啟示一:String和StringBuffer的不同之處
相信大家都知道String和StringBuffer之間是有區別的,但究竟它們之間到底區別在哪里?我們就再本小節中一探究竟,看看能給我們些什么啟示。還是剛才那個程序,我們把它改一改,將本程序中的String進行無限次的累加,看看什么時候拋出內存超限的異常,程序如下所示:
public class MemoryTest{
public static void main(String args[]){
String s="abcdefghijklmnop";
System.out.print("當前虛擬機最大可用內存為:");
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.print("循環前,虛擬機已占用內存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
int count = 0;
while(true){
try{
s+=s;
count++;
}
catch(Error o){
System.out.println("循環次數:"+count);
System.out.println("String實際字節數:"+s.length()/1024/1024+"M");
System.out.print("循環后,已占用內存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
System.out.println("Catch到的錯誤:"+o);
break;
}
}
}
}
|
程序運行后,果然不一會兒的功夫就報出了異常,如圖
3 3所示。
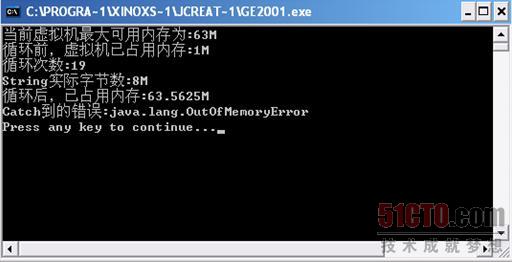
我們注意到,在String的實際字節數只有8M的情況下,循環后已占內存數竟然已經達到了63.56M。這說明,String這個對象的實際占用內存數量與其自身的字節數不相符。于是,在循環19次的時候就已經報"OutOfMemoryError"的錯誤了。
因此,應該少用String這東西,特別是
String的"+="操作,不僅原來的String對象不能繼續使用,而且又要產生多個新對象,因此會較高的占用內存。
所以必須要改用StringBuffer來實現相應目的,下面是改用StringBuffer來做一下測試:
public class MemoryTest{
public static void main(String args[]){
StringBuffer s=new StringBuffer("abcdefghijklmnop");
System.out.print("當前虛擬機最大可用內存為:");
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.print("循環前,虛擬機已占用內存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
int count = 0;
while(true){
try{
s.append(s);
count++;
}
catch(Error o){
System.out.println("循環次數:"+count);
System.out.println("String實際字節數:"+s.length()/1024/1024+"M");
System.out.println("循環后,已占用內存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
System.out.println("Catch到的錯誤:"+o);
break;
}
}
}
}
|
我們將String改為StringBuffer以后,在運行時得到了如下結果,如圖
3 4所示。
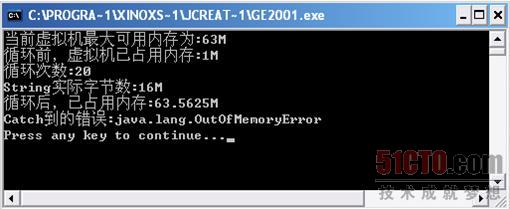
這次我們發現,當StringBuffer所占用的實際字節數為"16M"的時候才產生溢出,整整比上一個程序的String實際字節數"8M"多了一倍。
啟示2:用"-Xmx"參數來提高內存可控制量
前面我們介紹過"-Xmx"這個參數的用法,如果我們還是處理剛才的那個用StringBuffer的Java程序,我們用"-Xmx1024m"來啟動它,看看它的循環次數有什么變化。
輸入如下指令:
得到結果如圖 3 5所示。
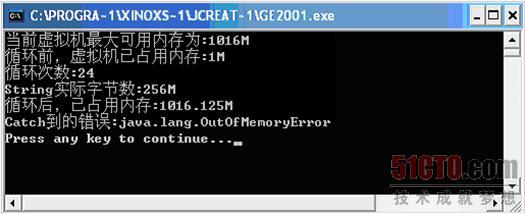
那么通過使用"-Xmx"參數將其可控內存量擴大至1024M后,那么這個程序到了1G的時候才內存超限,從而使內存的可控性提高了。
但擴大內存使用量永遠不是最終的解決方案,如果你的程序沒有去更加的優化,早晚還是會超限的。
啟示3:二維數組比一維數組占用更多內存空間
對于內存占用的問題還有一個地方值得我們注意,就是二維數組的內存占用問題。
有時候我們一廂情愿的認為:
二維數組的占用內存空間多無非就是二維數組的實際數組元素數比一維數組多而已,那么二維數組的所占空間,一定是實際申請的元素數而已。
但是,事實上并不是這樣的,對于一個二維數組而言,它所占用的內存空間要遠遠大于它開辟的數組元素數。下面我們來看一個一維數組程序的例子:
public class MemFor{
