這里介紹一個Flash的表格生成工具--FusionCharts,它是一個收費軟件,不過如果不是用于商業用途,只是用于,可以到網上下載破解版,csdn上面就有,如果想商業,購買應該也不貴。
下面我們來看一個最簡單的例子:
這個軟件生成表格的模式是:數據(XML文件或文件流)+模板。
1、XML數據:
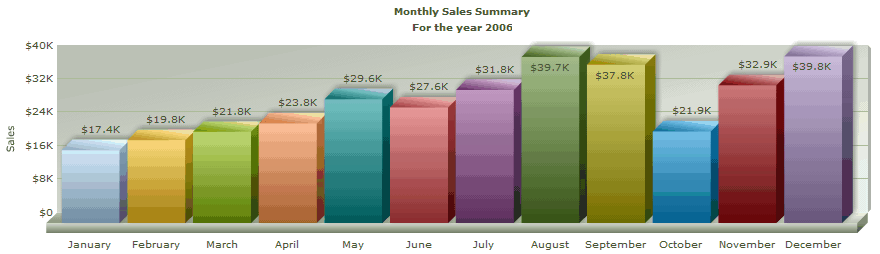
<set label='January' value='17400' />
<set label='February' value='19800' />
<set label='March' value='21800' />
<set label='April' value='23800' />
<set label='May' value='29600' />
<set label='June' value='27600' />
<set label='July' value='31800' />
<set label='August' value='39700' />
<set label='September' value='37800' />
<set label='October' value='21900' />
<set label='November' value='32900' />
<set label='December' value='39800' />
</chart>
2、將所有需要用到的模板拷貝到固定的位置。
3、在html中指定數據位置和模板名稱:
<head>
<title>My First FusionCharts</title>
</head>
<body bgcolor="#ffffff">
<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://fpdownload.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=8,0,0,0" width="900" height="300" id="Column3D" >
<param name="movie" value="../FusionCharts/Column3D.swf" />
<param name="FlashVars" value="&dataURL=Data.xml">
<param name="quality" value="high" />
<embed src="../FusionCharts/Column3D.swf" flashVars="&dataURL=Data.xml" quality="high" width="900" height="300" name="Column3D" type="application/x-shockwave-flash" pluginspage="http://www.macromedia.com/go/getflashplayer" />
</object>
</body>
</html>
4、運行結果:
1、安裝
Oracle 版本:Oracle Database 10g Release 2 (10.2.0.1)
下載地址:
http://www.oracle.com/technology/software/products/database/oracle10g/htdocs/10201winsoft.html
安裝設置:
1)這里的全局數據庫名即為你創建的數據庫名,以后在訪問數據,創建“本地Net服務名”時用到;
2)數據庫口令在登錄和創建“本地Net服務名”等地方會用到。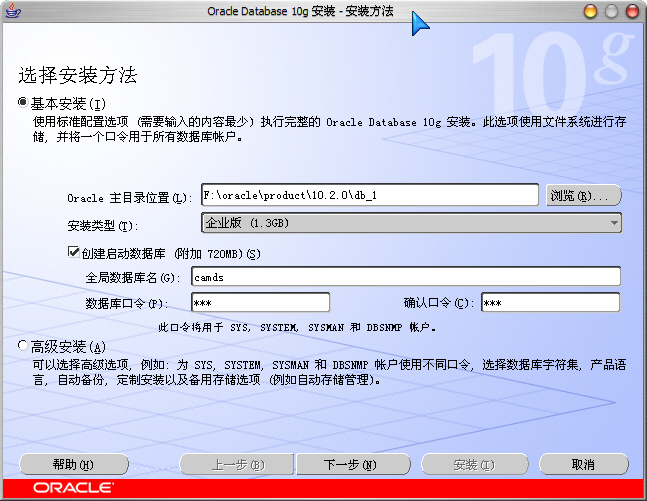
2、創建“本地Net服務名”
1)通過【程序】-》【Oracle - OraDb10g_home1】-》【配置和移植工具】-》【Net Configuration Assistant】,運行“網絡配置助手”工具:
2)選擇“本地 Net 服務名配置”:
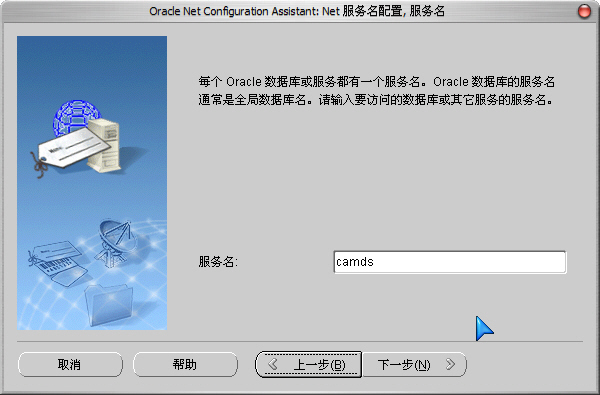
3)這里的“Net 服務名”我們輸入安裝數據庫時的“全局數據庫名”:
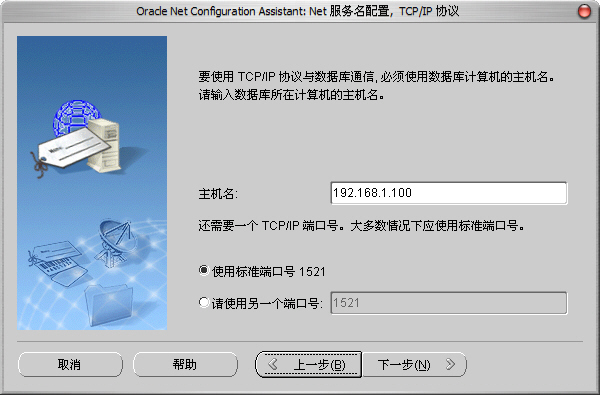
4)主機名我們輸入本機的IP地址:
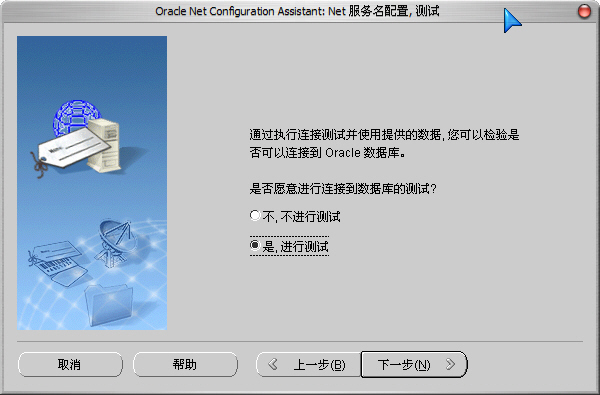
5)測試數據庫連接,用戶名/密碼為:System/數據庫口令(安裝時輸入的“數據庫口令”):
默認的用戶名/密碼錯誤:
更改登錄,輸入正確的用戶名/密碼:

測試成功:
3、PLSQL Developer 連接測試
輸入正確的用戶名/口令:
成功登陸:

4、創建表空間
打開sqlplus工具:
連接數據庫:
創建表空間:
5、創建新用戶
運行“P/L SQL Developer”工具,以DBA(用戶名:System)的身份登錄:1)新建“User(用戶):

2)設置用戶名、口令、默認表空間(使用上面新建的表空間)和臨時表空間:
3)設置角色權限:
4)設置”系統權限“:
5)點擊應用后,【應用】按鈕變灰,新用戶創建成功:
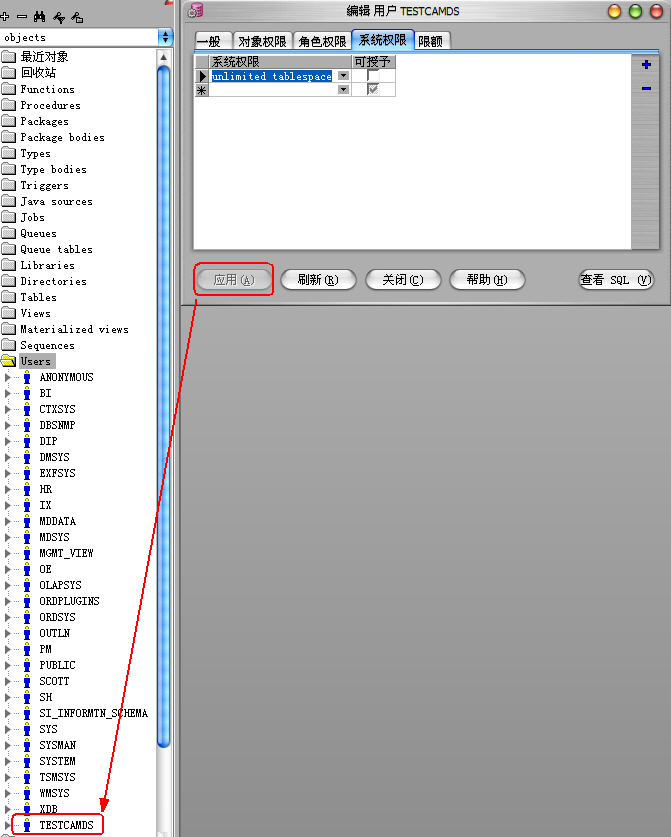
6)新用戶登錄測試:
輸入新用戶的“用戶名/口令”:
新用戶“testcamds”成功登陸:
6、導入導出數據庫
先運行cmd命令,進入命令行模式,轉到下面的目錄:D:"oracle"product"10.2.0"db_1"BIN【該目錄下有exp.exe文件】1)導入
命令語法:
命令實例:
導入結果:

2)導出:
命令語法:
命令實例:
導入結果:

下載地址為:
A:普通版:
http://downloads.myeclipseide.com/downloads/products/eworkbench/7.0/myeclipse-7.1-win32.exe
B:Blue版
http://downloads4.myeclipseide.com/downloads/products/eworkbench/7.0-Blue/myeclipse-blue-7.1-win32.exe
其中普通版可以直接用迅雷下載,但是blue卻連不上。
嘗試了多種方式,終于找到了下載方法,不過速度很慢,而且很不穩定:
使用的軟件
1、OperaTor-2.5
這是一個附帶代理的瀏覽器軟件;
2、eMule V1.1.3
常用的電驢軟件;
下面我們來看看如何下載:
【步驟1】:打開OperaTor,程序打開后,會發現托盤區有一個藍色圖標,上面有一個字母“P";
【步驟2】:將鼠標移到該圖標,點擊右鍵,依次選擇【Edit】-》【Main configuration】

【步驟3】:在打開的config.txt文件中,我們可以看到,本地代理的端口為:9050,

【步驟4】:設置電驢的代理服務器,這里的服務器類型選”Socks 4a“:

【步驟5】:最后,點擊電驢的”新建“按鈕,將”blue版“的地址拷貝過來就可以下載了:

