條件���,節點就將它記錄到相應的內存中�����。這樣做的原因有以下幾點:主要的原因是可以帶來更快的性能。雖然記住完全或部分匹配的對象需要內存�,它提供了速度和可伸縮性的特點���。當一條規則的所有條件都滿足����,這就是完全匹配���。而只有部分條件滿足���,就是部分匹配�。(我覺得引擎在每個節點都有其對應的內存來儲存滿足該節點條件的對象���,這就造成了如果一個對象是完全匹配����,那這個對象就會在每個節點的對應內存中都存有其映象。)
2. Leaps
算法:
Production systems
的
Leaps
算法使用了一種“
lazy
”方法來評估條件(
conditions
)。一種
Leaps
算法的修改版本的實現,作為
Drools v3
的一部分�����,嘗試結合
Leaps
和
RETE
方法的最好的特點來處理
Working Memory
中的
facts
���。
古典的
Leaps
方法將所有的
asserted
的
facts
�����,按照其被
asserted
在
Working Memory
中的順序(
FIFO
)���,放在主堆棧中�����。它一個個的檢查
facts
�,通過迭代匹配
data
type
的
facts
集合來找出每一個相關規則的匹配�。當一個匹配的數據被發現時,系統記住此時的迭代位置以備待會的繼續迭代,并且激發規則結果(
consequence
)�。當結果(
consequence
)執行完成以后�����,系統就會繼續處理處于主堆棧頂部的
fact
�����。如此反復��。