public static void main (String[] args) {
try{
int len=1024*1024*2; //設定循環次數
byte [] abc=new byte[len];
for (int i=0;i<len;i++){
abc[i]=(byte)i;
}
System.out.print("已占用內存:");
System.out.println(
Runtime.getRuntime().totalMemory()/1024/1024+"M");
}
catch(Error e){
}
}
}
|
這個程序是開辟了"1024*1024*2"即2M的數組元素的一維數組,運行這個程序得到的結果如圖
3 6所示,程序運行結果提示"已占用內存:3M"。
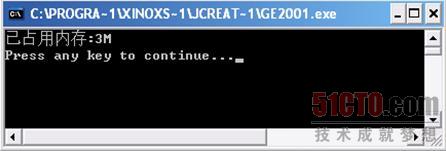
我們再將這個程序進行修改,改為一個二維數組,這個二維數組的元素數量我們也盡量的和上一個一維數組的元素數量保持一致。
public class MemFor{
public static void main (String[] args) {
try{
int len=1024*1024; //設定循環次數
byte [][] abc=new byte[len][2];
for (int i=0;i<len;i++){
abc[i][0]=(byte)i;
abc[i][1]=(byte)i;
}
System.out.print("已占用內存:");
System.out.println(
Runtime.getRuntime().totalMemory()/1024/1024+"M");
}
catch(Error e){
}
}
}
|
當我們把申請的元素數量未變,只是將二維數組的行數定為"1024*1024"列數定為"2",和剛才的那個一維數組"1024*1024*2"的數量完全一致,但我們得到的運算結果如圖
3 7所示,竟然占用達到了29M的空間。
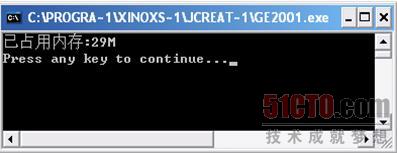
我們姑且不管造成這種情況的原因,我們只要知道一點就夠了,那就是"二維數組占內存"。所以,在編寫程序的時候要注意,能不用二維數組的地方盡量用一維數組,要求內存占用小的地方盡量用一維數組。
4.4.4 啟示4:用HashMap提高內存查詢速度
田富鵬主編的《大學計算機應用基礎》中是這樣描述內存的:
……
DRAM:即內存條。常說的內存并不是內部存儲器,而是DRAM。
……CPU的運行速度很快,而外部存儲器的讀取速度相對來說就很慢,如果CPU需要用到的數據總是從外部存儲器中讀取,由于外部設備很慢,……,CPU可能用到的數據預先讀到DRAM中,CPU產生的臨時數據也暫時存放在DRAM中,這樣的結果是大大的提高了CPU的利用率和計算機運行速度。
……
這是一個典型計算機基礎教材針對內存的描述,也許作為計算機專業的程序員對這段描述并不陌生。但也因為這段描述,而對內存的處理速度有神話的理解,認為內存中的處理速度是非常快的。
以使持有這種觀點的程序員遇到一個巨型的內存查詢循環的較長時間時,而束手無策了。
請看一下如下程序:
public class MemFor{
public static void main (String[] args) {
long start=System.currentTimeMillis(); //取得當前時間
int len=1024*1024*3; //設定循環次數
int [][] abc=new int[len][2];
for (int i=0;i<len;i++){
abc[i][0]=i;
abc[i][1]=(i+1);
}
long get=System.currentTimeMillis(); //取得當前時間
//循環將想要的數值取出來,本程序取數組的最后一個值
for (int i=0;i<len;i++){
if ((int)abc[i][0]==(1024*1024*3-1)){
System.out.println("取值結果:"+abc[i][1]);
}
}
long end=System.currentTimeMillis(); //取得當前時間
//輸出測試結果
System.out.println("賦值循環時間:"+(get-start)+"ms");
System.out.println("獲取循環時間:"+(end-get)+"ms");
System.out.print("Java可控內存:");
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.print("已占用內存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
}
}
|
運行這個程序:
程序的運行結果如下:
取值結果:3145728
賦值循環時間:2464ms
獲取循環時間:70ms
Java可控內存:1016M
已占用內存:128M
我們發現,這個程序循環了3145728次獲得想要的結果,循環獲取數值的時間用了70毫秒。
你覺得快嗎?
是啊,70毫秒雖然小于1秒鐘,但是如果你不得不在這個循環外面再套一個循環,即使外層嵌套的循環只有100次,那么,想想看是多少毫秒呢?
回答:70毫秒*100=7000毫秒=7秒
如果,循環1000次呢?