不過通過代理方式下載的速度很慢,有時候還會斷線,這時候只需要重新打開上面軟件就可以了。
一、Comparator
強行對某個對象collection進行整體排序的比較函數,可以將Comparator傳遞給Collections.sort或Arrays.sort。
接口方法:
* @return o1小于、等于或大于o2,分別返回負整數、零或正整數。
*/
int compare(Object o1, Object o2);
二、Comparable
強行對實現它的每個類的對象進行整體排序,實現此接口的對象列表(和數組)可以通過Collections.sort或Arrays.sort進行自動排序。
接口方法:
* @return 該對象小于、等于或大于指定對象o,分別返回負整數、零或正整數。
*/
int compareTo(Object o);
三、Comparator和Comparable的區別
一個類實現了Camparable接口則表明這個類的對象之間是可以相互比較的,這個類對象組成的集合就可以直接使用sort方法排序。
Comparator可以看成一種算法的實現,將算法和數據分離,Comparator也可以在下面兩種環境下使用:
1、類的設計師沒有考慮到比較問題而沒有實現Comparable,可以通過Comparator來實現排序而不必改變對象本身
2、可以使用多種排序標準,比如升序、降序等。
完整代碼:
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class SortObject {
public static void main(String[] args) {
sortByComparable();
sortByComparator();
}
/**
* 通過Comparable排序
*/
public static void sortByComparable() {
List list = new ArrayList();
list.add(new Person("Coder", 1));
list.add(new Person("King", 3));
list.add(new Person("Dream", 2));
list.add(new Person("Baby", 4));
System.out.println("--- Sort Before ---");
printPerson(list);
Collections.sort(list);
System.out.println("--- After Sorted ---");
printPerson(list);
}
/**
* 通過Comparator排序
*/
public static void sortByComparator() {
List list = new ArrayList();
list.add(new Person("Coder", 1));
list.add(new Person("King", 3));
list.add(new Person("Dream", 2));
list.add(new Person("Baby", 4));
System.out.println("--- Sort Before ---");
printPerson(list);
Collections.sort(list, new PersonComparator());
System.out.println("--- After Sorted ---");
printPerson(list);
}
/**
* 打印List
*
* @param list
*/
public static void printPerson(List list) {
int size = list.size();
Person p = null;
for (int i = 0; i < size; i++) {
p = (Person) list.get(i);
System.out.println(p.getName() + ":" + p.getId());
}
}
}
class Person implements Comparable {
public String name;
public int id;
public Person() {
}
public Person(String name, int id) {
this.name = name;
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int compareTo(Object o) {
Person p = (Person) o;
return this.getName().compareTo(p.getName());
}
}
class PersonComparator implements Comparator {
public int compare(Object o1, Object o2) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
return p1.name.compareTo(p2.name);
}
}
Coder:1
King:3
Dream:2
Baby:4
--- After Sorted ---
Baby:4
Coder:1
Dream:2
King:3
--- Sort Before ---
Coder:1
King:3
Dream:2
Baby:4
--- After Sorted ---
Baby:4
Coder:1
Dream:2
King:3
參考:
1、Comparator和Comparable在排序中的應用
2、 java中對于復雜對象排序的模型及其實現 [轉]
左邊鏈接(包括錨點)、右邊顯示
文件清單1:
<!-- 文件范例:index.html -->
<!-- 文件說明:框架集 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>框架集</TITLE>
</HEAD>
<FRAMESET COLS="30%,70%">
<FRAME SRC=menu.html Scrolling="No">
<FRAME SRC=1.html Name="right">
</FRAMESET>
</HTML>
1、<meta>標簽放在<title>之前可以讓IE自動選擇字符集,如UTF-8;
2、第二個frame的name為“right”,這個值會在menu.html中用到;
文件清單2:
<!-- 文件范例:menu.html -->
<!-- 文件說明:左側框架 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>左側框架</TITLE>
</HEAD>
<BODY>
<A href="1.HTML" Target="right">《商業周刊》:iPhone2.0帶來的鯰魚效應</A><P>
1、<A href="1.HTML#a1" Target="right">無線運營商的日子更不好過</A><P>
2、<A href="1.HTML#a2" Target="right">手機制造廠商們將更煩惱</A><P>
3、<A href="1.HTML#a3" Target="right">iPhone帶來的沖擊會持續多久?</A><P>
<A href="2.HTML" Target="right">Fireworks MX</A><P>
<A href="3.HTML" Target="right">Flash MX</A><P>
</BODY>
</HTML>
1、注意,這里<A>標簽的target都為index.html中定義的"right"
文件清單3:
<!-- 文件范例:1.html -->
<!-- 文件說明:右側框架一 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
<TITLE>右側框架一</TITLE>
<Style Type="text/css">
<!--
.abc {
font-weight: bold;
font-size: 18px;
}
-->
</Style>
</HEAD>
<BODY>
<H1><A name=aTitle>《商業周刊》:iPhone2.0帶來的鯰魚效應</A></H1>
ugmbbc發布于 2008-06-17 08:26:20|2998 次閱讀 字體:大 小 打印預覽<BR><BR>
北京時間6月16日,《商業周刊》發表評論文章分析了iPhone2.0對無線運營商和手機制造商們帶來的沖擊,以下為其全文:
當蘋果準備憑著3G版iPhone再次吹響戰斗號角的時候,也是手機制造商和無線運營商們更加頭疼的時候.蘋果在手機市場中可謂旗開得勝,在iPhone 入市的第一年,蘋果就從競爭對手RIM公司中搶過不少市場份額,而AT&T作為 iPhone唯一授權的運營商,也從其競爭對手Alltel和T-Mobile中吸引了不少用戶.可以想象,一個更便宜、速度更快、功能更全的 iPhone將帶來什么樣的沖擊.<BR><BR>
將在7月面市的新版iPhone,不僅售價不到200美元、升級到更快的網絡,而且新增了很多吸引普通消費者以及商業用戶的功能.
<A name=a1><p class=abc> 無線運營商的日子更不好過</p></A>
據業內人士說,為了對付iPhone帶來的沖擊,無線服務運營商們不得不提高對手機的補貼、提高營銷預算并降低一些服務的價格,所有這一切意味著利潤空間的縮減.面對iPhone的沖擊,本來就已經處在政府監管日益增加以及直面Google競爭的無線運營商們的日子更不好過了.<BR><BR>
在過去的一年里,美國的無線運營商們已經在手機津貼上展開激烈競爭,通過增加對手機的補貼來獲得長期無線服務合同.但現在AT&T以 iPhone為誘惑來吸引用戶,對別的運營商來說,必須采取相應的措施來吸引用戶,他們可能引進類iPhone的手機.但"大多數人要的是iPhone,就像他們喜歡iPod而不是其他MP3播放器一樣",東北大學營銷系教授Gloria Barczak說到,"人們要的是真正的iPhone".因此,要想讓用戶被吸引,必須得有別的優勢,比如價格優勢等.<BR><BR>
為了留住高端用戶,運營商們需要加大業務推廣的力度.據廣告顧問公司TNS媒體情報的數據,運營商Verizon無線今年第一季度的廣告支出增加了30%.<BR><BR>
Sprint Nextel同期的廣告開支下降20%,主要是由于自身的財務問題,當看到用戶不斷流失的時候,Sprint Nextel應該會加大廣告的投入."他們必須拿出能對抗iPhone誘惑的方案來,盡量發揮自己的長處",顧問公司TMNG的CEO Rich Nespola說到.<BR><BR>
另一種留住用戶的方式是降低服務的價格.事實上,這是一個有效對付AT&T的辦法.AT&T對提供iPhone的用戶增加了服務的價格,以彌補高額的津貼費用."AT&T的對手們將在今年下半年繼續加強價格優勢,可能會有30%到40%的下降.當人們因為高油價開支增多的情況下,每月在無線服務上節省50美元也是很有吸引力的",Pali研究所的分析師Walter Piecyk說到,"因此,無線運營商的利潤將從目前的40%下滑到30%".
<p class=abc><A name=a2> 手機制造廠商們將更煩惱</A></p>
手機制造廠商們也正在因為iPhone而大傷腦筋,盡管現在他們正受益于兩位數增長的智能手機市場.當運營商們因iPhone而必須提高補貼的時候,他們會將壓力轉加到手機制造廠商頭上,進而壓低手機價格.何況,如果iPhone真像分析師們預期那樣大賣的話,其他手機廠商的市場份額也會受到很大侵蝕.很久沒推出拳頭產品的摩托羅拉可能受創最重,三星、LG甚至諾基亞也會遭受沖擊,NPD集團的主任分析師Ross Rubin說到,"高端、時尚機型將受沖擊最大".<BR><BR>
還有,為了趕上iPhone的技術水平和圖形表現能力,手機制造廠商們將不得不提高他們的軟件研發成本.去年售出300萬臺觸摸手機的 HTC,已經開發了一種特殊的3D菜單,該菜單表現力強勁,把通訊錄做得就像在實際的紙制通訊錄中翻找一樣."我們希望能把用戶的觸摸體驗提升到一個新的水平",HTC 首席營銷官的John Wang說到.<BR><BR>
作為世界上最大手機制造商的諾基亞,在Ovi上投了大量資金,希望為它的智能手機建立一個集地圖、游戲和照片共享于一身的Web服務平臺,這次在iPhone的刺激下也在加緊推出新服務."我們將繼續推出新服務",諾基亞美洲區副總裁Bill Plummer說到.
<p class=abc><A name=a3> iPhone帶來的沖擊會持續多久?</A></p>
iPhone帶來的沖擊將會持續多久?這個很難說.一個重量級手機的銷售要達到頂峰需要幾年的時間.摩托羅拉傳奇的RAZR系列手機在2004年推出,直到2007年一季度才達到銷售的頂峰,據NPD的數據,當時RAZR系列手機銷售占全美手機銷售的12%.<BR><BR>
雖然不好說那些別的智能手機和類iPhone的手機將會如何發展,但是"畢竟,重要的是,它們不是iPhone",Jupiter研究所分析師Neil Strother說到,"這不是在蘋果堆里挑蘋果".<BR><BR>
</BODY>
</HTML>
文件清單4:
<!-- 文件范例:2.html -->
<!-- 文件說明:右側框架二 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>右側框架二</TITLE>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
</HEAD>
<BODY>
<H1>Fireworks MX</H1>
Fireworks MX作為網頁圖像設計軟件的代表,在繼承了前期版本圖形繪制、頁面特效功能的同時,大大地發展了位圖圖像方面的處理功能,這無疑使這個軟件有了向Photoshop挑戰的更多資本,而其在網頁設計方面的諸多應用,又無任何軟件可與之媲美。與Dreamweaver MX的整合使其在專業網站圖像設計過程中,扮演著不可或缺的角色。
</BODY>
</HTML>
文件清單5:
<!-- 文件范例:3.html -->
<!-- 文件說明:右側框架三 -->
<!-- ------------------------------ -->
<HTML>
<HEAD>
<TITLE>右側框架三</TITLE>
<META HTTP-EQUIV="CONTENT-TYPE" CONTENT="TEXT/HTML;CHARSET=UTF-8">
</HEAD>
<BODY>
<H1>Flash MX</H1>