70秒!
70秒的運行時間對于這個程序來說就是災難了。
面對這個程序的運行時間很多程序員已經束手無策了,其實,Java給程序員們提供了一個較快的查詢方法--哈希表查詢。
我們將這個程序用"HashMap"來改造一下,再看看運行結果:
import java.util.*;
public class HashMapTest{
public static void main (String[] args) {
HashMap has=new HashMap();
int len=1024*1024*3;
long start=System.currentTimeMillis();
for (int i=0;i<len;i++){
has.put(""+i,""+i);
}
long end=System.currentTimeMillis();
System.out.println("取值結果:"+has.get(""+(1024*1024*3-1)));
long end2=System.currentTimeMillis();
System.out.println("賦值循環時間:"+(end-start)+"ms");
System.out.println("獲取循環時間:"+(end2-end)+"ms");
System.out.print("Java可控內存:");
System.out.println(Runtime.getRuntime().maxMemory()/1024/1024+"M");
System.out.print("已占用內存:");
System.out.println(Runtime.getRuntime().totalMemory()/1024/1024+"M");
}
}
|
運行這個程序:
java -Xmx1024m HashMapTest
|
程序的運行結果如下:
取之結果:3145727
賦值循環時間:16454ms
獲取循環時間:0ms
Java可控內存:1016M
已占用內存:566M
那么現在用HashMap來取值的時間竟然不到1ms,這時我們的程序的效率明顯提高了,看來用哈希表進行內存中的數據搜索速度確實很快。
在提高數據搜索速度的同時也要注意到,賦值時間的差異和內存占用的差異。
賦值循環時間:
HashMap:16454ms
普通數組:2464ms
占用內存:
HashMap:566M
普通數組:128M
因此,可以看出HashMap在初始化以及內存占用方面都要高于普通數組,如果僅僅是為了數據存儲,用普通數組是比較適合的,但是,如果為了頻繁查詢的目的,HashMap是必然的選擇。
啟示5:用"arrayCopy()"提高數組截取速度
當我們需要處理一個大的數組應用時往往需要對數組進行大面積截取與復制操作,比如針對圖形顯示的應用時單純的通過對數組元素的處理操作有時捉襟見肘。
提高數組處理速度的一個很好的方法是"System.arrayCopy()",這個方法可以提高數組的截取速度,我們可以做一個對比試驗。
例如我們用普通的數組賦值方法來處理程序如下:
public class arraycopyTest1{
public static void main( String[] args ){
String temp="abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz";
char[] oldArray=temp.toCharArray();
char[] newArray=null;
long start=0L;
newArray=new char[length];
//開始時間記錄
start=System.currentTimeMillis();
for(int i=0;i<10000000;i++){
for(int j=0;j<length;j++){
newArray[j]=oldArray[begin+j];
}
}
//打印總用時間
System.out.println(System.currentTimeMillis()-start+"ms");
}
}
|
程序運行結果如圖 3 8所示。
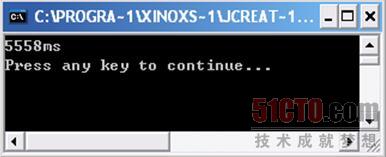
那么下面我們再用arrayCopy()的方法試驗一下:
public final class arraycopyTest2{
public static void main( String[] args ){
String temp="abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
+"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz";
char[] oldArray=temp.toCharArray();
char[] newArray=null;
long start=0L;
newArray=new char[length];
//記錄開始時間
start=System.currentTimeMillis();
for(int i=0;i<10000000;i++ ){
System.arraycopy(oldArray,100,newArray,0,120);
}
//打印總用時間
System.out.println((System.currentTimeMillis()-start)+"ms");
}
}
|
程序運行結果如圖 3 9所示。
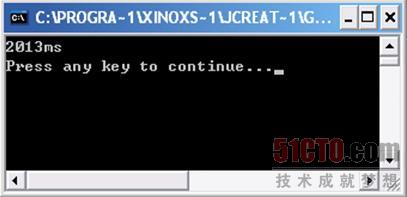
兩個程序的差距再3秒多,如果處理更大批量的數組他們的差距還會更大,因此,可以在適當的情況下用這個方法來處理數組的問題。
有時候我們為了使用方便,可以在自己的tools包中重載一個arrayCopy方法,如下:
public static Object[] arrayCopy(int pos,Object[] srcObj){
return arrayCopy(pos,srcObj.length,srcObj);
}
public static Object[] arrayCopy(int pos,int dest,Object[] srcObject){
Object[] rv=null;
rv=new Object[dest-pos];
System.arraycopy(srcObject,pos,rv,0,rv.length);
return rv;
}
|