Flash MX作為網頁矢量交互動畫軟件的代表,提供了圖形繪制、動畫制作和交互三大功能。掌握了這個軟件的核心,也就有能力在網上沖浪的同時,充當一把閃客的角色。越來越多的個人、商業網站采用Flash技術制作廣告Banner、動畫片頭、MTV、交互游戲,其廣泛的應用為Flash的學習者提供了廣闊的發展平臺,學習Flash MX軟件更是一個具有誘惑力的過程。
</BODY>
</HTML>
源代碼
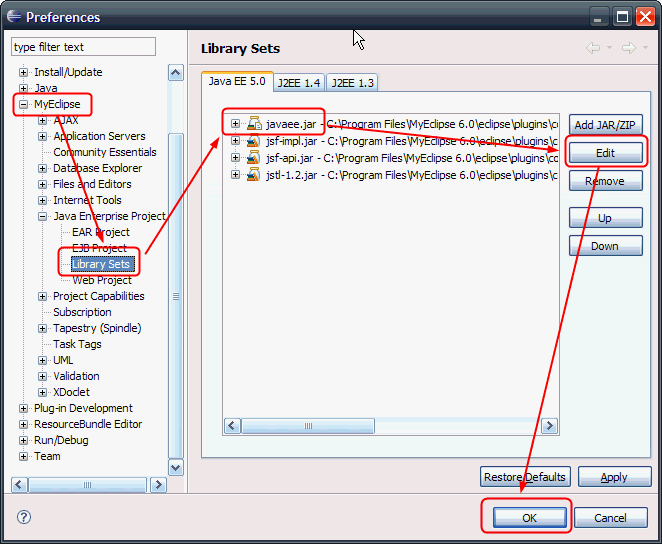
這是javaee.jar的設置畫面,其他Struts等等設置類似。
原始畫面:
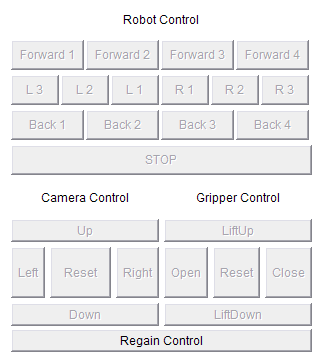
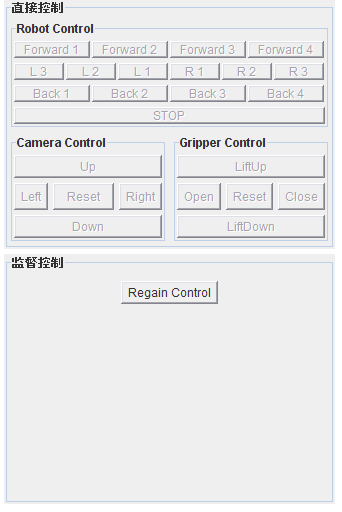
由于原來的程序使用的是AWT中的Panel,而這個控件我們沒有設置titleBorder的方法。
現在將更新為Swing中的JPanel面板,代碼分別為:
舊代碼:
pRoboCtrl.setLayout(new GridLayout(5, 1, 2, 5));
// Robot控制面板的第一排,面板的標題
Panel pR1=new Panel();
pR1.setLayout(new GridLayout(1, 1, 2, 3));
//Row One
pR1.add(new Label("Robot Control",Label.CENTER));
pRoboCtrl.setLayout(new GridLayout(4, 1, 2, 5));
Border titleBorder1=BorderFactory.createTitledBorder("Robot Control");
pRoboCtrl.setBorder(titleBorder1);
解決這個問題后,新問題又來了,兩個JPanel中的內容不一樣,上面多,下面少,但是現在面板卻是一樣大,要改成面板高度自動適應。
其實這只需要修改一行代碼就可以了,代碼如下:
舊代碼:
 CP.setLayout(new GridLayout(3, 1, 2, 5));
CP.setLayout(new GridLayout(3, 1, 2, 5)); 
以下代碼創建了一個JPanel容器,它采用垂直 BoxLayout,在這個容器中包含兩個Button,這兩個Button沿垂直方向分布,并且保持像素為 5 的固定垂直間隔。
panel.setLayout(new BoxLayout(panel, BoxLayout.Y_AXIS));// 沿垂直方向布置組件
panel.add(new JButton("Button1"));
panel.add(Box.createVerticalStrut(5));
panel.add(new JButton("Button2"));
源代碼:下載
https://quartz.dev.java.net/files/documents/1267/43545/quartz-1.6.0.zip
2、詳細講解Quartz如何從入門到精通
3、用 Quartz 進行作業調度
想必很多人都對正則表達式都頭疼。今天,我以我的認識,加上網上一些文章,希望用常人都可以理解的表達方式來和大家分享學習經驗。
開篇,還是得說說 ^ 和 $ 他們是分別用來匹配字符串的開始和結束,以下分別舉例說明:
"^The": 開頭一定要有"The"字符串;
"of despair$": 結尾一定要有"of despair" 的字符串;
那么,
"^abc$": 就是要求以abc開頭和以abc結尾的字符串,實際上是只有abc匹配。
"notice": 匹配包含notice的字符串。
你可以看見如果你沒有用我們提到的兩個字符(最后一個例子),就是說 模式(正則表達式) 可以出現在被檢驗字符串的任何地方,你沒有把他鎖定到兩邊。
接著,說說 '*', '+',和 '?',
他們用來表示一個字符可以出現的次數或者順序。 他們分別表示:
"zero or more"相當于{0,},
"one or more"相當于{1,},
"zero or one."相當于{0,1}, 這里是一些例子:
"ab*": 和ab{0,}同義,匹配以a開頭,后面可以接0個或者N個b組成的字符串("a", "ab", "abbb", 等);
"ab+": 和ab{1,}同義,同上條一樣,但最少要有一個b存在 ("ab", "abbb", 等。);
"ab?":和ab{0,1}同義,可以沒有或者只有一個b;
"a?b+$": 匹配以一個或者0個a再加上一個以上的b結尾的字符串。
要點, '*', '+',和 '?'只管它前面那個字符。
你也可以在大括號里面限制字符出現的個數,比如
"ab{2}": 要求a后面一定要跟兩個b(一個也不能少)("abb");
"ab{2,}": 要求a后面一定要有兩個或者兩個以上b(如"abb", "abbbb", 等。);
"ab{3,5}": 要求a后面可以有2-5個b("abbb", "abbbb", or "abbbbb")。
現在我們把一定幾個字符放到小括號里,比如:
"a(bc)*": 匹配 a 后面跟0個或者一個"bc";
"a(bc){1,5}": 一個到5個 "bc."
還有一個字符 '│', 相當于OR 操作:
"hi│hello": 匹配含有"hi" 或者 "hello" 的 字符串;
"(b│cd)ef": 匹配含有 "bef" 或者 "cdef"的字符串;
"(a│b)*c": 匹配含有這樣多個(包括0個)a或b,后面跟一個c的字符串;
一個點('.')可以代表所有的單一字符,不包括"\n"
如果,要匹配包括"\n"在內的所有單個字符,怎么辦?
對了,用'[\n.]'這種模式。
"a.[0-9]": 一個a加一個字符再加一個0到9的數字
"^.{3}$": 三個任意字符結尾 .
中括號括住的內容只匹配一個單一的字符
"[ab]": 匹配單個的 a 或者 b ( 和 "a│b" 一樣);
"[a-d]": 匹配'a' 到'd'的單個字符 (和"a│b│c│d" 還有 "[abcd]"效果一樣); 一般我們都用[a-zA-Z]來指定字符為一個大小寫英文
"^[a-zA-Z]": 匹配以大小寫字母開頭的字符串
"[0-9]%": 匹配含有 形如 x% 的字符串
",[a-zA-Z0-9]$": 匹配以逗號再加一個數字或字母結尾的字符串
你也可以把你不想要得字符列在中括號里,你只需要在總括號里面使用'^' 作為開頭 "%[^a-zA-Z]%" 匹配含有兩個百分號里面有一個非字母的字符串。
要點:^用在中括號開頭的時候,就表示排除括號里的字符。為了PHP能夠解釋,你必須在這些字符面前后加'',并且將一些字符轉義。
不要忘記在中括號里面的字符是這條規路的例外?在中括號里面, 所有的特殊字符,包括(''), 都將失去他們的特殊性質 "[*\+?{}.]"匹配含有這些字符的字符串。
還有,正如regx的手冊告訴我們: "如果列表里含有 ']', 最好把它作為列表里的第一個字符(可能跟在'^'后面)。 如果含有'-', 最好把它放在最前面或者最后面, or 或者一個范圍的第二個結束點[a-d-0-9]中間的‘-’將有效。
看了上面的例子,你對{n,m}應該理解了吧。要注意的是,n和m都不能為負整數,而且n總是小于m. 這樣,才能 最少匹配n次且最多匹配m次。 如"p{1,5}"將匹配 "pvpppppp"中的前五個p.
下面說說以\開頭的
\b 書上說他是用來匹配一個單詞邊界,就是……比如've\b',可以匹配love里的ve而不匹配very里有ve
\B 正好和上面的\b相反。例子我就不舉了
……突然想起來……可以到http://www.phpv.net/article.php/251 看看其它用\ 開頭的語法
好,我們來做個應用:
如何構建一個模式來匹配 貨幣數量 的輸入
構建一個匹配模式去檢查輸入的信息是否為一個表示money的數字。我們認為一個表示money的數量有四種方式: "10000.00" 和 "10,000.00",或者沒有小數部分, "10000" and "10,000". 現在讓我們開始構建這個匹配模式:
^[1-9][0-9]*$
這是所變量必須以非0的數字開頭。但這也意味著 單一的 "0" 也不能通過測試。 以下是解決的方法:
^(0│[1-9][0-9]*)$
"只有0和不以0開頭的數字與之匹配",我們也可以允許一個負號在數字之前:
^(0│-?[1-9][0-9]*)$
這就是: "0 或者 一個以0開頭 且可能 有一個負號在前面的數字。" 好了,現在讓我們別那么嚴謹,允許以0開頭。現在讓我們放棄 負號 , 因為我們在表示錢幣的時候并不需要用到。 我們現在指定 模式 用來匹配小數部分:
^[0-9]+(\.[0-9]+)?$
這暗示匹配的字符串必須最少以一個阿拉伯數字開頭。 但是注意,在上面模式中 "10." 是不匹配的, 只有 "10" 和 "10.2" 才可以。 (你知道為什么嗎)
^[0-9]+(\.[0-9]{2})?$
我們上面指定小數點后面必須有兩位小數。如果你認為這樣太苛刻,你可以改成:
^[0-9]+(\.[0-9]{1,2})?$
這將允許小數點后面有一到兩個字符。 現在我們加上用來增加可讀性的逗號(每隔三位), 我們可以這樣表示:
^[0-9]{1,3}(,[0-9]{3})*(\.[0-9]{1,2})?$
不要忘記 '+' 可以被 '*' 替代 如果你想允許空白字符串被輸入話 (為什么?)。 也不要忘記反斜桿 ‘\’ 在php字符串中可能會出現錯誤 (很普遍的錯誤)。
現在,我們已經可以確認字符串了, 我們現在把所有逗號都去掉 str_replace(",", "", $money) 然后在把類型看成 double然后我們就可以通過他做數學計算了。
再來一個:
構造檢查email的正則表達式
在一個完整的email地址中有三個部分:
1. 用戶名 (在 '@' 左邊的一切),
2.'@',
3. 服務器名(就是剩下那部分)。
用戶名可以含有大小寫字母阿拉伯數字,句號 ('.'), 減號('-'), and 下劃線 ('_')。 服務器名字也是符合這個規則,當然下劃線除外。
現在, 用戶名的開始和結束都不能是句點。 服務器也是這樣。 還有你不能有兩個連續的句點他們之間至少存在一個字符,好現在我們來看一下怎么為用戶名寫一個匹配模式:
^[_a-zA-Z0-9-]+$
現在還不能允許句號的存在。 我們把它加上:
^[_a-zA-Z0-9-]+(\.[_a-zA-Z0-9-]+)*$
上面的意思就是說: "以至少一個規范字符(除了。)開頭,后面跟著0個或者多個以點開始的字符串。"
簡單化一點, 我們可以用 eregi()取代 ereg()。eregi()對大小寫不敏感, 我們就不需要指定兩個范圍 "a-z" 和 "A-Z" ? 只需要指定一個就可以了:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*$
后面的服務器名字也是一樣,但要去掉下劃線:
^[a-z0-9-]+(\.[a-z0-9-]+)*$
好。 現在只需要用“@”把兩部分連接:
^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$
這就是完整的email認證匹配模式了,只需要調用
eregi(‘^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$ ’,$eamil)
就可以得到是否為email了。
正則表達式的其他用法
提取字符串
ereg() and eregi() 有一個特性是允許用戶通過正則表達式去提取字符串的一部分(具體用法你可以閱讀手冊)。 比如說,我們想從 path/URL 提取文件名 ? 下面的代碼就是你需要:
ereg("([^\\/]*)$", $pathOrUrl, $regs);
echo $regs[1];
高級的代換
ereg_replace() 和 eregi_replace()也是非常有用的: 假如我們想把所有的間隔負號都替換成逗號:
ereg_replace("[ \n\r\t]+", ",", trim($str));
最后,我把另一串檢查EMAIL的正則表達式讓看文章的你來分析一下。
"^[-!#$%&\'*+\\./0-9=?A-Z^_`a-z{|}~]+'.'@'.'[-!#$%&\'*+\\/0-9=?A-Z^_`a-z{|}~]+\.'.'[-!#$%&\'*+\\./0-9=?A-Z^_`a-z{|}~]+$"
如果能方便的讀懂,那這篇文章的目的就達到了。
原文地址:http://java.chinaitlab.com/base/732793.html
2、正則表達式話題
3、如何使用Java自帶的正則表達式
4、處理正則表達式的java包:regexp
5、Java正則表達式技巧總結
6、學點Java正則表達式
7、在JAVA中使用正則表達式
8、Java正則表達式(1)
9、java正則表達式; regular expression(2)
10、JAVA正則表達式(2)
§1黑暗歲月
有一個String,如何查詢其中是否有y和f字符?最黑暗的辦法就是:程序1:我知道if、for語句和charAt()啊。
public static void main(String args[]) {
String str="For my money, the important thing "+
"about the meeting was bridge-building";
char x='y';
char y='f';
boolean result=false;
for(int i=0;i<str.length();i++){
char z=str.charAt(i); //System.out.println(z);
if(x==z||y==z) {
result=true;
break;
}
else result=false;
}
System.out.println(result);
}
}
好像很直觀,但這種方式難以應付復雜的工作。如查詢一段文字中,是否有is?是否有thing或ting等。這是一個討厭的工作。
§2 Java的java.util.regex包
按照面向對象的思路,把希望查詢的字符串如is、thing或ting封裝成一個對象,以這個對象作為模板去匹配一段文字,就更加自然了。作為模板的那個東西就是下面要討論的正則表達式。先不考慮那么復雜,看一個例子:程序2:不懂。先看看可以吧?
class Regex1{
public static void main(String args[]) {
String str="For my money, the important thing "+
"about the meeting was bridge-building";
String regEx="a|f"; //表示a或f
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean result=m.find();
System.out.println(result);
}
}
如果str匹配regEx,那么result為true,否則為flase。如果想在查找時忽略大小寫,則可以寫成:
Pattern p=Pattern.compile(regEx,Pattern.CASE_INSENSITIVE);
雖然暫時不知道Pattern(模板、模式)和Matcher(匹配器)的細節,程序的感覺就比較爽,如果先查詢is、后來又要查詢thing或ting,我們只需要修改一下模板Pattern,而不是考慮if語句和for語句,或者通過charAt()。
1、寫一個特殊的字符串??正則表達式如a|f。
2、將正則表達式編譯成一個模板:p
3、用模板p去匹配字符串str。
思路清楚了,現在看Java是如何處理的(Java程序員直到JDK1.4才能使用這些類。
§3 Pattern類與查找
①public final class java.util.regex.Pattern是正則表達式編譯后的表達法。下面的語句將創建一個Pattern對象并賦值給句柄p:Pattern p=Pattern.compile(regEx);有趣的是,Pattern類是final類,而且它的構造器是private。也許有人告訴你一些設計模式的東西,或者你自己查有關資料。這里的結論是:Pattern類不能被繼承,我們不能通過new創建Pattern類的對象。
因此在Pattern類中,提供了2個重載的靜態方法,其返回值是Pattern對象(的引用)。如:
public static Pattern compile(String regex) {
return new Pattern(regex, 0);
}
當然,我們可以聲明Pattern類的句柄,如Pattern p=null;
②p.matcher(str)表示以用模板p去生成一個字符串str的匹配器,它的返回值是一個Matcher類的引用,為什么要這個東西呢?按照自然的想法,返回一個boolean值不行嗎?
我們可以簡單的使用如下方法:
boolean result=Pattern.compile(regEx).matcher(str).find();
呵呵,其實是三個語句合并的無句柄方式。無句柄常常不是好方式。后面再學習Matcher類吧。先看看regEx??這個怪咚咚。
§4 正則表達式之限定符
正則表達式(Regular Expression)是一種生成字符串的字符串。暈吧。比如說,String regEx="me+";這里字符串me+能夠生成的字符串是:me、mee、meee、meeeeeeeeee等等,一個正則表達式可能生成無窮的字符串,所以我們不可能(有必要嗎?)輸出正則表達式產生的所有東西。反過來考慮,對于字符串:me、mee、meee、meeeeeeeeee等等,我們能否有一種語言去描述它們呢?顯然,正則表達式語言是這種語言,它是一些字符串的模式??簡潔而深刻的描述。
我們使用正則表達式,用于字符串查找、匹配、指定字符串替換、字符串分割等等目的。
生成字符串的字符串??正則表達式,真有些復雜,因為我們希望由普通字符(例如字符 a 到 z)以及特殊字符(稱為元字符)描述任意的字符串,而且要準確。
先搞幾個正則表達式例子:
程序3:我們總用這個程序測試正則表達式。
class Regex1{
public static void main(String args[]) {
String str="For my money, the important thing ";
String regEx="ab*";
boolean result=Pattern.compile(regEx).matcher(str).find();
System.out.println(result);
}
}//ture
①"ab*"??能匹配a、ab、abb、abbb……。所以,*表示前面字符可以有零次或多次。如果僅僅考慮查找,直接用"a"也一樣。但想想替換的情況。 問題regEx="abb*"結果如何?
②"ab+"??能匹配ab、abb、abbb……。等價于"abb*"。問題regEx="or+"結果如何?
③"or?"??能匹配o和or。? 表示前面字符可以有零次或一次。
這些限定符*、+、?方便地表示了其前面字符(子串)出現的次數(我們用{}來描述):
x* 零次或多次 ≡{0,}
x+ 一次或多次 ≡{1,}
x? 零次或一次 ≡{0,1}
x{n} n次(n>0)
x{n,m} 最少n次至最多m次(0<n<m)
x{n,} 最少n次,
現在我們知道了連續字符串的查找、匹配。下面的是一些練習題:
①查找粗體字符串(不要求精確或要求精確匹配),寫出其正則表達式:
str regEX(不要求精確) regEX(要求精確) 試一試
abcffd b或bcff或bcf*或bc*或bc+ bcff或bcf{2} bc{3}
gooooogle o{1,}、o+ o{5}
banana (an)+ (an){2}a、a(na) {2}
②正則表達式匹配字符串,輸出是什么?
§5替換(刪除)、Matcher類
現在我們可能厭煩了true/false,我們看看替換。如把book,google替換成bak(這個文件后綴名,在EditPlus中還行)、look或goooogle。程序4:字符串的替換。
class Regex1{
public static void main(String args[]) {
String regEx="a+";//表示一個或多個a
String str="abbbaaa an banana hhaana";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
String s=m.replaceAll("⊙⊙"); // ("") 刪除
System.out.println(s);
}
}
這個程序與前面的程序的區別,在于使用了m.replaceAll(String)方法。看來Matcher類還有點用處。
① Matcher是一個匹配器。可以把他看成一個人,一手拿著模子(Pattern類的對象),一手拿著一個字符序列(CharSequence),通過解釋該模子而對字符序列進行匹配操作(match operations)。常常我們這樣編程:“喂,模子p,你和字符串str一起創建一個匹配器對象”。即Matcher m=p.matcher(str);
② m可以進行一些操作,如public String replaceAll(String replacement),它以replacement替換所有匹配的字符串。
§6正則表達式之特殊字符
我們熟悉這樣一個字符串"\n" 如:System.out.print(s+"\nbbb");這是Java中常用的轉移字符之一。其實轉移字符就是一種正則表達式,它使用了特殊字符 \ 。下面是正則表達式中常用的特殊字符:
匹配次數符號 * + ? {n}、{n,}、{n,m}
“或”符號 | 程序2已經使用過了
句點符號 . 句點符號匹配所有字符(一個),包括空格、Tab字符甚至換行符。
方括號 [ ] 僅僅匹配方括號其中的字符)
圓括號 () 分組,圓括號中的字符視為一個整體。
連字符 - 表示一個范圍。
“否”符號 ^ 表示不希望被匹配的字符(排除)
我們一下子學不了太多的東西,這不是正則表達式的全部內容和用法。但已經夠我們忙活的了。我們用程序4 驗證。(⊙⊙表示替換的字符)
① regEx為下列字符串時,能夠表示什么?
regEx 匹配 測試用str
(a|b){2} aa、ab、bb、ba aabbfooaabfooabfoob
a[abc]b aab、abb、acb 3dfacb5ooyfo6abbfooaab
. all string 3dfac
a. aa、ax……等等 3dfacgg
d[^j]a daa、d9a等等,除dja 3dfacggdjad5a
[d-g][ac]c dac、ecc、gac等 3dfacggggccad5c
[d-g].{2}c d⊙⊙c…… 3dfacggggccad5c
g{1,10} g、ggg…… 3dfacggggccad5c
[a|c][^a] 3dfacggggccad5c
② 下列字符串如何用regEx表示?
測試用str 匹配 regEx
aabbfoaoabfooafobob a⊙⊙b a..b
aabbfoaaobfooafbob a⊙b、除aab a[^a]b、
gooooooogle oooo……變成oo o{2,20}
一本書中的“tan”、“ten”、“tin”和“ton” t.n、t[aeio]n
abcaccbcbaacabccaa 刪除ac、ca (ca)|(ac)
abccbcbaabca 再刪除ab、ba 結果ccbcca(如何與上面的合并)
注:
1、String str="一本書中的tan、ten、tin和ton";
輸出: 一本書中的⊙⊙、⊙⊙、⊙⊙和⊙⊙
2、String str=" abcaccbcbaacabccaa "; 輸出:ccbcca
程序5:if、for語句和charAt(),886。
class Regex1{
public static void main(String args[]) {
String str="abcaccbcbaacabccaa";
String regEx="(ac)|(ca)";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
String s=m.replaceAll("");//⊙⊙
regEx="(ab)|(ba)";
p=Pattern.compile(regEx);
s=p.matcher(s).replaceAll("");
System.out.print(s+"\n");
}
}
§7 開始
好像我們知道了一些正則表達式與 Java的知識,事實上,我們才剛剛開始。這里列出我們知道的東西,也說一點我們不知道的東西。① Java在JDK1.4引入了(java.util.regex包)以支持正則表達式,包中有兩個類,分別是Pattern和Matcher。它們都有很多的方法,我們還不知道。String類中的split、matches方法等等也使用到了正則表達式。StringTokenizer是否沒有用處了?
② 正則表達式是一門語言。有許多正則表達式語法、選項和特殊字符,在Pattern.java源文件中大家可以查看。可能比想象中的要復雜。系統學習正則表達式的歷史、語法、全部特殊字符(相當于Java中的關鍵字的地位),組合邏輯是下一步的事情。
③ 正則表達式是文本處理的重要技術,在Perl、PHP、Python、JavaScript、Java、C#中被廣泛支持。被列為“保證你現在和未來不失業的十種關鍵技術”,呵呵,信不信由你
正則表達式在字符串處理上有著強大的功能,sun在jdk1.4加入了對它的支持
下面簡單的說下它的4種常用功能:
查詢:
以下是代碼片段:
String str="abc efg ABC";
String regEx="a|f"; //表示a或f
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean rs=m.find();
如果str中有regEx,那么rs為true,否則為flase。如果想在查找時忽略大小寫,則可以寫成Pattern p=Pattern.compile(regEx,Pattern.CASE_INSENSITIVE);
提取:
以下是代碼片段:
String regEx=".+\(.+)$";
String str="c:\dir1\dir2\name.txt";
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher(str);
boolean rs=m.find();
for(int i=1;i<=m.groupCount();i++){
System.out.println(m.group(i));
}
以上的執行結果為name.txt,提取的字符串儲存在m.group(i)中,其中i最大值為m.groupCount();
分割:
以下是代碼片段:
String regEx="::";
Pattern p=Pattern.compile(regEx);
String[] r=p.split("xd::abc::cde");
執行后,r就是{"xd","abc","cde"},其實分割時還有跟簡單的方法:
String str="xd::abc::cde";
String[] r=str.split("::");
替換(刪除):
以下是代碼片段:
String regEx="a+"; //表示一個或多個a
Pattern p=Pattern.compile(regEx);
Matcher m=p.matcher("aaabbced a ccdeaa");
String s=m.replaceAll("A");
結果為"Abbced A ccdeA"
如果寫成空串,既可達到刪除的功能,比如:
String s=m.replaceAll("");
結果為"bbced ccde"
附:
\D 等於 [^0-9] 非數字
\s 等於 [ \t\n\x0B\f ] 空白字元
\S 等於 [^ \t\n\x0B\f ] 非空白字元
\w 等於 [a-zA-Z_0-9] 數字或是英文字
\W 等於 [^a-zA-Z_0-9] 非數字與英文字
^ 表示每行的開頭
$ 表示每行的結尾
原文地址:http://java.chinaitlab.com/advance/350770.html
許多語言,包括Perl、PHP、Python、JavaScript和JScript,都支持用正則表達式處理文本,一些文本編輯器用正則表達式實現高級“搜索-替換”功能。那么Java又怎樣呢?本文寫作時,一個包含了用正則表達式進行文本處理的Java規范需求(Specification Request)已經得到認可,你可以期待在JDK的下一版本中看到它。
然而,如果現在就需要使用正則表達式,又該怎么辦呢?你可以從Apache.org下載源代碼開放的Jakarta-ORO庫。本文接下來的內容先簡要地介紹正則表達式的入門知識,然后以Jakarta-ORO API為例介紹如何使用正則表達式。
一、正則表達式基礎知識
我們先從簡單的開始。假設你要搜索一個包含字符“cat”的字符串,搜索用的正則表達式就是“cat”。如果搜索對大小寫不敏感,單詞“catalog”、“Catherine”、“sophisticated”都可以匹配。也就是說:

1.1 句點符號
假設你在玩英文拼字游戲,想要找出三個字母的單詞,而且這些單詞必須以“t”字母開頭,以“n”字母結束。另外,假設有一本英文字典,你可以用正則表達式搜索它的全部內容。要構造出這個正則表達式,你可以使用一個通配符——句點符號“.”。這樣,完整的表達式就是“t.n”,它匹配“tan”、“ten”、“tin”和“ton”,還匹配“t#n”、“tpn”甚至“t n”,還有其他許多無意義的組合。這是因為句點符號匹配所有字符,包括空格、Tab字符甚至換行符:

1.2 方括號符號
為了解決句點符號匹配范圍過于廣泛這一問題,你可以在方括號(“[]”)里面指定看來有意義的字符。此時,只有方括號里面指定的字符才參與匹配。也就是說,正則表達式“t[aeio]n”只匹配“tan”、“Ten”、“tin”和“ton”。但“Toon”不匹配,因為在方括號之內你只能匹配單個字符:

1.3 “或”符號
如果除了上面匹配的所有單詞之外,你還想要匹配“toon”,那么,你可以使用“|”操作符。“|”操作符的基本意義就是“或”運算。要匹配“toon”,使用“t(a|e|i|o|oo)n”正則表達式。這里不能使用方擴號,因為方括號只允許匹配單個字符;這里必須使用圓括號“()”。圓括號還可以用來分組,具體請參見后面介紹。

1.4 表示匹配次數的符號
表一顯示了表示匹配次數的符號,這些符號用來確定緊靠該符號左邊的符號出現的次數:

假設我們要在文本文件中搜索美國的社會安全號碼。這個號碼的格式是999-99-9999。用來匹配它的正則表達式如圖一所示。在正則表達式中,連字符(“-”)有著特殊的意義,它表示一個范圍,比如從0到9。因此,匹配社會安全號碼中的連字符號時,它的前面要加上一個轉義字符“\”。

圖一:匹配所有123-12-1234形式的社會安全號碼
假設進行搜索的時候,你希望連字符號可以出現,也可以不出現——即,999-99-9999和999999999都屬于正確的格式。這時,你可以在連字符號后面加上“?”數量限定符號,如圖二所示:

圖二:匹配所有123-12-1234和123121234形式的社會安全號碼
下面我們再來看另外一個例子。美國汽車牌照的一種格式是四個數字加上二個字母。它的正則表達式前面是數字部分“[0-9]{4}”,再加上字母部分“[A-Z]{2}”。圖三顯示了完整的正則表達式。

圖三:匹配典型的美國汽車牌照號碼,如8836KV
1.5 “否”符號
“^”符號稱為“否”符號。如果用在方括號內,“^”表示不想要匹配的字符。例如,圖四的正則表達式匹配所有單詞,但以“X”字母開頭的單詞除外。

圖四:匹配所有單詞,但“X”開頭的除外
1.6 圓括號和空白符號
假設要從格式為“June 26, 1951”的生日日期中提取出月份部分,用來匹配該日期的正則表達式可以如圖五所示:

圖五:匹配所有Moth DD,YYYY格式的日期
新出現的“\s”符號是空白符號,匹配所有的空白字符,包括Tab字符。如果字符串正確匹配,接下來如何提取出月份部分呢?只需在月份周圍加上一個圓括號創建一個組,然后用ORO API(本文后面詳細討論)提取出它的值。修改后的正則表達式如圖六所示:

圖六:匹配所有Month DD,YYYY格式的日期,定義月份值為第一個組
1.7 其它符號
為簡便起見,你可以使用一些為常見正則表達式創建的快捷符號。如表二所示:
表二:常用符號

例如,在前面社會安全號碼的例子中,所有出現“[0-9]”的地方我們都可以使用“\d”。修改后的正則表達式如圖七所示:

圖七:匹配所有123-12-1234格式的社會安全號碼
二、Jakarta-ORO庫
有許多源代碼開放的正則表達式庫可供Java程序員使用,而且它們中的許多支持Perl 5兼容的正則表達式語法。我在這里選用的是Jakarta-ORO正則表達式庫,它是最全面的正則表達式API之一,而且它與Perl 5正則表達式完全兼容。另外,它也是優化得最好的API之一。
Jakarta-ORO庫以前叫做OROMatcher,Daniel Savarese大方地把它贈送給了Jakarta Project。你可以按照本文最后參考資源的說明下載它。
我首先將簡要介紹使用Jakarta-ORO庫時你必須創建和訪問的對象,然后介紹如何使用Jakarta-ORO API。
▲ PatternCompiler對象
首先,創建一個Perl5Compiler類的實例,并把它賦值給PatternCompiler接口對象。Perl5Compiler是PatternCompiler接口的一個實現,允許你把正則表達式編譯成用來匹配的Pattern對象。

▲ Pattern對象
要把正則表達式編譯成Pattern對象,調用compiler對象的compile()方法,并在調用參數中指定正則表達式。例如,你可以按照下面這種方式編譯正則表達式“t[aeio]n”:

默認情況下,編譯器創建一個大小寫敏感的模式(pattern)。因此,上面代碼編譯得到的模式只匹配“tin”、“tan”、 “ten”和“ton”,但不匹配“Tin”和“taN”。要創建一個大小寫不敏感的模式,你應該在調用編譯器的時候指定一個額外的參數:

創建好Pattern對象之后,你就可以通過PatternMatcher類用該Pattern對象進行模式匹配。
▲ PatternMatcher對象
PatternMatcher對象根據Pattern對象和字符串進行匹配檢查。你要實例化一個Perl5Matcher類并把結果賦值給PatternMatcher接口。Perl5Matcher類是PatternMatcher接口的一個實現,它根據Perl 5正則表達式語法進行模式匹配:

使用PatternMatcher對象,你可以用多個方法進行匹配操作,這些方法的第一個參數都是需要根據正則表達式進行匹配的字符串:
· boolean matches(String input, Pattern pattern):當輸入字符串和正則表達式要精確匹配時使用。換句話說,正則表達式必須完整地描述輸入字符串。
· boolean matchesPrefix(String input, Pattern pattern):當正則表達式匹配輸入字符串起始部分時使用。
· boolean contains(String input, Pattern pattern):當正則表達式要匹配輸入字符串的一部分時使用(即,它必須是一個子串)。
另外,在上面三個方法調用中,你還可以用PatternMatcherInput對象作為參數替代String對象;這時,你可以從字符串中最后一次匹配的位置開始繼續進行匹配。當字符串可能有多個子串匹配給定的正則表達式時,用PatternMatcherInput對象作為參數就很有用了。用PatternMatcherInput對象作為參數替代String時,上述三個方法的語法如下:
· boolean matches(PatternMatcherInput input, Pattern pattern)
· boolean matchesPrefix(PatternMatcherInput input, Pattern pattern)
· boolean contains(PatternMatcherInput input, Pattern pattern)
三、應用實例
下面我們來看看Jakarta-ORO庫的一些應用實例。
3.1 日志文件處理
任務:分析一個Web服務器日志文件,確定每一個用戶花在網站上的時間。在典型的BEA WebLogic日志文件中,日志記錄的格式如下:

分析這個日志記錄,可以發現,要從這個日志文件提取的內容有兩項:IP地址和頁面訪問時間。你可以用分組符號(圓括號)從日志記錄提取出IP地址和時間標記。
首先我們來看看IP地址。IP地址有4個字節構成,每一個字節的值在0到255之間,各個字節通過一個句點分隔。因此,IP地址中的每一個字節有至少一個、最多三個數字。圖八顯示了為IP地址編寫的正則表達式:

圖八:匹配IP地址
IP地址中的句點字符必須進行轉義處理(前面加上“\”),因為IP地址中的句點具有它本來的含義,而不是采用正則表達式語法中的特殊含義。句點在正則表達式中的特殊含義本文前面已經介紹。
日志記錄的時間部分由一對方括號包圍。你可以按照如下思路提取出方括號里面的所有內容:首先搜索起始方括號字符(“[”),提取出所有不超過結束方括號字符(“]”)的內容,向前尋找直至找到結束方括號字符。圖九顯示了這部分的正則表達式。

圖九:匹配至少一個字符,直至找到“]”
現在,把上述兩個正則表達式加上分組符號(圓括號)后合并成單個表達式,這樣就可以從日志記錄提取出IP地址和時間。注意,為了匹配“- -”(但不提取它),正則表達式中間加入了“\s-\s-\s”。完整的正則表達式如圖十所示。

圖十:匹配IP地址和時間標記
現在正則表達式已經編寫完畢,接下來可以編寫使用正則表達式庫的Java代碼了。
為使用Jakarta-ORO庫,首先創建正則表達式字符串和待分析的日志記錄字符串:

這里使用的正則表達式與圖十的正則表達式差不多完全相同,但有一點例外:在Java中,你必須對每一個向前的斜杠(“\”)進行轉義處理。圖十不是Java的表示形式,所以我們要在每個“\”前面加上一個“\”以免出現編譯錯誤。遺憾的是,轉義處理過程很容易出現錯誤,所以應該小心謹慎。你可以首先輸入未經轉義處理的正則表達式,然后從左到右依次把每一個“\”替換成“\\”。如果要復檢,你可以試著把它輸出到屏幕上。
初始化字符串之后,實例化PatternCompiler對象,用PatternCompiler編譯正則表達式創建一個Pattern對象:

現在,創建PatternMatcher對象,調用PatternMatcher接口的contain()方法檢查匹配情況:

接下來,利用PatternMatcher接口返回的MatchResult對象,輸出匹配的組。由于logEntry字符串包含匹配的內容,你可以看到類如下面的輸出:

3.2 HTML處理實例一
下面一個任務是分析HTML頁面內FONT標記的所有屬性。HTML頁面內典型的FONT標記如下所示:

程序將按照如下形式,輸出每一個FONT標記的屬性:

在這種情況下,我建議你使用兩個正則表達式。第一個如圖十一所示,它從字體標記提取出“"face="Arial, Serif" size="+2" color="red"”。

圖十一:匹配FONT標記的所有屬性
第二個正則表達式如圖十二所示,它把各個屬性分割成名字-值對。

圖十二:匹配單個屬性,并把它分割成名字-值對
分割結果為:

現在我們來看看完成這個任務的Java代碼。首先創建兩個正則表達式字符串,用Perl5Compiler把它們編譯成Pattern對象。編譯正則表達式的時候,指定Perl5Compiler.CASE_INSENSITIVE_MASK選項,使得匹配操作不區分大小寫。
接下來,創建一個執行匹配操作的Perl5Matcher對象。

假設有一個String類型的變量html,它代表了HTML文件中的一行內容。如果html字符串包含FONT標記,匹配器將返回true。此時,你可以用匹配器對象返回的MatchResult對象獲得第一個組,它包含了FONT的所有屬性:

接下來創建一個PatternMatcherInput對象。這個對象允許你從最后一次匹配的位置開始繼續進行匹配操作,因此,它很適合于提取FONT標記內屬性的名字-值對。創建PatternMatcherInput對象,以參數形式傳入待匹配的字符串。然后,用匹配器實例提取出每一個FONT的屬性。這通過指定PatternMatcherInput對象(而不是字符串對象)為參數,反復地調用PatternMatcher對象的contains()方法完成。PatternMatcherInput對象之中的每一次迭代將把它內部的指針向前移動,下一次檢測將從前一次匹配位置的后面開始。
本例的輸出結果如下:

3.3 HTML處理實例二
下面我們來看看另一個處理HTML的例子。這一次,我們假定Web服務器從widgets.acme.com移到了newserver.acme.com。現在你要修改一些頁面中的鏈接:

執行這個搜索的正則表達式如圖十三所示:

圖十三:匹配修改前的鏈接
如果能夠匹配這個正則表達式,你可以用下面的內容替換圖十三的鏈接:

注意#字符的后面加上了$1。Perl正則表達式語法用$1、$2等表示已經匹配且提取出來的組。圖十三的表達式把所有作為一個組匹配和提取出來的內容附加到鏈接的后面。
現在,返回Java。就象前面我們所做的那樣,你必須創建測試字符串,創建把正則表達式編譯到Pattern對象所必需的對象,以及創建一個PatternMatcher對象:

接下來,用com.oroinc.text.regex包Util類的substitute()靜態方法進行替換,輸出結果字符串:

Util.substitute()方法的語法如下:

這個調用的前兩個參數是以前創建的PatternMatcher和Pattern對象。第三個參數是一個Substiution對象,它決定了替換操作如何進行。本例使用的是Perl5Substitution對象,它能夠進行Perl5風格的替換。第四個參數是想要進行替換操作的字符串,最后一個參數允許指定是否替換模式的所有匹配子串(Util.SUBSTITUTE_ALL),或只替換指定的次數。
【結束語】在這篇文章中,我為你介紹了正則表達式的強大功能。只要正確運用,正則表達式能夠在字符串提取和文本修改中起到很大的作用。另外,我還介紹了如何在Java程序中通過Jakarta-ORO庫利用正則表達式。至于最終采用老式的字符串處理方式(使用StringTokenizer,charAt,和substring),還是采用正則表達式,這就有待你自己決定了
原文地址:http://www.ccw.com.cn/htm/app/aprog/01_7_31_4.asp
入門簡介
簡單的說,正則表達式是一種可以用于模式匹配和替換的強有力的工具。我們可以在幾乎所有的基于UNIX系統的工具中找到正則表達式的身影,例如,vi編輯器,Perl或PHP腳本語言,以及awk或sed shell程序等。此外,象JavaScript這種客戶端的腳本語言也提供了對正則表達式的支持。由此可見,正則表達式已經超出了某種語言或某個系統的局限,成為人們廣為接受的概念和功能。
正則表達式可以讓用戶通過使用一系列的特殊字符構建匹配模式,然后把匹配模式與數據文件、程序輸入以及WEB頁面的表單輸入等目標對象進行比較,根據比較對象中是否包含匹配模式,執行相應的程序。
舉例來說,正則表達式的一個最為普遍的應用就是用于驗證用戶在線輸入的郵件地址的格式是否正確。如果通過正則表達式驗證用戶郵件地址的格式正確,用戶所填寫的表單信息將會被正常處理;反之,如果用戶輸入的郵件地址與正則表達的模式不匹配,將會彈出提示信息,要求用戶重新輸入正確的郵件地址。由此可見正則表達式在WEB應用的邏輯判斷中具有舉足輕重的作用。
基本語法
在對正則表達式的功能和作用有了初步的了解之后,我們就來具體看一下正則表達式的語法格式。
正則表達式的形式一般如下:
/love/
其中位于“/”定界符之間的部分就是將要在目標對象中進行匹配的模式。用戶只要把希望查找匹配對象的模式內容放入“/”定界符之間即可。為了能夠使用戶更加靈活的定制模式內容,正則表達式提供了專門的“元字符”。所謂元字符就是指那些在正則表達式中具有特殊意義的專用字符,可以用來規定其前導字符(即位于元字符前面的字符)在目標對象中的出現模式。
較為常用的元字符包括: “+”, “*”,以及 “?”。其中,“+”元字符規定其前導字符必須在目標對象? 續出現一次或多次,“*”元字符規定其前導字符必須在目標對象中出現零次或連續多次,而“?”元字符規定其前導對象必須在目標對象中連續出現零次或一次。
下面,就讓我們來看一下正則表達式元字符的具體應用。
/fo+/
因為上述正則表達式中包含“+”元字符,表示可以與目標對象中的 “fool”, “fo”, 或者 “football”等在字母f后面連續出現一個或多個字母o的字符串相匹配。
/eg*/
因為上述正則表達式中包含“*”元字符,表示可以與目標對象中的 “easy”, “ego”, 或者 “egg”等在字母e后面連續出現零個或多個字母g的字符串相匹配。
/Wil?/
因為上述正則表達式中包含“?”元字符,表示可以與目標對象中的 “Win”, 或者 “Wilson”,等在字母i后面連續出現零個或一個字母l的字符串相匹配。
除了元字符之外,用戶還可以精確指定模式在匹配對象中出現的頻率。例如,
/jim{2,6}/
上述正則表達式規定字符m可以在匹配對象中連續出現2-6次,因此,上述正則表達式可以同jimmy或jimmmmmy等字符串相匹配。
在對如何使用正則表達式有了初步了解之后,我們來看一下其它幾個重要的元字符的使用方式。
\s:用于匹配單個空格符,包括tab鍵和換行符;
\S:用于匹配除單個空格符之外的所有字符;
\d:用于匹配從0到9的數字;
\w:用于匹配字母,數字或下劃線字符;
\W:用于匹配所有與\w不匹配的字符;
. :用于匹配除換行符之外的所有字符。
(說明:我們可以把\s和\S以及\w和\W看作互為逆運算)
下面,我們就通過實例看一下如何在正則表達式中使用上述元字符。
/\s+/
上述正則表達式可以用于匹配目標對象中的一個或多個空格字符。
/\d000/
如果我們手中有一份復雜的財務報表,那么我們可以通過上述正則表達式輕而易舉的查找到所有總額達千元的款項。
除了我們以上所介紹的元字符之外,正則表達式中還具有另外一種較為獨特的專用字符,即定位符。定位符用于規定匹配模式在目標對象中的出現位置。
較為常用的定位符包括: “^”, “$”, “\b” 以及 “\B”。其中,“^”定位符規定匹配模式必須出現在目標字符串的開頭,“$”定位符規定匹配模式必須出現在目標對象的結尾,\b定位符規定匹配模式必須出現在目標字符串的開頭或結尾的兩個邊界之一,而“\B”定位符則規定匹配對象必須位于目標字符串的開頭和結尾兩個邊界之內,即匹配對象既不能作為目標字符串的開頭,也不能作為目標字符串的結尾。同樣,我們也可以把“^”和“$”以及“\b”和“\B”看作是互為逆運算的兩組定位符。舉例來說:
/^hell/
因為上述正則表達式中包含“^”定位符,所以可以與目標對象中以 “hell”, “hello”或 “hellhound”開頭的字符串相匹配。
/ar$/
因為上述正則表達式中包含“$”定位符,所以可以與目標對象中以 “car”, “bar”或 “ar” 結尾的字符串相匹配。
/\bbom/
因為上述正則表達式模式以“\b”定位符開頭,所以可以與目標對象中以 “bomb”, 或 “bom”開頭的字符串相匹配。
/man\b/
因為上述正則表達式模式以“\b”定位符結尾,所以可以與目標對象中以 “human”, “woman”或 “man”結尾的字符串相匹配。
為了能夠方便用戶更加靈活的設定匹配模式,正則表達式允許使用者在匹配模式中指定某一個范圍而不局限于具體的字符。例如:
/[A-Z]/
上述正則表達式將會與從A到Z范圍內任何一個大寫字母相匹配。
/[a-z]/
上述正則表達式將會與從a到z范圍內任何一個小寫字母相匹配。
/[0-9]/
上述正則表達式將會與從0到9范圍內任何一個數字相匹配。
/([a-z][A-Z][0-9])+/
上述正則表達式將會與任何由字母和數字組成的字符串,如 “aB0” 等相匹配。這里需要提醒用戶注意的一點就是可以在正則表達式中使用 “()” 把字符串組合在一起。“()”符號包含的內容必須同時出現在目標對象中。因此,上述正則表達式將無法與諸如 “abc”等的字符串匹配,因為“abc”中的最后一個字符為字母而非數字。
如果我們希望在正則表達式中實現類似編程邏輯中的“或”運算,在多個不同的模式中任選一個進行匹配的話,可以使用管道符 “|”。例如:
/to|too|2/
上述正則表達式將會與目標對象中的 “to”, “too”, 或 “2” 相匹配。
正則表達式中還有一個較為常用的運算符,即否定符 “[^]”。與我們前文所介紹的定位符 “^” 不同,否定符 “[^]”規定目標對象中不能存在模式中所規定的字符串。例如:
/[^A-C]/
上述字符串將會與目標對象中除A,B,和C之外的任何字符相匹配。一般來說,當“^”出現在 “[]”內時就被視做否定運算符;而當“^”位于“[]”之外,或沒有“[]”時,則應當被視做定位符。
最后,當用戶需要在正則表達式的模式中加入元字符,并查找其匹配對象時,可以使用轉義符“\”。例如:
/Th\*/
上述正則表達式將會與目標對象中的“Th*”而非“The”等相匹配。
原文鏈接:http://www.yesky.com/181/51681.shtml
public String[] split(String regex)
- 根據給定的正則表達式的匹配來拆分此字符串。
該方法的作用就像是使用給定的表達式和限制參數 0 來調用兩參數
split方法。因此,結果數組中不包括結尾空字符串。例如,字符串 "boo:and:foo" 產生帶有下面這些表達式的結果:
Regex 結果 : { "boo", "and", "foo" } o { "b", "", ":and:f" } - 參數:
regex- 定界正則表達式- 返回: 字符串數組,根據給定正則表達式的匹配來拆分此字符串,從而生成此數組。
- 拋出:
PatternSyntaxException- 如果正則表達式的語法無效 - 返回: 字符串數組,根據給定正則表達式的匹配來拆分此字符串,從而生成此數組。
public String[] split(String regex, int limit)
- 根據匹配給定的正則表達式來拆分此字符串。
此方法返回的數組包含此字符串的每個子字符串,這些子字符串由另一個匹配給定的表達式的子字符串終止或由字符串結束來終止。數組中的子字符串按它們在此字符串中的順序排列。如果表達式不匹配輸入的任何部分,則結果數組只具有一個元素,即此字符串。
limit 參數控制模式應用的次數,因此影響結果數組的長度。如果該限制 n 大于 0,則模式將被最多應用 n - 1 次,數組的長度將不會大于 n,而且數組的最后項將包含超出最后匹配的定界符的所有輸入。如果 n 為非正,則模式將被應用盡可能多的次數,而且數組可以是任意長度。如果 n 為零,則模式將被應用盡可能多的次數,數組可有任何長度,并且結尾空字符串將被丟棄。
例如,字符串 "boo:and:foo" 使用這些參數可生成下列結果:
Regex Limit 結果 : 2 { "boo", "and:foo" } : 5 { "boo", "and", "foo" } : -2 { "boo", "and", "foo" } o 5 { "b", "", ":and:f", "", "" } o -2 { "b", "", ":and:f", "", "" } o 0 { "b", "", ":and:f" } 這種形式的方法調用 str.split(regex, n) 產生與以下表達式完全相同的結果:
Pattern.compile(regex).split(str, n)參數:
regex- 定界正則表達式 ;limit- 結果閾值,如上所述- 返回: 字符串數組,根據給定正則表達式的匹配來拆分此字符串,從而生成此數組
public String replaceAll(String regex, String replacement)
- 使用給定的 replacement 字符串替換此字符串匹配給定的正則表達式的每個子字符串。
此方法調用的 str.replaceAll(regex, repl) 形式產生與以下表達式完全相同的結果:
Pattern.compile(regex).matcher(str).replaceAll(repl)參數:
regex- 用來匹配此字符串的正則表達式- 返回: 得到的 String
public String replaceFirst(String regex, String replacement)
- 使用給定的 replacement 字符串替換此字符串匹配給定的正則表達式的第一個子字符串。
此方法調用的 str.replaceFirst(regex, repl) 形式產生與以下表達式完全相同的結果:
Pattern.compile(regex).matcher(str).replaceFirst(repl)參數:
regex- 用來匹配此字符串的正則表達式- 返回: 得到的 String
這四個方法中都有一個參數為正則表達式(Regular Expression),而不是普通的字符串。
|
特殊字符 |
描述 |
| . | 表示任意一個字符 |
| [abc] | 表示a、b或c中的任意一個字符 |
| [^abc] | 除a、b和c以外的任意一個字符 |
| [a-zA-z] | 介于a到z,或A到Z中的任意一個字符 |
| \s | 空白符(空格、tab、換行、換頁、回車) |
| \S | 非空白符 |
| \d | 任意一個數字[0-9] |
| \D | 任意一個非數字[^0-9] |
| \w | 詞字符[a-zA-Z_0-9] |
| \W | 非詞字符 |
表示字符出現次數的符號
|
表示次數的符號 |
描述 |
| * | 0 次或者多次 |
| + | 1 次或者多次 |
| ? | 0 次或者 1 次 |
| {n} | 恰好 n 次 |
| {n, m} | 至少 n 次,不多于 m 次 |
/**
* @param args
*/
public static void main(String[] args) {
// 例如,字符串 "boo:and:foo" 產生帶有下面這些表達式的結果: Regex 結果
// : { "boo", "and", "foo" }
// o { "b", "", ":and:f" }
String tempStr = "boo:and:foo";
String[] a = tempStr.split(":");
pringStringArray(a);
String[] b = tempStr.split("o");
pringStringArray(b);
System.out.println("--------------------------");
// Regex Limit 結果
// : 2 { "boo", "and:foo" }
// : 5 { "boo", "and", "foo" }
// : -2 { "boo", "and", "foo" }
// o 5 { "b", "", ":and:f", "", "" }
// o -2 { "b", "", ":and:f", "", "" }
// o 0 { "b", "", ":and:f" }
pringStringArray(tempStr.split(":", 2));
pringStringArray(tempStr.split(":", 5));
pringStringArray(tempStr.split(":", -2));
pringStringArray(tempStr.split("o", 5));
pringStringArray(tempStr.split("o", -2));
pringStringArray(tempStr.split("o", 0));
// 字符串 "boo:and:foo"中的所有“:”都被替換為“XX”,輸出:booXXandXXfoo
System.out.println(tempStr.replaceAll(":", "XX"));
// 字符串 "boo:and:foo"中的第一個“:”都被替換為“XX”,輸出: booXXand:foo
System.out.println(tempStr.replaceFirst(":", "XX"));
}
public static void pringStringArray(String[] s) {
int index = s.length;
for (int i = 0; i < index; i++) {
System.err.println(i + ": " + s[i]);
}
}
}
下面的程序演示了正則表達式的用法:
* discription:
*
* @author CoderDream
*
*/
public class RegularExTester {
/**
* @param args
*/
public static void main(String[] args) {
// 把字符串中的“aaa”全部替換為“z”,打印:zbzcz
System.out.println("aaabaaacaaa".replaceAll("a{3}", "z"));
// 把字符串中的“aaa”、“aa”或者“a”全部替換為“*”,打印:*b*c*
System.out.println("aaabaaca".replaceAll("a{1,3}", "\\*"));
// 把字符串中的數字全部替換為“z”,打印:zzzazzbzzcc
System.out.println("123a44b35cc".replaceAll("\\d", "z"));
// 把字符串中的非數字全部替換為“0”,打印:1234000435000
System.out.println("1234abc435def".replaceAll("\\D", "0"));
// 把字符串中的“.”全部替換為“\”,打印:com\abc\dollapp\Doll
System.out.println("com.abc.dollapp.Doll".replaceAll("\\.", "\\\\"));
// 把字符串中的“a.b”全部替換為“_”,
// “a.b”表示長度為3的字符串,以“a”開頭,以“b”結尾
// 打印:-hello-all
System.out.println("azbhelloahball".replaceAll("a.b", "-"));
// 把字符串中的所有詞字符替換為“#”
// 正則表達式“[a-zA-z_0-9]”等價于“\w”
// 打印:#.#.#.#.#.#
System.out.println("a.b.c.1.2.3.4".replaceAll("[a-zA-z_0-9]", "#"));
System.out.println("a.b.c.1.2.3.4".replaceAll("\\w", "#"));
}
}
值得注意的是,由于“.”、“?”和“*”等在正則表達式中具有特殊的含義,如果要表示字面上的這些字符,必須以“\\”開頭。例如為了把字符串“com.abc.dollapp.Doll”中的“.”替換為“\”,應該調用replaceAll("\\.",\\\\)方法。
Java中的正則表達式類
public interface MatchResult
匹配操作的結果。
此接口包含用于確定與正則表達式匹配結果的查詢方法。通過 MatchResult 可以查看匹配邊界、組和組邊界,但是不能修改
public final class Matcher
-
- extends Object
- implements MatchResult
- extends Object
通過解釋 Pattern 對 字符序列 執行匹配操作的引擎。
通過調用模式的 matcher 方法從模式創建匹配器。創建匹配器后,可以使用它執行三種不同的匹配操作:
每個方法都返回一個表示成功或失敗的布爾值。通過查詢匹配器的狀態可以獲取關于成功匹配的更多信息。
public final class Pattern
-
- extends Object
- implements Serializable
- extends Object
正則表達式的編譯表示形式。
指定為字符串的正則表達式必須首先被編譯為此類的實例。然后,可將得到的模式用于創建 Matcher 對象,依照正則表達式,該對象可以與任意字符序列匹配。執行匹配所涉及的所有狀態都駐留在匹配器中,所以多個匹配器可以共享同一模式。
因此,典型的調用順序是
Pattern p = Pattern.matches();
在僅使用一次正則表達式時,可以方便地通過此類定義 matches 方法。此方法編譯表達式并在單個調用中將輸入序列與其匹配。語句
boolean b = Pattern.matches("a*b", "aaaaab");
等效于上面的三個語句,盡管對于重復的匹配而言它效率不高,因為它不允許重用已編譯的模式。
此類的實例是不可變的,可供多個并發線程安全使用。Matcher 類的實例用于此目的則不安全。
測試代碼:
* discription:Java中正則表達式類的使用
*
* @author CoderDream
*
*/
public class RegDemo {
/**
* @param args
*/
public static void main(String[] args) {
// 檢查字符串中是否含有“aaa”,有返回:true,無返回:false
System.out.println(isHaveBeenSetting("a{3}", "aaabaaacaaa"));
System.out.println(isHaveBeenSetting("a{3}", "aab"));
// 把字符串“abbaaacbaaaab”中的“aaa”全部替換為“z”,打印:abbzbza
System.out.println(replaceStr("a{3}", "abbaaabaaaa", "z"));
}
/**
*
* @param regEx
* 設定的正則表達式
* @param tempStr
* 系統參數中的設定的字符串
* @return 是否系統參數中的設定的字符串含有設定的正則表達式 如果有的則返回true
*/
public static boolean isHaveBeenSetting(String regEx, String tempStr) {
boolean result = false;
try {
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(tempStr);
result = m.find();
} catch (Exception e) {
e.printStackTrace();
}
return result;
}
/**
* 將字符串含有的regEx表達式替換為replaceRegEx
*
* @param regEx
* 需要被替換的正則表達式
* @param tempStr
* 替換的字符串
* @param replaceRegEx
* 替換的正則表達式
* @return 替換好后的字符串
*/
public static String replaceStr(String regEx, String tempStr,
String replaceRegEx) {
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(tempStr);
tempStr = m.replaceAll(replaceRegEx);
return tempStr;
}
}
實踐2:對不變的data和object reference使用final
實踐3:缺省情況下所有non-static函數都可被重寫
實踐4:在array和Vectors之間慎重選擇
實踐5:多態(polymorphism)優于instanceof
實踐6:必要時才使用instanceof
實踐7:一旦不需要object reference,就將它設為null
實踐1:參數以by value方式而非by reference方式傳遞
class PassByValue {
public static void modifyPoint(Point pt, int j) {
pt.setLocation(5, 5); // 1
j = 15;
System.out.println("During modifyPoint " + "pt = " + pt + " and j = " + j);
}
public static void main(String args[]) {
Point p = new Point(0, 0); // 2
int i = 10;
System.out.println("Before modifyPoint " + "p = " + p + " and i = " + i);
modifyPoint(p, i); // 3
System.out.println("After modifyPoint " + "p = " + p + " and i = " + i);
}
}
程序輸出如下:
During modifyPoint pt = java.awt.Point[x=5,y=5] and j = 15
After modifyPoint p = java.awt.Point[x=5,y=5] and i = 10
這顯示modifyPoint()改變了//2 所建立的Point對象,卻沒有改變int i。在main()之中,i被賦值10.由于參數通過by value方式傳遞,所以modifyPoint()收到i的一個副本,然后它將這個副本改為15并返回。main()內的原值i并沒有受到影響。
對比之下,事實上modifyPoint() 是在與“Point 對象的 reference 的復件”打交道,而不是與“Point對象的復件”打交道。當p從main()被傳入modifyPoint()時,傳遞的是p(也就是一個reference)的復件。所以modifyPoint()是在與同一個對象打交道,只不過通過別名pt罷了。在進入modifyPoint()之后和執行 //1 之前,這個對象看起來是這樣:
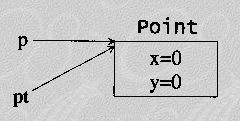
所以//1 執行以后,這個Point對象已經改變為(5,5)。
實踐2:對不變的data和object reference使用final
Java 關鍵字 final 用來表示常量數據。例如:
static final int someInt = 10;
//

}
這段代碼聲明了一個 static 類變量,命名為 someInt,并設其初值為10。
任何試圖修改 someInt 的代碼都將無法通過編譯。例如:
someInt = 9; // Error
//
關鍵字 final 可防止 classes 內的 instance 數據遭到無意間的修改。如果我們想要一個常量對象,又該如何呢?例如:
private double rad;
public Circle(double r) {
rad = r;
}
public void setRadius(double r) {
rad = r;
}
public double radius() {
return rad;
}
}
public class FinalTest {
private static final Circle wheel = new Circle(5.0);
public static void main(String args[]) {
System.out.println("Radius of wheel is " + wheel.radius());
wheel.setRadius(7.4);
System.out.println("Radius of wheel is now " + wheel.radius());
}
}
這段代碼的輸出是:
Radius of wheel is now 7.4
在上述第一個示例中,我們企圖改變final 數據值時,編譯器會偵測出錯誤。
在第二個示例中,雖然代碼改變了 instance變量wheel的值,編譯器還是讓它通過了。我們已經明確聲明wheel為final,它怎么還能被改變呢?
不,我們確實沒有改變 wheel 的值,我們改變的是wheel 所指對象的值。wheel 并無變化,仍然指向(代表)同一個對象。變量wheel是一個 object reference,它指向對象所在的heap位置。有鑒如此,下面的代碼會怎樣?
private static final Circle wheel = new Circle(5.0);
public static void main(String args[]) {
System.out.println("Radius of wheel is " + wheel.radius());
wheel = new Circle(7.4); // 1
System.out.println("Radius of wheel is now " + wheel.radius());
}
}
編譯代碼,// 1 處出錯。由于我們企圖改變 final 型變量 wheel 的值,所以這個示例將產生編譯錯誤。換言之,代碼企圖令wheel指向其他對象。變量wheel是final,因此也是不可變的。它必須永遠指向同一個對象。然而wheel所指向的對象并不受關鍵字final的影響,因此是可變的。
關鍵字 final 只能防止變量值的改變。如果被聲明為 final 的變量是個 object reference,那么該reference不能被改變,必須永遠指向同一個對象,但被指的那個對象可以隨意改變內部的屬性值。
實踐3:缺省情況下所有non-static函數都可以被覆蓋重寫
關鍵字final 在Java中有多重用途,即可被用于instance變量、static變量,也可用于classes或methods,用于類,表示該類不能有子類;用于方法,表示該方法不允許被子類覆蓋。實踐4:在array和vectors之間慎重選擇
array和Vector的比較
|
|
支持基本類型 |
支持對象 |
自動改變大小 |
速度快 |
|
array |
Yes |
Yes |
No |
Yes |
|
Vector |
No(1.5以上支持) |
Yes |
Yes |
No |
實踐5:多態(polymorphism)優于instanceof
代碼1:instanceof方式
public int salary();
}
class Manager implements Employee {
private static final int mgrSal = 40000;
public int salary() {
return mgrSal;
}
}
class Programmer implements Employee {
private static final int prgSal = 50000;
private static final int prgBonus = 10000;
public int salary() {
return prgSal;
}
public int bonus() {
return prgBonus;
}
}
class Payroll {
public int calcPayroll(Employee emp) {
int money = emp.salary();
if (emp instanceof Programmer)
money += ((Programmer) emp).bonus(); // Calculate the bonus
return money;
}
public static void main(String args[]) {
Payroll pr = new Payroll();
Programmer prg = new Programmer();
Manager mgr = new Manager();
System.out.println("Payroll for Programmer is " + pr.calcPayroll(prg));
System.out.println("payroll for Manager is " + pr.calcPayroll(mgr));
}
}
代碼2:多態方式
public int salary();
public int bonus();
}
class Manager implements Employee {
private static final int mgrSal = 40000;
private static final int mgrBonus = 0;
public int salary() {
return mgrSal;
}
public int bonus() {
return mgrBonus;
}
}
class Programmer implements Employee {
private static final int prgSal = 50000;
private static final int prgBonus = 10000;
public int salary() {
return prgSal;
}
public int bonus() {
return prgBonus;
}
}
class Payroll {
public int calcPayroll(Employee emp) {
// Calculate the bonus. No instanceof check needed.
return emp.salary() + emp.bonus();
}
public static void main(String args[]) {
Payroll pr = new Payroll();
Programmer prg = new Programmer();
Manager mgr = new Manager();
System.out.println("Payroll for Programmer is " + pr.calcPayroll(prg));
System.out.println("Payroll for Manager is " + pr.calcPayroll(mgr));
}
}
實踐6:必要時才使用instanceof
class Shape {
}
class Circle extends Shape {
public double radius() {
return 5.7;
}
//
}
class Triangle extends Shape {
public boolean isRightTriangle() {
// Code to determine if triangle is right
return true;
}
//
}
class StoreShapes {
public static void main(String args[]) {
Vector shapeVector = new Vector(10);
shapeVector.add(new Triangle());
shapeVector.add(new Triangle());
shapeVector.add(new Circle());
//
// Assume many Triangles and Circles are added and removed
//
int size = shapeVector.size();
for (int i = 0; i < size; i++) {
Object o = shapeVector.get(i);
if (o instanceof Triangle) {
if (((Triangle) o).isRightTriangle()) {
//
}
} else if (o instanceof Circle) {
double rad = ((Circle) o).radius();
//
}
}
}
}